Pytorch 深度学习实践 学习笔记
Pytorch 深度学习实践学习笔记
本学习笔记基于河北工业大学刘老师发布于b站的《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibilil,欢迎各位讨论并指正我的学习笔记中的错误
目录
第二节 线性模型(Lineat Model)
第三节 梯度下降(Gradient Descent)算法
第四节 反向传播(Back Propagation)
第五节 用Pytorch实现线性回归
第六节 逻辑斯蒂线性回归(Logistic Regression)
第七节 处理多维特征的输入
第八节 加载数据集
第九节 多分类问题
第十节 卷积神经网络(基础篇)
第十一节 卷积神经网络(提高篇)
第二节 线性模型(Linear Model)
问题引入
假设存在一个学生考试成绩与学习时间的数据集,预测其学习4小时将获得的分数(这个问题将在接下来几节中被反复使用)
概念引入
训练集 , 测试集
监督学习:使用具有label的实例调整分类器参数
损失函数(Loss function)
MSE(Mean Square Error): $$\frac{1}{N}\ \sum_{n=1}^{N}(\hat{y_n}-y_n)^2$$
线性模型(Linear Model)
\(\hat{y} = \omega * x + b \)
代码实现
源代码
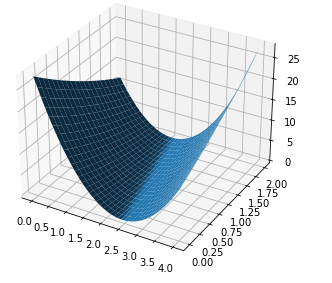
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D x_data=[1.0,2.0,3.0] y_data=[3.0,5.0,7.0] def forward(x): return x * w + b def loss(x,y): y_pred = forward(x) return (y_pred-y)*(y_pred-y) mse_list = [] w_list = np.arange(0.0,4.1,0.1) b_list = np.arange(0.0,2.1,0.1) [w,b]=np.meshgrid(w_list,b_list) l_sum=0 for x_val,y_val,in zip(x_data,y_data): y_pred_val = forward(x_val) loss_val =loss(x_val,y_val) l_sum += loss_val print('Y_hat= ',y_pred_val) fig = plt.figure() ax = Axes3D(fig) ax.plot_surface(w,b,l_sum/3) plt.show()
代码运行结果
第三节 梯度下降(Gradient Descent)算法
问题引入
可以发现上一章节我们寻找权重\( \omega \)的时候,使用的是遍历 \(\omega\) 的方法,显然在工程上这是不可行的,于是引入了梯度下降(Gradient Descent)算法。
梯度下降(Gradien Descent)
我们的目标是找出 \(\omega^*\) 最小化 \(cost(\omega)\)函数 。梯度下降使用公式\( \omega = \omega - \alpha * \frac{\partial cost}{\partial \omega } \),其中\(\alpha\)是人为设定的学习率,显然 \(\omega\) 总是往\(cost\)局部最小化的方向趋近(可以注意并不总是往全局最优的方向)
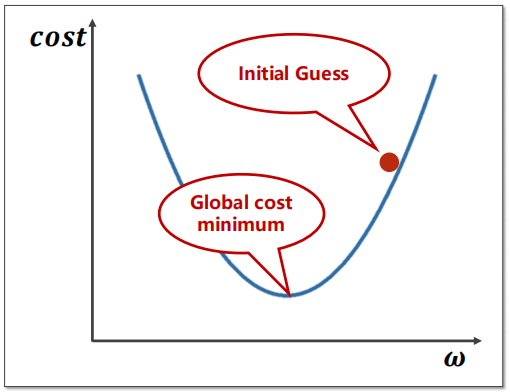
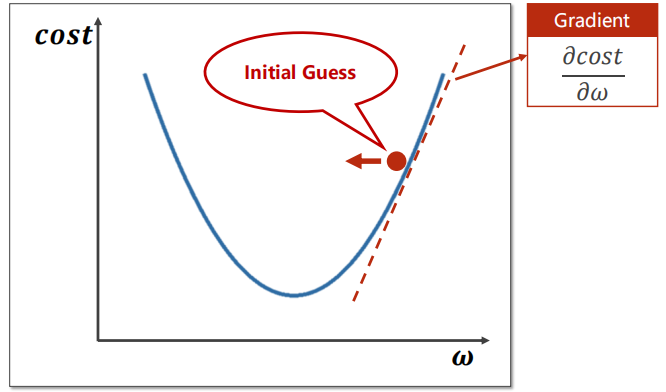
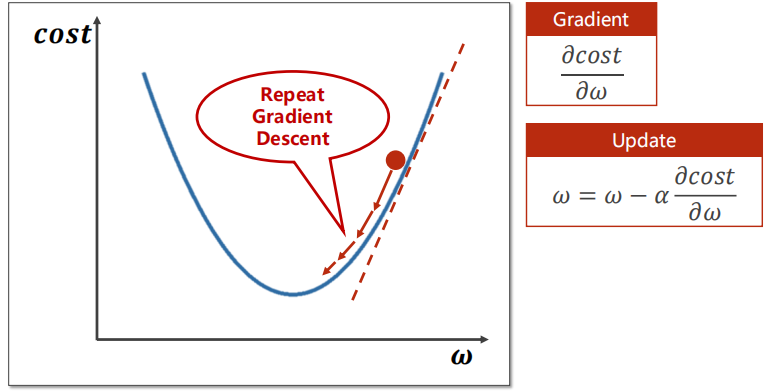
关于局部最优:我们经常担心模型在训练的过程中陷入局部最优的困境中,但实际上由于Mini-batch的存在在实际工程中模型陷入鞍点(局部最优)的概率是很小的(刘老师原话,由于笔者并没有工程经验,故留在此处仅供读者参考),在查询
资料中,或许可以使用动态调整学习率的方法(即在训练轮次小时使用较大的学习率,在轮次大时使用较大的学习率)来进一步防止其陷入鞍点(同时也对性能有一定的优化)
随机梯度下降(SGD)
随机梯度下降算法在梯度下降算法的基础上进行了一定的优化,其对于每一个实例都进行更新,也就是不是用MSE,而是 \( \omega = \omega - \alpha * \frac{\partial loss}{\partial \omega } \) 对 \(\omega \)进行更新
优势:SGD更不容易陷入鞍点之中,同时其拥有更好的性能
代码实现
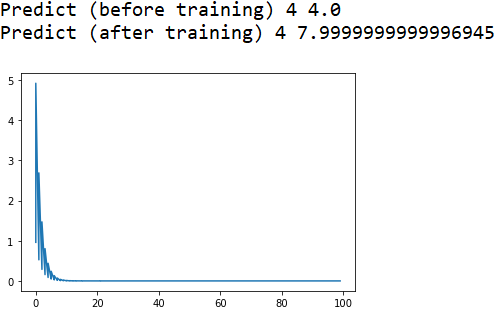
import matplotlib.pyplot as plt x_data=[1.0,2.0,3.0] y_data=[2.0,4.0,6.0] w=1.0 def forward(x): return x*w def loss(x,y): y_pred=forward(x) return (y_pred - y) ** 2 def gradient(x,y): return 2*x*(x*w-y) epoch_list= [] cost_list= [] print('Predict (before training)',4,forward(4)) for epoch in range(100): for x,y in zip(x_data,y_data): grad = gradient(x,y) w= w -0.01* grad #print("\tgrad:",x,y,grad) l=loss(x,y) cost_list.append(l) epoch_list.append(epoch) print("Predict (after training)" ,4,forward(4)) plt.plot(epoch_list,cost_list) plt.show()
代码运行结果
第四节 反向传播(Back Propagation)
问题引入
在上一章节的代码中,事实上我们手动计算了 \(\frac{\partial loss}{\partial \omega } \),在复杂的神经网络当中,这样的方法是不可行的
反向传播
本节引用 torch 库。使用Tensor构造计算图后, 利用.backward()函数 更新 \(\omega\) 的值
需要注意的是,在需要使用张量(Tensor)中的值时,需要使用 .item() 函数 以避免错误地构造计算图
代码实现
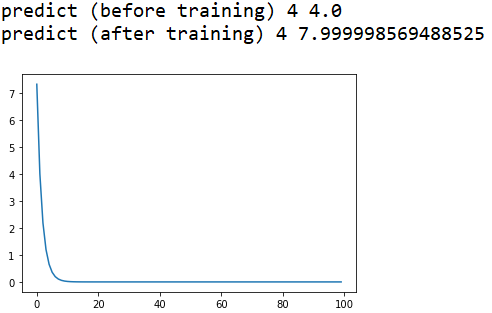
# -*- coding: utf-8 -*- """ Created on Fri Dec 10 10:53:59 2021 @author: Rbrq """ import torch import numpy as np import matplotlib.pyplot as plt x_data = [1.0,2.0,3.0] y_data = [2.0,4.0,6.0] w = torch.tensor([1.0]) w.requires_grad = True def forward(x): return x * w def loss( x , y ): y_pred = forward(x) return (y_pred - y) ** 2 epoch_list = [] loss_list = [] print("predict (before training)", 4 , forward(4).item()) for epoch in range(100): for x , y in zip(x_data,y_data): l = loss(x,y) l.backward() w.data = w.data -0.01 * w.grad.data w.grad.data.zero_() epoch_list.append(epoch) loss_list.append(l.item()) print("predict (after training)",4,forward(4).item()) plt.plot(epoch_list,loss_list) plt.show()
代码运行结果
第五节 用Pytorch实现线性回归
问题引入
本节主要介绍了如何使用pytorch来实现前文所介绍的方法,形式化的,我们可以将一个过程定义为四个部分: 准备数据集,定义一个神经网络,设计损失函数和优化器,训练循环(前馈,反向传播和更新)
具体做法
准备数据集
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[3.0],[5.0],[7.0]])
定义神经网络
class LinearModel(torch.nn.Module): def __init__(self): super(LinearModel,self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self,x): y_pred = self.linear(x) return y_pred model = LinearModel()
#务必将定义的模型实例化
设计损失函数及优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.0228)
训练循环
for epoch in range(100): #calculate forward y_pred = model(x_data) #calculate loss loss =criterion(y_pred,y_data) print('\teopch: ',epoch,'loss: ',loss.item()) optimizer.zero_grad() #back propogation loss.backward() #update optimizer.step()
代码运行结果
![]()
第六节 逻辑斯蒂回归(Logistic Regression)
问题引入
在计算机视觉的实际工程中,我们会遇到很多分类问题,基于此有本节
实际上我们采取的方法是,估计输入值被分为任意一类的概率,在最终输出概率最高的那一类,于是我们需要一个方法将原本模型的输出映射到一个\(\left [0,1 \right ] \)的区间内
Logistic函数:\(\frac{1}{1+e^{-x} } \) 属于一种Sigemoid函数 ,在工程中被广泛使用 ,在Pytorch库中用 torch.nn.functional.sigmoid()调用
在分类问题中,由于输入数据不再具有数据值上的意义,因此我们在定义损失函数时,应比较实际分布与预测分布之间的差异,因此使用交叉熵\(-(ylog\hat{y}+(1-y)log(1-\hat{y}) )\)来定义损失函数(01分布时)
代码实现
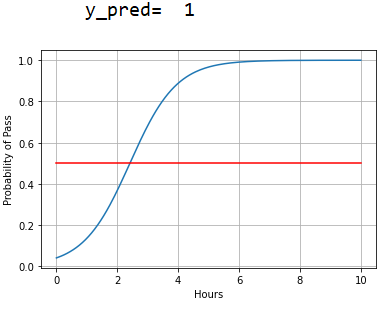
