
我在树莓派上跑通了bert模型,使用numpy实现bert模型,使用hugging face 或pytorch训练模型,保存参数为numpy格式,然后使用numpy加载模型推理
之前分别用numpy实现了mlp,cnn,lstm,这次搞一个大一点的模型bert,纯numpy实现,最重要的是可在树莓派上或其他不能安装pytorch的板子上运行,推理数据
本次模型是随便在hugging face上找的一个新闻评论的模型,7分类
看这些模型参数,这并不重要,模型占硬盘空间都要400+M
bert.embeddings.word_embeddings.weight torch.Size([21128, 768]) bert.embeddings.position_embeddings.weight torch.Size([512, 768]) bert.embeddings.token_type_embeddings.weight torch.Size([2, 768]) bert.embeddings.LayerNorm.weight torch.Size([768]) bert.embeddings.LayerNorm.bias torch.Size([768]) bert.encoder.layer.0.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.0.attention.self.query.bias torch.Size([768]) bert.encoder.layer.0.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.0.attention.self.key.bias torch.Size([768]) bert.encoder.layer.0.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.0.attention.self.value.bias torch.Size([768]) bert.encoder.layer.0.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.0.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.0.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.0.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.0.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.0.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.0.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.0.output.dense.bias torch.Size([768]) bert.encoder.layer.0.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.0.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.1.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.1.attention.self.query.bias torch.Size([768]) bert.encoder.layer.1.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.1.attention.self.key.bias torch.Size([768]) bert.encoder.layer.1.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.1.attention.self.value.bias torch.Size([768]) bert.encoder.layer.1.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.1.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.1.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.1.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.1.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.1.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.1.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.1.output.dense.bias torch.Size([768]) bert.encoder.layer.1.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.1.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.2.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.2.attention.self.query.bias torch.Size([768]) bert.encoder.layer.2.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.2.attention.self.key.bias torch.Size([768]) bert.encoder.layer.2.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.2.attention.self.value.bias torch.Size([768]) bert.encoder.layer.2.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.2.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.2.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.2.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.2.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.2.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.2.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.2.output.dense.bias torch.Size([768]) bert.encoder.layer.2.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.2.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.3.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.3.attention.self.query.bias torch.Size([768]) bert.encoder.layer.3.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.3.attention.self.key.bias torch.Size([768]) bert.encoder.layer.3.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.3.attention.self.value.bias torch.Size([768]) bert.encoder.layer.3.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.3.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.3.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.3.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.3.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.3.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.3.