
策略梯度玩 cartpole 游戏,强化学习代替PID算法控制平衡杆
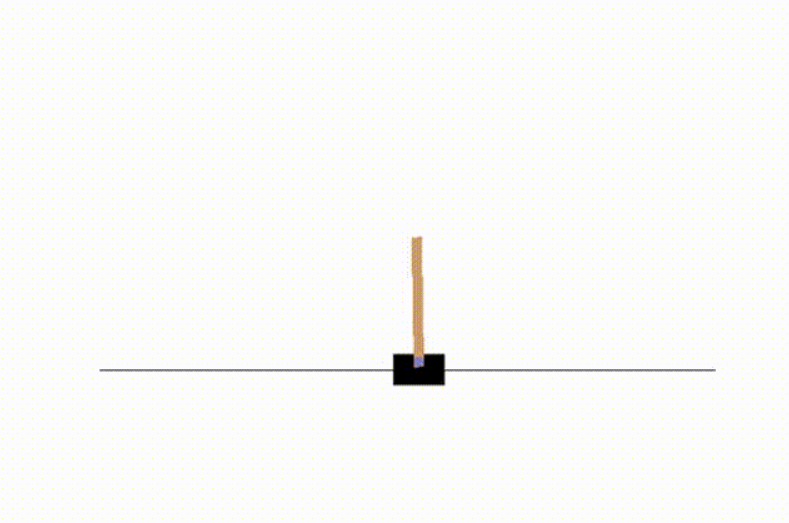
cartpole游戏,车上顶着一个自由摆动的杆子,实现杆子的平衡,杆子每次倒向一端车就开始移动让杆子保持动态直立的状态,策略函数使用一个两层的简单神经网络,输入状态有4个,车位置,车速度,杆角度,杆速度,输出action为左移动或右移动,输入状态发现至少要给3个才能稳定一会儿,给2个完全学不明白,给4个能学到很稳定的policy
策略梯度实现代码,使用torch实现一个简单的神经网络
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import pygame
import sys
from collections import deque
import numpy as np
# 策略网络定义
class PolicyNetwork(nn.Module):
def __init__(self):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 10), # 4个状态输入,128个隐藏单元
nn.Tanh(),
nn.Linear(10, 2), # 输出2个动作的概率
nn.Softmax(dim=-1)
)
def forward(self, x):
# print(x) 车位置 车速度 杆角度 杆速度
selected_values = x[:, [0,1,2,3]] #只使用车位置和杆角度
return self.fc(selected_values)
# 训练函数
def train(policy_net, optimizer, trajectories):
policy_net.zero_grad()
loss = 0
print(trajectories[0])
for trajectory in trajectories:
# if trajectory["returns"] > 90:
# returns = torch.tensor(trajectory["returns"]).float()
# else:
returns = torch.tensor(trajectory["returns"]).float() - torch.tensor(trajectory["step_mean_reward"]).float()
# print(f"获得奖励{returns}")
log_probs = trajectory["log_prob"]
loss += -(log_probs * returns).sum() # 计算策略梯度损失
loss.backward()
optimizer.step()
return loss.item()
# 主函数
def main():
env = gym.make('CartPole-v1')
policy_net = PolicyNetwork()
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)
print(env.action_space)
print(env.observation_space)
pygame.init()
screen = pygame.display.set_mode((600, 400))
clock = pygame.time.Clock()
rewards_one_episode= []
for episode in range(10000):
state = env.reset()
done = False
trajectories = []
state = state[0]
step = 0
torch.save(policy_net, 'policy_net_full.pth')
while not done:
state_tensor = torch.tensor(state).float().unsqueeze(0)
probs = policy_net(state_tensor)
action = torch.distributions.Categorical(probs).sample().item()
log_prob = torch.log(probs.squeeze(0)[action])
next_state, reward, done, _,_ = env.step(action)
# print(episode)
trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob})
state = next_state
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
step +=1
# 绘制环境状态
if rewards_one_episode and rewards_one_episode[-1] >99:
screen.fill((255, 255, 255))
cart_x = int(state[0] * 100 + 300)
pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30))
# print(state)
pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2)
pygame.display.flip()
clock.tick(200)
print(f"第{episode}回合",f"运行{step}步后挂了")
# 为策略梯度计算累积回报
returns = 0
for traj in reversed(trajectories):
returns = traj["reward"] + 0.99 * returns
traj["returns"] = returns
if rewards_one_episode:
# print(rewards_one_episode[:10])
traj["step_mean_reward"] = np.mean(rewards_one_episode[-10:])
else:
traj["step_mean_reward"] = 0
rewards_one_episode.append(returns)
# print(rewards_one_episode[:10])
train(policy_net, optimizer, trajectories)
def play():
env = gym.make('CartPole-v1')
policy_net = PolicyNetwork()
pygame.init()
screen = pygame.display.set_mode((600, 400))
clock = pygame.time.Clock()
state = env.reset()
done = False
trajectories = deque()
state = state[0]
step = 0
policy_net = torch.load('policy_net_full.pth')
while not done:
state_tensor = torch.tensor(state).float().unsqueeze(0)
probs = policy_net(state_tensor)
action = torch.distributions.Categorical(probs).sample().item()
log_prob = torch.log(probs.squeeze(0)[action])
next_state, reward, done, _,_ = env.step(action)
# print(episode)
trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob})
state = next_state
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
# 绘制环境状态
screen.fill((255, 255, 255))
cart_x = int(state[0] * 100 + 300)
pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30))
# print(state)
pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2)
pygame.display.flip()
clock.tick(60)
step +=1
print(f"运行{step}步后挂了")
if __name__ == '__main__':
main() #训练
# play() #推理
运行效果,训练过程不是很稳定,有时候学很多轮次也学不明白,有时侯只需要几十次就可以学明白了

多思考也是一种努力,做出正确的分析和选择,因为我们的时间和精力都有限,所以把时间花在更有价值的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号