# -*- coding: utf-8 -*- """ Created on Wed Dec 8 20:15:20 2021 @author: Rbrq """ import torch x_data = torch.Tensor([[1.0],[2.0],[3.0]]) y_data = torch.Tensor([[0],[0],[1]]) class LogisticRegressionModel(torch.nn.Module): def __init__(self): super(LogisticRegressionModel,self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self,x): y_pred = torch.sigmoid(self.linear(x)) return y_pred model = LogisticRegressionModel() criterion = torch.nn.BCELoss(reduction = 'sum') optimizer = torch.optim.SGD(model.parameters(),lr=0.01) for epoch in range(1000): #calculate forward y_pred = model(x_data) #calculate loss loss =criterion(y_pred,y_data) print('\teopch: ',epoch,'loss: ',loss.item()) optimizer.zero_grad() #back propogation loss.backward() #update optimizer.step() #test data x_test=torch.Tensor([4.0]) y_test=model(x_test) if y_test.item()>0.5: print('\ty_pred= ',1) else: print('\ty_pred= ',0) import numpy as np import matplotlib.pyplot as plt x = np.linspace(0,10,200) x_t = torch.Tensor(x).view(200,1) y_t = model(x_t) y = y_t.data.numpy() plt.plot(x,y) plt.plot([0,10],[0.5,0.5],c='r') plt.xlabel('Hours') plt.ylabel('Probability of Pass') plt.grid() plt.show()
代码运行结果
第七节 处理多维特征的输入
问题引入
在许多时候我们需要处理多维特征输入的处理,以糖尿病数据集(Diabetes Dataset)为实例,展示如何处理多维特征的输入
糖尿病数据集:由八个feature 的 sample 构成,通过学习来预判在下一年该患者糖尿病恶化的可能性
数据处理
假设我们处理的是一个具有n个feature的sample,则对应修改Logistic模型为\( \hat{y}^{(i)} = \sigma (\begin{bmatrix} x_1^{(i)},x_2^{(i)}...,x_n^{(i)}\end{bmatrix} \begin{bmatrix}w_1\\w_2\\...\\w_n\end{bmatrix} + b) = \sigma(z^{(i)})\),其中 \(\sigma(x) = \frac{1}{1+e^{-x} }\)
从而对于一个Mini-batch而言有 \( \begin{bmatrix}y^{(1)}\\y^{(2)}\\...\\y^{(n)}\end{bmatrix} = \sigma (\begin{bmatrix}z^{(1)}\\z^{(2)}\\...\\z^{(n)}\end{bmatrix}) = \sigma (\begin{bmatrix}x_1^{(1)}......x_n^{(1)}\\............\\x_1^{(m)}......x_n^{(m)} \end{bmatrix}\begin{bmatrix}\omega _1\\...\\\omega_n\end{bmatrix} + \begin{bmatrix} b_1\\...\\b_n\end{bmatrix})\) (将其矩阵化是为了使用GPU的并行计算能力)
对于需要多层神经网络的情况,可以使用神经网络模型叠加的方式进行
self.linear1 = torch.nn.Linear(8,2)
self.linear2 = torch.nn.Linear(2,1)
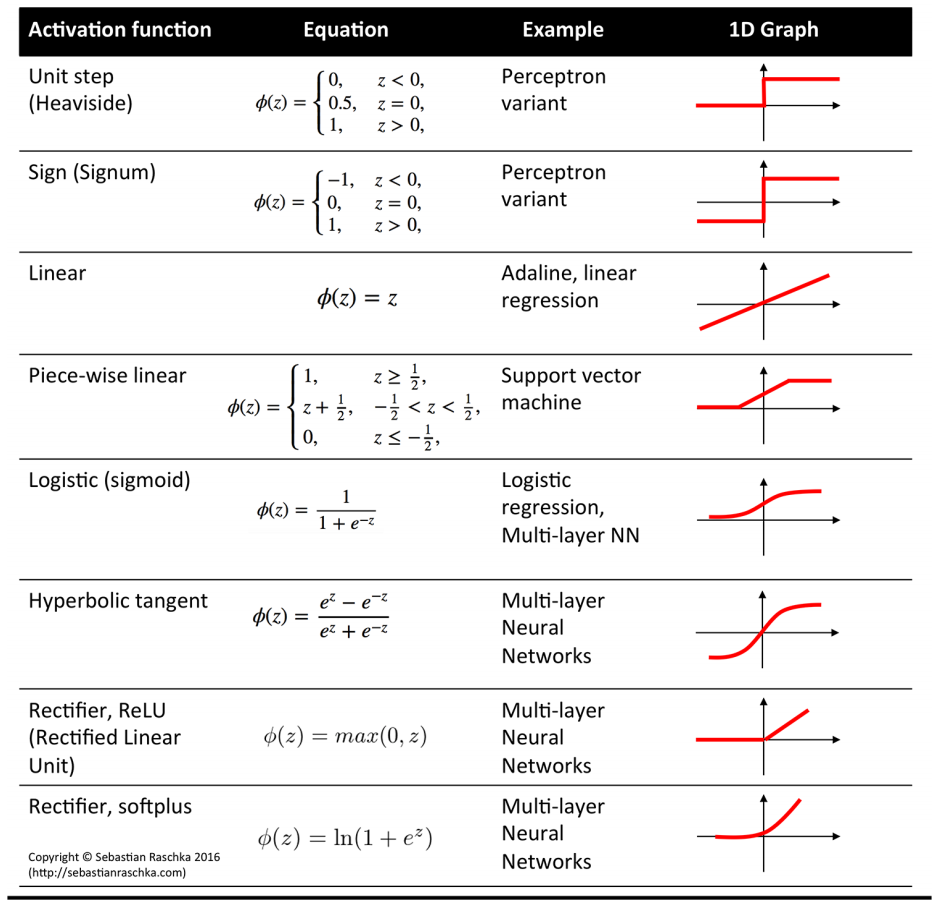
以下给出更多的激活函数
代码实现
# -*- coding: utf-8 -*- """ Created on Fri Dec 10 20:45:21 2021 @author: Rbrq """ import torch import numpy as np import matplotlib.pyplot as plt xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32) x_data = torch.from_numpy(xy[:,:-1]) y_data = torch.from_numpy(xy[:,[-1]]) class Model(torch.nn.Module): def __init__(self): super(Model,self).__init__() self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.sigmoid = torch.nn.Sigmoid() def forward(self,x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() criterion = torch.nn.BCELoss(size_average = True) optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) epoch_list = [] loss_list = [] for epoch in range(10000): y_pred = model(x_data) loss = criterion(y_pred,y_data) print('\tepoch:',epoch,'loss',loss.item()) epoch_list.append(epoch) loss_list.append(loss.item()) #print(epoch,loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() plt.plot(epoch_list,loss_list) plt.ylabel('loss') plt.xlabel('epoch') plt.show()
代码实现结果
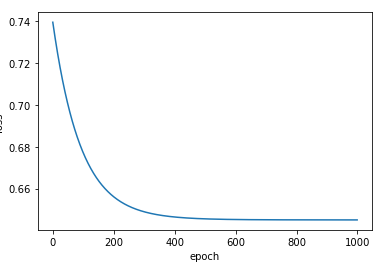
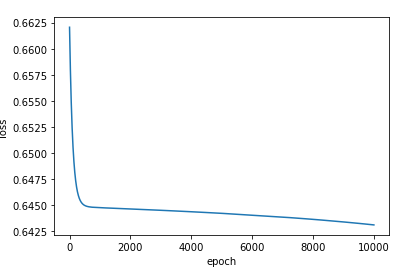
(学习1k次时的结果) (学习1w次时的结果)
第八节 加载数据集
问题引入
可以注意到,在上一节的代码当中,我们并没有使用Mini-batch,这一节中将会阐述如何划分Mini-batch
概念引入
Epoch:对于所有的examples进行一次train cycle称为一次Epoch,也就是对于循环嵌套而言
for epoch in range(traning_epoch): for i in range(total_batch):
Batch_size:一个Batch中所含有的examples的数量
itreration:所有examples被划分成为Batch的数量
shuffle:随机打乱sample
一个data准备过程可以用下图表示
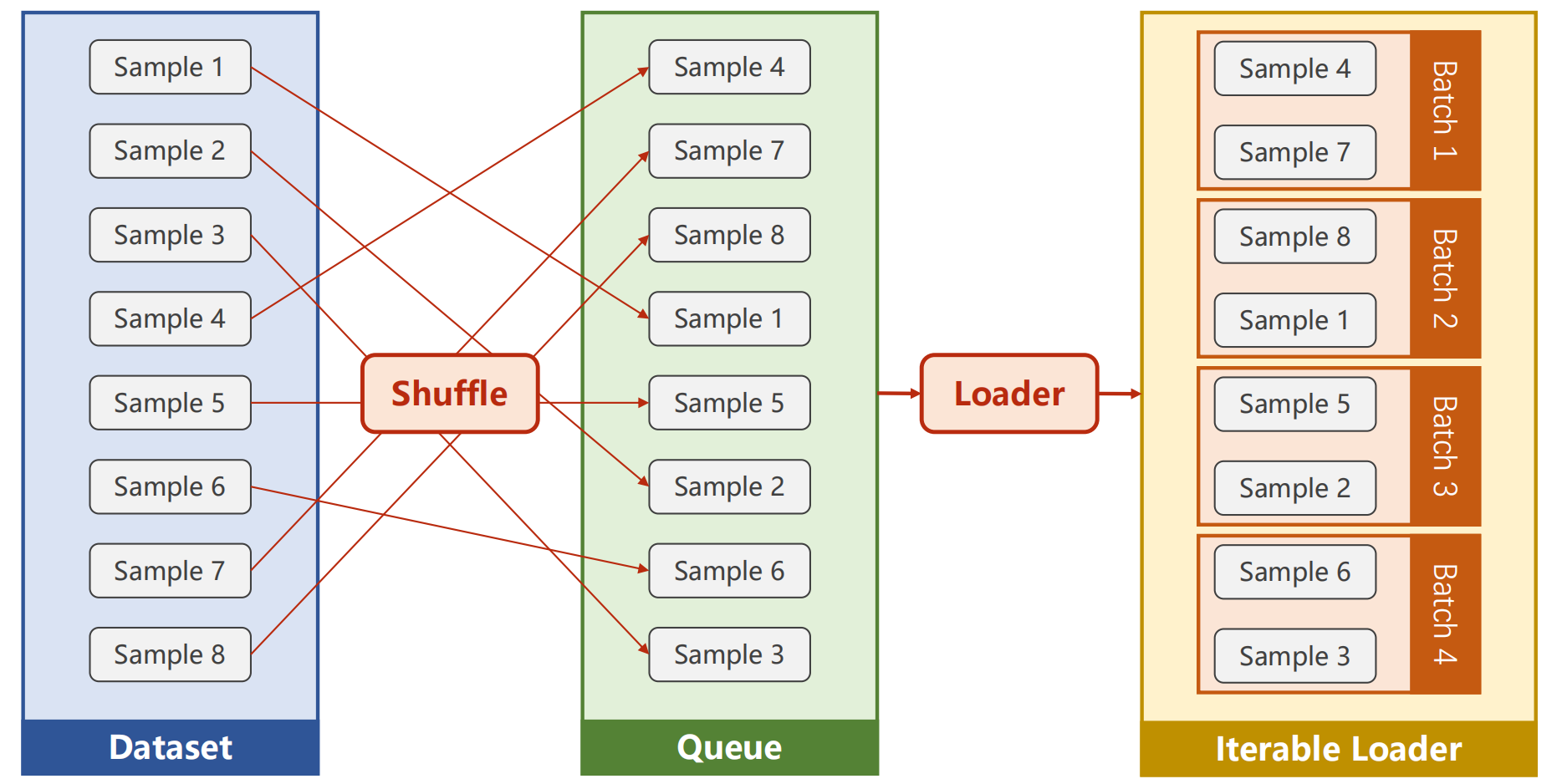
代码实现
# -*- coding: utf-8 -*- """ Created on Sat Dec 11 10:06:42 2021 @author: Rbrq """ import torch import numpy as np import matplotlib.pyplot as plt from torch.utils.data import Dataset from torch.utils.data import DataLoader class DiabetesDataset(Dataset): def __init__(self,filepath): xy = np.loadtxt(filepath,delimiter = ',',dtype = np.float32) self.len = xy.shape[0] self.x_data = torch.from_numpy(xy[:,:-1]) self.y_data = torch.from_numpy(xy[:,[-1]]) def __getitem__(self,index): return self.x_data[index],self.y_data[index] def __len__(self): return self.len dataset = DiabetesDataset('diabetes.csv.gz') train_loader=DataLoader(dataset=dataset,batch_size =32,shuffle=True,num_workers=0) class Model(torch.nn.Module): def __init__(self): super(Model,self).__init__() self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.sigmoid = torch.nn.Sigmoid() def forward(self,x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() criterion = torch.nn.BCELoss(reduction = 'mean') optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) if __name__ == '__main__': epoch_list = [] loss_list = [] for epoch in range(100): for i,data in enumerate(train_loader,0): inputs,labels = data y_pred = model(inputs) loss = criterion(y_pred,labels) optimizer.zero_grad() loss.backward() optimizer.step() print('\tepoch:',epoch,'loss',loss.item()) epoch_list.append(epoch) loss_list.append(loss.item()) plt.plot(epoch_list,loss_list) plt.ylabel('loss') plt.xlabel('epoch') plt.show()
实际上 这段代码存在一些笔者暂时无法理解且无法解决的问题,留在此处,希望得到回答(也因此并不给出代码运行结果):
1.在实际代码执行的过程中,单线程的表现反而比双线程/四线程快许多
2. 这个训练的结果并不收敛(此代码除了数据准备部分,与上一节的代码并无区别)
课后练习
