黄金点第四次博客
1 上周回顾:
在已有图形界面的基础上,我们通过前端后端的综合运用,改变了以前游戏数据的 “即用即存” 的形式,而是将玩家的历史选择、历史得分、历史黄金点都放入了本地数据库中,需要时直接调用,结合前端 html,js 等方法渲染可视化分析结果(折线图、箱型图、柱形图等)。但我们也发现了程序运行时还存在一点 bug ,在后续开发过程中我们会逐渐完善。
2 本周内容介绍
本周针对以下几个方面进行优化、开发:
- 将每次用户的输入改为 2 个数,用户的最终参与黄金点判定时的选择为两个输入数据的平均数;
- 针对 bug 的优化
- 继续针对需求建立预测模块(采用强化学习 Q-Learning 模型)并逐步实现
3 本周工作成果展示
3.1 AI 预测部分
考虑到程序运算执行的时间,在这里我们只设置 7 种状态,分别为第 4 局 ~ 第10局。由于在之前的博客中已经写到,如果都是 “聪明” 的玩家,那么第 10 局之后的黄金点将会在 0.5 ~ 3 之间波动,此时预测的效果将不显著,因此想要赢得最后累计最多的分数,在第 1 ~ 10 局将会是最好的机会。
① 设置一个一维数组全局变量 action, 每轮更新:
static double[] action = new double[]{ 前一轮的黄金点, 前两轮黄金点的均值, 前三轮黄金点的均值, 前十轮中每隔 1 轮进行采样后的黄金点的均值, 前十轮中每隔 2 轮进行采样后的黄金点的均值, 前十轮中最大的三个的GN的均值, 前十轮中最小的三个的GN的均值, };
action[0] = gold_point[i - 1]; action[1] = (gold_point[i - 1] + gold_point[i - 2]) / 2; action[2] = (gold_point[i - 1] + gold_point[i - 2] + gold_point[i - 3]) / 3; // 第四个动作:当前前10轮每隔1轮取黄金点均值 int temp = 0, temp_count = 0; for(int j = i; j >= 0; j -= 2) { temp += a[j], temp_count++; if(temp_count > 10) break; } action[3] = temp / temp_count; // 第五个动作:当前前10轮每隔2轮取黄金点均值 temp = 0, temp_count = 0; for(int j = i; j >= 0; j -= 3) { temp += a[j], temp_count++; if(temp_count > 10) break; } action[4] = temp / temp_count; // 用一个临时数组temp_gold_point[]把当前前10局的黄金点存入 quickSort(temp_gold_point, 0, n - 1); action[5] = (temp_gold_point[n - 1] + temp_gold_point[n - 2] + temp_gold_point[n - 3]) / 3; action[6] = (temp_gold_point[0] + temp_gold_point[1] + temp_gold_point[2]) / 3;
// 其中的快速排序算法 public static void quickSort(double a[], int low, int high){ if(low >= high) return; double temp = a[low + high >> 1], l = low - 1, r = high + 1; while(l < r){ do i++; while(a[l] < temp); do r--; while(a[r] > temp); if(l < r) swap(a[l], a[r]); } quickSort(a, low, r), quickSort(a, r + 1, high); }
