爬取网易云音乐评论


上图中,搜索到评论后,在新窗口打开,却是空白页面,所以进行以下几步。
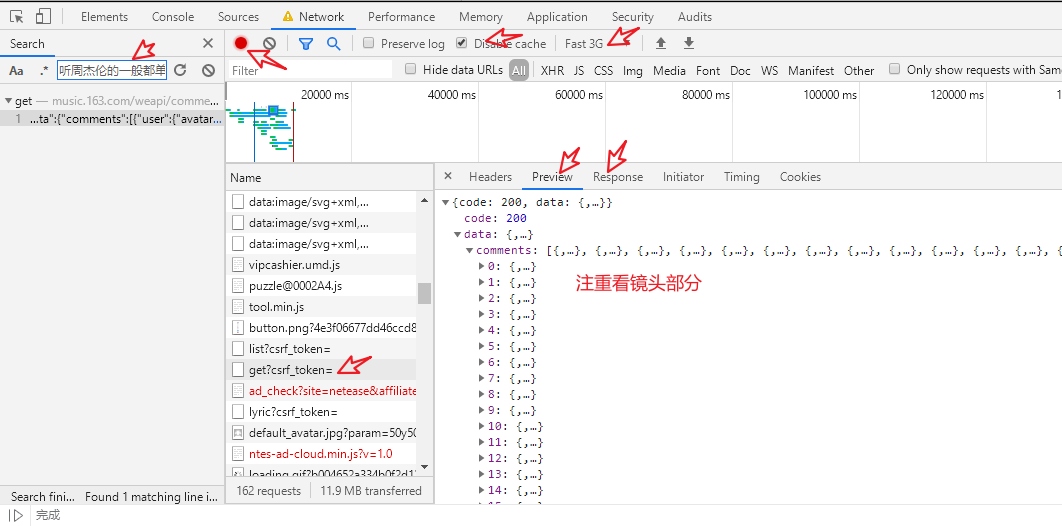
从服务器获取内容有多种方法,最常用的就是get和post, get方法就是直接从服务器获取内容,其参数都在网址的字符串里面;
post的话,需要向服务器提供特定/指定的data服务器才会给你数据。
所以在此次爬虫中,用的既然是POST方法,点击标头(Heades)向下拉,找From data,如下下图所示:

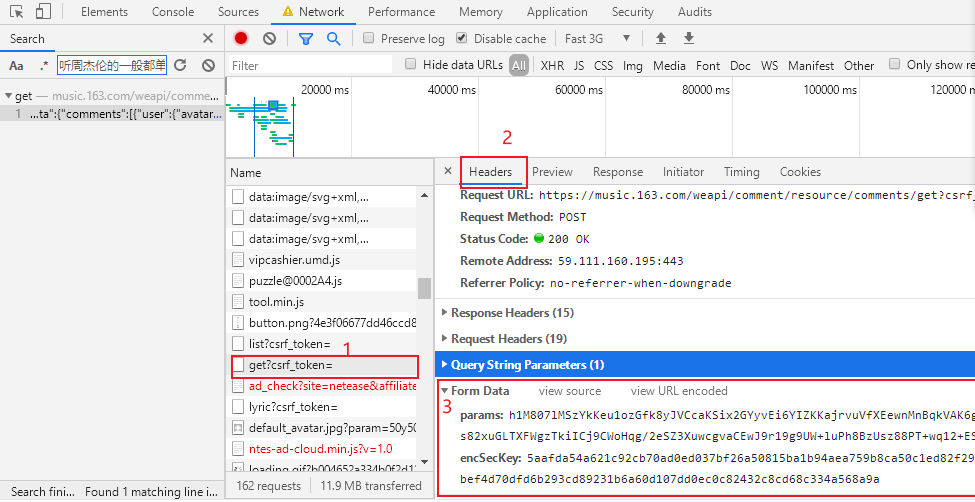
From Data是我们给服务器的内容,这样服务器验证后才会给我们返回内容。
第一阶段:
先把评论内容爬下来:
import requests
import bs4
import re
import openpyxl
def open_url(url):
name_id=url.split("=")[1] #用等号分割,分割后的第2个元素,e.g. https://music.163.com/#/song?id=1368934278,第2个元素是1368934278
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'","origin": "https://music.163.com","pragma": "no-cache","referer": "https://music.163.com/song?id={}".format(name_id),"sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-origin"}
#上一行的headrs中多传了refer,origin,pragma等参数,以免服务器疑神疑鬼
params = "rI3bLLAxz/t3/BANZWzk9NULxcbFEs+vEB1/q2416qyrw0UQc+k7iTBJACUFz9/FQiJcd6HYEMCB2s5wz43TeAhlDngWbLWbJlR5dSAhpKve0D6XMoxupTBiUWy7Ayx2nh/9Hv4gdFZp1lJQbtQaKf5YderW5zZMZGLvNYsFlxMLQvU/gkhBROkGVnzS3QKrDhm1IJeSNEKtjLkiZULkUc/IaOeqDdbdiITodDXlo8b6tXQ2TesbTjvTAuZKu2uxtPTYuncrZJdcK/ihYUTPzw=="
encSecKey="b3ebf54cbc3d8e1277cba213ef5b9562d1cc5f9515e852d5341b7b79ddfe7e65e96f18c22fe629984274d09d419ffc7c796342936c9e8f578ac44dd814fb6b362a02559d834e3e5a382a9f99418997576ad63483e854fce61d188adcd918f3132bea7fb1c5becae800b4a17eb485e13513854cb836df47d31c485048940d28fb"
data={"params":params,"encSecKey":encSecKey} #此处注意用的paras和encSecKey是传给服务器的验证密钥,每首歌曲的id不同,密钥也不同;所以,以一个初学者的我来说不知道怎么去解决这个问题
target_url="https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
res=requests.post(target_url,headers=headers,data=data)
return res
def find_infor(res):
soup=bs4.BeautifulSoup(res.text,'html.parser')
soup.find()
def main():
url=input("请输入链接地址:")
res=open_url(url)
with open("网页初始解析3.txt",'w',encoding='utf-8') as f:
f.write(res.text)
# data=find_infor(res
# to_excel(data)
if __name__=="__main__":
