Transformer代码解读
Scaled Dot Product Attention:
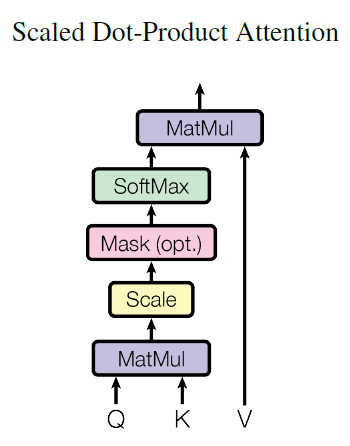
实现如图的操作,令Q乘以K的转置,如果需要mask,乘以Mask矩阵,再做Softmax操作,得到注意力权重矩阵,最后乘以V获得self-attention的输出。
class ScaledDotProductAttention(nn.Module): ''' Scaled Dot-Product Attention ''' def __init__(self, temperature, attn_dropout=0.1): super().__init__() self.temperature = temperature # 即根号dk self.dropout = nn.Dropout(attn_dropout) def forward(self, q, k, v, mask=None): attn = torch.matmul(q / self.temperature, k.transpose(2, 3)) if mask is not None: attn = attn.masked_fill(mask == 0, -1e9) # 将原矩阵乘以一个很小的数,即起到遮盖的目的 attn = self.dropout(F.softmax(attn, dim=-1)) output = torch.matmul(attn, v) return output, attn
位置编码Positional Encoding:
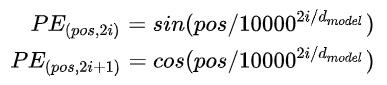
位置编码是直接加在embedding后的输入向量中的
class PositionalEncoding(nn.Module): def __init__(self, d_hid, n_position=200): super(PositionalEncoding, self).__init__() # Not a parameter self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid)) def _get_sinusoid_encoding_table(self, n_position, d_hid): ''' Sinusoid position encoding table ''' # TODO: make it with torch instead of numpy def get_position_angle_vec(position): return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)] sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 return torch.FloatTensor(sinusoid_table).unsqueeze(0)#(1,N,d) def forward(self, x): # x(B,N,d) return x + self.pos_table[:, :x.size(1)].clone().detach()
多头注意力MultiHead Attention:

如图所示,多头注意力机制就是将输入送进多个attention中,各自独立的处理数据,将各自的输出进行concatenate。
class MultiHeadAttention(nn.Module): ''' Multi-Head Attention module ''' def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1): super().__init__() self.n_head = n_head self.d_k = d_k self.d_v = d_v self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False) self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False) self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False) self.fc = nn.Linear(n_head * d_v, d_model, bias=False) self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5) self.dropout = nn.Dropout(dropout) self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) def forward(self, q, k, v, mask=None): d_k, d_v, n_head = self.d_k, self.d_v, self.n_head sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1) residual = q # Pass through the pre-attention projection: b x lq x (n*dv) # Separate different heads: b x lq x n x dv q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) k = self.w_ks(k).view(sz_b, len_k, n_head, d_k) v = self.w_vs(v).view(sz_b, len_v, n_head, d_v) # Transpose for attention dot product: b x n x lq x dv q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2) if mask is not None: mask = mask.unsqueeze(1) # For head axis broadcasting. q, attn = self.attention(q, k, v, mask=mask) #q (sz_b,n_head,N=len_q,d_k) #k (sz_b,n_head,N=len_k,d_k) #v (sz_b,n_head,N=len_v,d_v) # Transpose to move the head dimension back: b x lq x n x dv # Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv) q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1) #q (sz_b,len_q,n_head,N * d_k) q = self.dropout(self.fc(q)) q += residual q = self.layer_norm(q) return q, attn
前向传播Feed Forward Network:
class PositionwiseFeedForward(nn.Module): ''' A two-feed-forward-layer module ''' def __init__(self, d_in, d_hid, dropout=0.1): super().__init__() self.w_1 = nn.Linear(d_in, d_hid) # position-wise self.w_2 = nn.Linear(d_hid, d_in) # position-wise self.layer_norm = nn.LayerNorm(d_in, eps=1e-6) self.dropout = nn.Dropout(dropout) def forward(self, x): residual = x x = self.w_2(F.relu(self.w_1(x))) x = self.dropout(x) x += residual x = self.layer_norm(x) return x
编码器EncoderLayer:
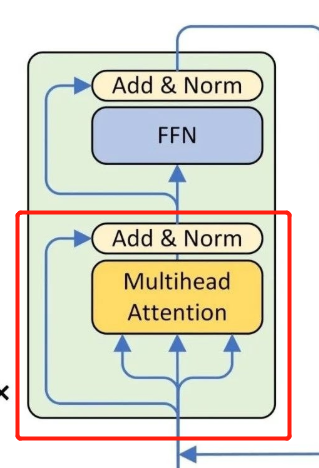
将上面的类组成一个编码器,结构如下图所示
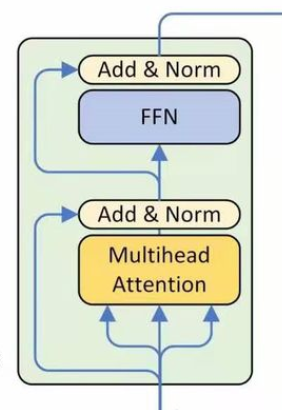
class EncoderLayer(nn.Module): ''' Compose with two layers ''' def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1): super(EncoderLayer, self).__init__() self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout) def forward(self, enc_input, slf_attn_mask=None): enc_output, enc_slf_attn = self.slf_attn(enc_input, enc_input, enc_input, mask=slf_attn_mask) enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
解码器DecoderLayer:
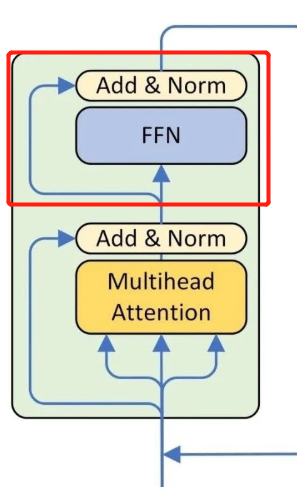
将上面的类组成一个解码器,如图所示
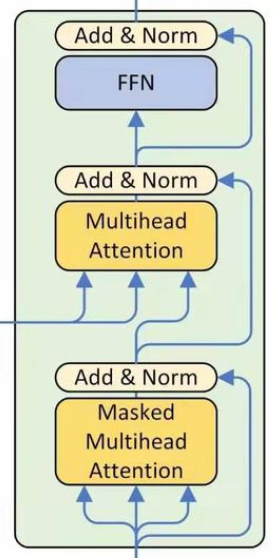
