可持久化数据结构学习笔记
定义
可持久化数据结构,主要解决的问题是查询数据结构的所有历史版本。
如果每对数据结构修改一次,就暴力记录新的数据结构,那么时间和空间复杂度都会增加 \(O(m)\) 。显然无法接受。
而可持久化数据结构的核心思想是记录当前版本与上个版本不一样的地方。这样一来,数据结构的时间复杂度没有增加,空间复杂度仅增长维与时间同级的规模。
换而言之,可持久化数据结构能够高效地记录一个数据结构的所有历史状态。
可持久化Trie
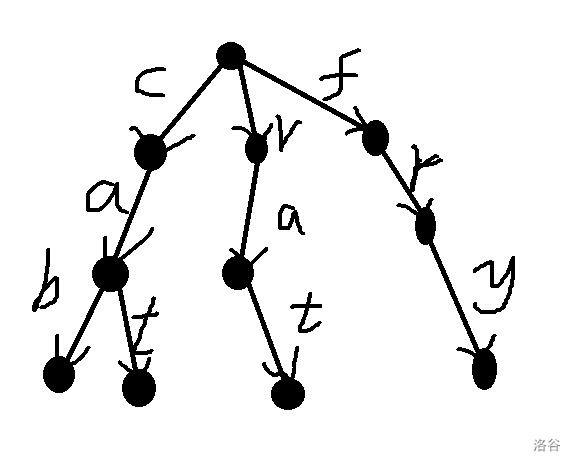
以记录字符串 \(cat,rat,cab,fry\) 为例。下图是普通的 \(Trie\) 树储存方法。
而可持久化 Trie 的按照以下步骤插入一个新的字符串 \(s\):
1.设当前可持久化 Trie 的根节点为 \(root\) ,令 \(p=root,i=0\)。
2.建立一个新的节点 \(q\),令 \(root'=q\)。
3.若 \(p \ne 0\),则对于每种字符 \(c\) ,令 \(trie[q,c]=trie[p,c]\)。
4.建立一个新的节点 \(q'\),令 \(trie[q,s_i]=q'\)。换言之,除了字符指针 \(s_i\) 不同之外,节点 \(q\) 与节点 \(p\) 的其他信息完全相同。(只记录不同的地方)
5.令 \(p=trie[p,s_i],q=trie[q,s_i],i=i+1\)。
6.重复步骤 3~5,直至 \(i\) 到达字符串末尾。
以上摘自 lyd 大佬的《算法竞赛进阶指南》。
通过以上的步骤,最终得到的可持久化 Trie 就如下图所示。
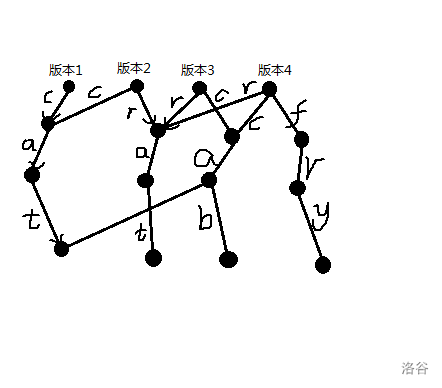
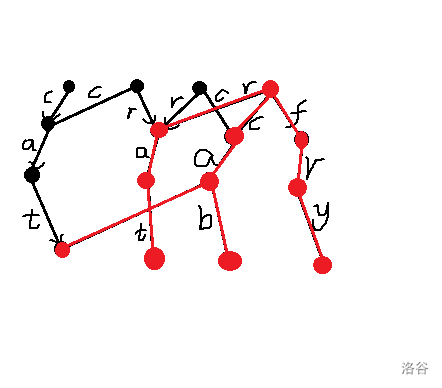
最上面的点就是每个版本的根节点。从每个版本的根节点出发,就可以得到该版本的 Trie 树。如下图所示,表示的是最后一个版本的 Trie
例题 最大异或和
题意
给定一个非负整数序列 \(a\),初始长度为 \(n\)。有 \(m\) 个操作,有以下两种操作类型:
1.A x:添加操作,表示在序列末尾添加一个数 \(x\),序列的长度 \(n+1\)。
2.Q l r x:询问操作,你需要找到一个位置 \(p\),满足\(l≤p≤r\),使得: $a[p] \oplus a[p+1] \oplus ... \oplus a[N] \oplus xa[p]⊕a[p+1]⊕...⊕a[N]⊕x $最大,输出最大是多少。
思路
首先可以回顾一下本题的简化版 最大异或对。
此题的题意可以简述为从 \(a\) 数组中选取两个数,使它们的异或值最大。可以看成是每新添加一个数,和之前的所有数进行匹配。我们可以把原有的数拆分成二进制数,按位从高到底储存到 Trie 中,
对于新添加的数,如果它在二进制表示下的最高位为 \(1\),那么如果在 Trie 中储存了最高位为 \(0\) 的数,那么就往这个子树走。以此类推。由于二进制下前一位为 \(1\) 后面全部为 \(0\) 一定比前一位为 \(0\) 后面全部为 \(1\) 更大。
由于 Trie 的深度为 \(log n\),所以这样做的时间复杂度为 \(O(nlogn)\)。
回到本题。可以先用前缀和的思想处理原数组,对于题目中的 \(a[p] \oplus....a[n] \oplus x\),就可以转化为 \(s[p-1] \oplus s[n] \oplus x\) 。
而 \(s[n] \oplus x\) 是一个常数,那么就题意可以转化为从 \(l\) 到 \(r\) 中寻找一个数 \(p\),使得 \(s[p-1] \oplus s[n] \oplus x\) 最大。那么就和简化版很相似了。但是如果用普通的 Trie 就无法解决区间限制的问题。于是就要用到可持久化 Trie。
