
python基础
python 基础
day01
1.markdown笔记
-
使用 一个#号 + 一个空格 + 内容, 将内容设置成一级标题,(两个 # 号 , 二级标题, 三个# 号, 三级标题)
-
使用 - + 一个空格 生成无序列表
-
使用 三个 ` 生成 代码块,(例如 : ``` python)
-
使用 tab 键可以 使无序列表降级。
-
使用 1. + 空格 可以生成有序列表。 同样可以使用 tab 键使有序列表降级。
-
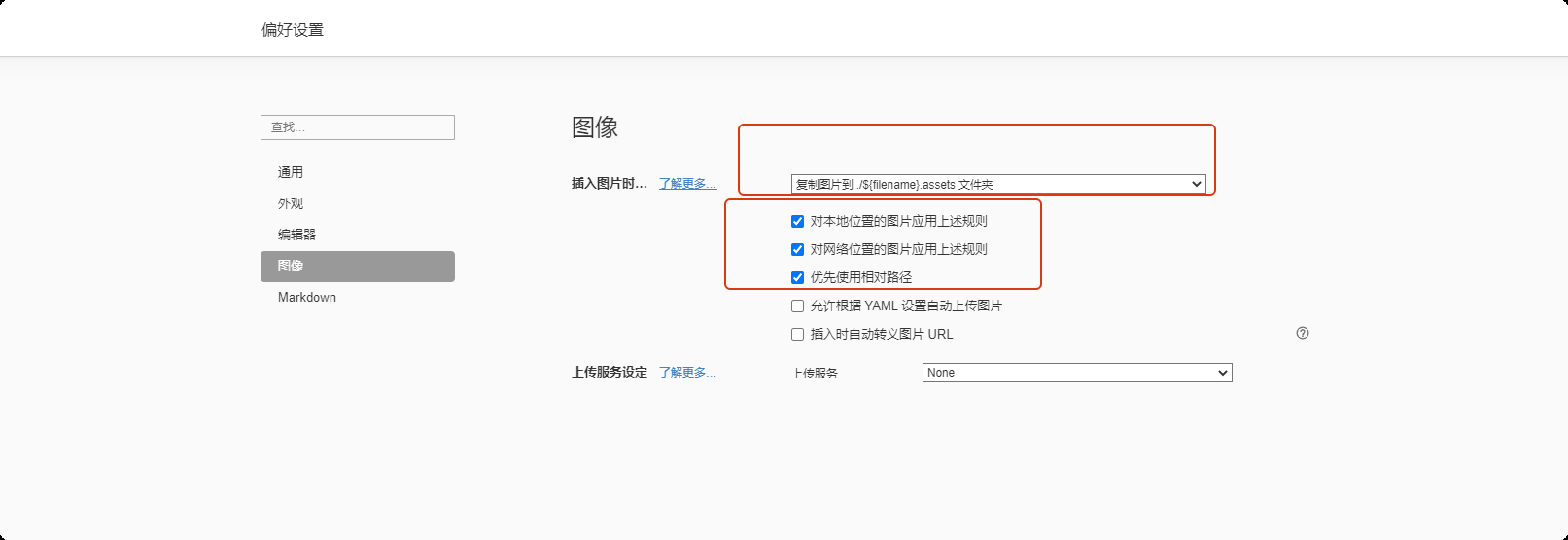
设置图片保存路径在当前文件所在的文件夹下的 ./assets 文件夹下,如下图
![image-20250606182259741]()

2.环境搭建相关
2.1 python
Cpython 解释器, 底层是用C 语言写的,解释执行Python代码。
-
根据语法规则,编写相关代码。
-
代码交给解释器运行。
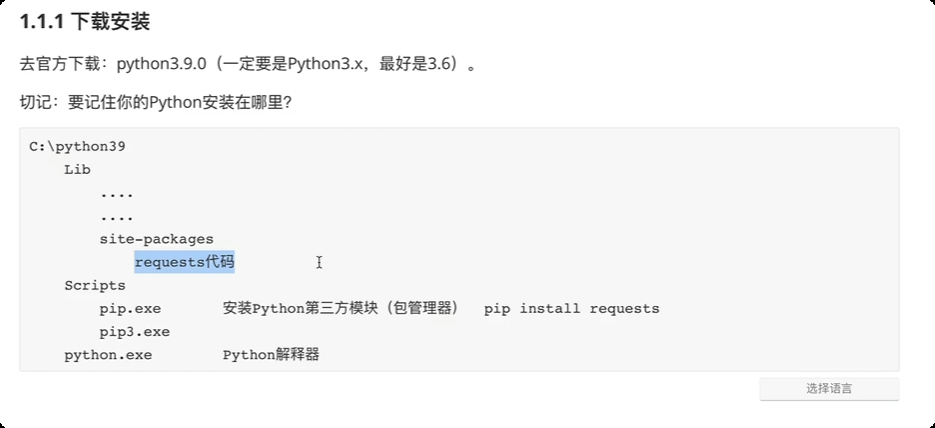
2.1.1 下载安装
官方下载: python3.x
要记住python 的安装位置
![image-20250606184340269]()
书写 app.py , 如果想要运行python 代码, 那么可以 打开终端 cmd 使用 :
C:python39\python.exe d:\app.py
2.2 pycharm
IDE, 集成开发环境。 注意事项:社区版 和专业版(推荐) 不要汉化(汉化的版本,一些功能,不能使用了)。
3.编码基础
-
计算机底层本质上都是010101。
-
编码, 文字 和二进制的对应关系。注意:文件用什么编码保存, 就要用什么编码打开。
-
常见的编码
ascii编码 256 种(英文字母, 标点符号) utf-8编码 中文、英文、韩语 。。。 gbk/gb2312编码 亚洲 -
写代码, 要保存起来-> 选择编码utf-8
-
python 解释器去运行
xxx/xxx/python解释器 xxx/xxx/xx/xx.py - 打开文件并读取,如果文件是用 utf-8 编码的, python解释器也要用 utf-8编码去打开(python解释器 默认就是用utf-8编码去打开所有的代码文件) - 解释并执行 -
强调用 utf-8编码打开文件
# -*- coding:utf-8 -*- print("你好,大可爱") -
注意:
- python3.x 解释器默认的编码utf-8
- python2.x 解释器默认的编码ascii(打开文件)
4.输出
写程序的本质,执行操作,查出结果。
print("hello, 小小")
# 默认 print 后会换行,可以指定 end参数
print(8888, end="")
print("*********** 欢迎使用移动xx系统 ************")
phone = input("请输入你的手机号:")
code = input("请输入验证码: ")
if phone == "222" and code == "999":
print("登录成功")
else:
print("登录失败")
5.数据类型
-
整型
平时生活中说的数字,例如:年龄、高低、重量
100 200 print(100) -
字符串类型
平时生活中想要表达文本信息, 例如:地址、城市、个人简绍。
# 双引号 "leetcode" # 单引号 'hello, world' # 为什么要有双引号和单引号, 防止 文本中有单引号 或者双引号 "你好',小明" '你好" 小红' # 三双引号 支持换行 """github is good website""" # 三单引号 '''cnblog''' -
布尔类型
真假
100 > 10 # True 101 < 88 # False
6.类型转换
-
整型 int
888 -
字符串 str
"hello, mpx" -
布尔类型 bool
True/False -
类型转换:
- 整型-> 字符串
9999 str(9999) -> "9999"-
字符串-> 整型
"123" int("123") -> 123 -
布尔类型转换
bool(123) # True bool(0) # False bool(-10) # True bool("hello") # True bool("") # False bool(" ") # True bool("000") # True # 只有 0, "" -> 布尔值 False 其他均为True
7.变量
-
变量理解成为昵称
# 变量 = 值 n1 = "mpy" m1 = 4056 u1 = False print(u1) print(m1) print(n1) # 关于 等号 number = 1 == 2 # number = False -
变量名的规范
- 三大原则
- 变量名中只能包含: 字母,数字,下划线
- 数字不能开头
- 不能是python 内置的关键字
- 变量的两条建议
- 下划线连接多个单词
- 见名知义
- 三大原则
-
内存关系
-
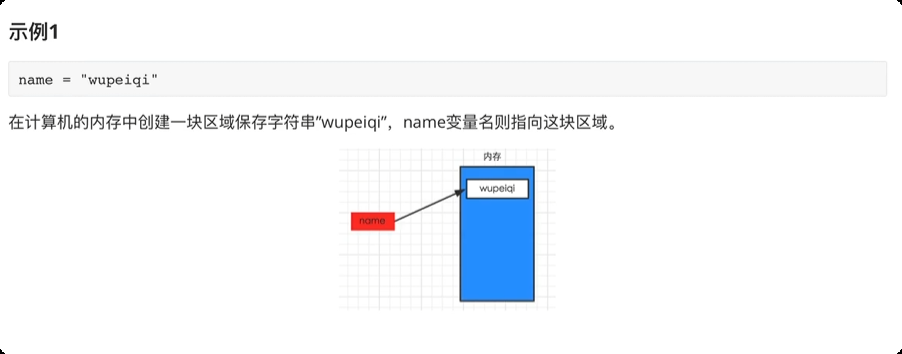
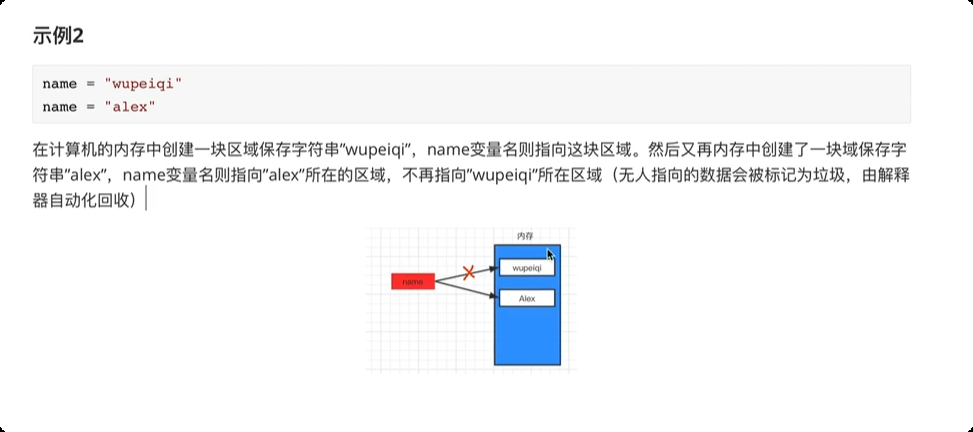
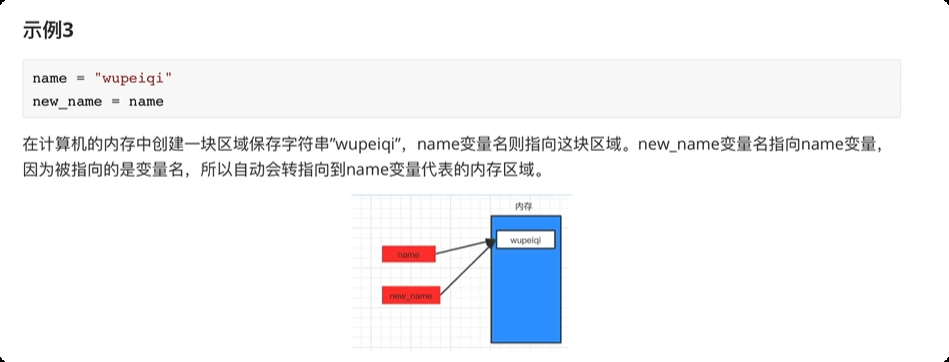
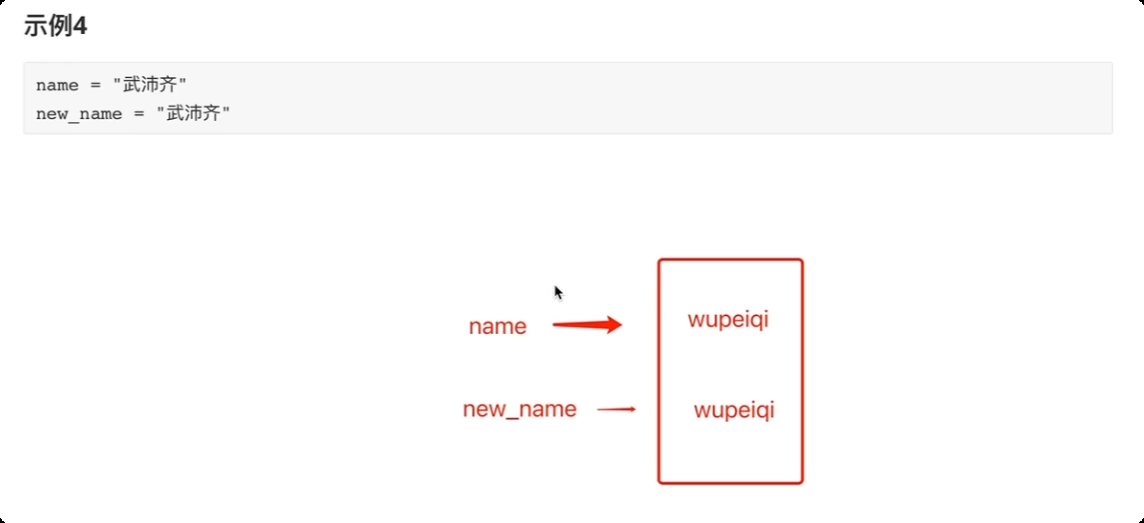
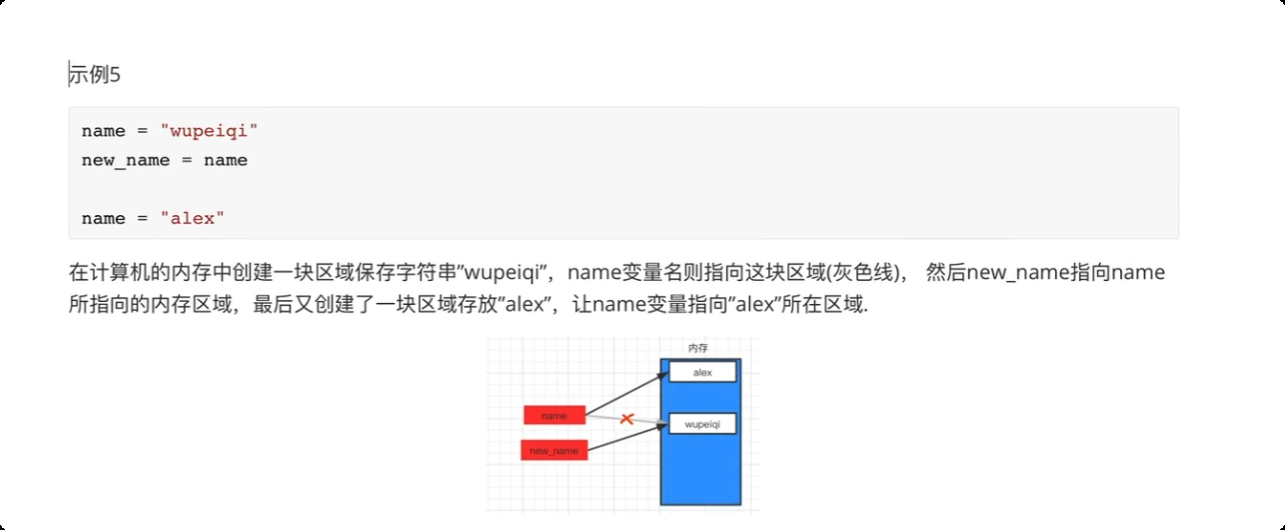
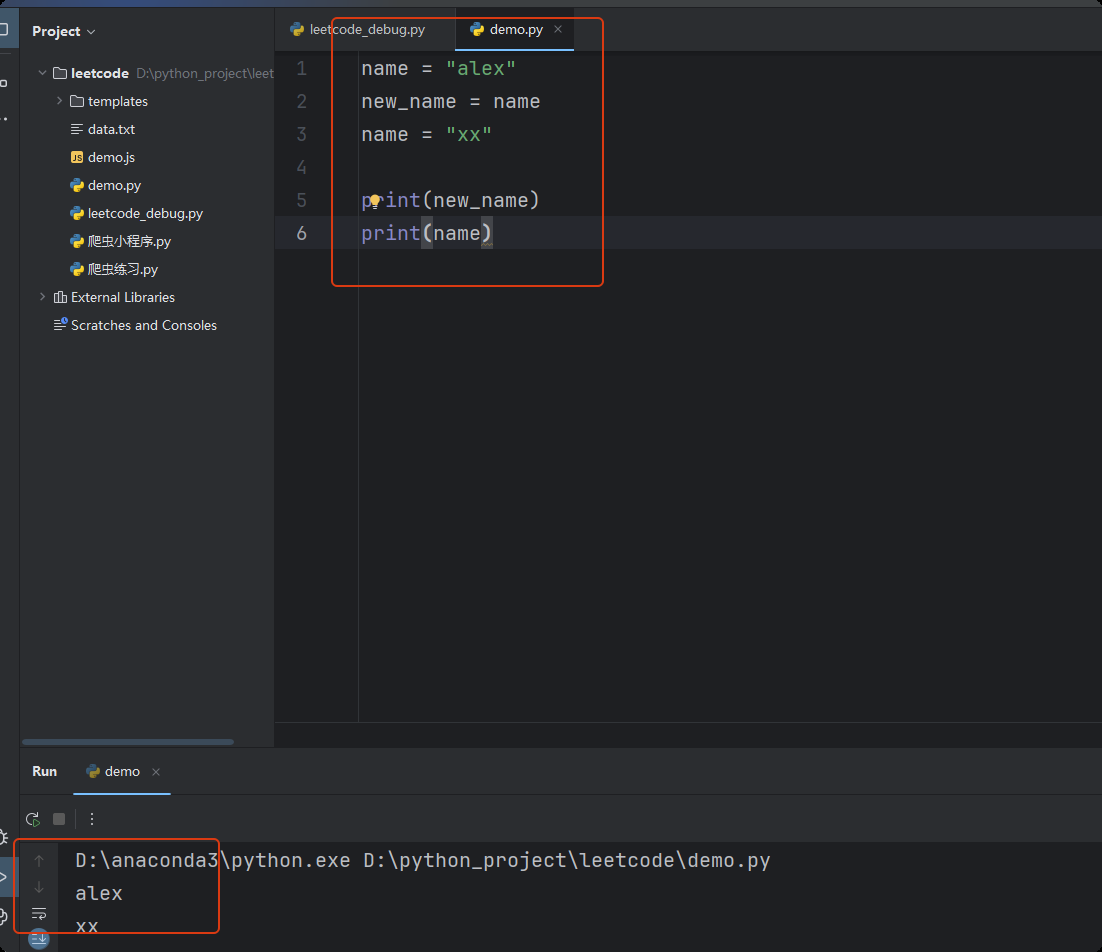
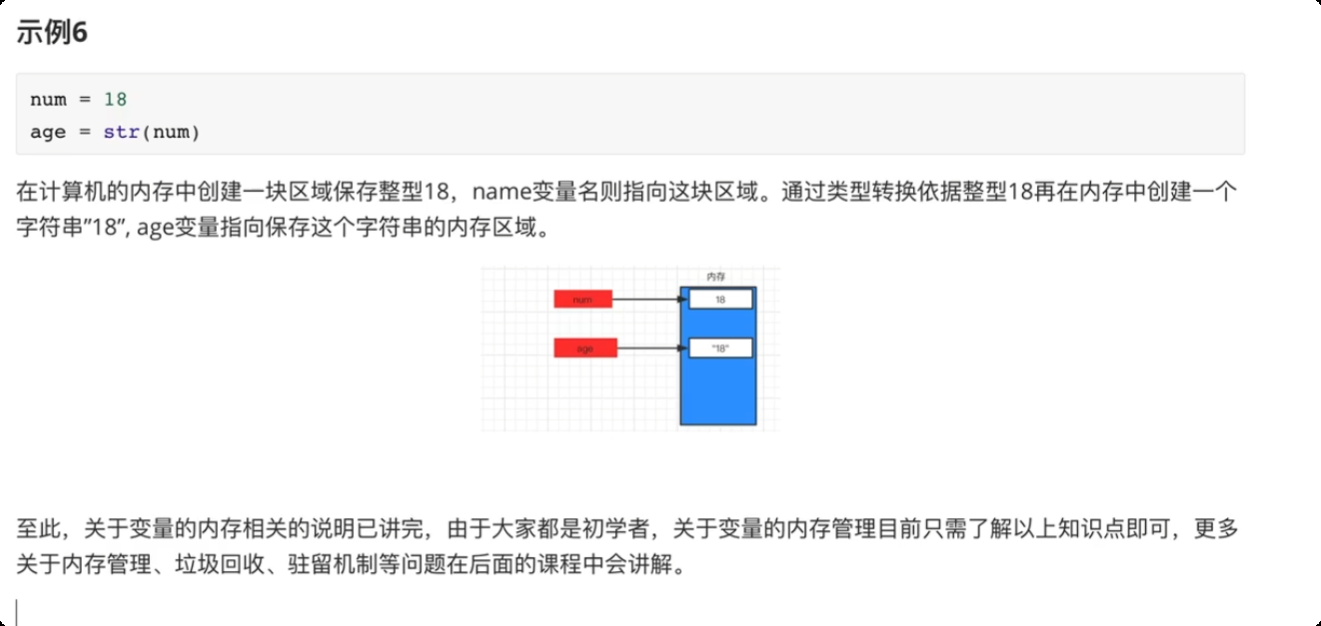
8.注释
-
单行注释
# 输出一个结果 print(123) print(123) # 输出一个结果 -
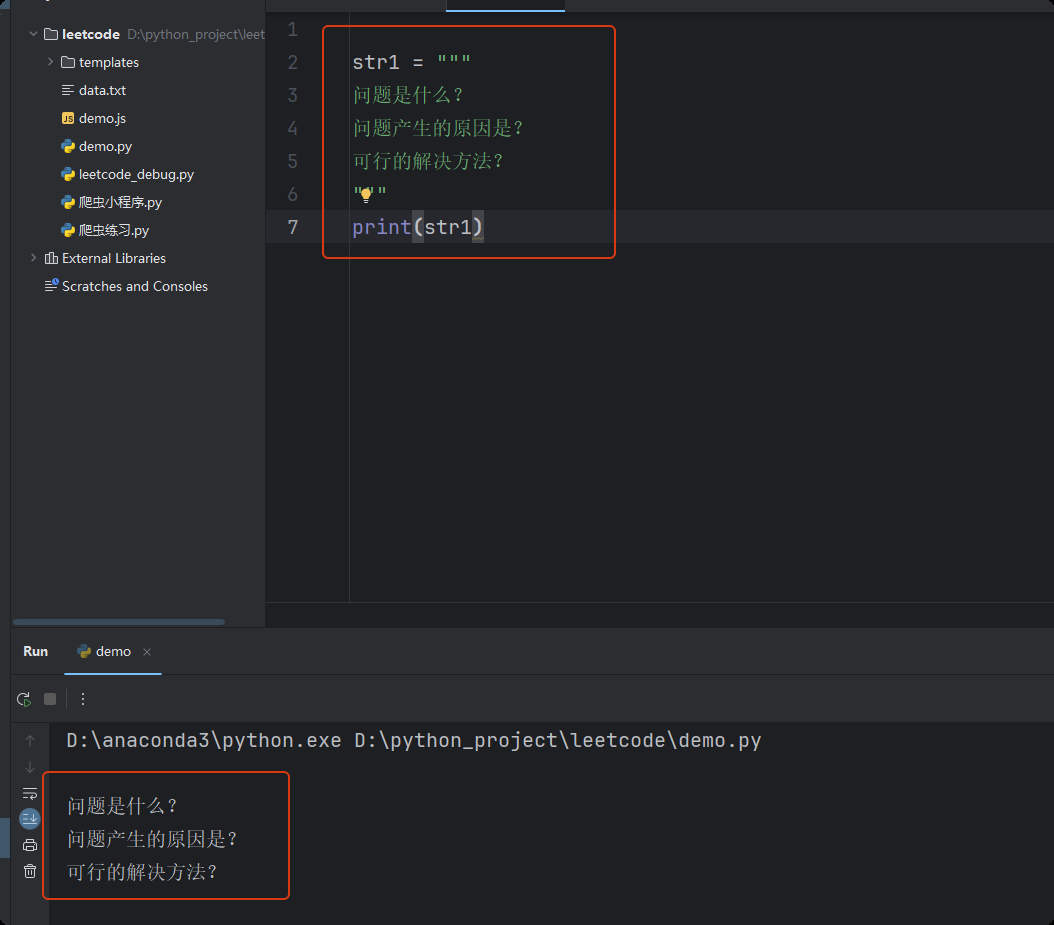
多行注释
# 多行变量 三引号括起来的内容, 前面用变量接收 str1 = """ 今天是个好天气 心情不错! """ # 多行注释, 前面不用变量接收 """ 这里是多行注释 嘿嘿嘿 """ # pycharm 中的注释快捷键 contrl + /![image-20250607130028950]()
-
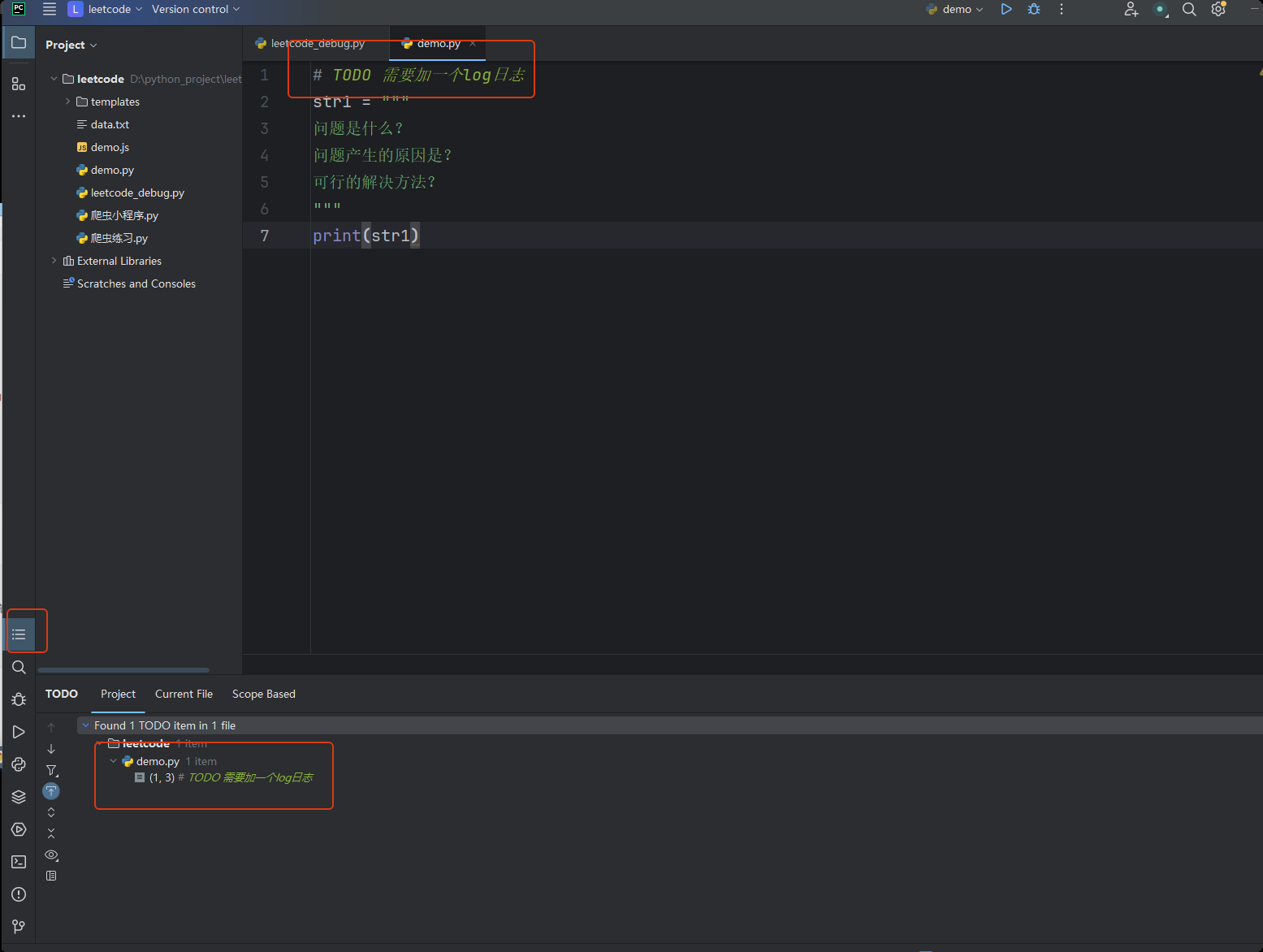
TODO
pycharm 根据TODO 关键字 帮助快速定位 TODO事项
![image-20250607131211062]()
9.输入
需要用户输入内容,才能继续向后走。
name = input("请输入用户名:") # "root"
age = input(">>>") # "18"
10.条件语句
类 c 编程语言的条件语句
if(条件){
条件成立,执行此处代码
}else{
不成立, 执行此处代码
}
# python 中的条件语句
if 条件:
print(123)
else:
print(456)
# 多条件语句
if 条件A:
pass
elif 条件B:
pass
elif 条件C:
pass
else:
pass
# 条件语句的嵌套
if 条件:
if 条件:
...
else:
...
elif 条件:
...
else:
...
11.循环语句
-
while 循环
while 条件: print(123) -
for 循环
name = "mmo" for ch in name: print(ch) # result: m n o # for 循环 + range 结合使用 v1 = range(5) # [0, 1, 2, 3, 4] v2 = range(1, 5) # [1, 2, 3, 4] for item in range(5): # [0, 1, 2, 3, 4] pass # range 加步长 v3 = range(0, 5, 2) # [0, 2, 4] v4 = range(10, 0, -2) # [10, 8, 6, 4, 2] range前取后不取(包头不包尾) v5 = range(5, -1, -1) # [5, 4, 3, 2, 1, 0] # for 循环 也支持 continue 和 break for item in range(10): #[0, 1, 2..9] print(item) break # 结果: 0 for item in range(3): print(1) continue print(item) # 结果: 三次循环输出 三个1 -
break 和 continue
break: 跳出循环,不再执行 continue: 跳过当前循环,继续执行下一次循环
12.字符串格式化
想要让多个值拼接出来一个内容,用字符串格式化就会比较方便。
text = "me" + "you" + "her"
name = "mpl"
age = 17
city = 'ooo'
text = "姓名" + name + "年龄" + str(age) + "在" + city + "工作" # 拼接字符串比较的麻烦。
-
%s
-
format(推荐)
name = "mpl" age = 17 city = 'ooo' text = "姓名{0}今年{1}岁, 在{2}工作".format(name, age, city) text = "姓名{}今年{}岁, 在{}工作".format(name, age, city) # 支持键值对的方式 text = "姓名{n1}今年{n2}岁, 在{n3}工作".format(n3=city, n1=name, n2=age) -
f-string
day02
数据类型
-
字符串
name = "mpx" data = "hiu"-
独有的功能
