
第五周--论文泛读
VSE++: Improving Visual-Semantic Embeddings with Hard Negatives
1 摘要
受到hard negative mining的启发(在结构化预测中使用hard negative和对loss function进行排序的启发),我们对用于多模态嵌入的常见损失函数进行了简单的更改。
- hard negative mining
难例挖掘和非极大值抑制NMS一样,都是为了解决目标检测样本不平衡和低召回率的问题。
在目标检测过程中为了提高召回率,通常会提出很多Region Proposal(远超过实际数量的ground truth),但是大量的Region Proposal会使得训练时绝大部份都是负样本,为了保证样本均衡,需要对负样本进行抽样。
一般情况下选取正负样本的比例为1:3,且选择负样本中容易被分错类的困难负样本进行网络训练。
如何判断困难负样本?
选用初始样本集去训练网络,再用训练好的网络去预测负样本集中剩余的负样本,选择置信度误差较大的负样本作为困难负样本。
- visual-semantic embeddings for cross-modal retrieval
embedding意味着从两个(或更多)结构域映射到其中语义上相关联的输入(例如,文本和图像)被映射到相似的公共向量空间。
visual-semantic embeddings则是检索具有标题的图像或查询图像的标题。
visual-semantic embeddings应用于很多领域:image-caption retrieval and generation、visualquestion-answering... - 本文创新点
利用hard negative的思想,对损失函数进行改进。
2 方法介绍
2.1 Visual-Semantic Embedding
- 图像采用VGG19或者ResNet152进行特征提取
- 文本描述采用GRU将文本与图像映射到同一个子空间
- 使用线性映射把图像特征和文本特征映射到Embedding中
![]()
- 使用内积计算相似度
![]()
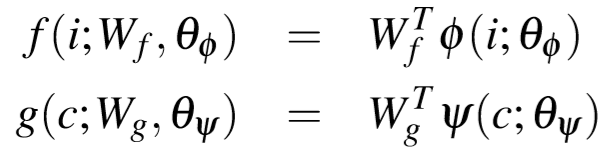
