

The Hello World of Deep Learning with Neural Networks
The Hello World of Deep Learning with Neural Networks
编写这样一个函数的代码:
float hw_function(float x){
float y = (2 * x) - 1;
return y;
}
Imports
导入 TensorFlow 并将其称为 tf,以方便使用。
导入一个名为 numpy 的库,它可以帮助我们轻松快速地将数据表示为列表。
导入kears(将神经网络定义为一组序列层的框架叫做 keras
import tensorflow as tf
import numpy as np
from tensorflow import keras
Define and Compile the Neural Network
创建最简单的神经网络。它有 1 层,该层有 1 个神经元,其输入形状只是 1 个值。
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
接下来编译神经网络。编译时,我们必须指定两个函数,一个是损失函数LOSS,另一个是优化器函数OPTIMIZER。
LOSS 函数会将猜测的答案与已知的正确答案进行对比,并衡量其结果的好坏。
然后,它会使用 OPTIMIZER 函数再做一次猜测。根据损失函数的结果,它将尝试使损失最小化。这时,它可能会得出 y=5x+5 这样的结果,虽然仍然很糟糕,但更接近正确结果(即损失更小)。
它会在许多次EPOCHS重复这样的计算(循环) 。但首先,我们要告诉它如何使用 "平均平方误差(MEAN SQUARED ERROR) "来计算损失函数loss,以及如何使用 "随机梯度下降(STOCHASTIC GRADIENT DESCENT) "来计算优化器。
model.compile(optimizer='sgd', loss='mean_squared_error')
Providing the Data
输入一些数据: 6 个 x 和 6 个 y。这些数据之间的关系是 y=2x-1,所以 x =-1,y=-3 等等。
一个名为 "Numpy "的 python 库提供了许多数组类型的数据结构,它们是一种事实上的标准方法。我们通过将数值指定为 np .array [] 来声明这些数据。
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
Training the Neural Network
训练神经网络的过程,也就是 "学习 "X 和 Y 之间关系的过程,是在 model.fit 调用中进行的。在这个过程中,它将经历我们上面提到的循环,做出猜测,衡量猜测的好坏(LOSS),使用优化器(OPTIMIZER)做出另一个猜测等等。它会按照你指定的EPOCHS进行。
model.fit(xs, ys, epochs=500)
使用 model.predict 方法让它计算出未知 X 的 Y 值。
print(model.predict([10.0]))
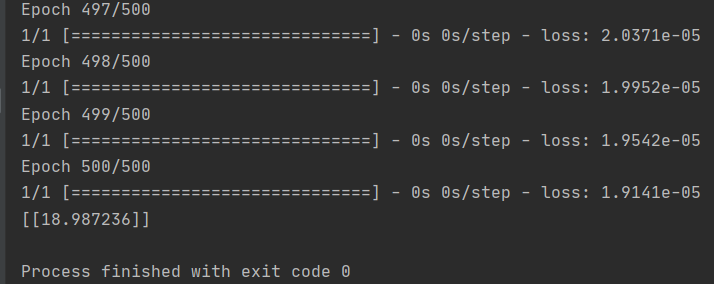 结果非常接近 19,但不一定是 19。
结果非常接近 19,但不一定是 19。
神经网络处理的是概率问题,而不是确定性问题,并且会进行一些编码,以便根据概率找出结果,尤其是在涉及分类的时候。(You will almost always deal with probabilities, not certainties, and will do a little bit of coding to figure out what the result is based on the probabilities, particularly when it comes to classification.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号