Design Patterns Note (设计模式学习笔记)
C++常用设计模式笔记
前言概述
“每一个模式描述了一个在我们周围不断重复发生的问题, 以及该问题的解决方案的核心。这样,你就能一次又一次地使用该方案而不必做重复劳动”。
——Christopher Alexander
软件设计的金科玉律:可复用!!
变化性就是复用最大天敌,而面向对象设计的最大优势便在于 抵御变化 。
重新认识面向对象
理解隔离变化
• 从宏观层面来看,面向对象的构建方式更能适应软件的变化, 能将变化所带来的影响减为最小
各司其职
• 从微观层面来看,面向对象的方式更强调各个类的“责任”
• 由于需求变化导致的新增类型不应该影响原来类型的实现—— 是所谓各负其责
对象是什么?
• 从语言实现层面来看,对象封装了代码和数据。
• 从规格层面讲,对象是一系列可被使用的公共接口。
• 从概念层面讲,对象是某种拥有责任的抽象。
面向对象设计原则(设计模式的基础)
所有的设计模式都建立在设计原则之上 不可以违背设计原则!
依赖倒置原则(DIP)
• 高层模块(稳定)不应该依赖于低层模块(变化),二者都应该依赖 于抽象(稳定) 。
• 抽象(稳定)不应该依赖于实现细节(变化) ,实现细节应该依赖于 抽象(稳定)
开放封闭原则(OCP)
• 对扩展开放,对更改封闭。
• 类模块应该是可扩展的,但是不可修改。
单一职责原则(SRP)
• 一个类应该仅有一个引起它变化的原因。
• 变化的方向隐含着类的责任。
Liskov 替换原则(LSP)
• 子类必须能够替换它们的基类(IS-A)。
• 继承表达类型抽象。
接口隔离原则(ISP)
• 不应该强迫客户程序依赖它们不用的方法。
• 接口应该小而完备。
优先使用对象组合,而不是类继承
• 类继承通常为“白箱复用”,对象组合通常为“黑箱复用”。
• 继承在某种程度上破坏了封装性,子类父类耦合度高。
• 而对象组合则只要求被组合的对象具有良好定义的接口,耦合 度低。
封装变化点
• 使用封装来创建对象之间的分界层,让设计者可以在分界层的 一侧进行修改,而不会对另一侧产生不良的影响,从而实现层 次间的松耦合。
针对接口编程,而不是针对实现编程
• 不将变量类型声明为某个特定的具体类,而是声明为某个接口。
• 客户程序无需获知对象的具体类型,只需要知道对象所具有的 接口。
• 减少系统中各部分的依赖关系,从而实现“高内聚、松耦合” 的类型设计方案。
从封装变化角度对模式分类
组件协作:
• Template Method
• Observer / Event
• Strategy
单一职责:
• Decorator
• Bridge
对象创建:
• Factory Method
• Abstract Factory
• Prototype
对象性能:
• Singleton
• Flyweight
接口隔离:
• Facade
• Proxy
• Mediator
• Adapter
状态变化:
• Memento
• State
数据结构:
• Composite
• Iterator
• Chain of Resposibility
行为变化:
• Command
• Visitor
领域问题:
• Interpreter
•Builder
模式详解
(各个模式的示例代码请看 设计模式-李建忠 老师的视频示例代码 。 这里贴出来很影响阅读,所以建议搭配学习。只贴出短小的例子)
一. 组件模式
现代软件专业分工之后的第一个结果是“框架与应用程序的划分”,“组件协作”模式通过晚期绑定,来实现框架与应用程序之 间的松耦合,是二者之间协作时常用的模式
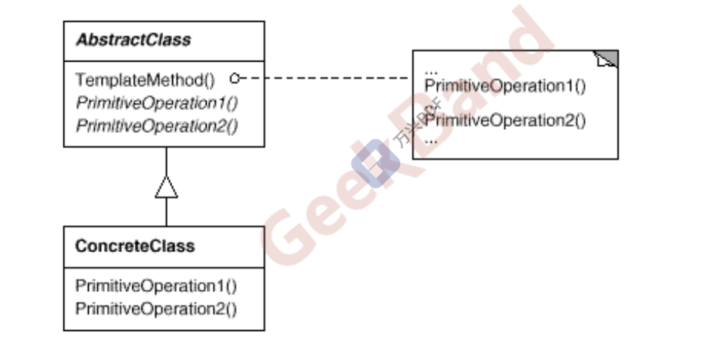
Template Method 模板方法模式
动机:在软件构建过程中,对于某一项任务,它常常有稳定的整体操作结构(可复用的),但各个子步骤却有很多改变的需求(变化的)。
模式定义(做法):定义一个模板结构,将具体内容延迟到子类去实现。在不改变模板结构的前提下在子类中重新定义模板中的内容。或者这样说:在父类中定义处理流程的框架(稳定可复用的),在子类中实现具体的处理方法(变化的)。
