神经渲染调研记录
- 神经帧生成&超分
- [2022] ExtraNet: Real-time Extrapolated Rendering for Low-latency Temporal Supersampling
- [2023] FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
- [2023] ExtraSS: A Framework for Joint Spatial Super Sampling and Frame Extrapolation
- [2024] GFFE: G-buffer Free Frame Extrapolation for Low-latency Real-time Rendering
- [2024-非AI] Mob-FGSR: Frame Generation and Super Resolution for Mobile Real-Time Rendering
- [2024-ARM] Moble Neural Super Samping
- [2023] LMV: Adaptive Recurrent Frame Prediction with Learnable Motion Vectors [TODO]
- [2025] MoFlow: Motion-Guided Flows for Recurrent Rendered Frame Prediction [TODO]
- 结论
- 神经纹理压缩
- [2023-Nvidia] Random-Access Neural Compression of Material Textures
- [2024] Real-Time Neural Materials using Block-Compressed Features
- [2024-高通] Neural Graphics Texture Compression Supporting Random Access
- [2024-AMD] Neural Texture Block Compression
- [2025] Image-GS: Content-Adaptive Image Representation via 2D Gaussians
- 结论
- 神经材质计算
神经帧生成&超分
[2022] ExtraNet: Real-time Extrapolated Rendering for Low-latency Temporal Supersampling
相关链接:ExtraNet: Real-time Extrapolated Rendering for Low-latency Temporal Supersampling
- 核心目标:帧外插。
- 输入:
- 3 个历史渲染帧(t,t-1,t-2)的 G-Buffer 和 color。
- 外插帧(t+0.5)的 G-Buffer 和 motion vector。
本方法用到的 G-Buffer 包含 depth,stencil,albedo,world position,NoV,normal,roughness,metallic,信息量还是太多了。
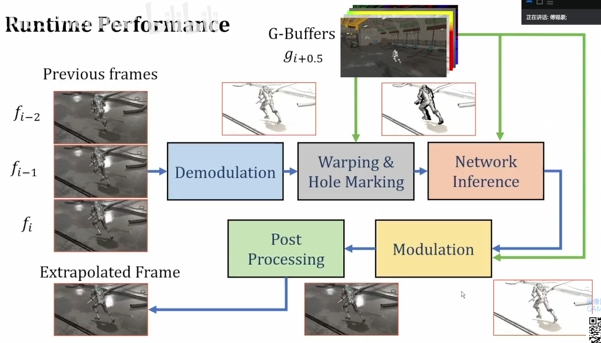
关键流程:
-
demodulation:将 color 解调(除于 albedo)成 diffuse irradiance 来用于插帧。
-
color warping(dual motion vector):传统 motion vector 因 disocclusion 现象而产生重投影失败的 pore pixels 会使用 dual motion vector 再次尝试重投影,解决了一部分鬼影效果。
-
hole marking:历史像素和生成像素比较 stencil、normal、world pos,重投影失败的地方标记为 disocclusion 空洞区域。
-
In-painting network:输入外插帧的 normal,depth,roughness,metallic,mask 以及 history color,history mask,推理输出 irradiance。

- history encoding:将历史 3 帧的 color 和 mask 进行编码,使用了 3x3 卷积网络并适当的时候 down sample,并且为了效率让这 3 帧的 encoding 共享权重。

