【MCU】"double 强转 uint64"程序飞了,损失惨重!听说因为代码没"对齐"程序就奔了?(深度剖析)【收藏】get这些技巧,HardFault_Handler排查只需要几分钟
【MCU】"double 强转 uint64"程序飞了,损失惨重!

1、聊一聊
一听这首歌曲,bug菌的思绪便飞到了十年前,没办法太经典了,As long as you love Me,Bug is always with you!
2、正文部分
1
情景
-
售后 : X工,现场出大事了,今天升级的程序跑着跑着就挂了!现在整个产线都等着这个设备恢复,能安排个人过来支援下吗?
-
bug菌 : my god !别慌,我问一下负责的A工。
-
bug菌 : 喂,A工,昨天升级的程序有问题,程序卡死,售后在现场你联系一下,支援他一波,顺便把程序发送给我一份,一起看看!
-
A工 : 啊,还有这种事,程序没改什么呀,行,我跟售后联系一下。
经过一番折腾,发现由于程序测试不到位,导致了一个强制类型转化引发的进入异常,这里就分享给大家。
2
bug演示
这是一个老项目,采用stm32F4芯片为主控,由于硬件限制而客户又不愿意花大价钱改造,所以程序架构等等都没有再大动作,由于通信上的传输和解析都是字节流,一些小的需求都只是在原来的通信架构上把4个字节拆成2个字节来用,然而这一次实在没办法没改接受数据类型,然后把一个double类型拆成了4个uint16来使用,没想到出问题了。
公司代码加密,所以这里简单的模拟演示了一下:
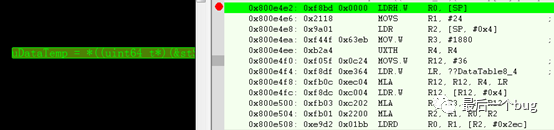
A工用一个double类型取地址,然后把地址强制转为uint64_t类型,以此类型指针取内容,当这段代码执行完程序就跳到了异常中断,导致死机。
其实这段代码对于经验丰富的人来说,一看就觉得很变扭,但是无论如何也不至于死机呀,毕竟强制类型转化大部分人拿来都是随便用。
3
bug解读
当看到A工写的这一套代码,bug菌其实隐隐约约就感觉这块有些问题,但是没敢确定,毕竟整套代码也是前人留下的,全是逻辑没什么精华也没有过细研究,最后看这段代码的汇编才知道问题所在。
在之前bug菌也曾比较详细的出过一篇分析此类问题的文章,可能这一块并没有吸引到你,不过还是一句话:"出来混都是要还的!"。
其实问题就出在LDRD这个ARM汇编指令上,LDRD指令表示从指定内存地址取double word,上面图片代码中的LDRD R0,R1,[R2,#0x2EC],可以分解为下面两个ldr步骤 :
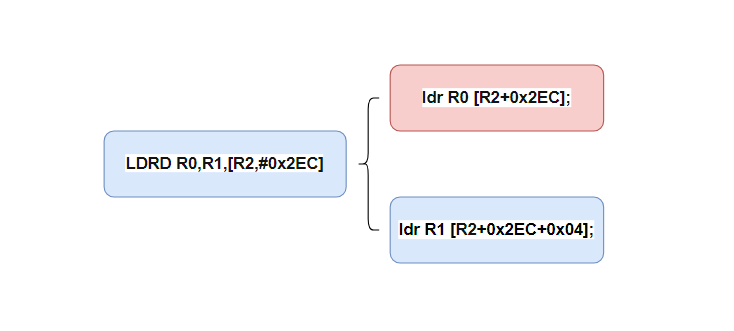
在ARM汇编指令集中LDRD和STRD是一对加载和提取指令,一般都需要使用__align(8)修饰来保证数据对象进行8直接对齐,而使用#pragma pack(8)是来指定结构体成员变量相对于第一个变量的地址的偏移量的对齐方式。
__align指示编译器在 n 字节边界上对齐变量,是一个存储类修饰符,当然也可以以让2字节的对象进行4字节对齐其与8字节对齐是等价的,一定要记得是存储的起始地址为8的整数倍。
对齐可以在一定程度上提高数据提取的效率,一旦起始地址没有对齐会导致对齐错误,所以上面的double浮点类型的结构体变量没有8字节地址对齐,当进行强制类型转化并使用LDRD指令就导致未对齐故障。
3
更专业点
当然对于跳转到硬件异常的故障是非常好排查的,下面这篇文章教你如何迅速的定位故障位置和故障信息 :
☞【收藏】get这些技巧,HardFault_Handler排查只需要几分钟
对于非对齐指令的执行会导致指令用法上的故障,那么Cortex芯片中相应的故障寄存器标志位会置位。


以上来自于Cortex技术文档,文档中也写得非常的详细。
当CPU尝试做一个未对齐的内存访问,然后就会发生此错误。特别是对于未对齐的LDM/STM/LDRD/STRD指令,所以进入异常中断以后查询芯片内部故障寄存器也是可以找到问题所在的,对于使用仿真器排查是再简单不过了,如果是离线排查就需要进行上篇文章那样打印相关日志来定位问题。
本文到此结束!