main()
第二阶段:
提取并美化结果
截止到第一阶段,我们爬取到的是一个大的字符串,也即是json的数据;其实看起来就是python的一个字典形式;这里的以文本形式保存的数据结构,是一个大的字符串,这个大的字符串我们称之为json;
json通俗的说是用字符串的形式把python的数据结构给封装起来,操作JSON格式的数据,通常有json.loads和json.dumps方法。


最外面的一层是{}的明显是json。
import requests
import bs4
import json
import re
import openpyxl
def get_comments(res):
comments_json = json.loads(res.text)
comments = comments_json['data']["comments"]
# with open('comments.txt',"w",encoding="utf-8") as file:
# for each in comments:
# file.write(each['user']['nickname']+':\n\n')
# file.write(each['content']+'\n')
# file.write("---------------------------------\n")
return comments
def open_url(url):
name_id=url.split("=")[1] #用等号分割,分割后的第2个元素,e.g. https://music.163.com/#/song?id=1368934278,第2个元素是1368934278
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'","origin": "https://music.163.com","pragma": "no-cache","referer": "https://music.163.com/song?id={}".format(name_id),"sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-origin"}
#上一行的headrs中多传了refer,origin,pragma等参数,以免服务器疑神疑鬼
params = "rI3bLLAxz/t3/BANZWzk9NULxcbFEs+vEB1/q2416qyrw0UQc+k7iTBJACUFz9/FQiJcd6HYEMCB2s5wz43TeAhlDngWbLWbJlR5dSAhpKve0D6XMoxupTBiUWy7Ayx2nh/9Hv4gdFZp1lJQbtQaKf5YderW5zZMZGLvNYsFlxMLQvU/gkhBROkGVnzS3QKrDhm1IJeSNEKtjLkiZULkUc/IaOeqDdbdiITodDXlo8b6tXQ2TesbTjvTAuZKu2uxtPTYuncrZJdcK/ihYUTPzw=="
encSecKey="b3ebf54cbc3d8e1277cba213ef5b9562d1cc5f9515e852d5341b7b79ddfe7e65e96f18c22fe629984274d09d419ffc7c796342936c9e8f578ac44dd814fb6b362a02559d834e3e5a382a9f99418997576ad63483e854fce61d188adcd918f3132bea7fb1c5becae800b4a17eb485e13513854cb836df47d31c485048940d28fb"
data={"params":params,"encSecKey":encSecKey} #此处注意用的paras和encSecKey是传给服务器的验证密钥,每首歌曲的id不同,密钥也不同;所以,以一个初学者的我来说不知道怎么去解决这个问题
target_url="https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
res=requests.post(target_url,headers=headers,data=data)
return res
def find_infor(res):
soup=bs4.BeautifulSoup(res.text,'html.parser')