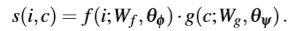
2.2 loss function
训练可以使损失最小化
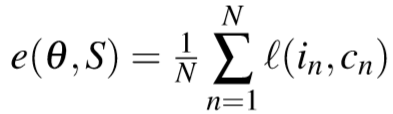
最近的方法使用a hinge-based triplet ranking loss作为损失函数
Sum of Hinges (SH) loss
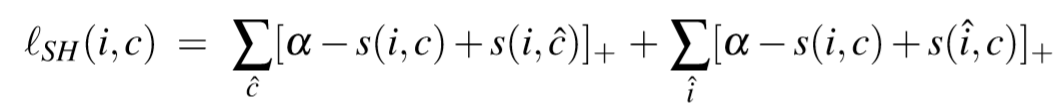
2.3 Emphasis on Hard Negatives
Max of Hinges (MH) loss
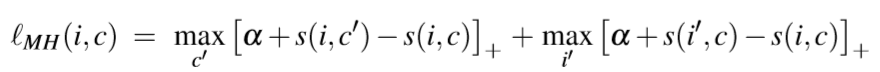
与之前的损失函数不同的是,这种损失是根据 the hardest negatives 确定的。
Leveraging Visual Question Answering for Image-Caption Ranking
1 摘要
提出了一个score-level和 representation-level融合模型,并整合学习到的VQA knowledge,最后利用在提高image caption ranking上面。
2 Building Blocks: Image-Caption Ranking and VQA
2.1 Image-Caption Ranking
Image-Caption Ranking是在给定查询字幕的情况下检索相关图像,并在给定查询图像的情况下检索相关字幕。
Image-Caption Ranking使用 ranking scoring function S(I,C),使得相应的检索概率最大化:
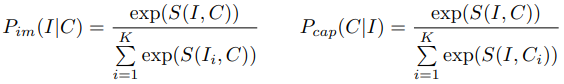
构造S(I,C)通常使用组合方式:
- 图像表示通常使用用于图像分类的预训练的CNN
- 字幕表示通常使用多模式下使用RNN计算的句子编码空间。
2.2 VQA
VQA的任务是给图像I和关于I的自由形式的开放式问题Q,并为该问题生成自然语言的答案A。
3 方法
3.1 VQA-Grounded Representations
