

结对项目:实现简单四则运算生成器
Java实现简单自动生成小学四则运算题目
项目语言:Java(JDK1.3及以上);
编译运行平台:IntelliJ IDEA;
作者:MDL;MZP;
1.GitHub项目网址:
网址:https://github.com/MDL-MZP/FourFundamentalRules
项目版本下载(当前时间最新版:v2.0):https://github.com/MDL-MZP/FourFundamentalRules/tags
2.个人PSP
PSP(严格来说是基于团队的PSP)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | |
| · Estimate | · 估计这个任务需要多少时间 | 10 | |
| Development | 开发 | 1015 | |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | |
| · Design Spec | · 生成设计文档 | 45 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | |
| · Design | · 具体设计 | 300 | |
| · Coding | · 具体编码 | 300 | |
| · Code Review | · 代码复审 | 120 | |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | |
| Reporting | 报告 | 90 | |
| · Test Report | · 测试报告 | 60 | |
| · Size Measurement | · 计算工作量 | 10 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | |
| 合计 | 1125 |
3.题目介绍与解题思路
3.1题目介绍:
-
使用 -n 参数控制生成题目的个数,例如:Myapp.exe -n 10 将生成10个题目。
-
使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围,例如 Myapp.exe -r 10 ,将生成10以内(不包括10)的四则运算题目。该参数可以设置为1或其他自然数。该参数必须给定,否则程序报错并给出帮助信息。
-
生成的题目中计算过程不能产生负数,也就是说算术表达式中如果存在形如e1− e2的子表达式,那么e1≥ e2。
-
生成的题目中如果存在形如e1÷ e2的子表达式,那么其结果应是真分数。
-
每道题目中出现的运算符个数不超过3个。
-
程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左结合的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。
-
生成的题目存入执行程序的当前目录下的Exercises.txt文件,格式如下:
四则运算题目1
四则运算题目2
……
其中真分数在输入输出时采用如下格式,真分数五分之三表示为3/5,真分数二又八分之三表示为2’3/8。
在生成题目的同时,计算出所有题目的答案,并存入执行程序的当前目录下的Answers.txt文件,格式如下:
1.答案1
2.答案2
特别的,真分数的运算如下例所示:1/6 + 1/8 = 7/24。
-
程序应能支持一万道题目的生成。
-
程序支持对给定的题目文件和答案文件,判定答案中的对错并进行数量统计,输入参数如下:
Myapp.exe -e <exercisefile>.txt -a <answerfile>.txt
统计结果输出到文件Grade.txt,格式如下:
Correct: 5 (1, 3, 5, 7, 9)
Wrong: 5 (2, 4, 6, 8, 10)
其中“:”后面的数字5表示对/错的题目的数量,括号内的是对/错题目的编号。为简单起见,假设输入的题目都是按照顺序编号的符合规范的题目。
3.2解题思路:
分解需求
-
生成计算表达式:
-
第一步先忽略括号的生成,数字和符号随机生成
-
第二步再在第一步的基础上随机在数字周围生成括号
-
删除一些不规范的括号
-
-
筛选不符合规则表达式:
-
一开始想到用树结构将表达式分解,获取符号优先级,那么就判断减号结点的左子树结果减去右子树结果是否为负数;除号结点的右子树是否为0;两条表达式生成两棵树,层次遍历两棵树可判断是否重复
-
后来决定分级别筛选,判断子表达式是否为负数和是否有除数为0的列为粗略筛选,可简单用递归的思想解决
-
而判断是否生成重复表达式,根据式子答案是否相同、长度是否相同、运算符优先级别是否相同、层次遍历是否相同作为精细筛选
-
-
用户输入答案:考虑到后面有一个选择:让用户决定是否校对答案, 就想着”用控制台输入信息“这个点卡住让程序停在这里,然后趁这段时间直接在生成的Exercise.txt文件中进行答题,控制台输入信息后再读取文件,拿到用户答案。但是失败了,读取Exercise.txt文件没有用户输入的答案。个人猜测是文件能read到的部分应该要write进去才行,而手动输入不行。最后把问题转变到控制台输出表达式,在控制台输入获取用户答案。
-
答案校对:
-
生成答案:可以用递归表达式,根据符号优先级一步一步算子表达式,最后得出结果;也可用直接遍历表达式,获取符号优先级,将数字强制放在运算符左右,根据优先级一路进行计算
-
校对答案,比较正确答案和用户答案两个数组内容,同一下标视为同一道题,便可知道答案正确与否
-
4.设计实现过程
4.1项目总体布局:

设计一个主类FourFundamental,用来调用其他功能类。
功能类包括Accuracy(输出正确率类)、CorrectAnswer(输出正确答案类)、Screen类(表达式筛选类)、 CreateCorrectExpression(创建正确表达式类)、File IO(文件读写类)、Input(控制台信息输入输出类)

当运行程序时,Team目录下会自动生成练习文件、答案文件、以及成绩文件
4.2具体类与方法说明与其之间的调用

5.1项目入口:
/** * @date 2020.03.31 * @author Mazin and Uncle-Drew 🌼 * 主类 */ public class FourFundamentalRules { public static void main(String[] args) throws Exception { /** * 提要求:给用户说明怎么使用以及实现最后文件自动删除 */ File file = new File(""); String file_path = file.getAbsolutePath(); File f1 = new File(file_path+"\\Exercise.txt"); File f2 = new File(file_path+"\\Answer.txt"); File f3 = new File(file_path+"\\Grade.txt"); FileIO.createOrFlush(f1); FileIO.createOrFlush(f2); FileIO.createOrFlush(f3); // 输入一些基本信息,如要生成的表达式数目num,和表达式的数值范围limits Input.inputBase(); // 输出表达式,等待用户作答,num:表达式数目,limits:表达式的数值范围 CreateCorrectExpression.outCorrectExpression(Input.num, Input.limits,f1,f2); // 用户答案获取 String[] useranswers = Input.usersAnswer(); // 如果要输出正确率,输入正确命令,表示输出自己答题情况 boolean tag = Input.inputExpand(); if (tag) { System.out.println("及时检查自己的作业哦"); // 写入文件 Accuracy.result(useranswers,f3); }else{ System.out.println("感谢您的使用"); } } }