soup.find()
def main():
url=input("请输入链接地址:")
res=open_url(url)
comments=get_comments(res)
with open('comments1.txt',"w",encoding="utf-8") as file:
for each in comments:
file.write(each['user']['nickname']+':\n\n')
file.write(each['content']+'\n')
file.write("---------------------------------\n")
# with open("网页初始解析3.txt",'w',encoding='utf-8') as f:
# f.write(res.text)
# data=find_infor(res
# to_excel(data)
if __name__=="__main__":
main()
上述有点小问题,只打印了最新的评论,而没有打印精彩评论。
第三阶段继续看:
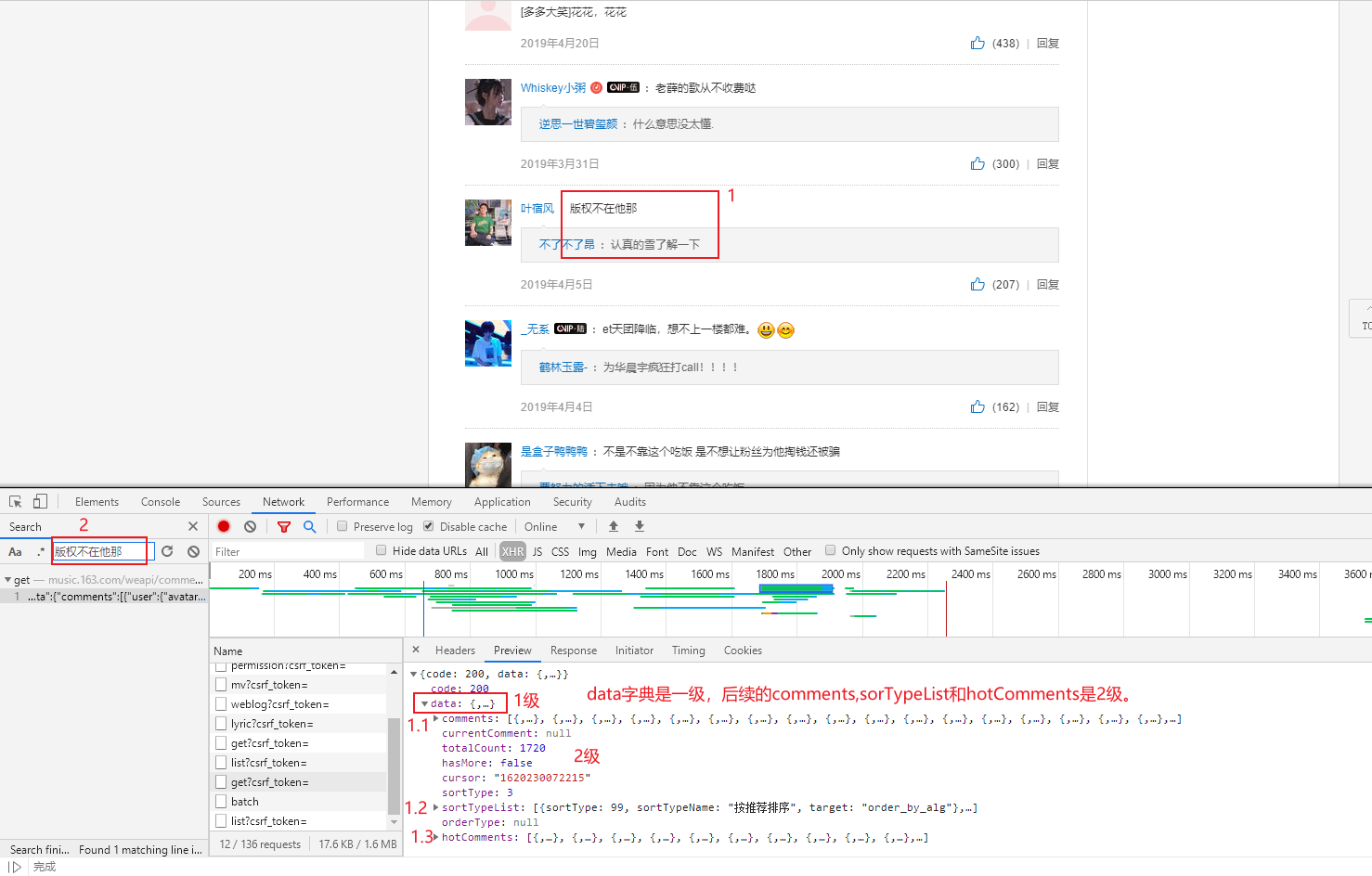
第四阶段:
打印了精彩评论但是却没打印,一般评论;
也尝试了,把一般评论和精彩评论合并到一块,但是用append()未成功。
import requests
import bs4
import json
import re
import openpyxl
def get_comments(res):
comments_json = json.loads(res.text)
comments = comments_json['data']["comments"]
comments1 = comments_json['data']['hotComments']
# comments = comments.append(comments1)
# with open('comments.txt',"w",encoding="utf-8") as file:
# for each in comments:
# file.write(each['user']['nickname']+':\n\n')
# file.write(each['content']+'\n')
# file.write("---------------------------------\n")
return comments1
def open_url(url):
name_id=url.split("=")[1] #用等号分割,分割后的第2个元素,e.g. https://music.163.com/#/song?id=1368934278,第2个元素是1368934278
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'","origin": "https://music.163.com","pragma": "no-cache","referer": "https://music.163.com/song?id={}".format(name_id),"sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-origin"}
#上一行的headrs中多传了refer,origin,pragma等参数,以免服务器疑神疑鬼
params = "oDVVbbZOHaFpsRbYsvfTFuwoSFkMd5C/Ne8TuTOoQ1+nuCmBjh9s1vwqDkXwWOd6qqA3nsQ3CV0vYtCN/NRnL0fpoF+xXaPCjwyvlJsP93LWLgNEYhNPtd4gPKEcd4jIxNLm0+7ywkaFSio8x8lS3zVOWUQXeo310FeGkfNg76qZzsjtA5fTIWkT7pCjMnTVMo8UR3mGdbdVgIF7q0cCzBq/wbKo/VytR/BCbMjm033R/ummZFmVwMAw1lL+tdphi25lUooqV1mrosiOZEJRMA=="