优点:
1.提高代码复用性:将相同部分的代码放在抽象的父类中(实现稳定复用)
2.提高了拓展性:将不同的代码放入不同的子类中,通过对子类的扩展增加新的行为(但同一个虚函数不同需求我们就要定义多个子类继承重写 增加了系统复杂度)
3.实现了反向控制:通过一个父类调用其子类的操作,通过对子类的扩展增加新的行为,实现了反向控制 & 符合“开闭原则”
//看下面的的例子,程序进行的 step() 永远是按顺序执行的(稳定的),则我们就可以把其放到父类中复用,
//而每个 step()的具体实现是可变化的 则子类用虚函数来重写
//如果我们不这样做,而将Application中具体的step()具体到 Application class里面实现 ,
//我们就要每次都创建两个类来逐一按执行顺序调用相应类相应函数来执行这个流程
//关键就是在于我们没有将可复用的(例子里面是run(),通过继承)代码封装复用。
//程序库开发人员 class Library{ public: //稳定 template method void Run(){ Step1(); if (Step2()) { //支持变化 ==> 虚函数的多态调用 Step3(); } for (int i = 0; i < 4; i++){ Step4(); //支持变化 ==> 虚函数的多态调用 } Step5(); } virtual ~Library(){ } protected: void Step1() { //稳定 //..... } void Step3() {//稳定 //..... } void Step5() { //稳定 //..... } virtual bool Step2() = 0;//变化 virtual void Step4() =0; //变化 }; //应用程序开发人员 class Application : public Library { protected: virtual bool Step2(){ //... 子类重写实现 } virtual void Step4() { //... 子类重写实现 } }; int main() { Library* pLib=new Application(); //父类指针可以动态调用子类函数 lib->Run(); delete pLib; } }
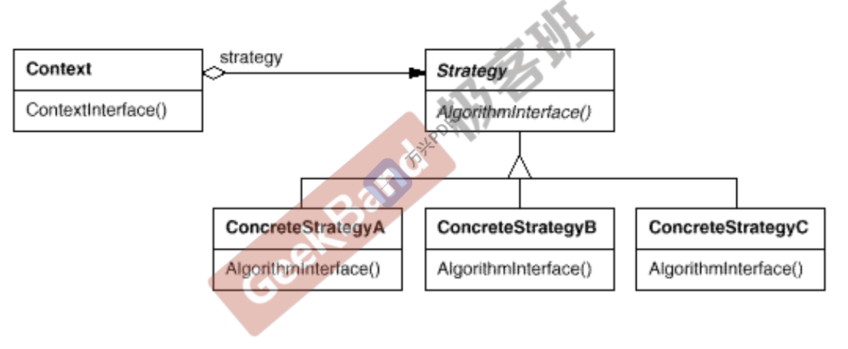
Strategy 策略模式
动机:在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,
将会使对象变得异常复杂; 而且有时候支持不使用的算法也是一个性能负担。
模式定义(做法):定义一系列算法,把它们一个个封装起来,并且使它们可互 相替换(变化)。
该模式使得算法可独立于使用它的客户程序(稳定)而变化(扩展,子类化)。
优点:
Strategy及其子类为组件提供了一系列可重用的算法,从而可以使得类型在运行时方便地根据需要在各个算法之间进行切换。
Strategy模式提供了用条件判断语句以外的另一种选择,消除条件判断语句,就是在解耦合。
如果Strategy对象没有实例变量,那么各个上下文可以共享同一个 Strategy对象,从而节省对象开销。
//我们看这第一种做法,每增加一种可能的算法,我们都需要更改源代码,而且整段代码都需要重新编译,
enum TaxBase { CN_Tax, US_Tax, DE_Tax, FR_Tax //更改 }; class SalesOrder{ TaxBase tax; public: double CalculateTax(){ //... if (tax == CN_Tax){ //CN*********** } else if (tax == US_Tax){ //US*********** } else if (tax == DE_Tax){ //DE*********** } else if (tax == FR_Tax){ //更改 //... } //.... } }; //修改后的代码,通过增加类和虚函数实现不同的算法,算法可以独立于外部变化(只用修改算法子类)
