
告别拼凑:记忆、检索与AI数据引擎的一站式技术栈解析(一)
作者:傅榕锋,OceanBase 高级技术专家
AI 开发者需要什么样的数据库
在开始正式话题前,我们不妨先思考一个问题: AI 时代下开发者需要什么样的数据库?
自本世纪初以来数据库需求的演变历程。Web 2.0及业务在线化的时代,强调的是一个可靠、精确的记录系统,能够精准地记录每一笔交易数据,满足典型的事务处理(TP)需求。进入移动互联网和数据智能化时代后,随着数据量的爆发式增长,海量数据分析的需求成为主流。这时,分析型(AP)数据库开始占据重要位置。AI 时代的真正到来,驱动数据库不仅要支持查询和分析功能,更需具备理解和推理的能力。
快来关注我,获取 OceanBase 第一手的产品信息和技术资源,与行业大咖 “唠” 出真知!
AI 时代开发者的痛点
作为数据库从业者,我们需要深入分析 AI 时代下开发者对数据库的具体需求。
数据类型的多维化:在传统数据库中,图片、视频、音频仅能被存储而难以有效利用。借助 AI 模型的帮助,这些非结构化数据可以转化为可检索的形式,如通过嵌入模型转换为向量,或使用大语言模型提取文本描述和标签,从而将非结构化数据转变为结构化或半结构化数据以实现高效检索。
性能与规模的极致化:鉴于向量数据对内存和磁盘资源的高占用特性,在成本与性能之间寻求最佳平衡显得尤为关键。为此,亟需采用高效的算法,以优化召回率与资源成本之间的权衡关系。
智能处理的内生化:例如,在 RAG 场景中,文档需先进行切片并生成向量,这通常涉及向量数据库、文档型数据库以及事务型数据库的联合使用。为了简化这一流程,理想的解决方案是让数据库自身承担更多的标准化数据处理任务,减少开发者的负担。
开发流程的敏捷化:目标是让开发者更加专注于业务逻辑本身,而非陷入复杂的数据处理流程之中。
AI 时代的理想数据库
基于上述痛点,AI 时代的理想数据库应具备以下四个特征。
- 多模态支持:提供统一的平台,支持多种数据类型,包括但不限于向量、全文、标量、 JSON 格式。
- 高性能引擎:针对 AI 工作负载进行优化,确保在控制成本的前提下实现最优性能表现。
- 智能化集成:内置 AI 运行时环境,使数据库可以直接执行复杂的智能处理任务,减少对外部系统的依赖。
- 简易操作:设计直观易用的界面和工具,降低非专业开发者的使用门槛,促进更多领域专家参与到数据处理工作中。
综上所述, AI 时代我们期待的数据库应该是强大、智能、一体化的,是数据与 AI 融合的平台。
AI原生的一体化数据库是否存在