使用VQA和VQA-字幕模型表示VQA空间中的图像和字幕
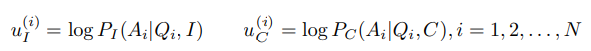
映射到同一 embedding space
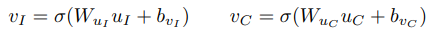
3.2 score-level fusion and representation-level fusion
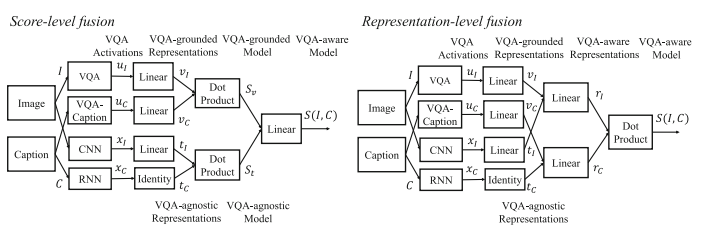
- Score-Level Fusion
![]()
- Representation-Level Fusion
![]()
![]()
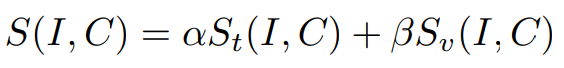
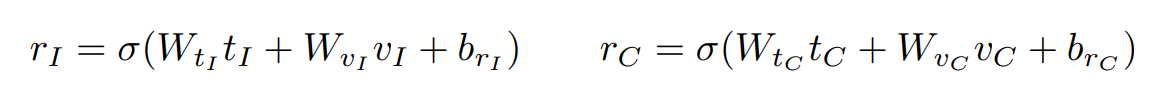
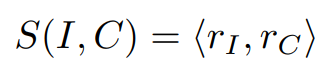
Knowledge Aware Semantic Concept Expansion for Image-Text Matching
1 摘要
解决的问题:现有模型仅从给定图像中检测语义概念,因此不太可能处理long-tail和遮挡概念。 同一场景中经常出现的概念,例如 卧室和床可以提供常识知识,以发现其他与语义相关的概念。
解决方式:Scene Concept Graph (SCG)--通过聚集图像场景图并提取频繁出现的概念对作为场景常识。
2 Scene Concept Graph Based Image-Text Matching
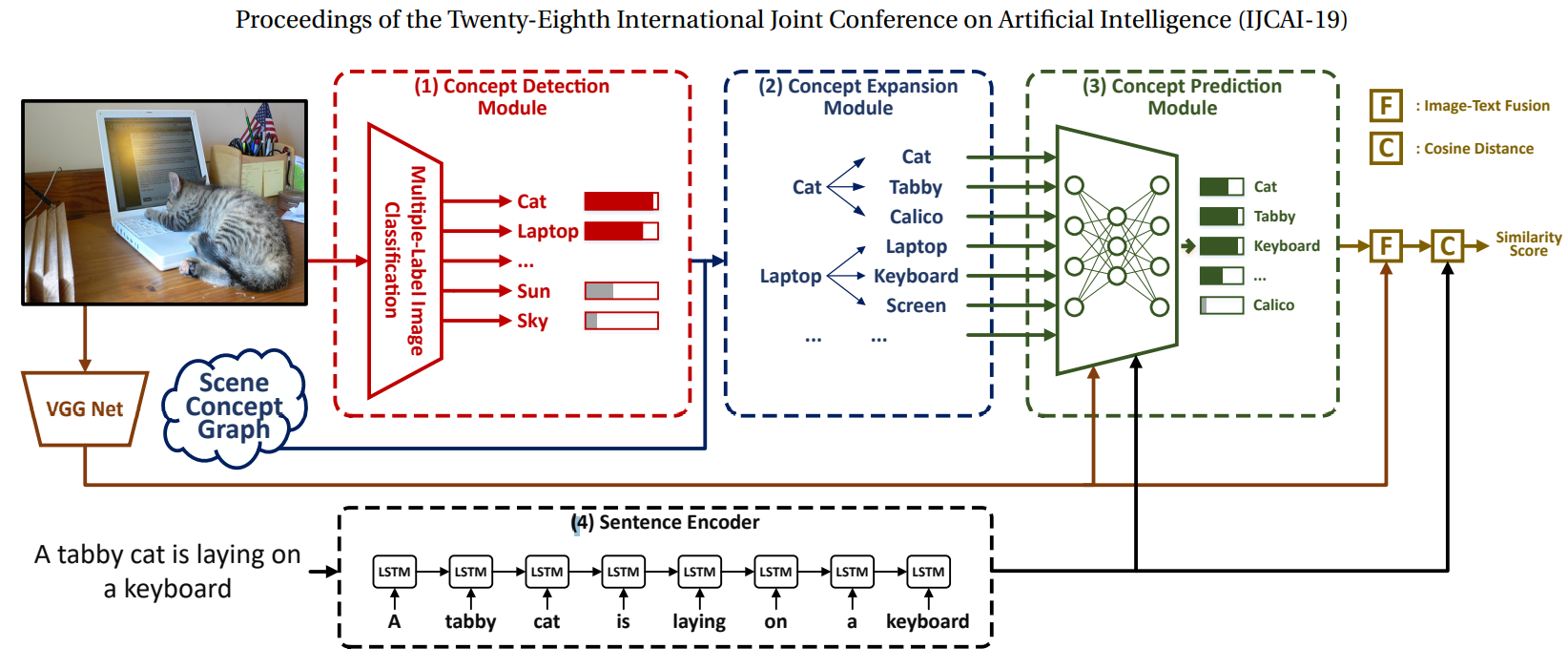
2.1 Text Feature Encoding
采用LSTM作为文本编码器以获取文本表示。
2.2 Visual Feature Module
使用VGG19网络,提取图像特征。最后得到4096维向量。
2.3 Concept Detection Module
我们使用多标签图像分类模型检测一个概念是否出现在图像中。
2.4 Concept Expansion Module
目的:缩小图像与文本的语义gap
输出:
向量第i维用0或者1表示这个concept不出现或出现在图像中。