首先考虑 \(l=1\) 的特殊情况,在此情况下,就可以直接用可持久化 Trie 记录 \(r=2,3,4,5.....n\) 的每一个版本。查询的时候直接分别查询每一个历史版本即可。
但是如果 \(l \ne 1\) 就不能这样做了。
回顾一下查询的过程。设此时查询的数在二进制下第 \(i\) 位为 \(0\),那么我们就希望在 Tire树中继续查询代表 \(1\) 的子树(也就是右子树)。但是如果最终得到的实际的数下标 \(<l\) 那么就查询错误了。
于是就可以在每次插入的时候记录当前插入的数的编号,在每一个子节点记录在这棵子树内的最大的数的编号。这样就可以在查询时直接比较最大数的编号是否大于等于左区间,也就可以保证最终的答案一定在区间 \([l,r]\) 中了。
code:
#include<cstdio>
#include<cstring>
using namespace std;
const int N=6e5+10;
const int M=25*N;//每次插入一个数要拆分成25位的二进制数 因为log2(10000000)约等于24
int n,m;
int tr[M][2],num,max_id[M],root[N],s[N];
int max(int a,int b){return a>b?a:b;}
void insert(int i,int k,int p,int q) //当前数的编号,第几位,前一个版本,当前版本
{
if(k<0) //如果是叶节点
{
max_id[q]=i;
return ;
}
int v=s[i]>>k&1;//取出当前位上的数
if(p) tr[q][v^1]=tr[p][v^1]; //如果这一位上个版本存在,就将上个版本除了当前节点外其他信息复制过来
tr[q][v]=++num; //添加新节点
insert(i,k-1,tr[p][v],tr[q][v]);//插入下一位
max_id[q]=max(max_id[tr[q][0]],max_id[tr[q][1]]);//更新最大节点编号
}
int query(int root,int C,int L)
{
int p=root;
for(int i=23;i>=0;i--)
{
int v=C>>i&1;
if(max_id[tr[p][v^1]]>=L) p=tr[p][v^1];//对立面是否存在使得该位异或值为0的数
else p=tr[p][v];
}
return C^s[max_id[p]];//最后搜索到的叶子节点的max_id就是这个数的的下标
}
int main()
{
scanf("%d%d",&n,&m);
max_id[0]=-1; //插入s[0]
root[0]=++num;
insert(0,23,0,root[0]);
for(int i=1;i<=n;i++)
{
scanf("%d",&s[i]);
s[i]=s[i-1]^s[i];
root[i]=++num;
insert(i,23,root[i-1],root[i]);
}
char op[2];
int l,r,x;
while(m--)
{
scanf("%s",op);
if(op[0]=='A')
{
scanf("%d",&x);
n++;
s[n]=x^s[n-1];
root[n]=++num;
insert(n,23,root[n-1],root[n]);
}
else
{
scanf("%d%d%d",&l,&r,&x);
printf("%d\n",query(root[r-1],s[n]^x,l-1));//前缀和是从l-1~r-1
}
}
return 0;
}
主席树(可持久化线段树)
徐主席万岁!!!!!!!!!!!!!!
