游戏架构设计:面向数据编程(DOP)
2022.5.30 已更新,下一篇并行架构也在路上了,包含 Parallel For,TBB,Job System,Asycn Compute 的多线程渲染模型等话题,下下篇则是 GPU Driven
随着软件需求的日益复杂发展,远古时期的面向过程编程(POP)思想才渐渐萌生了面向对象编程思想。当人们发现面向对象在应对高层软件的种种好处时,越来越沉醉于面向对象(OOP),热衷于研究如何更加优雅地抽象出对象。然而现代开发中渐渐发现面向对象编程层层抽象造成臃肿,导致运行效率降低,而这是性能要求高的游戏编程领域不想看到的。
之后,面向数据编程(DOP)的思想越来越被接受,已经是现代游戏编程中不可或缺的一部分,ECS 架构也成了游戏工业界里架构的一个典中典。
这次的主题是从 CPU Cache 的角度出发来减少 memory-bound 和从指令级并行(SIMD 指令)的角度出发来减少 CPU-bound
利用 CPU Cache
- 一般的数据通路:CPU Register(CPU 寄存器) <————> Main Memory(内存)
CPU 的运行频率非常快,而 CPU 访问内存的速度很慢。在上述数据通路的情况下,在处理器时钟周期内,CPU 常常需要等待寄存器读取内存,浪费时间。
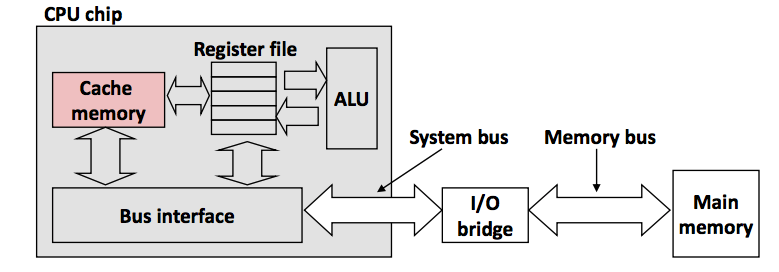
CPU Cache 是介于内存和 CPU 寄存器之间的一个存储区域。CPU 访问 CPU Cache 速度会比访问内存快很多,但同时 CPU Cache 的存储空间比内存小,比寄存器大 。
- 引入了Cache的数据通路:CPU Register(CPU 寄存器) <————> CPU Cache(CPU 缓存) <————> Main Memory(内存)
为了缓解 CPU 和内存之间速度的不匹配问题,则会让 CPU Cache 充当它们之间的一个缓冲中介。
CPU Cache 会预先读取好CPU可能会访问的内存数据到 Cache 上。
- 如果 Cache 命中成功,则 CPU 便可以很快从 Cache 上读取出想要的内存数据到寄存器(减少 memory-bound)
- 如果 Cache 命中失败,那么 CPU 便直接访问内存
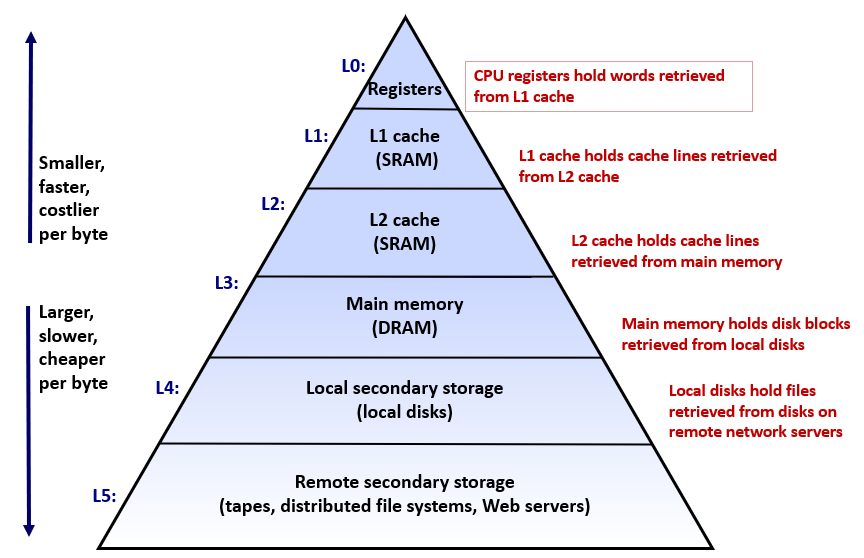
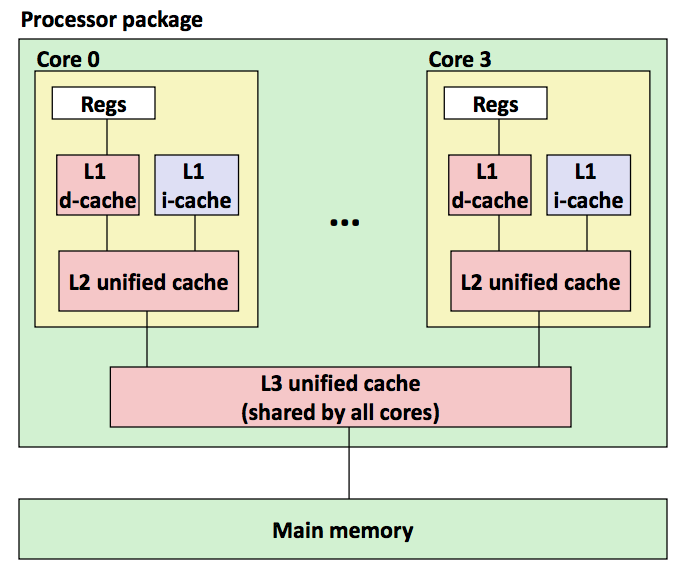
下图是一个现代CPU(Intel Core i7 Cache Hierarchy)的简化架构样例,可以大概了解下 Cache 的分级和关系:CPU core 的 Register(寄存器)可以和 L1 d-cache 直接通信;一个 CPU core 拥有 L1 d-cache(数据缓存),L1 i-cache(指令缓存),L2 cache;多个 CPU core 共享 L3 cache
那么 CPU Cache 一般读取的数据是什么呢?它是基于两个局部性来决定的:
- 空间局部性:如果某个数据被访问,那么与它相邻的数据很快也能被访问。
- 时间局部性:如果某个数据被访问,那么在不久的将来它很可能再次被访问。
CPU Cache 根据这两个特点,一般存储的是 最近被访问过的数据 和 被访问数据的相邻数据。
空间局部性
CPU Cache 和内存之间传输数据的最小单位是缓存行(一般为64字节)。
换句话说,假如通过内存直接访问了某个 16 字节的内存数据之后(Cache命中失败一次),那么 Cache 会将该数据所处内存位置的整行(64字节)读取出来存着。倘若接下来要使用的 3 个 16 字节的内存数据都在 Cache 中(Cache命中),那么 CPU 就直接去 Cache 取数据,而不必要进行内存直接访问。
而如果要使用的数据在内存中的分布间隔比较疏远,那么可能会发生更多次的内存直接访问和缓存行读取(多次Cache命中失败)。
因此要尽可能充分利用好空间局部性来提高 CPU Cache 命中率,关键就是要尽量让使用的数据紧凑在一起。
预取(Prefetching)
此外,现代 CPU 还会智能预测出可能要访问到的内存,提前给 Cache 发送一个读取缓存行指令,而不是等到命中失败后再读取缓存行
例如,当程序顺序访问 a[0], a[1] 时(假设一个元素占据刚好一个缓存行,即64字节),CPU 会智能地预测到接下来可能会读取 a[2],于是让 Cache 提前读取 a[2] 所在的缓存行。Cache 在后台默默读取数据的同时,CPU 自己在继续处理 a[0] 的数据。
这样等 a[0], a[1] 处理完以后,Cache 也刚好读取完 a[2] 了,从而CPU不用等待就可以直接开始处理 a[2],避免等待数据的时候 CPU 空转浪费时间。
预取(prefetch):由硬件自动识别程序的访存规律,决定要预取的地址。一般来说只有线性的地址访问规律(包括顺序、逆序;连续、跨步)能被识别出来,而如果程序的访存是随机的,那就很难预测,于是 CPU 不得不放弃预取,空转等待数据的抵达才能继续工作,浪费了时间。
但实际上,对于不得不随机访问一块的情况,我们还可以通过指令手动预取一个缓存行,只不过相比硬件自动预取的速度仍然会慢些。
_mm_prefetch :手动从内存地址预取一个缓存行
__mm_prefetch(&a[i*16],_MM_HINT_T0); // example
-
第一个参数:要预取的地址(最好对齐到缓存行,即64字节)
-
第二个参数:
_MM_HINT_T0:预取数据到一级 Cache_MM_HINT_T1:预取数据到二级 Cache_MM_HINT_T2:预取数据到三级 Cache_MM_HINT_NTA:预取到非临时缓冲结构中,可以最小化对 Cache 的污染,但是必须很快被用上
需要注意的是,prefetch 后是需要一定时间后才能取到缓存行,而不是立即可以访问该行数据,因此要访问该行数据时,应提前一定的时间来 prefetch
但提前的时间又不能太久,不然可能堆积太多数据到当前级别的 Cache ,到最后 Cache 容纳不下,不得不把最早 prefetch 的数据下放到下一级 Cache 乃至内存
// example
for(int y = 0; y < N; y++)
{
// 提前32次循环的时间来 prefetch
__mm_prefetch(&a[y+32][0],_MM_HINT_T0);
float sum = 0.0f;
for(int x = 0; x < 16; x++)
{
sum += a[y][x];
}
b[y][0] = sum;
}
直写(Streaming)
当 CPU 试图写入时,Cache 往往假设这个写入的内存地址所在的 64 字节(一个缓存行大小)会在将来再次用到,因此会将该缓存行读取进了 Cache。
但如果想要的只是纯粹的直接写入(Streaming)内存行为,而 Cache 还是从内存中读取了缓存行,就会浪费多约 1 倍的带宽。
容易推出:写入耗时是读取耗时的2倍;写入时同时读取的耗时和单单写入的耗时几乎是一样的
_mm_stream_si32 :可代替直接赋值的写入,够绕过 Cache 并直接写入 4 字节到挂起队列
- 只支持 int 做参数,使用别的类型则需要强制转换成 int 类型
_mm_stream_ps :利用 xmm 寄存器一次性写入 16 字节到挂起队列,更加高效
- 第二个参数是 __m128 类型,一般配合 SIMD 指令使用
- 写入的地址必须对齐到 16 字节,否则会产生段错误等异常
stream 系列指令需要注意的是:
-
挂起队列凑满 64 字节后将直接写入内存,从而完全避免读的带宽
-
写入的地址必须是连续的,中间不能有跨步,否则无法合并写入(会产生有中间数据读的带宽)
_mm_stream_si32((int*)&a[i], *(int*)&value); // example
_mm_stream_ps(&a[i], _mm_set1_ps(1.f)); // example
推荐符合以下全部情况时才应该用 stream 指令代替赋值写入:
- 想要写入的内容长度应为 64 字节的若干倍
为了凑满挂起队列
- 写入前不久没有读取该数组
如果写入前不久读取过该数组,那么 Cache 大概率是存储了该数组的内容,那么赋值写入行为就是写入到 Cache 中,而并不需要 stream 指令优化
- 写入后没有立即读取该数组
因为 stream 会直接把数据写入到内存,之后立即读取的话,就需要等待 stream 写回执行完成,然后重新读取到 Cache,反而更低效
冷知识问题:为什么 write0 比 write1 快?