2.5 Concept Prediction Module
目的:但是concept vocabulary太大使模型的表现力大大下降,所以我们希望发现尽可能地多词,但不会降低模块准确率。所以,引入了Scene Concept Graph,根据图像和描述,扩展更频繁的concept。
- Scene Concept Graph构建
![]()
- 根据构建的Scene Concept Graph扩展concept
![]()
- 算法描述
![]()
输出:![]()
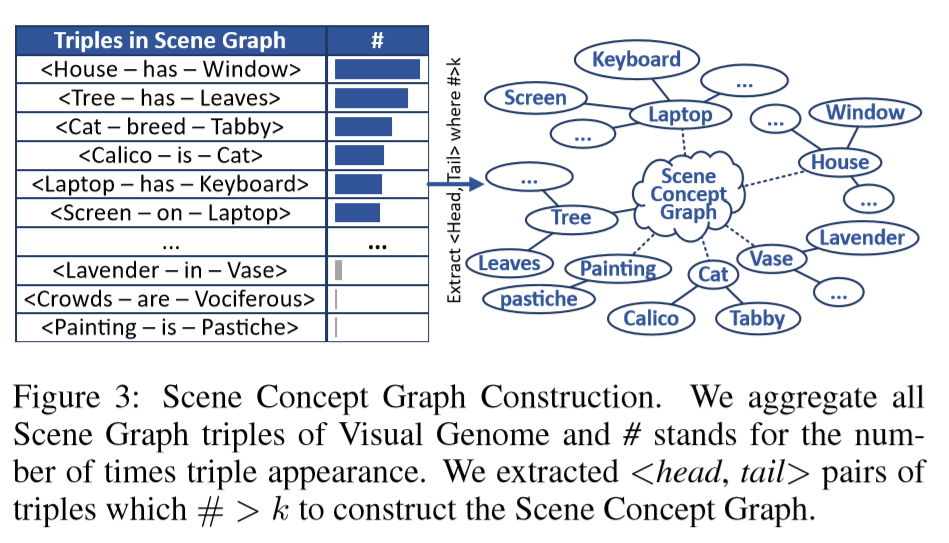
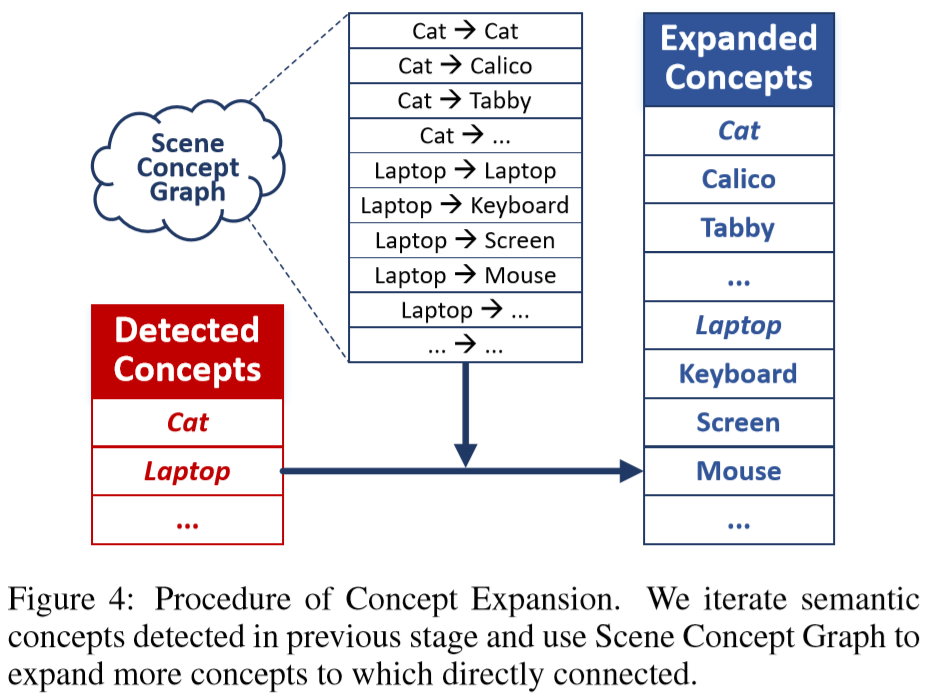

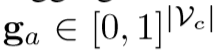
2.6 Image-Concept Fusion Module
目的:尽管我们可以通过SCG扩展许多未检测到的语义概念,但是很明显,一些与图像无关的嘈杂概念也会被扩展,从而导致性能更差。因此,我们提出了一种机制来选择性地学习和预测概念是否与图像相关。
输入:the whole-image encoding fi、the detected concept vector gd、the expanded concept vector ga
输出:the relevant concept vector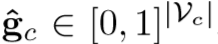
- 整合expanded concept vector ga和whole-image encoding fi
![]()
ELU--Exponential Linear Units - 预测结果
![]()
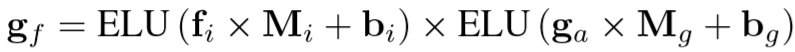
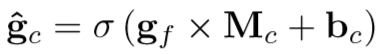
2.7 Image-Concept Fusion Module
输入:the predicted concept vector gˆc 、whole-image encoding fi
