

机器学习中常用的三种方法
机器学习中常用的三种方法
一、总结
一句话总结:
a、人工神经网络(Artificial Neural Network, ANN)
b、决策树算法:树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。
c、支持向量机(support vector machine, SVM):使特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解
1、人工神经网络方法的一般应用步骤是什么?
1、确定网络结构;
2、采用有监督的方法训练网络参数;
3、进行分类或者预测。
2、神经网络的学习算法中的反向传播(Back Propagation, BP)算法 基本思想?
a、信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。
b、误差反向传播:将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
二、机器学习总结
转自或参考:看见到洞见之引子(一)机器学习算法
http://blog.sina.com.cn/s/blog_4006fd240102x05t.html
什么是机器学习?
机器学习(Machine Learning, ML)是人工智能的一个分支,是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。同时,机器学习是一个涉及到多个领域的交叉学科,其涵盖范围包括了概率论、统计学、逼近论、凸分析、计算复杂性理论等学科。目前,机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。
机器学习的常用算法
人工神经网络(Artificial Neural Network, ANN)
神经网络是机器学习的一个分支,与之对应的是生物神经网络。生物神经网络一般指由神经元组成的网络,用于产生意识,帮助生物进行思考与行动。那么什么是神经元呢?
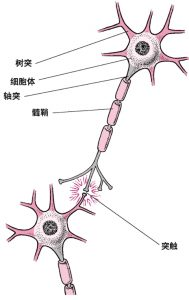
神经元
如图 1所示为一个生物神经元的示意图。神经元通过树突接受来自外界或者其它神经元的刺激,并将刺激传至细胞体。而轴突将刺激从细胞体传至远处,传递给另一个神经元的树突或者肌体的效应器。而神经元之间的连接不是固定不变的。在生物体的学习和成长过程中,一些新的连接会被逐渐建立起来,而一些连接可能会消失。神经元之间的连接关系变迁就形成了生物体的学习过程。
那么什么是人工神经网络呢?人工神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。与生物神经网络一样,人工神经网络同样由神经元组成,即感知器[1],如图 2所示。
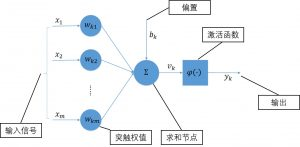
感知器
感知器可以看做是一个最简单的神经网络,其信号传递方程为:
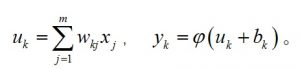
由传递方程可知,感知器本身为一个线性分类器。因此,其无法解决线性不可分的问题。如图 3所示,对于线性可分的AND(与)和OR(或)问题,感知器都可以对其进行求解。而对于XOR(异或)问题,由于其是一个线性不可分问题,所以感知器,也就是最简单的神经网络无法对其进行求解。
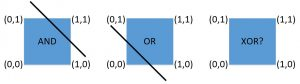
感知器线性可分与不可分
由于XOR问题不能用单个的感知器进行求解,那么可以考虑采用两层的感知器,其中,第一层感知器的输出作为第二层感知器的输入,如图 4所示。其中,权值为
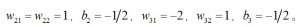
其对XOR问题求解的示意图如图 5所示。
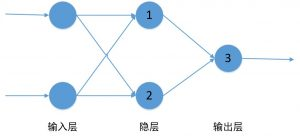
解决XOR问题的两层神经网络
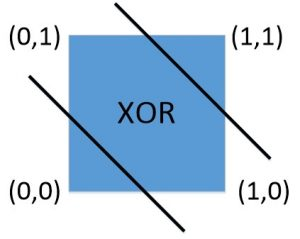
XOR问题求解
因此,对于线性不可分的问题,可以采用多层的神经元互相连接的方式来进行求解。如果需要求解的问题更加复杂,就需要更多的神经元组合在一起,构成更加复杂的网络,如图 6所示。在人工神经网络中,网络相邻层之间的节点都通过有向边进行连接,箭头的方向代表了信号的传递方向,连接的权值代表了不同层神经元之间作用的强度。网络同一层的节点之间没有连接。
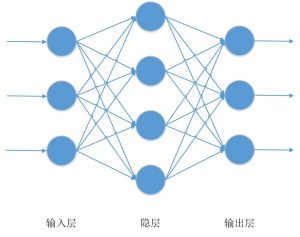
多层感知器
只有连接的神经网络还不能进行工作,因为其连接的权值还没有确定。因此首先需要通过有监督的方式训练神经网络,即学习过程。其经典的学习算法为反向传播(Back Propagation, BP)算法。由于BP算法的推导比较复杂,这里不做详细阐述,只介绍一下其基本思想:
- 信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。
