Dive into deeplearning(d2l) 学习笔记
Dive into deeplearning (d2l)学习笔记
第三章 线性模型
Summary
1.对于线性模型,可以用点积的形式来简洁的表达 \(\hat{\mathrm {y}}= \mathrm {X}\mathrm{w} ^{T} + b \),其本质是对输入feature的仿射变换
2.对于线性模型优劣程度的度量(线性模型的损失函数(loss function) \(L(w,b)=\frac{1}{n} \sum_{i=1}^{n}\frac{1}{2} \sqrt{\mathrm {X}\mathrm{w} ^{T}-y^{(i)} } \)
3.对于线性模型而言其最优解存在解析解,但对于绝大多数深度学习问题并非如此
4.小批量随机梯度下降(minibathc stochastic gradient descent)的数学表达式是:\( (\mathrm{w} ,b) \gets (\mathrm{w} ,b)-\frac{\eta }{\left | \mathfrak{B } \right | } \partial _{(\mathrm{w} ,b)}l^{i} (\mathrm{w } ,b) \),其中\(\eta \)为学习率 ,\( \left |\mathfrak{ B } \right | \)为每个minibatch中的样本数量
5.类似学习率或batch size这样可以调整但不在训练过程中被更新的参数被称为超参数(hyperparameter)
6.当label间没有自然顺序时,可采用独热编码(one-hot encoding)
7.softmax层通常为了解决分类问题,因此需要保证1.输出为正2.输出概率和为1 ,因此 做变换 \( \mathrm{Y} = softmax(\mathrm{O} \) 其中 \( \hat y_{j} = \frac{exp (o_{j})}{ {\textstyle \sum_{k}^{}}exp( o_{k})} \) , 最终softmax层的向量形式为$$\mathrm{O} = \mathrm{XW} + b$$ $$\mathrm{Y = softmax(O)} $$
question
1.Q: 3.1.1.1.一节中提到 ” 即使确信特征与标签的潜在关系是线性的, 我们也会加入一个噪声项来考虑观测误差带来的影响。“ 噪声项的引入体现在模型的什么地方?
A:引入噪声后的线性模型为\(\hat{\mathrm {y}}= \mathrm {X}\mathrm{w} ^{T} + b + \epsilon \),其中\(\epsilon \in \mathcal{N} \)
2.Q:假设数据不符合独立同分布对训练会产生什么影响
A:这取决于情况 4.4中讨论了这一问题
第四章 多层感知机
Summary
1.如果不引入激活函数\( \sigma \) ,多层感知机将变得毫无益处,因为单层的全连接层已经可以表达所有的仿射函数,因此为了提高模型非线性能力,引入激活函数\( \sigma \)
2.三个激活函数Relu:\( f(x)=max(0,x) \) 可以减轻梯度消失的问题
Sigmoid:\( f(x)=\frac{1}{1+e^{-x}} \)
tanh:\( f(x)=\frac{1-e^{-2x} }{1+e^{-2x} } \)
3.正则化(regularization)的方式可以对抗过拟合(over fitting)
4.k折交叉验证可以有效地解决在数据量较小时划分数据集的问题(将数据分为K个子集,训练k轮,每次选择k-1个子集作为训练集,剩下的子集选为测试集)
5.过拟合的三种常见原因:1.模型过于复杂(可调整的参数量过大(自由度过大)),2.模型内参数可调整范围过大3.数据量太小
6.权重衰减在损失函数上增加正则项来抑制函数复杂度的增加
7.协变量偏移---->解决方法:训练分类器分类输入属于哪个分布,并乘以权重。、
标签偏移------>解决方法
概念偏移------>利用现有新数据训练模型
d2l附加材料补充
1.收敛定理
2.感知机不能拟合XOR函数
Question
1.Q:"在哲学上,这与波普尔的科学理论的可证伪性标准密切相关: 如果一个理论能拟合数据,且有具体的测试可以用来证明它是错误的,那么它就是好的。 这一点很重要,因为所有的统计估计都是事后归纳。"的意思
2.Q:L2正则化函数描述了函数的复杂程度,但对于模型而言,并非越简单越好,如何保证添加正则化函数的正确性。
3.pytorch dropout何时不进行(似乎要自己设置,尝试结果,没找到可参考资料)
第六章 卷积神经网络
1.一个h * w的输入在经过一 size为n * m ,padding 为 (a,b) 步幅为c d的卷积操作后输出形状为
[(h - n + a + c)/c, (w - m + b + d)/d]
2. 1*1的卷积核的作用在于连接不同通道间的信息
3.池化层的作用:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
第七章 现代神经网络
1.Alexnet:机器提取特征
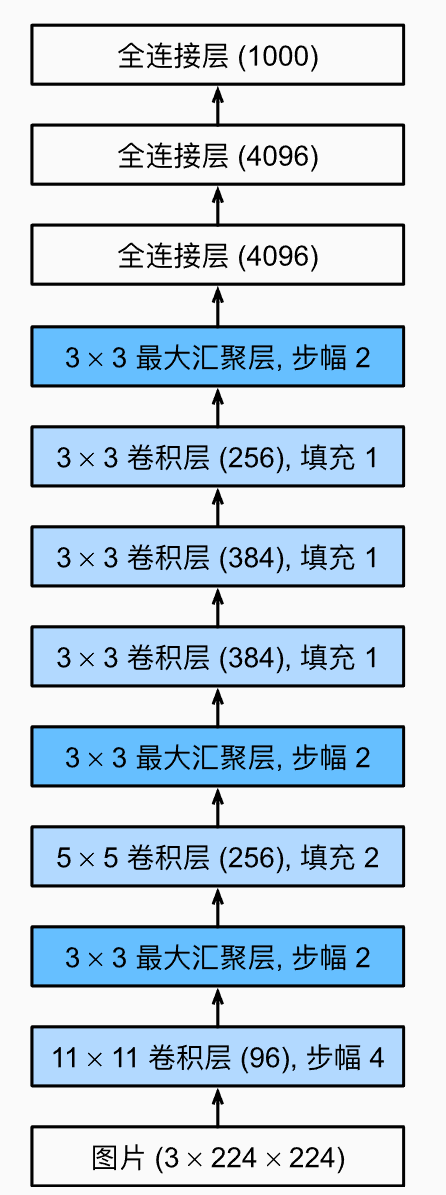
全篇
summary
1.超参数有:隐藏层的大小,epochs, 隐藏层数目, 激活函数, batch-szie, optimizer,
python库
1.enumerate(sequence, [start=0])
给出idx, object
pytorch库
1.torch.cat 拼接两个tensor 参数 torch.cat(tensor , dim)
2.torch.clamp 将输入限制在一个限定范围 参数torch.clamp(input, min, max)
3.torch之中的乘法 torch.mul --> 点乘 ;torch.mm---->矩阵乘法
4.net.state_dict 返回网络各层名称和参数值。
5.torch.save 和 torch.load可以保存/读入单个tensor
6.torch.save(net.state_dict(), 'filename')可以用来保存模型参数
7.net.load_state_dict(torch.load('filename'))可以载入保存在filename中的参数
8.torch.stack将多个tensor沿着新的维度堆叠

 浙公网安备 33010602011771号
浙公网安备 33010602011771号