输出: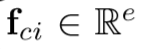
文中提供了两种融合方式
- element-wise product
- 线性映射到同一个embedding space
- 通过L2归一化将这两个映射的嵌入归一化
- element-wise product
- gated fusion
![]()
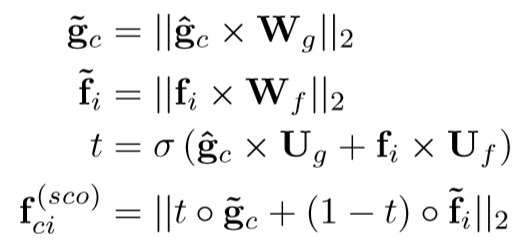
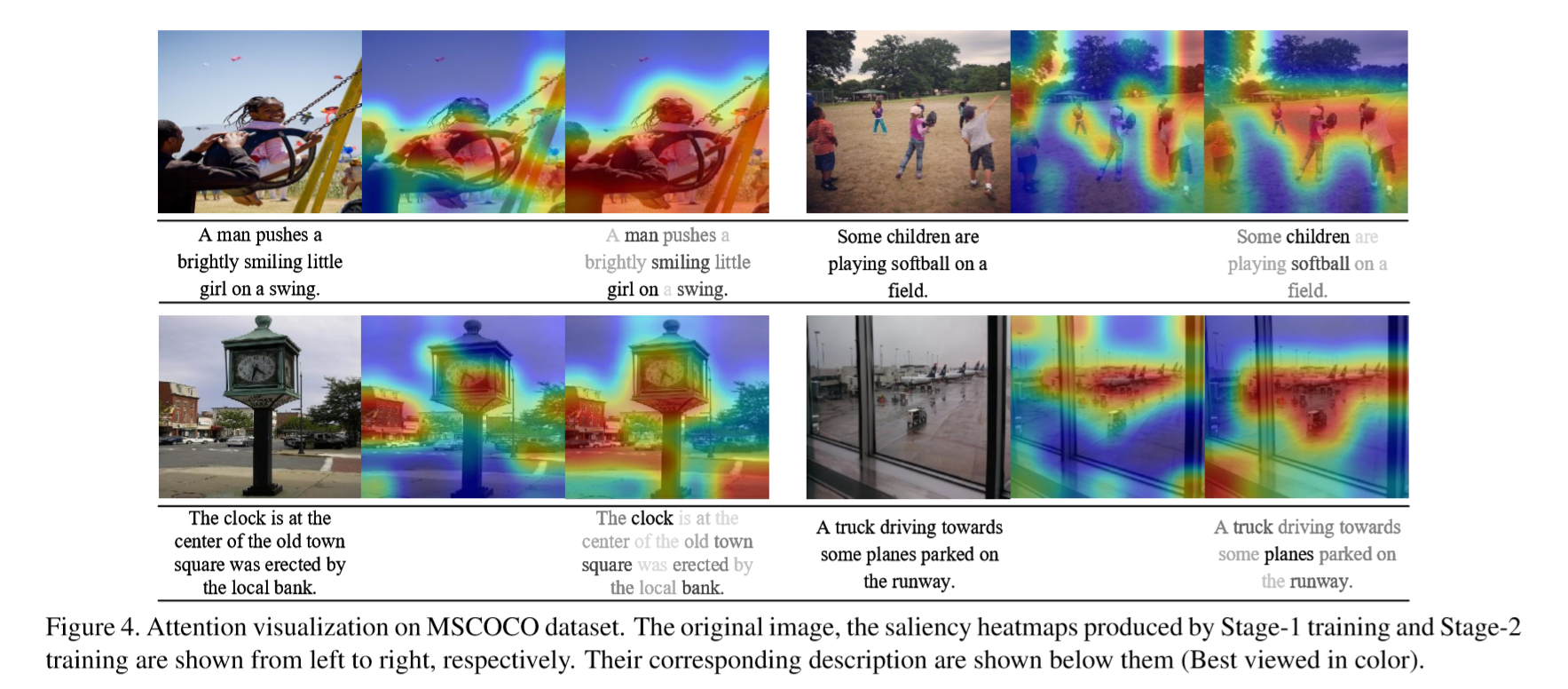
Saliency-GuidedAttentionNetworkforImage-SentenceMatching
1 摘要
研究的问题:图像与句子的匹配
解决的问题:与以前的方法主要采用对称架构来代表两种方式不同,本文采用不对称链接。
解决方式:Saliency-guided Attention Network (SAN)--在视觉和语言之间建立不对称链接,从而有效地学习细粒度的跨模态相关性。
2 the proposed SAN model
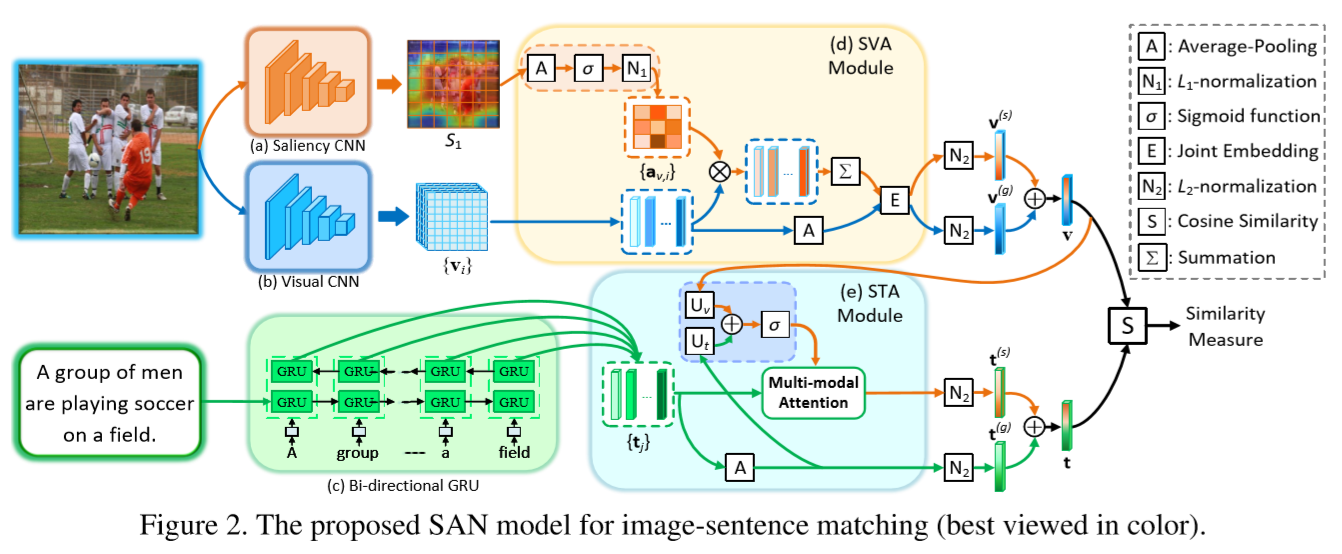
2.1 Input Representation
2.1.1 Visual Representation
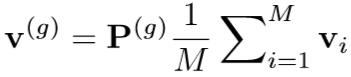
vi是图像I第i个区域的特征,一共有M个。上式是把图像的M个特征整合成一个全局特征Vg。
矩阵Pg表示附加的全连接层,它旨在将视觉特征嵌入到与文本特征兼容的k维联合空间中。
2.1.2 Textual Representation
- 把一句话分成L个words,用one-hot向量表示每个word
![]()
- 把word嵌入到embedding space
![]()
- 然后,我们在不同的时间步长将它们依次馈入双向GRU
![]()
- 取每个时间步向前隐藏状态和向后隐藏状态的平均值
![]()
- 对于整个sentence得到一个全局特征
![]()
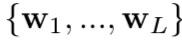
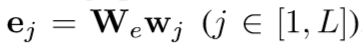
