【原创】(五)Linux内存管理zone_sizes_init
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 介绍
在(四)Linux内存模型之Sparse Memory Model中,我们分析了bootmem_init函数的上半部分,这次让我们来到下半部分吧,下半部分主要是围绕zone_sizes_init函数展开。
前景回顾:
bootmem_init()函数代码如下:
void __init bootmem_init(void)
{
unsigned long min, max;
min = PFN_UP(memblock_start_of_DRAM());
max = PFN_DOWN(memblock_end_of_DRAM());
early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT);
max_pfn = max_low_pfn = max;
arm64_numa_init();
/*
* Sparsemem tries to allocate bootmem in memory_present(), so must be
* done after the fixed reservations.
*/
arm64_memory_present();
sparse_init();
zone_sizes_init(min, max);
memblock_dump_all();
}
在Linux中,物理内存地址区域采用zone来管理。不打算来太多前戏了,先上一张zone_sizes_init的函数调用图吧:
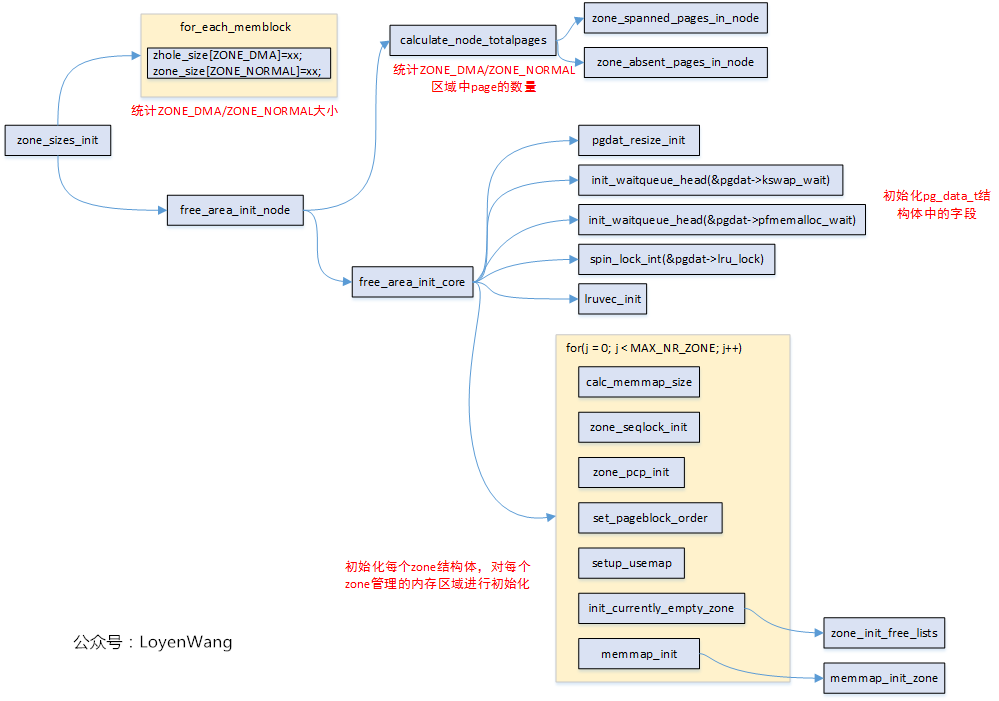
需要再说明一点是,使用的是ARM64,UMA(只有一个Node),此外,流程分析中那些没有打开的宏,相应的函数就不深入分析了。开始探索吧!
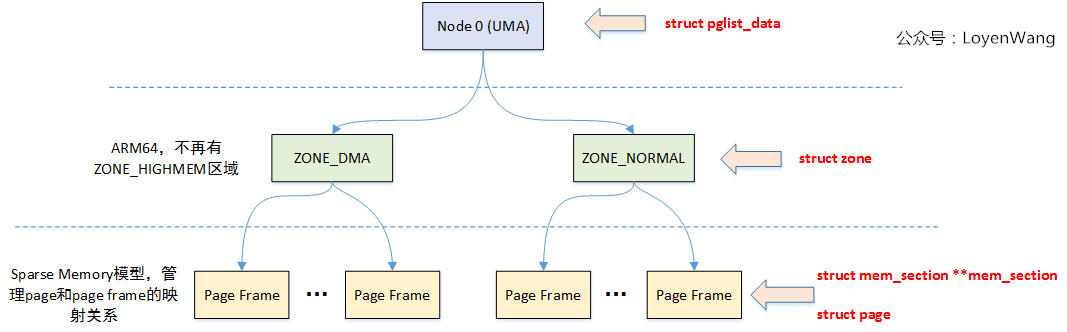
2. 数据结构

关键的结构体如上图所示。
在NUMA架构下,每一个Node都会对应一个struct pglist_data,在UMA架构中只会使用唯一的一个struct pglist_data结构,比如我们在ARM64 UMA中使用的全局变量struct pglist_data __refdata contig_page_data。
struct pglist_data 关键字段
struct zone node_zones[]; //对应的ZONE区域,比如ZONE_DMA,ZONE_NORMAL等
struct zonelist_node_zonelists[];
unsigned long node_start_pfn; //节点的起始内存页面帧号
unsigned long node_present_pages; //总共可用的页面数
unsigned long node_spanned_pages; //总共的页面数,包括有空洞的区域
wait_queue_head_t kswapd_wait; //页面回收进程使用的等待队列
struct task_struct *kswapd; //页面回收进程
struct zone 关键字段
unsigned long watermark[]; //水位值,WMARK_MIN/WMARK_LOV/WMARK_HIGH,页面分配器和kswapd页面回收中会用到
long lowmem_reserved[]; //zone中预留的内存
struct pglist_data *zone_pgdat; //执行所属的pglist_data
struct per_cpu_pageset *pageset; //Per-CPU上的页面,减少自旋锁的争用