# -*- coding: utf-8 -*- """ Created on Sat Dec 11 20:55:39 2021 @author: Rbrq """ import torch import numpy as np import pandas as pd import matplotlib.pyplot as plt from torch.utils.data import Dataset from torch.utils.data import DataLoader #define nn model class TitanicModel(torch.nn.Module): def __init__(self): super(TitanicModel, self).__init__() self.linear1 = torch.nn.Linear(7,4) self.linear2 = torch.nn.Linear(4,2) self.linear3 = torch.nn.Linear(2,1) self.activate = torch.nn.ReLU() self.sigmoid = torch.nn.Sigmoid() def forward(self,x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = TitanicModel() #------------------------------Train data------------------------------# #Dataset train_data = pd.read_csv('train.csv') #del useless data del train_data['PassengerId'] del train_data['Cabin'] del train_data['Name'] del train_data['Ticket'] #fill the empty ages train_data['Age'] = train_data['Age'].fillna(train_data['Age'].median()) #fill the empty embarked ans = train_data['Embarked'].value_counts() fillstr = ans.idxmax() train_data['Embarked'] = train_data['Embarked'].fillna(fillstr) #change sex && embarked type train_data.replace(["female","male"],[0,1],inplace = True) train_data.replace(["Q","C","S"],[0,1,2],inplace = True) #change data_type train_data = train_data.astype(np.float32) train_data.info() #prepare data train_data = np.array(train_data) x_data = torch.from_numpy(train_data[:,1:8]) print(x_data) y_data = torch.from_numpy(train_data[:,[0]]) #--------------------------------train data----------------------------# #define loss function criterion = torch.nn.BCELoss( reduction = 'mean') #define optimizer optimizer = torch.optim.SGD(model.parameters() , lr = 0.012) epoch_list = [] loss_list = [] #-----------------------------train cycle------------------------------# for epoch in range(25001): #forward y_pred = model(x_data) ans = y_pred.detach().numpy() #loss loss = criterion(y_pred,y_data) #backpropagation optimizer.zero_grad() loss.backward() #update optimizer.step() epoch_list.append(epoch) loss_list.append(loss.item()) #print("\tepoch: ",epoch,"loss:",loss.item()) #---------------------------train cycle----------------------------# #visual plt.plot(epoch_list,loss_list) plt.xlabel("epoch") plt.ylabel("loss") plt.show() ans[ans >= 0.5] = 1 ans[ans < 0.5] = 0 #----------------------Calculate the accuracy--------------------------# train_size = x_data.shape[0] cmd = 0 for i in range(train_size): cmd += (ans[i].item() == y_data[i]) accuracy = cmd / train_size print("\tAccuracy of predict survival:",accuracy*100.0,"%") #----------------------Calculate the accuracy--------------------------# #---------------------------Test MODEL --------------------------------# #TEST Dataset test_data = pd.read_csv('test.csv') #del useless data del test_data['Cabin'] del test_data['Name'] del test_data['Ticket'] #fill the empty ages test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median()) #fill the empty embarked ans = test_data['Embarked'].value_counts() fillstr = ans.idxmax() test_data['Embarked'] = test_data['Embarked'].fillna(fillstr) #change sex && embarked type test_data.replace(["female","male"],[0,1],inplace = True) test_data.replace(["Q","C","S"],[0,1,2],inplace = True) #change data_type test_data = test_data.astype(np.float32) test_data.info() #prepare data test_data = np.array(test_data) x_test = torch.from_numpy(test_data[:,1:8]) y_test = model(x_test) y = y_test.data.numpy() y[y >=0.5] = 1 y[y <0.5] = 0 #-------------------------------Test MODLE ---------------------------# #--------------------------------Output-------------------------------# pIds = pd.DataFrame(data=test_data[:,[0]].astype(int), columns=['PassengerId'], dtype=int) preds= pd.DataFrame(data= y, columns=['Survived'], dtype=int) result= pd.concat([pIds, preds], axis=1) result.to_csv('titanic_survival_predictions.csv', index=False) #--------------------------------Output-------------------------------#
作业结果
![]()
第九节 多分类问题
问题引入
在实际问题中我们会遇到一些多分类问题,例如经典问题MNIST,本节将介绍如何使用Softmax分类器来进行多分类问题的解决以及代码实现
多分类问题
假设我们使用二分类的类似解法来解决多分类问题(也就是对于一个分类 \( i\),我们讨论这个待分类的Sample属于/不属于\( i\) ),有可能出现对于两个分类 \( i , j \),他们的概率都很高,这并不符合我们对于多分类问题答案的期望,于是我
们希望找到一个方法,使得其答案满足一个分布(具体的来说 就是\( \sum{p_i} = 1 且 \forall i ,p_i\ge 0 \) ,于是我们使用Softmax Layer来实现这个变换
\(Softmax function: P(y = i) = \frac{e^{z_i}}{ {\textstyle \sum_{j=0}^{K-1}}e^{z_j} } ,i\in \left \{ 0...K-1 \right \} \)
下面考虑以MNIST为例子展示如何解决多分类问题
MNIST
可以考虑一个n*n且有m个通道数的图像可以转化为一个m*n*n的矩阵列,然后利用view函数将其变为一维向量即可转化为我们熟悉的输入模式
同时利用归一化函数normalize可以将像素转化为一个0-1的标准分布。
代码实现
# -*- coding: utf-8 -*- """ Created on Thu Dec 16 17:39:08 2021 @author: Rbrq """ import torch import numpy as np import torch.optim as optim import matplotlib.pyplot as plt from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader #-----------------------------prepare data-----------------------------------# batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), #0.1307是MNISTdataset的均值,0.3081是MNISTdataset的标准差 transforms.Normalize((0.1307,),(0.3081,)) ]) train_dataset = datasets.MNIST(root = '../dataset/mnist/', train = True, download = True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root = '../dataset/mnist/', train = False, download = True, transform=transform) test_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) #-----------------------------prepare data-----------------------------------# #---------------------------define nn model----------------------------------# class MnistModel(torch.nn.Module): def __init__(self): super(MnistModel,self).