

秒懂神经网络---震惊!!!神经网络原来可以这么简单!
秒懂神经网络---震惊!!!神经网络原来可以这么简单!
一、总结
一句话总结:
神经网络代码编写很容易:class+方法
神经网络的思路也很容易:由输入到输出,只不过这个过程经过了一些优化
1、神经网络解决实际问题步骤?
1、【搭建】神经网络模型:比如搭建神经网络基础模块 神经元
2、【训练(优化)】神经网络模型:用大量数据训练,减少神经网络损失,提高精确度
2、神经网络中的 基本模块 神经元是什么?
类似生物神经元:接受外来刺激(信号),再由细胞体传出刺激(信号)
权重输入+激活函数=输出:1、输入乘以权重; 2、加偏置; 3、经过激活函数处理;
3、神经网络中神经元中的 激活函数 的作用是什么?
格式化输出:输出介于0和1:将无限制的输入转换为可预测形式的输出
例如sigmoid:f(x)=e^x/(1+e^x):把 (−∞,+∞) 范围内的数压缩到 (0, 1)以内
4、神经网络最简单的神经元中,总共经过了哪三步计算?
1、输入乘以权重
2、加偏置
3、经过激活函数处理
先将两个输入乘以权重(weight): x1→x1 × w1 x2→x2 × w2 把两个结果想加,再加上一个偏置(bias): (x1 × w1)+(x2 × w2)+ b 最后将它们经过激活函数(activation function)处理得到输出: y = f(x1 × w1 + x2 × w2 + b)
5、神经网络最简单的神经元中,对于每个输入信号,它的格式是怎样的?
由输入属性构成:每个输入信号由多个输入的属性构成,比如输入为图片时:图片像素集,图片大小信息,图片时间信息 等
属性有自己的权重和偏移:信号输入中的每个属性,有自己的权重和偏移
实例:比如辨别图片中动物名字:图片像素集,图片大小信息,图片时间信息 等图片属性可以构成一个图片输入
6、Python数学函数库NumPy构建简单神经网络代码注意?
引入Numpy库:import numpy as np
构建神经元类:class Neuron:,里面有__init__()方法和正反馈feedforward()方法
输入数据:weights = np.array([0, 1]) # w1 = 0, w2 = 1 ; x = np.array([2, 3]) # x1 = 2, x2 = 3
feedforward 英 ['fiːdfɔːwəd] 美 n. 前馈(控制);正反馈 import numpy as np def sigmoid(x): # Our activation function: f(x) = 1 / (1 + e^(-x)) return 1 / (1 + np.exp(-x)) class Neuron: def __init__(self, weights, bias): self.weights = weights self.bias = bias def feedforward(self, inputs): # Weight inputs, add bias, then use the activation function total = np.dot(self.weights, inputs) + self.bias return sigmoid(total) weights = np.array([0, 1]) # w1 = 0, w2 = 1 bias = 4 # b = 4 n = Neuron(weights, bias) x = np.array([2, 3]) # x1 = 2, x2 = 3 print(n.feedforward(x)) # 0.9990889488055994
7、一个神经网络由哪大的三层构成?
输入层:Input Layer:
隐藏层:Hidden Layer:
输出层:Output Layer:
8、神经网络中的前馈(正反馈)是什么?
向前传递的过程:把神经元的输入向前传递获得输出的过程
9、神经网络的隐藏层可能有多层,那么 神经元的正反馈函数应该怎么写?
递归:其实神经网络的代码相对还是比较简单的
class OurNeuralNetwork: def feedforward(self, x): out_h1 = self.h1.feedforward(x) out_h2 = self.h2.feedforward(x) # The inputs for o1 are the outputs from h1 and h2 out_o1 = self.o1.feedforward(np.array([out_h1, out_h2])) return out_o1
