001 Python 基础
注释
# 这是第一个单行注释
print("hello python")
"""
这是一个多行注释,一对 连续的 三个 引号(单引号和双引号都可以)
在多行注释之间,可以写很多很多的内容
"""
print("hello python")数据类型篇
数字
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。
- 浮点型(floating point real values) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- 复数(complex numbers) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3+e18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2-E12 | 4.53e-7j |
int(x [,base ]) 将x转换为一个整数
float(x ) 将x转换到一个浮点数
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串 0x, 0xFF
oct(x ) 将一个整数转换为一个八进制字符串 :0o 0o7
bin(x ) 将一个整数转换为一个二制字符串 :0b, '0b11'
复数是由一个实数和一个虚数组合构成,表示为:x+yj。其中 x 是实数部分,y 是虚数部分。
aa=123-12j
print aa.real # output 实数部分 123.0
print aa.imag # output虚数部分 -12.0字符串
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,规则:
从左到右索引默认0开始的,最大范围是字符串长度少1
从右到左索引默认-1开始的,最大范围是字符串开头
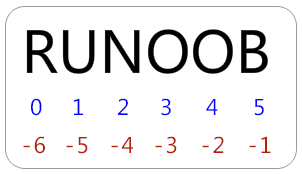
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符
>>> s = 'abcdef'
>>> s[1:5]
'bcde'
>>> s[-3:-1]
'de'
>>> 'abcdef'[3:]
'def'
>>> 'abcdef'[3:-1]
'de'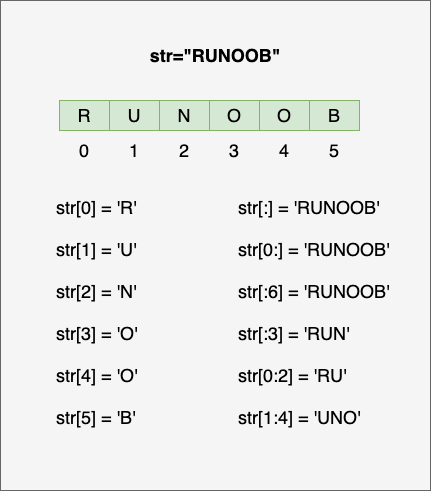
Python字符串运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b'HelloPython' |
| * | 重复输出字符串 | >>>a * 2'HelloHello' |
| [] | 通过索引获取字符串中字符 | >>>a[1]'e' |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4]'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in aTrue |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in aTrue |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n'
\n
>>> print R'\n'
\n |
Python 可以使用引号( ' )、双引号( " )、三引号( ''' 或 """ ) 来表示字符串
'引用字符串' #单引号
"双引用字符串" #引号
#多行字符串,使用三个单引号或者双引号:
'''
12123
123123
'''
"""
12123
123123
""" bool布尔类型:
True False 第一个字母大写,bool(0)=> False
空值("" [] {})都是False
列表List []
List(列表) 是 Python 中使用最频繁的数据类型。列表用 [ ] 标识
list1 = ['physics', 'chemistry', 1997, 2000] #定义
list2 = [] #空列表
list1[0] #查询,结果:physics
list1.append('Google') ## 使用 append() 添加元素
del list1[2] #删除列表的元素列表脚本操作符:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
列表截取:
>>> ['runoob', 786, 2.23, 'john', 70.2][1:4]
[786, 2.23, 'john']