正所谓“需求决定市场”,契合AI时代理想数据库特质的产品必然会出现。而就目前来看,OceanBase 新发布的 seekdb 已率先落地,不仅具备了相关核心能力,更在快速迭代中持续进化。
混搜架构的轻量级、多模态的AI原生数据库
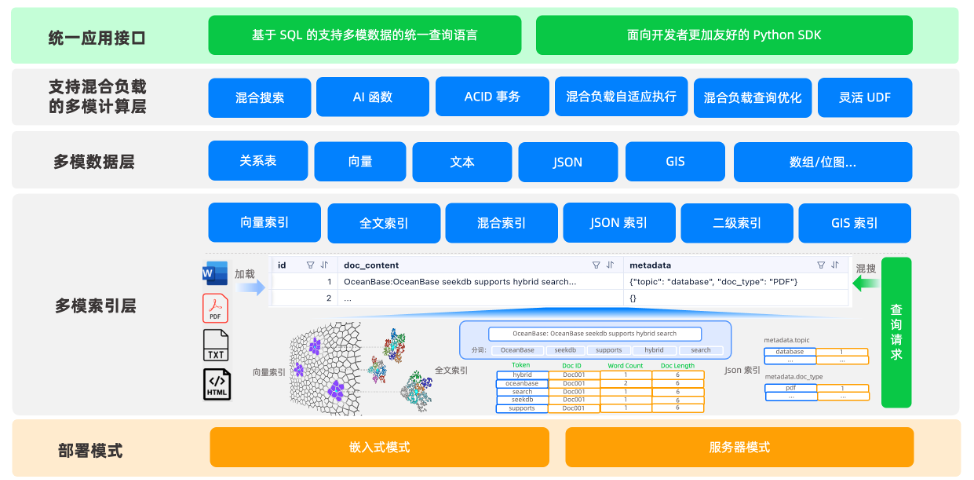
OceanBase seekdb 是一款面向 AI 场景的轻量级、多模态的原生数据库,专为支持混合搜索、上下文理解与智能数据处理而设计。其整体架构分为五个核心层级,实现从数据存储到查询执行的全链路优化。
1. 统一应用接口层。
seekdb提供基于 SQL 的统一查询语言,兼容标准 SQL 语法,支持多模态数据的联合查询。同时,提供面向开发者的 Python SDK,具备简洁易用的 API 接口,支持 skip-by-list 等高效检索模式,显著降低开发者使用门槛。
2. 支持混合负载的多模计算层。
继承自 OceanBase 的成熟优化器体系,seekdb具备强大的查询规划与执行能力,在混合检索场景中,会自动进行自适应执行和查询优化,能够根据查询条件自动选择最优执行路径。同时,支持混合负载自适应执行、AI 函数调用、ACID 事务保障及灵活 UDF 扩展,满足复杂业务需求。
3. 多模数据层。
支持多种数据类型统一存储,实现“存即能检”,打破传统系统中不同数据类型需分库管理的局限。包括:
- 关系表(传统结构化数据)
- 向量(Embedding 向量)
- 文本(原始文本内容)
- JSON(半结构化数据)
- GIS(地理空间数据)
- 数组、位图等扩展类型
4. 多模索引层。
构建业界领先的多模索引体系,支持的索引类型如下。
- 向量索引:高效支持近邻搜索(ANN),兼顾精度与性能。
- 全文索引:支持中文分词与语义匹配。
- 混合索引:结合向量与标量条件进行联合检索。
- JSON 索引:加速嵌套字段查询。
- 二级索引、GIS 索引:满足多样化查询需求。
支持多索引协同查询,在一次请求中完成跨模态数据的融合检索。
5. 部署模式层。
- 服务器模式:传统集群部署,适用于高并发、大规模生产环境。
- 嵌入式模式:以库的形式内嵌于应用程序中,生命周期与应用一致,适合边缘计算、AI 应用快速构建等轻量化场景。
OceanBase seekdb 通过“统一接口 + 多模存储 + 智能索引 + 灵活部署”的一体化设计,实现了对 AI 工作负载的端到端支持,真正做到了“一个数据库,搞定所有数据”。
快速构建:更灵活、更轻量、不止于 SQL
OceanBase seekdb 不仅具备强大的功能,更在易用性和部署灵活性上进行了深度优化,助力开发者快速构建 AI 应用。