void write0(){ for(int i=0; i<N; i++) a[i] = 0; }void write1(){ for(int i=0; i<N; i++) a[i] = 1; }答:write0 代码被编译器优化成 memset ,而 memset 的实现利用了 stream 指令绕开缓存以获得更快的写入速度。把 write1 也换成 stream 指令时,就可以获得与 write0 差不多的运行时间。
void write1(){ for(int i=0; i<N; i++) _mm_stream_si32(&a[i], 1); }
伪共享(False Sharing)
在多核的情形下,Cache 还需要注意 False Sharing 现象。
伪共享(False Sharing):当多个 CPU core 同时写入的地址非常接近时,速度会变得很慢。
这是因为如果两个 core 同时要修改内存上的某个缓存行(64字节)时,可能一个修改了前 32 字节而另一个修改了后 32 字节,为了保证缓存行写回内存时的一致性(既有前 32 字节的修改,又有后 32 字节的修改),Cache 只敢将该缓存行读取进所有 core 可共享的 L3 Cache,而不敢读取进每个 core 独有的 L1 Cache。
因此,多个 core 同时写入同一缓存行的速度受限于 L3 Cache 的速度,而不是 L1 Cache 的速度。
不过,False Sharing 只会发生在多个 core 同时写入的情况,如果多个核心同时读取很靠近的变量,是不会产生冲突的,因此 CPU 也可以放心读取进 L1 Cache
如何避免 False Sharing:
- 尽量把每个 core 写入的地址分隔开至少 64 字节(一个缓存行大小)的间距
访存优化
行主序遍历 or 列主序遍历
对二维数组int a[100][100]的遍历:
for(int y=0;y<100;++y)
for(int x=0;x<100;++x)
sum += a[y][x]; //do something
for(int x=0;x<100;++x)
for(int y=0;y<100;++y)
sum += a[y][x]; //do something
内循环应该是对 x 递增(行主序遍历)还是对 y 递增(列主序遍历)比较快?
答:对 x 递增(行主序遍历)比较快。因为,对 x 的递增(行主序遍历)是 1 个 int 大小的跳转,也就是说容易访问到相邻的内存,即容易命中 Cache;对 y 的递增(列主序遍历)是 100 个 int 大小的跳转,不容易命中 Cache
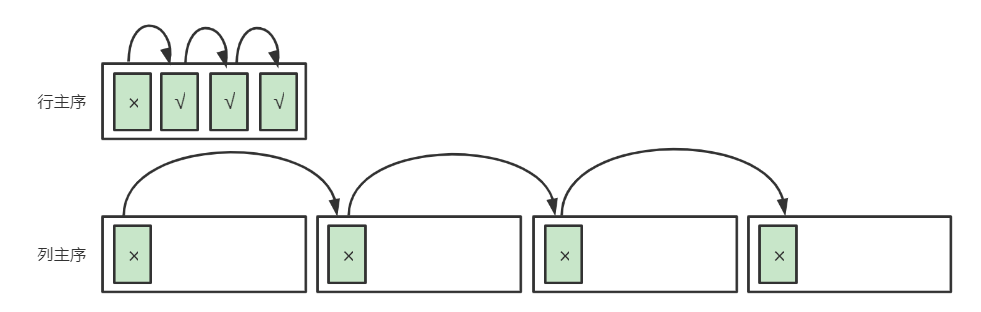
分块访问
我们知道行列主序遍历比行主序遍历的跳转更大 ,因此性能差了很多,但是否意味着列向(纵向)的访问就必定是低效?
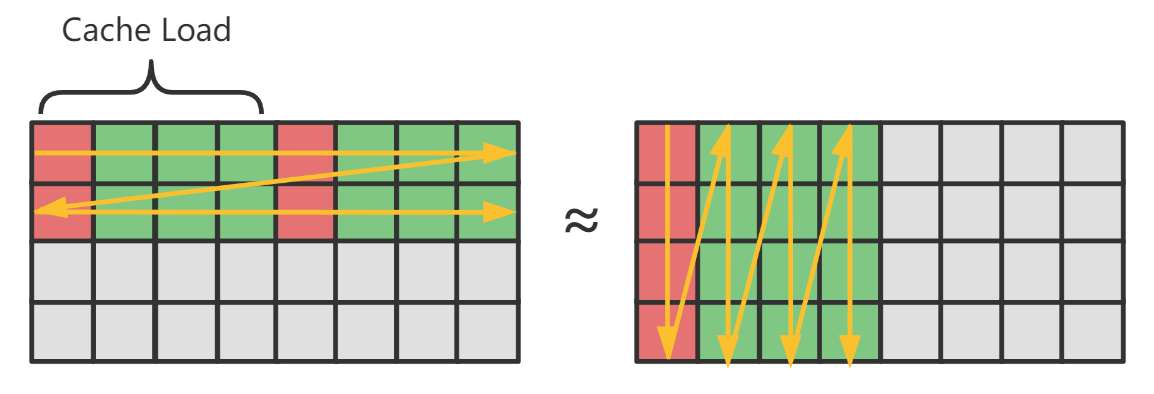
答:不是,只要对访问的区域进行分块,例如让每一块的大小都相当于装满 Cache 的容量(例如L1 Cache 有 32KB),那么在这个块内的任何次序的访问都是可以命中 Cache 的
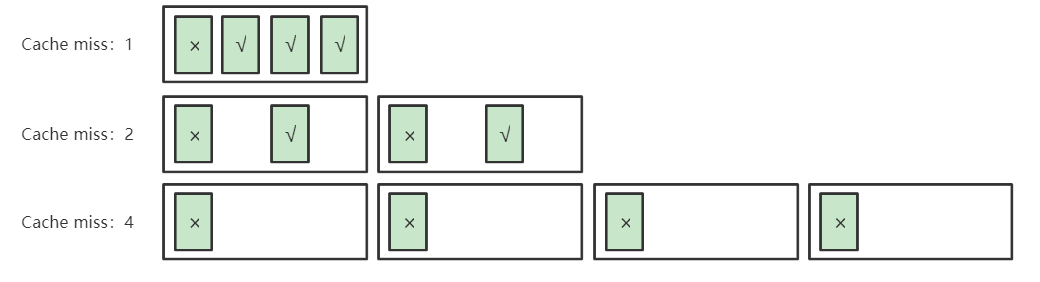