以区间最大值问题为例,线段树的“单点修改”只会使 \(O(logN)\) 个区间对应的节点发生更新。对于每个被更新的节点 \(p\),创建该节点的副本 \(p'\)。只要 \(p\) 不是叶子节点,\(p\) 的左右子树之一必然发生了更新,不妨设发生更新的是 \(p\) 的左子树 \(lc\),在 \(lc\) 中递归,返回时令 \(p'\) 的左子树为 \(lc'\),令 \(p'\) 的右子树与 \(p\) 的右子树相同,然后更新节点 \(p'\) 上的区间最大值即可。
下图展示了对位置 \(7\) 进行单点修改后,产生的新节点。
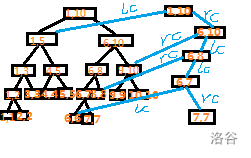
注意添加新节点后的向左新连的边不一定是新版本的左儿子。
由于可持久化线段树不再是完全二叉树,就不能用 \(p*2\) 和 \(p*2+1\) 来表示 \(p\) 节点的左右儿子。所以在可持久化线段树中储存的 \(l,r\) 不再是区间的左右端点,而是左右儿子的编号。
可持久化线段树的空间复杂度为 \(O(N+MlogN)\)。但需要注意,可持久化线段树难以支持区间修改操作。
例题 主席树 1
题意
维护一个长度为 \(n\) 的序列,支持如下几种操作:
1.在某个历史版本上修改某一个位置上的值。
2.访问某个历史版本上的某一位置的值
每进行一次操作(对于操作2,即为生成一个完全一样的版本,不作任何改动),就会生成一个新的版本。版本编号即为当前操作的编号(从1开始编号,版本0表示初始状态数组)。
思路
可以说本题是裸得不能再裸的主席树板子题。甚至比区间最大值的操作还要简单。唯一需要注意的就是题目中要求每次查询时生成一个完全一样的版本,那么直接令 \(root[i]=root[v]\) 就可以了。
还有一些主席树的细节见代码。
code:
#include<cstdio>
using namespace std;
const int N=1e6+10;
const int M=1e6+10;
struct tree{
int l,r;
int val;
}tr[N*4+M*21]; //最开始要建立[1,N]的线段树,之后每一次操作会新添加 log(N)个节点
int num,root[M],n,m,a[N];
int build_tree(int l,int r)//这里的l和r是区间的左右端点
{
int p=++num;//不能再用 p<<1和p<<1|1了
if(l==r)
{
tr[p].val=a[l];
return p;
}
int mid=(l+r)>>1;
tr[p].l=build_tree(l,mid),tr[p].r=build_tree(mid+1,r);//这里的l和r是p点的左右儿子编号
return p;
}
int insert(int p,int l,int r,int x,int k)//主席树的建树和修改(插入)操作都需要返回当前节点的编号,以便父节点记录子节点的编号
{
int q=++num;
tr[q]=tr[p];//除了修改的节点,新版本的其他信息与原版本完全一样
if(l==r)
{
tr[q].val=k;
return q;
}
int mid=(l+r)>>1;
if(x<=mid) tr[q].l=insert(tr[p].l,l,mid,x,k);
else tr[q].r=insert(tr[p].r,mid+1,r,x,k);
return q;
}
int query(int p,int l,int r,int x)
{
if(l==r) return tr[p].val;
int mid=(l+r)>>1;
if(x<=mid) return query(tr[p].l,l,mid,x);
else return query(tr[p].r,mid+1,r,x);
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
root[0]=build_tree(1,n);
for(int v,opt,loc,val,i=1;i<=m;i++)
{
scanf("%d%d",&v,&opt);
if(opt==1)
{
scanf("%d%d",&loc,&val);
root[i]=insert(root[v],1,n,loc,val);
}
else
{
scanf("%d",&loc);
printf("%d\n",query(root[v],1,n,loc));
root[i]=root[v];
}
}
return 0;
}
例题 主席树 2
题意
给定一个序列。多次查询在区间 \([l,r]\) 中第 \(k\) 小的数。
思路
由于本题中的数据范围较大,同时又只关心数与数之间的大小关系,于是可以对序列进行离散化处理。
然后在数值上建立一棵线段树。每个节点的值的含义为在该区间内一共插入过多少个数。起初数值为都为 \(0\)。
对于序列上的每一个数,在刚建立的可持久化线段树上进行单点修改操作,将其节点的数值 \(+1\)。
此时,可持久化线段树中“以 \(root[i]\) 为根的线段树”值域区间 \([l,r]\) 就保存了 \(A\) 的前 \(i\) 个数有多少落在值域 \([l,r]\) 内。