unsigned long zone_start_pfn; //ZONE的起始内存页面帧号
unsigned long managed_pages; //被Buddy System管理的页面数量
unsigned long spanned_pages; //ZONE中总共的页面数,包含空洞的区域
unsigned long present_pages; //ZONE里实际管理的页面数量
struct frea_area free_area[]; //管理空闲页面的列表
宏观点的描述:struct pglist_data描述单个Node的内存(UMA架构中的所有内存),然后内存又分成不同的zone区域,zone描述区域内的不同页面,包括空闲页面,Buddy System管理的页面等。
3. zone
上个代码吧:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
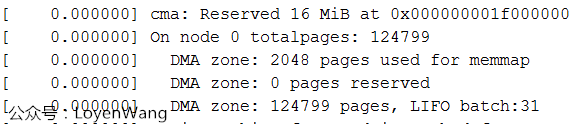
通用内存管理要应对各种不同的架构,X86,ARM,MIPS...,为了减少复杂度,只需要挑自己架构相关的。目前我使用的平台,只配置了ZONE_DMA和ZONE_NORMAL。Log输出如下图:
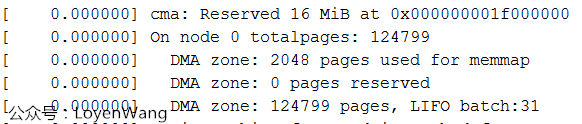
为什么没有ZONE_NORMAL区域内,跟踪一通代码发现,ZONE_DMA区域设置的大小是从起始内存开始的4G区域并且不能超过4G边界区域,而我使用的内存为512M,所以都在这个区域内了。
从上述结构体中可以看到,ZONE_DMA是由宏定义的,ZONE_NORMAL才是所有架构都有的区域,那么为什么需要一个ZONE_DMA区域内,来张图:
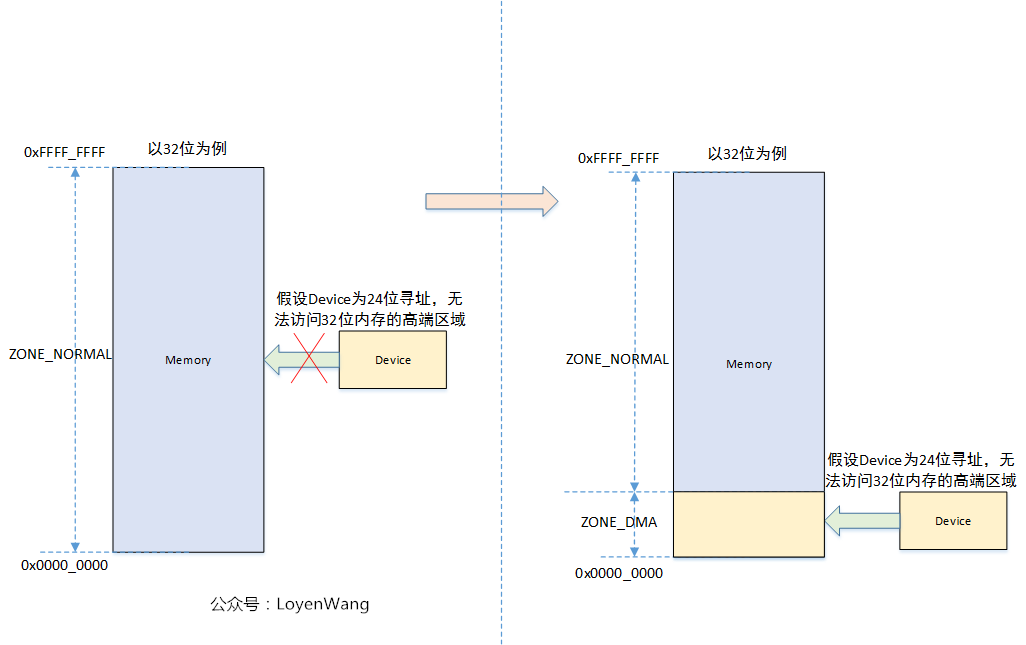
所以,如果所有设备的寻址范围都是在内存的区域内的话,那么一个ZONE_NORMAL是够用的。
4. calculate_node_totalpages
这个从名字看就很容易知道是为了统计Node中的页面数,一张图片解释所有:
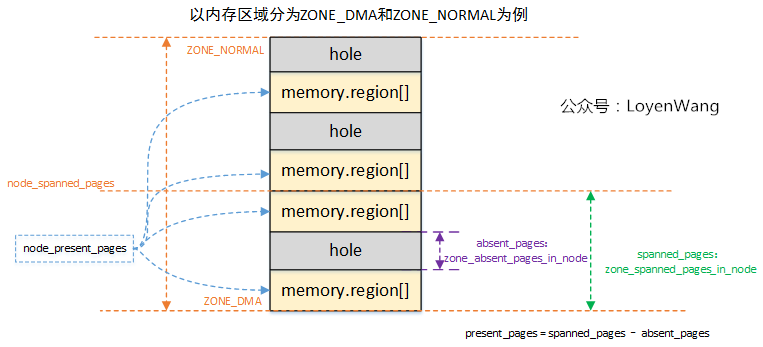
- 前边的文章分析过,物理内存由
memblock维护,整个内存区域,是有可能存在空洞区域,也就是图中的hole部分; - 针对每个类型的
ZONE区域,分别会去统计跨越的page frame,以及可能存在的空洞,并计算实际可用的页面present_pages; Node管理各个ZONE,它的spanned_pages和present_pages是统计各个ZONE相应页面之和。
这个过程计算完,基本就把页框的信息纳入管理了。
5. free_area_init_core
简单来说,free_area_init_core函数主要完成struct pglist_data结构中的字段初始化,并初始化它所管理的各个zone,看一下代码吧:
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*
* NOTE: pgdat should get zeroed by caller.
*/
static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_resize_init(pgdat);
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spin_lock_init(&pgdat->split_queue_lock);
INIT_LIST_HEAD(&pgdat->split_queue);