# 判断是否以 xx 开头 v1 = "leetcode" # True/False result = v1.startswith("lee") # 判断是否以 xx 结尾 # True/False result = v1.endswith("code") # 判断一个字符串中是否全是数字 data = "123" result = data.isdecimal() if result: ans = int(data) # 大小写 msg = "Root" # 将字符串转换成全大写的 data = msg.upper() print(data) # ROOT print(msg) # Root # 将字符串转换成全小写 data = msg.lower() print(data) # root # 注意: python 中的字符串类型是不可变的。(不能修改内容元素) # 去除空白 rstrip 去除右边的空白 data = "中国移动 " result = data.rstrip() print(result) # "中国移动" print(data) # "中国移动 " # 去除左边的空白 lstrip() data1 = " 中国移动" result = data1.lstrip() print(result) # "中国移动" print(data1) # " 中国移动" # 去除两边的空白 data2 = " lll " result = data2.strip() print(result) # "111" print(data2) # " 111 " # 替换 replace data = "mpp jxj zyy" result = data.replace(" ", "") print(result) # "mppjxjzyy" # 切割 split # 切割 csv文件 line = "31231,1232,mpp" result = line.split(',') # ["31231", "1234", "mpp"] # 拼接 join data_list = ["111", '222', '333'] result = ",".join(data_list) # "111,222,333" # 字符串和字节 data = "中国移动" # unicode编码存储, 每个中文字符占4个字节 # 将字符串转换成utf-8编码(压缩,能用更少的字节)
-
result = data.encode("utf-8") # 字节(二进制形式)
result1 = result.decode("utf-8") # 字符串格式
```
-
公共功能
# len() 获取长度 name = "mpp" length = len(name) print(length) # 3 # 通过索引获得字符串中的字符, 只能读取(字符串不支持修改,不可变类型) str1 = "hllo" str1[0] # 'h' str1[2] # 'l' str1[len(str1) - 1] # 'o' str1[-2] # 'l' # 切片 包头不包尾 name = "root" name[0:2] # "ro" # for 循环 name = "root" for item in name: print(itme) # r o o t -
列表
data = [1, 2, "str", True]-
独有功能
-
追加 append 在原列表的尾部追加一个元素
data = [1, 2] data.append("mpp") print(data) # [1, 2, 'mpp'] -
插入,insert 将元素插入到原列表的指定位置
data1 = [1, 2, "ooo"] data1.insert(0, "p") print(data1) # ["p", 1, 2, "ooo"] -
删除, remove 将指定的元素从列表中删除, 列表中有多个相同的要删除的元素,从左到右找到第一个删除,
如果找不到要删除的元素,会报一个ValueError 的错误
list1 = ['moo', 'ioo', 'uoo'] list1.remove('moo') print(list1) # ['ioo', 'uoo'] # 使用 remove 删除列表中的一个元素的时候, 要保证元素在列表中, 可以使用in 判断 "ioo" in list1 # True -
清空列表 clear ()
data = [1,2,3] data.clear() print(data) # [] -
排序 sort()
data_list = [2,3,4,5,1] data_list.sort() # 从小到大排序 print(data_list) # [1,2,3,4,5] data_list.sort(reverse=True) # 从大到小排序 data2 = ["今天", "明天", '昨天'] data2.sort() # 依据是什么? unicode编码值的大小进行比较 print(data_list) -
反转 ,reverse()
data1 = [1, 2, 3] data1.reverse() print(data1) # [3, 2, 1]
-
-
公共功能
-
长度 len
data_list = [1, 2, "mpp"] size = len(data_list) print(size) # 3 -
索引
data_list = [1, 2, 6] # 读取 data_list[1] # 2 # 修改 data_list[1] = 5 print(data_list) # [1, 5, 6] # 删除, 根据索引进行删除, 删除指定索引位置处的元素 del data_list[0] print(data_list) # [5, 6] -
切片 包头不包尾
data_list = [1, 2, 3, 4, 5] data_list[1:3] # [2,3] -
for 循环
data_list = ['0', 'mm', 1, 3] for item in data_list: print(item) for i in range(len(data_list)): item = data_list[i] print(item)
-
-
-
元组 内部元素不允许修改
data = (11, 22, 33, 44) # 元组 data1 = [11, 22, 33] # 列表 v1 = (11) # 11 v1 = (11,) # (11, )-
独有功能
无
-
公共功能
-
长度
v1 = (11, 22, 33) size = len(v1) print(size) -
索引
v1 = (11, 22, 33) v1[0] # 11 -
切片
v1 = (11, 22, 33) v1[0:2] # (11, 22) -
for循环
v1 = (11, 22, 33) for item in v1: print(item) # 11 22 33
-
-
-
字典
字典中存储的是键值对的数据,
键:必须是可hash 的类型 由键获取一个相对应hash值, 目前可哈希的: int 、bool 、str 、tuple
值:可以是任意类型
info = {"k1":123, "l": 567} info1 = { 1:234, "xxx":100, False:"mmp", (11,22):False }-
独有的功能
-
获取值
info1 = { "name": "mpp", "age": 28, "school": "xxx" } # 根据 键 获取值 v1 = info1.get("name") # "mpp" # 获取字典中没有的元素, 如果字典中不存在相关的键, 返回空值None v2 = info1.get("kkkk") # None # 获取字典中对应 key 的值,获取到值,返回结果, 获取不到,可以设置一个默认值, 返回默认值 v1 = info1.get("ooo",777) # 777 -
键/值/键值对
info1 = { "name":'mpp', "age": 30, "school": 'ppp' } data1 = info.keys() # ['name', 'age', 'school'] data2 = info.values() # ['mpp', 30, 'ppp'] data3 = info.items() # [(name, mpp), (age, 30), (school, ppp)]for item in info1.keys(): print(item) for item in info1.values(): print(item) for item in info1.items(): print(item) print(item[0]) print(item[1]) for key,value in info1.items(): print(key, vlaue)
-
-
公共功能
-
长度
info1 = { "age":124, 'name':'mpp' } size = len(info1) # 2 -
索引
info1 = { "age":111, "name":"lll" } # 读取 info1["age"] # 111 如果键不存在,报错 KeyError info1.get("age") # 111 如果键不存在,返回None # 增加 键不存在时,增加新的键值对,键存在时,修改键的值 info["add"] = 100 # 删除 del info["age"] -
修改
info1["age"] = 999- for循环 可以结合字典里面的keys(), values(), items()来使用。
-
-
-
集合
![image-20250608211545826]()
-
嵌套
数据类型由于出现了容器类型很容易出现嵌套关系。一种数据类型中包含另一种数据类型, 例如:列表中包含列表
-
类型分析
-
是否可hash, 只有可hash 的类型才能作为字典的键。
可哈希: int/str/tuple/bool 不可哈希: list, dict -
是否是可变类型
不可变: int/str/tuple/bool 可变:list, dict
-

函数
函数, 一大堆功能代码的集合
# 函数定义
def 函数名():
代码..
....