- network input:外插帧的 normal,depth,roughness,metallic,mask 以及 3 帧 history encoder 的输出。
-
modulation & post processing:最后将生成出来的 diffuse irradiance 乘回 albedo 再经过引擎正常的后处理即可。
总结:依赖的 G-Buffer 信息太多了,费!依赖太多历史帧信息,网络也太过复杂,费!毕竟是早期论文,有点类似于不知道帧生成到底需要什么特征,于是乎什么历史帧或一堆 G-Buffer 塞进去嗯 encoding,总会力大砖飞出不错的结果。
[2023] FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
相关链接:FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
-
核心目标:超分。
-
输入:
- 2 个历史帧(t-1, t-2)的 LR color。
- 当前帧(t)的 HR G-Buffer 和 LR color。
LR 指低分辨率,HR 指高分辨率。
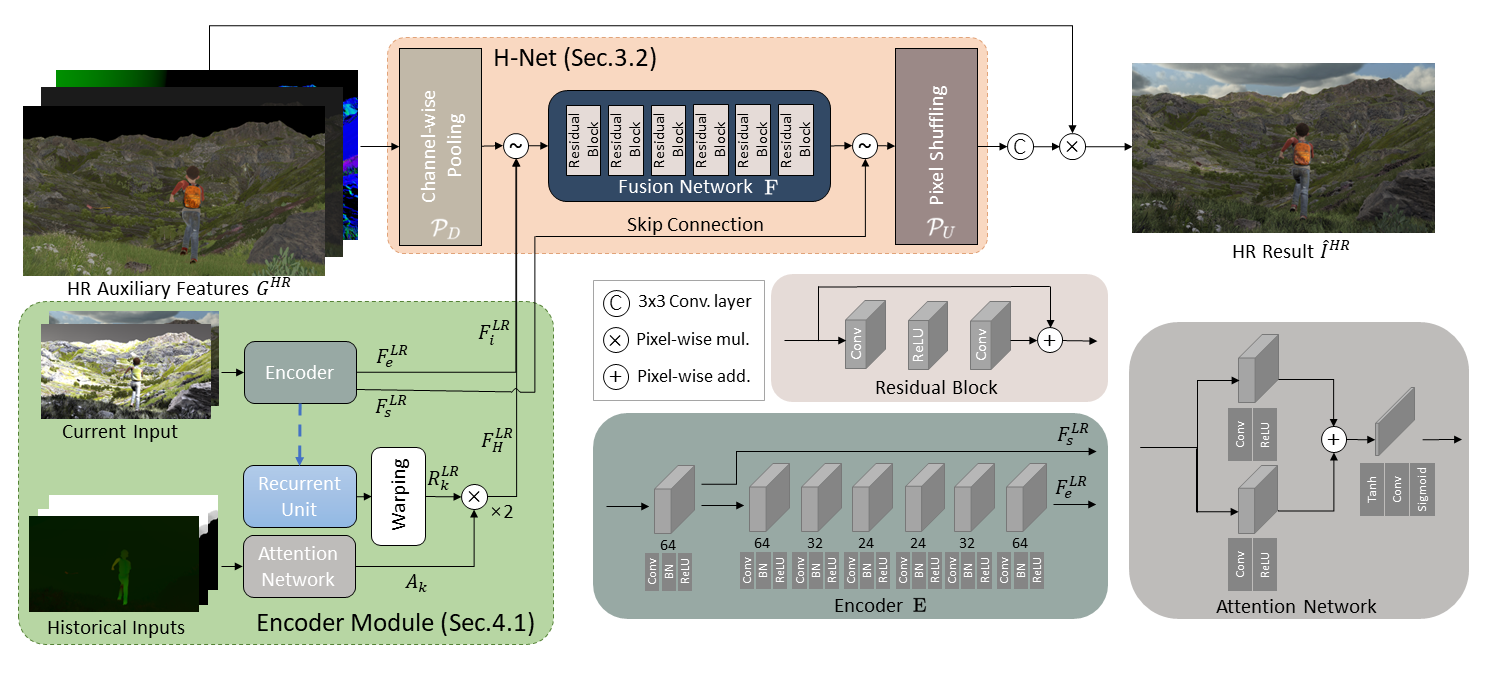
关键流程:
-
demodulation:将 color 解调成近似的 lighting 积分来用于超分(参考基于 BRDF 预积分的信号解调),这样达到同时考虑 diffuse/specular/glossy 的效果。
-
H-Net network:
-
HR G-Buffer unshuffling:将高分辨率单通道输入转成低分辨率多通道输入,从而可以对齐 LR 屏幕空间,方便作为低分辨率网络的输入。

