

机器学习西瓜书笔记---1、绪论
机器学习西瓜书笔记---1、绪论
一、总结
一句话总结:
【书上要比别人的总结好理解的多】:别人说来真觉浅,还需自己来深读
机器学习辅助2012年美国大选奥巴马以及自动驾驶,其实都非常无比的说明【机器学习无比有前途,可以应用在生活的各个方面】
1、机器学习 通俗定义?
机器学习正是这样一门学科,它致力于研究如何通过计算的手段,【利用经验来改善系统自身的性能】。
在计算机系统中,【“经验”通常以“数据”形式存在】,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)。
如果说【计算机科学是研究关于“算法”的学问】,那么类似的,可以说【机器学习是研究关于“学习算法”的学问】.
2、“特征向量”?
例如我们把【“色泽”“根蒂”“敲声”作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间】,每个西瓜都可在这个空间中找到自己的坐标位置。由于【空间中的每个点对应一个坐标向量】,因此我们也把一个示例【称为一个“特征向量”(feature vector)】。
3、预测西瓜的分类和回归实例?
若我们欲预测的是【离散值,例如“好瓜”“坏瓜”】,此类学习任务称为【“分类”(classification)】;
若欲【预测的是连续值,例如西瓜成熟度0.95、0.37】,此类学习任务称为【“回归”(regression)】.
4、对西瓜做“聚类”(clustering)?
【我们还可以对西瓜做“聚类”(clustering),即将训练集中的西瓜分成若干组,每组称为一个“簇”(cluster)】;这些自动形成的簇可能对应一些潜在的概念划分,例如“浅色瓜”“深色瓜”,甚至“本地瓜”“外地瓜”.
【这样的学习过程有助于我们了解数据内在的规律,能为更深入地分析数据建立基础】.需说明的是,在聚类学习中,“浅色瓜”“本地瓜”这样的概念我们事先是不知道的,【而且学习过程中使用的训练样本通常不拥有标记信息】.
根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:“监督学习”(supervised learning)和“无监督学习”(unsupervised learning),【分类和回归是前者的代表,而聚类则是后者的代表】.
5、“泛化”(【generalization】)能力?
generalization
6、“独立同分布”(independent and identically distributed,简称i.i.d.)?
通常假设样本空间中【全体样本服从一个未知“分布”(distribution)D,我们获得的每个样本都是独立地从这个分布上采样获得的】,即“独立同分布”(independent and identically distributed,简称i.i.d.).
一般而言,【训练样本越多,我们得到的关于D的信息越多】,这样就越有可能通过学习获得具有强泛化能力的模型.
7、“概念学习”或“概念形成”?
归纳学习有狭义与广义之分,广义的归纳学习大体相当于从样例中学习,而【狭义的归纳学习则要求从训练数据中学得概念(concept)】,因此亦称为“概念学习”或“概念形成”.
【概念学习技术目前研究、应用都比较少,因为要学得泛化性能好且语义明确的概念实在太困难了】,现实常用的技术大多是产生“黑箱”模型.然而,对概念学习有所了解,有助于理解机器学习的一些基础思想.
【概念学习中最基本的是布尔概念学习,即对“是”“不是”这样的可表示为0/1布尔值的目标概念的学习】.举一个简单的例子,假定我们获得了这样一个训练数据集:

8、机器学习条件的逻辑表达式写法?
【“好瓜 <-->(色泽=?)∩(根蒂=?)∩(敲声=?)”】,这里“?”表示尚未确定的取值
更一般的情况是考虑【形如(A ∩ B)∪(C ∩ D)的析合范式】
9、为什么tensorflow中是fit函数?
我们可以把学习过程看作一个【在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”(fit)的假设】,即能够将训练集中的瓜判断正确的假设.假设的表示一旦确定,假设空间及其规模大小就确定了.
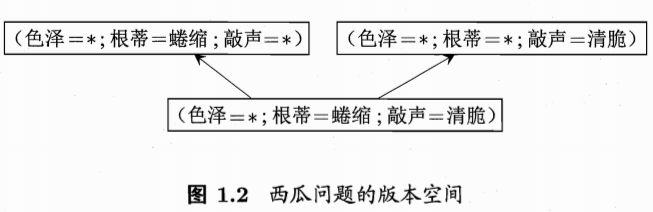
10、“版本空间”(version space)?
需注意的是,现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即【存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”(version space)】.例如,
11、1.4归纳偏好?
然而,对于一个具体的学习算法而言,它必须要产生一个模型.这时,【学习算法本身的“偏好”就会起到关键的作用】.
例如,【若我们的算法喜欢“尽可能特殊”的模型,则它会选择“好瓜 <->(色泽=*)∩(根蒂=蜷缩)∩(敲声=浊响)”】;但若我们的算法喜欢“尽可能一般”的模型,并且由于某种原因它更“相信”根蒂,则它会选择“好瓜 <->(色泽=*)∩(根蒂=蜷缩)∩(敲声=*)”.
【机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”(inductive bias)】,或简称为“偏好”.
12、任何一个有效的机器学习算法必有其归纳偏好?
任何一个有效的机器学习算法必有其归纳偏好,【否则它将被假设空间中看似在训练集上“等效”的假设所迷惑,而无法产生确定的学习结果】.