# 函数执行
函数名()
def info():
print(123)
print("你好!")
info()
# 函数存在的意义?
"""
增强代码的重用性
增加代码的可读性
"""
-
函数的参数
def info1(x1): data = x1 + 100 print(data) info(1) info(20) # 位置传参,按照位置一一对应的去传递参数 # 关键字传参, info(x1=20) # 默认参数 定义函数时, 默认参数必须放在最后 def do_something(a1, a2, a3=100): pass do_something(11, 22) # 参数未传递, 使用默认参数 do_something(11, 22, 55) # 传递参数, 使用传递的参数 # 动态参数 * def do_something(*args): # 统一将用户传入的参数放在一个元组中 args=(1, ) args=(1, 11, 22, 55) args[0] args[1] pass do_something(1) do_something(1, 11, 22, 55) # 动态参数 ** 接收多个关键字参数 def do_something(**kwargs): # 统一将传入的参数放入一个字典中 kwargs={"k1": 1}, kwargs={"k1": 1, "k2": 2, "k3": 6} pass do_something(k1=1) do_something(k1=1, k2=2, k3=6) # 动态参数 * + ** def do_something(*args, **kwargs): pass do_something(11, 22) do_something(k1=11, k2=22) do_something(11, 22, k1=11, k2=22) -
函数的返回值
函数的本质是许多代码的集合,经过函数处理后 需要输出一个结果
def plus(v1, v2): data = v1 + v2 + 50 return data result = plug(50, 100) # 200 # 关于返回值的三个关键知识点 返回值的类型可以是任意类型,如果函数没有返回值,默认返回None 在函数中一旦遇到return, 立即结束函数的执行。 在函数返回值时,可能会用逗号分开多个值,会返回一个元组
作用域和关键字global
if 1 == 1:
name = "root"
print(name) # root
for i in range(10):
pass
print(i) # 9
# python 中是以函数为作用域的, 在函数内部声明的变量,叫做局部变量,全局作用域中的变量,叫做全局变量。
# 寻找变量的时候,局部作用域中没有,就向上一级作用域中找。
# global 关键字, 在局部作用域中,对全局变量进行引用,并操作。
生成器
# 生成器函数
def func():
yield 11
yield 22
yield 33
# 调用生成器函数, 会得到一个生成器对象
gen = func()
v1 = next(gen) # 11
v2 = next(gen) # 22
v3 = next(gen) # 33
v4 = next(gen) # 报错, StopIteration
def func1():
yield 88
yield 99
yield 66
gen1 = func1()
for item in gen1:
print(item)
# 88 99 66
def create_big_num(max_num=100):
num = 0
while True:
yield num
if num == max_num:
return
num = num + 1
obj = create_big_num()
for item in obj:
print(item)
装饰器
def outer(func):
def inner():