-
network input:HR G-Buffer unshuffling 的结果、当前帧的 LR G-Buffer 和 LR color、2 帧历史帧的 LR G-Buffer 和 LR color(历史帧信息的输入视为了保持画面效果连贯性)。
-
HR color shuffling:最后网络输出低分辨率多通道的结果,将其转成高分辨率 RGB 通道的 color 输出。
-
总结:网络推理(尤其太多的 skip connection)其实性能开销还是相当的大,并且还要依赖 HR G-Buffer。虽然作者说快速版可以去掉历史帧信息的输入,后续 fusion network 换成了更轻量级的 DWSV2,先不说网络推理够不够满足,就说依赖 HR G-Buffer 这点仍然是一个大痛点。
[2023] ExtraSS: A Framework for Joint Spatial Super Sampling and Frame Extrapolation
相关链接:ExtraSS: A Framework for Joint Spatial Super Sampling and Frame Extrapolation
- 核心目标:超分和帧外插。
- 输入:
- 2 个历史渲染帧(t-1,t)的 LR G-Buffer 和 LR color。
- 外插帧(t+0.5)的 LR G-Buffer。
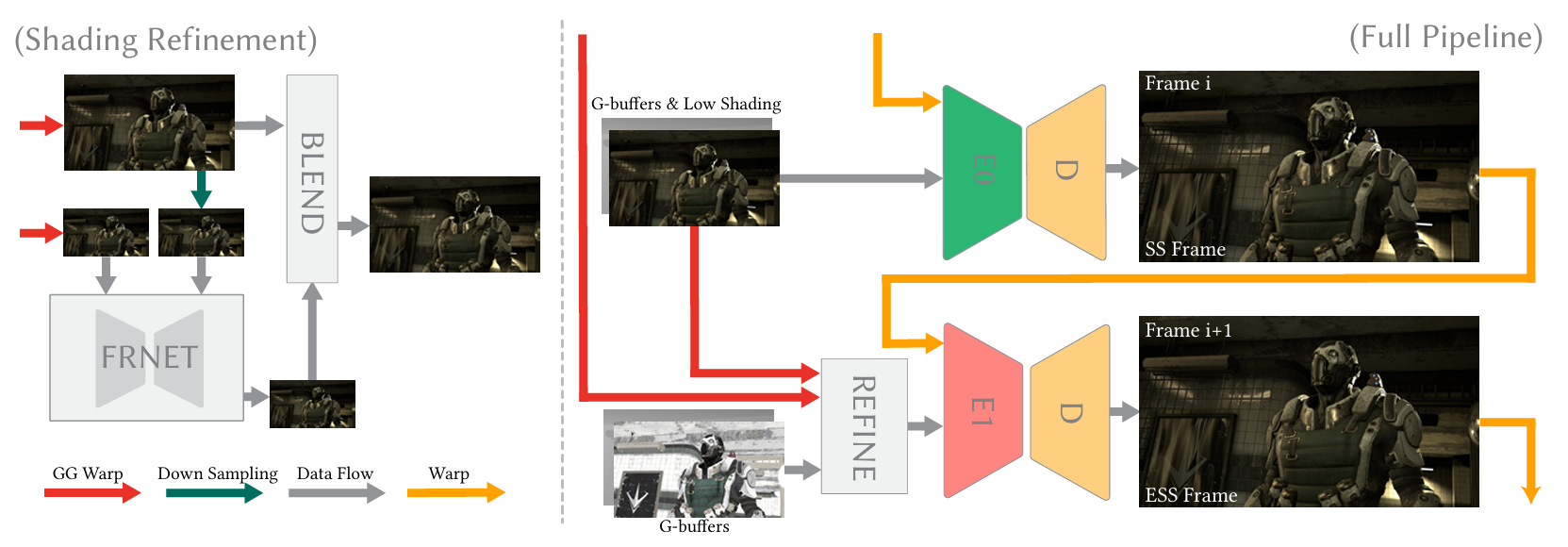
关键流程:
-
color warping(dual motion vector + spatial-filtering): motion vector & dual motion vector 重投影都失败的 pore pixels 将使用空间滤波(motion vector 往往是找历史点邻近的4个样本来作为参考,空间滤波相当于再找历史的一堆样本来作为参考),并且以 G-Buffer 作为指导来填充。由此先生成一张 warped LR color。

-
FRNet network:基于 optical flow 的轻量级网络,用于修正帧生成时阴影和反射的运动。
基于 mv 的物体几何运动估计已经够准确了(毕竟现在的 warp 操作已经基本能 hold 住绝大多数情况了),因此 FRNet 的重点在于关注和矫正光影的运动。输入了 t、t-1 的 history color,这两帧 color 的差异基本就隐含了两帧之间的光影运动信息。
-
network input:前两帧渲染帧(t、t-1)的 down-sampled history color 和当前帧的 down-sampled roughness(这个是为了帮助修正反射效果)。
这里的 down sample 分辨率均指 LR 基础上再继续 down sample,目的是为了进一步缩小网络输入规模。
-
feature warping(optical flow):和前面 warp 操作不同,这里是利用 decoder 输出的 optical flow 来指导 warp 出一张新的 warped feature(而非 color)。网络里分别有三次不同分辨率下的 feature warping(方便对齐不同的 decoder 输入空间),每个 warp 结果将 concat 到下一个 decoder 的输入上。
-
network output:输出的是 down-sampled optical flow(每层 decoder 相当于输出不同分辨率的 optical flow)。
-
-
修正后混合:
- FRNet 最终输出的 down-sampled optical flow 用来 warp 成一张 down-sampled warped color(基于 optical flow 指导)再和第1步的 warped color(基于 mv 和 spatial-filtering 指导)进行混合。
- 像素混合权重取决于当前外插帧采样 down-sampled G-Buffer 和 G-Buffer 的几何属性差异和颜色差异,混合后生成本帧的 LR color。
可以这么理解,mv warping 能够展现更精确的物体几何运动信息,optical flow warping 能够展现更准确的光影运动信息。几何差异过大的时候说明 optical flow warping 更失真,几何差异较小但颜色差异过大的时候说明 mv warping 更失真。
-
Joint Extra-SS network:
-
渲染帧和外插帧使用不同的 encoder,再搭配上专用于超分的 decoder。
- 渲染帧 network input: LR color、LR depth 和 warped history HR color(即上一帧的 HR color output warp 到本帧)。
- 外插帧 network input: LR warped color(其实就是 FRNet 输出的 LR color)、LR depth、LR base color 和 warped history HR color。
-
S2D(space to depth) 和 D2S(depth to space) 本质上就是 pixel unshuffling & shuffling。