>>> ['runoob', 786, 2.23, 'john', 70.2][0:4:2] #第三个参数,参数作用是截取的步长,以下实例在索引0到索引4的位置并设置为步长为2
['runoob', 2.23]维护有序列表:
bisect 模块用于对有序列表进行二分查找和插入操作,是标准库中的一个非常高效的算法工具,适合处理排序数组的“插入 + 查找”类场景。
| 函数名 | 作用 |
|---|---|
bisect.bisect_left(a, x) | 返回 x 应该插入的位置,插入点在左边 |
bisect.bisect_right(a, x) / bisect.bisect() | 返回 x 应该插入的位置,插入点在右边(默认) |
bisect.insort_left(a, x) | 插入 x 到有序列表中(插在左边) |
bisect.insort_right(a, x) / bisect.insort() | 插在右边(默认) |
import bisect
a = [2,5,7]
bisect.insort(a,16) # 插入
print(a) #[2, 5, 7, 16]
pos = bisect.bisect_right(a, 4)
print(pos) # 1(插入在 2 右边。所以位置是1)
==============================
#学生分数评级
import bisect
# 分段阈值:必须是升序 60 以下为 F,60–69 为 D,70–79 为 C, 80–89 为 B,90 以上为 A
#时间复杂度 O(log n),适合数量多、变化频繁
score_bounds = [ 60, 70, 80, 90]
grade_labels = ['F', 'D', 'C', 'B', 'A']
def get_grade(score):
idx = bisect.bisect_right(score_bounds, score)
return grade_labels[idx]
print(get_grade(95)) # A
print(get_grade(83)) # B
print(get_grade(62)) # D
print(get_grade(50)) # F元组tuple ()
元组是另一个数据类型,类似于 List(列表)。但是元组不能二次赋值,相当于只读列表。
元组用 () 标识。内部元素用逗号隔开。
只有一个元素的元组:(1,) 不然编译器认为这个括号是加法的运算符号。
空元组:()
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
集合 set { 只有key}
值的集合(只有key), "{ }"标识
无序 不重复
添加
s={'1','2'}
s.add('3') # {'1','3','2'}
>>> {1,2,3}-{2} #差集
{1, 3}
>>> {1,2,3}&{2} #交集
{2}
>>> {1,2} | {3} # 合集
{1, 2, 3}空集合: set()
字典 dict {key : value}
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。 键-值对(key → value)
{'name': 'runoob','code':6734, 'dept': 'sales'}空类型讲解
None 不等于空字符串、空列表或False。
类型差异:使用type()检查会发现None是NoneType类型,而空字符串是str类型,空列表是list类型,False是bool类型.
None 表示"不存在"的概念
False表示布尔假值
空列表 表示容器无元素
空字符 串表示字符序列为空
判空操作本质:
a = []
#是对变量进行布尔运算,适用于空字符串、空列表、等"假值"
if not a:
#是严格检查是否为对象
if a is None:
with 语法:
一个对象能用 with 来包裹,它必须实现 __enter__() 和 __exit__() 这两个方法。
是一个用于简化资源管理的语法糖,常用于打开文件、网络连接、数据库等“需要释放资源”的场景。
with 表达式 as 变量:
代码块
#相当于:
变量 = 表达式.__enter__()
try:
代码块
finally:
表达式.__exit__()变量
Python 中的变量赋值不需要类型声明。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
值类型(不可改变):int str tuple
引用类型: list set dict
运算符