print("before")
res = func()
print('after')
return res
return inner
v = outer(123)
v()
# 语法糖
@outer
def func2():
print("hello, world")
匿名函数 lambda 表达式
# 普通函数
def func(a1, a2):
return a1 + a2
v1 = func(1,2)
print(v1) # 3
# 匿名函数 对于简单函数可以做的简写
func1 = lambda a1, a2 : a1 + a2
v2 = func1(1,2)
print(v2)
day03
模块,将不同功能的代码放到不同的文件中
模块有
- 自定义模块
- 内置模块
- 第三方模块
自定义模块
模块和包
# 模块, py 文件
# 包, 文件夹
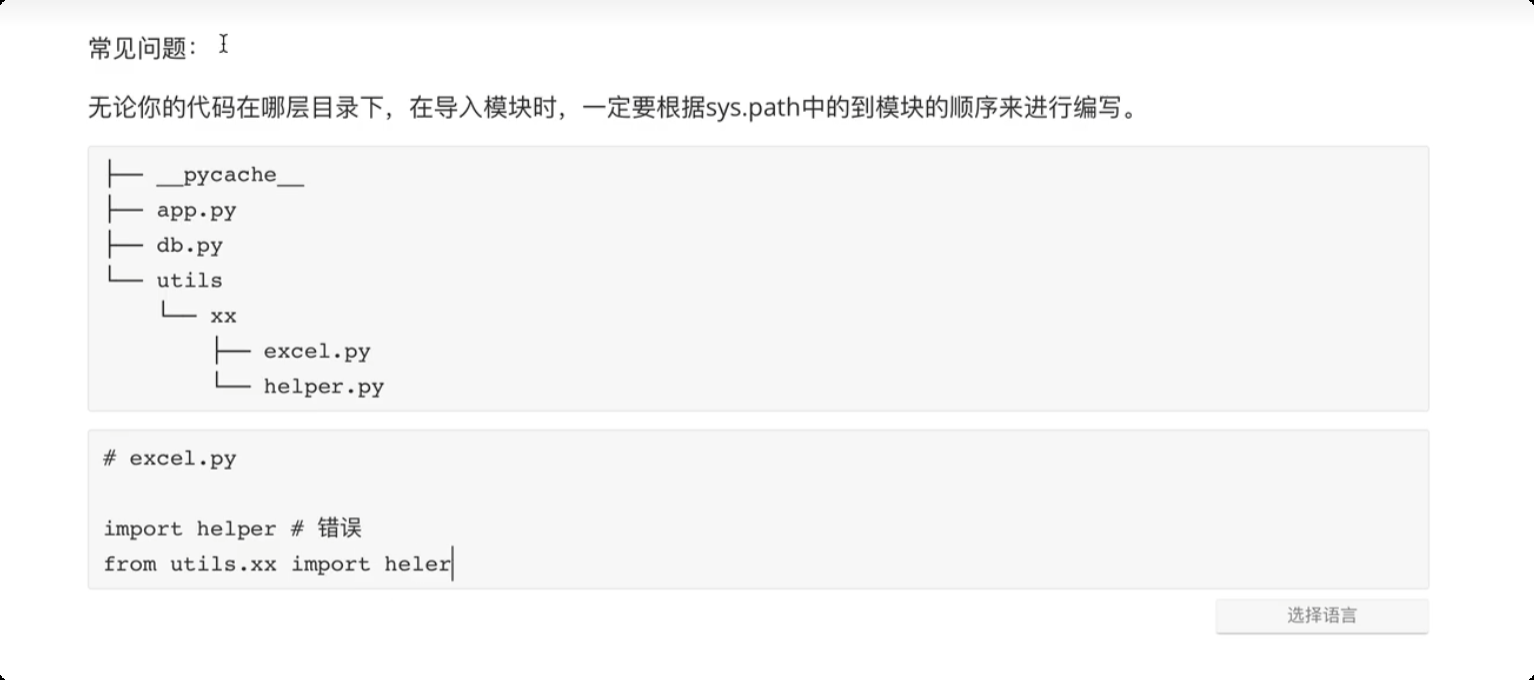
导入问题
# 导入一个模块时,从 sys.path 中的路径中一个一个去找,
import sys
print(sys.path)
# 导入的方式
import
from xxx import
# 主函数, 程序运行时自动会执行的函数。
def func1():
pass
# 运行当前文件时, __name__ 等于 "__main__", 其他文件导入时 __name__ 等于 py文件的名字
if __name__ == "__main__":
func1()
第三方模块
别人写好的py文件或者文件夹,需要下载使用。
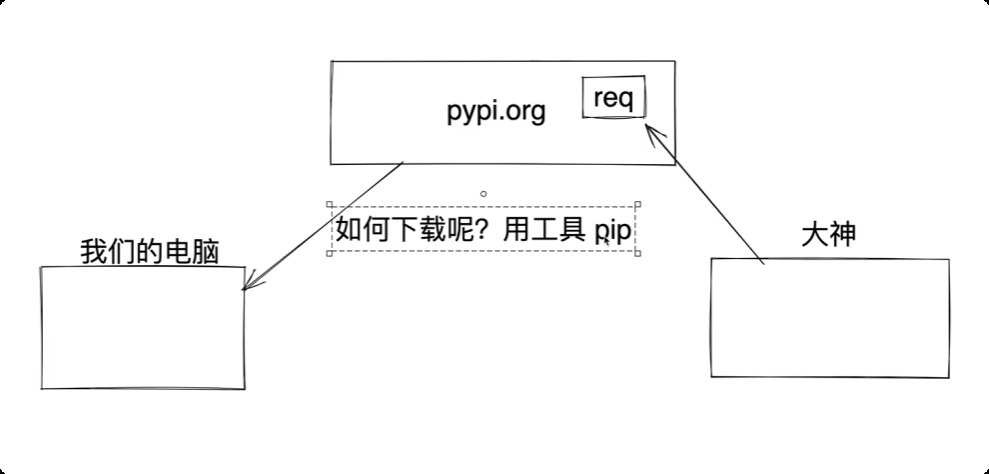
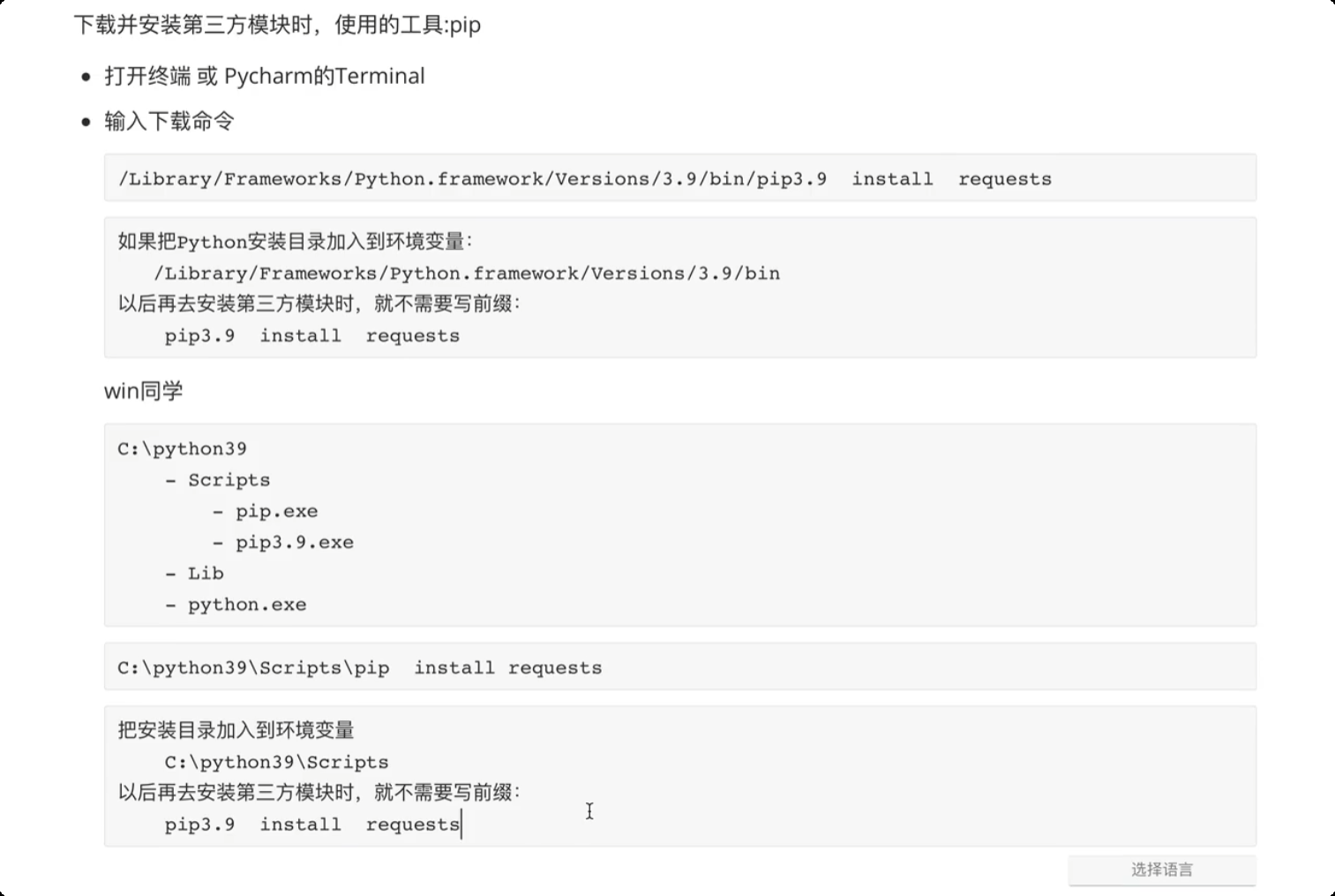
# 下载并安装第三方模块时, 使用工具: pip
# 打开终端 或 Pycharm的 Terminal
pip文件所在路径 install request
# 如果把python 安装目录加入到环境变量,就不需要写pip 路径的前缀了
pip install request

下载的第三方包的位置在 安装python 解释器的 lib/site-packages 目录下
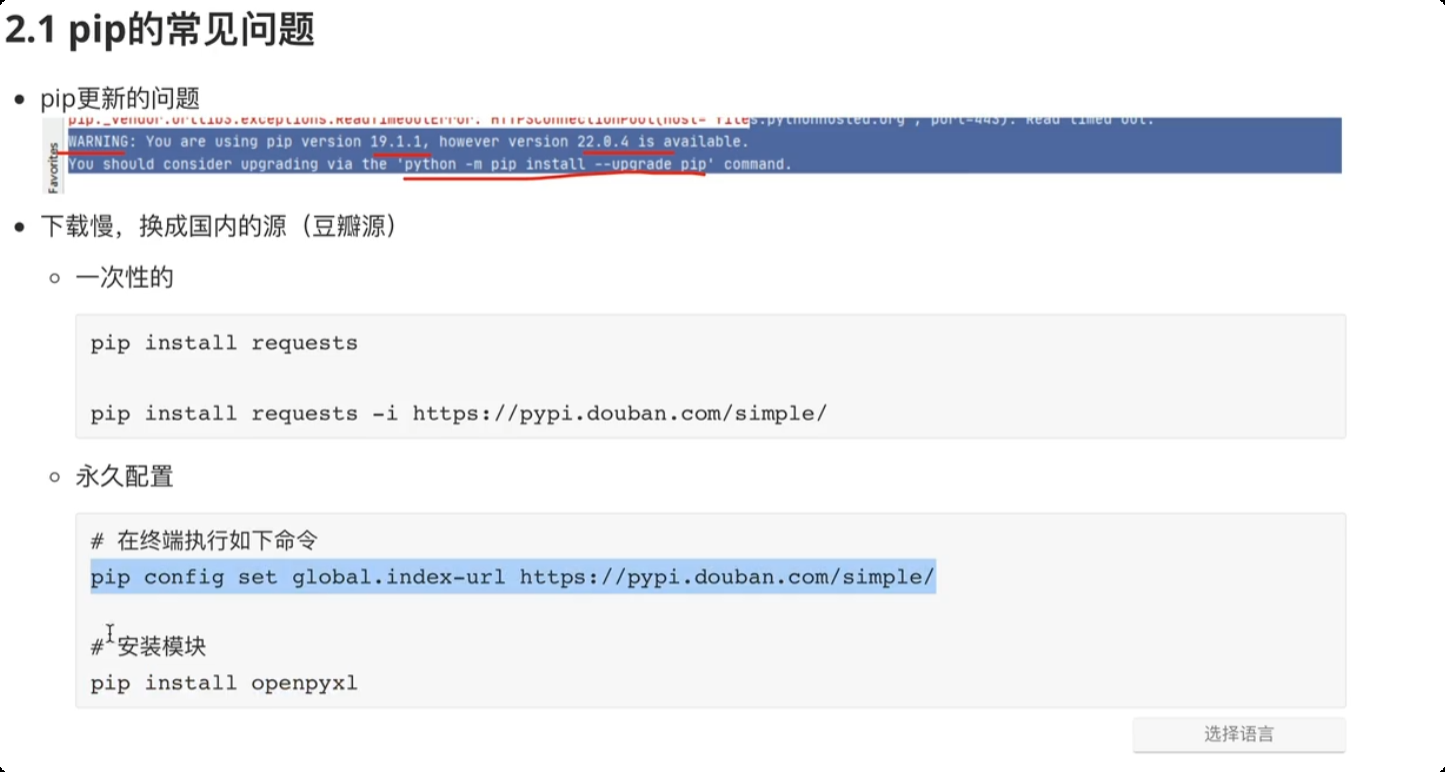
pip 更新问题,pip 的软件包更新,可以选择更新
pip 下载第三方包的时候, 下载慢的情况。换成国内的镜像源。

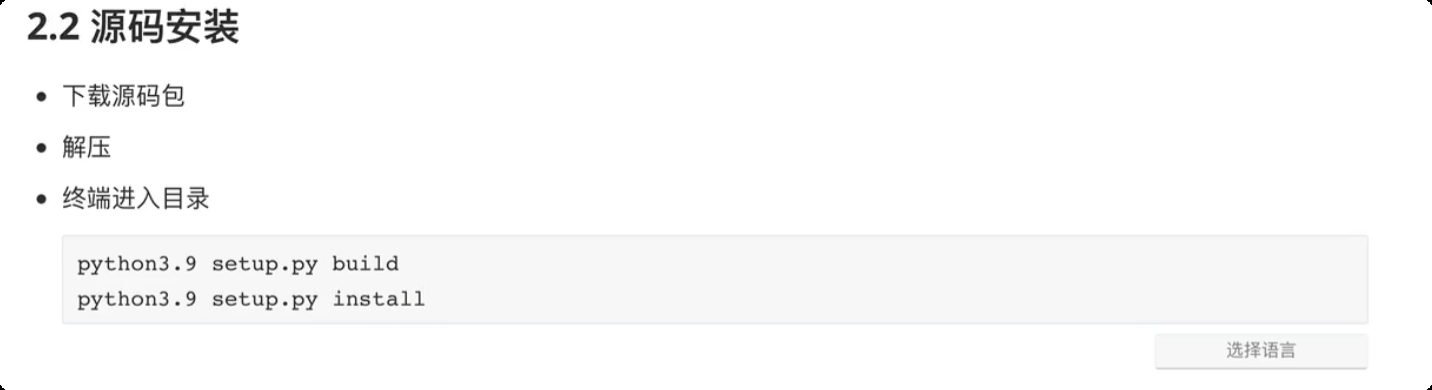
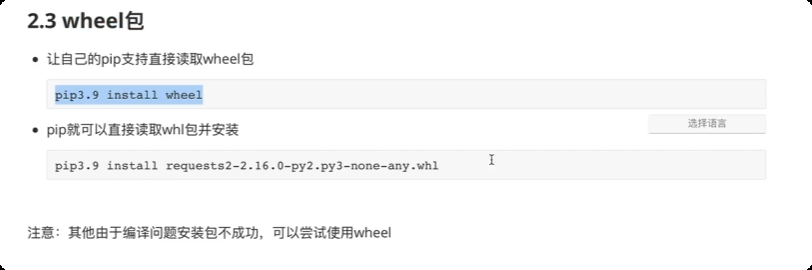
内置模块
python 内部为我们提供的功能
-
hashlib
# 可以对数据进行md5加密。 用来对用户密码进行加密 import hashlib data_string = "中国移动" obj = hashlib.md5() obj.update(data_string.encode("utf-8")) result = obj.hexdigest() print(result) # md5 进行加“盐”, 本质上:加密时再加上我们自定义的字符串。 # 建议:只要用md5加密,就要进行加盐。 import hashlib data_string = "中国移动" # 加盐的位置 obj = hashlib.md5("dsdhasdsha") obj.update(data_string.encode("utf-8")) result = obj.hexdigest() print(result) -
json 模块
# 将 json 字符串转换成python 中的字典 反序列化 str1 = '{"ada":"daasd", "name":112}' data_dict = json.loads(str1) # 将python 中的字典 转换成json字符串 序列化 dict1 = {"aa": 134, "bb":"hello"} data_stirng = json.dumps(dict1)![image-20250609185717158]()

json 字符串中不包含 单引号, 不包含大写的True/False , 包含 小写的 true/false, 不包含 ()元组, 包含[]