class DecoderLayer(nn.Module): ''' Compose with three layers ''' def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1): super(DecoderLayer, self).__init__() self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout) self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout) def forward(self, dec_input, enc_output, slf_attn_mask=None, dec_enc_attn_mask=None): dec_output, dec_slf_attn = self.slf_attn(dec_input, dec_input, dec_input, mask=slf_attn_mask) dec_output, dec_enc_attn = self.enc_attn(dec_output, enc_output, enc_output, mask=dec_enc_attn_mask) dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn
编码器部分Encoder:
class Encoder(nn.Module): ''' A encoder model with self attention mechanism. ''' def __init__( self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v, d_model, d_inner, pad_idx, dropout=0.1, n_position=200): super().__init__() self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx) self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) self.dropout = nn.Dropout(p=dropout) self.layer_stack = nn.ModuleList([ EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout) for _ in range(n_layers)]) self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) def forward(self, src_seq, src_mask, return_attns=False): enc_slf_attn_list = [] # -- Forward enc_output = self.dropout(self.position_enc(self.src_word_emb(src_seq))) enc_output = self.layer_norm(enc_output) for enc_layer in self.layer_stack: enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask) enc_slf_attn_list += [enc_slf_attn] if return_attns else [] if return_attns: return enc_output, enc_slf_attn_list return enc_output
解码器部分Decoder:
class Decoder(nn.Module): ''' A decoder model with self attention mechanism. ''' def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False): dec_slf_attn_list, dec_enc_attn_list = [], [] # -- Forward dec_output = self.dropout(self.position_enc(self.trg_word_emb(trg_seq))) dec_output = self.layer_norm(dec_output) for dec_layer in self.layer_stack: dec_output, dec_slf_attn, dec_enc_attn = dec_layer( dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask) dec_slf_attn_list += [dec_slf_attn] if return_attns else [] dec_enc_attn_list += [dec_enc_attn] if return_attns else [] if return_attns: return dec_output, dec_slf_attn_list, dec_enc_attn_list return dec_output
整体结构Transformer
class Transformer(nn.Module): ''' A sequence to sequence model with attention mechanism. ''' def __init__( self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx, d_word_vec=512, d_model=512, d_inner=2048, n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200, trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True): super().__init__() self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx self.encoder = Encoder( n_src_vocab=n_src_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=src_pad_idx, dropout=dropout) self.decoder = Decoder( n_trg_vocab=n_trg_vocab, n_position=n_position, d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner, n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v, pad_idx=trg_pad_idx, dropout=dropout) self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False) for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) assert d_model == d_word_vec, \ 'To facilitate the residual connections, \ the dimensions of all module outputs shall be the same.' self.x_logit_scale = 1. if trg_emb_prj_weight_sharing: # Share the weight between target word embedding & last dense layer self.trg_word_prj.weight = self.decoder.trg_word_emb.weight self.x_logit_scale = (d_model ** -0.5) if emb_src_trg_weight_sharing: self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight def forward(self, src_seq, trg_seq): src_mask = get_pad_mask(src_seq, self.src_pad_idx) # Encoder的Mask,一列Bool值,用于把标点mask掉 trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq) # 防止预测时提前知道下一部分的信息 enc_output, *_ = self.encoder(src_seq, src_mask) dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask) seq_logit = self.trg_word_prj(dec_output) * self.x_logit_scale return seq_logit.view(-1, seq_logit.size(2))
Mask的生成:
def get_pad_mask(seq, pad_idx): return (seq != pad_idx).unsqueeze(-2) def get_subsequent_mask(seq): ''' For masking out the subsequent info. ''' sz_b, len_s = seq.size() subsequent_mask = (1 - torch.triu( torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool() return subsequent_mask

 浙公网安备 33010602011771号
浙公网安备 33010602011771号