如图,假设 Cache 只能容纳 4 个缓存行,一个缓存行相当于4个数据大小 ,那么:
- 左图按照行主序遍历有 75% 的 Cache 命中率
- 右图采用分块访问,块内部采用列主序遍历,但也有 75% 的 Cache 命中率
不过还要一提,在实际的 CPU 环境中,实际上按行主序遍历命中率还会更高些(例如因为硬件预测 prefetch 机制),所以分块访问的理论适合用在不得不采用非连续访问的情形
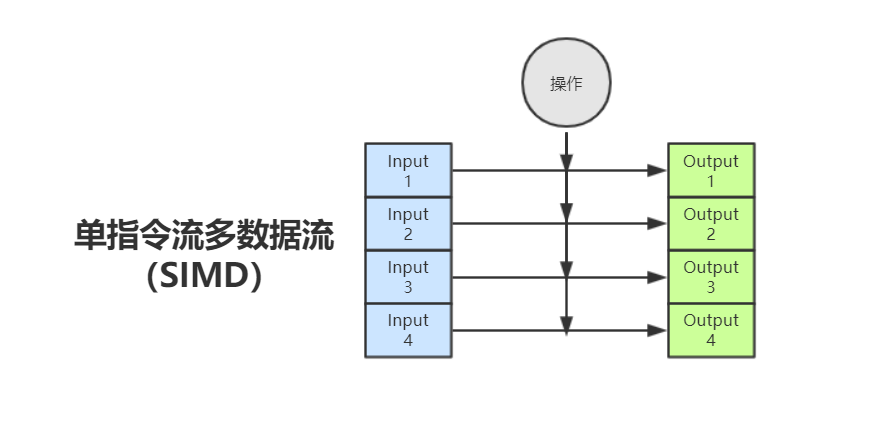
利用 SIMD 指令
SIMD(Single Instruction Multiple Data):简单说就是用单个指令来同时对多个数据分别执行相同的操作,实现指令级并行,可以大大增加计算密集型程序的吞吐量

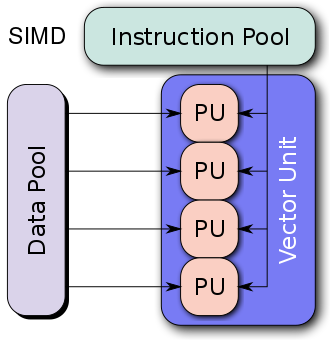
SIMD 把多个 float 打包到一个 xmm 寄存器里同时运算,很像数学中矢量的逐元素加法。因此 SIMD 优化又被称为矢量化,而原始的一次只能处理 1 个 float 的方式,则称为标量。
例如,两个 int32 可以打包成一个 int64,四个 int32 可以打包成一个__m128,八个 int32 可以打包为一个__m256(需支持AVX指令集)
在一定条件下,聪明的编译器能够自动把处理标量 float 的代码,转换成利用 SIMD 指令来处理矢量 float 的代码,从而减轻 CPU-bound,增强程序的吞吐能力。
我们可以查看生成的汇编代码来推断出有无矢量化成功,例如对于加法指令:
addss:一个 float 加法addsd:一个 double 加法addps:四个 float 加法,SIMD 指令addpd:两个 double 加法,SIMD 指令add 后面第一个字母:
- s 表示标量 (scalar)
- p 表示矢量(packed)
add 后面第二个字母:
- s 表示单精度浮点数(single),即 float 类型
- d 表示双精度浮点数(double),即 double 类型
如果编译器生成的汇编里,有大量 ss 结尾的指令则说明矢量化失败;如果看到大多数都是 ps 结尾则说明矢量化成功
理想状态下,同时处理 4 个 float 的 SIMD 指令可以加速 4 倍左右(对于 CPU-bound 程序)。
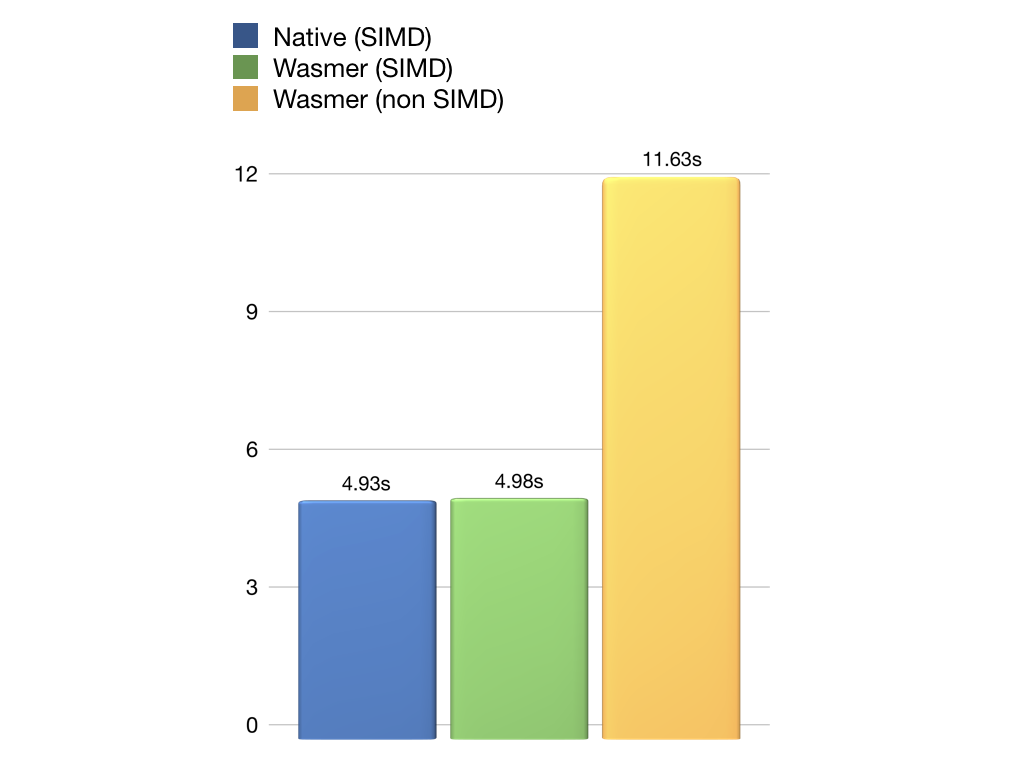
但是 SIMD 指令也有一定局限,因为它一般对矢量算术型操作(例如矢量相加,矢量相乘)支持的很好,而不支持其他类型操作(例如分支判断和跳转)。所以 SIMD 技术常用于 CPU 计算密集型应用(例如人工智能、物理计算、粒子系统、光线追踪、图像处理)
而现在主流就是用 SSE/AVX 指令集来实现 SIMD 技术,并且现代 x86 CPU 都支持了 SSE 系列指令集
- SSE 指令集:128位操作( 4×32bits 或者 2×64bits )
- AVX 指令集:256位操作( 8×32bits 或者 4×64bits)
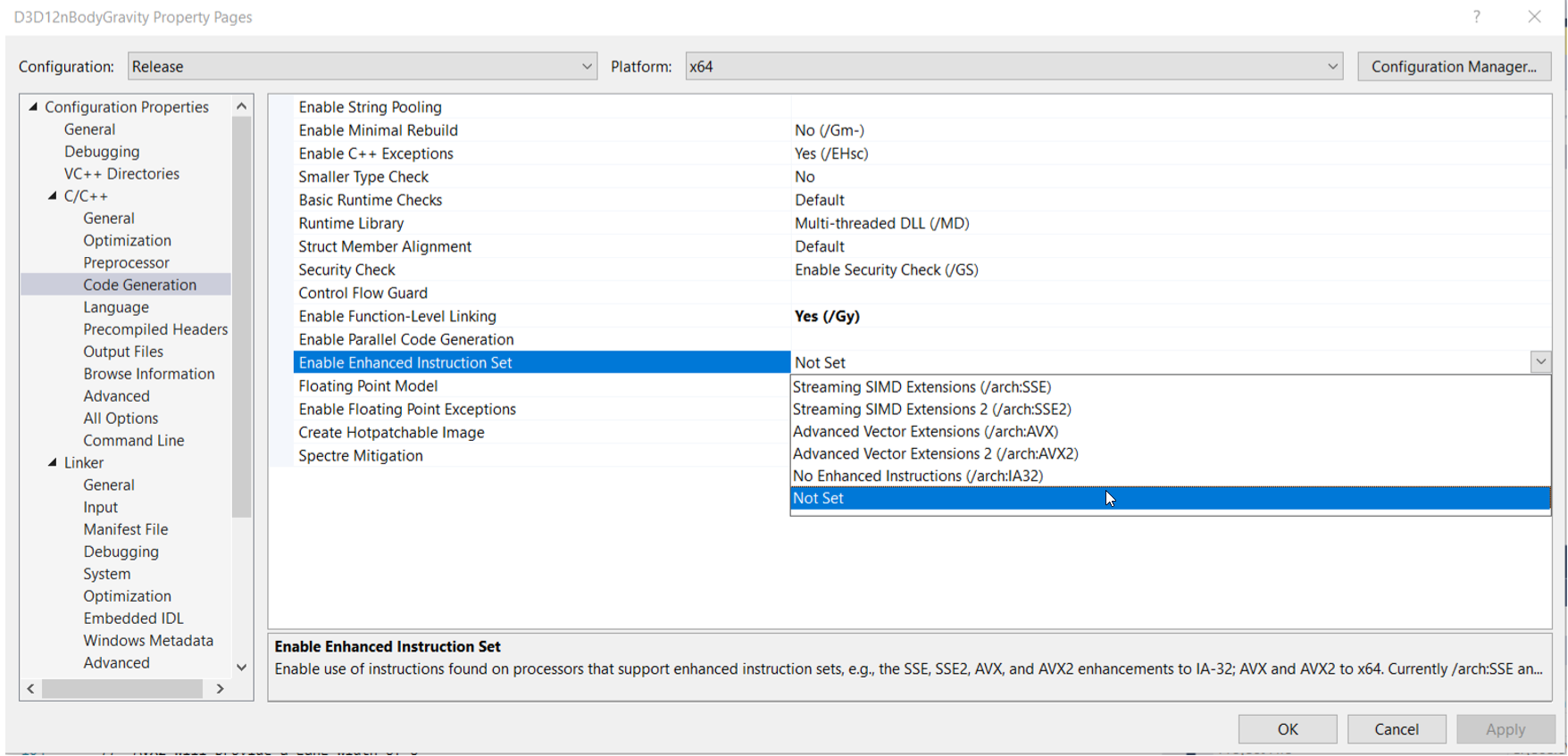