encSecKey = "9c1e8a0c9d5b4ad60ca0ee1e6688ac2a41cef5a3aea003a1d3e79eae42a589ea14f501ac48c8bf29f82f1a3d232f895081920f35e75ef38361afbcd5a4aec7ab91325c155a8195fd1f376410090633648cdeb2e480951f8d4bb78bb870fc8f376442b590dc496dc2f83e58b5be67e0a5450f25edb64175392ea8bd090c188379"
data={"params":params,"encSecKey":encSecKey} #此处注意用的paras和encSecKey是传给服务器的验证密钥,每首歌曲的id不同,密钥也不同;所以,以一个初学者的我来说不知道怎么去解决这个问题
target_url="https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
res=requests.post(target_url,headers=headers,data=data)
return res
def find_infor(res):
soup=bs4.BeautifulSoup(res.text,'html.parser')
soup.find()
def main():
url=input("请输入链接地址:")
res=open_url(url)
comments=get_comments(res)
print(type(comments)) #可看到comments是list列表
with open('comments6.txt',"w",encoding="utf-8") as file:
for each in comments:
file.write(each['user']['nickname']+':\n\n')
file.write(each['content']+'\n')
file.write("---------------------------------\n")
# with open("网页初始解析3.txt",'w',encoding='utf-8') as f:
# f.write(res.text)
# data=find_infor(res
# to_excel(data)
if __name__=="__main__":
main()
第五阶段:
搞定
import requests
import bs4
import json
import re
import openpyxl
def get_comments(res):
comments_json = json.loads(res.text)
comments1 = comments_json['data']["comments"]
comments2 = comments_json['data']['hotComments']
comments3 = comments1+comments2
# with open('comments.txt',"w",encoding="utf-8") as file:
# for each in comments:
# file.write(each['user']['nickname']+':\n\n')
# file.write(each['content']+'\n')
# file.write("---------------------------------\n")
return comments3
def open_url(url):
name_id=url.split("=")[1] #用等号分割,分割后的第2个元素,e.g. https://music.163.com/#/song?id=1368934278,第2个元素是1368934278
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'","origin": "https://music.163.com","pragma": "no-cache","referer": "https://music.163.com/song?id={}".format(name_id),"sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-origin"}
#上一行的headrs中多传了refer,origin,pragma等参数,以免服务器疑神疑鬼