//客户端方便根据外部条件选择不同策略来解决不同问题
class TaxStrategy{ public: virtual double Calculate(const Context& context)=0; virtual ~TaxStrategy(){} }; class CNTax : public TaxStrategy{ public: virtual double Calculate(const Context& context){ //*********** } }; class USTax : public TaxStrategy{ public: virtual double Calculate(const Context& context){ //*********** } }; class DETax : public TaxStrategy{ public: virtual double Calculate(const Context& context){ //*********** } }; //扩展 //********************************* class FRTax : public TaxStrategy{ public: virtual double Calculate(const Context& context){ //......... } }; class SalesOrder{ private: TaxStrategy* strategy; public: SalesOrder(StrategyFactory* strategyFactory){ this->strategy = strategyFactory->NewStrategy(); } ~SalesOrder(){ delete this->strategy; } public double CalculateTax(){ //... Context context(); double val = strategy->Calculate(context); //多态调用 //... } };
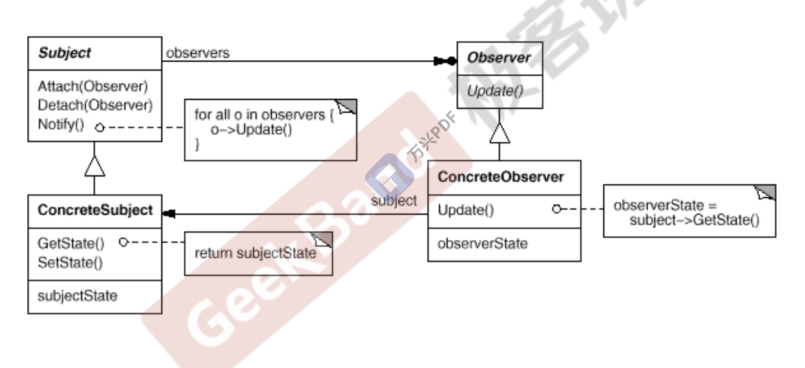
Observer 观察者模式
动机:
在软件构建过程中,我们需要为某些对象建立一种“通知依赖关系” ——一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知。
如果这样的依赖关系过于紧密, 将使软件不能很好地抵御变化。
使用面向对象技术,可以将这种依赖关系弱化,并形成一种稳定 的依赖关系。从而实现软件体系结构的松耦合。
模式定义(做法):定义对象间的一种一对多(变化)的依赖关系,以便当一个对象的状态发生改变时,所有依赖于它的对象都 得到通知并自动更新。
优点:
使用面向对象的抽象,Observer模式使得我们可以独立地改变目标与观察者,从而使二者之间的依赖关系达致松耦合。
二. “单一职责”模式
在软件组件的设计中,如果责任划分的不清晰,使用继承得到的 结果往往是随着需求的变化,子类急剧膨胀,同时充斥着重复代码, 这时候的关键是划清责任。
以下两个模式很相似,都利用了基类指针运行多态解决了子类膨胀问题(子类过多),但也有一点不同,注意模式动机
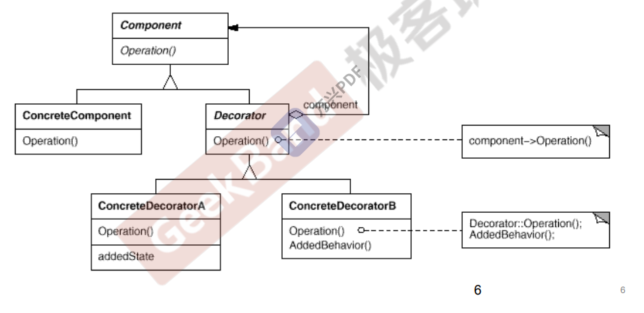
Decorator 装饰模式
动机:在某些情况下我们可能会“过度地使用继承来扩展对象的功能”, 由于继承为类型引入的静态特质,使得这种扩展方式缺乏灵活性; 并且随着子类的增多(扩展功能的增多),各种子类的组合(扩展 功能的组合)会导致更多子类的膨胀。
模式定义:动态(组合)地给一个对象增加一些额外的职责。就增加功 能而言,Decorator模式比生成子类(继承)更为灵活(消 除重复代码 & 减少子类个数)。
要点:
通过采用组合而非继承的手法, Decorator模式实现了在运行时 动态扩展对象功能的能力,而且可以根据需要扩展多个功能。避免了使用继承带来的“灵活性差”和“多子 类衍生问题”。
Decorator类在接口上表现为is-a Component的继承关系,即 Decorator类继承了Component类所具有的接口。但在实现上又 表现为has-a Component的组合关系,即 Decorator类又使用了 另外一个Component类。
Decorator模式的目的并非解决“多子类衍生的多继承”问题, Decorator模式应用的要点在于解决“主体类在多个方向上的扩展 功能”——是为“装饰”的含义。
一般一个derive class 继承一个 basic class 而且 derive class 中又有 basic * 字段 一般可以采用Decorator模式解决多子类膨胀问题(经验之谈)
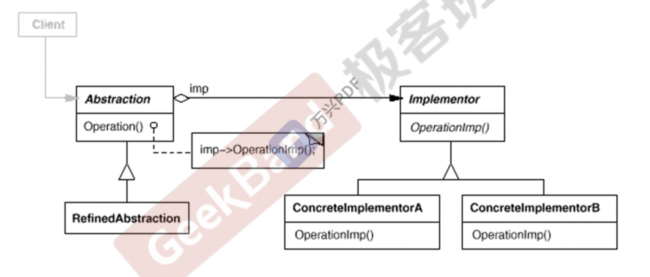
Bridge 桥模式
动机:由于某些类型的固有的实现逻辑,使得它们具有两个变化的维度, 乃至多个纬度的变化。
模式定义:将抽象部分(业务功能)与实现部分(平台实现)分离,使它们都可以独立地变化。
要点:
Bridge模式使用“对象间的组合关系”解耦了抽象和实现之间固 有的绑定关系,使得抽象和实现可以沿着各自的维度来变化。所谓 抽象和实现沿着各自纬度的变化,即“子类化”它们。
Bridge模式有时候类似于多继承方案,但是多继承方案往往违背 单一职责原则(即一个类只有一个变化的原因),复用性比较差。 Bridge模式是比多继承方案更好的解决方法。
Bridge模式的应用一般在“两个非常强的变化维度”,有时一个类也有多于两个的变化维度,这时可以使用Bridge的扩展模式。
三. “对象创建”模式
通过“对象创建” 模式绕开new,来避免对象创建(new)过程 中所导致的紧耦合(依赖具体类),从而支持对象创建的稳定。它是接口抽象之后的第一步工作。
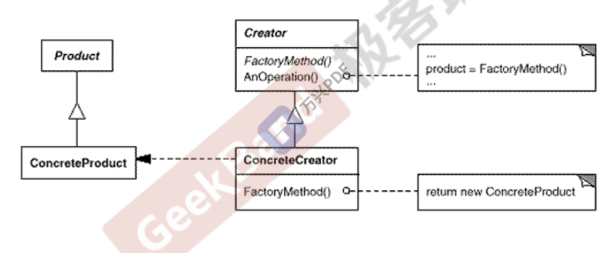
Factory Method工厂方法
动机:在软件系统中,经常面临着创建对象的工作;由于需求的变化, 需要创建的对象的具体类型经常变化。(要符合倒置依赖原则,开闭原则)
模式定义:定义一个用于创建对象的接口,让其子类决定实例化哪一个类。 Factory Method使得一个类的实例化延迟(目的:解耦, 手段:虚函数)到子类(工厂类抽象类,子类继承,实现依赖于抽象(稳定))。
要点:
Factory Method模式用于隔离类对象的使用者和具体类型之间的 耦合关系。面对一个经常 变化的具体类型,紧耦合关系(new)会导 致软件的脆弱。
Factory Method模式通过面向对象的手法,将所要创建的具体对 象工作延迟到子类,从而实现一种扩展(而非更改)的策略,较好 地解决了这种紧耦合关系。
Factory Method模式解决“单个对象”的需求变化。缺点在于要 求创建方法/参数相同。
//简单工厂模式例子,我们看到,在工厂类内部判断要生产什么类,
//每增加一个类(继承于SingleCore的类),都要修改工厂类源代码,不符合开闭原则!
enum CTYPE {COREA, COREB};
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() { cout<<"SingleCore B"<<endl; }
};
//唯一的工厂,可以生产两种型号的处理器核,在内部判断
class Factory
{
public:
SingleCore* CreateSingleCore(enum CTYPE ctype)
{
if(ctype == COREA) //工厂内部判断
return new SingleCoreA(); //生产核A
else if(ctype == COREB)
return new SingleCoreB(); //生产核B
else
return NULL;
}
};
//以下是利用了工厂方法模式代替了上面的简单工厂模式