和上一道例题一样,如果区间是 \([1,r]\) 就可以直接二分查询了。具体做法就是判断当前节点左子树的值 \(val\) 是否大于等于 \(k\),如果大于就继续搜索左子树,因为左子树的值 \(val\) 就代表这个区间包含了前 \(val\) 小的数,反之则继续搜索右子树。直到搜索到的最后一个叶子节点就是答案。
有一条重要的性质:所有 \(root[i]\) 的结构都一样,因为都是存储同一个区间的信息。也就是说,除了值不同,任何版本的线段树的结构都是完全相同的。那么就可以用 \(root[r]\) 版本的值减去 \(root[l-1]\) 版本的值,那么就是在 \([l,r]\) 这个区间中的序列上有多少个数落在值域 \([L,R]\) 上(这里表述有点模糊,可以借代码理解一下)。所以利用相减就可以得出最终的答案。
code:
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
const int N=2e5+10;
const int M=2e5+10;
int n,m;
int a[N];
vector<int> nums;//离散化
struct tree{
int l,r,cnt;
}tr[N*4+N*17];//N*4是原始版本需要的节点数,每一次添加最多会增加log(N)个节点,总共会添加N次
int root[N],num;
int find(int x){return lower_bound(nums.begin(),nums.end(),x)-nums.begin(); }
int build(int l,int r)
{
int p=++num;
if(l==r) return p;
int mid=(l+r)>>1;
tr[p].l=build(l,mid),tr[p].r=build(mid+1,r);//这里的l,r表示的是左右儿子的节点编号,而不是区间边界
return p;
}
int insert(int p,int l,int r,int x)//上一个版本的根节点,左区间,右区间,需要修改的单点区间
{
int q=++num;
tr[q]=tr[p];
if(l==r)
{
tr[q].cnt++;
return q;
}
int mid=(l+r)>>1;
if(x<=mid) tr[q].l=insert(tr[p].l,l,mid,x);
else tr[q].r=insert(tr[p].r,mid+1,r,x);
tr[q].cnt=tr[tr[q].l].cnt+tr[tr[q].r].cnt;
return q;
}
int query(int q,int p,int l,int r,int k)
{
if(l==r) return l;
int cnt=tr[tr[q].l].cnt-tr[tr[p].l].cnt;
int mid=(l+r)>>1;
if(k<=cnt) return query(tr[q].l,tr[p].l,l,mid,k);
else return query(tr[q].r,tr[p].r,mid+1,r,k-cnt);//注意在右子树就是第k-cnt大的数了
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) scanf("%d",&a[i]),nums.push_back(a[i]);
sort(nums.begin(),nums.end());
nums.erase(unique(nums.begin(),nums.end()),nums.end());
root[0]=build(0,nums.size()-1);
for(int i=1;i<=n;i++) root[i]=insert(root[i-1],0,nums.size()-1,find(a[i]));
while(m--)
{
int l,r,k;
scanf("%d%d%d",&l,&r,&k);
printf("%d\n",nums[query(root[r],root[l-1],0,nums.size()-1,k)]);//变成离散化之前的值
}
return 0;
}
可持久化并查集
可持久化并查集,实际上就是用可持久化数组维护的并查集,本质和可持久化数组是一样的。(所以主席树是可持久化并查集的基础)
在没有使用路径压缩时的并查集,实际上就是一个 \(father\) 数组,也就是说,只要能够用主席树来维护 \(father\) 数组,也就可以实现可持久化并查集。
但是不使用路径压缩的并查集,时间复杂度太高了,所以还需要进一步优化。
想到并查集的两种优化方法,既然无法使用路径压缩,那只能用按秩合并来优化可持久化并查集了。
所谓“秩”,一般有两种定义,有的资料把并查集中集合的秩定义为树的深度(未路径压缩时)。有的资料把集合的秩定义为集合的大小。无论采用哪种定义,我们都可以把集合的秩记录在“代表元素”,也就是树根上。在合并时都把秩较小的树根作为秩较大的树根的子节点。
值得一题的是,当秩定义为集合的大小时,按秩合并也称为“启发式合并”。启发式合并的原则是:把“小的结构”合并到“大的结构”中,并且只会增加“小的结构”的查询代价。这样一来,把所有的结构全部合并起来,增加的总代价不会超过 \(NlogN\)。故单独采用“按秩合并”优化的并查集,每次查找的均摊时间复杂度为 \(O(logN)\)。
(以上两段摘自lyd大佬的《算法竞赛进阶指南》。)
这里给出秩为集合大小时,按秩合并的代码
int merge(int x,int y)
{