-
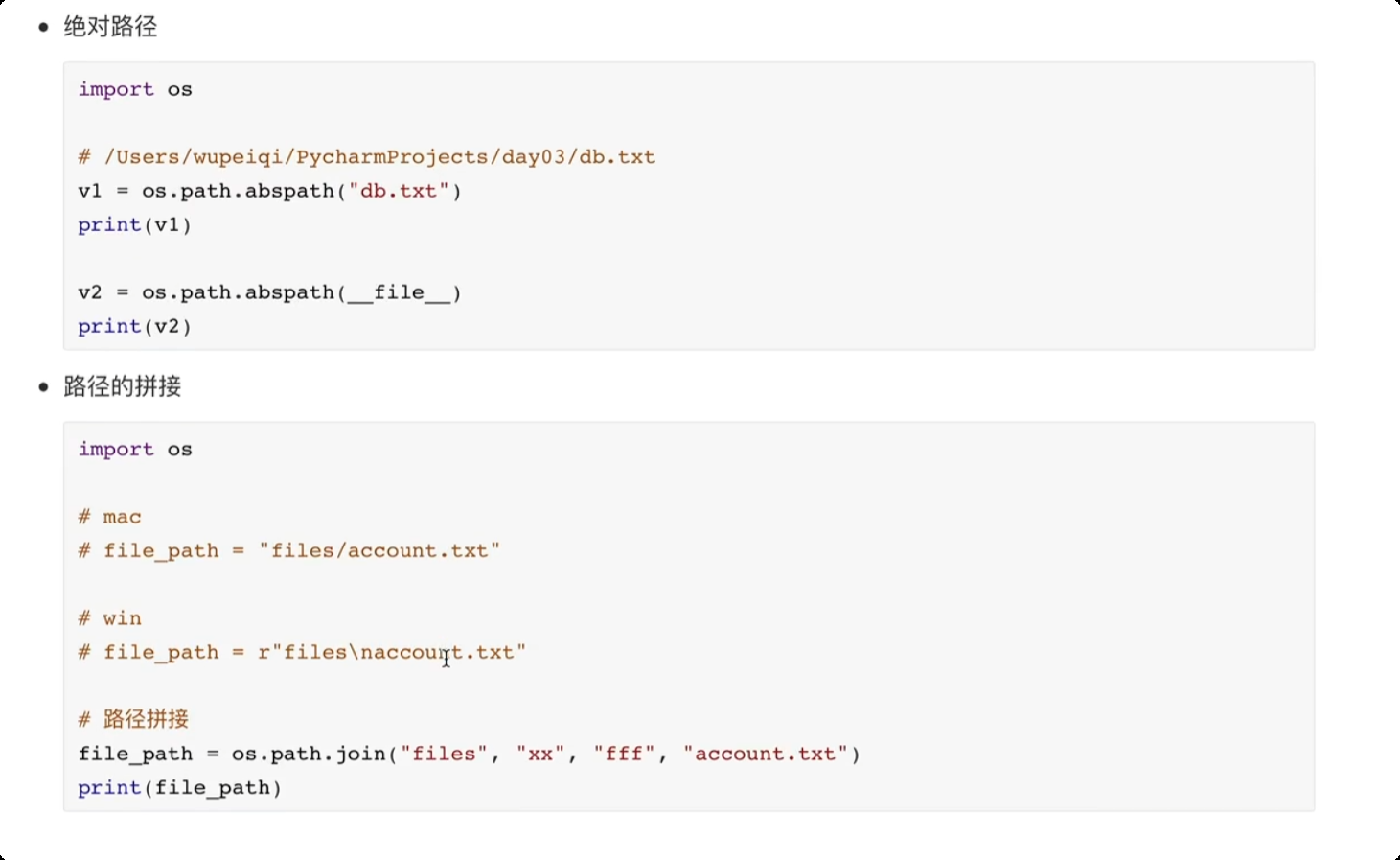
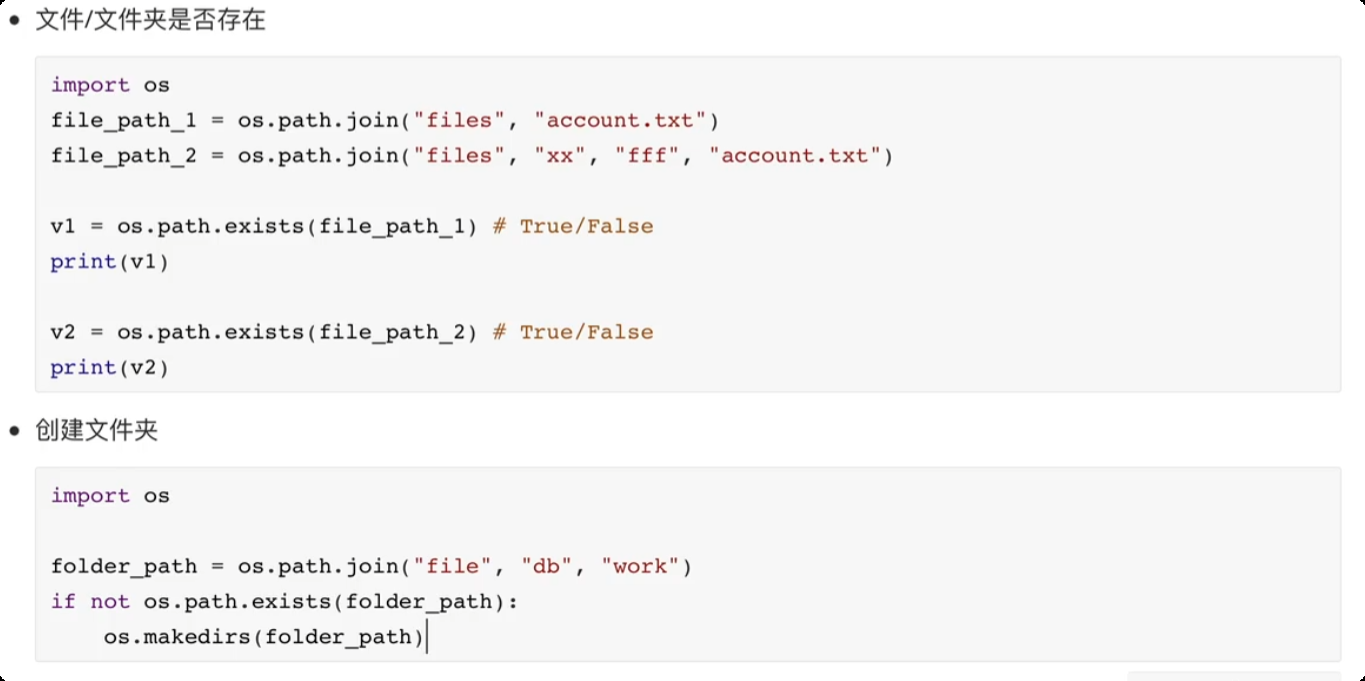
os 模块
![image-20250609191216290]()
![image-20250609191604322]()


-
random
# 生成一个范围内随机数 import random v1 = random.randint(0, 3) print(v1) # 从一个列表中随机选择一个数 import random num_list = [11, 22, 33, 44] v2 = random.choice(num_list) print(v2) # 将数据打散 import random num_list = [99, 11, 67,30] random.shuffle(num_list) print(num_list) -
时间模块
-
time
# 获取当前的时间戳 # 从1970年1月1号,到现在经历的秒数。 import time v1 = time.time() print(v1) # 计算程序运行时间 import time start = time.time() num = 0 for i in range(10000000): num +=i end = time.time() use_time = end - start print(use_time) # 设置等待时间 import time time.sleep(5) -
datetime
# datetime 对象的形式 import datetime v1 = datetime.datetime.now() print(v1) # 可以设置时区 tz = datetime.timezone(datetime.timedelta(hours=7)) v2 = datetime.datetime.now(tz) print(v2) v3 = datetime.datetime.utcnow() print(v3) # 输出 2025-06-10 09:46:05.642171 2025-06-10 08:46:05.642171+07:00 2025-06-10 01:46:05.642171# datetime 类型, 很方便的实现时间的加减 from datetime import datetime, timedelta # 本地时间 v1 = datetime.now() print(v1) v2 = v1 + timedelta(days=7, hours=19) print(v2) # 输出 2025-06-10 09:49:59.578464 2025-06-18 04:49:59.578464# datetime 类型时间 和字符串 时间之间的相互转换 # datetime -> 字符串类型 from datetime import datetime v1 = datetime.now() print(v1) v2 = v1.strftime("%Y-%m-%d %H:%M:%S") print(v2, type(v2)) # 输出 2025-06-10 09:56:30.964154 2025-06-10 09:56:30 <class 'str'> # 字符串时间 -> datetime 类型时间 from datetime import datetime v1 = "2025-6-10" v2 = datetime.strptime(v1, "%Y-%m-%d") print(v2, type(v2)) # 输出 2025-06-10 00:00:00 <class 'datetime.datetime'> -
ini 格式