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级),幂 ,又称次方、乘方,2 ** 3 = 8 |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除, 取模(取余数),返回除法的余数 9 % 2 = 1 取整除,返回除法的整数部分(商) 9 // 2 输出结果 4 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 判断两个标识符是不是引用自一个对象 x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
增量赋值运算符+=
+ 创建新对象 ,(返回新值)
+= 尝试原地修改 ,但是只有list才成功,其他不行,见下表
| 类型 | a += b 作用 | 是否改变原对象 | 示例结果 |
|---|---|---|---|
int | 加法运算(不可变) | ❌ 否(创建新对象) | a = 1; a += 2 → 3 |
str | 字符串拼接(不可变) | ❌ 否 | "ab" += "cd" → "abcd" |
list | 就地扩展(等价于 list.extend()) | ✅ 是 | [1,2] += [3] → [1,2,3] |
tuple | 不可变类型 | ❌ 否(创建新元组) | (1,2) += (3,) → (1,2,3) |
a = [1, 2]
b = [3, 4]
c = a
a = a + b # a+b创建新对象,a 改变,但 c 不变
print(c) # [1, 2]
===================================
a = [1, 2]
b = [3, 4]
c = a
a += b # 就地修改 a,也影响了 c
print(c) # [1, 2, 3, 4]Python语句
#if
if 1==2 :
pass
elif 2==4 :
pass
else:
pass
#while
mod = [1,23]
while len(mod)>0 :
print("词库名:",mod.pop());
else:
print("已经输出完毕")
#for
mod = [1,23]
for value in mod:
print(value)
for i in range(1, 101): # range(1, 101) 表示从 1 到 100(包含 1,不包含 101)
print(i)
break语句用在while和for循环中。
continue语句用在while和for循环中。enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for idx, col in enumerate(['姓名', '年龄', '性别']):
print(i, col)
'''
0 姓名
1 年龄
2 性别
'''Python 模块
import.... 语句 ,在调用模块中的函数,需要模块名.函数名
import cmath
cmath.sqrt(9)
import cmath as m
m.sqrt(9)from…A…import....a1.... 语句 从模块A中导入一个指定的部分(a1)到当前命名空间中,
from cmath import sqrt
print(sqrt(9))
from cmath import * #这个是引入模块的所有内容Python中的包
包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__init__.py 用于标识当前文件夹是一个包。

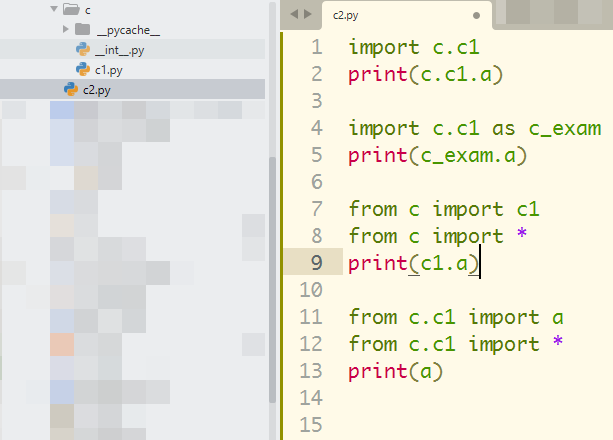
方式1: import c.c1 引入c这个包下的c1.py ,使用的时候连同包名一起才能访问a print(c.c1.a)
方式2:使用as别名 c_exam,简化引入print(c_exam.a)
方式3.1:from…import.... ,从c 引入 c1模块
方式3.2:from…import.... ,从c 引入 所有模块
方式4.1:from…import.... ,从c.c1 引入 a变量
方式4.2:from…import.... ,从c.c1 引所有变量
Python3 函数
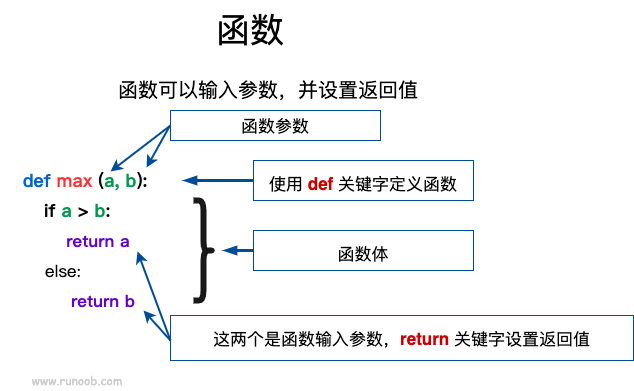
Python 定义函数使用 def 关键字,一般格式如下:
关键字参数:使用关键字参数允许函数调用时参数的顺序与声明时不一致、 Python 解释器能够用参数名匹配参数值。
def printinfo( name, age ):
print ("名字: ", name)
print ("年龄: ", age)