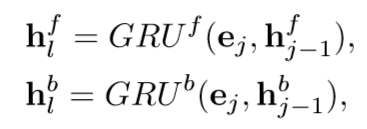
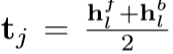
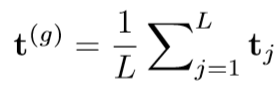
2.2 Saliency-weightedVisualAttention(SVA)
2.2.1 The Residual Refinement Saliency Network(RRSNet)
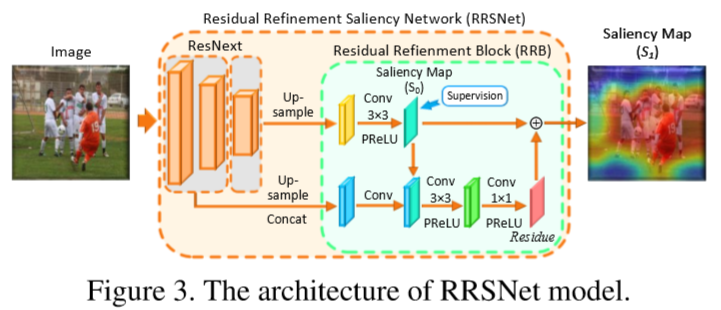
目的:之前用于视觉显着性检测的网络关注精确性,而忽视网络的体积,所以导致这些方法的网络体积比较大。本文提出了一个轻量级的网络RRSNet。
- ResNeXt-50作为backbone network,输出一组不同比例的特征图
- 首先对第二个卷积层的特征图进行上采样,以使其大小与第一层的特征图相同。 然后,我们将它们串联起来并应用卷积运算以减小冗余通道的尺寸,从而产生一个低层的集成特征。
![]()
gc(·)是一种特征融合网络,它通过卷积运算和PReLU激活函数集成了低级特征。
![]()
- the Residual Refinement Block(RRB)
RRB的原则是利用低层特征和高层特征来学习中间显着性预测和ground truth之间的残差。
![]()
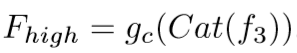
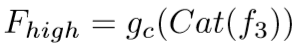

2.2.2 Saliency-weighted Visual Attention Module
目的:利用显着性信息作为指导进行visual attention
- 首先使用平均池化操作对显着性图S1至S2进行下采样,以使其与视觉特征图V∈RX×Y×d的大小对齐
- 归一化S2得到
![]()
![]()
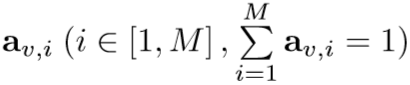
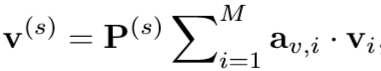
2.3 Saliency-guidedTextualAttention(STA)