可以想象,如果没有偏好,我们的西瓜学习算法产生的模型每次在进行预测时随机抽选训练集上的等效假设,那么对这个新瓜“(色泽=青绿;根蒂=蜷缩;敲声=沉闷)”,【学得模型时而告诉我们它是好的、时而告诉我们它是不好的,这样的学习结果显然没有意义】.
13、那么,有没有一般性的原则来引导算法确立“正确的”偏好呢?
归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中【对假设进行选择的启发式或“价值观”】.
“奥卡姆剃刀”(Occam's razor)是一种常用的、自然科学研究中最基本的原则,即“【若有多个假设与观察一致,则选最简单的那个】”.
如果采用这个原则,并且【假设我们认为“更平滑”意味着“更简单”】(例如曲线A更易于描述,其方程式是y=-x^2+6x+1,而曲线B则要复杂得多),则在图1.3中我们会自然地偏好“平滑”的曲线A.
14、没有免费的午餐?
【对于一个学习算法c,若它在某些问题上比学习算法b好,则必然存在另一些问题,在那里b比c好】。有趣的是,这个结论对任何算法均成立
15、深度学习为什么此时才热起来呢?
有两个基本原因:【数据大了、计算能力强了】.深度学习模型拥有大量参数,若数据样本少,则很容易“过拟合”;如此复杂的模型、如此大的数据样本,若缺乏强力计算设备,根本无法求解.
16、数据挖掘与机器学习的联系?
【数据挖掘】是【从海量数据中发掘知识,这就必然涉及对“海量数据”的管理和分析】.
大体来说,【数据库领域的研究为数据挖掘提供数据管理技术】,而【机器学习和统计学的研究为数据挖掘提供数据分析技术】.
由于统计学界的研究成果通常需要经由机器学习研究来形成有效的学习算法,之后再进入数据挖掘领域,因此从这个意义上说,【统计学主要是通过机器学习对数据挖掘发挥影响,而机器学习领域和数据库领域则是数据挖掘的两大支撑】.
17、机器学习技术甚至已影响到人类社会政治生活.【2012年美国大选期间,奥巴马麾下有一支机器学习团队,他们对各类选情数据进行分析,为奥巴马提示下一步竞选行动】?
例如他们使用机器学习技术分析社交网络数据,判断出在总统候选人第一次辩论之后哪些选民会倒戈,并根据分析的结果开发出个性化宣传策略,能为每位选民找出一个最有说服力的挽留理由;【他们基于机器学习模型的分析结果提示奥巴马应去何处开展拉票活动】,有些建议甚至让专业竞选顾问大吃一惊,而结果表明去这些地方大有收获.
【总统选举需要大量金钱,机器学习技术在这方面发挥了奇效】.例如,机器学习模型分析出,某电影明星对某地区某年龄段的特定人群很有吸引力,而这个群体很愿意出高价与该明星及奥巴马共进晚餐……果然,这样一次筹资晚宴成功募集到1500万美元;最终,借助机器学习模型,奥巴马筹到了创纪录的10亿美元竞选经费.
【机器学习技术不仅有助于竞选经费“开源”,还可帮助“节流”】,例如机器学习模型通过对不同群体选民进行分析,建议购买了一些冷门节目的广告时段,而没有采用在昂贵的黄金时段购买广告的传统做法,使得广告资金效率相比2008年竞选提高了14%;…….胜选后,《时代》周刊专门报道了这个被奥巴马称为【“竞选核武器”】、由半监督学习研究专家R.Ghani领导的团队.
启示:【机器学习说不定可以很好的解决自己的所有问题】,不仅在开源方面,而且在节流方面,当然首要是学好
18、自动驾驶是可行的?
再举一例.车祸是人类最凶险的杀手之一,全世界每年有上百万人丧生车轮,仅我国每年就有约十万人死于车祸.由计算机来实现自动汽车驾驶是一个理想的方案,【因为机器上路时可以确保不是新手驾驶、不会疲劳驾驶,更不会酒后驾驶,而且还有重要的军事用途】.美国在二十世纪八十年代就开始进行这方面研究.这里最大的困难是无法在汽车厂里事先把汽车上路后所会遇到的所有情况都考虑到、设计出处理规则并加以编程实现,而只能根据上路时遇到的情况即时处理.若把车载传感器接收到的信息作为输入,把方向、刹车、油门的控制行为作为输出,则这里的关键问题恰可抽象为一个机器学习任务.
【2004年3月,在美国DARPA组织的自动驾驶车比赛中,斯坦福大学机器学习专家S.Thrun的小组研制的参赛车用6小时53分钟成功走完了132英里赛程获得冠军】.比赛路段是在内华达州西南部的山区和沙漠中,路况相当复杂,在这样的路段上行车即使对经验丰富的人类司机来说也是一个挑战.S.Thrun后来到谷歌领导自动驾驶车项目团队.值得一提的是,自动驾驶车在近几年取得了飞跃式发展,除谷歌外,通用、奥迪、大众、宝马等传统汽车公司均投入巨资进行研发,目前已开始有产品进入市场.
【2011年6月,美国内华达州议会通过法案,成为美国第一个认可自动驾驶车的州】,此后,夏威夷州和佛罗里达州也先后通过类似法案.自动驾驶汽车可望在不久的将来出现在普通人的生活中,而机器学习技术则起到了“司机”作用.
启示:【机器学习是非常非常非常有前途的,学好了,什么位置都可以用,因为它就是从数据中找规律】
二、内容在总结中
博客对应课程的视频位置:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号