mysql 的配置文件是这种格式的
[mysqld] # 节点 mpx=000 [redis] ooo=daas [mongodb] qwqe=qewqw# 使用 configparser 模块读取 ini 结果文件中的数据 import configparser parser = configparser.ConfigParser() parser.read("my.ini", encoding="utf-8") data_list = parser.sections() print(data_list) # 输出 ['mysqld', 'redis', 'mongodb'] print(parser.items("mysqld")) # [('mpx', '000')] v3 = parser.get("mysqld", 'mpx') # 000 # 内存中删除 parser.remove_option("mysqld", 'mpx') # 把删除操作后的数据保存到制定 文件中 parser.write(open('my.ini', encoding='utf-8', mode='w')) # 内存中删除节点 parser.remove_section("redis") parser.write(open("my.ini", encoding='utf-8', mode='w')) # 设置 将 mongodb 下的 qwqe 设置成xfsf, 不存在时添加, 存在时修改 parser.set("mongodb", "qwqe", 'xfsf') # 添加节点 parser.add_section("group")
-
-
正则表达式
-
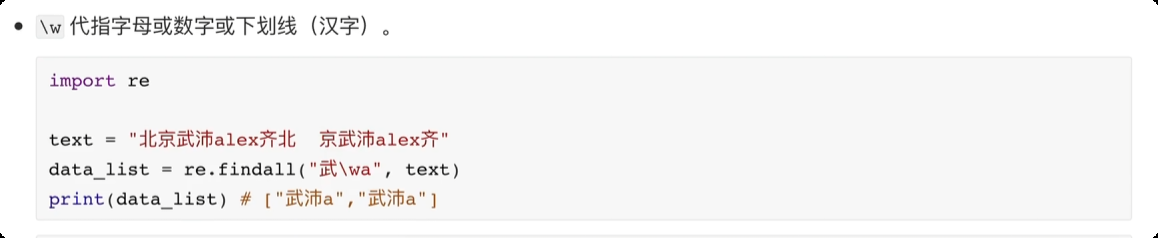
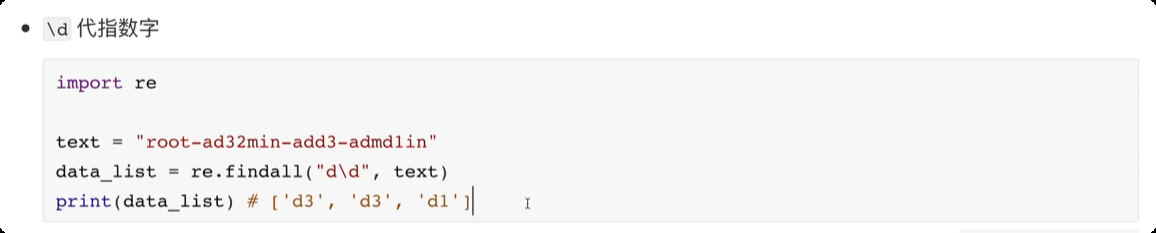
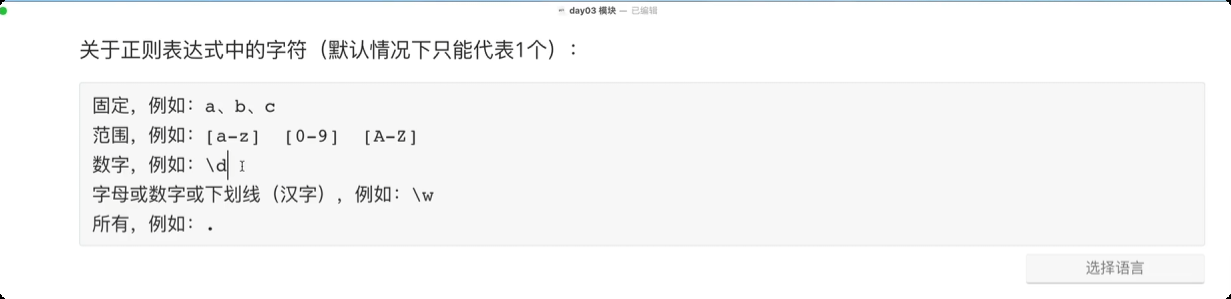
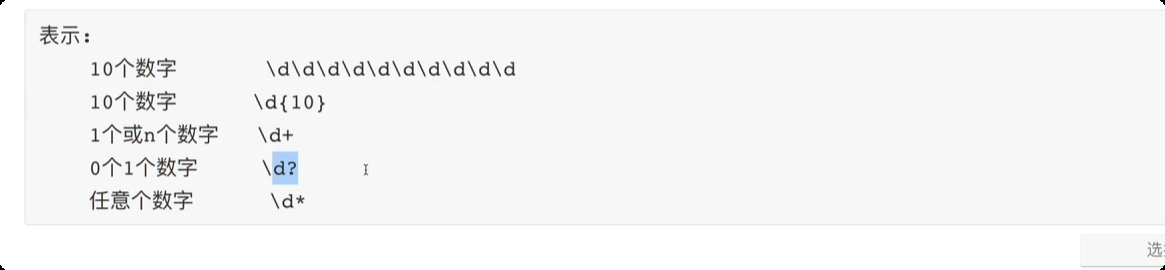
正则表达式
![image-20250610221624543]()
![image-20250610222012588]()
![image-20250610222033981]()
![image-20250610222158584]()
![image-20250610222352838]()
![image-20250610222605124]()
![image-20250610222645273]()
![image-20250610222839510]()
![image-20250610223038578]()
![image-20250610223356954]()
![image-20250610223445795]()
![image-20250610223545074]()
![image-20250610223635132]()
![image-20250610223929851]()
匹配次数的贪婪匹配和非贪婪匹配import re text = "raoooadsadaso" # + 匹配 1 次或更多次, 默认贪婪匹配,尽可能匹配多一些 data_list = re.findall(r"r.+o", text) print(data_list) # ['raoooadsadaso'] # 在 + 号 后面添加 ? 将贪婪匹配转化成非贪婪匹配 data_list1 = re.findall(r"r.+?o", text) print(data_list1) # ['rao']![image-20250610224223277]()
![image-20250610224518727]()
![image-20250610224827710]()