1. 更灵活:双运行模式,适配多样场景。
- 服务器模式:适用于企业级、高可用、分布式部署。
- 嵌入式模式:直接集成到 #Python 应用中,无需独立部署数据库服务,极大简化开发流程,特别适合 RAG、Agent、智能问答等轻量级 AI 应用。
2. 更轻量:极简资源占用,轻松跑起基准测试。
单实例仅需 1C2G 内存即可运行 VectorDBBench 基准测试,相比传统数据库,资源消耗更低,启动更快,非常适合本地调试、原型验证和边缘部署。
3. 不止于 SQL:引入 Schemaless SDK。
引入 Schemaless SDK,开发者无需定义表结构即可直接插入和查询数据,提升开发灵活性。
使用seekdb快速创建RAG应用
下面我们演示一下如何使用 seekdb 快使创建一个 RAG 应用。
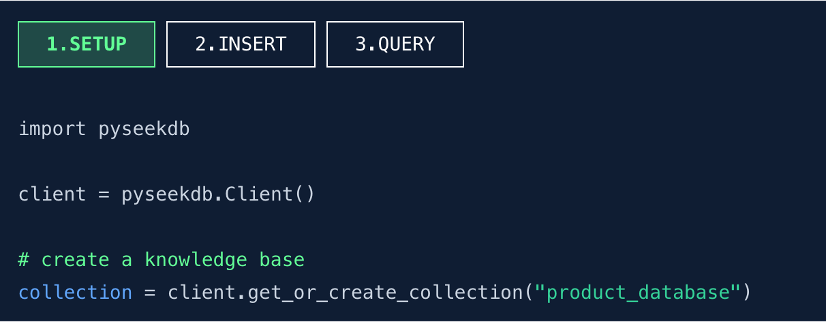
第一步:三行代码快速创建一个知识库(SETUP)
- 导入 pyseekdb 模块,启用 seekdb 的 Python SDK。
- 初始化客户端实例,参数为空表示采用嵌入式模式,数据库生命周期与应用绑定,无需独立部署服务。
- 创建知识库并定义为 Collection。
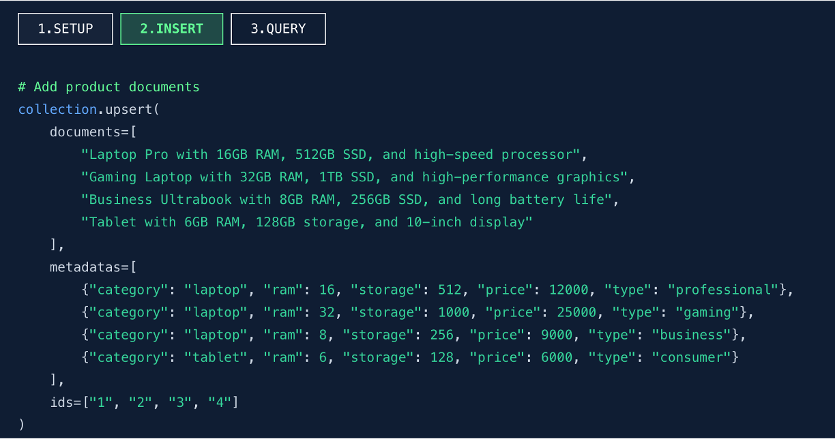
第二步:批量插入文档片段(INSERT)
功能说明:
- 调用 upsert() 函数批量插入文档内容(documents)。
- 同时关联元数据(metadatas),包括分类、内存、存储、价格等结构化信息。
- 显式指定文档 ID(ids),便于后续检索与更新。
关键特性:
- 用户仅需提供原始文本和元数据,无需手动调用嵌入模型生成向量。
- 数据库内部自动调用内置的嵌入模型,将文本转换为向量并存储。
AI 能力下沉至数据库,开发者无需关注向量化过程,seekdb 自动完成文本 → 向量的转换,实现“透明化”处理。
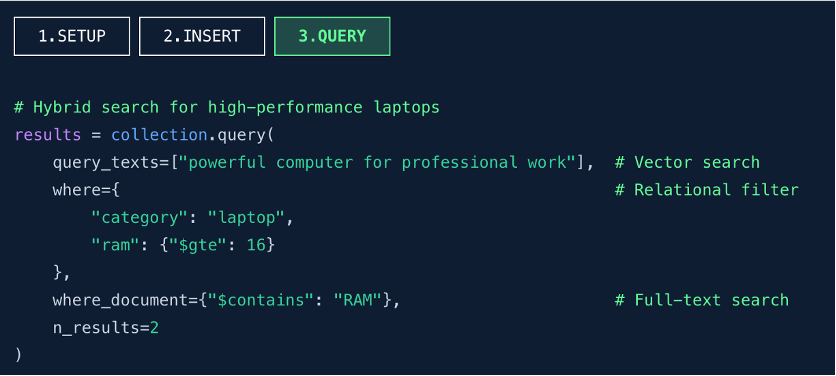
第三步:混合检索,精准召回(QUERY)
查询维度分析:
- query_texts:输入自然语言文本,触发向量检索,用于语义匹配。
- where:设置关系型过滤条件,如 category == laptop 和 ram >= 16,实现精确筛选。
- where_document:基于全文索引进行关键词匹配,要求文档内容包含 “RAM”。
- n_results:限制返回结果数量为 2 条。
实现机制:
- 查询时,seekdb 内部自动将 query_texts 输入传递给嵌入模型,生成查询向量。