__init__() self.linear1 = torch.nn.Linear(784,512) self.linear2 = torch.nn.Linear(512,256) self.linear3 = torch.nn.Linear(256,128) self.linear4 = torch.nn.Linear(128,64) self.linear5 = torch.nn.Linear(64,10) self.activate = torch.nn.ReLU() def forward(self,x): x = x.view(-1,784) x = self.activate(self.linear1(x)) x = self.activate(self.linear2(x)) x = self.activate(self.linear3(x)) x = self.activate(self.linear4(x)) #最后一层nn不需要激活 x = self.linear5(x) return x model = MnistModel() criterion = torch.nn.CrossEntropyLoss() #使用带有冲量的优化器 optimizer = optim.SGD(model.parameters(),lr = 0.01, momentum = 0.5) #---------------------------define nn model----------------------------------# #---------------------------------train cycle--------------------------------# def train(epoch): running_loss = 0.0 for batch_idx , data in enumerate(train_loader,0): inputs , labels = data optimizer.zero_grad() y_pred = model(inputs) loss = criterion(y_pred,labels) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx %300 == 299: print('[%d %5d] loss:%3f'%(epoch + 1, batch_idx +1 , running_loss/300)) running_loss = 0.0 #---------------------------------train cycle--------------------------------# #----------------------------------test--------------------------------------# def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images , labels = data y_pred = model(images) total += labels.size(0) _, predicted = torch.max(y_pred.data,dim=1) correct += (predicted == labels).sum().item() print("ACC:%d %%" % (100 *correct / total)) #----------------------------------test--------------------------------------# if __name__ == '__main__': for epoch in range(20): train(epoch) test()
代码运行结果
![]()
课后作业代码
# -*- coding: utf-8 -*- """ Created on Thu Dec 16 20:35:00 2021 @author: Rbrq """ import torch import numpy as np import pandas as pd import matplotlib.pyplot as plt from torchvision import datasets from torchvision import transforms from torch.utils.data import Dataset from torch.utils.data import DataLoader #--------------------------------处理训练数据----------------------------------# def labelchange(lables): target_id = [] target_lables = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9'] for lable in lables: target_id.append(target_lables.index(lable)) return target_id class Ottodataset(Dataset): def __init__(self,filepath): data = pd.read_csv(filepath) lables = data["target"] self.x_data = torch.from_numpy(np.array(data)[:,1:-1].astype(np.float32)) self.y_data = labelchange(lables) self.len = data.shape[0] def __getitem__(self,index): return self.x_data[index],self.y_data[index] def __len__(self): return self.len transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5),(0.5)) ]) train_data = Ottodataset("train.csv") train_loader = DataLoader(train_data, shuffle = True, batch_size = 64, num_workers = 0) #--------------------------------处理训练数据----------------------------------# #--------------------------定义模型,损失函数,优化器-----------------------------# class OttogroupModel(torch.nn.Module): def __init__(self): super(OttogroupModel,self).__init__() self.linear1 = torch.nn.Linear(93,64) self.linear2 = torch.nn.Linear(64,32) self.linear3 = torch.nn.Linear(32,16) self.linear4 = torch.nn.Linear(16,9) self.activate= torch.nn.ReLU() def forward(self,x): x = self.activate(self.linear1(x)) x = self.activate(self.linear2(x)) x = self.activate(self.linear3(x)) x = self.linear4(x) return x model = OttogroupModel() criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters() , lr = 0.015 ,momentum = 0.5) #--------------------------定义模型,损失函数,优化器-----------------------------# #----------------------------------训练循环------------------------------------# def train(epoch): running_loss = 0.0 for batch_idx , data in enumerate(train_loader,0): inputs , labels = data optimizer.zero_grad() y_pred = model(inputs) loss = criterion(y_pred,labels) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx %300 == 299: print('[%d %5d] loss:%3f'%(epoch + 1, batch_idx +1 , running_loss/300)) running_loss = 0.0 #----------------------------------训练循环------------------------------------# #--------------------------------处理测试数据-----------------------------------# #--------------------------------处理测试数据-----------------------------------# #------------------------------------测试--------------------------------------# def test_in(): correct = 0 total = 0 with torch.no_grad(): for data in train_loader: images , labels = data y_pred = model(images) total += labels.size(0) _, predicted = torch.max(y_pred.data,dim=1) correct += (predicted == labels).sum().item() print("ACC:%d %%" % (100 *correct / total)) def test(): test_data = pd.read_csv("test.csv") x_test = torch.from_numpy(np.array(test_data)[:,1:].astype(np.float32)) y_pred = model(x_test) _, pred = torch.max(y_pred,dim=1) out = pd.get_dummies(pred) lables = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9'] out.columns = lables out.insert(0, 'id', test_data['id']) print(out) result = pd.DataFrame(out) result.to_csv('otto-group-product_predictions.csv', index=False) #------------------------------------测试--------------------------------------# if __name__ == '__main__': for epoch in range(250): train(epoch) test_in() test()
作业结果
![]()
第十节 基础卷积神经网络(Basic CNN)
问题引入
在上一节当中,我们使用全链接的网络计算MNIST的方式,但是这种方式会丢失掉图像空间之间的相关信息,于是我们需要一些方法去提取图像的特征。
问题解决
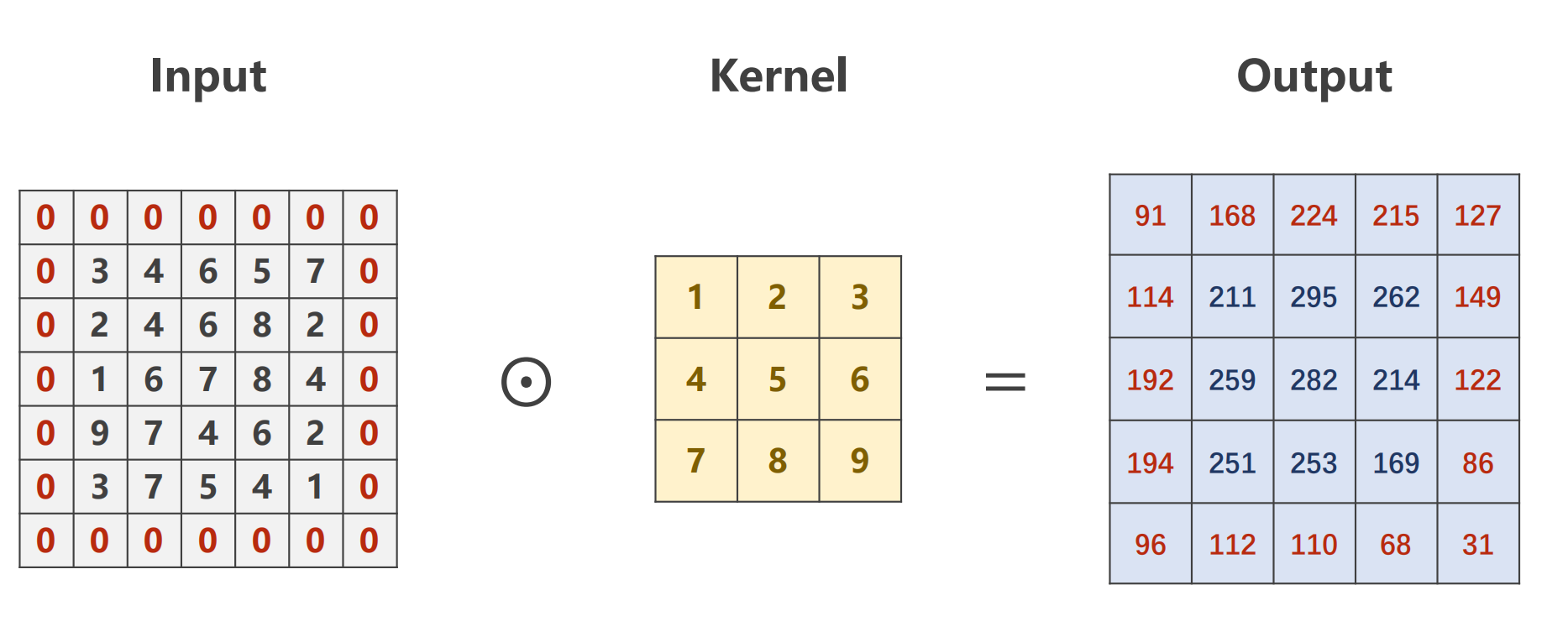
首先考虑步长为1的卷积操作,对于一个shape为n*n的卷积核(先考虑一个通道时的情况),其实质上就是遍历原矩阵中每一个n阶子式,并对应位置做乘积.