我们可以在编译器里设置好使用哪种支持 SIMD 技术的增强指令集
引导编译器 SIMD 优化 or 显式写出 SIMD 指令
首先,编译器需要添加命令行选项 -O1 , -O2 ,-O3 可以进行不同级别的优化(包含 SIMD 优化),这样可以提高程序的性能,同时代价是也会加大了程序的规模。
但是在相当部分些情形,编译器仍然不敢去做 SIMD 优化。
例如,在下面这个例子:
由于编译器不确定 a 指针和 b 指针是否指向同一块地方(指针重叠),因此不敢进行 SIMD 优化。
void func(float* a,float* b){ for(int i = 0;i<1024;i++) a[i] = b[i] + 1; }
__restrict保证a和b不会有数据依赖,可让编译器大胆执行 SIMD 优化void func(float* __restrict a,float* __restrict b){ for(int i = 0;i<1024;i++) a[i] = b[i] + 1; }也可以使用 OpenMP 指令强行启用 SIMD 优化(需编译器打开
-fopenmp选项)void func(float* a,float* b){ #pragma omp simd for(int i = 0;i<1024;i++) a[i] = b[i] + 1; }而对于
std::vector等变成引用的情形,则无法使用__restrict,必须得通过#pragma omp simd强制进行 SIMD 优化void func(std::vector<int>& a, std::vector<int>& b){ #pragma omp simd for(int i = 0; i<1024; i++) a[i] = b[i] + 1; }
如果引导编译器进行隐式的 SIMD 优化仍不够多,那么可以包含进 SIMD 指令集库来直接显式使用 SIMD 指令,就能更大程度利用 SIMD 指令集:
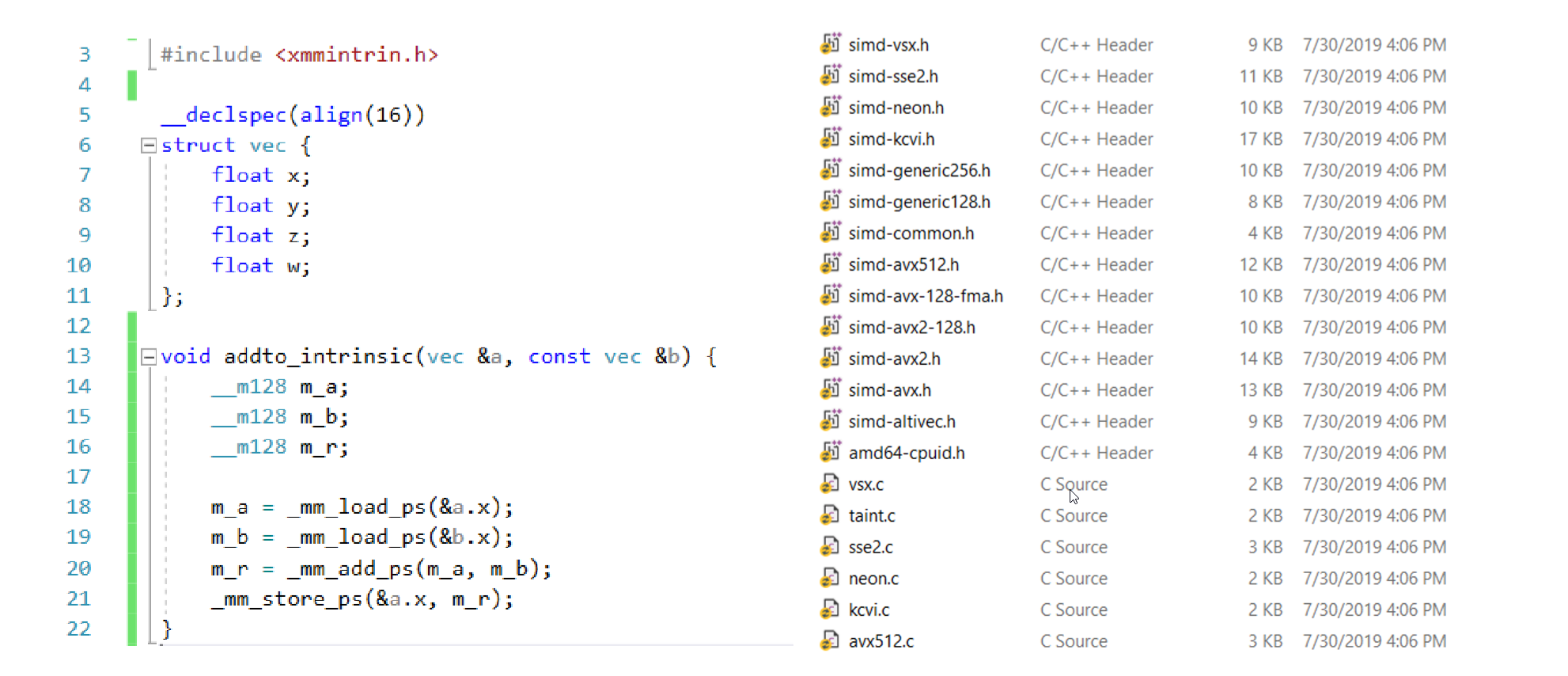
但是,这样编写的代码就需要根据不同平台指令集,包含不同指令集库头文件(无跨平台特性),而且使用这些接近汇编指令会让代码变得晦涩难懂
ISPC 语言
- ISPC 是英特尔推出的面向 CPU 的着色器语言,它适用多种指令集的矢量指令(如SSE2、SSE4、AVX、AVX2等)
- ISPC 是基于 C 语言的,所以它大部分语法和 C 语言是一致的,可以减少学习成本
- ISPC 源代码,经过编译后输出 .obj 文件和 .h 文件。这样我们在编写 C/C++ 程序时可以包含该头文件以使用ISPC代码
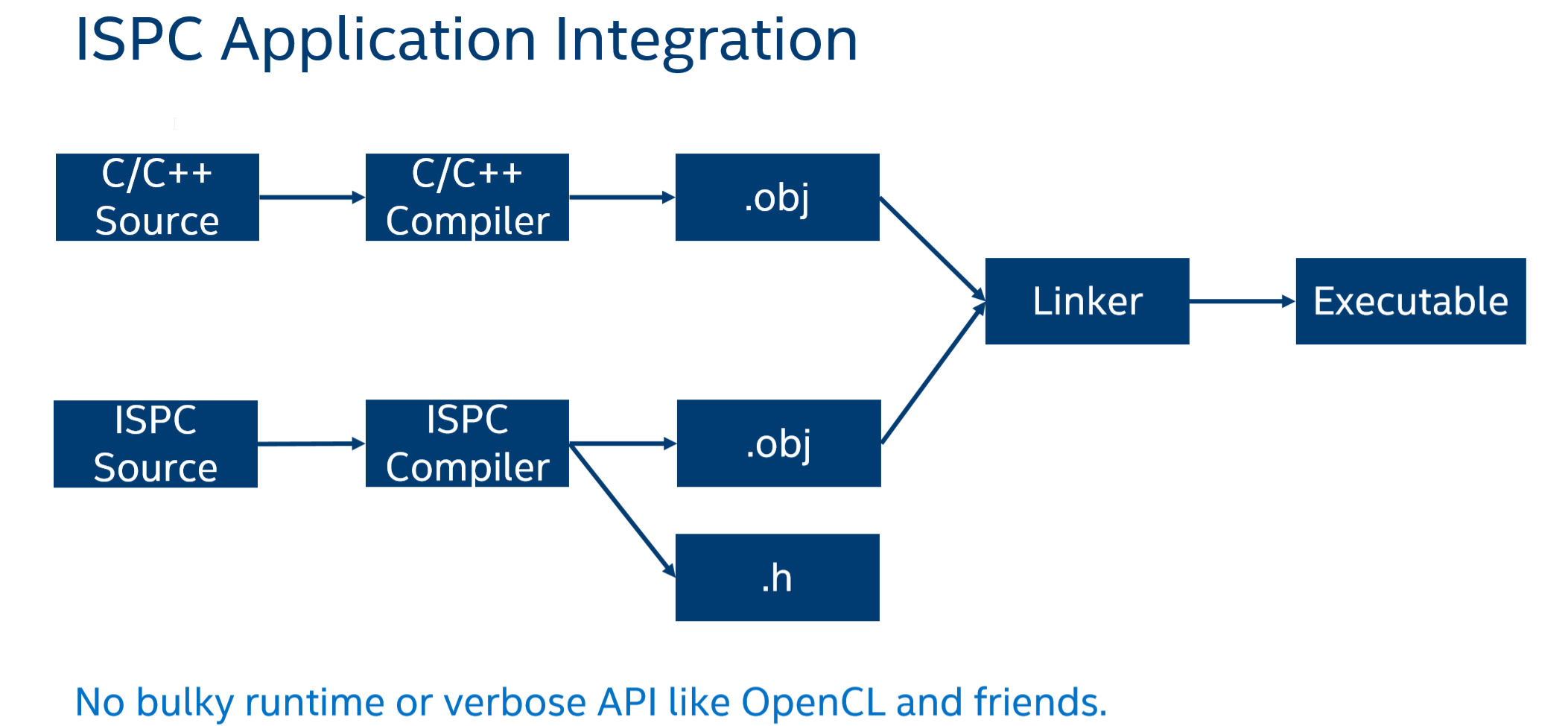
在线编译器 Godbolt ,可以用于测试ISPC代码及调试汇编代码:Compiler Explorer | ISPC
ISPC 语言的语法非常易学,因为它的关键字真的很少:
- 类似于C/C++的关键字:
if,else,switch,for,while,do…while,goto - 当然也有为了支持并行循环的关键字:
foreach,foreach_active,foreach_tiled,foreach_unique - ...