②初始化 Q 表
double[][] Q = new double[][] {
{0, 0, 0, 0, 0, 0, 0},
{-1, -1, -1, -1, -1, -1, -1},
{-1, -1, -1, -1, -1, -1, -1},
{-1, -1, -1, -1, -1, -1, -1},
{-1, -1, -1, -1, -1, -1, -1},
{-1, -1, -1, -1, -1, -1, -1},
{-1, -1, -1, -1, -1, -1, -1}
};
这里解释一下我们所理解的 state 状态:我们认为,每一个状态就是结合当前所在轮的所知的所有信息基础上的状态,假定从第 4 - 10 轮开始,共 7 轮,之后每七轮重新定义一次状态。当前的 “预测” 功能可以基于当前状态,在每一个状态都可以最期望的分数。比如从第4轮开始预测,那第一行的 7 个动作都为 0,代表此时七个动作都可以选择;第 2 ~ 7 行此时为 -1,代表当前还没有到后面几轮,所以 Q 表值为 -1,此时不能选择。后面会根据当前的轮数重新设置 Q 表。
③设置奖励
int reward = abs(action[i] - (gold_point[i - 1] + gold_point[i - 2]) / 2); // 奖励 = 每个动作的选择数所减去上两轮黄金点的平均值的绝对值
④完整模块代码
package homework; import java.util.Arrays; import static com.sun.tools.javac.jvm.ByteCodes.swap; import static java.lang.Math.*; public class QLearning { /* 每一局游戏都要更新,全局变量 double[] possible_choice = new double[]{ 前一轮的黄金点, 前两轮黄金点的均值, 前三轮黄金点的均值, 前十轮中每隔 1 轮进行采样后的黄金点的均值, 前十轮中每隔 2 轮进行采样后的黄金点的均值, 前十轮中最大的三个的GN的均值, 前十轮中最小的三个的GN的均值, }; */ public static void main(String[] args) { double[][] Q = new double[][] { {0, 0, 0, 0, 0, 0, 0}, {-1, -1, -1, -1, -1, -1, -1}, {-1, -1, -1, -1, -1, -1, -1}, {-1, -1, -1, -1, -1, -1, -1}, {-1, -1, -1, -1, -1, -1, -1}, {-1, -1, -1, -1, -1, -1, -1}, {-1, -1, -1, -1, -1, -1, -1} }; double epsilon = 0.8; double alpha = 0.2; double gamma = 0.8; int N = 10; int MAX_EPISODES = 400; // 一般都通过设置最大迭代次数来控制训练轮数 action[0] = gold_point[i - 1]; action[1] = (gold_point[i - 1] + gold_point[i - 2]) / 2; action[2] = (gold_point[i - 