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.3.output.dense.bias torch.Size([768]) bert.encoder.layer.3.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.3.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.4.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.4.attention.self.query.bias torch.Size([768]) bert.encoder.layer.4.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.4.attention.self.key.bias torch.Size([768]) bert.encoder.layer.4.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.4.attention.self.value.bias torch.Size([768]) bert.encoder.layer.4.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.4.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.4.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.4.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.4.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.4.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.4.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.4.output.dense.bias torch.Size([768]) bert.encoder.layer.4.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.4.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.5.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.5.attention.self.query.bias torch.Size([768]) bert.encoder.layer.5.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.5.attention.self.key.bias torch.Size([768]) bert.encoder.layer.5.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.5.attention.self.value.bias torch.Size([768]) bert.encoder.layer.5.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.5.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.5.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.5.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.5.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.5.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.5.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.5.output.dense.bias torch.Size([768]) bert.encoder.layer.5.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.5.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.6.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.6.attention.self.query.bias torch.Size([768]) bert.encoder.layer.6.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.6.attention.self.key.bias torch.Size([768]) bert.encoder.layer.6.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.6.attention.self.value.bias torch.Size([768]) bert.encoder.layer.6.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.6.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.6.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.6.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.6.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.6.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.6.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.6.output.dense.bias torch.Size([768]) bert.encoder.layer.6.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.6.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.7.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.7.attention.self.query.bias torch.Size([768]) bert.encoder.layer.7.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.7.attention.self.key.bias torch.Size([768]) bert.encoder.layer.7.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.7.attention.self.value.bias torch.Size([768]) bert.encoder.layer.7.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.7.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.7.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.7.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.7.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.7.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.7.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.7.output.dense.bias torch.Size([768]) bert.encoder.layer.7.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.7.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.8.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.8.attention.self.query.bias torch.Size([768]) bert.encoder.layer.8.