更多更具体的 ISPC 语法就不多讲解,可以自行去查看官方文档(文章末尾参考部分会给出链接)
// C/C++ Code
void func(int N,
float A[],
float B[],
float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] * B[i];
}
}
上面是一个正常的 C/C++ 循环代码,这样就是一般的分量操作,如下图左侧:
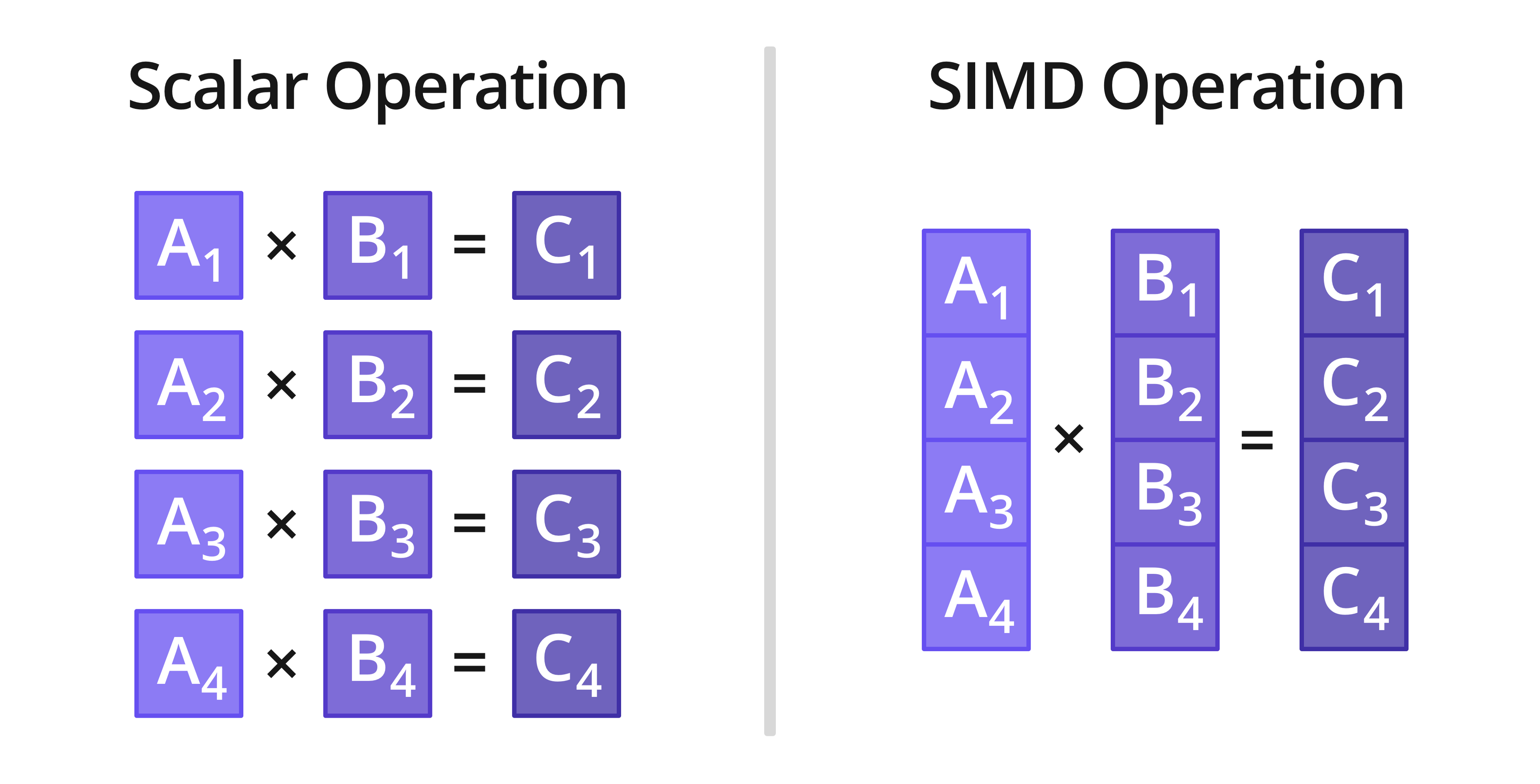
在ISPC语法里,只需简单的写上 foreach(i = 0 ... N) ,IPSC 编译器编译时会为其编译成图中右侧的行为,即一次循环并行处理M个元素,实际循环N/M次。
// ISPC Code
export void rgb2grey(int N,
uniform float A[],
uniform float B[],
uniform float C[]) {
foreach(i = 0 ... N) {
C[i] = A[i] * B[i];
}
}
更方便的是,ISPC 会自动处理并行循环的边界情况(例如每次并行处理4个元素时,N/4次循环后余出1~3个元素);而且 ISPC 还支持 Parallel For ,利用多核进一步并行化循环
避免 Gather 行为
SIMD 寄存器读取变量一般都是一次性读取连续若干个(在图中为4个)变量,这种行为叫做矢量读取(Vector Load)。
这是一个 OOP(面向对象编程)定义的颜色结构,文中定义了若干个颜色对象。
struct Color{
float r,g,b;
};
Color colors[1024];
其内存分布则如图:当程序只想要对 4 个 r 分量进行矢量化操作时,却需要进行多次读取,这被称为 Gather 行为。
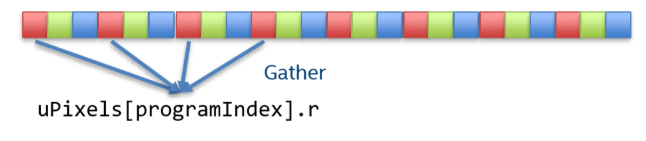
如果,我们将结构体定义成:
struct VaryingColor{
float r[VLEN];
float g[VLEN];
float b[VLEN];
};
Color colors[1024/VLEN];
其内存分布则如下:可以一次 Vector Load 得到 4 个 r 分量,从而更加容易进行 SIMD 优化,而且也是对齐到 2 的幂次方,因此被称为一种 SIMD 友好型的结构
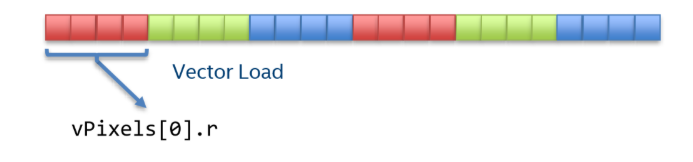
而在ISPC语言里,使用 varying 类型可以在代码层面上符合 OOP 设计思想,在实际编译出来的行为上却是实现成 SIMD 友好型结构,非常方便。
struct Color{
float r, g, b;
};
varying Color vPixels[1024];
数据布局
结构体大小对齐到2的幂次方
结构体大小如果对齐到2的幂次方字节,会对计算机各种硬件更加友好。
例如:SIMD 矢量化单位往往是 16 字节或 32 字节,对齐可以更加容易 SIMD 矢量化
为了填充结构体大小,可以直接塞入 padding 变量:
struct MyVec{
float x;
float y;
float z;
char padding[4];
};
而 C++11 提供了 alignas 的语法糖,自动塞入 padding ,让 struct 对齐到指定的大小:
struct alignas(16) MyVec{
float x;
float y;
float z;
};
但同时,要注意塞入 padding 后的结构体大小比原来大了,为此可能带来另一种性能代价:
例如:原本一个缓存行可以装载 5 个 MyVec ,对齐后只能装载 4 个 MyVec,影响 Cache 命中率

因此,结构体尽量设计成对齐2的幂次方大小,实在对不齐则需要严格测试两种方式的性能,再选择是否使用 padding 对齐
分配页对齐的内存
操作系统的内存是采用分页(page)来管理的,有些页可能不可访问或者还没有分配到内存,访问这些页就会产生异常,进入内核模式。因此硬件出于安全,会让 Cache Prefetch 不能跨越页边界,否则可能会触发不必要的 page fault
那么,只要我们申请分配内存是边界地址对齐到页:
- 所需分配的内存大小 <= 一页(4096 B)时,就能完全避免块内部跨页现象
- 所需分配的内存大小 > 一页(4096 B)时,则稍微注意一下内部访问的对齐也能避免内部跨页现象
而使用 malloc 等常用的内存分配是不对齐的,那么无论所需分配的内存有多大,都不能保证避免内部跨页现象
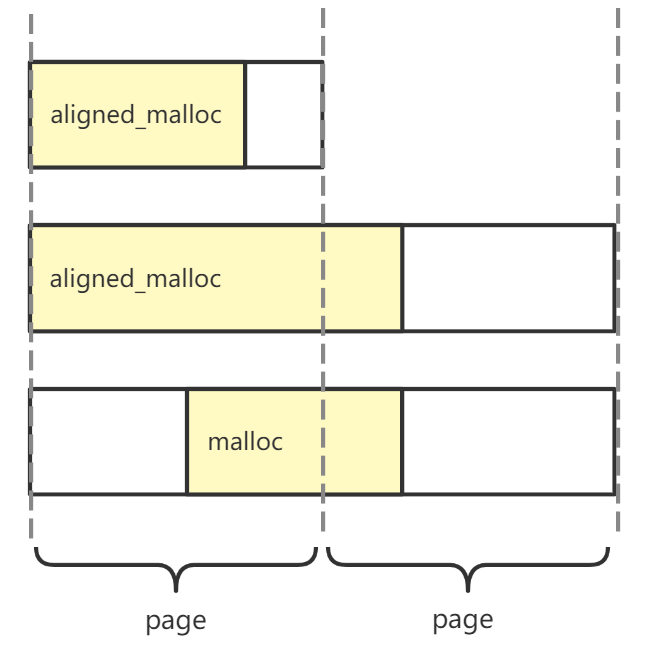
_mm_malloc :申请起始地址对齐到指定边界地址大小的一段内存,为了实现页对齐,应当将边界地址大小设置为 4096 字节;需要搭配 _mm_free 使用;仅适用于 Intel 编译器
float* a = (float*)_mm_malloc(n * sizeof(float), 4096);
aligned_malloc :C++17 <memory> 库提供的内存对齐分配函数;需要搭配 aligned_free 使用;相对前者跨平台性更好
float* a = (float*)aligned_malloc(n * sizeof(float), 4096);
使用对象数组存储批处理对象
传统的组件模式,往往让游戏对象持有一个或多个组件的引用(指针):
// 例如一个游戏对象类,包含了2种组件的指针
class GameObject {
// ...GameObject的属性
Component1* m_component1;
Component2* m_component2;
};
下面一幅图显示了这种传统模式的结构: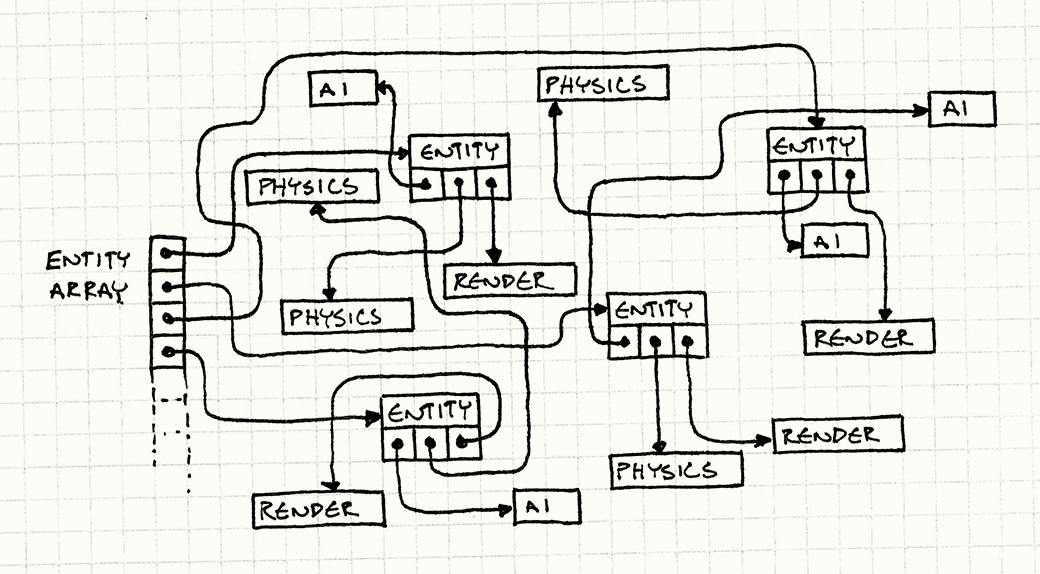
游戏对象/组件往往是批处理操作较多(每帧更新/渲染/或其他操作)的对象。
这个传统结构相应的每帧更新代码:
for(int i = 0; i < GameObjectsNum; ++i) {
if(g[i].componet1 != nullptr)g[i].componet1->update();
if(g[i].componet2 != nullptr)g[i].componet2->update();
}
而根据图中可以看到,这种指来指去的结构对 CPU Cache 极其不友好:为了访问各个组件,总是跳转到不相邻的内存。
倘若游戏对象和组件的更新顺序不影响游戏逻辑,则一个可行的办法是将他们都以连续数组形式存在。
注意是对象数组,而不是指针数组。如果是指针数组的话,这对CPU缓存命中没有意义(因为要通过指针跳转到不相邻的内存)
Component1 a[MAX_COMPONENT_NUM];
Component2 b[MAX_COMPONENT_NUM];