1] + gold_point[i - 2] + gold_point[i - 3]) / 3; // 第四个动作:当前前10轮每隔1轮取黄金点均值 int temp = 0, temp_count = 0; for(int j = i; j >= 0; j -= 2) { temp += a[j], temp_count++; if(temp_count > 10) break; } action[3] = temp / temp_count; // 第五个动作:当前前10轮每隔2轮取黄金点均值 temp = 0, temp_count = 0; for(int j = i; j >= 0; j -= 3) { temp += a[j], temp_count++; if(temp_count > 10) break; } action[4] = temp / temp_count; // 用一个临时数组temp_gold_point[]把当前前10局的黄金点存入 quickSort(temp_gold_point, 0, n - 1); action[5] = (temp_gold_point[n - 1] + temp_gold_point[n - 2] + temp_gold_point[n - 3]) / 3; action[6] = (temp_gold_point[0] + temp_gold_point[1] + temp_gold_point[2]) / 3; for(int episode = 0; episode < MAX_EPISODES; ++episode) { System.out.println("第"+episode+"轮训练..."); int index = 0; while(index <= 9) { // 到达目标状态,结束循环,进行下一轮训练 int next; if(Math.random() < epsilon) next = max(Q[index]); // 通过 Q 表选择动作 else next = randomNext(Q[index]); // 随机选择可行动作 /*if(index == 0) next = Q[index][0]; if(index == 1){ if(Math.random() < epsilon) next = max(Q[index][0], Q[index][1]); else next = randomNext(Q[index]); }*/ // 每一轮更新所有action对应的值 int reward = abs(action[i] - pre_round_gp); // 奖励 = 每个动作所减去 Q[index][next] = (1-alpha)*Q[index][next] + alpha*(reward+gamma*maxNextQ(Q[next])); index = next; // 更新状态 } } System.out.println(Arrays.deepToString(Q)); } private static int randomNext(double[] is) { // 蓄水池抽样,等概率选择流式数据 int next = 0, n = 1; for(int i = 0; i < is.length; ++i) { if(is[i] >= 0 && Math.random() < 1.0/n++) next = i; } return next; } private static int max(double[] is) { int max = 0; for(int i = 1; i < is.length; ++i) { if(is[i] > is[max]) max = i; } return max; } private static double maxNextQ(double[] is) { double max = is[0]; for(int i = 1; i < is.length; ++i) { if(is[i] > max) max = is[i]; } return max; } // 快速排序 public static void quickSort(double a[], int low, int high){ if(low >= high) return; double temp = a[(low + high) >> 1], l = low - 1, r = high + 1; while(l < r){ do l++; while(a[l] < temp); do r--; while(a[r] > temp); if(l < r) swap(a[l], a[r]); } quickSort(a, low, r), quickSort(a, r + 1, high); } }
⑤选择操作
在训练出较为稳定的代码后,我们选择当前所在行的七个值中最大的两个数作为输入。看一个例子(这里我们还没有加入到整个游戏中,还在改进模型中:)
假设有一个最短路问题:
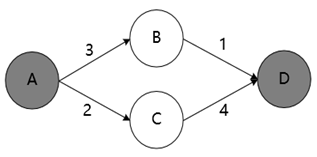
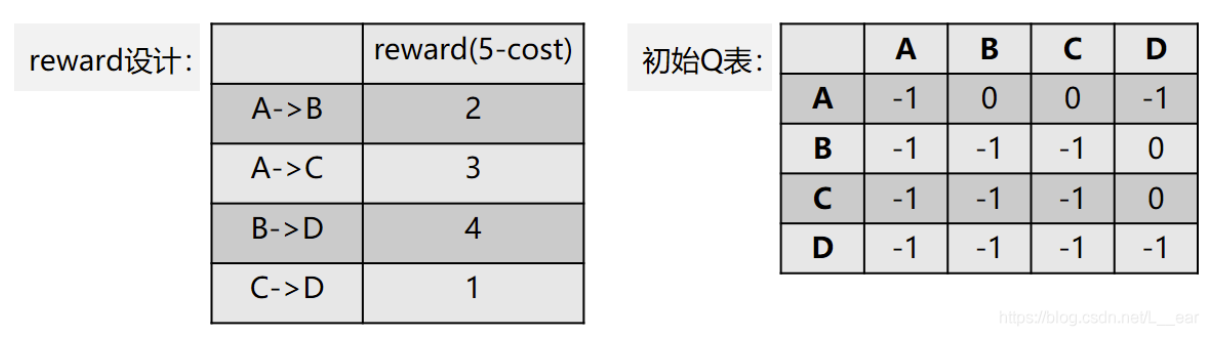
那么,奖励 reward 和 Q 表可以设置成:
训练过程中:
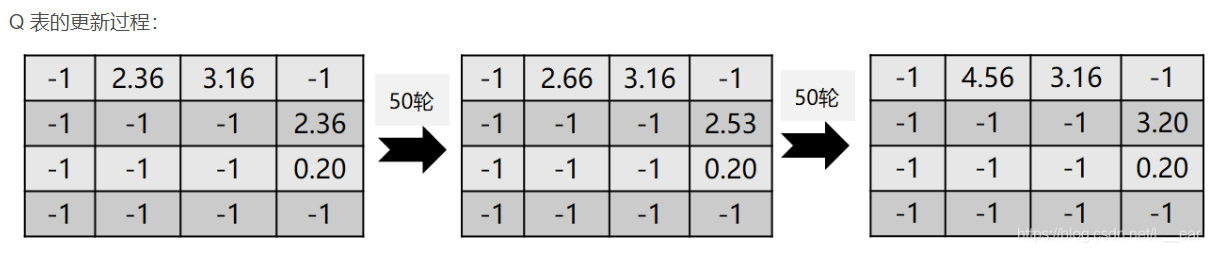
那么,最后的路径选择就是 A -> B(4.56) -> D(3.20),问题解决。我们设想的黄金点思路也是这样。不过我们是 java 语言开发,而且经过不少的资料查阅,用神经网络训练出的 Q-Learning(DNQ)效果并不会显著强于普通 Q-Learning 方法,所以这里为了简便便暂时采用该方法。
3.2 增加成立两个输入
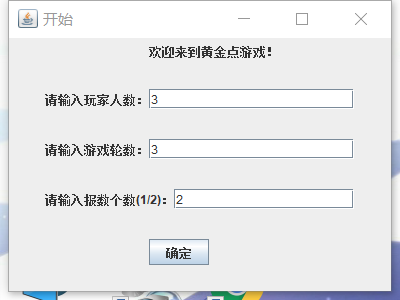
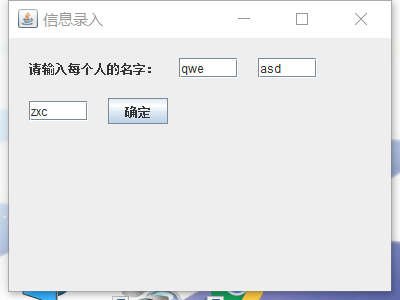
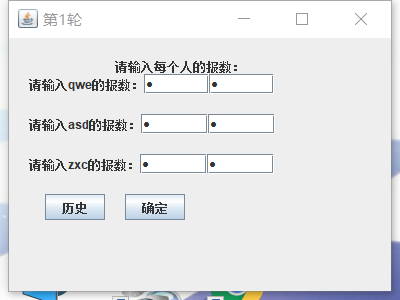
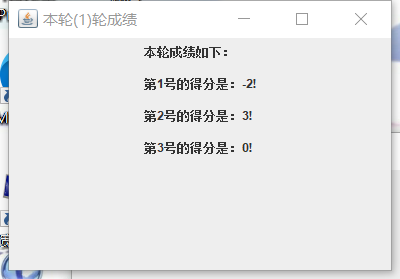
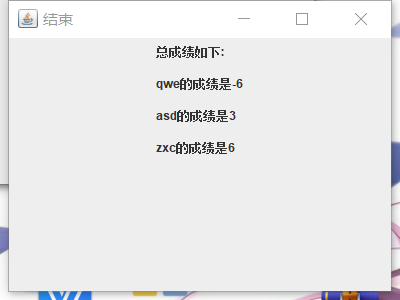
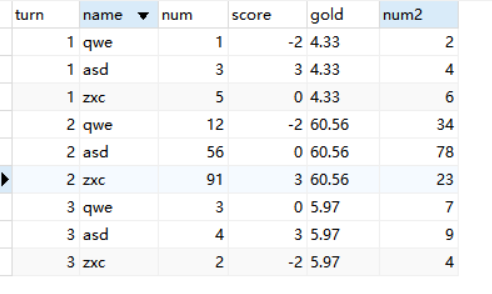
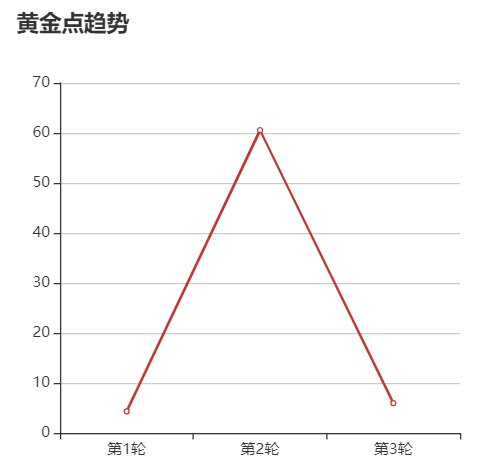
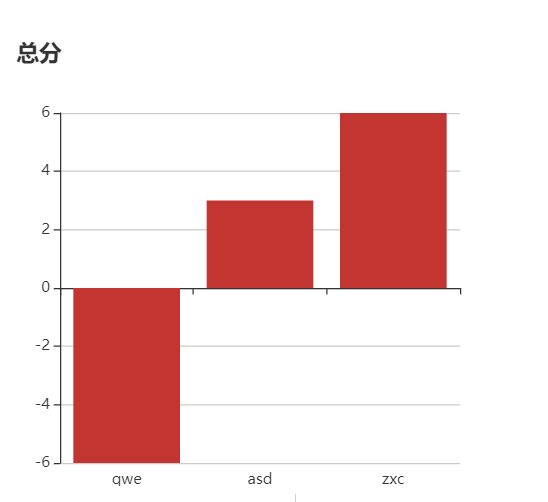
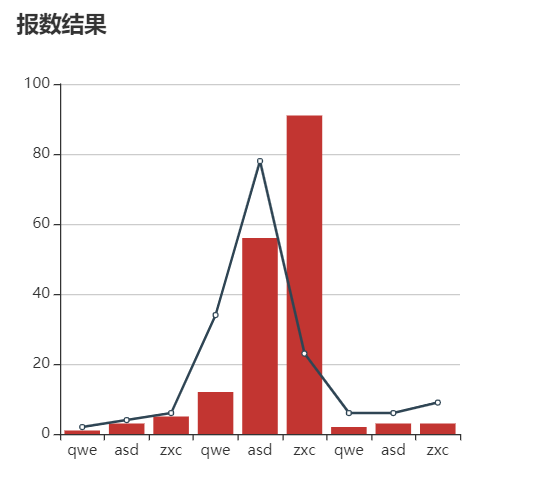
3.3 语音播报
我们在展示每轮成绩以及最后的总成绩时,加入了语音播报功能。语音播报用到了activeX库,先将每轮成绩的展示以字符串的形式存入.txt文件,再由我们设定的方法进行读取并且朗读,可以自由设定播报音量以及速度。
首先是java中对每一轮成绩展示以字符串形式并存入文本文件的方法:
// 写入文件的方法(每次得到了整体的字符串就写一个文件) public static boolean to_write_scores(int turnNum, String str, boolean append){ // turnNum是所展示语音播报的轮数(如第2轮) // str拿到的存储句子, 如 String str = "张三的成绩是:5,\n李四的成绩是:10,\n王五的成绩是8。" // 不同人的成绩间一定要用逗号结尾,因为语音播报句号之间是不会停顿的。 // append为true代表可追加写入,否则不能追加。 boolean falg = false; // 写入文件举例 String file_path = "D:\\软工课设\\"; file_path = file_path + turnNum + ".txt"; // 结果为: D:\\软工课设\\1.txt File file = new File(file_path); try{ if(!file.exists()) file.createNewFile(); // 不存在则创建该文件 FileWriter fw = new FileWriter(file_path, append); // append表示可以追加 fw.write(str); fw.close(); }catch(IOException e){ e.printStackTrace(); } flag = true; return flag; }
然后是语音播报的代码:
// 每次在输入数字后弹出本轮成绩页面的时候,就用这个try, file_path是存文本文件的路径。例如第一局:D:\\1.txt, 第二局:D:\\2.txt。 try{ voice(file_path); }catch(IOException e){ } // 音响方法 public static void voice(String file_path) throws IOException { // 拿到音响 ActiveXComponent sap = new ActiveXComponent("sapi.SpVoice"); // 找到本地要朗读的文件 try { File srcFile = new File(file_path); // 获取文本文档的内容 FileReader file = new FileReader(srcFile); // 从缓存区拿到数据 BufferedReader bf = new BufferedReader(file); // 拿到缓冲区的数据 String content = "", result = ""; //= bf.readLine(); while((content = bf.readLine()) != null){ result += content; } // 测试一下 有没有拿到数据 System.out.println(result); // 调节语速 音量大小 sap.setProperty("Volume", new Variant(100)); sap.setProperty("Rate", new Variant(1)); Dispatch xj = sap.getObject(); // 执行朗读 没有读完就继续读 while (result != null) { Dispatch.call(xj, "Speak", new Variant(result)); } xj.safeRelease(); bf.close(); } catch (FileNotFoundException e) { e.printStackTrace(); sap.safeRelease(); } }
经过实际测试后,程序能够很好地将每轮成绩存入指定文件夹,并且调用该方法进行语音播报。
4 总结
下一步我们将继续优化预测模型,并且开始准备收尾工作:测试并修改 bug,美化软件界面,使可视化结果更加清晰直观,并根据黄金点历史生成游戏的文字总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号