3、结束语
所以嵌入式软件的编写不能太过随意,往往你在PC机上跑得飞起的模拟程序,或许真正到嵌入式平台上根本没法运行。
好了,这里是公众号:“最后一个bug”,一个为大家打造的技术知识提升基地,创作不易,觉得不错给bug菌点个赞。
听说因为代码没"对齐"程序就奔了?(深度剖析)
1、来聊聊(轻松一刻)
来深圳这么久确实没有看到过下雪,而今天推荐的这首歌却唱出了广漂的小伙伴不少的心声,"...不下雪的广东,不一样的天空,他们都一样彼此有着破碎的梦...";也许这就是生活本来的模样吧。
好了,不管怎样心中都要充满着热爱!!今天为大家带来嵌入式中关于"对齐"的那些事,比如地址对齐、结构体数据对齐以及一些常用的处理小技巧。
2、嵌入式中的那些"周期"
在之前的《C语言里面嵌入点“机器码”玩一玩》中作者重点把指令与机器码以及数字电路进行了互连,相信大家应该对程序的运行有了一个形象的认识吧。那么执行这些指令的时间节拍到底是这样的呢?这里作者就把时钟周期、机器周期、指令周期等等周期概念跟大家简单的聊一聊。
1)时钟周期
当我们使用的晶振或者频率没有经过倍频处理,那么这时候的时钟周期 = 1/振荡频率;如果经过锁相环进行倍频以后那么这个时候的时钟周期 = 1/系统主频。
2)机器周期
我们都知道我们的CPU需要进行取指令、译码、执行,然后CPU进行每项基础的操作都需要时间,这个时间我们认为是机器周期,那么机器周期一般都会由一个或者多个时钟周期构成。
3)指令周期
需要知道的是每一条指令都是由一个或者多个机器周期构成的,不过现在随着处理器的进步出现了很多单周期的指令,单周期指令执行时间为一个时钟周期。那么对于多周期指令根据指令的复杂程度其执行时间是不一样的,所以作者在之前的说如何测定程序运行时间中提到:对于通过数指令个数来确定程序运行时间是比较麻烦的。
好了,这里对于这几个概念不过多解释了,主要是为了后面字节对齐效率分析进行一个铺垫,顺便简单画个图供大家理解下:
3、结构体内部对齐
小伙伴们对于int类型根据平台不同会存在差异比较熟悉,而对于结构体的大小也可能会因为系统的字节对齐原因产生变化。下面简单体会一下结构体内的字节对齐:
#include <stdio.h> #include <stdlib.h> /************************************************ * Fuciton :结构体定义区 * Author :(公众号:最后一个bug) ************************************************/ typedef struct _tag_Test { unsigned char byVal1; int intVal; unsigned char byVal2; } stTest; #pragma pack(1) typedef struct _tag_Test1 { unsigned char byVal1; int intVal; unsigned char byVal2; } stTest1; #pragma pack() typedef struct _tag_Test2 { int intVal; unsigned char byVal1; unsigned char byVal2; } stTest2; /************************************************ * Fuciton :main * Author :(公众号:最后一个bug) ************************************************/ int main(int argc, char*argv[]) { printf("sizeof(stTest) : %d\n",sizeof(stTest)); printf("sizeof(stTest1) : %d\n",sizeof(stTest1)); printf("sizeof(stTest2) : %d\n",sizeof(stTest2)); printf("公众号:最后一个bug"); return0; }
最终数据的结果:
解析一下:从上面的程序来看,int属于4个字节,那么结构体1采用四字节对齐的方式一共就是12个字节,而结构体2,我们通过使用#pragma pack(1)这样来使得结构体1个字节对齐,同时使用#pragma pack()来进行解除一个字节对齐模式,从而刚好占用6个字节,而结构体3仅仅只是相对结构体1进行变量顺序上的交换,却只有用了8个字节。
对于结构体3的解释 : 编译器在为结构体成员分配内存的时候,结构体的第一个成员分配在offset = 0的位置,而第二个成员通过计算其成员本身占用大小与当前字节对齐大小进行对比,如果还能够装满字节对齐大小,便直接存储,否则就需要分配到下一个对齐地址处,这样之前没有使用完的部分就被填充,从而在一定程度上浪费了一定的内存空间,而结构体3后两个成员刚好可以放到4字节对齐地址里面,所以内存空间减少。
所以平时大家也有这样的说法:“把结构体成员中字节占用比较大的放在结构体头部”,这种说法不完全正确,还是要根据成员大小情况具体排列位置,同时对于第二个结构体采用1字节对齐方式的处理办法便能够节省一定的内存,同时也增强了代码的可移植性,不过就是相对比较耗时间,后面作者会解释一下。
4、内存对齐
其实不仅仅只是结构体内部会存在这样的对齐方式,其实对于平时我们分配的全局变量等内存也是存在地址对齐的问题。我们这里想想如果仅仅只是上面的结构体内部成员对齐,而结构体首地址并没有对齐,那从整体上来看结构体内部对齐也就没有什么意义了。
这里作者就来说说内存对齐,我们都知道CPU在访问内存的时候是通过总线来进行访问,不同CPU其总线都有着不同的宽度,比如16位,32位,64位等,位数越高CPU对数据的吞吐量也就越大,那么一部分CPU为了简化设计加快访问速度,都会只能访问对齐地址上的数据,比如说一些16位的CPU仅仅只能访问偶数地址的内存数据。
那么对于跨越在两个对齐区域的多字节数据会如何处理呢?