//我们把工厂类也进行抽象,每种同系列的类型产品都继承于抽象的工厂类,实现每种类型自己的工厂
//我们发现这样就变成了“可扩展,依赖于抽象”,把new推迟到了工厂子类
//缺点很明显,每增加一种产品就要增加一个对象的工厂
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() { cout<<"SingleCore B"<<endl; }
};
class Factory
{
public:
virtual SingleCore* CreateSingleCore() = 0;
};
//生产A核的工厂
class FactoryA: public Factory
{
public:
SingleCoreA* CreateSingleCore() { return new SingleCoreA; }
};
//生产B核的工厂
class FactoryB: public Factory
{
public:
SingleCoreB* CreateSingleCore() { return new SingleCoreB; }
};
————————————————
版权声明:本文为CSDN博主「Lethe♪」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33854260/article/details/77398781
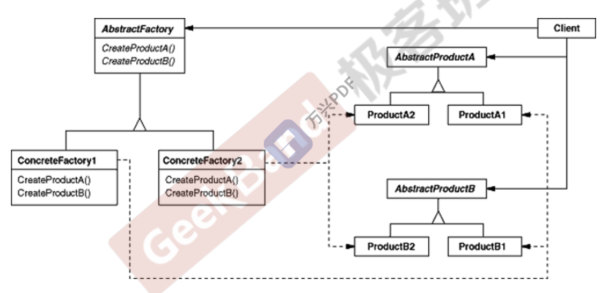
Abstract Factory 抽象工厂
动机:在软件系统中,经常面临着“一系列相互依赖的对象”的创建工作;同时,由于需求的变化,往往存在更多系列对象的创建工作。
模式定义:提供一个接口,让该接口负责创建一系列“相关或者相互依 赖的对象”,无需指定它们具体的类。
要点:
如果没有应对“多系列对象构建”的需求变化,则没有必要使用 Abstract Factory模式,这时候使用简单的工厂完全可以。
“系列对象”指的是在某一特定系列下的对象之间有相互依赖、 或作用的关系。不同系列的对象之间不能相互依赖。
Abstract Factory模式主要在于应对“新系列”的需求变动。其缺 点在于难以应对“新对象”的需求变动。
//抽象工厂的定义为提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。 1.抽象工厂关键在于产品之间的抽象关系,所以至少要两个产品;工厂方法在于生成产品,不关注产品间的关系,所以可以只生成一个产品。 2.抽象工厂中客户端把产品的抽象关系理清楚,在最终使用的时候,一般使用客户端(和其接口),产品之间的关系是被封装固定的;
而工厂方法是在最终使用的时候,使用产品本身(和其接口)。 3.抽象工厂的工厂是类;工厂方法的工厂是方法。 //单核 class SingleCore { public: virtual void Show() = 0; }; class SingleCoreA: public SingleCore { public: void Show() { cout<<"Single Core A"<<endl; } }; class SingleCoreB :public SingleCore { public: void Show() { cout<<"Single Core B"<<endl; } }; //多核 class MultiCore { public: virtual void Show() = 0; }; class MultiCoreA : public MultiCore { public: void Show() { cout<<"Multi Core A"<<endl; } }; class MultiCoreB : public MultiCore { public: void Show() { cout<<"Multi Core B"<<endl; } }; //抽象工厂 class CoreFactory { public: virtual SingleCore* CreateSingleCore() = 0; virtual MultiCore* CreateMultiCore() = 0; }; //工厂A,专门用来生产A型号的处理器 class FactoryA :public CoreFactory { public: SingleCore* CreateSingleCore() { return new SingleCoreA(); } MultiCore* CreateMultiCore() { return new MultiCoreA(); } }; //工厂B,专门用来生产B型号的处理器 class FactoryB : public CoreFactory { public: SingleCore* CreateSingleCore() { return new SingleCoreB(); } MultiCore* CreateMultiCore() { return new MultiCoreB(); } }; ———————————————— 版权声明:本文为CSDN博主「Lethe♪」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_33854260/article/details/77398781
"对象性能"模式
面向对面很好的解决了"抽象问题",但也有代价(如虚函数)。对于某些情况我们必须要对面向对象所带来的成本谨慎地处理
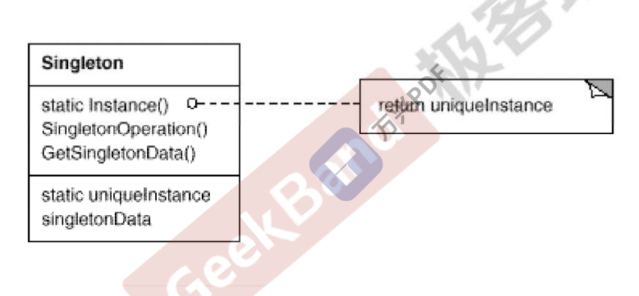
Singleton单例模式
动机:有些特殊的类只存在一个实例才能确保逻辑正常和相率良好。所以动机是绕过常规的构造器,提供一种机制保证一个类只有一个实例(只new一次)
模式定义:保证一个类只有一个实例,并提供一个该实例的全局访问点。
要点:
Singleton模式中的实例构造器可以设置为protected以允许子类派生。
Singleton模式一般不要支持copyctor和clone接口,因为可能导致多个对象实例
class Singleton{ private: Singleton(); Singleton(const Singleton& other); public: static Singleton* getInstance(); static Singleton* m_instance; }; Singleton* Singleton::m_instance=nullptr; //线程非安全版本 Singleton* Singleton::getInstance() { if (m_instance == nullptr) { m_instance = new Singleton(); } return m_instance; } //线程安全版本,但锁的代价过高 Singleton* Singleton::getInstance() { Lock lock; if (m_instance == nullptr) { m_instance = new Singleton(); } return m_instance; } //双检查锁,但由于内存读写reorder不安全 //编译器优化可能并不是 分配内存-执行构造器-再把内存地址给m_instance //而是 分配内存-内存地址赋给m_instance-执行构造器 //此时另外一个线程可能在执行完第二步,就调用对象,可对象根本没有构造完成! Singleton* Singleton::getInstance() { if(m_instance==nullptr){ Lock lock;