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.8.attention.self.key.bias torch.Size([768]) bert.encoder.layer.8.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.8.attention.self.value.bias torch.Size([768]) bert.encoder.layer.8.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.8.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.8.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.8.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.8.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.8.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.8.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.8.output.dense.bias torch.Size([768]) bert.encoder.layer.8.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.8.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.9.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.9.attention.self.query.bias torch.Size([768]) bert.encoder.layer.9.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.9.attention.self.key.bias torch.Size([768]) bert.encoder.layer.9.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.9.attention.self.value.bias torch.Size([768]) bert.encoder.layer.9.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.9.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.9.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.9.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.9.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.9.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.9.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.9.output.dense.bias torch.Size([768]) bert.encoder.layer.9.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.9.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.10.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.10.attention.self.query.bias torch.Size([768]) bert.encoder.layer.10.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.10.attention.self.key.bias torch.Size([768]) bert.encoder.layer.10.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.10.attention.self.value.bias torch.Size([768]) bert.encoder.layer.10.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.10.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.10.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.10.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.10.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.10.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.10.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.10.output.dense.bias torch.Size([768]) bert.encoder.layer.10.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.10.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.11.attention.self.query.weight torch.Size([768, 768]) bert.encoder.layer.11.attention.self.query.bias torch.Size([768]) bert.encoder.layer.11.attention.self.key.weight torch.Size([768, 768]) bert.encoder.layer.11.attention.self.key.bias torch.Size([768]) bert.encoder.layer.11.attention.self.value.weight torch.Size([768, 768]) bert.encoder.layer.11.attention.self.value.bias torch.Size([768]) bert.encoder.layer.11.attention.output.dense.weight torch.Size([768, 768]) bert.encoder.layer.11.attention.output.dense.bias torch.Size([768]) bert.encoder.layer.11.attention.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.11.attention.output.LayerNorm.bias torch.Size([768]) bert.encoder.layer.11.intermediate.dense.weight torch.Size([3072, 768]) bert.encoder.layer.11.intermediate.dense.bias torch.Size([3072]) bert.encoder.layer.11.output.dense.weight torch.Size([768, 3072]) bert.encoder.layer.11.output.dense.bias torch.Size([768]) bert.encoder.layer.11.output.LayerNorm.weight torch.Size([768]) bert.encoder.layer.11.output.LayerNorm.bias torch.Size([768]) bert.pooler.dense.weight torch.Size([768, 768]) bert.pooler.dense.bias torch.Size([768]) classifier.weight torch.Size([7, 768]) classifier.bias torch.Size([7])
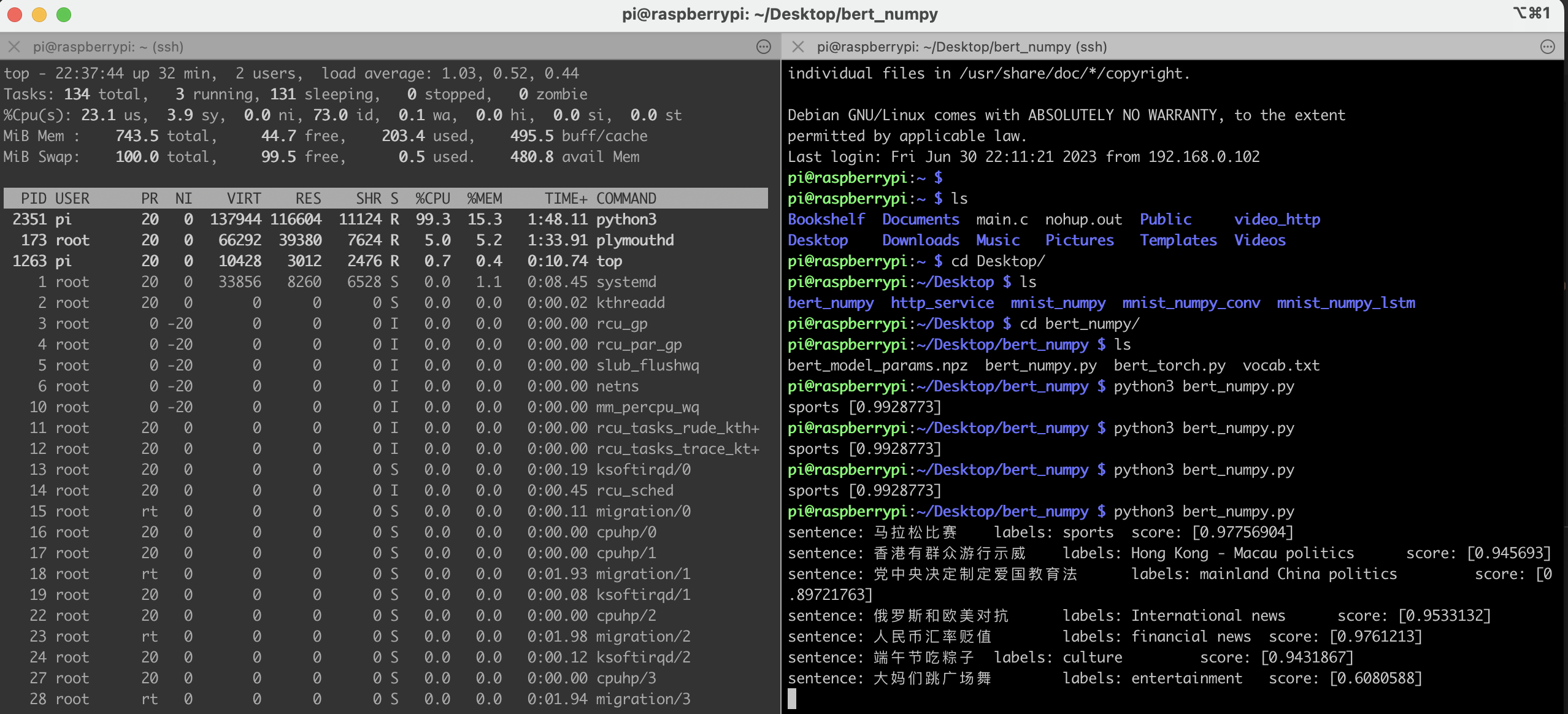
为了实现numpy的bert模型,踩了两天的坑,一步步对比huggingface源码实现的,真的太难了~~~