对于一个有m channel的输入 的卷积核也需要有m个通道数,这样的一个卷积核被称为一个fillter
形式化的 对于一个 n*a*a 的输入patch 经过m个fillter的操作后(每个卷积核为n*k*k) 其转化为一个 m*b*b的输出(其中当步长为1时,b=a-k+1)
对于fillter的理解有个形象化的说法,例如对于一个人脸,fillter a筛选与耳朵有关的特征 而 fillter b筛选与眼睛有关的特征 诸如此类
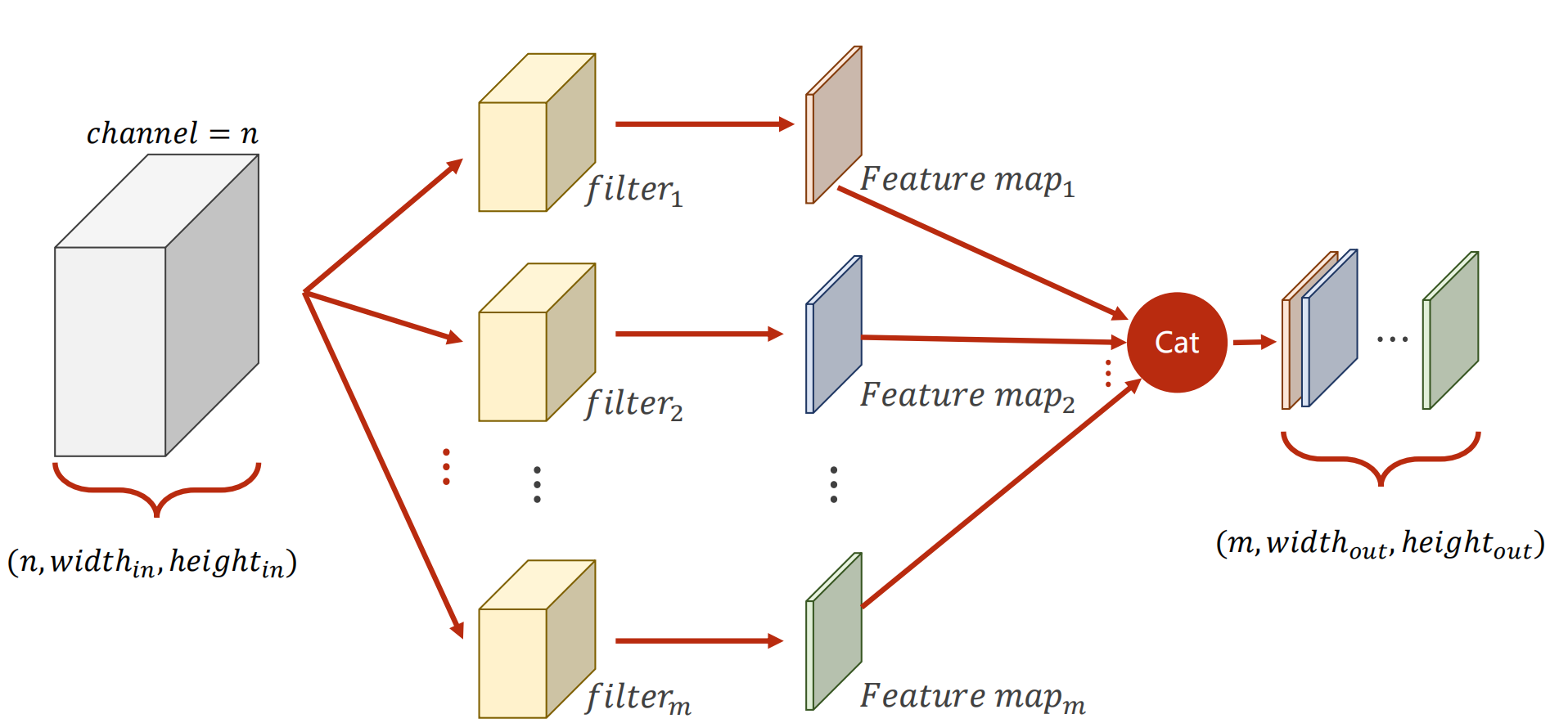

再介绍两种卷积操作:
1.padding 扩充输入的维度来获得更大维度的输出
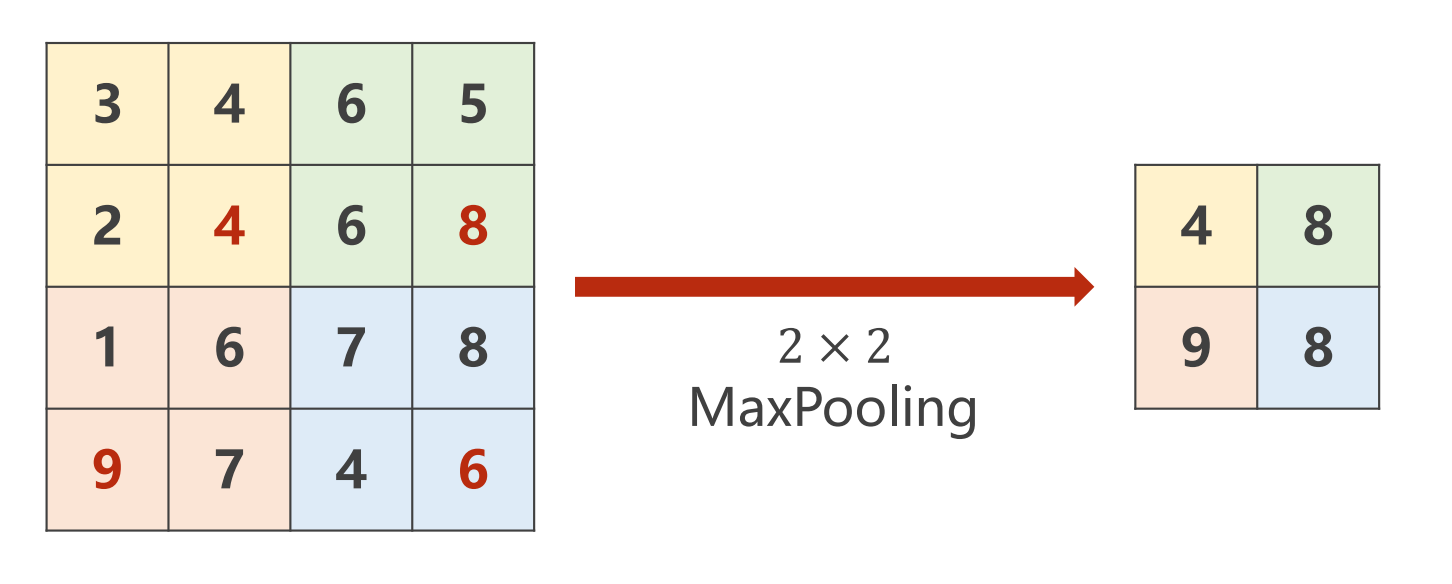
2.最大池化操作 Maxpooling (默认步长stride为2) 取出一个2*2 的网格并取最大值
一个模式化的操作可以认为是:a--->卷积操作--->池化操作--->激活函数.....--->线性变换

代码使用
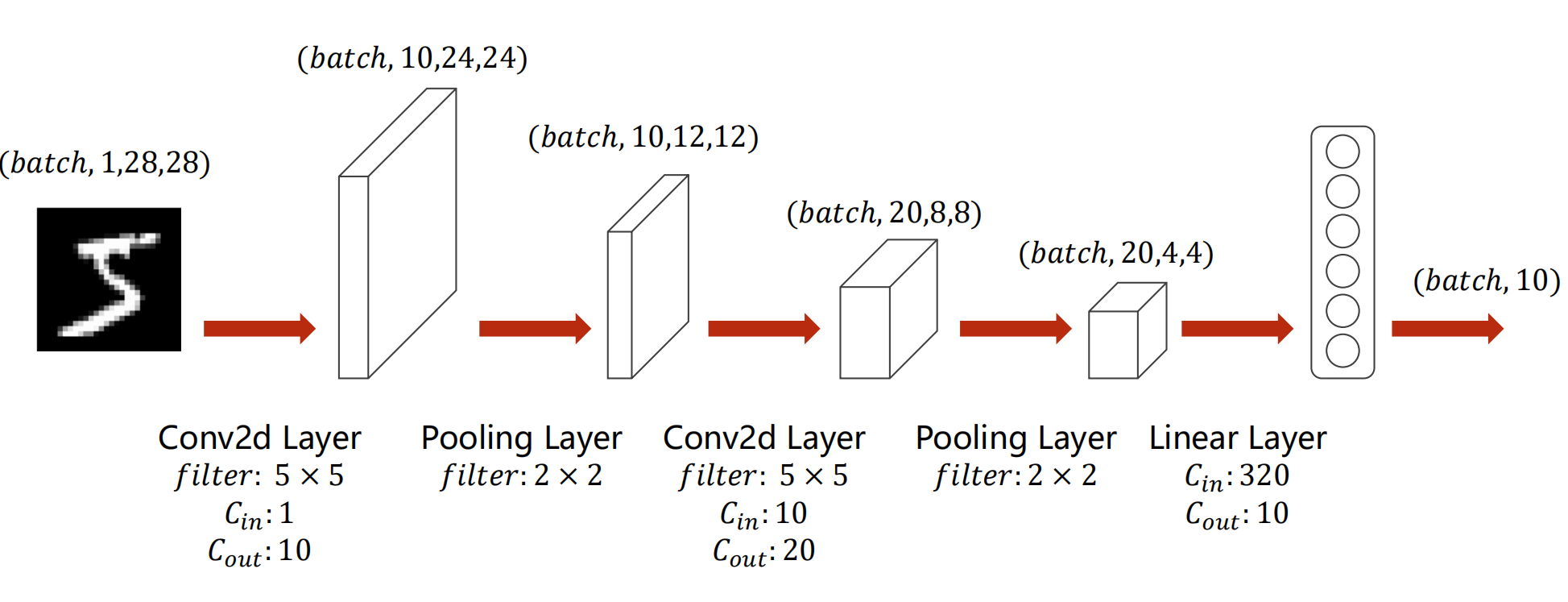
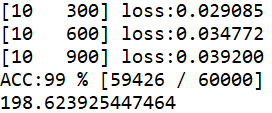
# -*- coding: utf-8 -*- """ Created on Fri Dec 17 22:00:20 2021 @author: Rbrq """ # -*- coding: utf-8 -*- """ Created on Thu Dec 16 17:39:08 2021 @author: Rbrq """ import time import torch import numpy as np import torch.optim as optim import matplotlib.pyplot as plt import torch.nn.functional as F from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader #-----------------------------prepare data-----------------------------------# T1 = time.time() batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), #0.1307是MNISTdataset的均值,0.3081是MNISTdataset的标准差 transforms.Normalize((0.1307,),(0.3081,)) ]) train_dataset = datasets.MNIST(root = '../dataset/mnist/', train = True, download = True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root = '../dataset/mnist/', train = False, download = True, transform=transform) test_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) #-----------------------------prepare data-----------------------------------# #---------------------------define nn model----------------------------------# class Net(torch.nn.Module): def __init__(self): super(Net,self).__init__() self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5) self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.activate = torch.nn.ReLU() self.linear1 = torch.nn.Linear(320,10) def forward(self,x): batch_size = x.size(0) x = self.activate(self.pooling(self.conv1(x))) x = self.activate(self.pooling(self.conv2(x))) x = x.view(batch_size,-1) x = self.linear1(x) return x model = Net() if torch.cuda.is_available(): print("Nvida Yes") device = torch.device("cuda:0"if torch.cuda.is_available() else "cpu") model.to(device) criterion = torch.nn.CrossEntropyLoss() #使用带有冲量的优化器 optimizer = optim.SGD(model.parameters(),lr = 0.01, momentum = 0.5) #---------------------------define nn model----------------------------------# #---------------------------------train cycle--------------------------------# def train(epoch): running_loss = 0.0 for batch_idx , data in enumerate(train_loader,0): inputs , labels = data inputs ,labels = inputs.to(device),labels.to(device) optimizer.zero_grad() y_pred = model(inputs) loss = criterion(y_pred,labels) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx %300 == 299: print('[%d %5d] loss:%3f'%(epoch + 1, batch_idx +1 , running_loss/300)) running_loss = 0.0 #---------------------------------train cycle--------------------------------# #----------------------------------test--------------------------------------# def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images , labels = data images ,labels = images.to(device),labels.to(device) y_pred = model(images) total += labels.size(0) _, predicted = torch.max(y_pred.data,dim=1) correct += (predicted == labels).sum().item() print("ACC:%d %% [%d / %d]" % (100 *correct / total , correct, total)) #----------------------------------test--------------------------------------# if __name__ == '__main__': for epoch in range(10): train(epoch) test() T2 =time.time() print(T2-T1)
#为了对比gpu版本和cpu版本的计算速度