- 结合向量索引、全文索引、二级索引等多种索引执行混合检索。
- 最终返回满足所有条件的最相关结果。
第四步:效果展示
输入检索条件为:需要一个 12 GB 内存以上的高性能笔记本。运行后输出结果如下图所示,
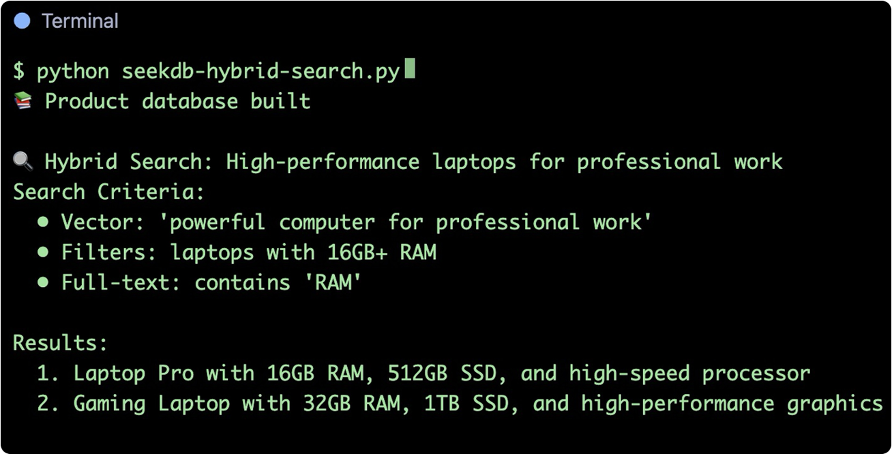
召回结果分析如下。
- 第一条:16GB 内存、512GB 固态的专业笔记本,完全满足“高性能 + 16GB 以上内存”的要求。
- 第二条:32GB 内存、1TB 固态的游戏本,虽非专业用途但性能卓越,符合语义意图。
该案例模拟了典型的 RAG 场景,用户只需输入自然语言问题,系统即可自动完成文本向量化、多条件联合检索、高精度召回。全流程由数据库内核统一处理,极大简化了开发复杂度,真正实现“让开发者专注于业务,而非数据处理”。
欢迎亲自上手试用:https://github.com/oceanbase/seekdb。当前版本支持 Linux 平台下的嵌入式模式运行,Windows 和 macOS 版本将在近期和大家见面。可访问 oceanbase.ai 获取样例代码,支持本地测试与快速验证。
SQL 直接调用 AI 的原生体验
OceanBase seekdb 不仅是一个支持多模态数据存储与混合检索的数据库,更致力于将 AI 能力深度集成于数据库内核,实现“SQL 直接调用 AI”的原生体验。
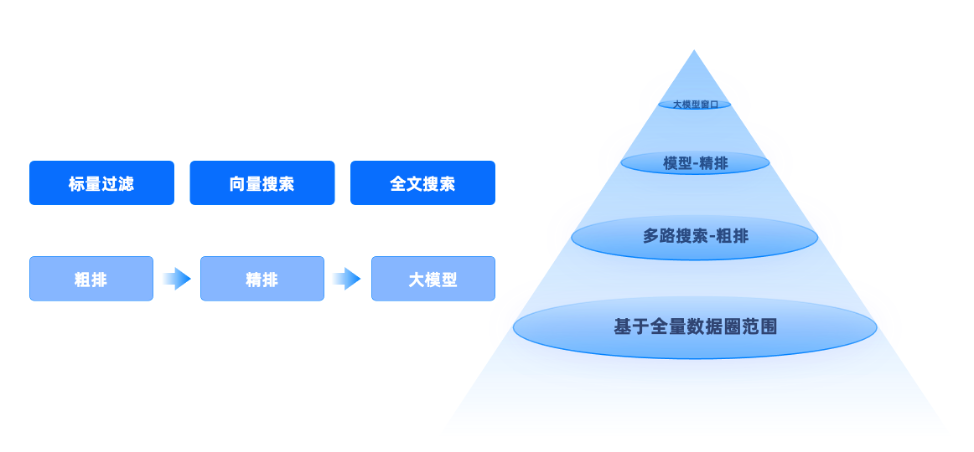
seekdb AI Inside 的内置处理除了 AI_EMBED 方法外,还引入 AI_RERANK 和 AI_COMPLETE,可以实现数据分析自动化、特征提取、智能内容生成、语义搜索增强、结果优化等效果。在 seekdb 中使用可以构建从粗排到精排的高效分层混合检索处理流程。该流程分为四个阶段。
阶段1:标量过滤(Scalar Filtering)。在全量数据集上首先执行关系型条件过滤(如 category = 'laptop', ram >= 16),缩小候选集过滤范围。
阶段2:向量搜索(Vector Search)。对过滤后的候选集执行向量相似度检索,基于语义匹配找出最相关的文档,使用近邻搜索算法(ANN)高效完成高维向量比对。
阶段3:全文搜索(Full-text Search)。在候选集中进一步执行关键词匹配,确保结果包含用户关心的关键信息(如 "RAM"),支持中文分词与模糊匹配,提升召回精度。其中标量、向量、全文的过滤顺序取决于优化器。