这是使用numpy实现的bert代码,分数上和huggingface有稍微的一点点区别,可能是模型太大,保存的模型参数误差累计造成的!
看下面的代码真的有利于直接了解bert模型结构,各种细节简单又到位,自己都服自己,研究这个东西~~~
import numpy as np def word_embedding(input_ids, word_embeddings): return word_embeddings[input_ids] def position_embedding(position_ids, position_embeddings): return position_embeddings[position_ids] def token_type_embedding(token_type_ids, token_type_embeddings): return token_type_embeddings[token_type_ids] def softmax(x, axis=None): # e_x = np.exp(x).astype(np.float32) # e_x = np.exp(x - np.max(x, axis=axis, keepdims=True)) sum_ex = np.sum(e_x, axis=axis,keepdims=True).astype(np.float32) return e_x / sum_ex def scaled_dot_product_attention(Q, K, V, mask=None): d_k = Q.shape[-1] scores = np.matmul(Q, K.transpose(0, 2, 1)) / np.sqrt(d_k) if mask is not None: scores = np.where(mask, scores, np.full_like(scores, -np.inf)) attention_weights = softmax(scores, axis=-1) # print(attention_weights) # print(np.sum(attention_weights,axis=-1)) output = np.matmul(attention_weights, V) return output, attention_weights def multihead_attention(input, num_heads,W_Q,B_Q,W_K,B_K,W_V,B_V,W_O,B_O): q = np.matmul(input, W_Q.T)+B_Q k = np.matmul(input, W_K.T)+B_K v = np.matmul(input, W_V.T)+B_V # 分割输入为多个头 q = np.split(q, num_heads, axis=-1) k = np.split(k, num_heads, axis=-1) v = np.split(v, num_heads, axis=-1) outputs = [] for q_,k_,v_ in zip(q,k,v): output, attention_weights = scaled_dot_product_attention(q_, k_, v_) outputs.append(output) outputs = np.concatenate(outputs, axis=-1) outputs = np.matmul(outputs, W_O.T)+B_O return outputs def layer_normalization(x, weight, bias, eps=1e-12): mean = np.mean(x, axis=-1, keepdims=True) variance = np.var(x, axis=-1, keepdims=True) std = np.sqrt(variance + eps) normalized_x = (x - mean) / std output = weight * normalized_x + bias return output def feed_forward_layer(inputs, weight, bias, activation='relu'): linear_output = np.matmul(inputs,weight) + bias if activation == 'relu': activated_output = np.maximum(0, linear_output) # ReLU激活函数 elif activation == 'gelu': activated_output = 0.5 * linear_output * (1 + np.tanh(np.sqrt(2 / np.pi) * (linear_output + 0.044715 * np.power(linear_output, 3)))) # GELU激活函数 elif activation == "tanh" : activated_output = np.tanh(linear_output) else: activated_output = linear_output # 无激活函数 return activated_output def residual_connection(inputs, residual): # 残差连接 residual_output = inputs + residual return residual_output def tokenize_sentence(sentence, vocab_file = 'vocab.txt'): with open(vocab_file, 'r', encoding='utf-8') as f: vocab = f.readlines() vocab = [i.strip() for i in vocab] # print(len(vocab)) tokenized_sentence = ['[CLS]'] + list(sentence) + ["[SEP]"] # 在句子开头添加[cls] token_ids = [vocab.index(token) for token in tokenized_sentence] return token_ids # 加载保存的模型数据 model_data = np.load('bert_model_params.npz') word_embeddings = model_data["bert.embeddings.word_embeddings.weight"] position_embeddings = model_data["bert.embeddings.position_embeddings.weight"] token_type_embeddings = model_data["bert.embeddings.token_type_embeddings.weight"] def model_input(sentence): token_ids = tokenize_sentence(sentence) input_ids = np.array(token_ids) # 输入的词汇id word_embedded = word_embedding(input_ids, word_embeddings) position_ids = np.array(range(len(input_ids))) # 位置id # 位置嵌入矩阵,形状为 (max_position, embedding_size) position_embedded = position_embedding(position_ids, position_embeddings) token_type_ids = np.array([0]*len(input_ids)) # 片段类型id # 片段类型嵌入矩阵,形状为 (num_token_types, embedding_size) token_type_embedded = token_type_embedding(token_type_ids, token_type_embeddings) embedding_output = np.expand_dims(word_embedded + position_embedded + token_type_embedded, axis=0) return embedding_output def bert(input,num_heads): ebd_LayerNorm_weight = model_data['bert.embeddings.LayerNorm.weight'] ebd_LayerNorm_bias = model_data['bert.embeddings.LayerNorm.bias'] input = layer_normalization(input,ebd_LayerNorm_weight,ebd_LayerNorm_bias) #这里和模型输出一致 for i in range(12): # 调用多头自注意力函数 W_Q = model_data['bert.encoder.layer.