printinfo( age=50, name="runoob" )序列解包:返回参数的时候,逐一列出
def getinfo( name, age ):
return name,age
name,age = getinfo("runoob",30)
匿名函数 : 使用lambda关键字定义匿名函数,语法为lambda 参数列表: 表达式
add = lambda x, y: x + y
add(1,2)三元表达式:
经典语言语法:x > y ? x : y(条件判断在前,用问号分隔)
map函数
本质: map是一个类(class)而非函数
参数结构:
第一个参数:函数对象(function)
第二个参数:(如列表、元组、集合等)
nums = [1,2,3]
result = map(lambda x:x*x , nums)
print(list(result))
============
nums = [1,2,3]
def add_one(x):
return x + 1
result = map(add_one , nums)
print(list(result))
reduce函数
reduce() 是 Python 中一个将一个可迭代对象“累计计算”为单一值的高阶函数。它来自模块 functools,常用于把列表合成一个结果(比如求和、连乘、拼接等)。
from functools import reduce
#列表求和
nums = [1,2,3,4]
result_add = reduce(lambda x,y:x+y , nums)
#10
#列表连乘
result = reduce(lambda x,y:x*y , nums)
print( (result))
#24
#拼接字符串
words = ["我", "是", "谁"]
result = reduce(lambda x,y:x+y , words)
#我是谁 filter函数
根据指定规则过滤序列中的元素,保留符合条件的元素
#筛选偶数
nums = [1,2,3,4]
result_add = filter(lambda x:x%2==0 , nums)
print(list(result_add))
#[2, 4]浅拷贝:复制的是对象的引用层,内部子对象共享
深拷贝:复制的是对象及其所有嵌套子对象的完整副本,完全独立
import copy
a = [1, [2, 3]]
b = copy.copy(a)
c = copy.deepcopy(a)
b[1][0] = 'X'
c[1][1] = 'Y'
print(a) # [1, ['X', 3]] ← 被 b 修改了(浅拷贝)
print(b) # [1, ['X', 3]]
print(c) # [1, [2, 'Y']] ← 完全独立(深拷贝)
数学函数
for i in range(1, 101): # range(1, 101) 表示从 1 到 100(包含 1,不包含 101)
print(i)Python3 面向对象
魔法函数:
以 __xxx__ 形式命名的函数。
字符串表示: __str__ 打印字符串表现(print(obj)) __repr__ 调试输出表现(命令行直接打 obj)
class MyClass:
def __init__(self, name, age): # 初始化方法
self.name = name
self.age = age
self.__age = age # 定义私有属性
@staticmethod
def greet(name):
print(f"Hello, {name}!")
p = MyClass("Alice", 25) # 自动调用 __init__
print(p.name) # Alice
MyClass.greet('123') #Hello, 123!__getattr
__getattribute__ 当访问任何属性(不论该属性是否存在)时,都会调用 __getattribute__。
__getattr__ 只有当访问的属性 不存在时,才会调用 __getattr__。是属性访问的“兜底”机制。
@property 让你可以像访问属性一样调用方法,但可以在方法里做控制逻辑。加上 @xxx.setter 才能赋值,
加上 @xxx.deleter 才能删除。
class Person:
def __init__(self, name):
self._name = name # 私有变量
@property
def name(self): # getter
print(" 正在获取 name...")
return self._name
@name.setter
def name(self, value): # setter
print(" 正在设置 name...")