阶段4:粗排 → 精排 → 大模型重排。经过以上过滤后得到粗排的结果,此时再去调用 AI_RERANK,数据库会直接调用 RERANK 模型进行精排,精排结束后,通过调用 AI_COMPLETE 即可调用大模型,大模型会直接进行回答。以上所有的 AI 标准操作流程都在数据库中进行,开发者只需在查询中添加相应函数,即可让数据库自动调用大模型对数据进行处理,显著提升用户体验。
OceanBase seekdb 适用场景
OceanBase seekdb 作为一款轻量级、多模态、AI 原生的数据库,凭借其统一存储、混合检索、内嵌 AI 能力 和嵌入式部署支持,在多个新兴与传统智能化场景中展现出显著优势。以下是其典型的适用场景。
1.替代“三库并行”,降本增效
在 RAG 架构中,传统方案通常需要同时维护三类数据库。
- 向量数据库存储文本嵌入向量。
- 文档数据库保存原始文本内容。
- 关系型数据库管理元数据(如分类、时间、权限等)。
这种“三库并行”模式不仅带来高昂的运维复杂度,还导致资源重复占用(三份独立实例),难以在资源受限的本地或边缘环境中落地。seekdb 通过单一数据库统一承载向量、文本与结构化元数据,实现一次写入,多路索引(向量索引 + 全文索引 + 二级索引)、统一查询接口,支持混合条件过滤、极低资源开销(1C2G 即可运行),适合个人本地知识库、中小企业内部知识管理系统、边缘侧智能问答应用等。
2.语义搜索引擎,打破模态壁垒
seekdb 的多模态能力使其天然适配跨模态语义搜索场景。无论是文本、图片、音频还是视频,均可通过嵌入模型转化为统一的向量表示,并结合元数据进行联合检索,通过统一向量 + 元数据 + 全文的混合检索框架,打破模态壁垒。典型应用包括:以图搜图、音频内容检、视频片段语义匹配、多媒体资产管理系统。
3.Agentic AI 应用,保证数据一致性
在 Agentic AI(智能体)场景中,Agent 需要频繁执行上下文感知的混合检索,比如结合用户历史行为(标量过滤)、匹配任务目标语义(向量搜索)、检索相关文档片段(全文匹配)。seekdb 的原生混合检索引擎与内嵌 AI 函数能够高效支撑此类复杂查询,避免外部服务调用带来的延迟与一致性问题。适用于任务型对话系统、自主决策机器人、智能工作流引擎等应用场景。
4.AI 辅助编程,提升质量,降低成本
AI 编程助手存在云端 + 客户端双端检索需求,传统方案面临两大挑战。
- 架构割裂:云端使用多源召回(向量+全文+语法树),客户端依赖轻量插件(如 SQLite + 向量扩展),两套系统逻辑不一致。
- 性能瓶颈:通用数据库缺乏专业向量索引与优化器,召回效果与效率受限。