10、我们怎么才算把我们的神经网络模型设计好了?
测试结果小于 设定的误差值:我们设定了一个设定的误差值,如果测试结果的数据小于设定的误差值,我们可以看做神经网络模型搭建好了
11、训练神经网络的过程的 实质 是什么?
优化模型的过程:其实也就是让损失函数的结果最小
12、如果我们用神经网络根据某人的身高和体重来推测其性别,那么输入是什么?
一个人的信息即为一条输入信号
每个输入信号分为多个属性:比如a的身高,a的体重就是a这个人对应的输入信号的两个属性(或者叫分支)
13、我们如何衡量一个神经网络模型的好坏?
用Loss Function(损失函数):最简单的损失函数比如 均方误差(MSE)
import numpy as np def mse_loss(y_true, y_pred): # y_true and y_pred are numpy arrays of the same length. return ((y_true - y_pred) ** 2).mean() y_true = np.array([1, 0, 0, 1]) y_pred = np.array([0, 0, 0, 0]) print(mse_loss(y_true, y_pred)) # 0.5
14、我们比如用 均方误差 来衡量一个神经网络模型的好坏,那么 均方误差 是什么?
所有数据方差的平均值:我们不妨就把它定义为损失函数。预测结果越好,损失就越低,训练神经网络就是将损失最小化。
15、神经网络中那种错综复杂的上传到下层的线如何实现?
属性的权重和:因为每一个下层节点得到的是一整套的输入,而不是某个输入的属性
16、如果调整一下w1,损失函数是会变大还是变小?
偏导数∂L/∂w1:偏导数∂L/∂w1是正是负能回答这个问题:当∂L/∂w1是正数时,w1会变小;当∂L/∂w1是负数 时,w1会变大。
17、如何求一个函数的导数,比如 偏导数∂L/∂w1?
自变量降次:在函数中,把∂w1看成自变量,然后对∂w1进行降次处理,相当于一次函数求斜率
18、神经网络中,如何求 输出结果对某一个权重的偏倒数,比如Ypred(最终结果)对w1(输入信号的属性第一个的权重)?
链式展开:Ypred对w1的偏导=Ypred对h1的偏导 * h1对w1的偏导
19、神经网络中的优化神经网络中的 随机梯度下降 是干嘛的?
优化神经网络:无非就是优化【权重 和 偏移】
优化权重:随机梯度下降是用来优化权重的
w1=w1-η·∂L/∂w1:看这个函数就特别清晰随机梯度下降是干嘛的以及它的特性有哪些
20、随机梯度下降(w1=w1-η·∂L/∂w1)中的η是干嘛的?
学习率:训练网络快慢:η是一个常数,称为学习率(learning rate),它决定了我们训练网络速率的快慢。
21、随机梯度下降(w1=w1-η·∂L/∂w1)的特性是什么?
将w1减去η·∂L/∂w1,就等到了新的权重w1。
当∂L/∂w1是正数时,w1会变小;当∂L/∂w1是负数 时,w1会变大。
22、神经网络的 伪代码 如何书写?
类+方法:就是一个神经网络的类,里面有【初始化,正反馈,负反馈等】几个方法
23、神经网络的学习进阶?
1、强大的库:用更大更好的机器学习库搭建神经网络,如Tensorflow、Keras、PyTorch
2、可视化:在浏览器中的直观理解神经网络:https://playground.tensorflow.org/
3、激活函数:学习sigmoid以外的其他激活函数:https://keras.io/activations/
4、优化器:学习SGD以外的其他优化器:https://keras.io/optimizers/
1、用更大更好的机器学习库搭建神经网络,如Tensorflow、Keras、PyTorch 2、在浏览器中的直观理解神经网络:https://playground.tensorflow.org/ 3、学习sigmoid以外的其他激活函数:https://keras.io/activations/ 4、学习SGD以外的其他优化器:https://keras.io/optimizers/ 5、学习卷积神经网络(CNN) 6、学习递归神经网络(RNN)
二、非常简单清晰的神经网络教程(转)
转自:AI之城
https://mp.weixin.qq.com/s/GQyXEdURHixd8jrf9A197A
“我在网上看到过很多神经网络的实现方法,但这一篇是最简单、最清晰的。”
一位来自普林斯顿的华人小哥Victor Zhou,写了篇神经网络入门教程,在线代码网站Repl.it联合创始人Amjad Masad看完以后,给予如是评价。