![image-20250610224916887]()
![image-20250610225037742]()
![image-20250610225245293]()
![image-20250610225358354]()
![image-20250610225440009]()
![image-20250610225645642]()
![image-20250610225844475]()
![image-20250610225906986]()
-
re 模块
![image-20250610230414133]()
![image-20250610230913163]()
-




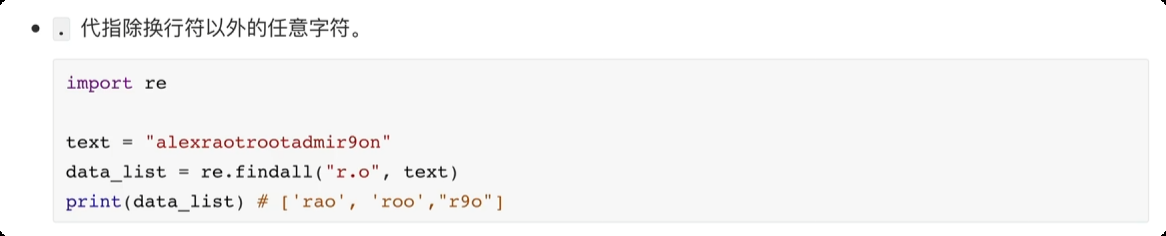


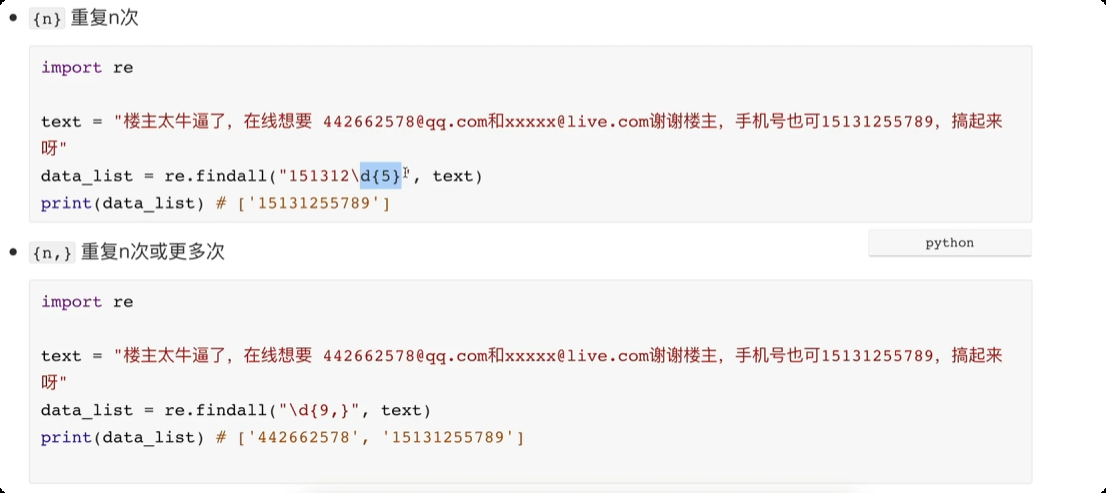
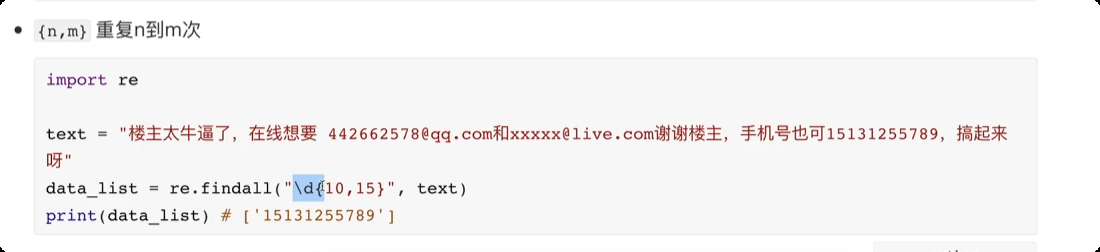









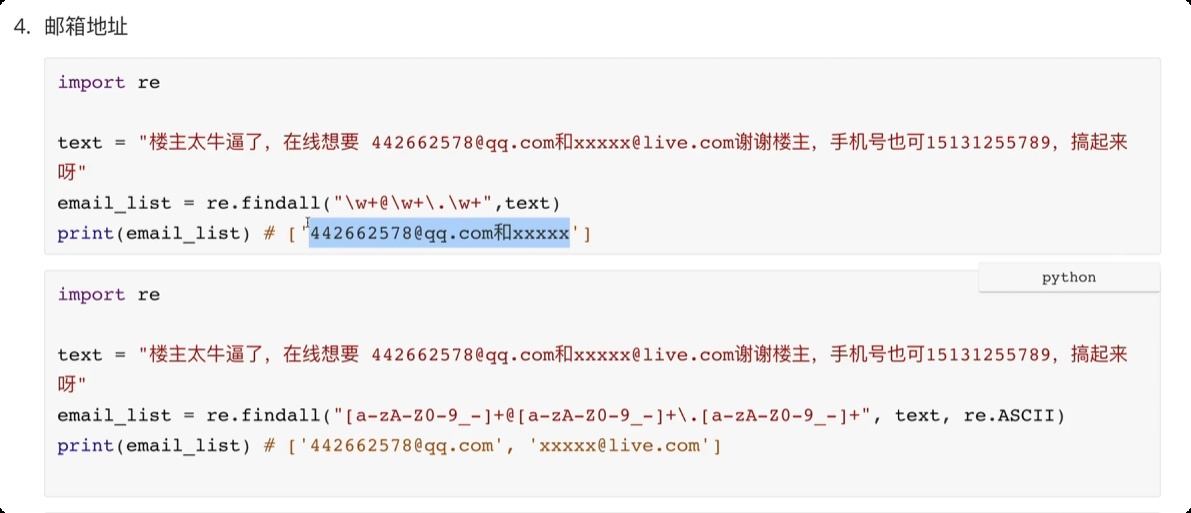

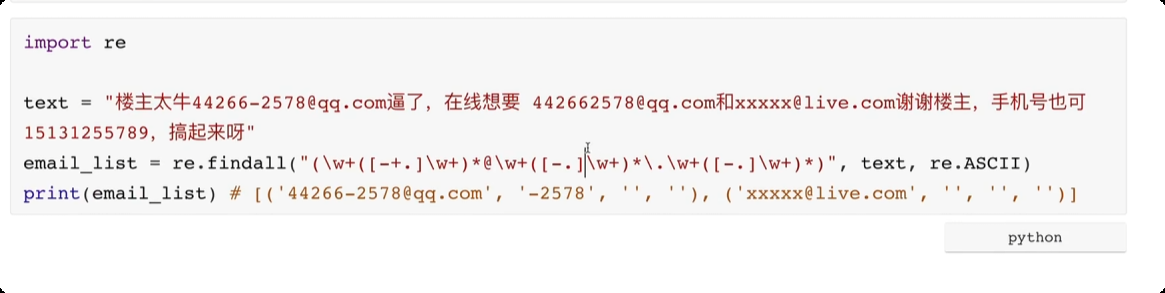

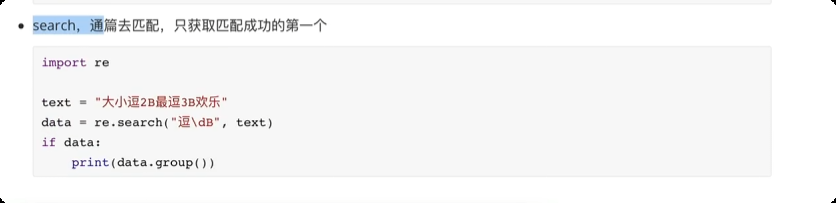

day04
面向对象
编程方式:
-
面向过程编程,按照功能从上到下逐一去实现。
-
函数式编程,功能拆分, 名字代指一部分代码。
-
面向对象编程。
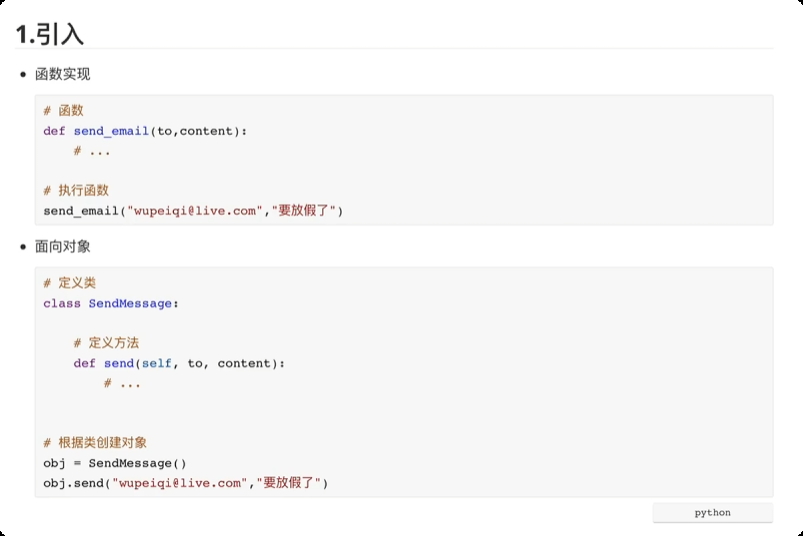
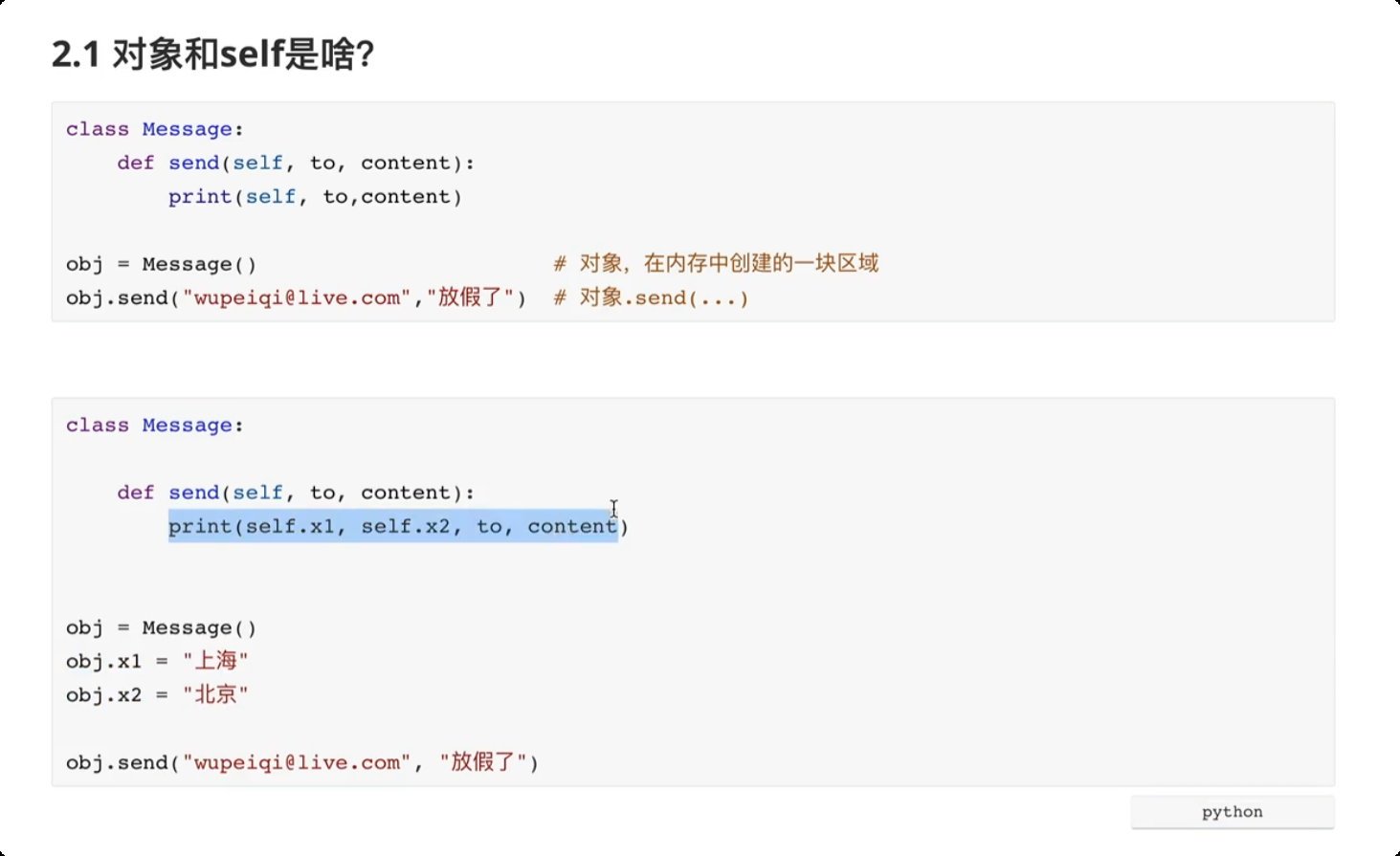
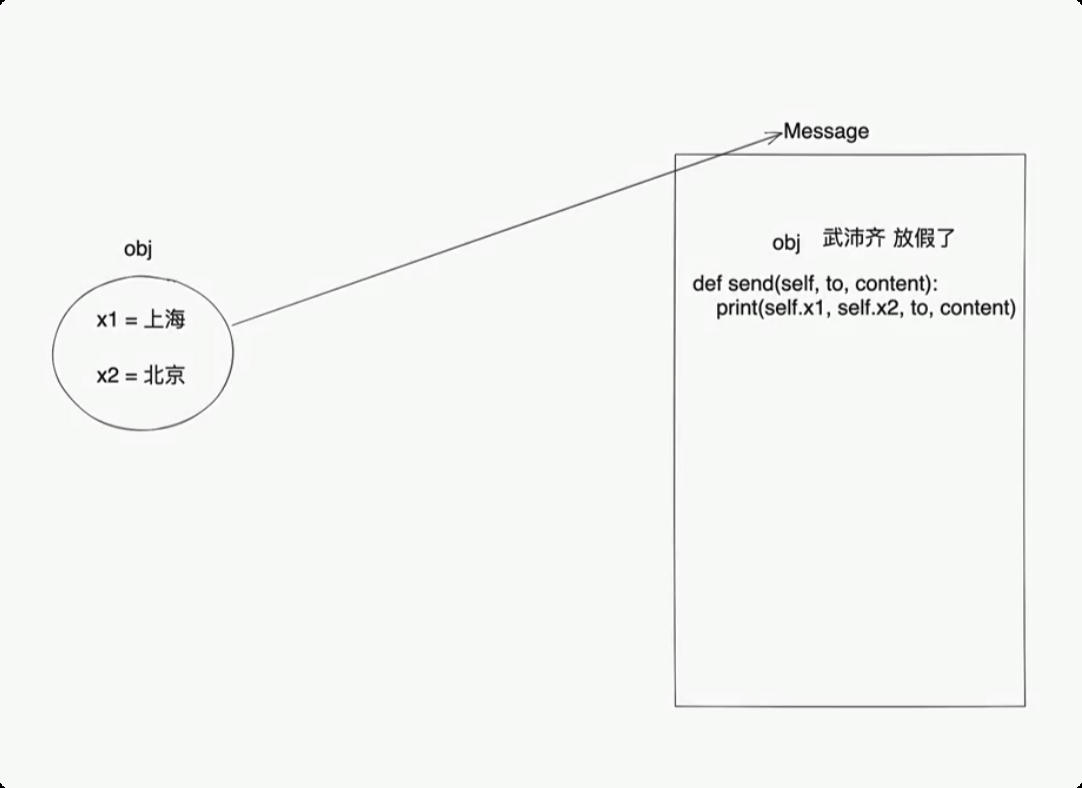

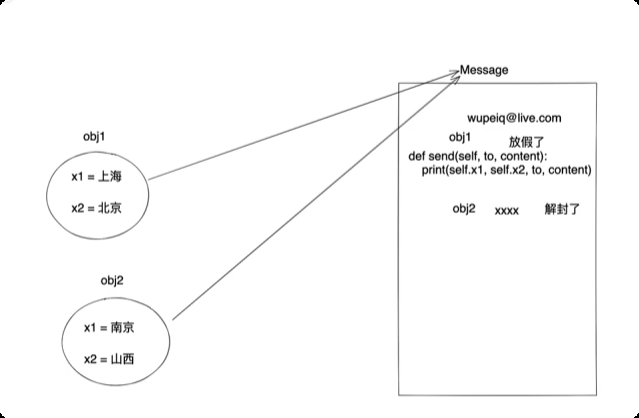
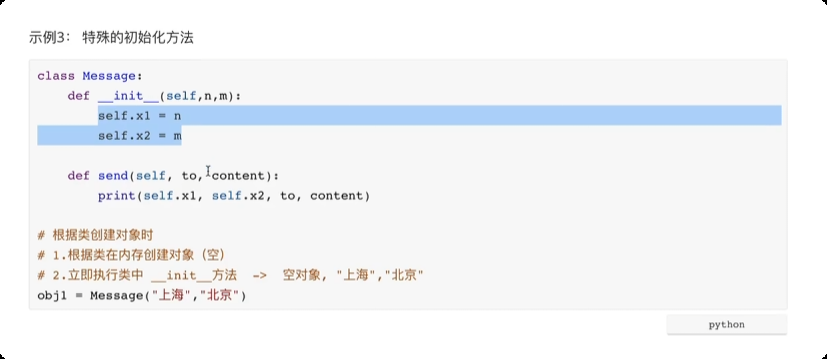
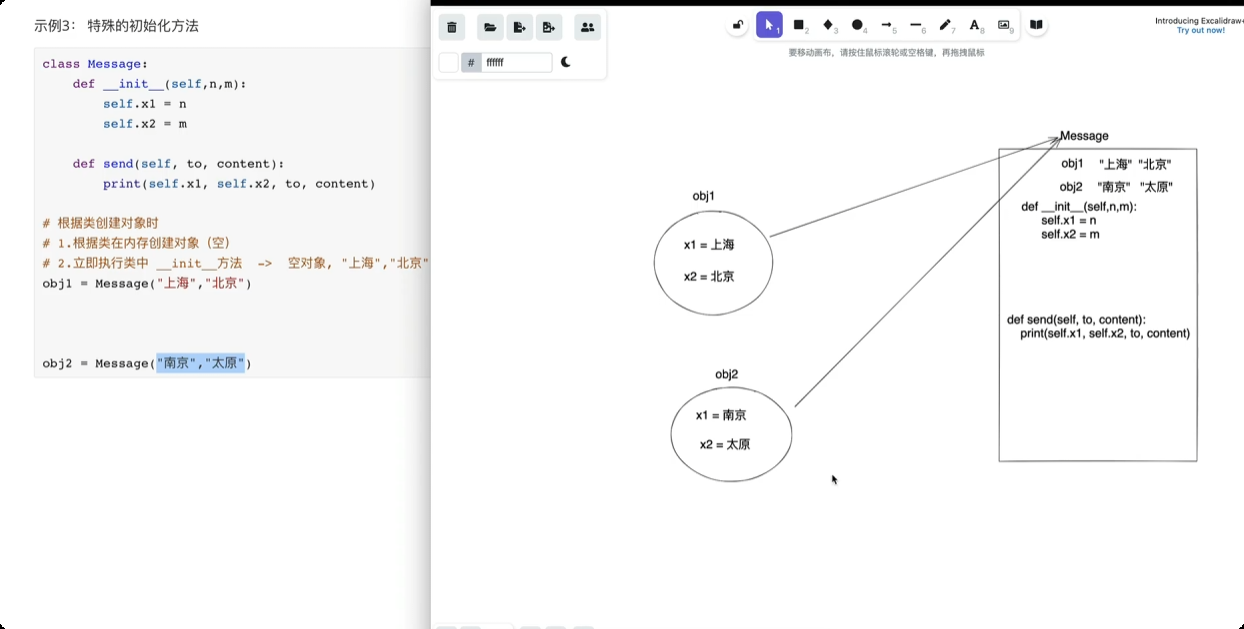




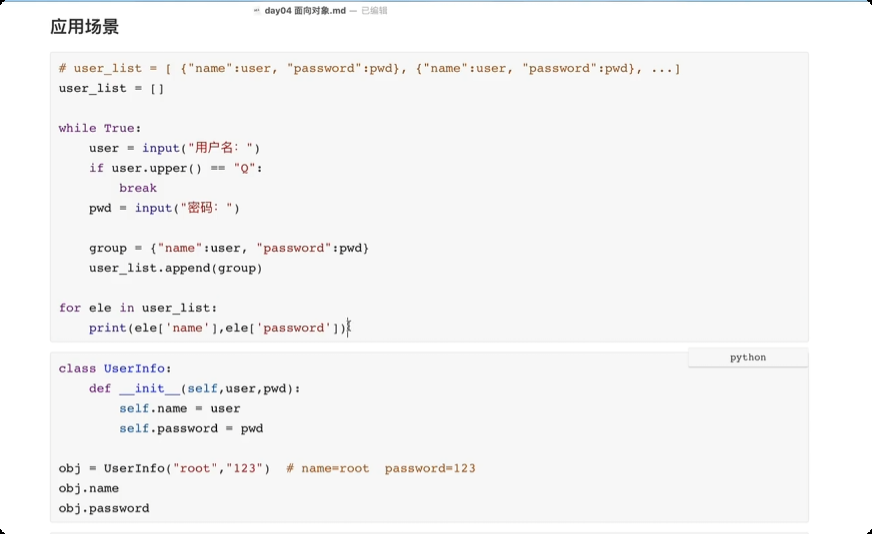

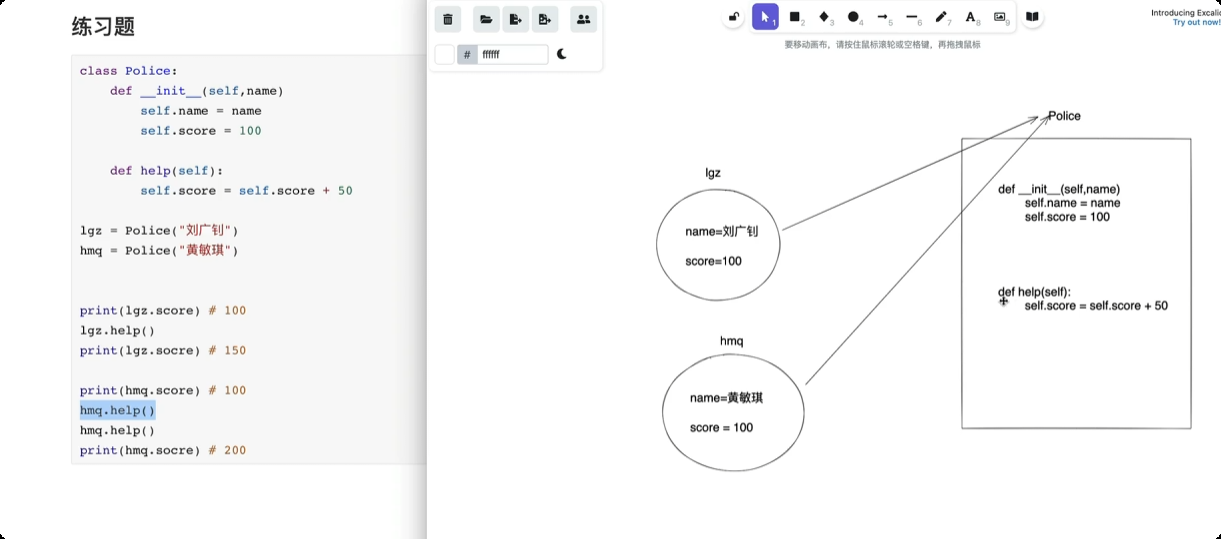
面向对象三大特性
-
封装
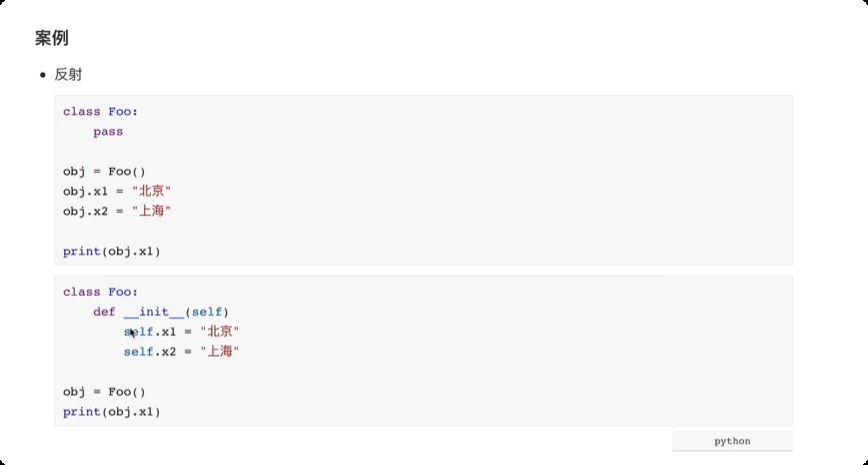
封装, 将数据封装到一个对象中, 后期再去对象中获取已封装的数据。
class UserInfo: def __init(self, user, pwd): self.name = user self.password = pwd obj = UserInfo("root", "123") obj.name obj.password![image-20250611163931737]()
-
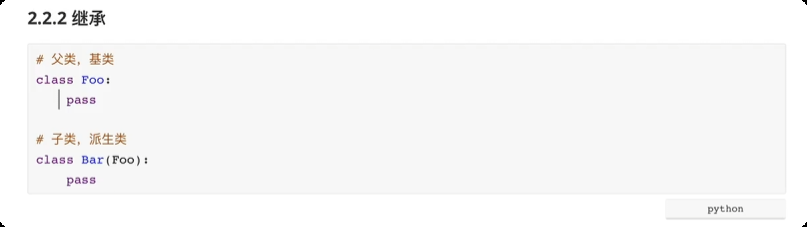
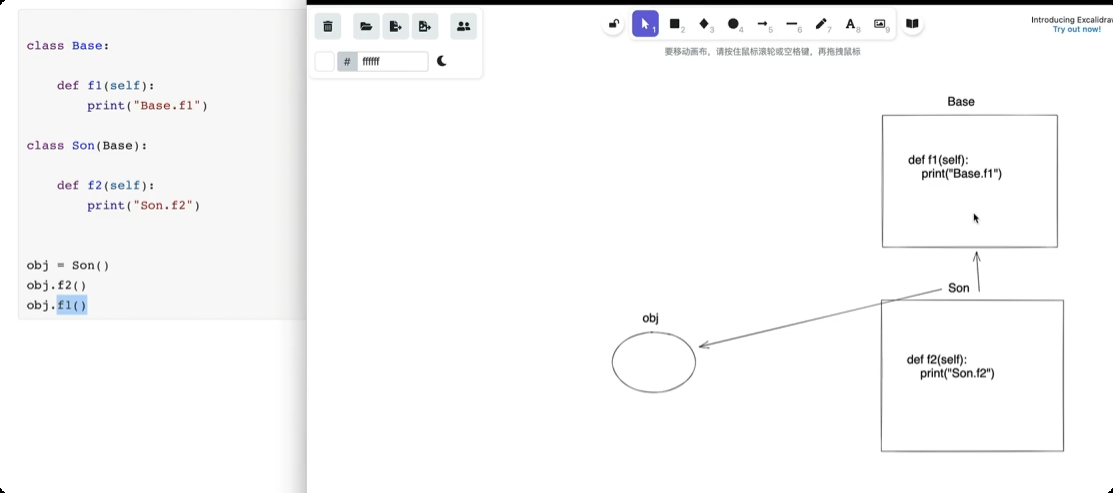
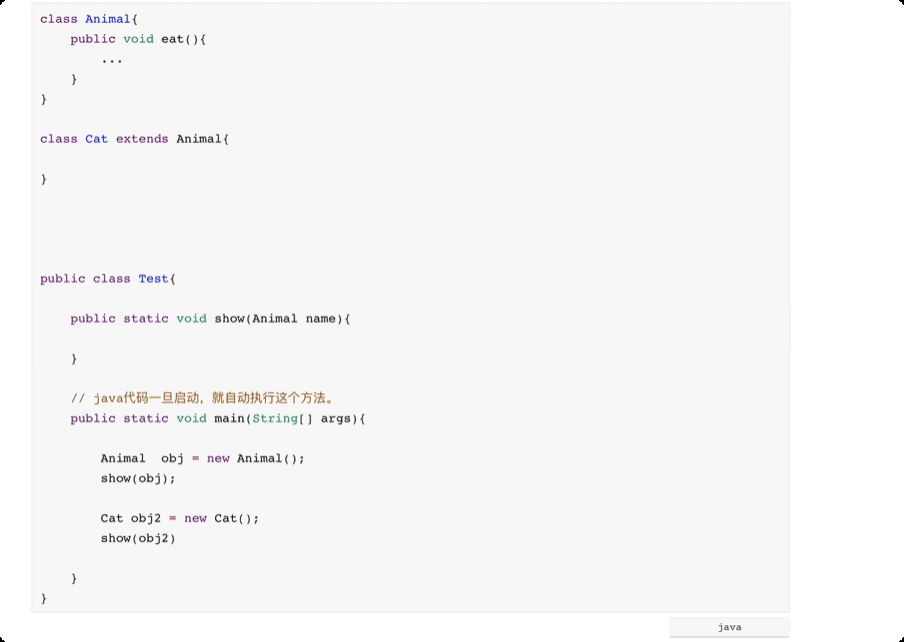
继承
![image-20250611164134971]()
![image-20250611164352590]()
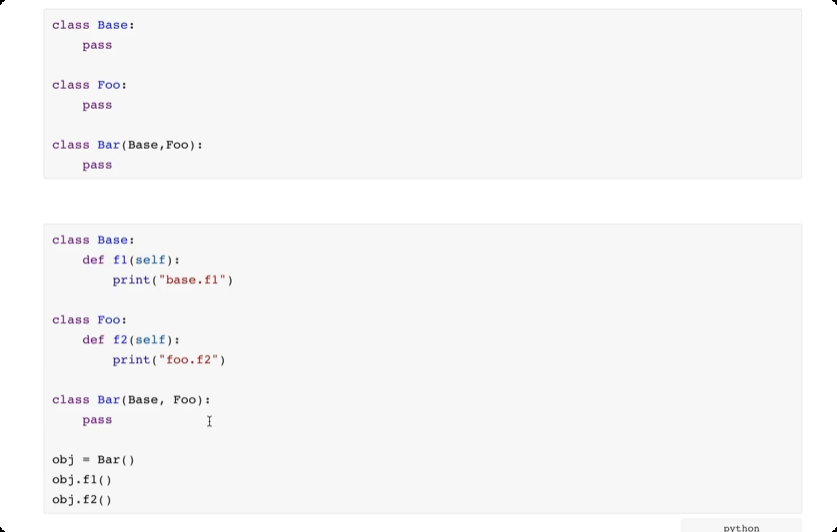
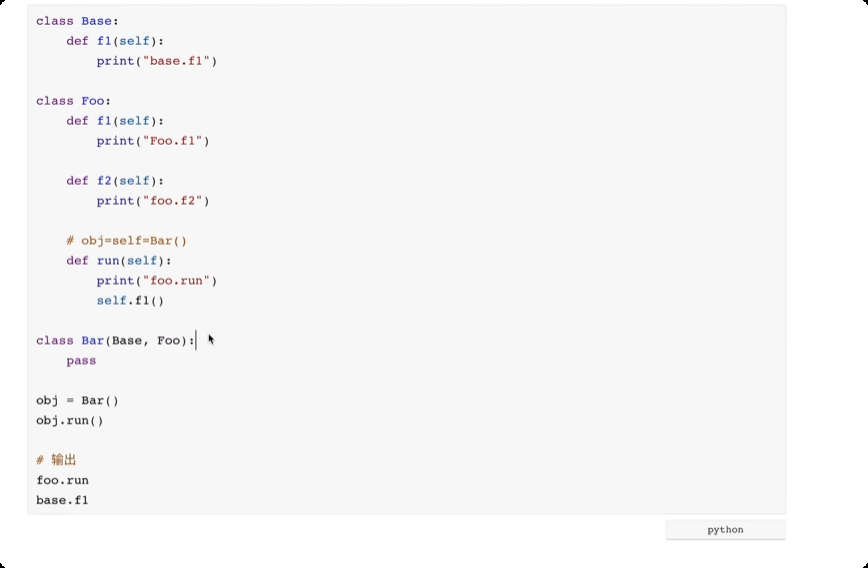
多继承
![image-20250611164654433]()
![image-20250611165012298]()
![image-20250611165254680]()
![image-20250611165411663]()
![image-20250611165607704]()
![image-20250611165740287]()
![image-20250611170204106]()
![image-20250611170307216]()