seekdb 提供统一的 SDK 与查询接口,可使云端与客户端使用同一套 API,且客户端在嵌入式模式下仍具备专业级向量检索能力。seekdb还支持代码语义搜索、API 推荐、错误修复建议等高级功能。通过这些能力统一技术栈,提升召回质量,降低双端开发与维护成本。
5.企业应用智能化丝滑升级
对于大量仍在使用 MySQL 的传统企业应用,seekdb 提供了一条平滑演进路径:
- 高度兼容 MySQL 协议,现有应用可无缝迁移。
- 迁移后即可获得 向量检索、全文搜索、JSON 支持等 AI 原生能力。
- 为未来引入 RAG、智能报表、自动化分析等 AI 功能奠定数据基础。
因此,MySQL 到 OceanBase 的迁移是“最丝滑”的路径之一。seekdb 作为其轻量化延伸,进一步降低了企业智能化转型的技术门槛。
6.端侧应用智能化的理想选择
随着终端设备算力提升,越来越多智能应用向端侧迁移。seekdb 的嵌入式部署能力使其成为端侧智能数据库的理想选择:
- 资源占用极低(1C2G 可运行)。
- 支持离线向量检索与语义理解。
- 生命周期与应用绑定,无需独立服务进程。
- 让端侧应用具备“本地大脑”,减少对云服务的依赖。
典型场景包括:
- 智能家居设备中的本地知识问答。
- 工业机器人中的实时故障诊断。
- 移动端个人助理的上下文记忆管理。
- 车载系统的本地语义导航。
从轻到重、从简到繁: AI 应用快速迭代的理想基础设施
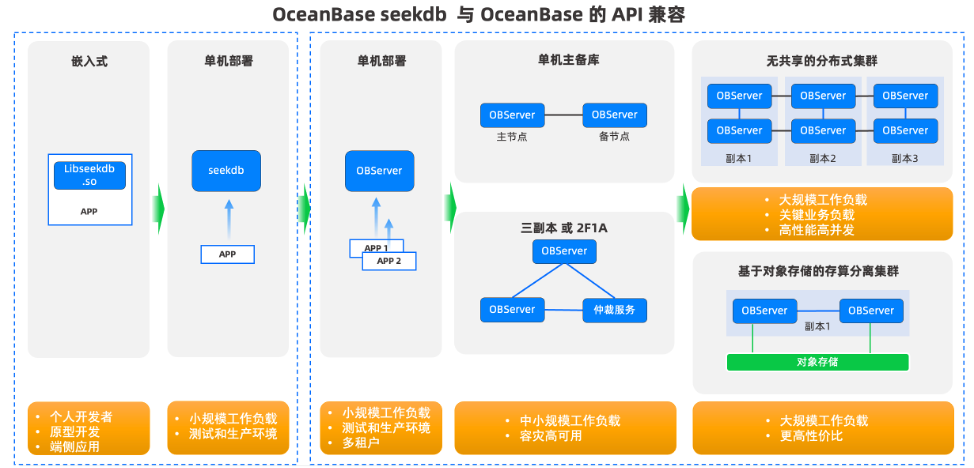
在 AI 应用快速迭代的背景下,开发者面临从原型验证、开发测试到生产部署的多阶段需求。OceanBase 与 seekdb 的深度融合,构建了一套覆盖全生命周期、支持平滑演进的弹性数据库架构,能够满足不同阶段、不同规模场景下的灵活部署需求。
原型验证与开发测试阶段:嵌入式模式(seekdb)
在项目初期,开发者通常需要快速验证 AI 模型效果或构建最小可行产品(MVP)。此时可采用 seekdb 嵌入式模式:
- 将 libseekdb.so 动态库直接集成至应用中,作为本地数据库运行。
- 数据库生命周期与应用绑定,启动即用,关闭即销毁。
- 无需独立部署服务,极大简化环境搭建流程。
- 支持向量、文本、JSON 等多模态数据存储与混合检索。
嵌入式模式适用于个人开发者快速原型开发、端侧智能应用(如移动端、机器人)、本地调试与算法验证等场景。
测试与小规模生产环境:单机部署模式
当应用进入测试或小规模上线阶段,可迁移到单机部署模式:
- 启动独立的 seekdb 进程,提供服务端接口。
- 支持多客户端连接,适合团队协作开发。