#博主使用的gpu为rtx3060 130w移动版 cpu为5800H
#最后测试中gou快于cpu gpu:198s cpu:233s (该结果未重复测试取均值,仅供参考)
运行结果
作业
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=3)
self.conv3 = torch.nn.Conv2d(20,40,kernel_size=4)
self.pooling = torch.nn.MaxPool2d(2)
self.activate = torch.nn.ReLU()
self.linear1 = torch.nn.Linear(40,32)
self.linear2 = torch.nn.Linear(32,16)
self.linear3 = torch.nn.Linear(16,10)
def forward(self,x):
batch_size = x.size(0)
x = self.activate(self.pooling(self.conv1(x)))
x = self.activate(self.pooling(self.conv2(x)))
x = self.activate(self.pooling(self.conv3(x)))
x = x.view(batch_size,-1)
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = self.linear3(x)
return x
#实际上性能还略微变差了(xiao
#其余部分与上文代码无任何区别
#运行时间221s
运行结果

第十一节 卷积神经网络(高级篇) Advanced CNN
问题引入
大部分问题中问题的解决(模型的定义并不是串行的),因此在本节中介绍一些较为复杂的卷积神经网络
GooLeNet
如GooLeNet网络示意图,可以看到其有很多重复过程,为了减少代码冗余,可以将此封装为一个类,被封装的一个类称为Inception,图2给出了一个典型的Inception
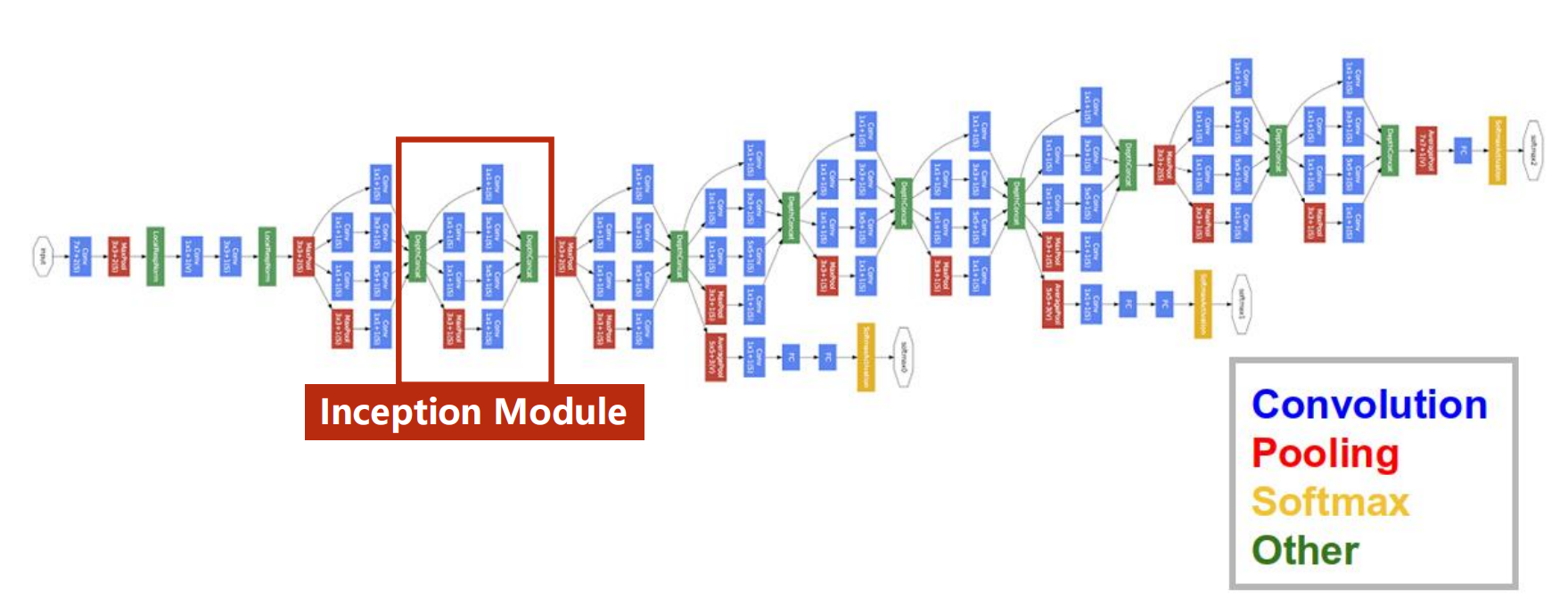
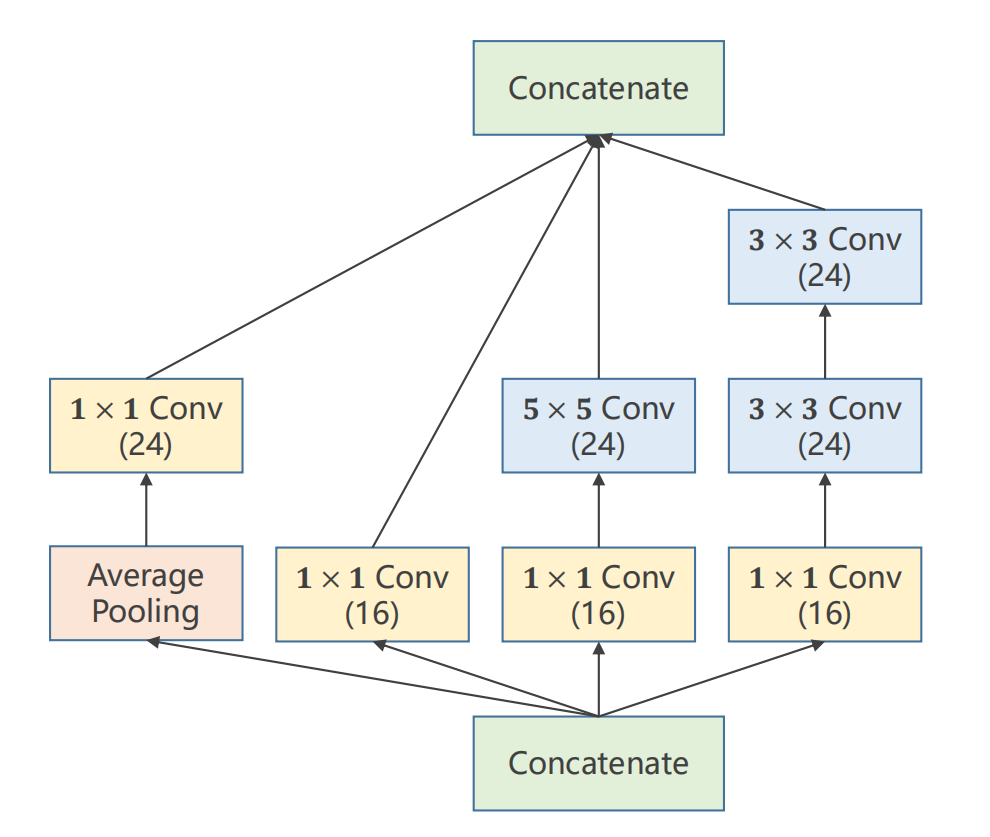
在GooLeNet中的Inception有着各种的卷积核,随着学习的进行,较为合理的大小的卷积核会逐渐拥有更大的权重,以解决超参数难以确定的问题
Avergae_pooling:均值池化 设置stride=1 , pedding = 1 可以保证张量的大小不变
Shape 1 * 1 的卷积核的作用 : 将图像的通道数(channel)变为1 ,包含各个通道中相同位置的元素的信息 ,同时预先使用可以减少计算量
信息融合: 融合各维度信息 提取某指定feature(同时会丢失信息)
因此可以写出一个Inception的class类代码
import torch from torch.nn.functional import F class InceptionA(torch.nn.Module): def __init__(self,in_channels): super(InceptionA,self).__init__() self.branch_pool = torch.nn.Conv2d(in_channels,24,kernel_size=1) self.branch1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch5x5_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch5x5_2 = torch.nn.Conv2d(16,24,kernel_size=5,padding=2) self.branch3x3_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch3x3_2 = torch.nn.Conv2d(16,24,kernel_size=3,padding=1) self.branch3x3_3 = torch.nn.Conv2d(24,24,kernel_size=3,padding=1) def forward(self,x): branch_pool_x = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1) branch_pool_x = self.branch_pool(branch_pool_x) branch1x1_x = self.branch1x1(x) branch5x5_x = self.branch5x5_1(x) branch5x5_x = self.branch5x5_2(branch5x5_x) branch3x3_x = self.branch3x3_1(x) branch3x3_x = self.branch3x3_2(branch3x3_x) branch3x3_x = self.branch3x3_3(branch3x3_x) branch_out = [branch1x1_x , branch3x3_x , branch5x5_x , branch_pool_x] return torch.cat(branch_out,dim=1)
于是可以完整定义一个model
class MNISTAdvancedCNNModel(torch.nn.Module): def __init__(self): super(MNISTAdvancedCNNModel,self).__init__() self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5) self.conv2 = torch.nn.Conv2d(88,20,kernel_size=5) self.ince1 = InceptionA(in_channels=10) self.ince2 = InceptionA(in_channels=20) self.pooling = torch.nn.MaxPool2d(2) self.linear1 = torch.nn.Linear(1408,10) self.activate = torch.nn.ReLU() def forward(self,x): in_size = x.shape(0) x = self.activate(self.pooling(self.conv1(x))) x = self.ince1(x) x = self.activate(self.pooling(self.conv2(x))) x = self.ince2(x) x = x.view(in_size,-1) x = self.linear1(x) return x
关于1408的计算方式:输入为1*28*28,在经过一个5*5卷积核和一个max_pool后则变为\( (28-5+1) / 2 = 12\) 而inception不改变weith和length 再经过一个5*5的卷积核和max_pool变为\( (12 - 5 +1)/2 = 4\) ,则有4*4*88 = 1408
运行结果
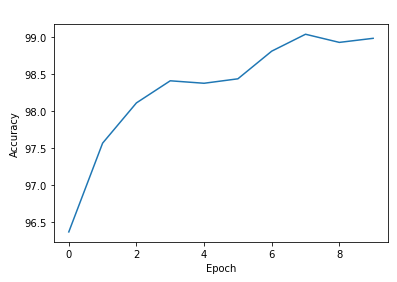
可以看到实际上最优值并不是在最后一次训练取到,我们可以备份每一次训练的权重结果,这样就可以获得训练中泛化性能最好的.