-
总结:关于帧外插这部分,warp 操作本身既有 dual motion vector 还有 spatial-filtering 的加持,已经足以生成较为精确的物体几何运动信息;其次,FRNet 算是轻量级一些了,但还有不少潜在优化改进空间(后面的 GFFE 论文就是改进得一个例子)。至于 SS 这部分就比较一般了。
[2024] GFFE: G-buffer Free Frame Extrapolation for Low-latency Real-time Rendering
相关链接:GFFE: G-buffer Free Frame Extrapolation for Low-latency Real-time Rendering
- 核心目标:帧外插。
- 输入:
- 渲染帧(t-1)的 color、depth。
- 渲染帧(t)的 color、depth、motion vector。
- 外插帧(t+a)无需渲染管线生成任何信息,全靠上一帧渲染帧的信息来估计生成 color、depth、motion vector。
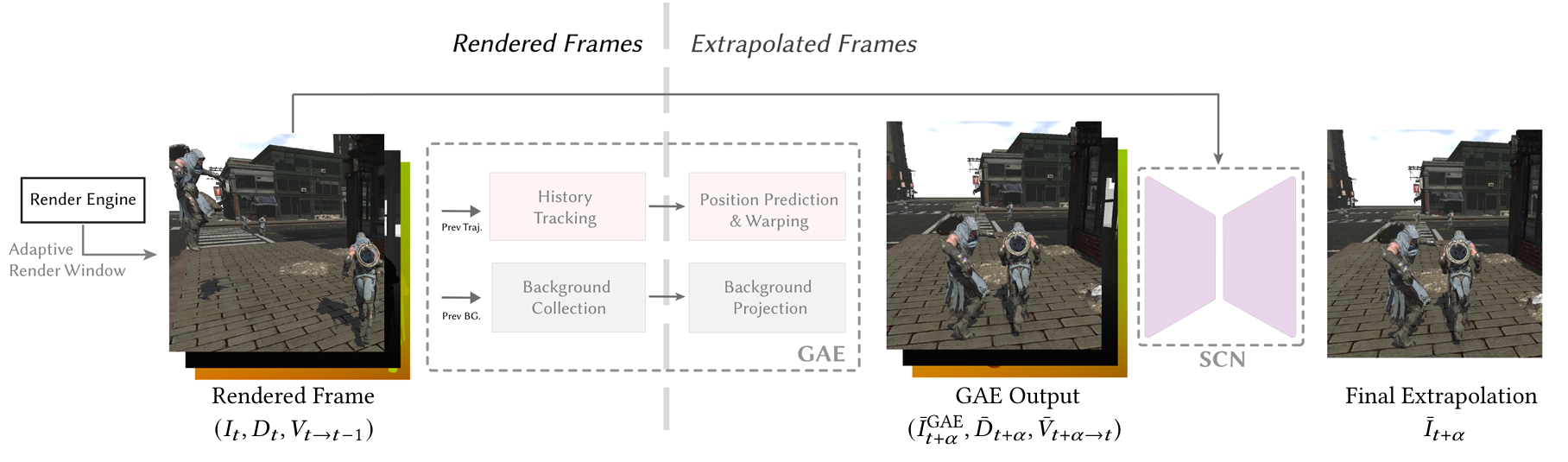
关键流程:
-
渲染管线改动:
-
自适应渲染窗口:动态调整比 display viewport 更大的 render viewport 以覆盖未来帧的潜在区域,用来弥补 camera 视角转动时 warped color 屏幕边缘历史信息的缺失。
-
background collection:缓存多层背景信息用于辅助后续 GAE 模块的 warping,每层背景都有自己的 color 和 depth,然后每层的分辨率都是前一层的1/4。
说简单点,正常渲染就只有最表面的第一层信息。background collection 其实就是希望把每一层被遮挡的像素尽可能缓存到下一层级,从而缓存起了多级表面信息用于后续 GAE 模块来填充 disocclusion 区域。
那么,如何更新第 \(l\) 层 background 呢?
- 对于第 0 层,需要先将当前帧最终输出的 depth、color 中静态像素的部分全部直接拷贝到 \(B_0\) 上(不能拷贝动态的物体像素!)。
- 对于第 \(l\) 层(l = 0,1,2...),将缓存的历史帧背景 \(B'_{l}\) 的像素 \(x\) 投影到当前帧背景 \(B_{l}\) 的像素 \(x'\) 上,有以下两种情况:
- 如果 \(B_l[x']\) 是无效像素,那么直将像素 \(B'_l[x]\) 的 depth、color 覆盖 \(B_l[x']\) 的 depth、color。
- 如果 \(B_l[x']\) 是有效像素,但 \(B'_l[x]\) 的 depth 比 \(B_l[x']\) 的 depth 要更远,那么将 \(B'_l[x]\) 的 depth、color 覆盖到 \(B_{l+1}[x']\) (即下一层的 \(x'\))上。