if (m_instance == nullptr) { m_instance = new Singleton(); } } return m_instance; } //C++ 11版本之后的跨平台实现 (volatile) std::atomic<Singleton*> Singleton::m_instance; std::mutex Singleton::m_mutex; Singleton* Singleton::getInstance() { Singleton* tmp = m_instance.load(std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_acquire);//获取内存fence if (tmp == nullptr) { std::lock_guard<std::mutex> lock(m_mutex); tmp = m_instance.load(std::memory_order_relaxed); if (tmp == nullptr) { tmp = new Singleton; std::atomic_thread_fence(std::memory_order_release);//释放内存fence m_instance.store(tmp, std::memory_order_relaxed); } } return tmp;
Flyweight 享元模式
动机:在软件系统中采用纯粹的对象方案的问题在于大量细粒度的对象(对象细分导致对象增多)会很快充斥再系统中,从而带来很高的运行时代价---如内存需求
模式定义:通过共享实例的方式来避免重复的对象被new出来,节约系统资源
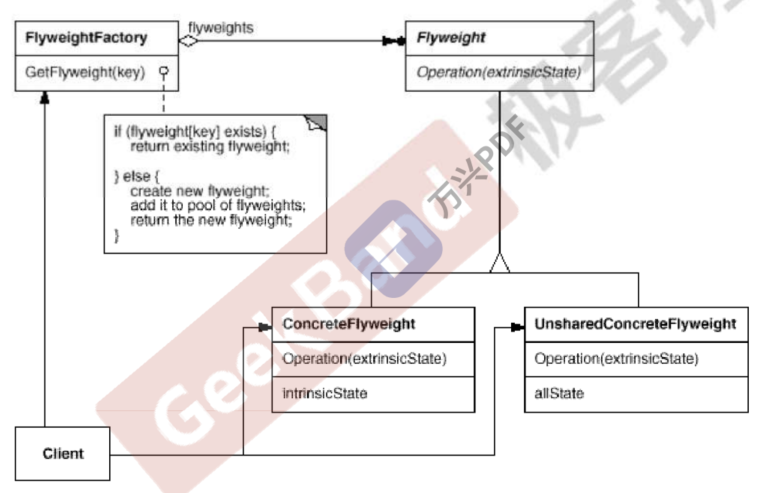
class Font { private: //unique object key string key; //object state //... public: Font(const string& key){ //... } }; ß class FontFactory{ private: map<string,Font* > fontPool; public: Font* GetFont(const string& key){ //找到就直接返回拿来用,找不到就new,类似于一个存储对象的池子 map<string,Font*>::iterator item=fontPool.find(key); if(item!=footPool.end()){ return fontPool[key]; } else{ Font* font = new Font(key); fontPool[key]= font; return font; } } void clear(){ //... } };
"接口隔离模式"
在组建构建过程中,某些接口之间的直接以来会带来问题,曹勇添加一层间接接口,隔离本来互相紧密关联的接口
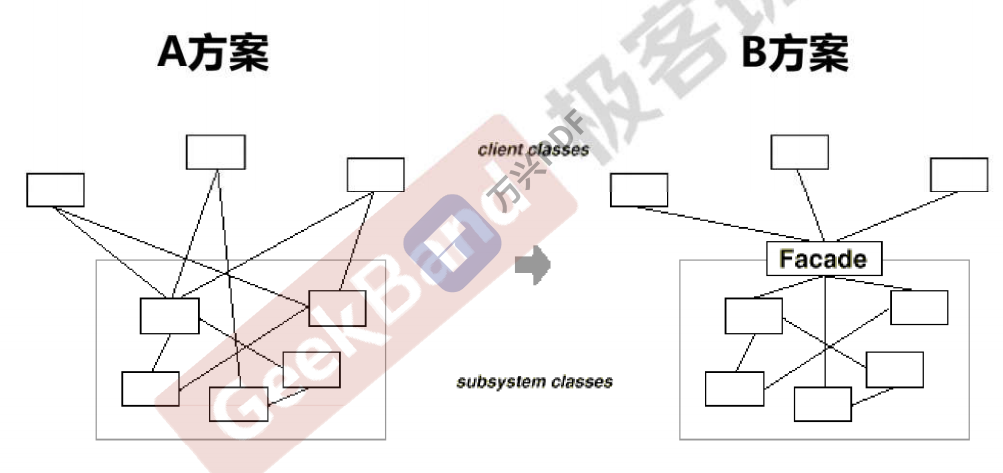
Facade 门面模式(比较简单,可类比硬件与软件中操作系统这一层)
模式定义:为子系统的一组接口提供一个一致的(稳定)的界面,Facade模式定义了一个高层接口,这个接口使得这一个子系统更加容易使用(复用)
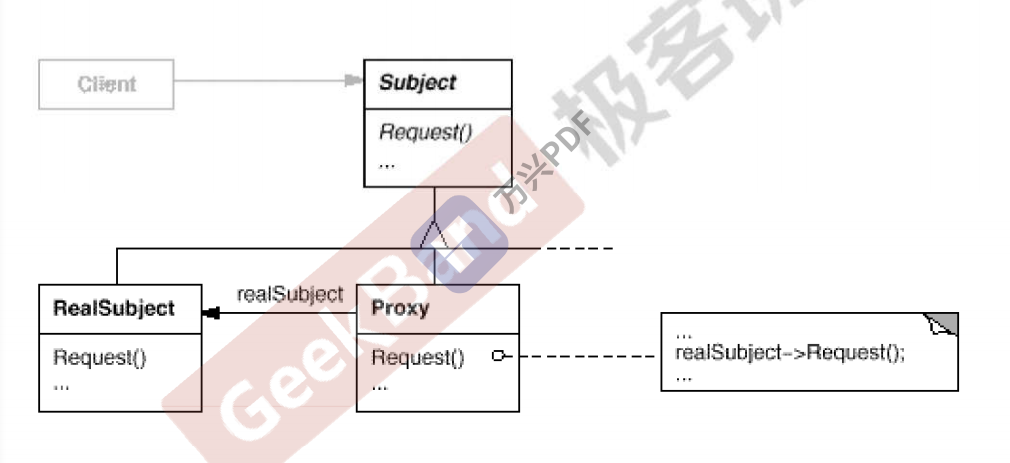
Proxy 代理模式
动机:在面向对象系统中,有些对象的直接访问会给使用者或者系统带来麻烦
模式定义:为其他对象提供一种代理以控制对这个对象的访问
Adapter 适配器模式
动机:在软件系统中,由于应用环境的变化,需要将“一些现存的对象”放在新的环境中应用,但是新环境要求的接口是现存对象所不能满足的
模式定义:将一个类的接口转换成客户希望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类可以一起工作
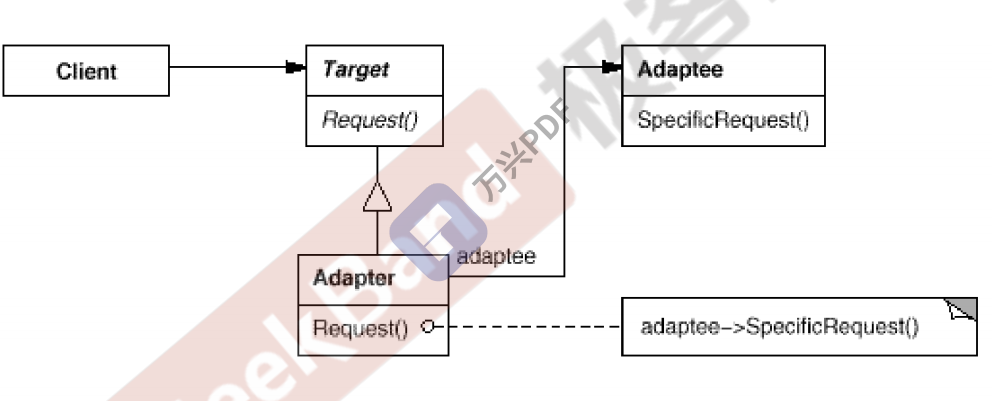