1)对于支持非对齐地址访问的CPU,一般都会具有对应的非对齐访问指令,通过判断地址是否跨多个对齐区域,然后分别读取多个对齐区域,最后组合以后返回对应数据(如上图所示),这样明显会增加指令的运行时间,降低了CPU的运行效率;有些小伙伴就会问了,我看编译的汇编代码都是执行了一条指令呀,时间应该都是一样的呀?如果你提了这样的问题,记得返回去一下指令周期的定义。
2 )而对于不支持对齐地址访问的CPU,如果我们在程序中访问不对齐的地址,系统就会抛出异常,比如硬件中断、或者段错误等等。同样结构体对齐也要注意这样的访问问题,所以以后大家在发现程序异常"跑死",定位到异常点以后也可以往地址对齐这方面考虑。
说到这里很多小伙伴都会非常疑惑,好像我们平时写嵌入式代码并没有考虑这么多呀,也没发现有什么问题呀?听到你这里好像我没定义一个变量都要小心翼翼了。哈哈,是的,确实我们平时大多数时候都不用考虑,因为我们都使用了配套的编译器,编译器会检测不同的变量类型,然后为我们自动的进行内存分配的对齐处理,同样结构体内部对齐也会处理,不过对于有些指针的处理部分编译器并不会特意提示开发人员,比如说:我们把char*ptr指针转化为int*ptr指针进行++访问,便有可能会出现非对齐地址访问的问题。
5、最后小结
对于内存对齐问题,还有很多需要各位小伙伴注意的,比如代码的可移植性,不同平台的网络通信过程中的处理等等,都需要对其进行考虑和处理。这里对于该问题有个感性认识即可,对于部分问题还是需要具体熟悉芯片内核的处理办法进行综合分析,对于结构体还有很多丰富的操作技巧,后续作者会一一跟大家带来。
好了,这里是公众号:“最后一个bug”,一个为大家打造的技术知识提升基地。同时非常感谢各位小伙伴的支持,我们下期精彩见!