5.2关键类与方法
-
![]() CreateCorrectExpression
CreateCorrectExpression

-
![]() CorrectAnswer
CorrectAnswer/** * @author Mazin * 答案 */ public class CorrectAnswer { /** * 配合正确输出的算术表达式 并 做出正确答案 * @param correctExpression 经过筛选过后的表达式 * @return 返回表达式的结果 */ public static String answer(String correctExpression) { // 准备接受正确的结果 String s; // 表达式的StringBuffer类型 StringBuffer temp = new StringBuffer(); // 运算符优先级数组 String[] charpriority; // 计算主体 str 数组 String[] str = correctExpression.split(" "); for (int i = 0; i < str.length; i++) { temp.append(str[i]); } // 得到优先级 charpriority = priority(temp); // 得到charpriority的实际长度len int len = 0; for(int j = 0; j < charpriority.length && charpriority[j] != null; j++){ len++; } // 除去括号的 str 数组, 并调整优先级的下标 for(int i = 0; i < str.length;){ // 遇到括号,准备删除 if("(".equals(str[i]) || ")".equals(str[i])){ // 将括号后面的数据全部前移一位 for(int j = i; j < str.length-1; j++) { str[j] = str[j + 1]; } // 需要调整所有的运算符 for(int j = 0; j < len; j++){ // 取出 运算符在 str 数组的下标 int n = Integer.parseInt(charpriority[j]); // 运算符在括号后面才需要 -1 前移 if(n > i){ charpriority[j] = String.valueOf(--n); } } }else{ i++; } } // 按照运算符的顺序. 一个一个传入计算 , 在函数里计算 s = adjust(str,charpriority,len); return s; } /** * 调整表达式,计算算法思想体现 * @param str 表达式的String数组,主要在这里计算 * @param charpriority 运算符的优先级String数组 * @param len 运算符优先级数组的实际长度 * @return 返回运算结果 */ private static String adjust(String[] str, String[] charpriority,int len) { String s = ""; int oldIndex = 0; // count是计量 charpriority数组的实际长度 for(int count = 0; count < len; count++) { // 取出 运算符 在 str 数组的下标 int i = Integer.parseInt(charpriority[count]); // 将第1、2次的累计结果放在 上一次运算符 最靠近下一个运算符 的位置 if (count >= 1) { if (i > oldIndex) { str[oldIndex + 1] = s; } else { str[oldIndex - 1] = s; } } // 如果有3个运算符,那么最后一个,就强制把第二次的结果放到最后一个运算符的临位(左或右) if(count == 2){ if (i > oldIndex) { str[i - 1] = s; } else { str[i + 1] = s; } } // 得到运算符(String)的 char 类型 char[] c = str[i].toCharArray(); // 做计算前的准备,并进入下一层去计算 s = beforeCaculate(str[i - 1],str[i + 1],c[0]); // 记录上一次运算符的位置 oldIndex = i; } return s; } /** * 真分数数值计算, 转化为统一形式 * @param a 参与运算的数字1的String形式 * @param b 参与运算的数字2的String形式 * @param c 运算符的字符形式 * @return 返回运算结果 */ private static String beforeCaculate(String a,String b,char c) { String[] separate1,separate2,temp; int[] num1 = new int[3]; int[] num2 = new int[3]; // 变为统一形式, 要求数字必须为 "整数'分子/分母”形式 if(!a.contains("/")){ a = a + "\'0/1"; }else if(!a.contains("'")){ a = 0 + "'" + a; } if(!b.contains("/")){ b = b + "\'0/1"; }else if(!b.contains("'")){ b = 0 + "'" + b; } // 提取 字符 a ,用separate1数组 separate1 = a.split("'"); temp = separate1[1].split("/"); num1[0] = Integer.parseInt(separate1[0]); num1[1] = Integer.parseInt(temp[0]); num1[2] = Integer.parseInt(temp[1]); // 提取 字符 b ,用separate2数组 separate2 = b.split("'"); temp = separate2[1].split("/"); num2[0] = Integer.parseInt(separate2[0]); num2[1] = Integer.parseInt(temp[0]); num2[2] = Integer.parseInt(temp[1]); // 计算前准备完成,计算 String s = caculate(num1,num2,c); return s; } /** * 选择运算符,通分计算 * @param num1 运算的第一个数 * @param num2 运算的第二个数 * @param c 运算符的字符类型 * @return 返回num1和num2的运算结果 */ private static String caculate(int[] num1,int[] num2,char c){ String s = ""; // up:分子,down:分母 int up1,down1,up2,down2; up1 = num1[0] * num1[2] + num1[1]; down1 = num1[2]; up2 = num2[0] * num2[2] + num2[1]; down2 = num2[2]; // 通分结果,result[0]放分子,result[1]放分母 int[] result = new int[2]; // 简单通分,直接分子分母相乘 up1 = up1 * down2; up2 = up2 * down1; // 通分后分母 result[1] = down1 * down2; // 选择运算符 switch (c) { case '+': result[0] = up1+up2; break; case '-': result[0] = up1-up2; break; case '÷': result[0] = up1 * result[1]; result[1] = up2 * result[1]; break; case '×': result[0] = up1*up2; result[1] = result[1] * result[1]; break; default: } // 整数部分 int integer = result[0] / result[1]; // 分子部分 int fraction = result[0] % result[1]; // 因为最后需要除以公约数,防止除以0,因为0和其他数的最大公约为0 if(fraction != 0) { // 求最大公约数 int common = f(fraction, result[1]); // 约分 fraction = fraction / common; result[1] = result[1] / common; } // 选择输出的形式 if (integer != 0) { if(fraction != 0) { s = integer + "'" + fraction + "/" + result[1]; }else{ s = integer + ""; } } else { if(fraction != 0) { s = fraction + "/" + result[1]; }else{ s = "0"; } } return s; } /** * 辗转相除 求最大公约数,down大 up小 * @param up 分子 * @param down 分母 * @return 返回up和down的最大公约数 */ private static int f(int up,int down){ int temp; while(true) { temp = down % up; if (temp == 0) { return up; } else { down = up; up = temp; } } } /** * 计算符号优先级 * @param temp 表达式的StringBuffer类型 * @return 返回排好运算符优先级的String[]数组,[0]优先级最高 */ private static String[] priority(StringBuffer temp) { String[] newstr; StringBuffer t = new StringBuffer(temp); // 4个括号的下标数组,初始化-1 // blankets 记录 表达式StringBuffer类型的 括号下标,[0][1]记录外层括号,[2][3]记录内层括号 int[] blankets = {-1, -1, -1, -1}; // real 记录 表达式String[]类型的 括号下标,(主要)[0][1]记录外层括号,[2][3]记录内层括号 int[] real = {-1,-1,-1,-1}; blankets[0] = t.indexOf("("); if(blankets[0] != -1) { t.deleteCharAt(blankets[0]); if (t.indexOf("(") == -1) { // 仅有一个括号,且被删除了 ( blankets[1] = t.indexOf(")") + 1; } else if (t.indexOf("(") > t.indexOf(")")) { blankets[1] = t.indexOf(")") + 1; // 被删除了 ( blankets[2] = t.indexOf("(") + 1; blankets[3] = t.lastIndexOf(")") + 1; } else { blankets[1] = t.lastIndexOf(")") + 1; blankets[2] = t.indexOf("(") + 1; blankets[3] = t.indexOf(")") + 1; } } // real先拿到blankets的值,再做更新 for(int i = 0; i < 4; i++){ real[i] = blankets[i]; } // 更新real为 str 数组的括号下标,一共4个括号 for(int j = 0; j < 4; j++) { // flag 用于多位数的 计数,如 123 应该记为 1。 boolean flag = true; // count是记录实际 str 数组的括号下标,-1表示不存在 int count = -1; if(real[j] != -1) { x: // 在遇到 指定 的括号前,计数 数字、运算符、其他括号 for (int i = 0; i <= real[j]; i++) { boolean tag1 = (temp.charAt(i) >= 48 && temp.charAt(i) <= 57); boolean tag2 = temp.charAt(i) == '×' || temp.charAt(i) == '-' || temp.charAt(i) == '+' || temp.charAt(i) == '÷'; // 遇到数字 if (tag1 && flag) { count++; flag = false; } // 遇到运算符 if (tag2) { count++; flag = true; } // 遇到括号,是否为 指定 括号待定 if (!tag1 && !tag2) { // 到达末尾,则为 指定 括号 if (i == real[j]) { real[j] = ++count; break x; } // 不是 指定 括号 else{ flag = true; count++; } } } } } //求表达式StringBuffer类型下的运算符和下标,不考虑优先级,直接从左到右读取运算符 String[] oldstr = charAndIndex(temp); // 结合括号,运算符 整理得到 最终 按优先级排序的 运算符 的 下标 newstr= sort(blankets, oldstr,temp,real); return newstr; } /** * 统计括号的情况, * @param blankets 表达式StringBuffer类型的 括号下标 * @param oldstr 表达式 运算符及其下标的数组,下标在前,运算符在后 * @param expression 表达式的StringBuffer类型 * @param real 表达式String数组类型的 括号下标 * @return 返回排好运算符优先级的String[]数组,[0]优先级最高,且只存下标,该下标针对表达式的String数组下标 */ private static String[] sort(int[] blankets, String[] oldstr,StringBuffer expression,int[] real) { String[] newstr = new String[6]; // 将oldstr数组拷贝到 oldstring 数组 String[] oldstring = new String[6]; for(int i = 0 ; i < 6; i++){ oldstring[i] = oldstr[i]; } // 按照无括号的形式排序优先级得到all,其实只是为了方便找到未进行排序的运算符下标 String[] all = blanketsJudge(oldstr); // all 和 oldstr 的区别:对整条表达式,all比较了优先级(“忽视”括号的情况),oldstr未比较优先级,只是从左到右记录 // 无内层括号 if (blankets[2] == -1) { // 无内层无外层括号 if (blankets[0] == -1) { // 无括号便是 all 的情况 newstr = all; return newstr; } else { String[] str; // 截取出括号内的表达式,这也是为什么要blankets的原因 StringBuffer s = new StringBuffer(expression.substring(blankets[0]+1,blankets[1])); // 求出括号内表达式的运算符和下标 str = charAndIndex(s); //截取出来的运算符下标,这个下标是在str数组内的,所以少了括号的下标用real,要加上 int j = 0; while(str[j] != null){ str[j] = String.valueOf(Integer.parseInt(str[j]) + real[0] + 1); j += 2; } // 对括号内的运算符做优先级排序,输出运算符下标 newstr = blanketsJudge(str); // 算str的实际长度, 其实也就是 newstr现有长度的两倍 int len = 0; for(j = 0; str[j] != null; j++){ len++; } len /= 2; // 找到,未进行排序的 运算符下标, 而all已经排序了,从头找到未进行排序的下标,按顺序添加至newstr末尾就行 x: for (int i = 0; i < all.length && all[i] != null;i++) { for (int x = 0; newstr[x] != null; x++) { if (newstr[x].equals(all[i])) { continue x; } } newstr[len++] = all[i]; } return newstr; } }else{ //2个括号,一定是3个运算符 String[] temp = new String[6]; int j = 0, p; String[] str1; String[] str2; // 双括号嵌套 if(blankets[1] > blankets[2]) { // 截取括号内的StringBuffer表达式 StringBuffer s1 = new StringBuffer(expression.substring(blankets[0] + 1, blankets[1])); StringBuffer s2 = new StringBuffer(expression.substring(blankets[2] + 1, blankets[3])); // 求出括号内表达式的运算符和下标 str1 = charAndIndex(s1); str2 = charAndIndex(s2); // 截取出来的运算符下标,这个下标是在str数组内的,所以少了括号的下标用real,要加上 while (str2[j] != null) { str2[j] = String.valueOf(Integer.parseInt(str2[j]) + real[2] + 1); j += 2; } j = 0; while (str1[j] != null) { str1[j] = String.valueOf(Integer.parseInt(str1[j]) + real[0] + 1); j += 2; } //str2是必定是最内层括号内的 下标和运算符 newstr[0] = str2[0]; // 比较外层括号里的2个运算符,找到跟内层括号不同的运算符下标 if (str1[0].equals(str2[0])) { newstr[1] = str1[2]; } else { newstr[1] = str1[0]; } x: // 第3个运算符需要跟 all 比较,少的那个直接加到 newstr 末尾 for (p = 0; p < all.length; p++) { for (int x = 0; newstr[x] != null; x++) { if (newstr[x].equals(all[p])) { continue x; } } newstr[2] = all[p]; break x; } return newstr; } // 平行双括号(1+2)-(3+4), 那么,必定是第一个运算符,第三个运算符,第二个运算符这样的顺序 else{ newstr[0] = oldstring[0]; newstr[1] = oldstring[4]; newstr[2] = oldstring[2]; return newstr; } } } /** * 输出 str数组内运算符 按优先级排序好的顺序, 记录下标 * @param str 需要作运算符优先级判断的数组 * @return 返回str数组内运算符的优先级顺序 */ private static String[] blanketsJudge(String[] str){ boolean tag1,tag2,flag = false,endtag = true; // temp用来记录 +- 符号的 下标 int temp = -1,j = 0; for(int i = 1; i < str.length; i+=2) { // 拿出下标对应的运算符 tag1 = "+".equals(str[i]) || "-".equals(str[i]); tag2 = "×".equals(str[i]) || "÷".equals(str[i]); // 遇到 +- if (tag1) { // flag 表示先遇到+-在遇到×÷,那么就需要调整优先级 flag = true; // temp 记录 +- 下标 temp = i; } // 遇到×÷ if (tag2) { // flag为true,就是需要交换了(+-在×÷之前),到时候直接从数组开头到末尾读取 if (flag) { // 把下标和运算符都交换 swap(str, i, temp); swap(str, i - 1, temp - 1); // 有交换,那么不结束 endtag = false; // temp 跟进 +- 号 temp = i; } // 如果前面不做交换,那么有结束的前提 else { endtag = true; } } // 结束的标志有 endtag,且得到表达式末尾 if (!endtag && i == str.length - 1) { // 到达末尾,但不能结束,那么,初始化数据,重新遍历,i=-1,是为了i+=2能变成1 flag = false; temp = -1; i = -1; } // endtag为true表示可以结束了,如果此时到末尾,直接结束 else if (endtag && i == str.length - 1) { break; } // 处理下一个运算符 } String[] newstr = new String[6]; // 输出排序后, 运算符的下标,偶数下标 for(int index = 0;index < str.length; index+=2){ newstr[j++] = str[index]; } return newstr; } private static void swap(String[] oldstr,int a,int b){ String temp; temp = oldstr[a]; oldstr[a] = oldstr[b]; oldstr[b] = temp; } /** * 求运算符和下标 * @param temp 表达式的StringBuffer类型 * @return 返回运算符及其下标的数组,下标在前,运算符在后 */ private static String[] charAndIndex(StringBuffer