- 可通过配置文件管理数据路径、内存参数等。
- 仍保持与嵌入式模式的 API 兼容性,代码无需变更。
单机部署模式适用于小型工作负载、测试环境与生产环境、多租户需求等场景。
生产环境:多租户与高可用架构
随着业务稳定运行,需考虑资源隔离、高可用性和容灾能力,此时可选择以下两种生产级部署方式。
- 单机多租户模式(OceanBase 单机部署) :
- 使用 OceanBase 单机实例,通过多租户机制实现多个业务之间的资源隔离。
- 适用于多个业务共享同一数据库实例但需独立管理资源的场景。
- 支持独立的配额控制、备份策略和监控告警。
- 主备模式 / 三副本模式(OceanBase 高可用架构):
- 采用主备架构或三副本(2F1A)架构,保障数据高可用。
- 支持自动故障切换与读写分离。
- 适用于对稳定性要求较高的中小规模业务系统。
多租户与高可用架构适用于中小规模工作负载、对容灾和高可用有明确要求的业务、多租户共用数据库的 SaaS 平台等场景。
大规模与高性能场景:分布式集群架构
当业务持续增长,数据量和并发请求激增时,可进一步扩展为分布式集群架构。
- 无共享分布式集群 :
- 由多个 OBServer 节点组成,支持水平扩展。
- 支持大规模工作负载、关键业务高并发访问。
- 具备强一致性、线性可扩展性与动态扩容能力。
- 基于对象存储的存算分离集群:
- 存储层使用对象存储(如 OSS),计算层由 OBServer 提供。
- 实现“冷热数据分离”,降低存储成本。
- 适用于海量非敏感数据分析场景(如日志分析、历史归档)。
- 提供更高的性价比与更强的扩展能力。
分布式集群架构适用于大规模工作负载、关键业务系统、高性能高并发、更高性价比的大数据处理任务等场景。
OceanBase 与 seekdb 的组合形成了一个 “从轻到重、从简到繁” 的完整弹性架构体系,核心优势有如下三点。
- API 完全兼容:无论选择哪种部署模式,业务代码无需修改;
- 配置驱动升级:只需更改连接地址与配置参数,即可完成架构迁移;
- 平滑演进路径:支持从个人开发到企业级生产的无缝过渡。
这使得 OceanBase + seekdb 成为 AI 应用快速迭代的理想基础设施,真正实现了“一次开发,全栈适配”,助力企业在 AI 时代加速创新落地。
当然,在AI时代,AI数据库不足以支撑应用所需的完整基础设施能力,因此,OceanBase构建了上下文工程体系中的关键能力。让我们敬请期待下一篇文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号