【收藏】get这些技巧,HardFault_Handler排查只需要几分钟
1、聊一聊
今天跟大家推荐的这首歌曲挺有意思的,特别是副歌部分记得加入歌单。
这篇文章主要是跟大家介绍几种比较使用的方法,用于排除stm32硬件fault,其实bug菌不太喜欢讲一些针对某款固定芯片的特有技术,这里仅仅只是以stm32为例讲解一下如何去处理此类问题,其他芯片效仿即可。
2、仿真定位排查
1
提出问题对于使用stm32有一段时间的小伙伴,应该都认识HardFault_Handler了吧,可能大部分都是在程序挂掉了以后才知道有这个中断服务函数,所以大家一般就把它与程序死机困在了一块,原因是里面写了一个死循环。
其实所谓的异常中断都是通知用户来完成响应操作,在开发阶段一旦有异常触发大部分都会在此处stop,然后观察系统的各状态寄存器等来排查异常触发点,而在实际的产品阶段此处应该是系统软件发生异常的最后补救点。
不过很多小伙伴都没有去修改官方的中断服务例程,当异常发生一脸懵逼不知道该如何下手排查问题,于是便拿jlink一步一步的仿真调试来查看程序在哪个点开始进入异常中断,如果程序不大可能还好排查;如果程序稍微大一点,花个几天时间应该大有人在,这就大大影响了开发的效率。
同时一些产品被封起来根本无法使用仿真器,而且有些fault可能非常难以复现,所以必须得使用一种自动检测的手段来排查问题。
2
理论依据既然bug菌要在这里跟大家介绍一些实用的方法,就一定得有一些理论基础,如果大家对下面的这些知识不熟悉还得好好补充一下:(这里以Cortex-M3为例)
需要补充的知识点:
-
Cortex-M3相关寄存器的作用;