这篇教程发布仅天时间,就在Hacker News论坛上收获了574赞。程序员们纷纷夸赞这篇文章的代码写得很好,变量名很规范,让人一目了然。
下面就让我们一起从零开始学习神经网络吧。
实现方法
搭建基本模块——神经元
在说神经网络之前,我们讨论一下神经元(Neurons),它是神经网络的基本单元。神经元先获得输入,然后执行某些数学运算后,再产生一个输出。比如一个2输入神经元的例子:
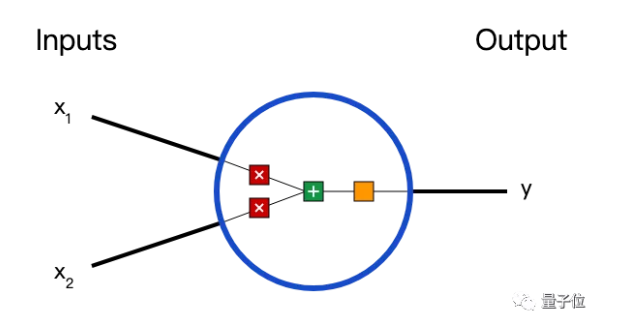
在这个神经元中,输入总共经历了3步数学运算,
先将两个输入乘以权重(weight):
x1→x1 × w1
x2→x2 × w2
把两个结果想加,再加上一个偏置(bias):
(x1 × w1)+(x2 × w2)+ b
最后将它们经过激活函数(activation function)处理得到输出:
y = f(x1 × w1 + x2 × w2 + b)
激活函数的作用是将无限制的输入转换为可预测形式的输出。一种常用的激活函数是sigmoid函数:
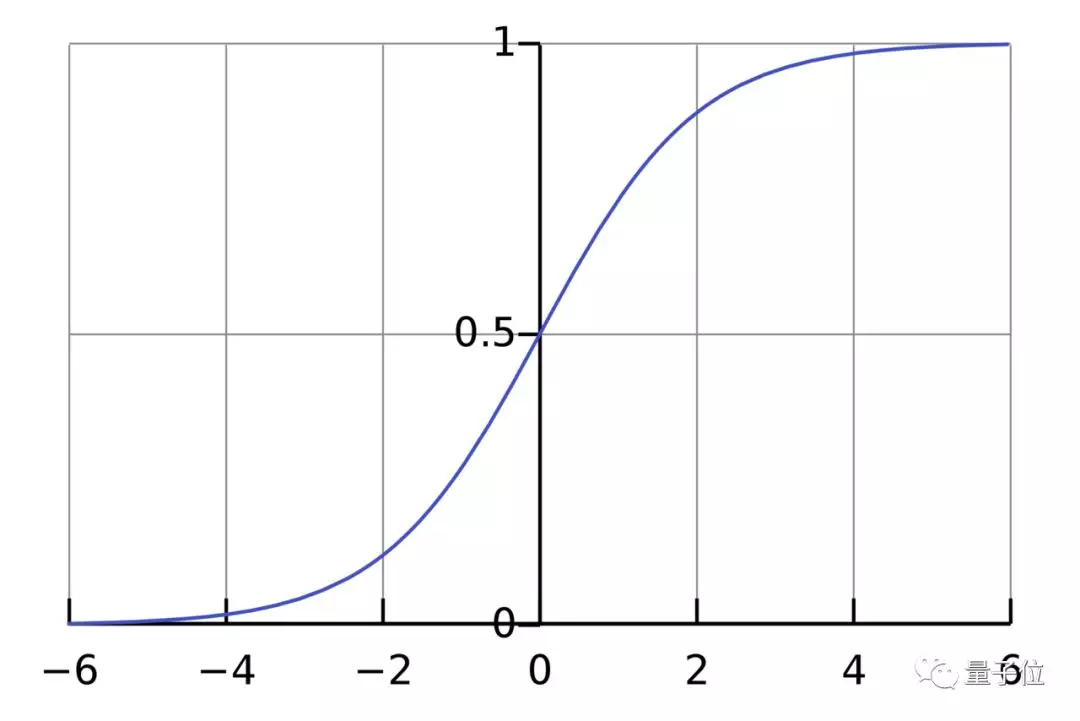
sigmoid函数的输出介于0和1,我们可以理解为它把 (−∞,+∞) 范围内的数压缩到 (0, 1)以内。正值越大输出越接近1,负向数值越大输出越接近0。
举个例子,上面神经元里的权重和偏置取如下数值:
w=[0,1]
b = 4
w=[0,1]是w1=0、w2=1的向量形式写法。给神经元一个输入x=[2,3],可以用向量点积的形式把神经元的输出计算出来:
w·x+b =(x1 × w1)+(x2 × w2)+ b = 0×2+1×3+4=7
y=f(w⋅X+b)=f(7)=0.999
以上步骤的Python代码是:
import numpy as np
def sigmoid(x):
# Our activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# Weight inputs, add bias, then use the activation function
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994我们在代码中调用了一个强大的Python数学函数库NumPy。
搭建神经网络
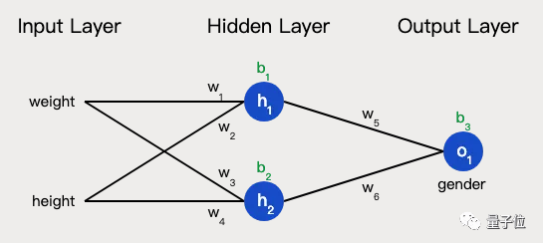
神经网络就是把一堆神经元连接在一起,下面是一个神经网络的简单举例:

这个网络有2个输入、一个包含2个神经元的隐藏层(h1和h2)、包含1个神经元的输出层o1。
隐藏层是夹在输入输入层和输出层之间的部分,一个神经网络可以有多个隐藏层。
把神经元的输入向前传递获得输出的过程称为前馈(feedforward)。
我们假设上面的网络里所有神经元都具有相同的权重w=[0,1]和偏置b=0,激活函数都是sigmoid,那么我们会得到什么输出呢?
h1=h2=f(w⋅x+b)=f((0×2)+(1×3)+0)
=f(3)
=0.9526
o1=f(w⋅[h1,h2]+b)=f((0∗h1)+(1∗h2)+0)
=f(0.9526)
=0.7216
以下是实现代码:
import numpy as np
# ... code from previous section here
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
Each neuron has the same weights and bias:
- w = [0, 1]
- b = 0
'''
def __init__(self):
weights = np.array([0, 1])
bias = 0
# The Neuron class here is from the previous section
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# The inputs for o1 are the outputs from h1 and h2
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421训练神经网络
现在我们已经学会了如何搭建神经网络,现在我们来学习如何训练它,其实这就是一个优化的过程。
假设有一个数据集,包含4个人的身高、体重和性别:

现在我们的目标是训练一个网络,根据体重和身高来推测某人的性别。

为了简便起见,我们将每个人的身高、体重减去一个固定数值,把性别男定义为1、性别女定义为0。

在训练神经网络之前,我们需要有一个标准定义它到底好不好,以便我们进行改进,这就是损失(loss)。
比如用均方误差(MSE)来定义损失:

n是样本的数量,在上面的数据集中是4;
y代表人的性别,男性是1,女性是0;
ytrue是变量的真实值,ypred是变量的预测值。
顾名思义,均方误差就是所有数据方差的平均值,我们不妨就把它定义为损失函数。预测结果越好,损失就越低,训练神经网络就是将损失最小化。
如果上面网络的输出一直是0,也就是预测所有人都是男性,那么损失是:

MSE= 1/4 (1+0+0+1)= 0.5
计算损失函数的代码如下:
import numpy as np
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5减少神经网络损失
这个神经网络不够好,还要不断优化,尽量减少损失。我们知道,改变网络的权重和偏置可以影响预测值,但我们应该怎么做呢?
为了简单起见,我们把数据集缩减到只包含Alice一个人的数据。于是损失函数就剩下Alice一个人的方差:
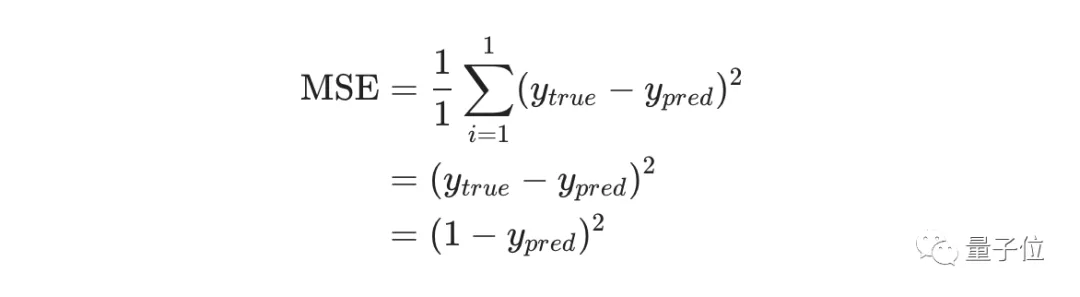
预测值是由一系列网络权重和偏置计算出来的:
所以损失函数实际上是包含多个权重、偏置的多元函数:

(注意!前方高能!需要你有一些基本的多元函数微分知识,比如偏导数、链式求导法则。)
如果调整一下w1,损失函数是会变大还是变小?我们需要知道偏导数∂L/∂w1是正是负才能回答这个问题。
根据链式求导法则:
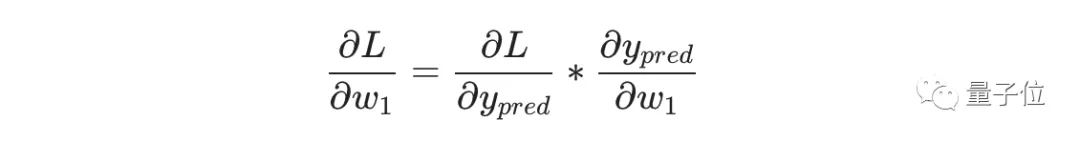
而L=(1-ypred)2,可以求得第一项偏导数:
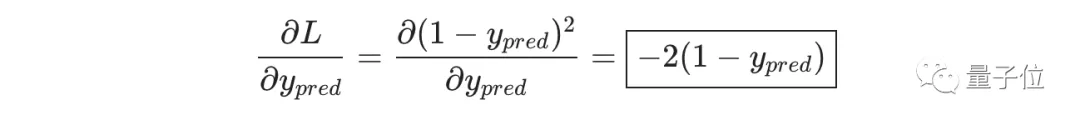
接下来我们要想办法获得ypred和w1的关系,我们已经知道神经元h1、h2和o1的数学运算规则:
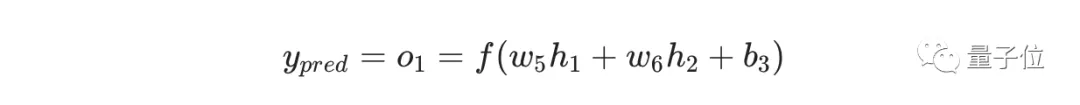
实际上只有神经元h1中包含权重w1,所以我们再次运用链式求导法则:

然后求∂h1/∂w1
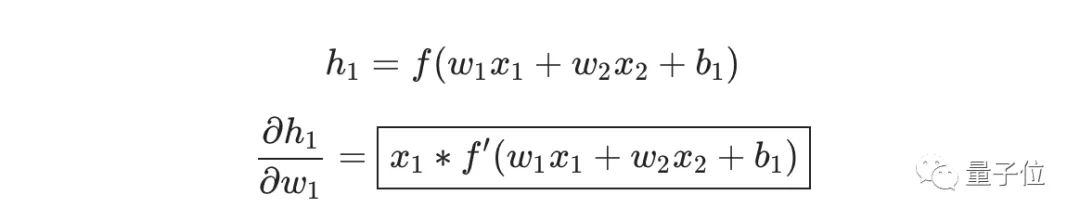
我们在上面的计算中遇到了2次激活函数sigmoid的导数f′(x),sigmoid函数的导数很容易求得:
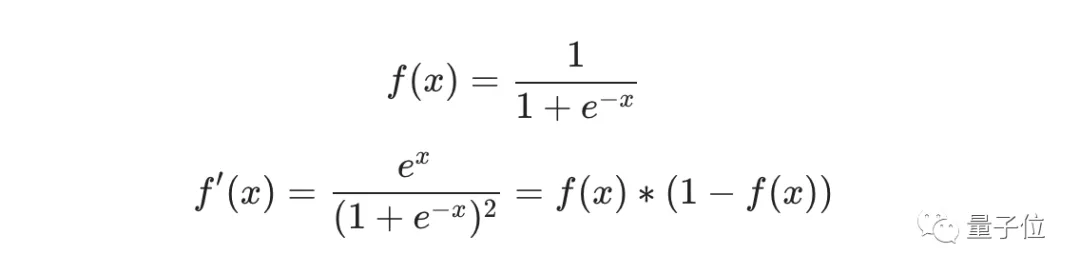
总的链式求导公式:

这种向后计算偏导数的系统称为反向传播(backpropagation)。
上面的数学符号太多,下面我们带入实际数值来计算一下。h1、h2和o1
h1=f(x1⋅w1+x2⋅w2+b1)=0.0474
h2=f(w3⋅x3+w4⋅x4+b2)=0.0474
o1=f(w5⋅h1+w6⋅h2+b3)=f(0.0474+0.0474+0)=f(0.0948)=0.524
神经网络的输出y=0.524,没有显示出强烈的是男(1)是女(0)的证据。现在的预测效果还很不好。
我们再计算一下当前网络的偏导数∂L/∂w1:

这个结果告诉我们:如果增大w1,损失函数L会有一个非常小的增长。
随机梯度下降
下面将使用一种称为随机梯度下降(SGD)的优化算法,来训练网络。
经过前面的运算,我们已经有了训练神经网络所有数据。但是该如何操作?SGD定义了改变权重和偏置的方法:
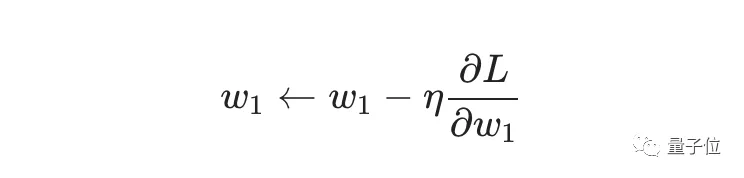
η是一个常数,称为学习率(learning rate),它决定了我们训练网络速率的快慢。将w1减去η·∂L/∂w1,就等到了新的权重w1。
当∂L/∂w1是正数时,w1会变小;当∂L/∂w1是负数 时,w1会变大。
如果我们用这种方法去逐步改变网络的权重w和偏置b,损失函数会缓慢地降低,从而改进我们的神经网络。
训练流程如下:
1、从数据集中选择一个样本;
2、计算损失函数对所有权重和偏置的偏导数;
3、使用更新公式更新每个权重和偏置;
4、回到第1步。
我们用Python代码实现这个过程:
import numpy as np
def sigmoid(x):
# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
*** DISCLAIMER ***:
The code below is intended to be simple and educational, NOT optimal.
Real neural net code looks nothing like this. DO NOT use this code.
Instead, read/run it to understand how this specific network works.
'''
def __init__(self):
# Weights
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# Biases
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# x is a numpy array with 2 elements.
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
- data is a (n x 2) numpy array, n = # of samples in the dataset.
- all_y_trues is a numpy array with n elements.
Elements in all_y_trues correspond to those in data.
'''
learn_rate = 0.1
epochs = 1000 # number of times to loop through the entire dataset
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- Do a feedforward (we'll need these values later)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- Calculate partial derivatives.
# --- Naming: d_L_d_w1 represents "partial L / partial w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Neuron o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- Update weights and biases
# Neuron h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- Calculate total loss at the end of each epoch
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# Define dataset
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# Train our neural network!
network = OurNeuralNetwork()
network.train(data, all_y_trues)随着学习过程的进行,损失函数逐渐减小。
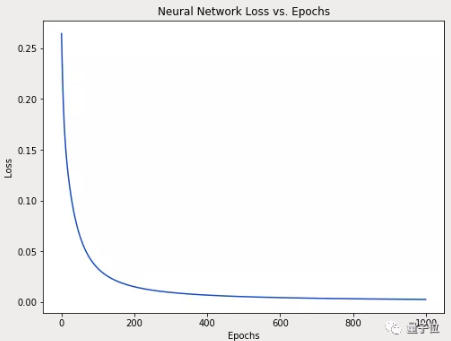
现在我们可以用它来推测出每个人的性别了:
# Make some predictions
emily = np.array([-7, -3]) # 128 pounds, 63 inches
frank = np.array([20, 2]) # 155 pounds, 68 inches
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M更多
这篇教程只是万里长征第一步,后面还有很多知识需要学习:
1、用更大更好的机器学习库搭建神经网络,如Tensorflow、Keras、PyTorch
2、在浏览器中的直观理解神经网络:https://playground.tensorflow.org/
3、学习sigmoid以外的其他激活函数:https://keras.io/activations/
4、学习SGD以外的其他优化器:https://keras.io/optimizers/
5、学习卷积神经网络(CNN)
6、学习递归神经网络(RNN)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号