-
-
GAE(Geometry Aware Extrapolation):无神经网络,用于物体几何运动估计。GAE 最终将估计出外插帧的 color、depth、motion vector 和输出一个 mask(标记哪些像素是 dynamic 的,哪些是 static 且没被 disocclusion 的) ,以下是一些流程:
- color warping(3D position motion):将渲染帧(t)投影到外插帧(t+a),采用 3D position motion 方式来生成一张 warped color(t->t+a)。
- background reprojetion:在 warped color 的基础上利用多层 background 信息来填充 disocclusion 区域(如静态/动态遮挡)。
-
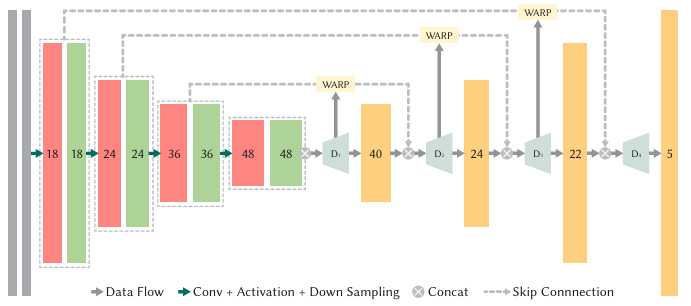
SCN network:基于 optical flow 的轻量级网络,用于修正帧生成时阴影和反射的运动,其实和 ExtraSS 的 FRNet 大差不差。
-
预处理:利用 GAE 输出的 motion vector 来投影,生成又一张新的 warped color(t-1->t+a),其中的 disocclusion 区域用 GAE 输出的 color 来填充。
-
network input:GAE 输出的 color(本质上是 t->t+a)、depth 和 mask,新生成的 warped color(t-1->t+a)。
两张 color 虽然都是 t+a 空间上 warp 过来的(物体几何基本一致),但是 warp 的源头分别是来自 t-1 和 t,因此这两个 warped color 的差异便是光影的运动。
-
feature warping:不多解释。
-
network output:修正后的 color 以及 focus mask(标记像素需要网络关注的程度)。
\[\begin{aligned} M^{\mathrm{focus}}[x]= & \left(\min _{x^{\prime} \in N(x)} s\left(I^{\mathrm{GAE}}[x], I^{\mathrm{gt}}\left[x^{\prime}\right]\right)>0.5\right) \\ & \wedge\left(\hat{M}^{\mathrm{dyn}}[x]=0\right) \end{aligned} \]focus mask[x] = 1 就代表了 x 像素不为动态像素且与周围共9个 ground truth 像素颜色差异较大,反之亦然就是 = 0。当然网络往往只能推理出0~1的值(可以理解为置信度)。
-
blend:network 最终 refine 出的 color 和 GAE 输出的 color 再进行一次混合,每个像素的混合权重取决于 focus mask。

-
总结:相比 ExtraSS,GFFE 在物体几何运动估计方面通过 background collection 进一步提高 warp 的准确度;在光影运动估计方面(GFFE SCN 相比 ExtraSS FRNet),最大的改变在于提前在 encoder 输入前进行 warp,而非在 decoder 输出入前进行 warp,应该就是这部提升了的准确度。
关于性能,通过论文对比(但其实两篇论文的机器都不一样,但论文都是同一个作者而且给出 IFRNet 性能数据一致,就假定它们同一台机器吧),看起来1080P下:
- GFFE(GAE 4.32 ms + SCN 2.3 ms)
- ExtraSS(GBuffer-guided warp 1.7ms +FRNet 2.9ms)
不过,GAE 本身还要包含生成 depth、motion vector,完全不需要渲染管线走一次 prepass,可以进一步节省耗时。
[2024-非AI] Mob-FGSR: Frame Generation and Super Resolution for Mobile Real-Time Rendering
相关链接:Mob-FGSR: Frame Generation and Super Resolution for Mobile Real-Time Rendering
-
核心目标:帧内插&帧外插&超分,无需神经网络推理。
-
输入:
- 渲染帧的 LR depth、LR color 和 LR motion vector。
- 外插/内插帧的 LR depth 和 LR motion vector。
关键流程:
-
内插:

-
渲染帧1的像素通过 \(M_1\) 后向投影找到渲染帧 0 的像素及其 \(M_0\),有了两帧的 mv 就可以通过 quadratic motion 方法估约内插帧 \(Pixel_a\) 的位置,并以原子操作的方式将 \(M_{1->a}\) 写入到内插帧 reprojection texture 里对应的 \(Pixel_a\)(当然这时候也会存在一些从没被填充的 \(Pixel_a\))。
\(Pixel_a\) 可以通过 \(M_{1->a}\) 找到 \(Pixel_1\),然后又通过 \(M_1\) 找到 \(Pixel_0\),也就是说实际上 \(Pixel_a\) 是可以访问到 \(M_{1}\) 和 \(M_{0}\) 的,从而对应上论文里的 splatting 流程(其实说白了也还是 warping,只不过 warp 的对象是 motion vector 而非 color)。
-
reprojection texture 每个 \(Pixel_a\) 根据 \(M_{1->a}\) (如果没被填充,则 fall back 成直接采样 \(M_0\) 并后续采用 linear motion 去估计)去拿到 \(M_1\) 和 \(M_{0}\) 并使用 quadratic motion 方法估计出新的 \(M_{1->a}\) 和 \(M_{0->a}\) ,并去找到渲染帧里新对应的 \(Pixel_0\) 和 \(Pixel_1\),并采样它们的 depth 和 color,其中采样 color 时使用了基于 LUT 权重的 4x4 采样(而非一次 bilinear 采样)。
原文说算权重是先通过神经网络去拟合的(输入 uv offset,输出 weight),后面再将神经网络的输出做成一个 LUT,这样就可以用查询 LUT 代替网络推理,并且说性能比 bicubic 还要快,效果比 bicubic 好一丢丢。
但说实话,这个仅考虑平面上 uv offset 输入的权重一点都不靠谱,一个曲线就能拟合好的权重偏偏搞成个复杂的神经网络/LUT来拟合。哪怕这个 LUT 查询多依赖一个 depth offset(例如 uv distance & depth offset 的输入组合),我都会觉得用网络/LUT的方法都稍微显得靠谱一些。对于性能比 bicubic 快也是有点怀疑的(移动端往往是带宽瓶颈大于ALU)。
-
最后根据 \(Pixel_0\) 和 \(Pixel_1\) 深度的差异去决定如何混合它们的 color 来作为输出。
-
-
外插:

- 渲染帧1的像素前向投影到外插帧中的某个 \(Pixel_{1+a}\),并以原子操作的方式将 \(M_{1->1+a}\) 写入到外插帧 reprojection texture 里对应的 \(Pixel_{1+a}\)。
- reprojection texture 每个 \(Pixel_{1+a}\) 根据 \(M_{1->1+a}\) (如果没被填充,则 fall back 成直接采样 \(M_1\) 并后续采用 linear motion 去估计而非 quadratic motion),去拿到 \(M_1\) 和 \(M_{0}\) 并使用 quadratic motion 方法估计出新的 \(M_{1->1+a}\),并去找到渲染帧里新对应的 \(Pixel_1\),并直接采样 color(采样 color 也是用 LUT 4x4权重)的结果作为输出。
超分:

- 对当前帧的 LR depth 和 LR motion vector 做了一个简单的基于 dilate filter 的 upsampling 变成 HR depth 和 HR motion vector。
- 每个 HR pixel 投影到历史帧的 HR color 里,采样了 4x4 个样本(权重基于 LUT),混合出一个历史颜色。
- 每个 HR pixel 到当前帧的 LR color 采样一个当前颜色。
- 根据 HR pixel 投影到历史帧的深度和当前帧的深度差来决定混合当前颜色和历史颜色的比例。
总结:Mob-FGSR 其中的 quadratic motion 方法可以值得一学。
[2024-ARM] Moble Neural Super Samping
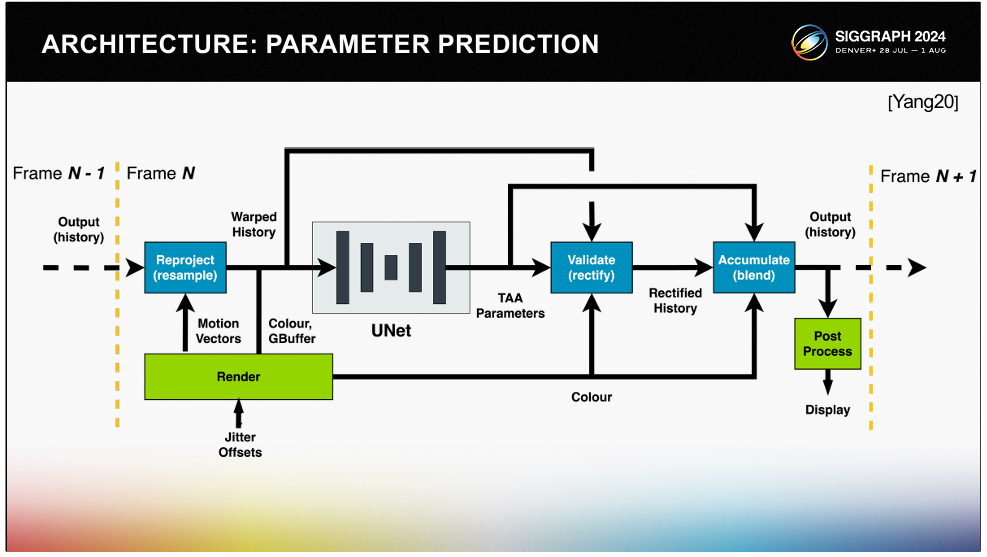
核心:ARM 尝试了三种架构路线:
- Image Prediction:nn 直接预测超分图像,泛化能力差(容易过拟合),从而稳定性也差。
- Kernel Prediction Network:nn 预测超分时的滤波核(3x3滤波的权重),可控性和泛化性都强,对量化友好,但是带宽瓶颈严重(需要输出超分后分辨率×9个权重的巨大张量)。
- Parameter Prediction Network:nn 预测 TSR 方法的少量参数(具体是哪些参数呢,没说),可控性和泛化性都进一步增强,对量化友好,带宽瓶颈也相对少很多。
总结:第三种架构路线是最合适的。
[2023] LMV: Adaptive Recurrent Frame Prediction with Learnable Motion Vectors [TODO]
[2025] MoFlow: Motion-Guided Flows for Recurrent Rendered Frame Prediction [TODO]
相关链接:MoFlow: Motion-Guided Flows for Recurrent Rendered Frame Prediction | ACM Transactions on Graphics
结论
nn帧生成面临的主要问题:
- 时序复用时遮挡像素的处理:帧内推基本没啥问题,帧外推就非常麻烦。这部分传统渲染可以尝试解决一部分,但很难完全解决。神经网络去解决则非常不稳定,也不好搞。
- 光影/反射变化问题:基本得用光流法去解决,传统光流法非常费性能,因此神经光流是很关键的方向。
- 推理性能开销问题。
nn超分面临的主要问题:
- 帧间稳定性:每帧的推理效果可能略微不同,看起来会闪烁。
- 推理性能开销问题最为严重。
帧生成和超分全部交给 nn 是不可靠的,只有不断地把 nn 的某些环节替换成传统算法才能有效果比较鲁棒并且性能足够快的方案。例如,ARM 的 nn 超分路线很值得借鉴:最早的直接预测超分颜色(Image Prediction) => 预测滤波核(Kernel Prediction Network) => 预测 TSR 的某些参数(Parameter Prediction Network)。也就是说传统渲染算法仍然是方案主体,只是其中少部分难搞的环节才交给 nn 去做,既能提高方案的性能,也能增强图像稳定性(避免太多环节交给 nn 推理导致不稳定)。
神经纹理压缩
[2023-Nvidia] Random-Access Neural Compression of Material Textures
相关链接:GitHub - NVIDIA-RTX/RTXNTC: NVIDIA Neural Texture Compression SDK

数据:

核心:
- 该方法考虑了纹理组之间的冗余,而传统块压缩算法只考虑块内的压缩。
- 推理加速:使用了 DX12 新特性 Cooporative Vector。
总结:开创性质的论文,利用神经网络实现材质的纹理随机采样。但 NTC 推理不能使用 CUDA-DX12 显存映射的方式,必须得在 pixel shader 处理完毕。而目前推理加速所使用的 DX12 Cooporative Vector 特性目前还不稳定也不够普及,很难实用。也就是说 NTC 最终要想落地,必须得精简网络。
[2024] Real-Time Neural Materials using Block-Compressed Features
相关链接:Real-Time Neural Materials using Block-Compressed Features

数据:

核心:
- 设计实现了一个可微的BC6解码函数,然后 feature texture 就可以直接用块压缩格式训练/推理。
- 由于 BC 格式解压出来的 features 会比 NTC 方式(即直接采样纹理)多很多,因此 MLP 可以设计的很轻量,大大增加了推理速度。
总结:可微块压缩有用,因为块压缩本来就是很多硬件支持的操作(BC/ASCT),有助于推理加速。虽然 BCf 看起来压缩率比 NTC 差了,但是还是比传统 BC/ASTC 要好,最重要的贡献是推理加速了很多(硬件BC解压+MLP小了)。
[2024-高通] Neural Graphics Texture Compression Supporting Random Access
相关链接:Neural Graphics Texture Compression Supporting Random Access

数据:

核心:
- 该方法考虑了 mipmaps 之间的冗余,因此 Global Transformation 只通过 mipmap 0 的信息来提取 feature grids。
- feature grids 划分为高频和低频两部分分别用于4次点采样和1次线性采样,从而提供更准确的高频信息(而 Nvidia NTC 是不会划分的,点采样和线性采样都作用于同一张 feature gird)。
总结:在 Nvidia NTC 基础上对 mipmap 的冗余考虑更加多,因此压缩率更高。
[2024-AMD] Neural Texture Block Compression