-
Cortex-M3的双堆栈机制;
-
从用户模式到中断服务例程寄存器的入栈和出栈机制等;
-
fault 分类以及各自诱因等。
以上这几点知识大家都可以在<Cortex-M3权威指南>上找到,并且非常的通俗易懂,bug菌就不在这里重复"造轮子"了,如果有些小伙伴平时使用的并不是stm32,所需补充的知识其实大同小异,找到对应芯片内核参考手册,然而根据如上的几个方面进行分析即可。
3
排查原理对于常规的仿真器调试一旦程序进入HardFault_Handler,那么程序便卡在了中断服务程序中的死循环中,不太熟悉内核的小伙伴一定希望"如果仿真器能够有程序倒退功能该多好呀",也就说大部分的硬件异常只需找到主程序的进入点基本上就能定位具体的fault原因。
可惜的是目前仿真器并没有此类功能,程序是一直往下执行的,对于开发人员倒是可以通过编程让程序回到入口点,不过处理相对比较麻烦,不过我们可以通过程序运行的各个状态推导出之前的程序的运行状态。
然而异常中断本质上和普通的定时器中断等等并无差别,那么在中断触发前必然是要保存现场,运行完中断服务函数以后需要恢复现场,然后继续运行之前的程序,同样当触发HardFault同样需要保存现场,那么完全可以根据系统所保存的现场信息推导出进入异常的入口点。
那么所有的问题都归结到触发中断系统是如何保存中断现场,要回答这个问题大家得看看上面所提到的几点知识。那么下面作者就以两个开源项目中该部分的处理为大家简单介绍一下如何排查fault。
3、RTT中的处理
RTT系统中对HardFault_Handler进行了比较详细的处理,基本上可以把这块参考过来,下面bug菌画了个流程图方便大家阅读:(如下图所示)