temp){ int count = -1 ; // flag 计数 运算符前的 个数 boolean flag = true; String[] oldstr = new String[6]; for (int i = 0, j = 0; i < temp.length(); i++) { // 数字 boolean tag1 = (temp.charAt(i) >= 48 && temp.charAt(i) <= 57); // 括号或= boolean tag2 = temp.charAt(i) == '(' || temp.charAt(i) == ')' || temp.charAt(i) == '='; // 遇到数字,且flag为true,flag是保证在多位数情况下正确计数 if(tag1 && flag){ count++; flag = false; } // 遇到括号或= if(tag2){ count++; flag = true; } // 遇到运算符 if (!tag1 && !tag2) { // 运算符的下标 oldstr[j++] = String.valueOf(++count); // 运算符 oldstr[j++] = String.valueOf(temp.charAt(i)); flag = true; } } return oldstr; } }
-
![]() Accuracy
Accuracy/** * @author Mazin * 正确率Result */ public class Accuracy{ /** * 输出正确率到文件中,需要比较userAnswers和Answers * @param userAnswers 用户答案 * @param grade 正确率文件 * @throws Exception */ public static void result(String[] userAnswers,File grade) throws Exception { // 拿到正确答案集,和用户答案做比较 // 正确题目数和错误题目数 int correctNum = 0; int wrongNum = 0; // 正确行输出 String correctIndex = ""; // 错误行输出 String wrongIndex = ""; // 得到标准答案数组 String[] answers = CreateCorrectExpression.getAnswers(); String[] write = new String[2]; for (int i = 0; i < answers.length && answers[i] != null; i++) { // 相同下标,用户答案和标准答案一样便是正确 if (answers[i].equals(userAnswers[i])) { correctNum++; // +1 是为了达到正确的题目序号,保存所有正确的题目序号 correctIndex += i + 1 + " ,"; } else { wrongNum++; wrongIndex += i + 1 + " ,"; } } StringBuffer s1 = new StringBuffer(correctIndex); StringBuffer s2 = new StringBuffer(wrongIndex); // 正确数为0,就不加上后面的括号() if (correctNum != 0){ s1.insert(0, "( "); // 取代末尾的 , 变为 ) s1.replace(s1.length()-1,s1.length(),")"); } if(wrongNum != 0) { s2.insert(0, "("); s2.replace(s2.length()-1,s2.length(),")"); } correctIndex = s1.toString(); wrongIndex = s2.toString(); // 拼接 write[0] = "Correct : " + correctNum + " " + correctIndex; write[1] = "Wrong : " + wrongNum + " " + wrongIndex; write(grade,write); } /** * 专门用于Grade文件的写 * @param fileName Grade.txt * @param content 写入Grade.txt文件的内容 * @throws Exception */ private static void write(File fileName,String[] content) throws Exception{ FileWriter fw = new FileWriter(fileName); for(int i = 0; i < content.length; i++) { fw.write(content[i]); fw.write("\n"); } fw.close(); } }
-
![]() IsRepeatExpression
IsRepeatExpressionpublic class IsRepeatExpression { private Ruler ruler = new Ruler(); /** * * 完成从后缀表达式构造查重表达式的过程(主要是运用堆栈的做法,基本和计算后缀表达式一样的做法). * 以后缀的长度循环,遇到数字压栈,遇到字符连续出栈两个数字字符,出栈后将“#”压入数字栈,这个字符只起占位的作用, * 方便代码编写.循环结束后即可得到查重表达式 * */ public void getisrepeatExpressionArray(String[] targetArray, Expression expression){ String topStr= null;//栈顶的字符串 int isrepeatArrayLength = 0;//用于表示查重表达式的长度 Stack<String> stack = new Stack<String>(); int lenth = ruler.getTrueLength(targetArray);//获得后缀表达式的真实长度 String tempStr = null; for (int i = 0; i < lenth; i++) {// 字符串的长度超过一,代表这是数字则压栈 if (targetArray[i].length() > 1||targetArray[i].equals("#")) { stack.push(targetArray[i]); } else {// 代表这是运算符 expression.getisrepeatExprssion()[isrepeatArrayLength++] = targetArray[i];//加入到查重表达式中 topStr = stack.pop(); if(!topStr.equals("#")){ expression.getisrepeatExprssion()[isrepeatArrayLength++] = topStr;//加入到查重表达式中 } topStr = stack.pop(); if(!topStr.equals("#")){ expression.getisrepeatExprssion()[isrepeatArrayLength++] = topStr;//加入到查重表达式中 } stack.push("#"); } } } /** * * * @param exp1 要查重的表达式一 * @param exp2 要查重的表达式二 * @return 这两表达式是否重复 */ public Boolean isrepeatExression(Expression exp1, Expression exp2){ String [] isrepeatStrArray1 = exp1.getisrepeatExprssion(); String [] isrepeatStrArray2 = exp2.getisrepeatExprssion(); int arrayLenth1 = ruler.getTrueLength(isrepeatStrArray1); //获得表达式一查重数组的真实长度 int arrayLenth2 = ruler.getTrueLength(isrepeatStrArray2);//获得表达式二查重数组的真实长度 if(arrayLenth1!