int fx=find(x),fy=find(y);
if(fx!=fy)
{
if(cnt[fx]>cnt[fy])
{
fa[fy]=fx;
cnt[fx]+=cnt[fy];
}
else
{
fa[fx]=fy;
cnt[fy]+=cnt[fx];
}
}
}
接着就可以实现可持久化并查集了,还是借一道例题来学习。
例题 可持久化并查集模板题
题意
给定 \(n\) 个集合,每个集合初始只有一个数。有 \(m\) 次操作,一共有 \(3\) 种操作类型:
-
a b 合并 a,b 所在集合;
-
k 回到第 k 次操作(执行三种操作中的任意一种都记为一次操作)之后的状态;
-
a b 询问 a,b 是否属于同一集合,如果是则输出 1,否则输出 0。
思路
模板题,思路就是实现可持久化并查集。这里的秩定义为树的深度。操作 2 要求回到第 \(k\) 次操作后,直接令 \(root[i]=root[k]\) 即可,一些实现细节见代码。
code:
#include<cstdio>
#include<iostream>
using namespace std;
const int N=1e5+10;
const int M=2e5+10;
struct node{
int l,r,fa,depth;
}tr[N*4+15*M];
int n,m,root[M],num;
int build_tree(int l,int r)//和一般的主席树建树方式一样
{
int p=++num;
if(l==r)
{
tr[p].fa=l;
return p;
}
int mid=l+r>>1;
tr[p].l=build_tree(l,mid);
tr[p].r=build_tree(mid+1,r);
return p;
}
int query(int p,int l,int r,int x)//查询第x个数在主席树中的下标
{
if(l==r) return p;
int mid=(l+r)>>1;
if(x<=mid) return query(tr[p].l,l,mid,x);
else return query(tr[p].r,mid+1,r,x);
}
int insert(int p,int x,int y,int l,int r)//单点修改操作,将第x个数的父亲修改为第y个数
{
int q=++num;
tr[q]=tr[p];//克隆一遍上一个版本的信息
if(l==r)
{
tr[q].fa=y;
return q;
}
int mid=l+r>>1;
if(x<=mid) tr[q].l=insert(tr[p].l,x,y,l,mid);//如果不是叶子节点,那么需要更新的节点所在的区间就和上一个版本不一样了
else tr[q].r=insert(tr[p].r,x,y,mid+1,r);
return q;
}
void add(int p,int l,int r,int x)//按秩合并的需要,即将第x个数所代表的并查集的深度+1
{
if(l==r)
{
tr[p].depth++;
return ;
}
int mid=(l+r)>>1;
if(x<=mid) add(tr[p].l,l,mid,x);
else add(tr[p].r,mid+1,r,x);
}
int find(int root,int x)//查找第x个数的祖先,注意,这里的y表示的是祖先在主席树中的下标,而不是祖先的数值,所以需要用tr[y].fa来表示数值
{
int y=query(root,1,n,x);
return tr[y].fa==x?y:find(root,tr[y].fa);
}
int main()
{
scanf("%d%d",&n,&m);
root[0]=build_tree(1,n);
for(int opt,a,b,k,i=1;i<=m;i++)
{
scanf("%d",&opt);
root[i]=root[i-1];//先将上一个版本克隆过来
if(opt==1)
{
scanf("%d%d",&a,&b);
int fx=find(root[i],a),fy=find(root[i],b);//这里的fx,fy均表示祖先在主席树中的编号,而不是数值
if(tr[fx].depth>tr[fy].depth) std::swap(fx,fy);//不妨设fx的深度比fy小,那么就一定是将fx所在的树合并到fy所在的子树下面了
if(tr[fx].fa==tr[fy].fa) continue;
root[i]=insert(root[i-1],tr[fx].fa,tr[fy].fa,1,n);//将fx的祖先更改为fy
if(tr[fx].depth==tr[fy].depth) add(root[i],1,n,tr[fy].fa);//只有当fx的深度与fy相等时,树的深度才会+1
}
else if(opt==2) scanf("%d",&k),root[i]=root[k];
else
{
scanf("%d%d",&a,&b);
int fx=find(root[i],a),fy=find(root[i],b);
printf("%d\n",tr[fx].fa==tr[fy].fa?1:0);//注意比较数值,而不是编号
}
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号