{}.attention.self.query.weight'.format(i)] B_Q = model_data['bert.encoder.layer.{}.attention.self.query.bias'.format(i)] W_K = model_data['bert.encoder.layer.{}.attention.self.key.weight'.format(i)] B_K = model_data['bert.encoder.layer.{}.attention.self.key.bias'.format(i)] W_V = model_data['bert.encoder.layer.{}.attention.self.value.weight'.format(i)] B_V = model_data['bert.encoder.layer.{}.attention.self.value.bias'.format(i)] W_O = model_data['bert.encoder.layer.{}.attention.output.dense.weight'.format(i)] B_O = model_data['bert.encoder.layer.{}.attention.output.dense.bias'.format(i)] attention_output_LayerNorm_weight = model_data['bert.encoder.layer.{}.attention.output.LayerNorm.weight'.format(i)] attention_output_LayerNorm_bias = model_data['bert.encoder.layer.{}.attention.output.LayerNorm.bias'.format(i)] intermediate_weight = model_data['bert.encoder.layer.{}.intermediate.dense.weight'.format(i)] intermediate_bias = model_data['bert.encoder.layer.{}.intermediate.dense.bias'.format(i)] dense_weight = model_data['bert.encoder.layer.{}.output.dense.weight'.format(i)] dense_bias = model_data['bert.encoder.layer.{}.output.dense.bias'.format(i)] output_LayerNorm_weight = model_data['bert.encoder.layer.{}.output.LayerNorm.weight'.format(i)] output_LayerNorm_bias = model_data['bert.encoder.layer.{}.output.LayerNorm.bias'.format(i)] output = multihead_attention(input, num_heads,W_Q,B_Q,W_K,B_K,W_V,B_V,W_O,B_O) output = residual_connection(input,output) output1 = layer_normalization(output,attention_output_LayerNorm_weight,attention_output_LayerNorm_bias) #这里和模型输出一致 output = feed_forward_layer(output1, intermediate_weight.T, intermediate_bias, activation='gelu') output = feed_forward_layer(output, dense_weight.T, dense_bias, activation='') output = residual_connection(output1,output) output2 = layer_normalization(output,output_LayerNorm_weight,output_LayerNorm_bias) #一致 input = output2 bert_pooler_dense_weight = model_data['bert.pooler.dense.weight'] bert_pooler_dense_bias = model_data['bert.pooler.dense.bias'] output = feed_forward_layer(output2, bert_pooler_dense_weight.T, bert_pooler_dense_bias, activation='tanh') #一致 return output # for i in model_data: # # print(i) # print(i,model_data[i].shape) id2label = {0: 'mainland China politics', 1: 'Hong Kong - Macau politics', 2: 'International news', 3: 'financial news', 4: 'culture', 5: 'entertainment', 6: 'sports'} classifier_weight = model_data['classifier.weight'] classifier_bias = model_data['classifier.bias'] if __name__ == "__main__": sentences = ["马拉松比赛","香港有群众游行示威","党中央决定制定爱国教育法","俄罗斯和欧美对抗","人民币汇率贬值","端午节吃粽子","大妈们跳广场舞"] while True: # 示例用法 for sentence in sentences: # print(model_input(sentence).shape) output = bert(model_input(sentence),num_heads=12) # print(output) output = feed_forward_layer(output[:,0,:], classifier_weight.T, classifier_bias, activation='') # print(output) output = softmax(output,axis=-1) label_id = np.argmax(output,axis=-1) label_score = output[0][label_id] print("sentence:",sentence,"\tlabels:",id2label[label_id[0]],"\tscore:",label_score)
这是hugging face上找的一个别人训练好的模型,roberta模型作新闻7分类,并且保存模型结构为numpy格式,为了上面的代码加载
import numpy as np from transformers import AutoModelForSequenceClassification,AutoTokenizer,pipeline model = AutoModelForSequenceClassification.from_pretrained('uer/roberta-base-finetuned-chinanews-chinese') tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-chinanews-chinese') text_classification = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer) print(text_classification("马拉松决赛")) # print(model) # 打印BERT模型的权重维度 for name, param in model.named_parameters(): print(name, param.data.shape) # # # 保存模型参数为NumPy格式 model_params = {name: param.data.cpu().numpy() for name, param in model.named_parameters()} np.savez('bert_model_params.npz', **model_params) # model_params
对比两个结果:
hugging face:[{'label': 'sports', 'score': 0.9929242134094238}]
numpy:sports [0.9928773]
多思考也是一种努力,做出正确的分析和选择,因为我们的时间和精力都有限,所以把时间花在更有价值的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号