Residual_net
梯度消失:由于网络的叠加,再训练后梯度小于1的不断乘积累加,最后出现梯度趋近0的现象,称为梯度消失
解决梯度消失的方法:分别训练每一层的权重
Residual net加上一层跳连接来实现这个过程,实现对输入比较近的层的充分训练,也就是在求\(\frac{\partial H(x)}{\partial x} \)时加上了“1“
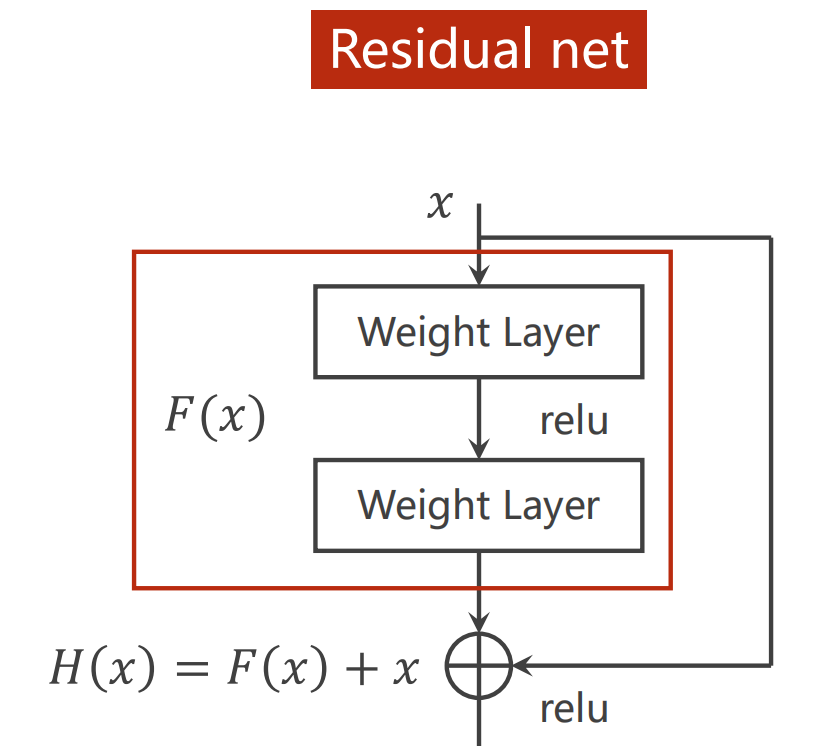
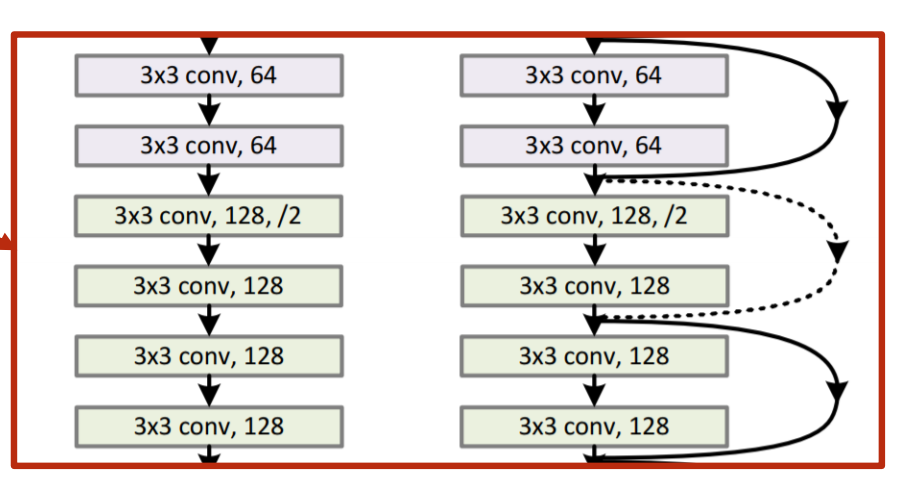
给出Redidual_block的代码
class ResidualBlock(torch.nn.Module): def __init__(self,channels): super(ResidualBlock,self).__init__() self.channels = channels self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1) self.conv2 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1) self.activate = torch.nn.ReLU() def forward(self,x): y = self.activate(self.conv1(x)) y = self.conv2(y) return self.activate(x+y) class MNISTAdvancedCNNModel(torch.nn.Module): def __init__(self): super(MNISTAdvancedCNNModel,self).__init__() self.conv1 = torch.nn.Conv2d(1,16,kernel_size=5) self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.rbb1 = ResidualBlock(16) self.rbb2 = ResidualBlock(32) self.activate = torch.nn.ReLU() self.fc1 = torch.nn.Linear(512,10) def forward(self,x): in_size = x.size(0) x = self.activate(self.pooling(self.conv1(x))) x = self.rbb1(x) x = self.activate(self.pooling(self.conv2(x))) x = self.rbb2(x) x = x.view(in_size,-1) x = self.fc1(x) return x
运行结果
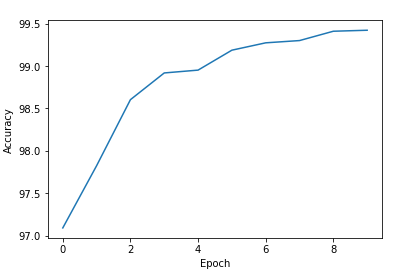
最后给出完整的GooLeNet & Residual Net的代码
# -*- coding: utf-8 -*- """ Created on Thu Dec 16 17:39:08 2021 @author: Rbrq """ import time import torch import numpy as np import torch.optim as optim import matplotlib.pyplot as plt import torch.nn.functional as F from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader #-----------------------------prepare data-----------------------------------# T1 = time.time() batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), #0.1307是MNISTdataset的均值,0.3081是MNISTdataset的标准差 transforms.Normalize((0.1307,),(0.3081,)) ]) train_dataset = datasets.MNIST(root = '../dataset/mnist/', train = True, download = True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root = '../dataset/mnist/', train = False, download = True, transform=transform) test_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) #-----------------------------prepare data-----------------------------------# #---------------------------define nn model----------------------------------# class InceptionA(torch.nn.Module): def __init__(self,in_channels): super(InceptionA,self).__init__() self.branch_pool = torch.nn.Conv2d(in_channels,24,kernel_size=1) self.branch1x1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch5x5_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch5x5_2 = torch.nn.Conv2d(16,24,kernel_size=5,padding=2) self.branch3x3_1 = torch.nn.Conv2d(in_channels,16,kernel_size=1) self.branch3x3_2 = torch.nn.Conv2d(16,24,kernel_size=3,padding=1) self.branch3x3_3 = torch.nn.Conv2d(24,24,kernel_size=3,padding=1) def forward(self,x): branch_pool_x = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1) branch_pool_x = self.branch_pool(branch_pool_x) branch1x1_x = self.branch1x1(x) branch5x5_x = self.branch5x5_1(x) branch5x5_x = self.branch5x5_2(branch5x5_x) branch3x3_x = self.branch3x3_1(x) branch3x3_x = self.branch3x3_2(branch3x3_x) branch3x3_x = self.branch3x3_3(branch3x3_x) branch_out = [branch1x1_x , branch3x3_x , branch5x5_x , branch_pool_x] return torch.cat(branch_out,dim=1) class MNISTAdvancedCNNModel(torch.nn.Module): def __init__(self): super(MNISTAdvancedCNNModel,self).__init__() self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5) self.conv2 = torch.nn.Conv2d(88,20,kernel_size=5) self.ince1 = InceptionA(in_channels=10) self.ince2 = InceptionA(in_channels=20) self.pooling = torch.nn.MaxPool2d(2) self.linear1 = torch.nn.Linear(1408,10) self.activate = torch.nn.ReLU() def forward(self,x): in_size = x.size(0) x = self.activate(self.pooling(self.conv1(x))) x = self.ince1(x) x = self.activate(self.pooling(self.conv2(x))) x = self.ince2(x) x = x.view(in_size,-1) x = self.linear1(x) return x model = MNISTAdvancedCNNModel() device = torch.device("cuda:0"if torch.cuda.is_available() else "cpu") model.to(device) criterion = torch.nn.CrossEntropyLoss() #使用带有冲量的优化器 optimizer = optim.SGD(model.parameters(),lr = 0.01, momentum = 0.5) #---------------------------define nn model----------------------------------# #---------------------------------train cycle--------------------------------# def train(epoch): running_loss = 0.0 for batch_idx , data in enumerate(train_loader,0): inputs , labels = data inputs ,labels = inputs.to(device),labels.to(device) optimizer.zero_grad() y_pred = model(inputs) loss = criterion(y_pred,labels) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx %300 == 299: print('[%d %5d] loss:%3f'%(epoch + 1, batch_idx +1 , running_loss/300)) running_loss = 0.0 #---------------------------------train cycle--------------------------------# #----------------------------------test--------------------------------------# def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images , labels = data images ,labels = images.to(device),labels.to(device) y_pred = model(images) total += labels.size(0) _, predicted = torch.max(y_pred.data,dim=1) correct += (predicted == labels).sum().item() print("ACC:%d %% [%d / %d]" % (100 *correct / total , correct, total)) return 100*correct / total #----------------------------------test--------------------------------------# if __name__ == '__main__': epoch_list = [] acc_list = [] for epoch in range(10): train(epoch) epoch_list.append(epoch) acc_list.append(test()) T2 = time.time() print(T2-T1) plt.plot(epoch_list,acc_list) plt.xlabel("Epoch") plt.ylabel("Accuracy") plt.show()
# -*- coding: utf-8 -*- """ Created on Thu Dec 16 17:39:08 2021 @author: Rbrq """ import time import torch import numpy as np import torch.optim as optim import matplotlib.pyplot as plt import torch.nn.functional as F from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader #-----------------------------prepare data-----------------------------------# T1 = time.time() batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), #0.1307是MNISTdataset的均值,0.3081是MNISTdataset的标准差 transforms.Normalize((0.1307,),(0.3081,)) ]) train_dataset = datasets.MNIST(root = '../dataset/mnist/', train = True, download = True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root = '../dataset/mnist/', train = False, download = True, transform=transform) test_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) #-----------------------------prepare data-----------------------------------# #---------------------------define nn model----------------------------------# class ResidualBlock(torch.nn.Module): def __init__(self,channels): super(ResidualBlock,self).__init__() self.channels = channels self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1) self.conv2 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1) self.activate = torch.nn.ReLU() def forward(self,x): y = self.activate(self.conv1(x)) y = self.conv2(y) return self.activate(x+y) class MNISTAdvancedCNNModel(torch.nn.Module): def __init__(self): super(MNISTAdvancedCNNModel,self).__init__() self.conv1 = torch.nn.Conv2d(1,16,kernel_size=5) self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.rbb1 = ResidualBlock(16) self.rbb2 = ResidualBlock(32) self.activate = torch.nn.ReLU() self.fc1 = torch.nn.Linear(512,10) def forward(self,x): in_size = x.size(0) x = self.activate(self.pooling(self.conv1(x))) x = self.rbb1(x) x = self.activate(self.pooling(self.conv2(x))) x = self.rbb2(x) x = x.view(in_size,-1) x = self.fc1(x) return x model = MNISTAdvancedCNNModel() criterion = torch.nn.CrossEntropyLoss() #使用带有冲量的优化器 optimizer = optim.SGD(model.parameters(),lr = 0.01, momentum = 0.5) #---------------------------define nn model----------------------------------# #---------------------------------train cycle--------------------------------# def train(epoch): running_loss = 0.0 for batch_idx , data in enumerate(train_loader,0): inputs , labels = data optimizer.zero_grad() y_pred = model(inputs) loss = criterion(y_pred,labels) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx %300 == 299: print('[%d %5d] loss:%3f'%(epoch + 1, batch_idx +1 , running_loss/300)) running_loss = 0.0 #---------------------------------train cycle--------------------------------# #----------------------------------test--------------------------------------# def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images , labels = data y_pred = model(images) total += labels.size(0) _, predicted = torch.max(y_pred.data,dim=1) correct += (predicted == labels).sum().item() print("ACC:%d %% [%d / %d]" % (100 *correct / total , correct, total)) return 100*correct / total #----------------------------------test--------------------------------------# if __name__ == '__main__': epoch_list = [] acc_list = [] for epoch in range(10): train(epoch) epoch_list.append(epoch) acc_list.append(test()) T2 = time.time() print(T2-T1) plt.plot(epoch_list,acc_list) plt.xlabel("Epoch") plt.ylabel("Accuracy") plt.show()
关于课后练习 会单独出论文阅读笔记
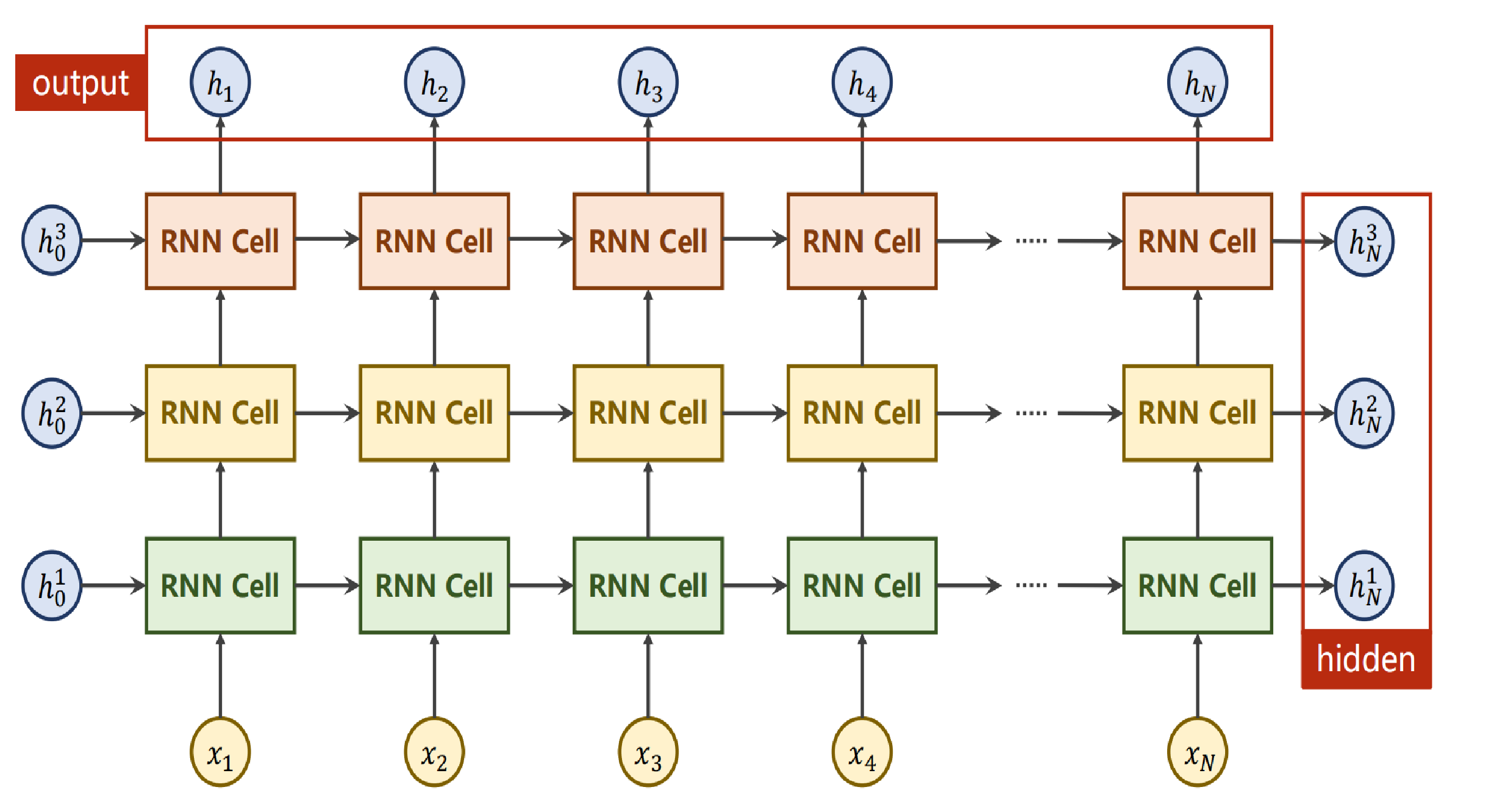
第十二节 循环神经网络 RNN
问题引入
我们在处理问题的时候可能会遇到一些依赖于一定的序列的问题,因此引入了RNN循环神经网络来解决这个问题
RNN
RNN Cell:本质上是一个线性层,包含了序列前一项的信息
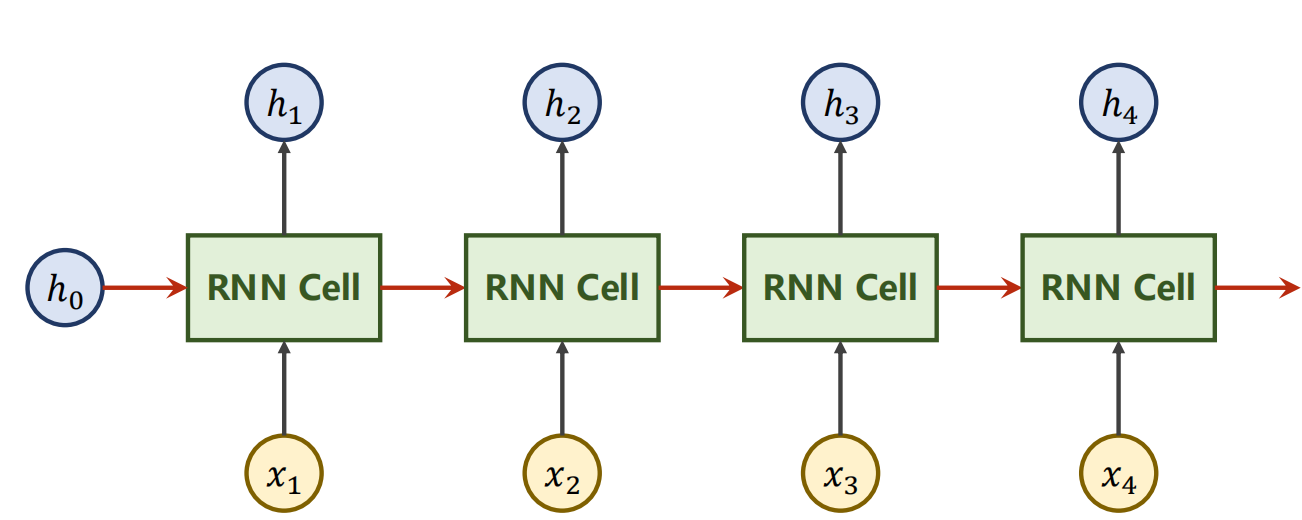
在循环神经网络中我们喜欢使用tanh来进行激活
RNN当中的number_Layer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号