
机器学习笔记——第二周
1.多元梯度下降算法演练1——特征缩放(Feature Scaling)
(1)在一个有多个特征的机器学习问题中,并且确保这些特征的取值都处在一个相近的范围,这样梯度下降算法就能更快地收敛。
(2)例:关于房价问题。假如有一个具有两个特征的问题:x1:房屋面积的大小,取值在0~2000之间;x2:房屋的数量,取值在1~5之间。以两个参数分别为横纵坐标,绘制代价函数的等高线图(下图):
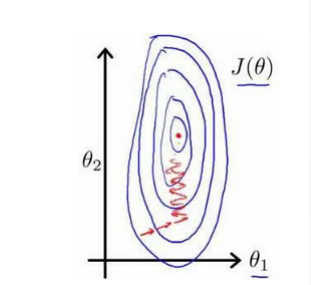
- 可以看到,梯度下降算法需要非常多次的迭代才能收敛(达到全局的最小值)。为了解决这个问题,我们可以进行特征缩放,将特征的取值约束到-1到1之间,或者其它非常接近-1到1的其它范围。
(3)均值归一化(Mean Normalization)
- 在特征缩放中,我们也需要做均值归一化的工作,有一个特征 x-n 用xn-μn来代替,让特征值具有为0的平均值(但不应用于x0中,因为x0=1,不可能为0的平均值。)
- 我们可以令:
![]() 来实现均值归一化。
来实现均值归一化。 - 其中:μn表示训练集中的特征xn的平均值 ;sn表示该特征的取值范围(最大值减最小值)。
- 通过特征缩放的方法,可以将梯度下降的速度变得更快,收敛所需的迭代次数更少。
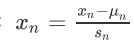 来实现均值归一化。
来实现均值归一化。
2.多元梯度下降算法演练2——学习率( Learning Rate)
(1)学习率是梯度下降算法的更新规则,确保梯度下降正常工作:
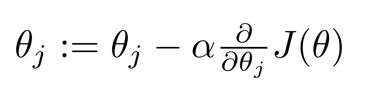
(2)我们画出求J(θ)最小值的图像:
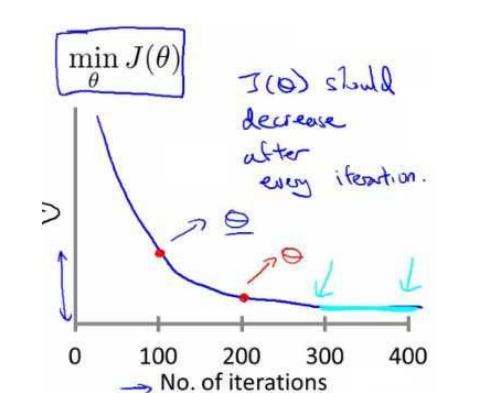
- x轴表示梯度下降算法的迭代次数。
- θ(蓝色)表示运行了100次的梯度下降迭代,得到的一个θ值,这个θ纵坐标代表根据此θ值算出的J(θ)。
- 通过图像我们可以看出,这条曲线,随着x轴的增大,逐渐趋于平稳,当进行了400次迭代后(即x=400)时,曲线几乎没有变化,因此我们可以通过这个图像来判断梯度下降算法已经收敛了。
- 如果梯度下降算法正常工作,那么每一步迭代后的J(θ)都应该是下降的。但是有时候我们也会看到这样的图像:
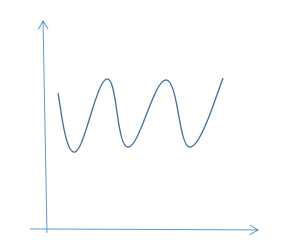
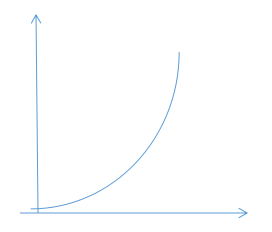
- 如果曲线J(θ)实际上是不断上升,或出现反复波动的情况,这表明梯度下降算法没有正常工作,通常意味着我们的应该设置较小的学习率α。如果学习率过大,那么梯度下降算法将会不断地冲过最小值,然后会得到越来越糟糕的结果。
- 数学家证明,只要学习率α足够小,那么每次迭代后的代价函数J(θ)都会下降。
(3)我们应该设置合适的学习率,学习率过大或者过小会出现怎样的问题呢?
- 当学习率过大时:代价函数J(θ)可能不会每次迭代都下降,甚至可能不收敛;
- 当学习率过小时:梯度下降算法会收敛得很慢,需要迭代很多次才能够达到J(θ)的最小值。
(4)另外,我们可以进行一些自动的收敛测试。让一种算法来告诉我们梯度下降算法是否已经收敛了。例如,我们可以设置一个很小的值,当代价函数J(θ)一步步迭代后的下降小于这个很小的值,那么我们就可以因此判断这个函数已经收敛。
3.特征和多项式回归(Features and Polynomial Regression)
- 我们可以使用多元线性回归的方式对算法做一个简单的修改来实现模型与数据的拟合。
- 可以通过二次方模型或者三次方模型来适应我们的数据。
4.正规方程( Normal Equation)
(1)对于某些线性回归问题,不用迭代算法,就可以一次求的参数θ的最优值,这个方式就是正规方程。
(2)例:m=4
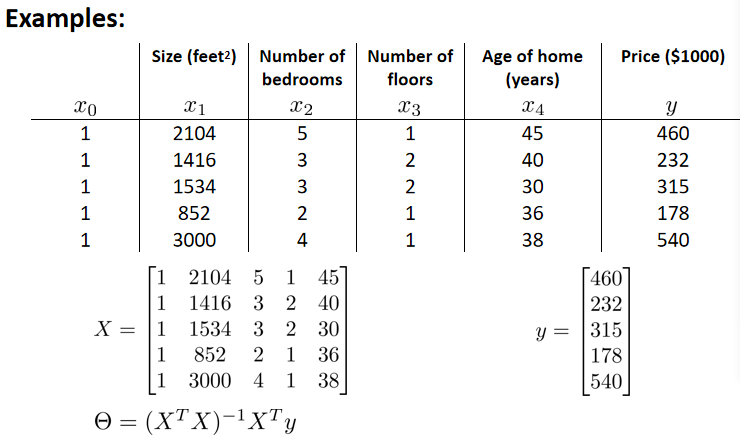
构造矩阵X,这个矩阵基本包含了训练样本的所有特征变量。X是一个m*(n+1)的矩阵,Y是一个m维向量。
其中,m是训练样本数量;n是特征变量数,实际上是(n+1)(因为X矩阵中加了额外的特征变量x0)。
用矩阵X和向量Y来求算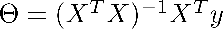 ,这样可以计算出使得代价函数最小化的θ值。
,这样可以计算出使得代价函数最小化的θ值。
5.正规方程在矩阵不可逆的情况下的解决方案:
首先看是否有多余的特征,如果有就将多余的特征删除;如果没有多余的特征,我们可以考虑是否有过多的特征,可以选择删除一些删掉后对结果没有影响的特征。
在Octave中,用pinv函数(也称伪逆函数)来使算法正常运行。
6.正规方程和梯度下降的比较:

判断n的数量大小通常是以一万左右来衡量。并没有固定的值。
注:笔记中的内容均来自与吴恩达《机器学习》视频课程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号