//目标接口(新接口) class ITarget{ public: virtual void process()=0; }; //遗留接口(老接口) class IAdaptee{ public: virtual void foo(int data)=0; virtual int bar()=0; }; //遗留类型 class OldClass: public IAdaptee{ //.... }; //对象适配器,继承其实有意味着同意基类的接口规范的意思 class Adapter: public ITarget{ //继承 protected: IAdaptee* pAdaptee;//组合 public: Adapter(IAdaptee* pAdaptee){ this->pAdaptee=pAdaptee; } virtual void process(){ int data=pAdaptee->bar(); pAdaptee->foo(data); } }; //类适配器 class Adapter: public ITarget, protected OldClass{ //多继承 } int main(){ IAdaptee* pAdaptee=new OldClass(); //旧类对象 ITarget* pTarget=new Adapter(pAdaptee);//旧类对象通过适配器转成一个“新类” pTarget->process(); } //其实stack ,queue 内部实现都用了 dequeue 对象,在实现合适自己的接口 class stack{ deqeue container; }; class queue{ deqeue container; };
Mediator 中介者模式
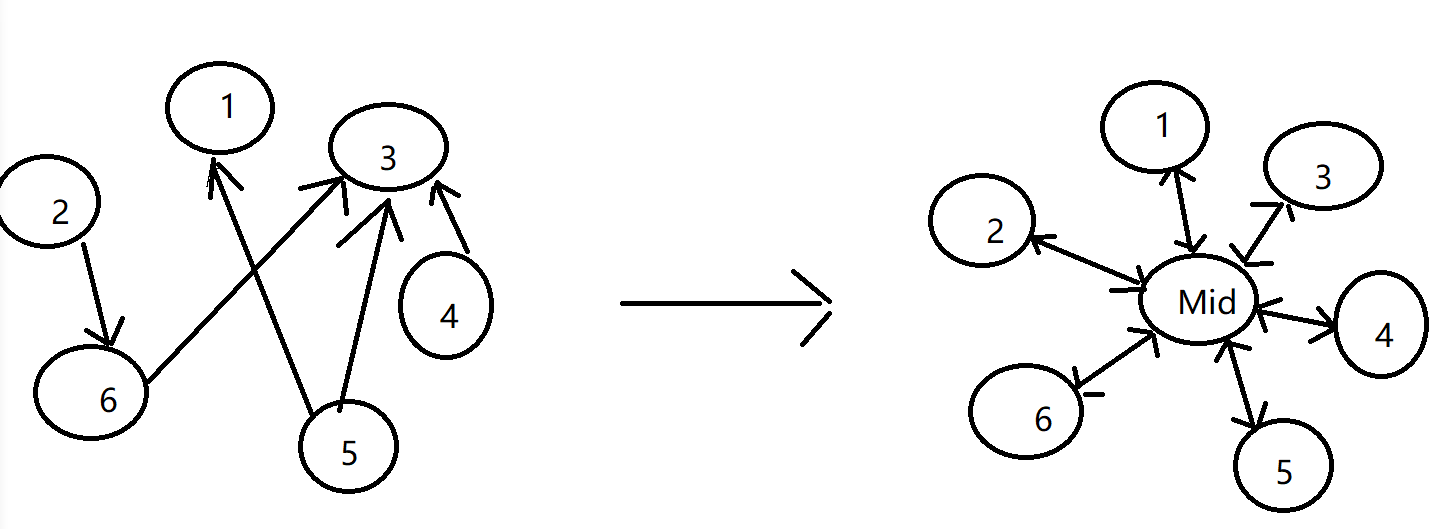
动机:在软件构建过程中,经常会出现多个对象相互关联交互的情况,对象间会维持一种复杂的引用关系,若遇到需求的更改,这种直接引用关系可能也随着变化。
模式定义:用一个中介者对象来封装(封装变化)一系列的对象交互。中介者使得对象不需要显式的相互引用(编译时依赖->运行时依赖),从而使耦合松散(管理变化),而且可以独立的改变特么之间的交互
"状态变化模式"
解决问题:在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效管理同时又维持高层模块的稳定?
Memento 备忘录模式
动机:要求程序能够回溯到对象之前处于某个点时的状态,如果使用一些共有接口让其他对象得到对象的状态,这样会暴露对象细节实现。
模式定义:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样一行就可以恢复到原先保存的状态。
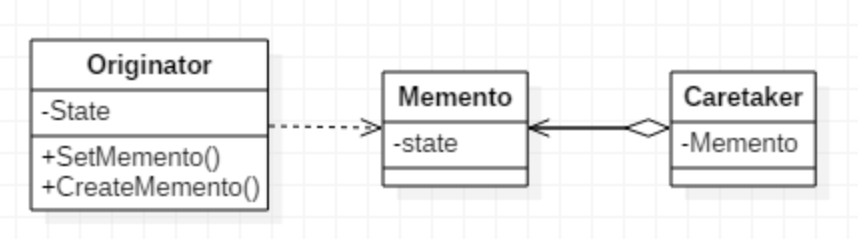
//存储对象状态的类,以便以后返回保存的状态 class Memento { string state; //.. public: Memento(const string & s) : state(s) {} string getState() const { return state; } void setState(const string & s) { state = s; } }; //不要破坏这个类的封装性 class Originator { string state; //.... public: Originator() {} Memento createMomento() { Memento m(state); return m; } void setMomento(const Memento & m) { state = m.getState(); } }; int main() { Originator orginator; //捕获对象状态,存储到备忘录 Memento mem = orginator.createMomento(); //... 改变orginator状态 //从备忘录中恢复 orginator.setMomento(memento); }
iterater 模式 (已经过时了) //现在可以参考 STL Iterater 的实现模式
其他设计模式---未完待更

 浙公网安备 33010602011771号
浙公网安备 33010602011771号