- 将全局视觉特征v(g)和SVA向量v(s)合并为具有平均池的集成视觉特征v
![]()
![]()
![]()
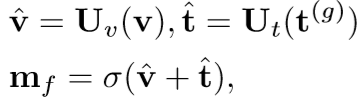
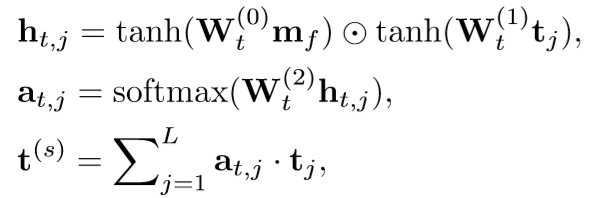
Deep Cross-Modal Projection Learning for Image-Text Matching
1 摘要
解决的问题:尽管将deep cross-modal embeddings与bi-directional ranking loss相关联取得了巨大的进步,但是开发用于挖掘有用的三元组和选择适当的margin的策略在实际应用中仍然是一个挑战。
解决方式:a cross-modal projection matching (CMPM) loss and a cross-modal projection classification (CMPC) loss----learning discriminative image-text embeddings
CMPM最大程度地减少了投影相容性分布与微型批次中所有正负样本定义的归一化匹配分布之间的KL差异。
CMPC尝试使用改进的norm-softmax损失将表示形式的矢量投影从一种模态分类到另一种模态,以进一步增强每个类别的特征紧凑性。
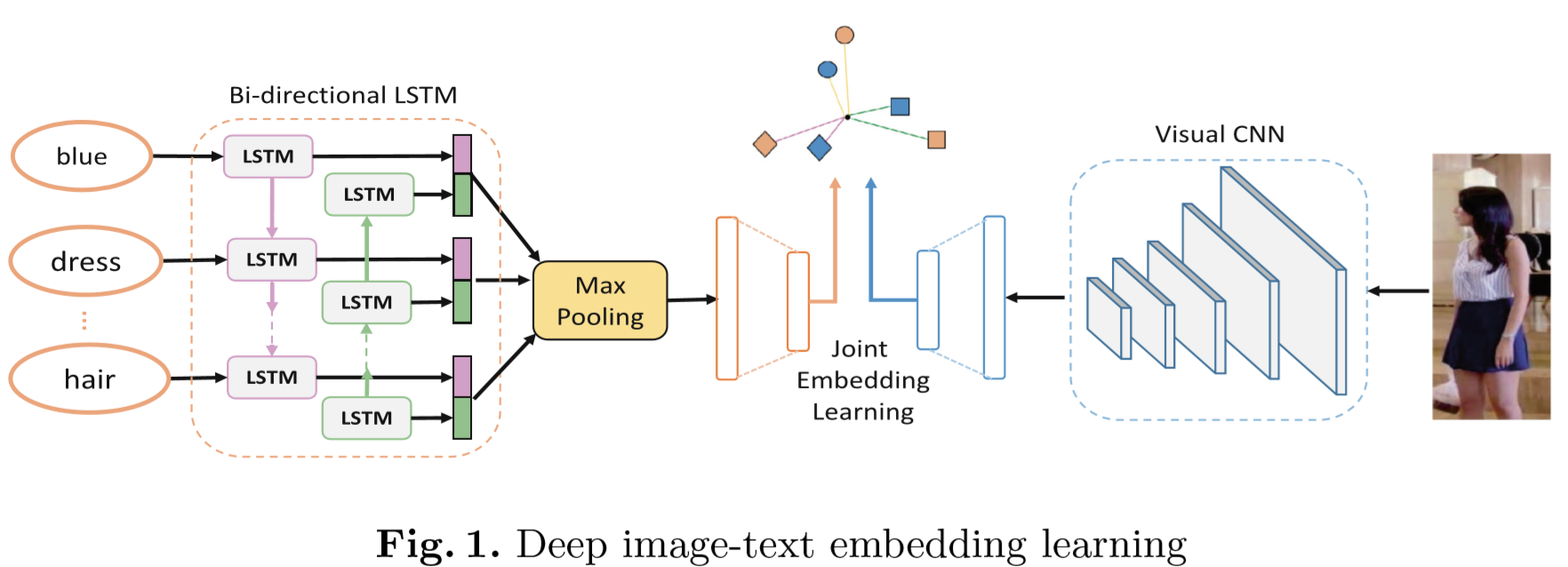
2 Deep Image-Text Matching
- joint embedding learning
- pairwise similarity learning
3 The Proposed Algorithm
3.1 Cross-Modal Projection Matching
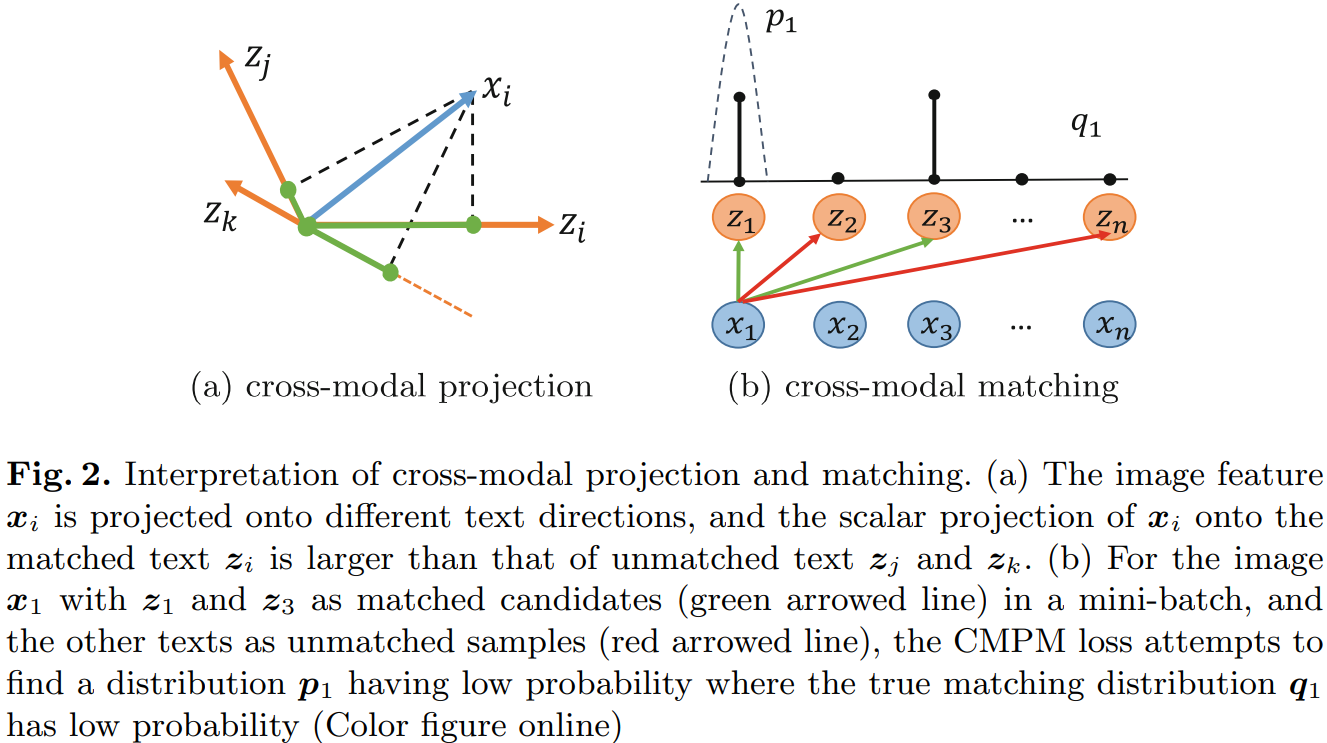
方法:incorporates the cross-modal projection into KL divergence to associate the representations across different modalities
