正则化是如何防止过拟合的
对于模型来说,其参数越少、越小,其复杂度越低,泛化能力越强;
正则化就是通过减小参数或稀疏化参数来达到降低模型复杂度,进而防止过拟合。
其中L1正则化是通过稀疏化参数来降低复杂度,L2正则化是通过减小参数的大小来降低复杂度。
一、L2正则化
L2正则化就是在原先的代价函数后面增加一个L2正则项
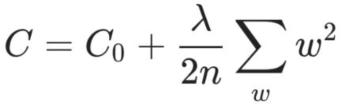
正则项的内容为所有权值的平方和除以样本数,λ为正则化系数,1/2是为了求导方便,是一个大于0的超参数(过大容易欠拟合,过小过拟合),代价函数对权值和偏置的求导如下
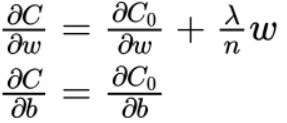
可以看出,正则项对权重w有影响,但对偏置b不产生影响;
进一步的,在权重更新的角度,式子如下
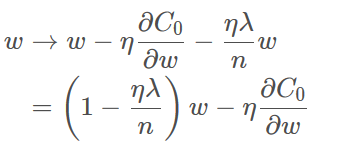
式中η、λ、n都是正数,故w前的系数小于1,其效果是对权重进行衰减,这就是weight decay,当然w的具体增加还是减少由整体式子来决定。
由此可见,L2正则化是通过减小参数的大小来防止过拟合的。
2. L1正则化
L1正则化是在原先的代价函数后面增加一个L1正则项
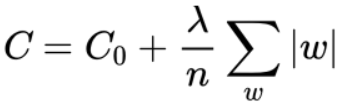
正则项的内容为所有权中的绝对值的和,乘以λ/n,代价函数求导后为
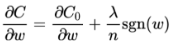
上式中的sgn表示为w的符号,则权重更新的式子为
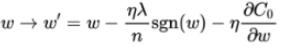
可见L1正则化的目的是让权重向0靠拢,通过稀疏化参数来防止过拟合的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号