// 连续数组存储能让下面的批处理中CPU缓存命中率较高
for (int i = 0; i < Componet1Num; ++i) {
a[i].update();
}
for (int i = 0; i < Componet2Num; ++i) {
b[i].update();
}
AOS,SOA,AOSOA
AOS(Array of Struct):单个对象的属性紧挨着存,即 (xyz)(xyz)(xyz)(xyz)(xyz)(xyz)(xyz)(xyz)

- 是 OOP(面向对象编程)的数据布局方式,便于存储在各类容器
- AOS 必须对齐到 2 的幂才能高效(便于 SIMD 优化),但总体来看往往效率不高
struct MyVec {
float x;
float y;
float z;
};
MyVec a[N];
void func(){
for(int i = 0; i < N; i++){
a[i].x *= a[i].y;
}
}
SOA(Struct of Array):属性分离存储在多个数组,即 (xxxxxxxx)(yyyyyyyy)(zzzzzzzz)

- 比较反直觉,只适合存储在数组,属于DOP(面向数据编程)的一种数据布局方式
- 便于 SIMD 优化,通常效率更高
struct MyVec {
float x[N];
float y[N];
float z[N];
};
MyVec a;
void func(){
for(int i = 0; i < N; i++){
a.x[i] *= a.y[i];
}
}
AOSOA:属于AOS和SOA的组合方式,如 ((xxxx)(yyyy)(zzzz))((xxxx)(yyyy)(zzzz))

- 既有 AOS 便于存储在各类容器的特性,又有类似 SOA 那样一定的高效特性
- 数据访问方式变复杂,例如遍历可能需要两层 for 循环
- 对象数量需要保证是内部 SOA 大小(例子中是1024字节)的整数倍,否则需要额外特判法代码
- 内部 SOA 不宜太小。假如内部 SOA 太小,就会使得内部循环的连续访问次数会少些,从而导致 prefetch 机制失效率更高(内部 SOA 遍历完后,需要跳转到一个 SOA 的距离,而不是一个标量的距离)
struct MyVec {
float x[1024];
float y[1024];
float z[1024];
};
MyVec a[N/1024];
void func(){
for(int i = 0; i < N/1024; i++){
for(int j = 0; j < 1024; j++){
a[i].x[j] *= a[i].y[j];
}
}
}
简单总结:一般来说,在面向数据编程(DOP)中应当多使用 SOA 或者 AOSOA,在大部分情况下都能获得较好的优化效果,但这不意味着 AOS 就是绝对低效的
-
需要做 SIMD 优化时:SOA、AOSOA 是 SIMD 友好型结构,几乎基于该布局的结构都能很好做 SIMD 优化;而 AOS 需要对齐到 2 的幂次方才可能做部分 SIMD 优化
-
属性几乎总是同时一起用的:使用 AOS 比较好,减轻 prefetch 压力
例如:位置的 x,y,z 分量,大部分时候都是同时读取同时修改的
-
属性有时只用到部分 or 所有属性不一定同时写入:使用 SOA 比较好,省内存带宽
例如:position 和 velocity,通常的情况都是 position += velocity,也就是 position 是读写,velocity 是只读
-
希望方便使用各种数据结构,同时享受 SOA 优化效果:使用 AOSOA 比较好,在高层保持 AOS 的统一索引,底层又享受 SOA 带来的 SIMD 优化和缓存行预取等好处
例如:数据结构不是数组,而是稀疏的哈希网格之类的,就更适合 AOSOA 而不适合 SOA
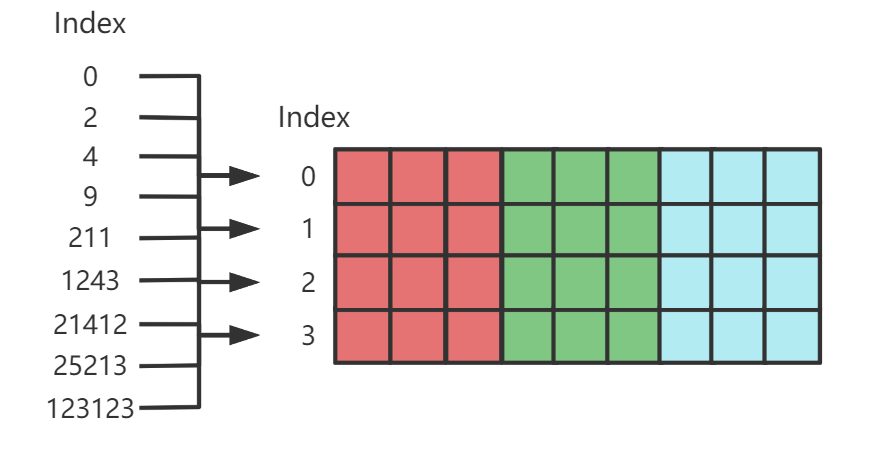
避免无效数据夹杂在 Cache
这是一个简单的粒子系统:
// 粒子类
struct Particle {
Vec3 position;
Vec3 velocity;
bool active;
// ... 其它成员
};
int main(){
Particle particles[MAX_PARTICLE_NUM];
int particleNum = 1024;
for (int i = 0; i < particleNum; ++i) {
if (particles[i].isActive()) {
particles[i].update();
}
}
return 0;
}
它使用了典型的lazy策略:
- 当要删除一个粒子时,只需改变active标记,无需移动内存
- 利用标记判断,每帧更新的时候可以略过删除掉的粒子
- 当需要创建新粒子时,只需要找到第一个被删除掉的粒子,更改其属性即可
表面上看这很科学,实际上这样做 CPU Cache 命中率不高:每次批处理 CPU Cache 都加载过很多不会用到的粒子数据(标记被删除的粒子)
例如下图加载的两个缓存行,可能实际进行有效 update 的粒子只有 4 个,浪费了一半的 Cache
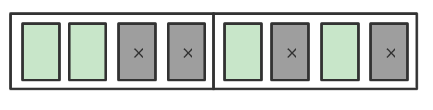
一个可行的方法是:当要删除粒子时,将队列尾的粒子内存复制到该粒子的位置,并记录减少后的粒子数量。移动内存(复制内存)操作是程序员最不想看到的,但是实际执行批处理带来的速度提升相比删除的开销多的非常多,除非你移动的内存对象大小实在大到令人发指
particles[i] = particles[particleNum];
particleNum--;

这样我们就可以保证在这个粒子批量更新操作中,CPU Cache 总是能以高命中率命中。
for (int i = 0; i < particleNum; ++i) {
particles[i].update();
}
冷热数据分割
有人可能认为这样能最大程度利用 CPU Cache :把一个对象所有要用的数据(包括组件数据)都塞进一个类里,而没有任何用指针或引用的形式间接存储数据。
实际上这个想法是错误的,我们不能忽视一个问题:CPU Cache 的存储空间是有限的
于是我们希望 CPU Cache 存储的是经常使用的数据,而不是那些少用的数据。这就引入了冷数据/热数据分割的概念了
- 热数据:经常要操作使用的数据,我们一般可以直接作为可直接访问的成员变量
- 冷数据:比较少用的数据,我们一般以引用/指针来间接访问(即存储的是指针或者引用)
一个游戏中的例子:对于怪物对象来说,生命值位置速度都是经常需要操作的变量,是热数据。而掉落物对象只有怪物死亡的时候才需要用到,所以是冷数据;
class Monster {
Vec3 position;
Vec3 velocity;
float health;
LootDrop* drop;
//....