数据:相同压缩率下,NTBC 效果好过 BC。

核心:
- 传统BC算法通过保存块的双端颜色(e0、e1)以及各个像素的索引来进行存储;而 NTBC 用一个复杂的网络来拟合双端颜色,再用另一个简化的网络来拟合出低频的图像颜色(而不是直接去拟合索引,因为索引变化太高频了,MLP很难学习到)。推理时,就可以将推理出来的低频图像颜色 c 映射到推理出来的 e0-e1 的插值空间中,就能得到索引了。
总结:虽然压缩率很高,但这个论文只是单纯减少了硬盘存储空间,纹理在显存中还是要还原成传统的BC格式...
[2025] Image-GS: Content-Adaptive Image Representation via 2D Gaussians

数据:

核心:
- 给定一张纹理和任意初始化的 2DGS,并通过可微渲染优化来让 2DGS 拟合纹理。
- 随机访问纹理可能比较费,需要遍历 2DGS。
总结:GS 在表达不规律稀疏的大中小块图元时非常高效,但是对像素级别的细节图元表示则太过冗余。虽然 Image-GS 不是神经网络,但是也提供了另一种图像压缩新思路,可能以后能考虑结合神经网络 + GS 的混合拟合方法。
结论
- NTC 对管线改动基本不大。
- NTC 在低效果质量下压缩率一般是传统(BC/ASTC)的 5~10 倍,在中等效果质量下则为 2~4 倍。可以根据两种任务进一步特化算法:加载时推理(往往需要让 NTC 压缩率更高但推理速度更慢)、运行时推理(往往需要让 NTC 推理速度加快但压缩率稍微下降)。
神经材质计算
[2024-Nvidia] Real-time Neural Appearance Models

数据:

核心:
- 与 NTC 相比,采样得到的 features(latent code)不用解码出纹理值,而是直接用于后续的材质计算环节(BRDF计算或重要性采样),相当于把材质的两个环节都用 neural 去替换掉了。
- TBN 变换的处理:多层材质有多个TBN空间的变换,而 latent code decoding 直接替换掉空间变换的效果并不好,所以采用了 latent code 先 decode 出来多个T和N,再用经典构建 TBN 矩阵的形式来变换入射方向和出射方向。
- 重要性采样:神经材质直接进行重要性采样往往是不可行,因此本文没有直接 decode 出来一个样本,而是先 decode 成某些参数来控制一个可解析分布的形状,从而通过解析方法进行重要性采样。
总结:主要是统一了单层/多层材质,不管你材质是单层还是有多少层(材质复杂性无关),都可以使用相同的 shader,大大减少材质的变体数以及提高 GPU 并行度。甚至还可以减少一些多层材质的计算冗余,实现比传统多层材质更高效的材质计算。
[2025-SIGGRAPH] Towards Comprehensive Neural Materials: Dynamic Structure-Preserving Synthesis with Accurate Silhouette at Instant Inference Speed

核心:
- 入射&出射方向重参数化为半程向量h和"different"向量d(入射方向和半程向量的角度差),然后 uv,h,d 分别去不同的3个 featrue grid 进行采样。这时候就可以分配给高频的 feature grid 更高的分辨率,给低频的 feature gird 更低的分辨率。
- 推理加速:利用量化。
总结:只有重参数化思路可以。
[2025-SIGGRAPH] Neural BRDF Importance Sampling by Reparameterization


核心:
- 神经 BRDF 不好做 BRDF 重要性采样,因此不要让神经 BRDF 直接去学习真实 BRDF 分布,而是学习一个变换,对一些先验分布(例如高斯分布)进行变换来拟合真实 BRDF 分布。
- 多重重要性采样:另外训练一个轻量级网络来专门学习 pdf。由于MIS的无偏性只要求权重之和为1,而对权重本身的精确度没有严格要求,因此使用近似 pdf 值来计算权重不会给最终的渲染结果引入任何 bias。
总结:神经材质的一种新思路吧,网络可以更简化,还能很好的和传统渲染中的 MIS 去结合,还能无偏。
结论
- 延迟渲染管线改动量较大:
- 神经材质可能需要改变管线中的 G-Buffer,改为存储 features 的 Feature-Buffer。
- 神经材质需要修改 lighting pass 的部分光照计算函数,主要是 eval BRDF 函数。
- 前向渲染管线改动量不大: 神经材质比较容易嵌入,不需要改变管线结构。
- 在多层材质上,神经材质推理速度约为传统材质计算速度的2~4倍(在一点点质量损失下)。
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号