params = "oDVVbbZOHaFpsRbYsvfTFuwoSFkMd5C/Ne8TuTOoQ1+nuCmBjh9s1vwqDkXwWOd6qqA3nsQ3CV0vYtCN/NRnL0fpoF+xXaPCjwyvlJsP93LWLgNEYhNPtd4gPKEcd4jIxNLm0+7ywkaFSio8x8lS3zVOWUQXeo310FeGkfNg76qZzsjtA5fTIWkT7pCjMnTVMo8UR3mGdbdVgIF7q0cCzBq/wbKo/VytR/BCbMjm033R/ummZFmVwMAw1lL+tdphi25lUooqV1mrosiOZEJRMA=="
encSecKey = "9c1e8a0c9d5b4ad60ca0ee1e6688ac2a41cef5a3aea003a1d3e79eae42a589ea14f501ac48c8bf29f82f1a3d232f895081920f35e75ef38361afbcd5a4aec7ab91325c155a8195fd1f376410090633648cdeb2e480951f8d4bb78bb870fc8f376442b590dc496dc2f83e58b5be67e0a5450f25edb64175392ea8bd090c188379"
data={"params":params,"encSecKey":encSecKey} #此处注意用的paras和encSecKey是传给服务器的验证密钥,每首歌曲的id不同,密钥也不同;所以,以一个初学者的我来说不知道怎么去解决这个问题
target_url="https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
res=requests.post(target_url,headers=headers,data=data)
return res
def find_infor(res):
soup=bs4.BeautifulSoup(res.text,'html.parser')
soup.find()
def main():
url=input("请输入链接地址:")
res=open_url(url)
comments=get_comments(res)
print(type(comments))
with open('comments7.txt',"w",encoding="utf-8") as file:
for each in comments:
file.write(each['user']['nickname']+':\n\n')
file.write(each['content']+'\n')
file.write("---------------------------------\n")
# with open("网页初始解析3.txt",'w',encoding='utf-8') as f:
# f.write(res.text)
# data=find_infor(res
# to_excel(data)
if __name__=="__main__":
main()
# import random
# list1=[1,2,3]
# list2=[4,5,6]
# print(list1,list2,end='\n')
# # list3=list1.append(list2)#list1.append(list2)之后list1为空了;
# # list3=list1.extend(list2)#list1.extend(list2)之后list1为空了;
# print(type(list1),list1.append(list2))
# print(type(list2),list1.extend(list2))
# list3=list1+list2
# print(type(list3),list3)
此外,关于加密部分可参考这两个:https://blog.csdn.net/weixin_44530979/article/details/87925950,https://blog.csdn.net/weixin_40352715/article/details/107879915,写的很好。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号