if not isinstance(value, str):
raise ValueError("名字必须是字符串")
self._name = value
@name.deleter
def name(self):
print("️ 删除 name")
del self._name
p = Person("Tom")
print(p.name) # 自动调用 @property 修饰的方法(getter)
p.name = "Jerry" # 自动调用 name.setter 方法
del p.name # 自动调用 name.deleter 方法多继承:
Python 用的是 C3 线性化算法,结合了深度优先和广度优先的优点;
保证子类总是排在父类之前(继承树的“从下到上”顺序);
保证继承声明的顺序被尊重(局部顺序一致性);
合并父类的 MRO 顺序,避免冲突和二义性。
Mixin(混入类)
是 Python 中常用的多重继承技巧,用于为其他类提供额外功能,不用于独立实例化对象,主要目的是 “功能组合而非继承结构”。
命名建议以 Mixin 结尾(如 LogMixin, AuditMixin);
class ReprMixin:
def __repr__(self):
return f"<{self.__class__.__name__} {self.__dict__}>"
class User(ReprMixin):
def __init__(self, name, age):
self.name = name
self.age = age
u = User("Alice", 30)
print(u) # <User {'name': 'Alice', 'age': 30}>
迭代器 生成器
迭代器是可以被
next() 调用不断返回下一个值的对象。只要一个对象实现了 __iter__() 和 __next__() 方法,它就是一个迭代器。生成器是简化版的迭代器,本质是一个 函数 或 表达式,它用 yield 语句“暂停并返回”一个值,下一次继续从 yield 后执行。
def my_gen():
for i in range(5):
yield i #①“暂停并返回”一个值, ③下一次继续从 yield 后执行。
g = my_gen()
for i in g:
print(i) #②返回到这里,执行逻辑。
=========================================
#500GBtxt 文件是 只有一行的字符串,字段之间用自定义分隔符 【|】 分隔,那你要:
def read_large_line_custom_delim(file_path, delim="【|】", chunk_size=1024*1024):
buffer = ""
delim_len = len(delim)
with open(file_path, 'r', encoding='utf-8') as f:
while True:
chunk = f.read(chunk_size) #自动从上次读取结束的位置继续往下读
if not chunk:
break
buffer += chunk
parts = buffer.split(delim)
# 最后一个可能是被拆开的字段,留在 buffer 继续处理
buffer = parts.pop()
for field in parts:
yield field
# 文件最后剩下的部分(可能是最后一个字段)
if buffer:
yield buffer
for i, field in enumerate(read_large_line_custom_delim("bigfile.txt")):
print(f"字段 {i+1}: {field}")Socket编程
#服务端:
import socket
def start_server(host='127.0.0.1', port=5000):
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((host, port))
server_socket.listen(5)
print(f"服务器启动,监听 {host}:{port}...")
while True:
client_socket, client_address = server_socket.accept() #当有新客户端连接时马上返回一个新 socket
print(f"连接来自 {client_address}")
data = client_socket.recv(1024)
print(f"收到数据:{data.decode()}")
client_socket.sendall("数据已接收".encode('utf-8'))
client_socket.close()
if __name__ == "__main__":
start_server()
#客户端
import socket
def connect_to_server(host='127.0.0.1', port=5000):
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect((host, port))
#加个wile就可以一直运行
# 从命令行读取一行
msg = input("> ")
# 发送(先编码)
client_socket.sendall(msg.encode('utf-8'))
# 接收服务器回应
response = client_socket.recv(1024)
print(f"服务器响应:{response.decode()}")
client_socket.close()
if __name__ == "__main__":
connect_to_server()改为多线程服务器:
import socket
import threading
def handle_client(client_sock, address):
"""
每个客户端连接都会走到这里,
在独立线程中收发数据,直到客户端断开。
"""
print(f"[+] New connection from {address}")
try:
while True:
data = client_sock.recv(4096)
if not data:
print(f"[-] Client {address} disconnected")
break
text = data.decode('utf-8').strip()
print(f"[{address}] {text}")
# 回显 + 自定义逻辑
reply = f"Server received: {text}\n"
client_sock.sendall(reply.encode('utf-8'))
except ConnectionResetError:
print(f"[!] Connection reset by {address}")
finally:
client_sock.close()
def start_server(host='0.0.0.0', port=5000):
"""
服务器主线程负责监听和 accept 新连接,
每接到一个客户端,就创建并启动一个处理线程。
"""
server_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_sock.bind((host, port))
server_sock.listen()
print(f"[*] Server listening on {host}:{port}")
try:
while True:
client_sock, addr = server_sock.accept()
# 启动一个新线程来处理这个客户端
t = threading.Thread(target=handle_client, args=(client_sock, addr), daemon=True)
t.start()
except KeyboardInterrupt:
print("\n[!] Server shutting down")
finally:
server_sock.close()
if __name__ == "__main__":
start_server()
Python 文件I/O
读取键盘输入
安装:
pip install -i https://mirrors.cloud.tencent.com/pypi/simple/ ipython
 浙公网安备 33010602011771号
浙公网安备 33010602011771号