![image-20250611170340986]()
多继承,一个类可以继承多个类。寻找方法的时候,如果自己没有,按照顺序从左到右每个类中寻找相关的方法。
![image-20250611170928016]()
![image-20250611171108513]()
-
多态
![image-20250611171335323]()
![image-20250611171606072]()
![image-20250611172025615]()

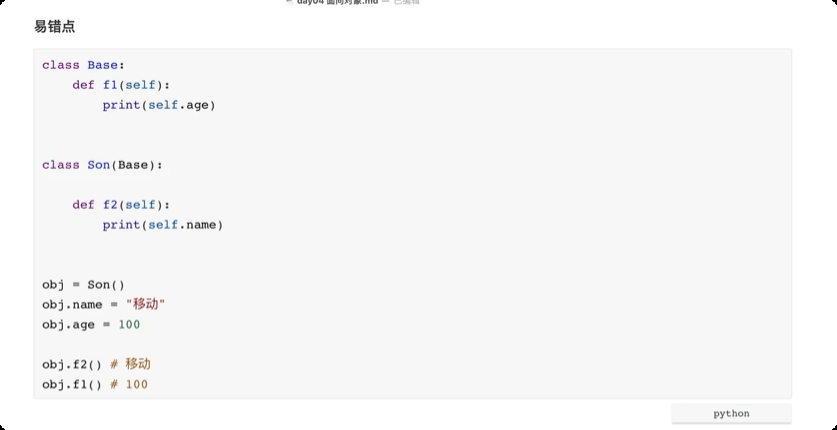


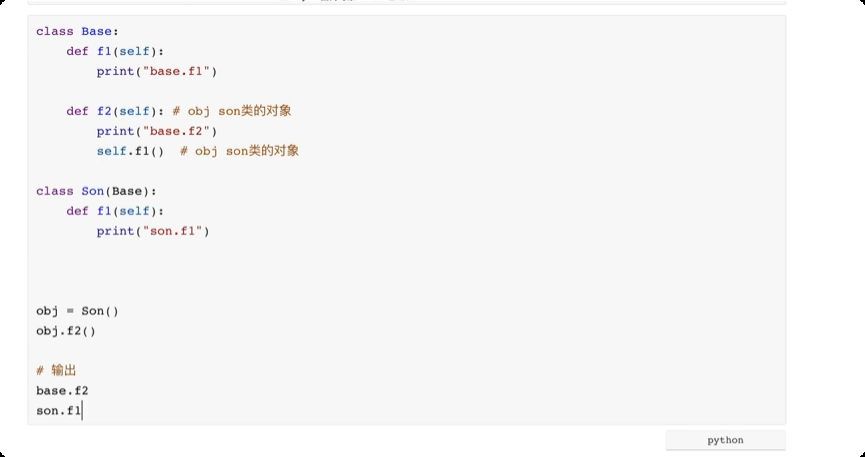


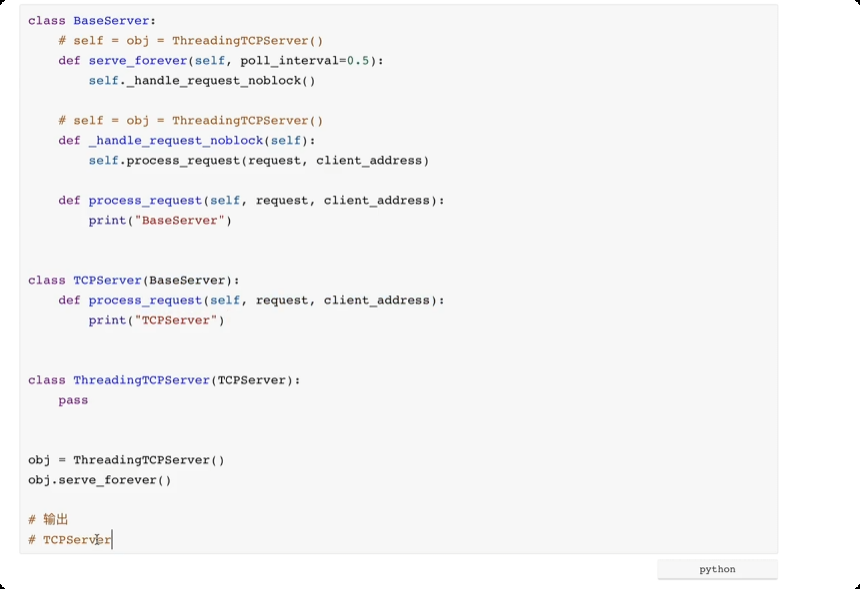
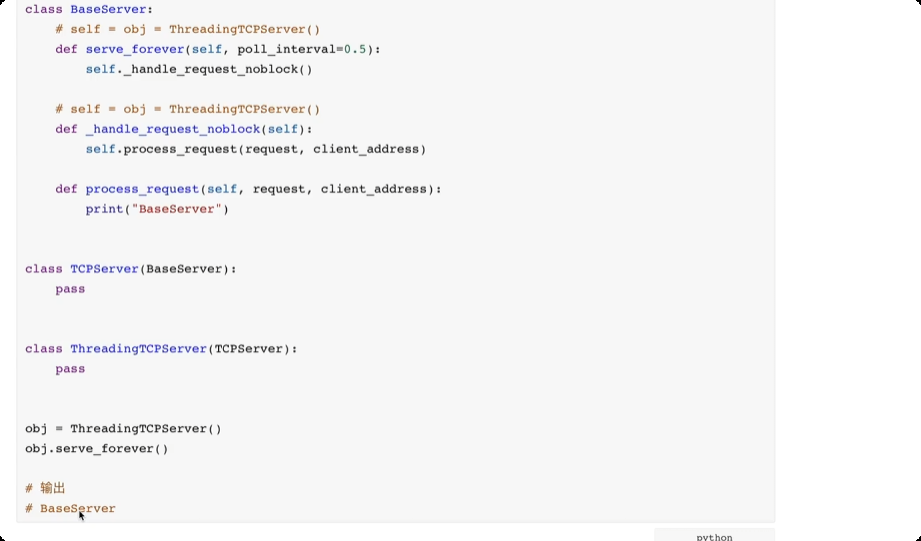

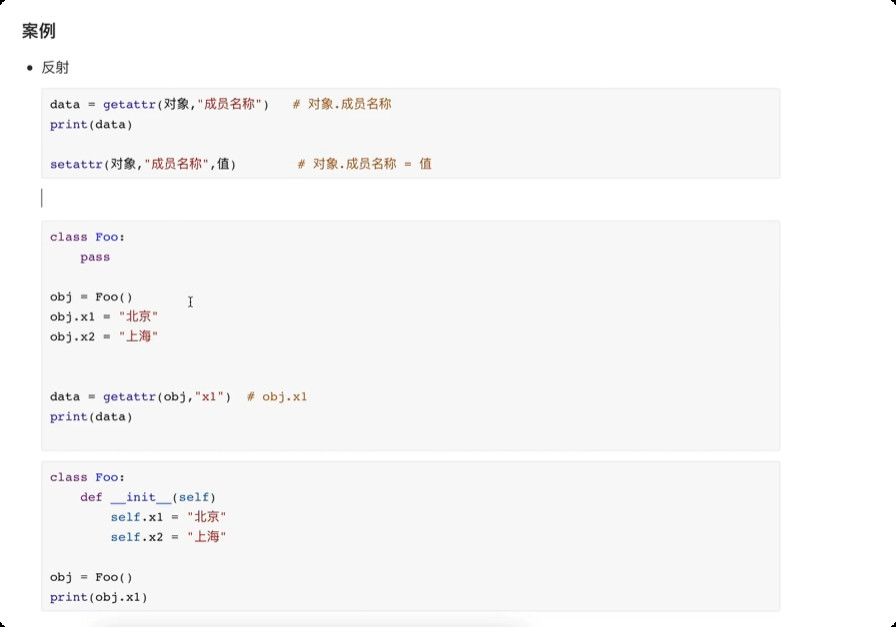
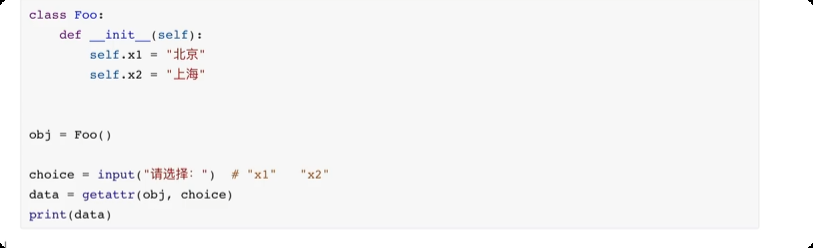

面向对象进阶
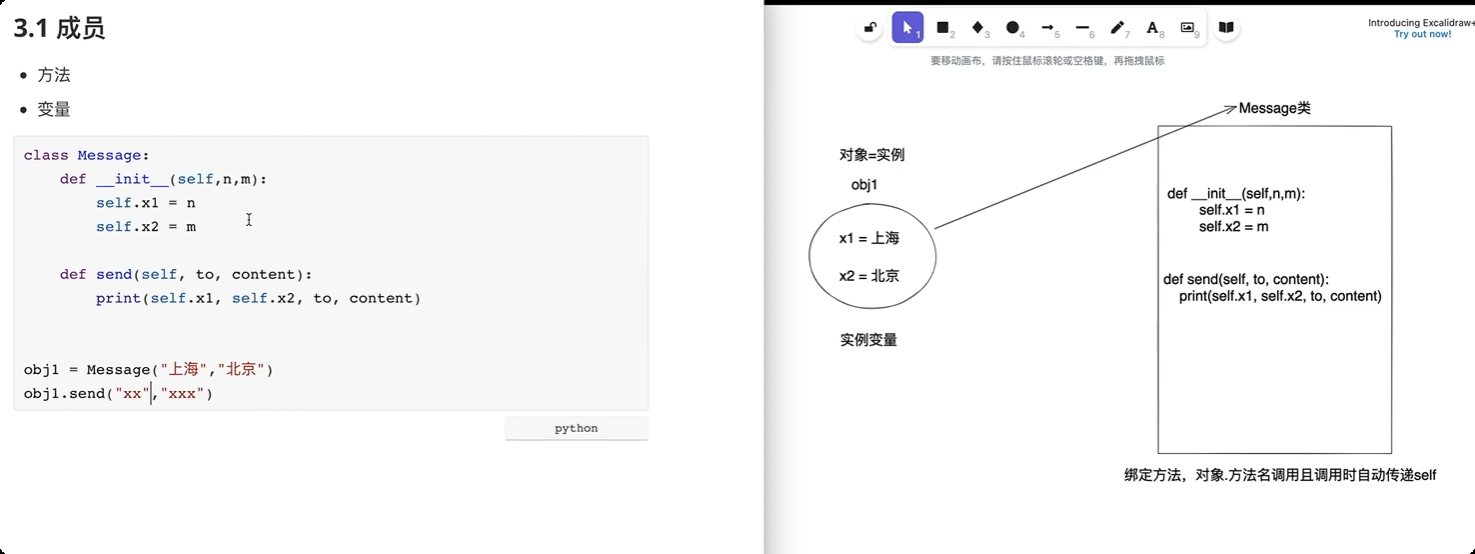
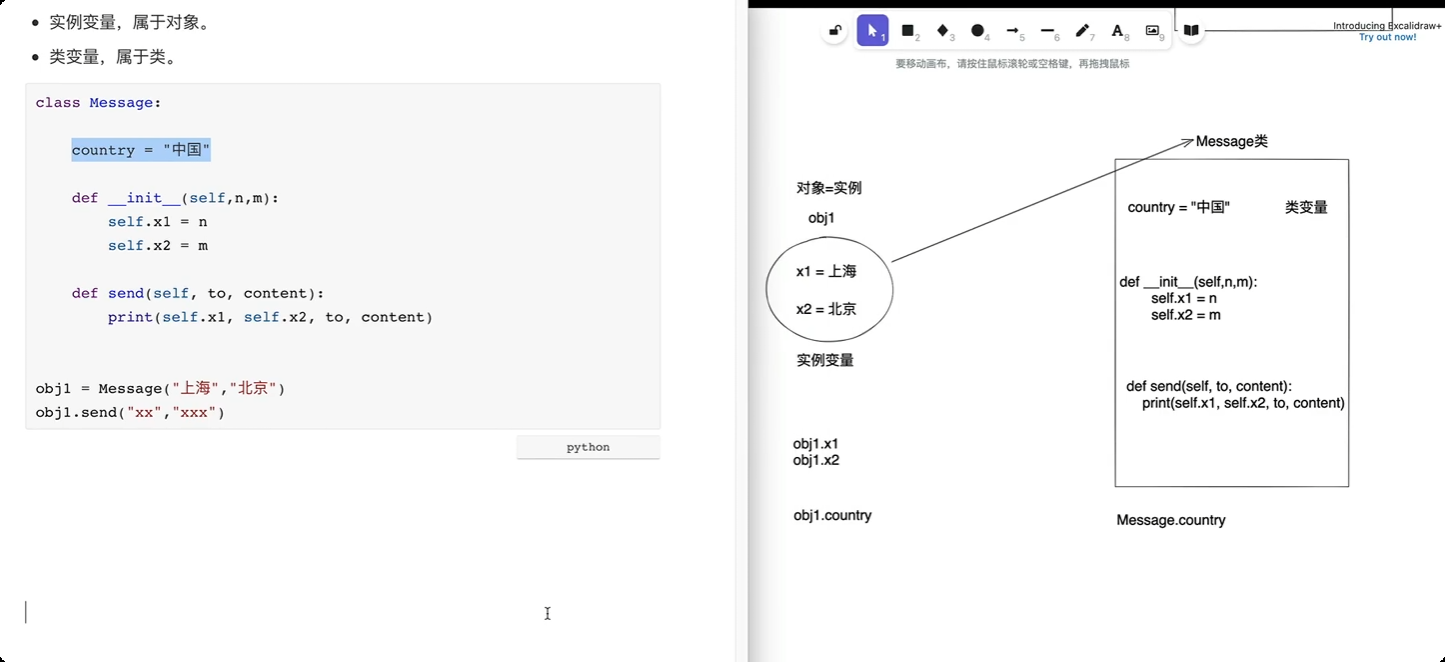
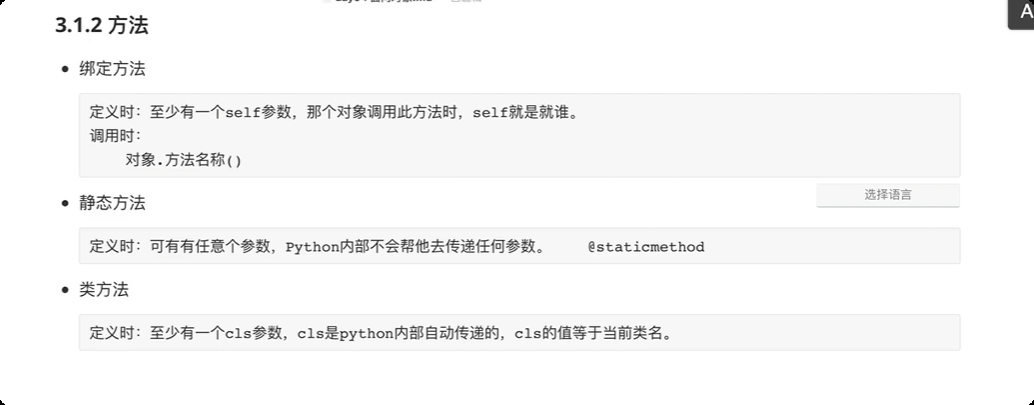
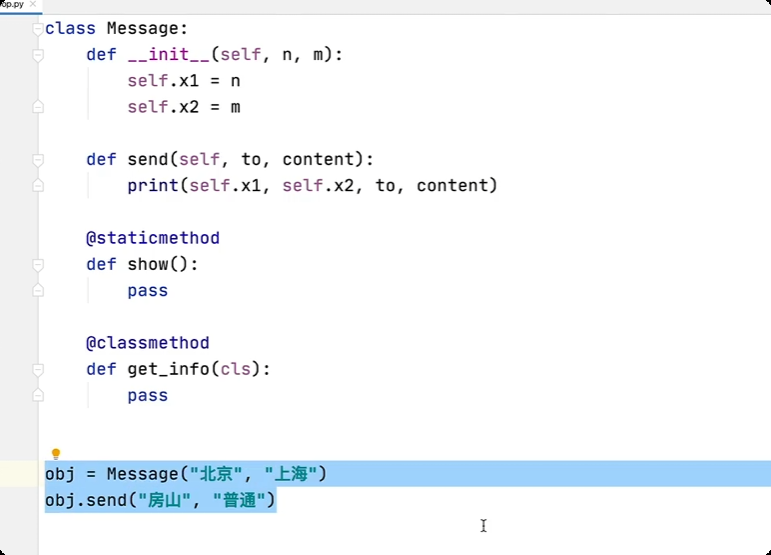
绑定方法

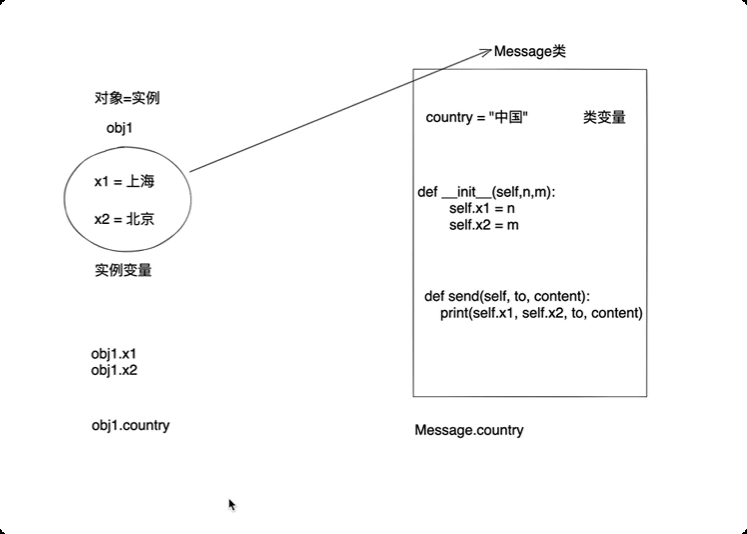
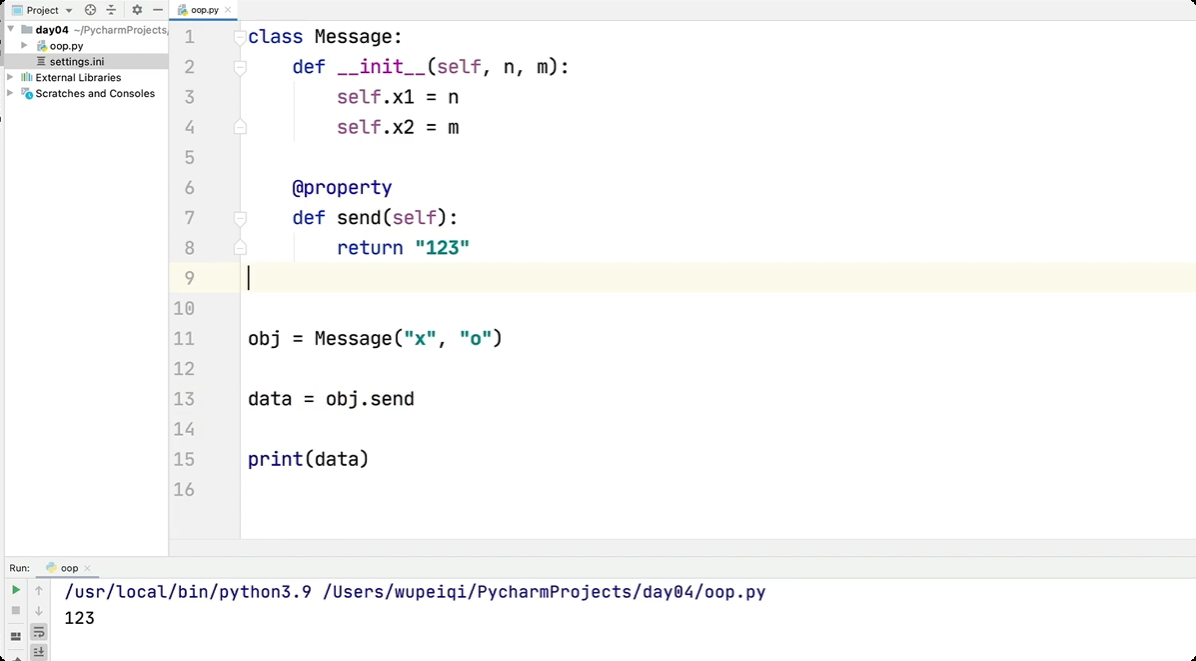
属性
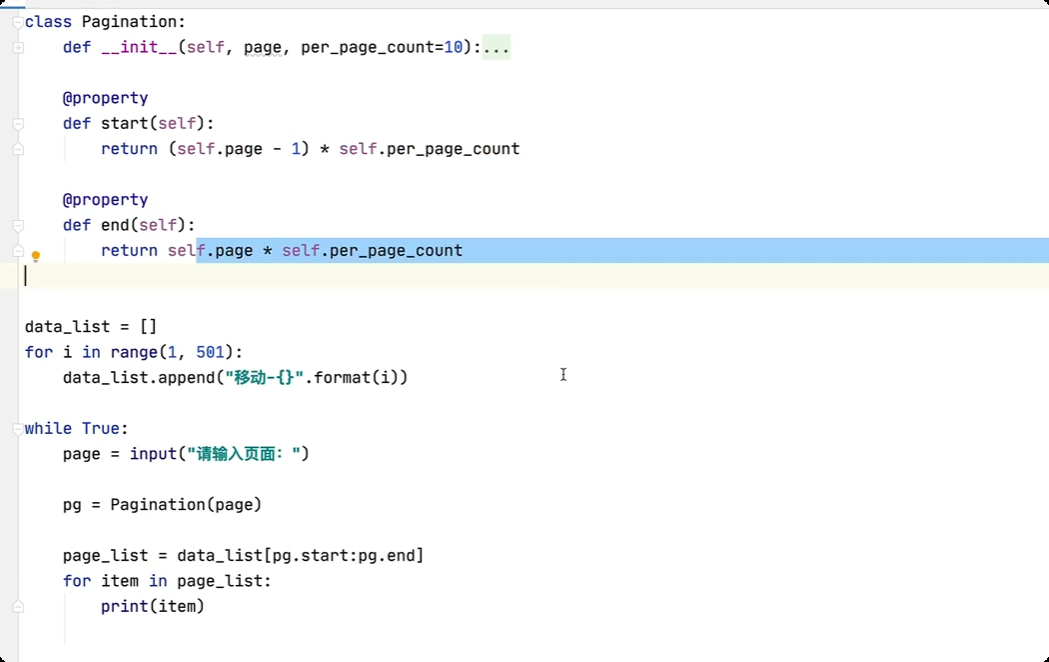
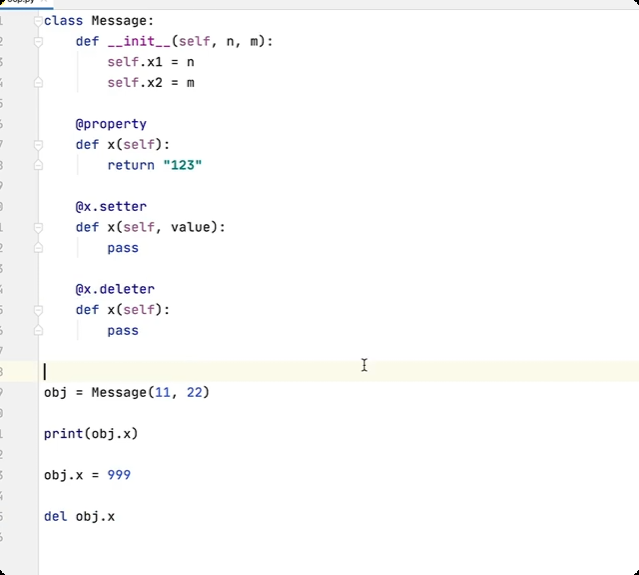
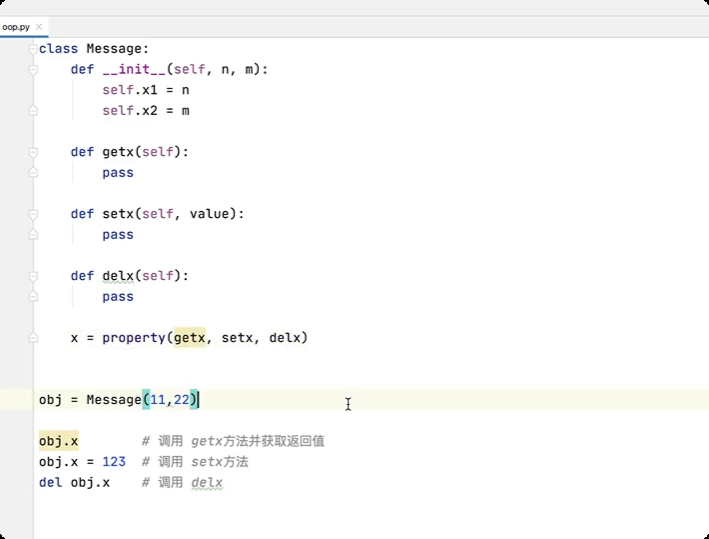
类的嵌套
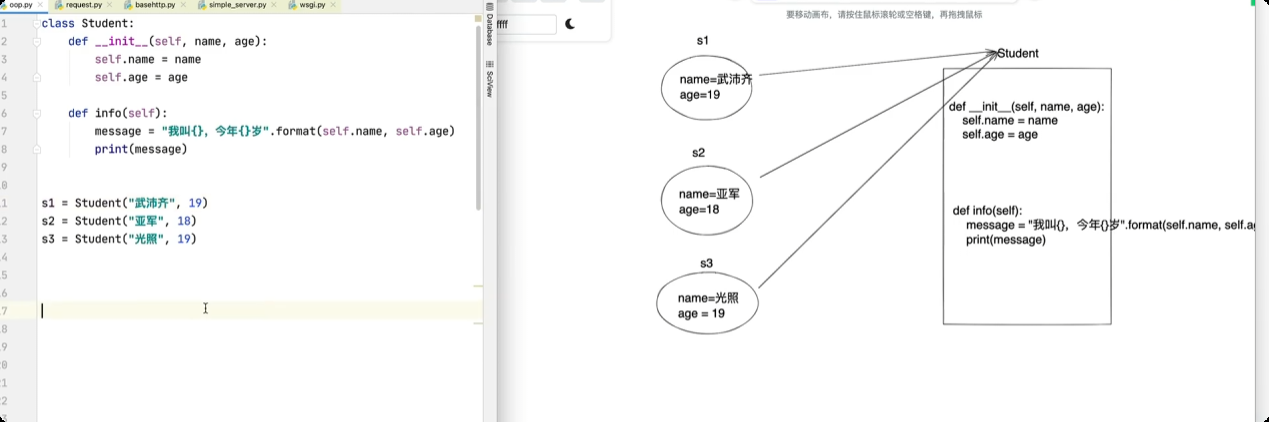
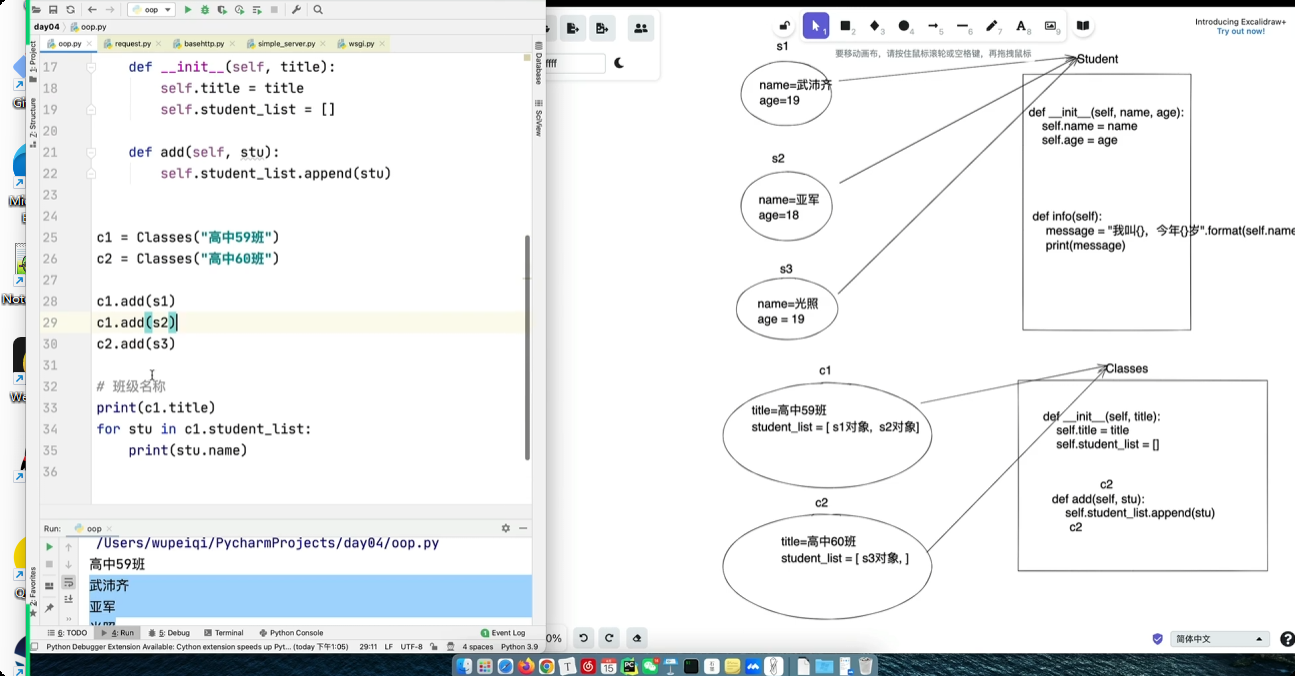
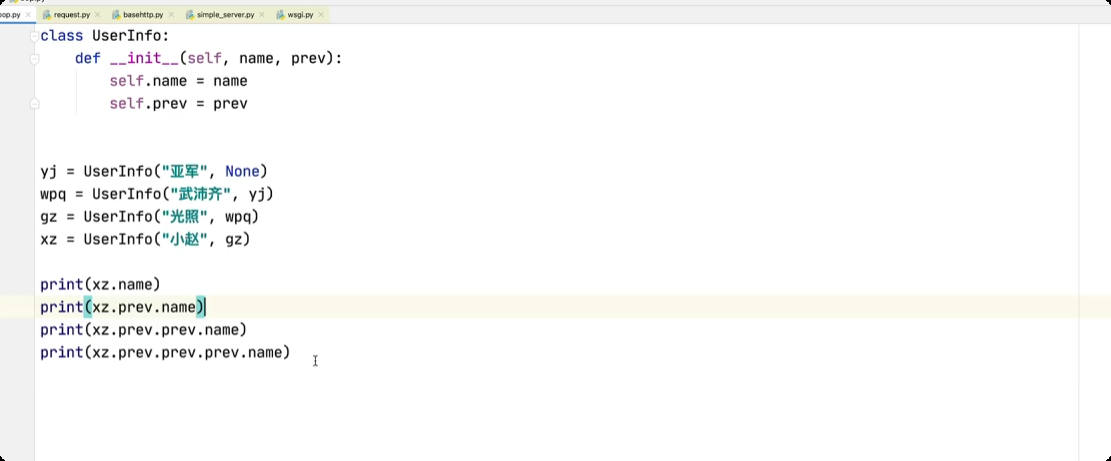
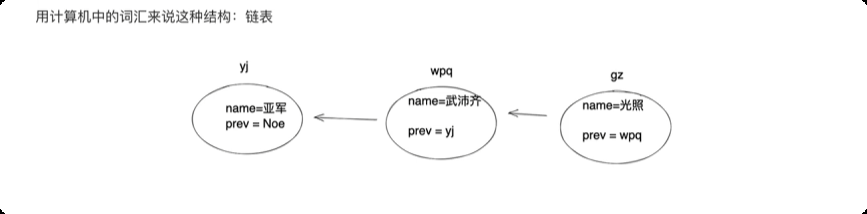
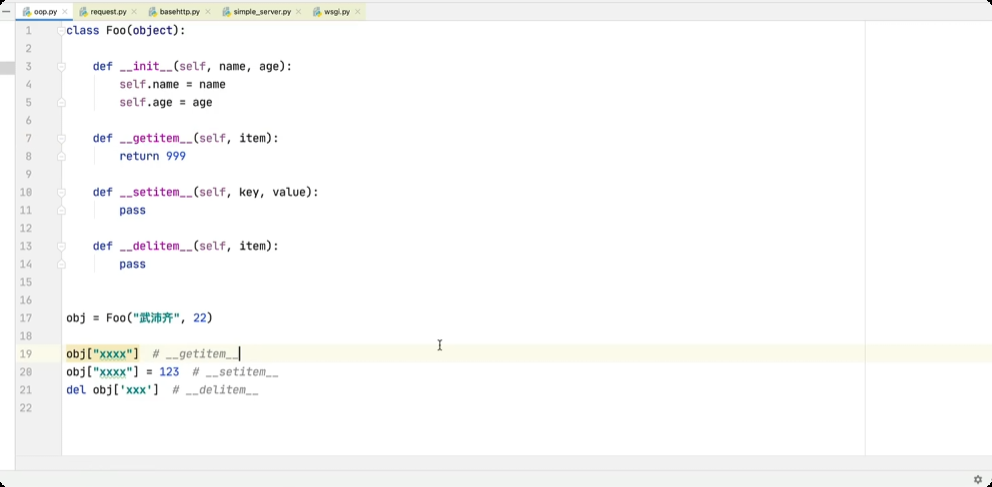
面向对象中的特殊成员
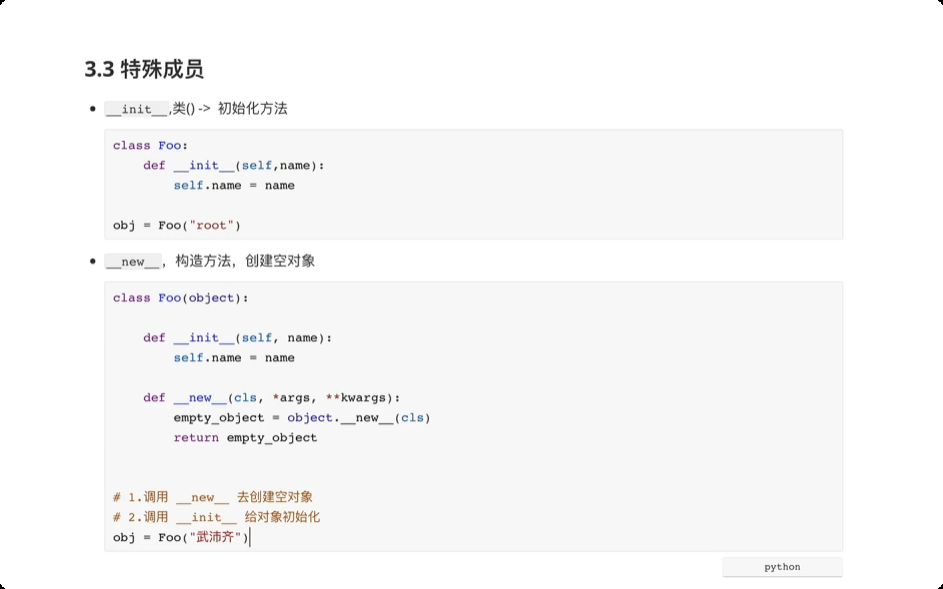
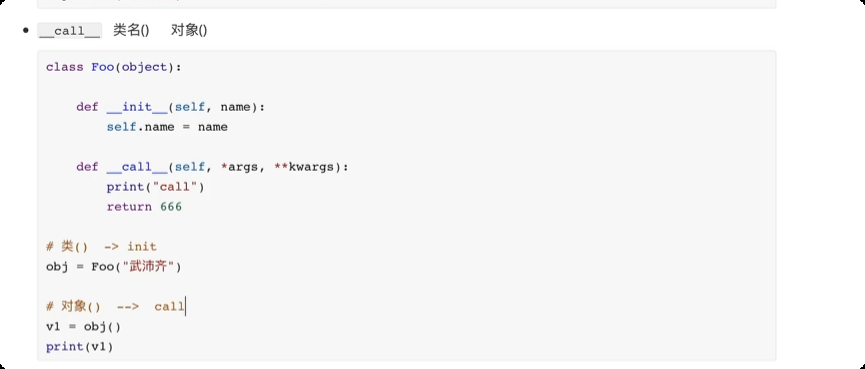
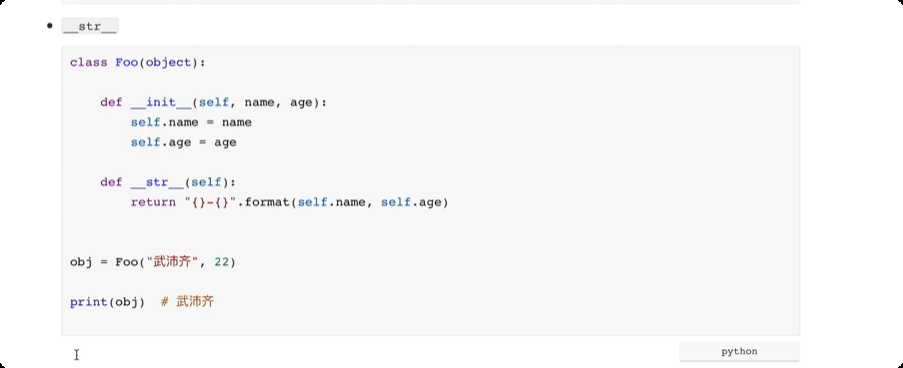

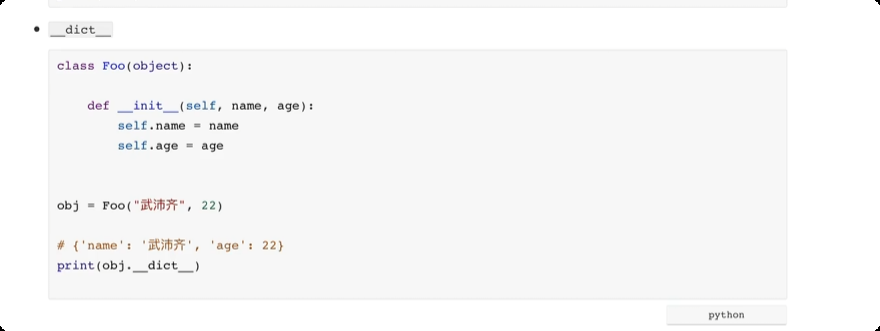
# __getitem__, __setitem__, __delitem__ 方法
# __add__ 对象之间的相加
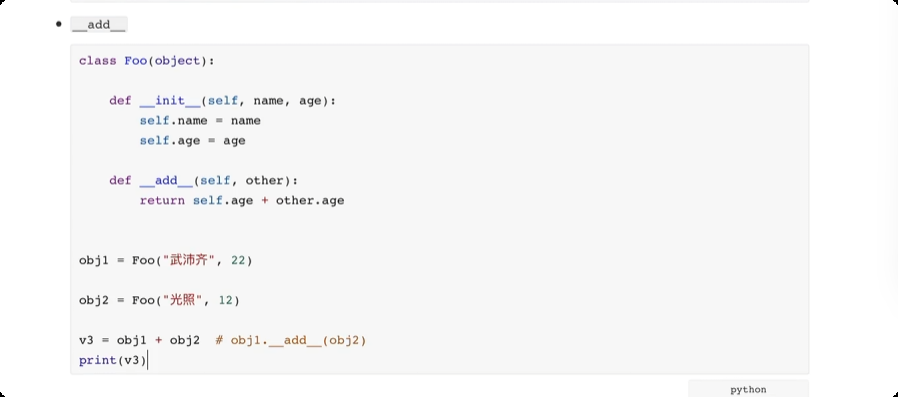
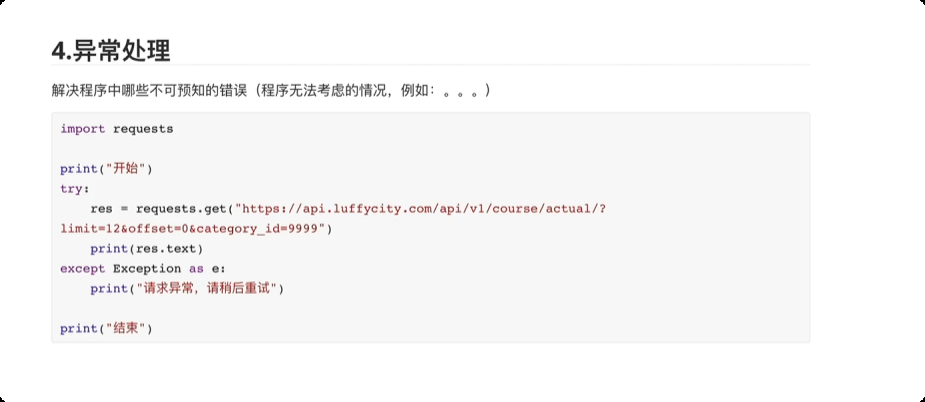
异常处理
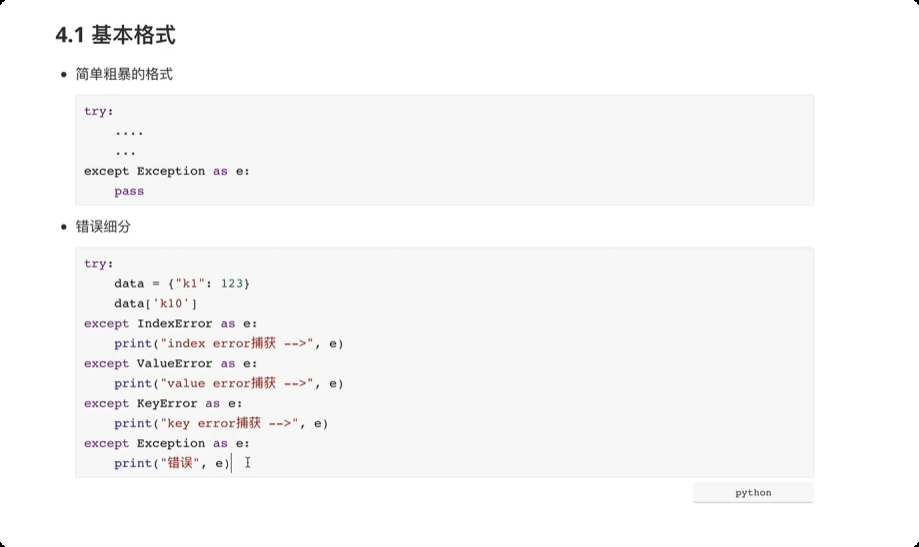
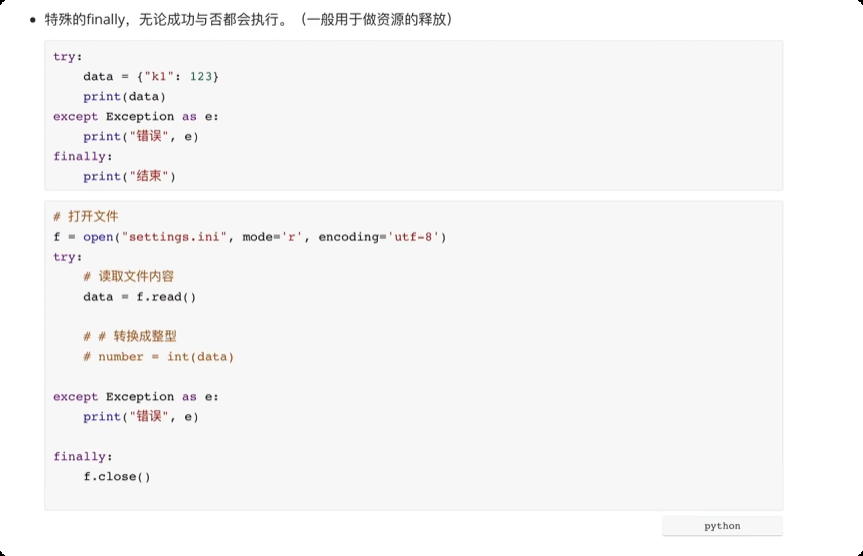
解决程序中那些不可预知的错误。
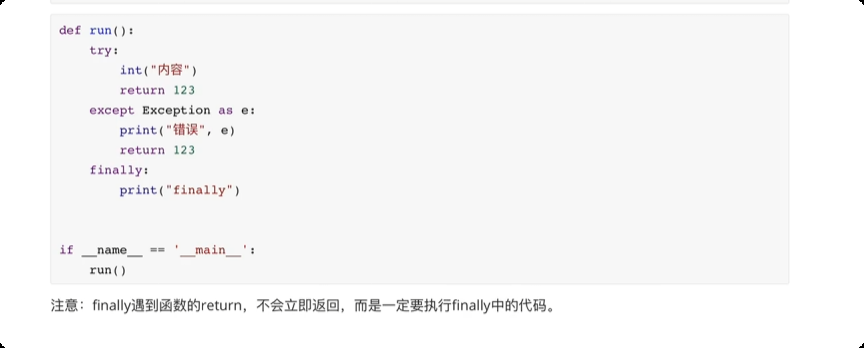
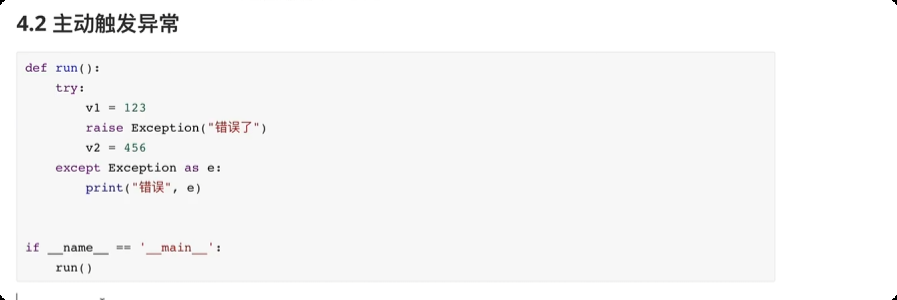
主动触发异常

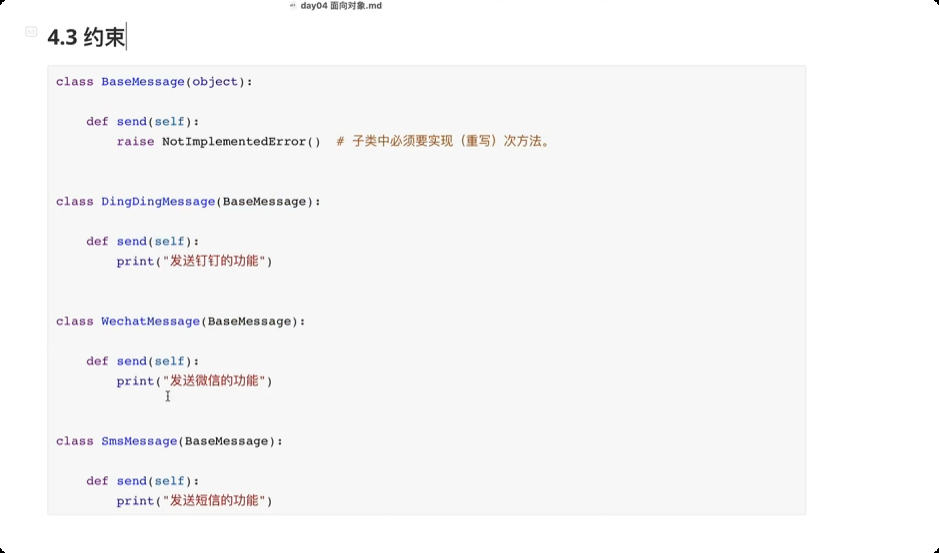
约束
继承父类的子类中必须实现某个方法的约束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号