输入: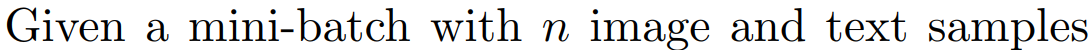
![]()
![]() 意味着图片与文本匹配
意味着图片与文本匹配
![]() 意味着图片与文本不匹配
意味着图片与文本不匹配![]()
![]()
这一步的操作是考虑到可能一张图片匹配到多个多个文本,所以定义了一个 true matching probability。![]()
![]()
![]()
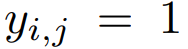 意味着图片与文本匹配
意味着图片与文本匹配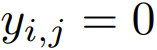 意味着图片与文本不匹配
意味着图片与文本不匹配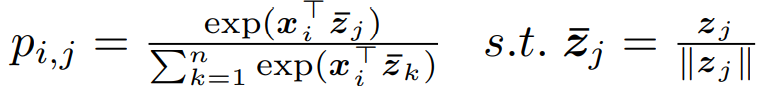

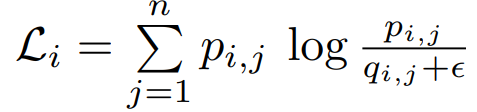
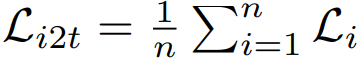
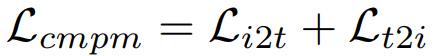
3.2 Cross-Modal Projection Classification
输入:image feature
text feature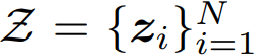
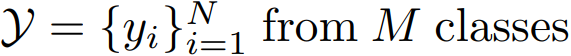
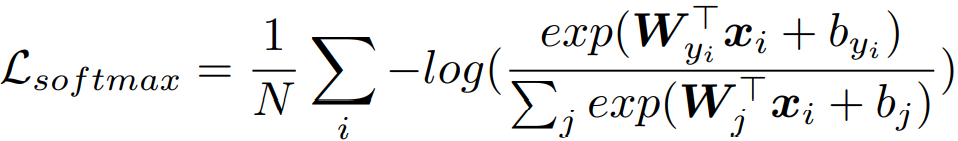
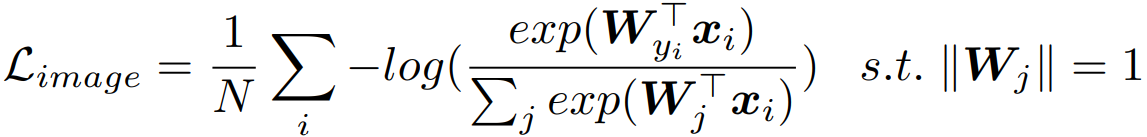
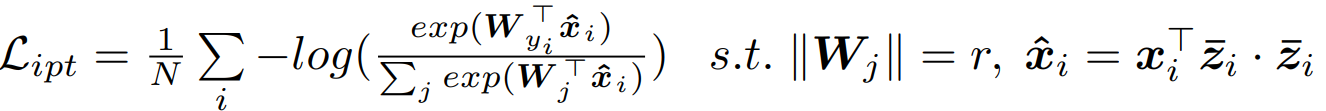
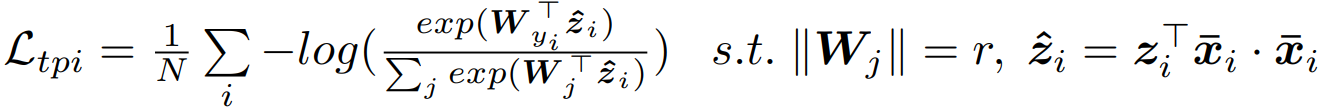
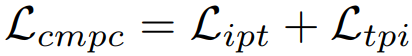
3.3 Objective Functions
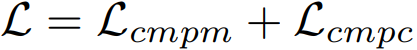

 浙公网安备 33010602011771号
浙公网安备 33010602011771号