=arrayLenth2) return false;// 若数组长度不相等,则表达式一定不同. if(ruler.arrayToString(isrepeatStrArray1).equals(ruler.arrayToString(isrepeatStrArray2))) return true; //如果查重数组完全一致则是为重复数组. if(isrepeatStrArray1[0].equals("+")||isrepeatStrArray1[0].equals("*")){//只有加或乘的情况才可能出现 交换左右操作数当做重复的表达式 String temp = isrepeatStrArray1[1]; //交换首个符号之后的两个数字 isrepeatStrArray1[1] = isrepeatStrArray1[2]; isrepeatStrArray1[2] = temp; } //若交换后相等则也为重复. if(ruler.arrayToString(isrepeatStrArray1).equals(ruler.arrayToString(isrepeatStrArray2))) return true; //如果查重数组完全一致则是为重复数组. return false; } }
-
![]() Screen
Screen/** * *核心思想用递归方法解决算术表达式的分解、判断 * 注释中基础表达式是指一个运算符两个运算数子,例如:"1 - 2" *@description: 筛选类,包含筛选表达式所使用的方法 *@author: MDL *@time: 2020.3.31 * */ public class Screen { static Screen screen = new Screen(); /** * 粗略筛选 * @param exps 算术表达式字符串,数字和符号用空格隔开 * @return 返回字符串,如果为"false"则表明算术表达式不符合 */ public String roughScreen(String exps){ String result = "";//存放结果字符串 String[] exps_array = screen.splitExpression(exps);//得到分隔后的字符串数组 if (exps_array.length == 1){//字符串数组只有一位表示为数字 result = exps;//直接返回值 }else if (exps_array.length == 3){//一个基础的算术表达式,例如:"1 - 2" if (true == baseExpression(exps)){//判断是否符合基础规则 result = screen.espressionResult(exps);//计算返回值 }else{ result = "false";//不符合基本规则返回"false"用于递归 } }else if(exps.equals("false")){//递归时用于判断 result = "false"; }else { String left_exps = "";//左算术式 String left_result = "";//左算术式结果 String right_exps = "";//右算术式 String right_result = "";//右算术结果 int[] adr_array = screen.operator(exps);//获取算术表达式的运算符优先级,存放的为所在原字符串数组下标 int adr = adr_array[adr_array.length-1];//获取当前算术运算符 for (int i = 0;i <= adr-1;i++){//以当前算术运算符向左拼接表达式获取左表达式 left_exps += exps_array[i] + " "; } left_exps = screen.deleteBracket(left_exps);//去括号 for (int j = adr+1;j <= exps_array.length-1;j++){//以当前算术运算符向右拼接表达式获取右表达式 right_exps += exps_array[j] + " "; } right_exps = screen.deleteBracket(right_exps); left_result = screen.roughScreen(left_exps);//左表达式递归 right_result = screen.roughScreen(right_exps);//右表达式递归 if (!left_result.equals("false") && !right_result.equals("false")){//左右子表达式都符合要求 String new_exps;//把左结果和右结果以及运算符结合成新的运算式 new_exps = left_result + " " + exps_array[adr]+ " "+ right_result;//生成新的基本表达式 if (true == baseExpression(new_exps)) {//新的基本表达式是否符合基础要求 result = screen.espressionResult(new_exps);//计算结果 }else{ result = "false";//新基础表达式不符合 } }else { result = "false"; } } return result; } /** * 去除算术表达式括号 * @param exps 算术表达式字符串,数字和符号用空格隔开 * @return 返回去掉首尾括号的算术表达式字符串 */ public String deleteBracket(String exps){ String[] exps_array = screen.splitExpression(exps);//得到分隔后的字符串数组 //首尾是否右括号 if (exps_array[0].equals("(") && exps_array[exps_array.length-1].equals(")")){ return exps.substring(2,exps.length()-2); }else { return exps; } } /** * 粗略计算基本表达式结果,不作真分数、分数运算 * @param exps 算术表达式字符串,数字和符号用空格隔开 * @return 返回数值用字符串表示 */ public String espressionResult(String exps){ String result_str;//运算结果 String[] exps_array = screen.splitExpression(exps);//得到分隔后的字符串数组 //默认左右运算数用double运算 double left = Double.parseDouble(exps_array[0]); double right = Double.parseDouble(exps_array[2]); double result; switch (exps_array[1]){ case "+": result = left + right; result_str = String.valueOf(result); break; case "-": result = left - right; break; case "×": result = left * right; break; case "÷": result = left / right; break; default: result = -1; } result_str = String.valueOf(result)+ " ";//结果尾处加一空格,方便字符串分解 return result_str; } /** * 获取算术表达式运算符的优先级 * 核心思想遍历一次算术表达式,依次将括号内的运算符、乘除、加减所在数组位置放入各自优先级数组位置,记录的是运算符的地址 * @param total_exps 算术表达式字符串,数字和符号用空格隔开 * @return 返回数组记录运算符优先级所在地址 */ public int[] operator(String total_exps){ String[] exps_array = screen.splitExpression(total_exps);//得到分隔后的字符串数组 int[] adr_add = new int[3];//记录加减号地址的数组 int[] adr_minus = new int[3];//记录乘除号地址的数组 int[] adr_bracket = new int[3];//记录括号内运算符地址的数组 int count = 0;//运算符数量统计 int adr_bracket_i = 0;//括号优先级数组下标 int adr_add_i = 0;//加减号优先级数组下标 int adr_minus_i =0;//乘除号优先级数组下标 int adr_i = 0;//总优先级数组下标 int j; for (int i = 0;i < exps_array.length; ++i){ if (exps_array[i].equals("(")){//括号优先级 if (exps_array[i+1].equals("(")){//例如:((1+2)+3) adr_bracket[adr_bracket_i] = i + 3; adr_bracket[adr_bracket_i+1] = i + 6; adr_bracket_i = adr_bracket_i +2; i = i + 8; count+=2; }else if (exps_array[i+3].equals("(")){//例如:(1+(1+2)) adr_bracket[adr_bracket_i] = i + 5; adr_bracket[adr_bracket_i+1] = i + 2; adr_bracket_i = adr_bracket_i +2; i = i + 8; count+=2; }else if (exps_array[i+4].equals(")")){//例如:(1+2)+3 adr_bracket[adr_bracket_i] = i + 2;//存放符号所在exps_array数组地址 adr_bracket_i++; i = i + 4; count++; }else if (exps_array[i+6].equals(")")){//例如:(1+2+3)+4 if (exps_array[i+2].equals("×") || exps_array[i+2].equals("÷")){ adr_bracket[adr_bracket_i]= i + 2; adr_bracket[adr_bracket_i+1] = i + 4; }else{ // (exps_array[i+2].equals("+") || exps_array[i+2].equals("-")) if (exps_array[i+4].equals("×") || exps_array[i+4].equals("÷")){ adr_bracket[adr_bracket_i]= i + 4; adr_bracket[adr_bracket_i+1] = i + 2; }else { adr_bracket[adr_bracket_i]= i + 2; adr_bracket[adr_bracket_i+1] = i + 4; } } adr_bracket_i = adr_bracket_i + 2; i = i + 6; count+=2; } }else if(exps_array[i].equals("×") || exps_array[i].equals("÷")){ adr_minus[adr_minus_i] = i; adr_minus_i++; count++; }else if (exps_array[i].equals("+") || exps_array[i].equals("-")){ adr_add[adr_add_i] = i; adr_add_i++; count++; } } int[] adr = new int[count];//总优先级数组 for ( j = 0;adr_bracket_i != 0 && j <= adr_bracket_i-1;j++){//依次存入括号优先级运算符地址 adr[adr_i] = adr_bracket[j]; adr_i++; } for ( j = 0;adr_minus_i != 0 && j <= adr_minus_i-1;j++){//依次存入乘除号优先级运算符地址 adr[adr_i] = adr_minus[j]; adr_i++; } for ( j = 0;adr_add_i != 0 && j <= adr_add_i-1;j++){//依次存入加减号优先级运算符地址 adr[adr_i] = adr_add[j]; adr_i++; } return adr; } /** * 分割字符串,以空格为标志将运算数、运算符号、括号作为字符串存入字符串数组 * @param exps 算术表达式字符串,数字和符号用空格隔开 * @return 返回字符串数组 */ public String[] splitExpression(String exps){ //以空格为标志 String[] exps_array = exps.split(" +"); return exps_array; } /** * 基础算术表达式判断,是否会出现负数结果,是否会出现除数为0 * @param base_exps 基础算术表达式字符串,数字和符号用空格隔开 * @return true:符合规则;false:不符合规则 */ public boolean baseExpression(String base_exps){ String[] exps_array = screen.splitExpression(base_exps);//得到分隔后的字符串数组 //表达式只有一个运算符的,例如"1 + 2" if (exps_array.length == 3){ if (exps_array[1].equals("÷")){//运算符是除号 if(screen.zeroBehindDenominator(exps_array[2]) == true)//除数为0 return false; }else if(exps_array[1].equals("-")){//运算符号是减号 if (screen.negativeExps(exps_array[0],exps_array[2]) == true)//子运算式为负数结果 return false; } return true; }else { return false; } } /** * 判断除数是否为0 * @param s 除数,字符串类型 * @return true:除数为0;false:除数不为0 */ public boolean zeroBehindDenominator(String s){ //字符串只有一位且为“0”; if (s.equals("0") || s.equals("0.0")){ return true; }else { return false; } } /** * 基本运算式是否会出现负数 * @param s1 被减数字符串 * @param s2 减数字符串 * @return true:运算结果为负数;false:运算结果不为负数 */ public boolean negativeExps(String s1,String s2){ double num1,num2; num1 = Double.parseDouble(s1); num2 = Double.parseDouble(s2); //比较被减数与减数关系 if (num1 < num2) { return true; }else { return false; } } }