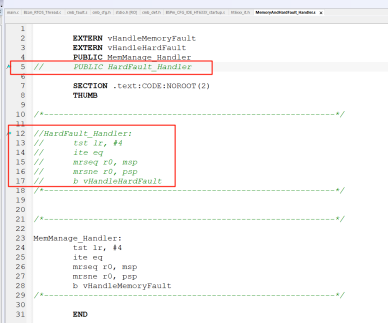
代码概要分析:1、代码碎片1
上面代码实现的是流程图左半部分,很多小伙伴发现r0~r3、r12,lr,pc等等几个寄存器并没有入栈,其实这几个寄存器是硬件上自动压入堆栈中了,不需要我们手动压入。
为什么需要判断MSP和PSP呢 ? 这个问题大家可以参考<Cortex-M3权威指南>里面的双堆栈机制,一般在RTOS中任务中使用的PSP,而中断中使用的是MSP,但我们进入中断服务函数以后其堆栈指针变成了MSP,为了能够获得任务状态下产生的异常,我们需要找到之前的PSP然后获得其自动入栈的寄存器数据来进行分析,自动入栈的PC和LR都是我们用来定位异常前程序位置的重要寄存器。特别是LR是调用子程序时存储返回地址,从而可以定位发生异常的位置。
2、代码碎片2
上图是调用的异常处理函数,其中参数来自r0寄存器的传递(可以查找ARM的函数调用传参形式),那么这个结构体指针参数应该是与入栈寄存器是一一对应的(如下图所示),这样我们便可以通过该指针获得相应的寄存器数据并打印出来,这样对于一些不能使用仿真器的场合是再好用不过了。
3、代码碎片3
该部分的处理就是所画流程图的右侧部分实现,其中hard_fault_track函数中主要就是根据具体的每种fault类型寄存器分析fault的原因(其中每个寄存器中的每个位代表什么故障原因都在权威指南中有详细说明)。
好了,那么RTT中对HardFault_Handler的处理Bug菌就讲到这里,其输出的相关信息,通过把源程序仿真查看汇编与C的映射栏进行定位异常前的代码位置,进而进一步分析代码。如下图Keil中的汇编与C映射窗口,可以通过直接查找Code地址来定位C代码。