- 误差反向传播:将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
- 因此,人工神经网络方法的一般应用步骤为:1. 确定网络结构;2. 采用有监督的方法训练网络参数;3. 进行分类或者预测。
决策树算法
机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。决策树的示意图如图 7所示。
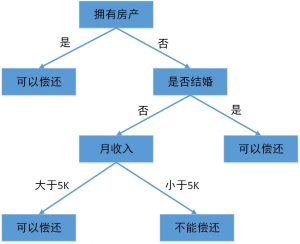
决策树示意图
图 7中的决策树用来预测贷款用户是否具有偿还贷款的能力。贷款用户主要具备三个属性:是否拥有房产,是否结婚,平均月收入。每一个内部节点都表示一个属性条件判断,叶子节点表示贷款用户是否具有偿还贷款的能力。例如:用户甲没有房产,没有结婚,月收入 6K。通过决策树的根节点判断,用户甲符合右边分支(拥有房产为“否”);再判断是否结婚,用户甲符合左边分支(是否结婚为否);然后判断月收入是否大于5K,用户甲符合左边分支(月收入大于5K),该用户落在“可以偿还”的叶子节点上。所以预测用户甲具备偿还贷款的能力。
可以看到,决策树的决策过程非常直观,容易被人理解。因此,决策树在很多领域得到了广泛的应用。
决策树的构造过程不依赖于领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量,以确定各个特征属性之间的拓扑结构。属性选择度量算法有很多,常用的有ID3算法[2]和C4.5算法[3]。这里不介绍算法的具体流程,有兴趣的读者可以参考相关的文献。
从信息论知识中可知,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
ID3算法存在一个问题,就是偏向于多值属性。例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图解决这个问题。
在分类模型建立的过程中,很容易出现过拟合的现象。过拟合是指在模型学习训练中,训练样本达到非常高的逼近精度,但对检验样本的逼近误差随着训练次数的增加呈现出先下降后上升的现象。过拟合时训练误差很小,但是检验误差很大,不利于实际应用。
决策树的过拟合现象可以通过剪枝进行一定的修复。剪枝分为预先剪枝和后剪枝两种。预先剪枝指在决策树生长过程中,使用一定条件加以限制,使得产生完全拟合的决策树之前就停止生长。后剪枝是在决策树生长完成之后,按照自底向上的方式修剪决策树。后剪枝有两种方式,一种用新的叶子节点替换子树,该节点的预测类由子树数据集中的多数类来决定。另一种用子树中最常使用的分支代替子树。预先剪枝可能过早的终止决策树的生长,后剪枝一般能够产生更好的效果。但后剪枝在子树被剪掉后,决策树生长的一部分计算就被浪费了。
支持向量机
支持向量机(support vector machine, SVM)[4]是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。SVM在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。SVM是一种监督学习方法,其原理示意图如图 8所示。
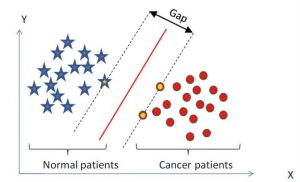
SVM原理
SVM的主要思想是针对两类分类问题,寻找一个超平面作为两类训练样本点的分割,以保证最小的分类错误率。在线性可分的情况下,存在一个或多个超平面使得训练样本完全分开,SVM的目标是找到其中的最优超平面,即使得每一类数据中与超平面距离最近的向量距离超平面的距离达到最大。如图 8所示,中间的实线便是寻找到的最优超平面,其到两条虚线边界的距离相等。而虚线间隔边界上的点则是支持向量。
前面介绍了SVM方法在解决线性可分问题中的应用。线性不可分问题将如何处理呢?这就需要引入核函数的概念。通过核函数将待分类的数据映射到高维空间,来解决在原始空间中线性不可分的问题,如图 9所示。
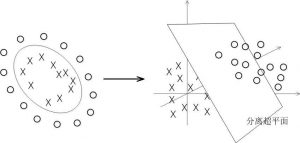
SVM核函数
小结
本期介绍了监督学习中常用的三种方法的原理。
- 参考文献
- F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain,” Psychol. Rev., vol. 65, no. 6, pp. 386–408, 1958.
- R. Quinlan, “Induction of decision trees,” Mach. Learn., vol. 1, no. 1, pp. 81–106, 1986.
- R. Quinlan, C4.5: Programs for Machine Learning. San Mateo, CA, USA: Morgan Kaufmann, 1993.
- V. Vapnik, The Nature of Statistical Learning Theory. New York, NY, USA: Spriner, 2010.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号