};
class LootDrop{
std::vector<Item> itemsToDrop;
std::vector<float> possibility;
//....
};
应用
Blur 操作优化
以 2D 均值模糊的操作为例,可以分成横向的 Blur 和纵向的 Blur,按顺序做完这两个方向的 Blur 其效果就等价于对 2D 范围内的 Blur:
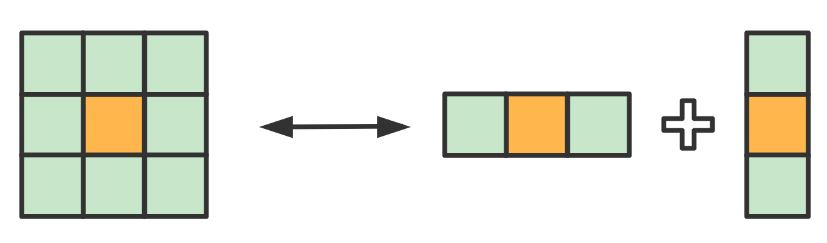
X方向 Blur
- 使用 prefetch :由于 Blur 的时候,最内层循环的遍历方向往往是跳到反方向的某个位置开始访问,使得硬件自动预测的 prefetch 容易失效(预测原本是期待顺着 x 方向连续访问),因此这里需要手动使用 prefetch 指令提示机器预取 Cache
- 使用 stream :由于我们只需要写入 b[y][x] 而不需要读取 b[y][x] 的值,因此使用直写可以避免 b 数组污染 Cache
for (int y = 0; y < height; y++)
for (int xBase = 0; xBase < width; xBase += 16)
{
// prefetch,提前了 16 次内循环的时间
_mm_prefetch(&a[y][xBase+16], _MM_HINT_T0);
// 一个缓存行大小
for (int x = xBase; x < xBase + 16; x++)
{
float res = 0;
for (int t = -RADIUS; t <= RADIUS; t++)
{
res += a[y][x+t];
}
// stream
__mm_stream_ps(&b[y][x], res/SUM);
}
}
Y方向 Blur
- 分块访问 :
- 上图为传统行主序遍历的纵向 Blur,可以看到纵向的元素相隔的时间太远,对时间局部性不友好,很难命中 Cache
- 下图为利用分块访问的思想,一竖块一竖块地遍历,块内正常使用行主序遍历,那么此时会发现纵向地元素相隔时间都较短,对时间局部性友好
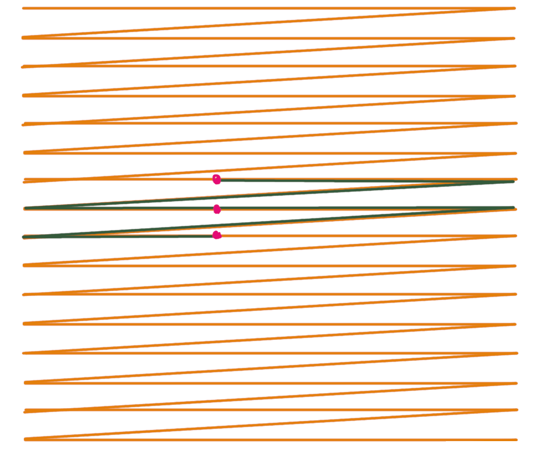
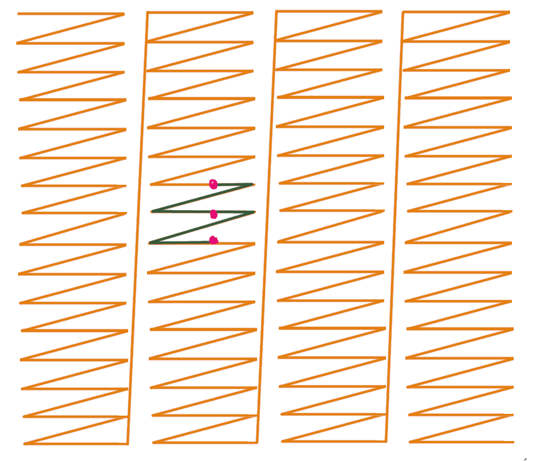
- 使用 prefetch :y 方向的访问必定是跳跃的,无连续可言,因此需要用 prefetch 指令提示机器预取 Cache
- 使用 SIMD 指令:并行计算,减轻 CPU-bound
- 使用 stream :只需要写入 b[y][x] 而不需要读 b[y][x] 的值,因此使用直写可以避免 b 数组污染 Cache
// 对 X 分块
for (int x = 0; x < width; x += 32)
for (int y = 0; y < height; y ++)
{
// prefetch,提前了 RADIUS+40 次内循环的时间
_mm_prefetch(&a[y+RADIUS+40][x], _MM_HINT_T0);
_mm_prefetch(&a[y+RADIUS+40][x+16], _MM_HINT_T0);
// 让 res 初始化为 0,利用 SIMD(AVX指令) 置0
__m256 res[4];
#pragma GCC unroll 4
for (int offest = 0; offset < 4; offset++)
{
res[offset] = _mm256_setzero_ps();
}
// 利用 SIMD(AVX指令) 累加
for (int t = -RADIUS; t <= RADIUS; t++)
#pragma GCC unroll 4
for (int offset = 0; offset < 4; offset++)
{
res[offset] = _mm256_add_ps(res[offset],_mm256_load_ps(&a[y+t][x+offset*8]));
}
#pragma GCC unroll 4
// stream
for (int offset = 0; offset < 4; offset++)
{
_mm256_stream_ps(&b[y][x+offset*8], res[offset]/SUM);
}
}
ECS 架构
ECS架构:由Entities(实体),Components(组件),Systems(系统)三部分组成的一个面向数据编程(DOP)架构, 也是游戏工业界比较新的架构。要理解 ECS 架构,可以分别从这三部分的概念了解。
ECS 架构的普及可以归功于 GDC 2017上的演讲 "Overwatch Gameplay Architecture and Netcode" ,这个演讲便是讲述了《守望先锋》所使用的 ECS 架构; Unity 也有插件所支持的 Entitas 框架,再后来 Unity 2018 也推出了 ECS 框架的 preview 版本(至今仍然 preview );至于 Epic 则在 UE5 中推出了 MASS 框架,其实也是属于一种 ECS 架构
Entity(实体):代表了一个装有若干个 Component 的容器,可以添加或删除 Component;Entity 本身没有属性和逻辑,而是通过的 Components 的组合来体现 Entity 的属性组成