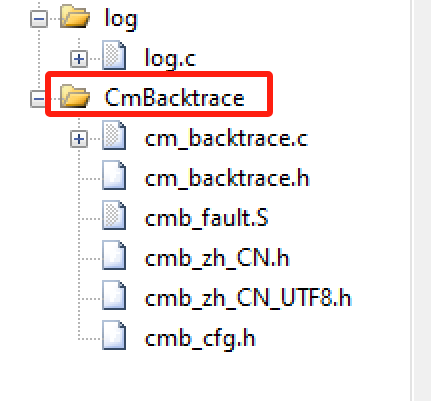
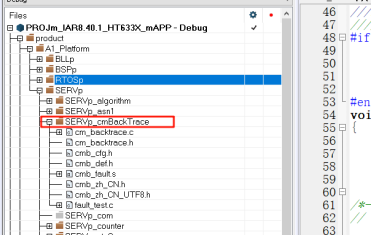
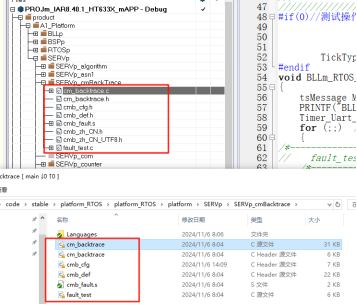
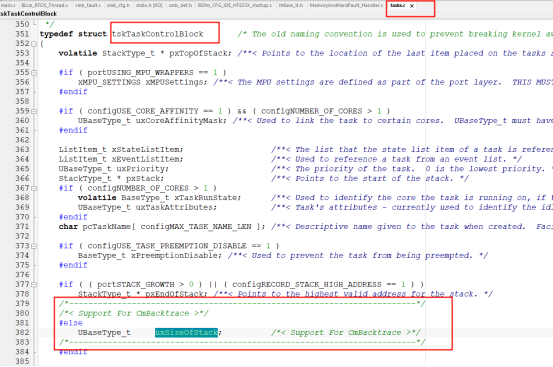
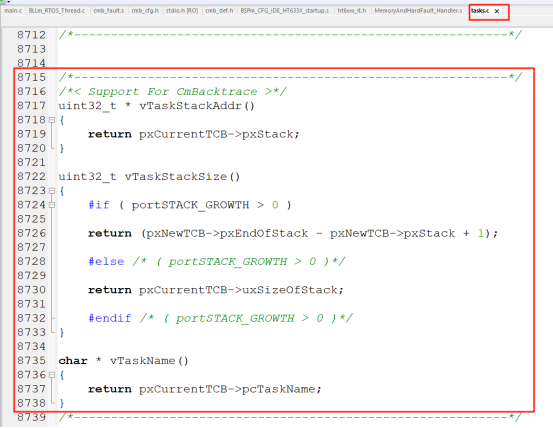
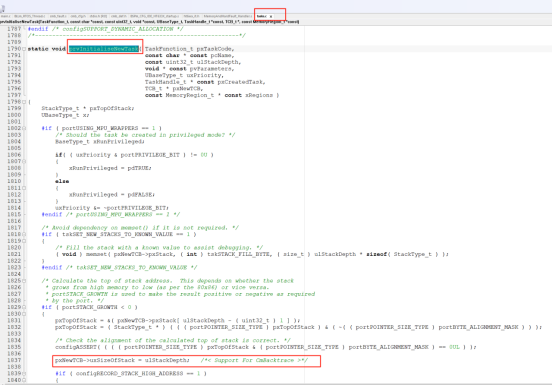
4、开源故障诊断-"CmBacktrace"
cmbacktrace是amink开源的一个ARM Cortex-M 系列 MCU 错误追踪库,其可以支持stm32不同系列的内核fault分析,同时也支持不同的RTOS分析,比如RTT,FreeRTOS,Ucos。
github地址 : https://github.com/armink/CmBacktrace
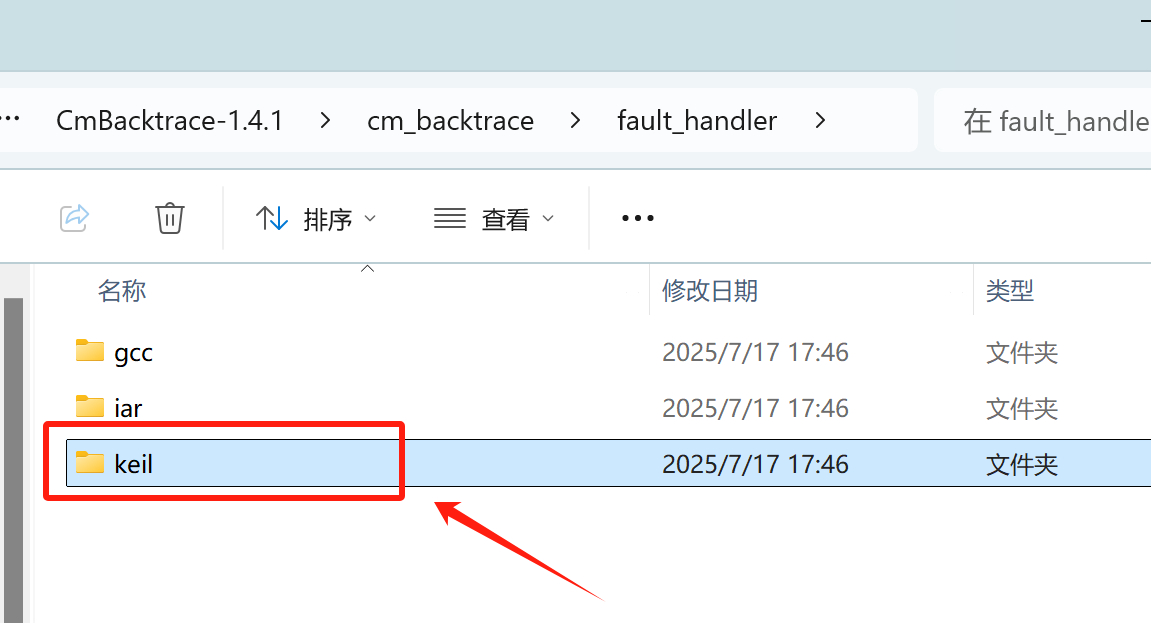
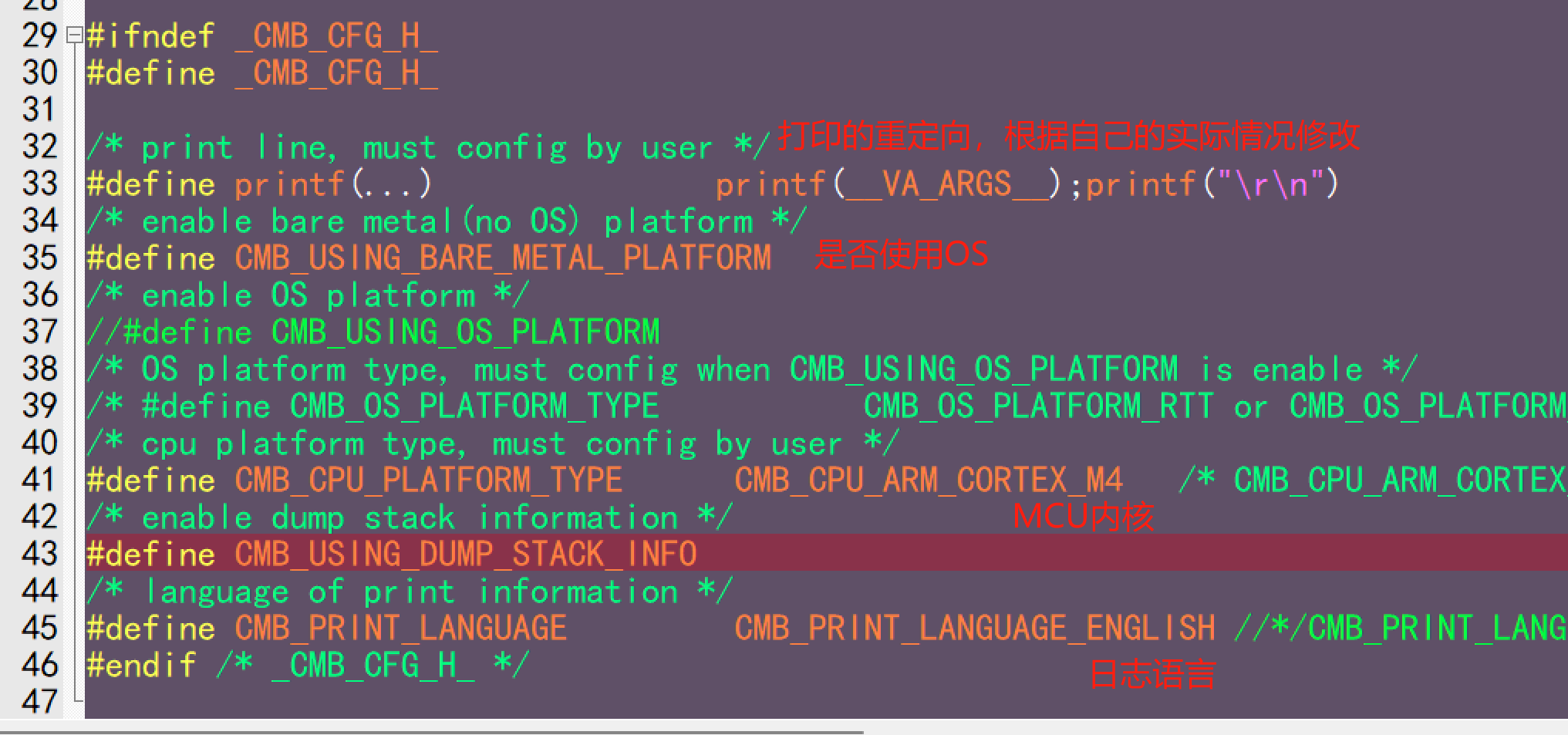
通过包含如上几个文件即可加入到对应的项目工程用于分析故障,其具体的实现思路是与RTT类似的,这里就不具体分析了。
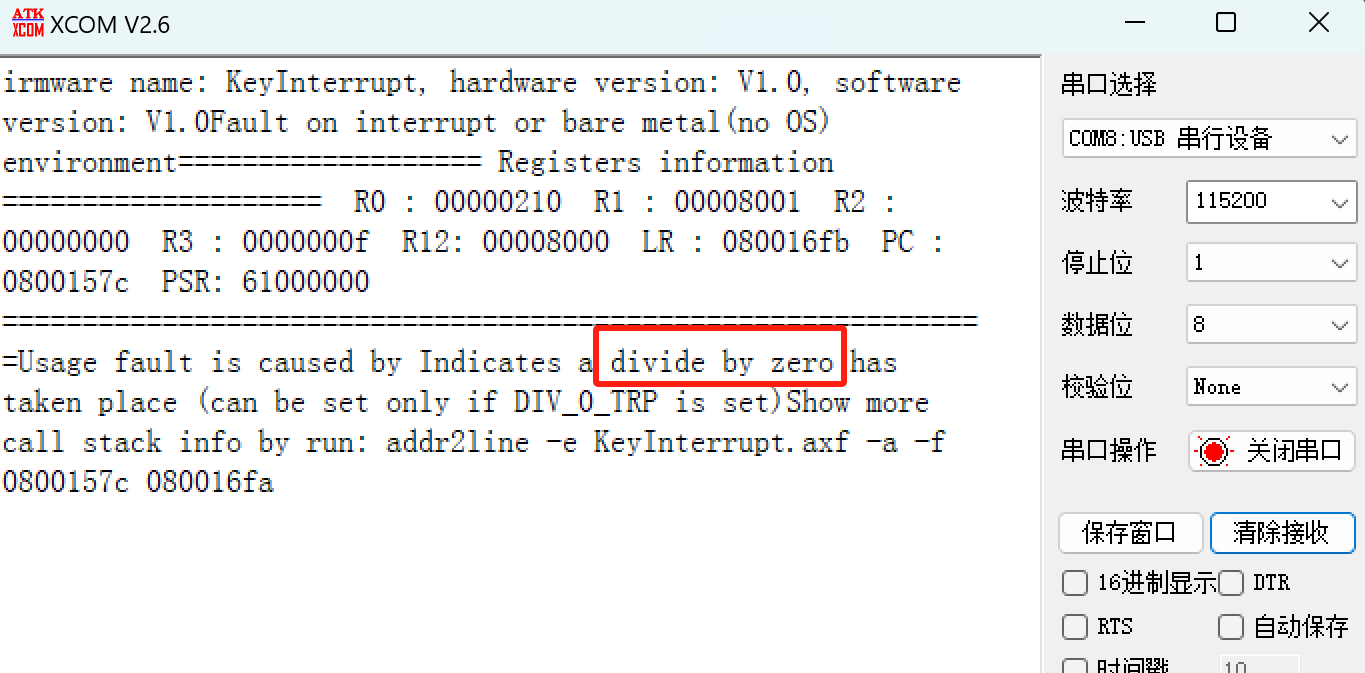
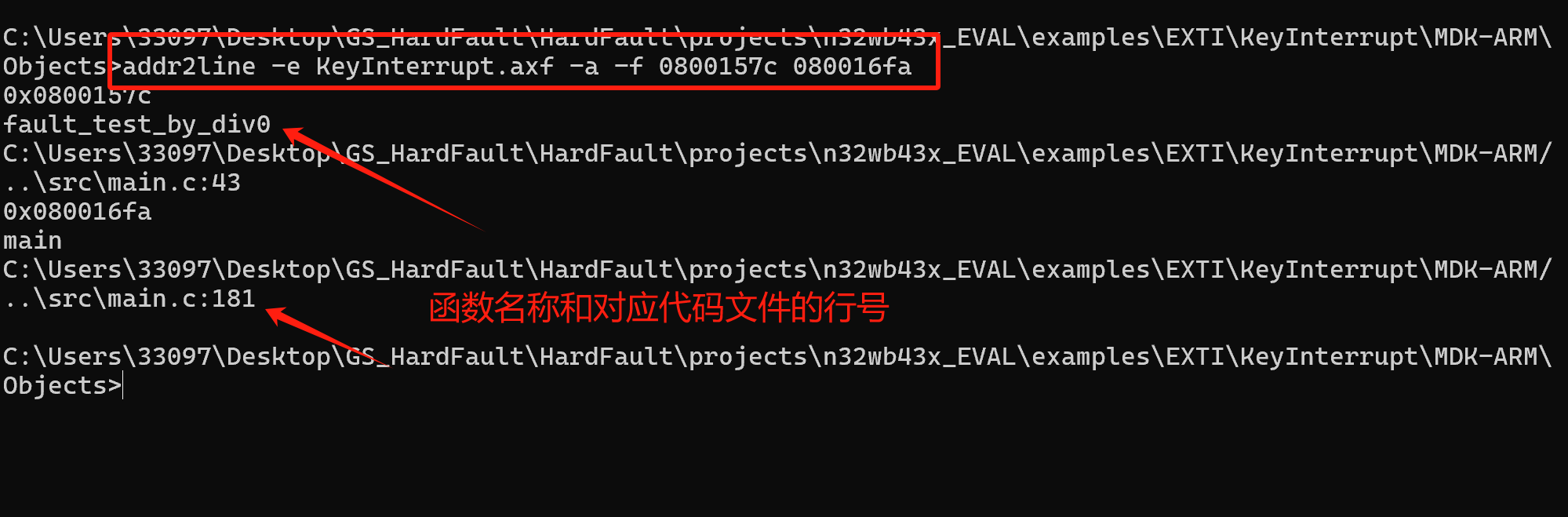
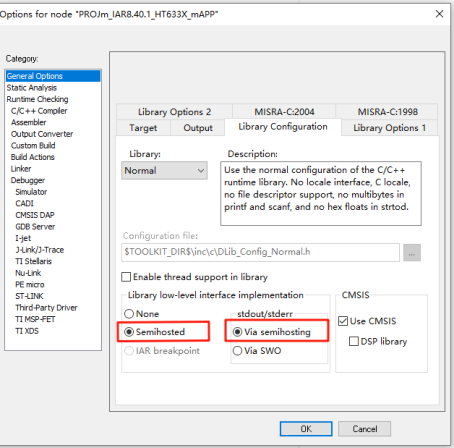