-
有关算术表达式生成范围,目前仍未实现生成分数或者真分数
-
用户答案输入不能完全识别是否为分数,例如:3‘‘’‘’‘’‘’、/1、////、‘’‘’‘’程序也识别为答案
-
有关筛选类和生成答案类相当一部分代码功能相同但是由于分工合作交流不当编写时产生冗余部分仍需改进
-
关于判断算术表达式是否有重复功能,例如(1+2)*(3+4) 和(4+3)*(2+1)此类型表达式我们尚未想出办法解决,基于初步想法也只想出精确筛选表达式是否会有重复可以分三种情况进行,且筛选正确率逐步提升:
-
依据两式子答案相同、字符串长度相同、运算符计算优先级相同判断为两表达式等价:
-
将获取式子的优先级和运算数提取成查重表达式,例如: 原式为:3*(1+2) +5 其后缀为 1 2 + 3 * 5 +,依据加号和乘号两边数据可调换,判断传入两表达式的查重式是否相同判断是否等价
![]() 待改进
待改进 -
而对于可执行交换律的运算符“*”和“+”,当出现三个运算符都是此两种时,仍未想出具体算法可以准确且高效判断是否等价
6.效能分析与测试运行
6.1效能分析与改进

数据类型消耗,char[] 、Object[]、String[] 、StringBuffer 类型用得最多

内存消耗,只有一条线程main
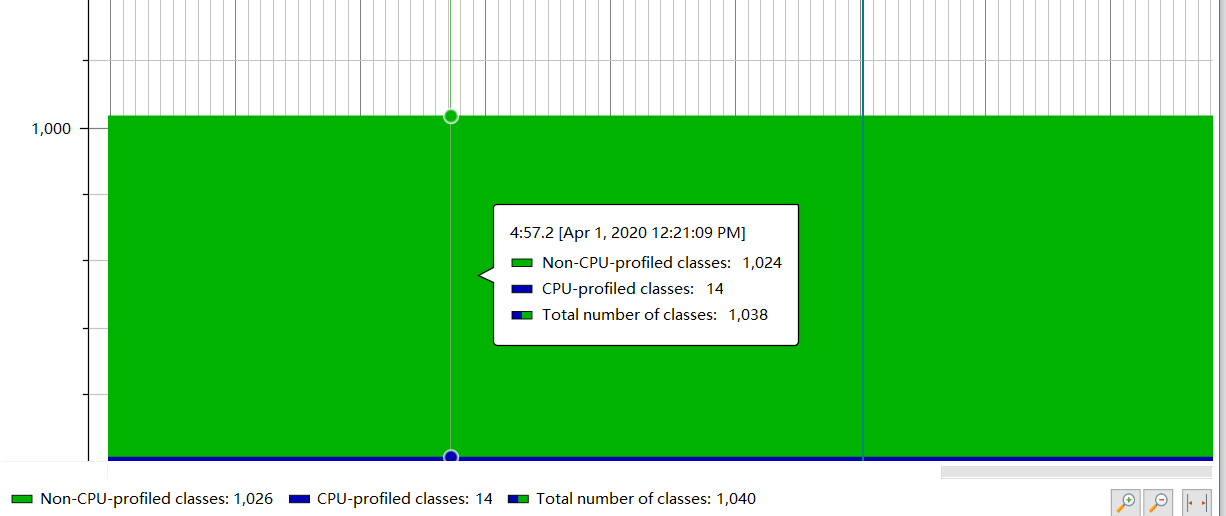
class占用cpu
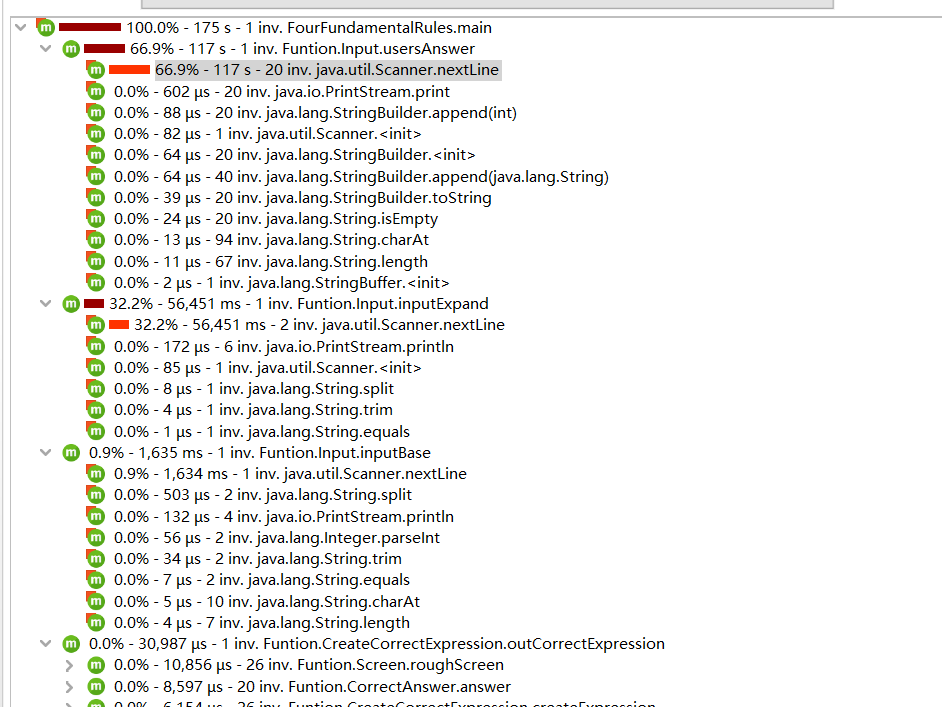

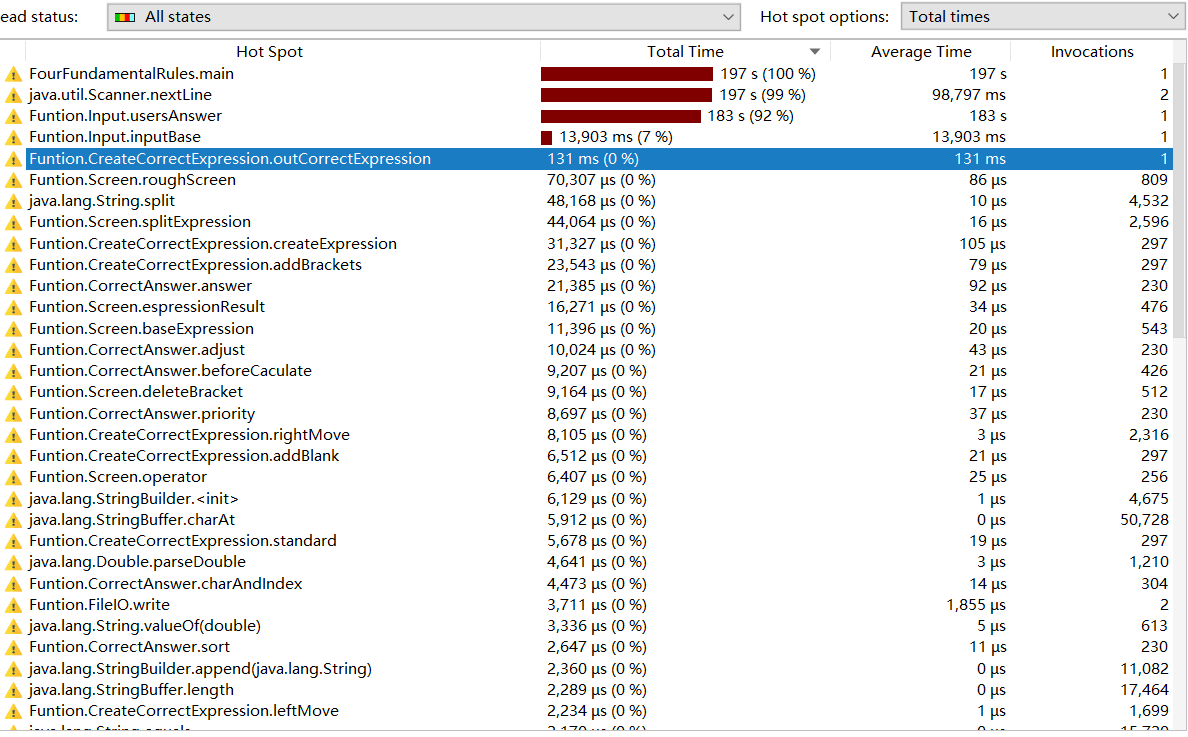
由图可知,几乎都消耗在String.nextLine()输入上,特别是最后一步在控制台获取用户答案时,占用了后面几乎所有的资源
6.2用例测试
使用说明:
(1)点击运行程序,首先需要输入命令和两个数字,“-n ”命令后面加第一个数字num,表示控制生成的题目数量num、“-r ”命令后面加第二个数字,表示控制题目中出现的数字的数值范围 [ 0 , limits )。
(2)接着,会在控制台自动出现一条表达式,需要作完一道题后才能出现下一道,没法跳过题目做下一道题。所有的题目都保存在当前目录的Exercise.txt文件,标准答案在Answer.txt文件。
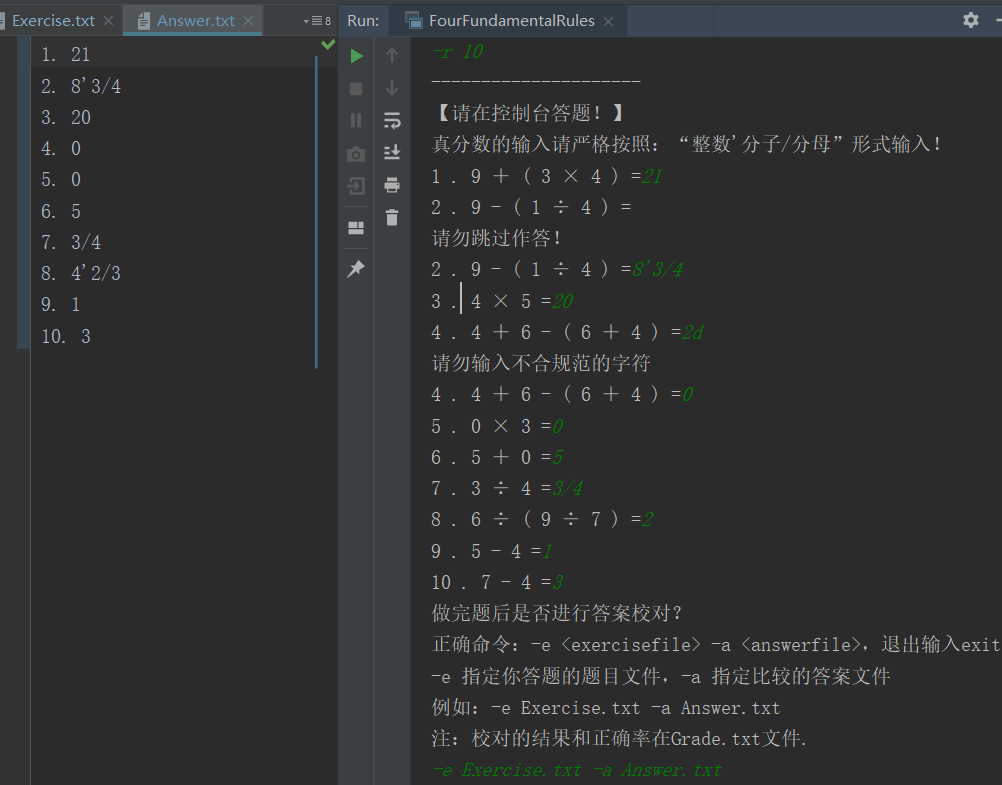
(3)做完题目后,选择是否进行校对答案。输入“ -e -a ”命令表示校对,校对的结果在当前目录下的Grade.txt文件;输入 “ exit ” 表示退出,虽然退出了,但是还是要记得校对答案哦。
-
校对答案例子(包括用户的一些错误输入处理)



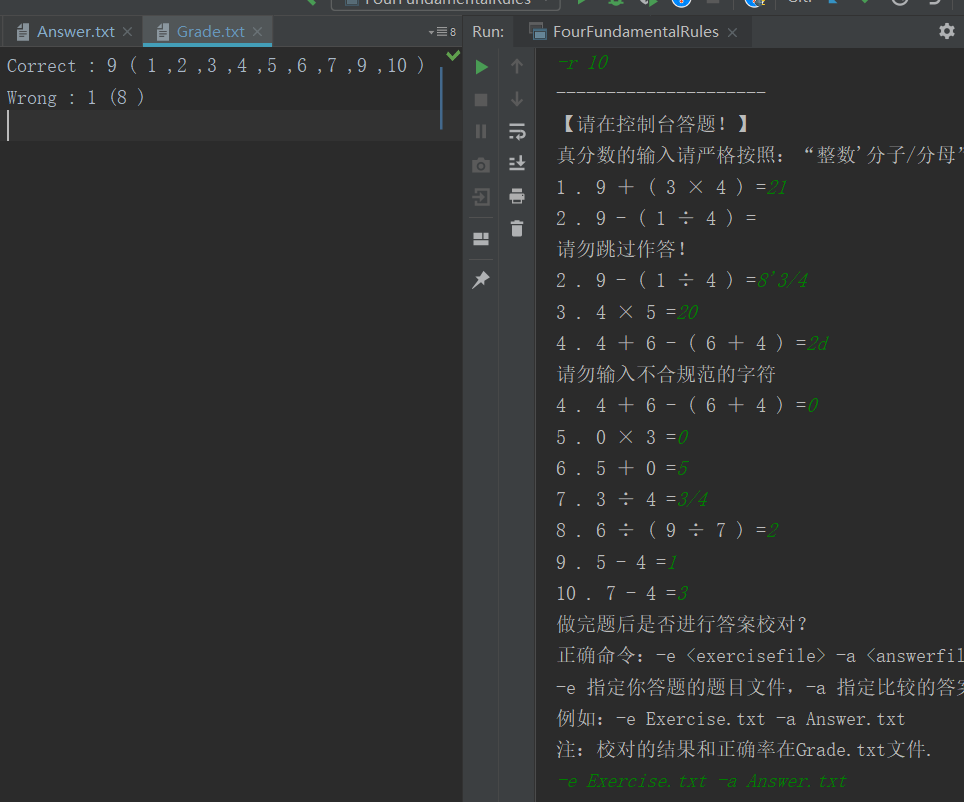
2. 不校对答案例子

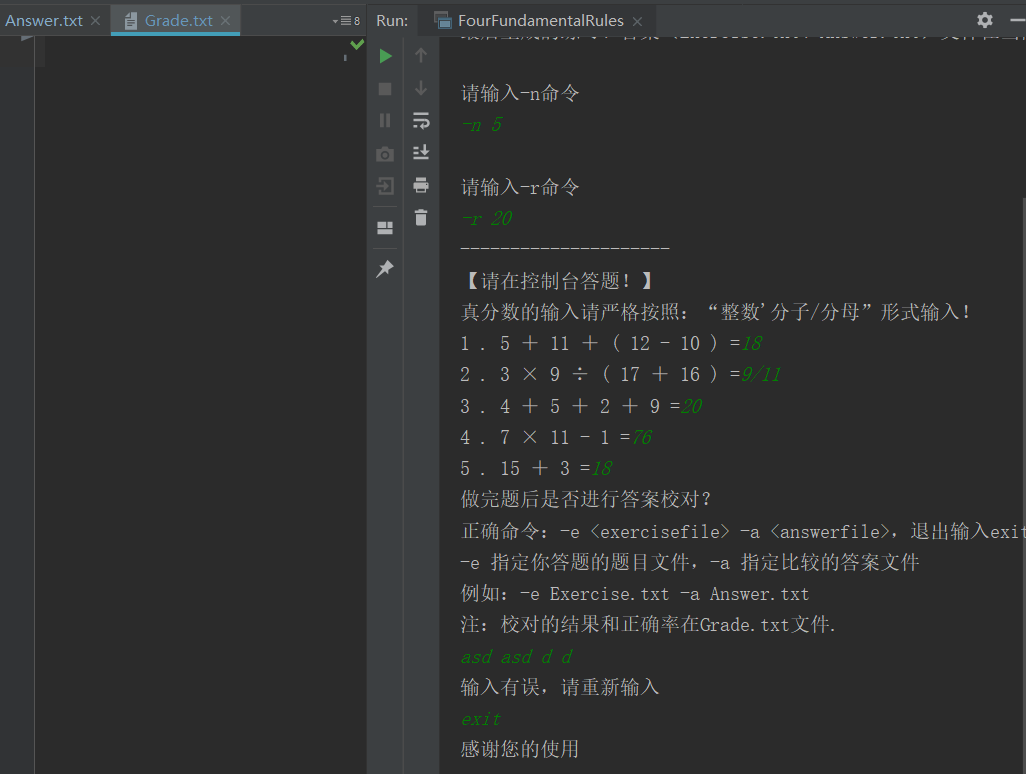
3. 支持生成1w条表达式

7.1小白入门…初步分工
-
![]()
-
团队合作用在结对编程这件事我们确实是第一次接触,一开始只是草率地分配任务放羊式打码;后来准备收官的时候才发现有些需求实在没想出来,但是冷静思考这次作业的意义是什么:不在于你的功能有多高大上,我认为是可以体验软件开发中的必要流程;包括:
-
重视PSP
-
合理使用工具(单元测试、性能测试、版本控制软件等)
-
协作开发(各自获取需求是否有考虑有重复的地方、每天的项目进度需要及时沟通跟进、必要的舍弃与加班等)
以上种种,我们有一部分是后面几天才简单体验过,所以项目至此还会有许多问题;但同时也是经验,为我们下次做得更好
-

7.2软件版本控制入门学习
-
版本控制确实是开发过程中非常必需的流程,像这次我们前期代码交换就是自己打包压缩包然后微信发送给对方;这样实在太乱,而且效率底下很难回溯之前的版本;基于此我们下定决心一定要学会git,花的时间虽然多但也值得!有关总结git命令可以参照下面博客:https://www.cnblogs.com/Thinker-Bob/articles/10539214.html
-
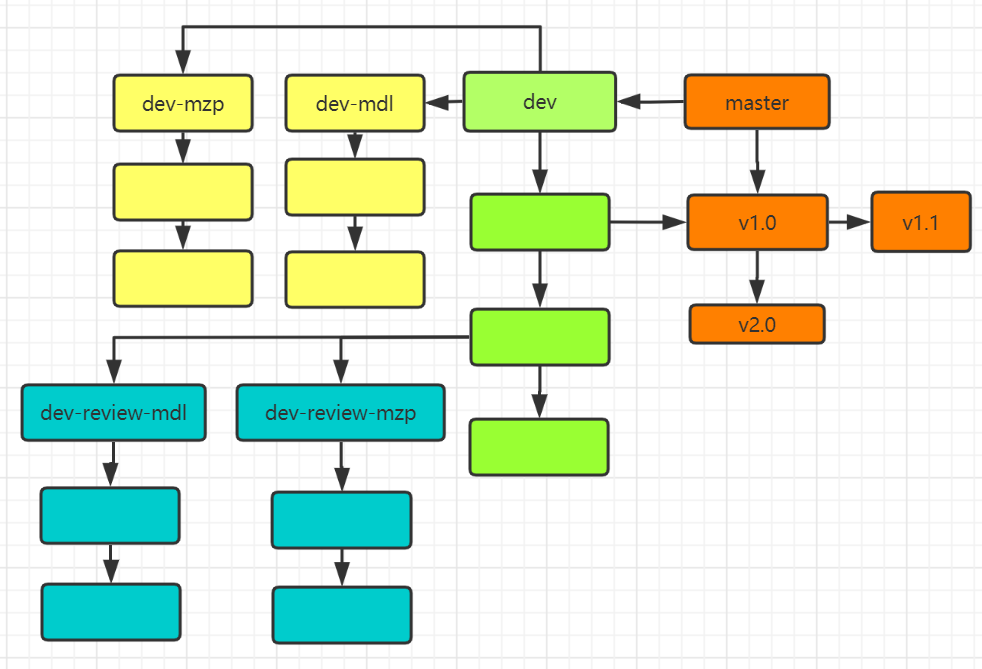
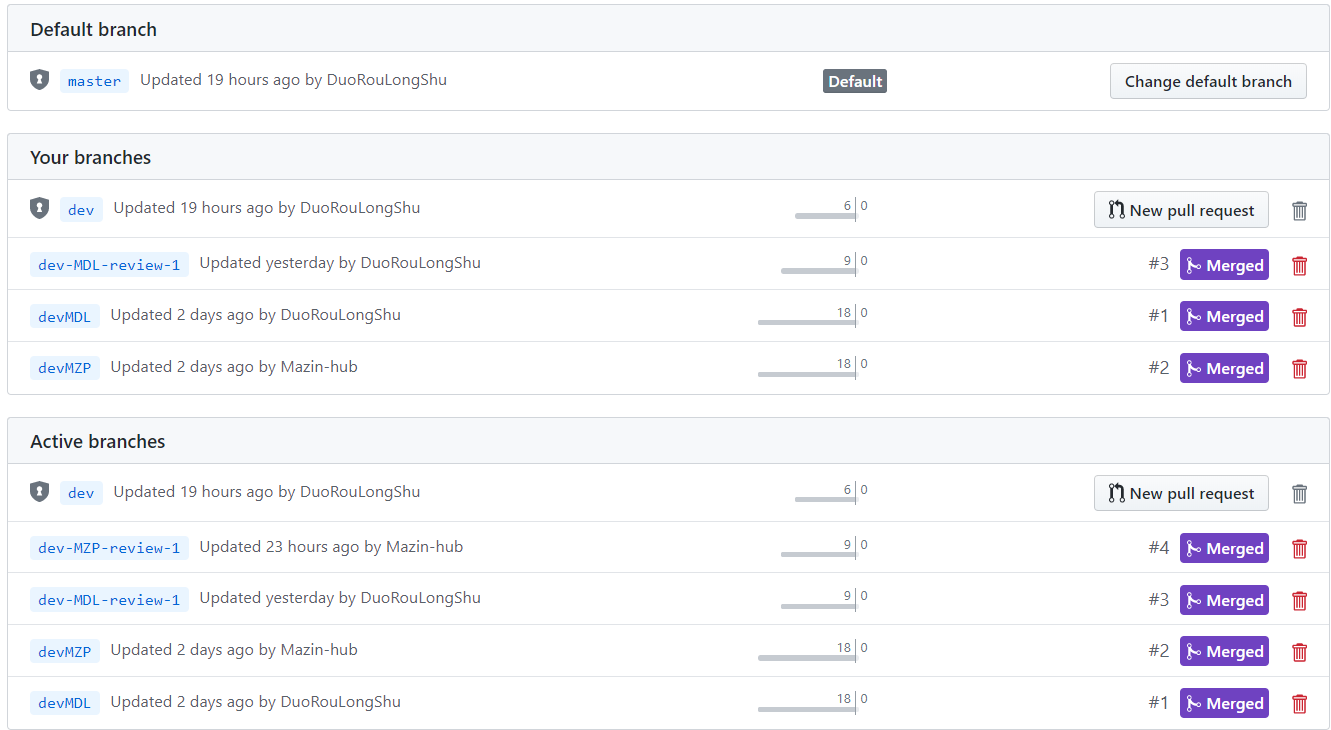
关于详细的git学习,以及企业开发模式等等许多相关知识都有待我们抓紧学习,此次第一次入门也算是一知半解,下次争取做到更好!附上我们二人的阉割版分支管理
-
![]()
![]()
- 有关分支管理学习可参照此博客:https://www.cnblogs.com/spec-dog/p/11043371.html
8.项目完结个人PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1015 | 1380 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 480 |
| · Design Spec | · 生成设计文档 | 45 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 120 |
| · Design | · 具体设计 | 300 | 120 |
| · Coding | · 具体编码 | 300 | 300 |
| · Code Review | · 代码复审 | 120 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 90 | 310 |
| · Test Report | · 测试报告 | 60 | 120 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 180 |
| 合计 | 1125 | 1700 |
9.感想与总结
核心编程:
-
进步之处:与上一次相比,作业都比较提前进行,按照计划来合作,经常和小伙伴讨论,所以最后各方面自我感觉完成度还是有很大进步的。同时学习新知识得能力得到锻炼,不再是像以前磨洋工,能够遇到挫折坚持下去不断寻找能改进的办法。以及对这门课,对软件工程这个专业有了一点基本认识!
-
不足之处:做事还是拖拉,给的时间虽然很多,但是一开始计划却中间整整拖了一个星期才抓紧,这也是我最大的问题;不懂得取舍,基础薄弱导致具体编程使得代码冗余、解题质量不佳。
打码是项目的核心,或许不是这门课程的核心。但其实还是暴露了很多问题,自身对Java代码的诸多不熟悉导致了具体编码时候拖延项目进度,以及很多想实现的功能都无法得心应手。我想这也是我今后需要加倍努力的方向。系统学习Java基础知识、Web编程、idea工具使用、性能分析等等。每做一次作业,我都能愈发感觉到危机感,自己的专业素养缺乏,与很多大佬得差距甚大。时间紧迫,更要不断地学习,不断沉淀,总该经历的,就是现在了。
团队合作:这次项目能够完结,非常感谢我的小伙伴MZP带我,整个程序的框架就是他写出来的,Java基础比我高多了!也得幸于此,我们后续很多工作开展都有一个底气!遇到很多问题我们都能及时沟通及时反馈,我想这也是我们这次团队项目最大的收获,不论是否完美,我们这次的经验一定会对我们有帮助的! 欢迎多光临我的小伙伴博客(dlddw!!!)https://www.cnblogs.com/Mzp6/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号