Component(组件):代表了一份特定格式的数据;例如:Translation,它可以包含一个 vec4 变量来表示位移数据
System(系统):代表一个每帧都会执行的行为逻辑,其接口一般是输入若干个 Component,输出(或者更准确说是修改)若干个 Component;例如:TransformUpdate,它可以输入 Rotation、Scale、Translation,然后修改 LocalToWorld
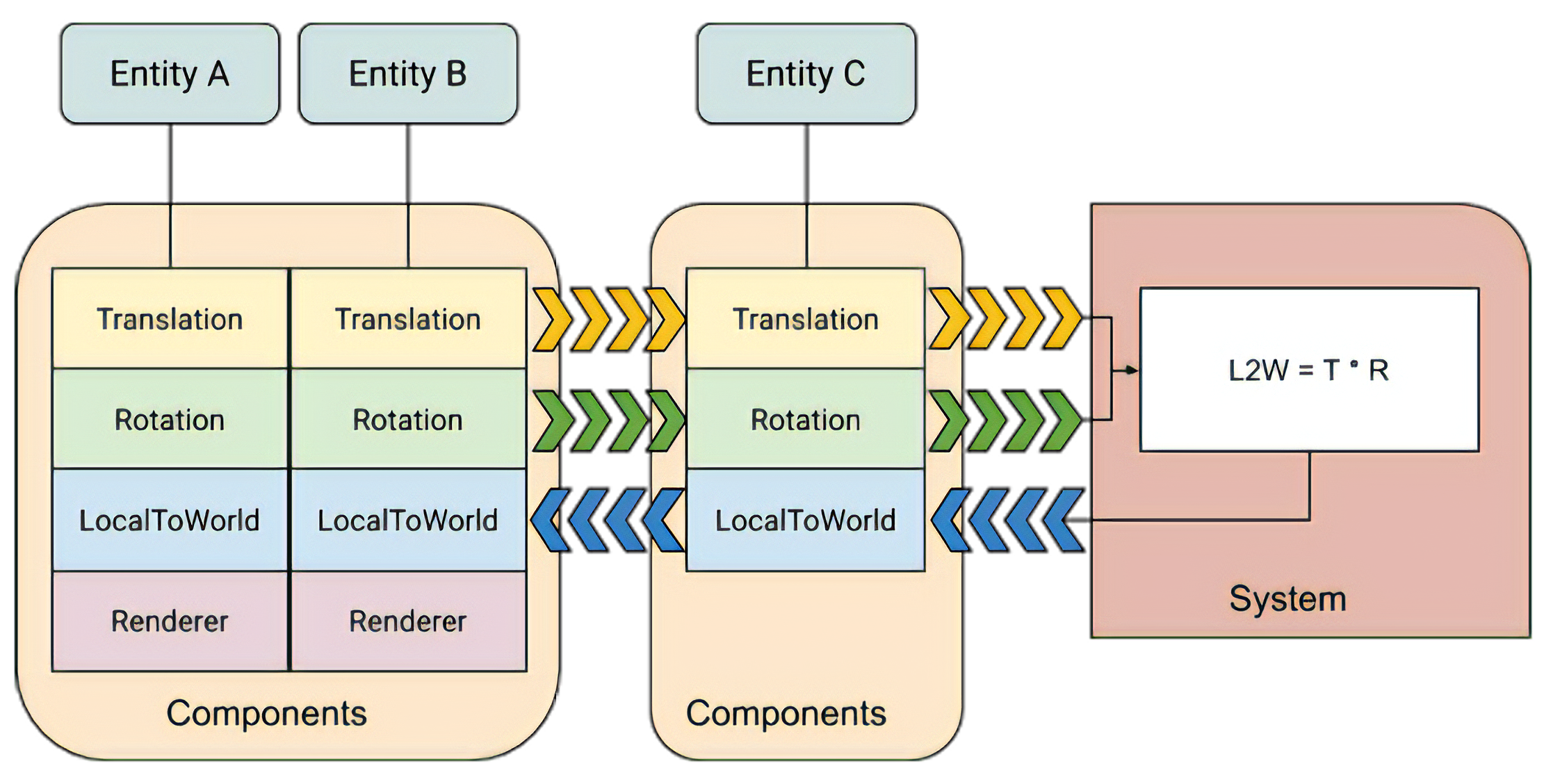
ECS 架构的优势在于:
- 组件模式设计,解耦合,易扩展
- 数据布局对 CPU Cache 友好,减少 memory-bound
- 可以搭配 Job System 来充分利用多核,从而获得更好的并行加速,减少 CPU-bound
缺点在于:
- 编写 ECS 代码实际上就是在某种规范约束下写逻辑(DOP是比较反直觉的,需要优先考虑数据布局),很难像面向对象编程(OOP)那样随心所欲地抽象出各种逻辑(例如父子关系就难以在 ECS 框架中实现 ),在某种意义上是牺牲了代码开发效率
- 在某些方面(例如游戏UI),ECS 框架的优化效果并不明显;只有在比较大规模相同物体的情况下才能获得明显的优化效果
更多设计细节
Entity
- Entity 的具体实现往往只包含一个身份 ID(索引),通过向数据结构(一般是动态数组)进行索引查询可以知道这个 Entity 对应的那些 Components
Component
- Component 的属性应当是强联系的,相关性不强的属性应该切分成多种 Components,这主要是为了 Cache 友好。例如一些 System 行为中,只对 Component 的部分数据感兴趣,但由于空间局部性,另一部分不感兴趣的数据也加载进 Cache(避免无效数据夹杂在连续内存),如果切分 Component 的粒度设计的好,那么就可以只加载感兴趣的 Component 进 Cache
- 删除 Entity 时,需要删除其对应的 Components。为此不推荐使用 lazy 标记的删除方法,而是将 buffer 中最后一个 Entity 的 Components 覆盖到被删除的位置,并将 buffer 中的 Components 数量减去1
System
- 如果确定各个 System 行为的依赖关系(无依赖关系则是最理想的情况)并分好顺序,那么就可以使用多线程来并行跑 Systems(Job System 就是为此而用的),减少 CPU-bound
- 还可以引入 LOD 机制,通过计算与玩家的距离来决定 Systems 的 update 频率
Unity ECS
举个 Unity ECS 框架的例子,来一窥 ECS 的一种实现方案
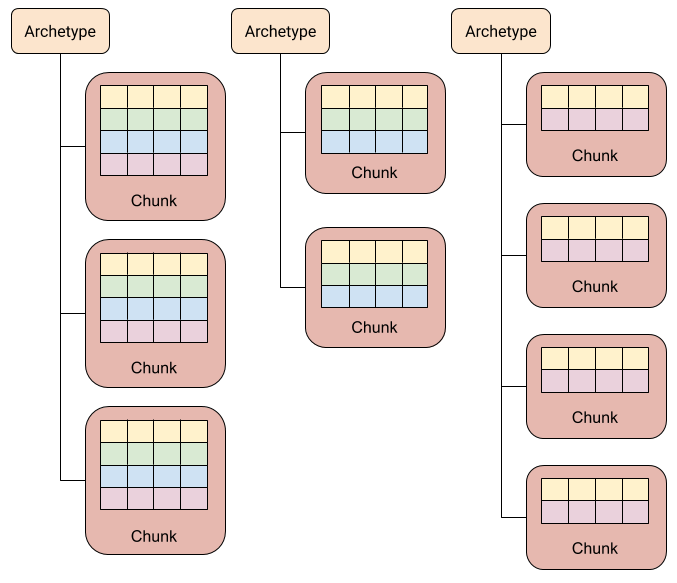
Archetype(原型):一种 Components 的组合方式,可以把 Archetype 理解成一个类,而 Entity 则是类的实例化对象。通过 Archetype 可以生成并管理若干个含有相同 Components 组合的 Entities
为什么需要 Archetype ?
- 使用 Archetype 可以将相同种类的 Entities 聚拢,设计 System 的行为时就可以跑在指定种类的 Entities 上,也就是跑在一个或多个 Archetype 上
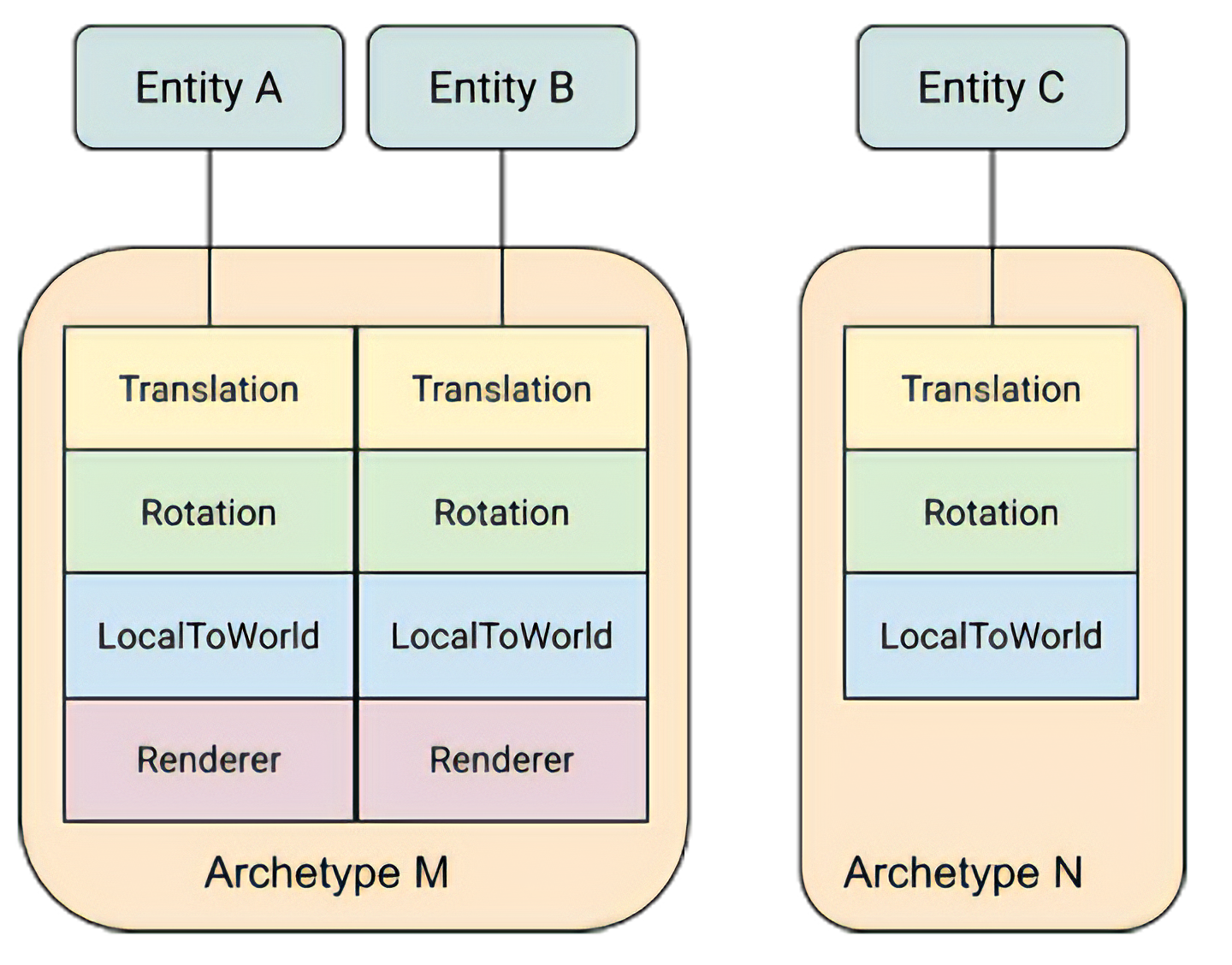
ArchetypeChunk:是存放 Entity 对应 Components 的 buffer,而每个 Archetype 各自管理着自己的 Chunks;每个 Chunk 只能容纳一定数量的 Components ,若超出数量,Archetype 会创建新的 Chunk 来容纳多出的 Entity Components
为什么需要 ArchetypeChunk ?
- 假如 Archetype 直接管理着一个无限大的 Chunk ,然后把所有自己实例化出来的 Entity Components 通通塞进去,那么在多线程环境下的删除等操作很容易造成冲突
- 分成若干个 Chunk(但不宜让 Chunk 容量太小,不然会丧失 ECS 的优化效果),并让每个 Chunk 最多受到一个线程的处理。那么对某个 Entity 的删除操作则只会影响当前 Chunk 的线程,不会干扰到其它线程
参考
- [1] 《Game Engine Architecture》 by Jason Gregory
- [2] 《深入理解计算机系统》by Bryant,R.E.
- [3] 高性能并行编程课程 Parallel101 by 小彭老师
- [4] 【GDC2017】Overwatch Gameplay Architecture and Netcode
- [5] 浅谈Unity ECS(一)Uniy ECS基础概念介绍:面向未来的ECS
- [6] Unity3D DOTS | ECS concepts
- [7] 使用英特尔® ISPC 简化SIMD开发 | 英特尔® 软件
- [8] Intel® Implicit SPMD Program Compiler | ispc.github.io
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号