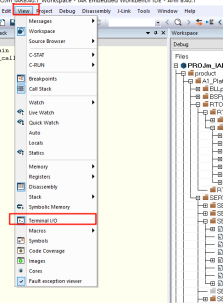
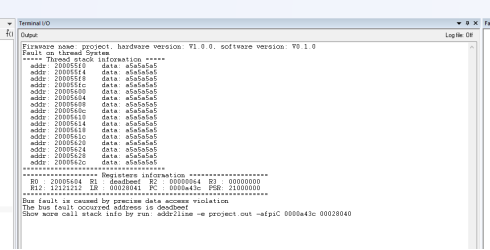
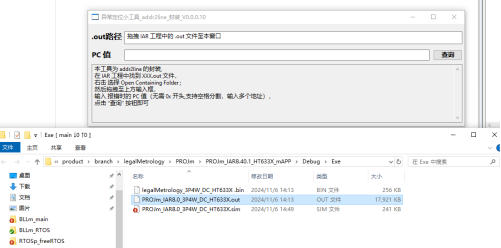
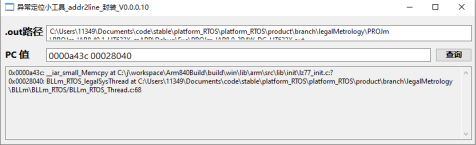
不过相对功能比较丰富,比如输出错误现场的函数调用栈,也可以在正常状态下使用该库,获取当前的函数调用栈,从而可以更加详细的了解程序运行情况,大家可以参考学习顺便可以了解一下Cortex内核的相关知识,作者也简单的跑了一下例程,其运行结果如下:
5、最后小结
对于硬件异常故障的排查bug菌就介绍这么多了,出现硬件异常问题大部分的小伙伴都是由于编码不规范、代码的容错机制不够强大导致的,比如数组越界,调用空指针,堆栈溢出等等常见问题,所以大家在调试阶段可以把断言用上便于开发。
好了,这里是公众号:“最后一个bug”,一个为大家打造的技术知识提升基地。同时非常感谢各位小伙伴的支持,我们下期精彩见!
如果有想加入公众号群聊共同讨论技术的小伙伴可以添加下方bug菌微信!
推荐好文 点击蓝色字体即可跳转
☞【硬壳】C程序里面嵌点"机器码"玩一玩"(小知识揭露大道理)
推荐好文 点击蓝色字体即可跳转
☞【硬壳】C程序里面嵌点"机器码"玩一玩"(小知识揭露大道理)







https://gitee.com/powes/,作者:前沿风暴,转载请注明原文链接:https://www.cnblogs.com/Kreos/p/19470052

 浙公网安备 33010602011771号
浙公网安备 33010602011771号