pgdat->split_queue_len = 0;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTION
init_waitqueue_head(&pgdat->kcompactd_wait);
#endif
pgdat_page_ext_init(pgdat);
spin_lock_init(&pgdat->lru_lock);
lruvec_init(node_lruvec(pgdat));
pgdat->per_cpu_nodestats = &boot_nodestats;
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn;
size = zone->spanned_pages;
realsize = freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
#endif
zone->name = zone_names[j];
zone->zone_pgdat = pgdat;
spin_lock_init(&zone->lock);
zone_seqlock_init(zone);
zone_pcp_init(zone);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
init_currently_empty_zone(zone, zone_start_pfn, size);
memmap_init(size, nid, j, zone_start_pfn);
}
}
- 初始化
struct pglist_data内部使用的锁和队列;
遍历各个zone区域,进行如下初始化:
-
根据
zone的spanned_pages和present_pages,调用calc_memmap_size计算管理该zone所需的struct page结构所占的页面数memmap_pages; -
zone中的freesize表示可用的区域,需要减去memmap_pages和DMA_RESERVE的区域,如下图在开发板的Log打印所示:memmap使用2048页,DMA保留0页;
-
计算
nr_kernel_pages和nr_all_pages的数量,为了说明这两个参数和页面的关系,来一张图(由于我使用的平台只有一个ZONE_DMA区域,且ARM64没有ZONE_HIGHMEM区域,不具备典型性,故以ARM32为例):
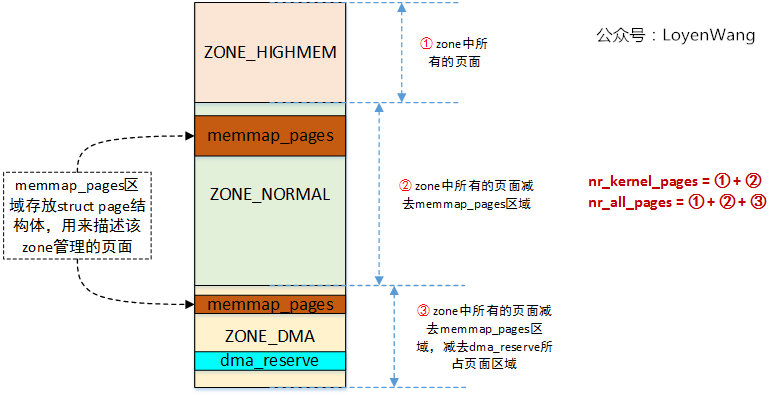
-
初始化
zone使用的各类锁; -
分配和初始化
usemap,初始化Buddy System中使用的free_area[],lruvec,pcp等; -
memmap_init()->memmap_init_zone(),该函数主要是根据PFN,通过pfn_to_page找到对应的struct page结构,并将该结构进行初始化处理,并设置MIGRATE_MOVABLE标志,表明可移动;
最后,当我们回顾bootmem_init函数时,发现它基本上完成了linux物理内存框架的初始化,包括Node, Zone, Page Frame,以及对应的数据结构等。
结合上篇文章(四)Linux内存模型之Sparse Memory Model阅读,效果会更佳噢!
持续中...

出处:https://www.cnblogs.com/LoyenWang/
公众号:LoyenWang
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任

 浙公网安备 33010602011771号
浙公网安备 33010602011771号