JuiceFS 在大搜车数据平台的实践
大搜车已经搭建起比较完整的汽车产业互联网协同生态。在这一生态中,不仅涵盖了大搜车已经数字化的全国 90% 中大型二手车商、9000+ 家 4S 店和 70000+ 家新车二网,还包括大搜车旗下车易拍、车行168、运车管家、布雷克索等具备较强产业链服务能力的公司, 与大搜车在新零售解决方案上达成深度战略合作的长城汽车、长安汽车、英菲尼迪等主机厂商,以及与中石油昆仑好客等产业链上下游的合作伙伴。基于这样的生态布局,大搜车数字化了汽车流通链条上的每个环节,进而为整个行业赋能。
说到大数据,对于每个公司都不陌生。存储组件 HDFS,计算资源管理 YARN,离线计算 Hive、Spark、Spark SQL,列存储数据库 HBase,实时计算Spark Streaming、Flink等。这些组件在集群稳定情况下维护还算比较轻松,但是在公司快速发展过程中,集群容量的高速增长是不可避免的,作为大数据的设计者不得不从集群的成本和效益上思考两者的权衡。
大数据集群现状
大搜车目前大数据集群分为离线计算集群和实时计算集群,离线计算基于 Hive 和 Spark,实时计算基于 Flink,这两类集群分别基于 HDP 和 CDH 两套管理方式。早期离线计算选用了 HDP,实时计算后来选用 CDH 的初衷是多集群管理比较方便。由于离线计算引擎两者是有区别的,迁移会有兼容性问题,两套集群一直并存,集群间资源完全隔离。
集群维护痛点
数据量持续增长,成本一定的情况下做集群扩容耗时耗力
从 18 年初到 19 年 6 月份,离线集群从最初的数十个节点持续增长到上百个节点,数据量也从数十 TiB 增长了 10 多倍,并且保持每天数 TiB 的速度增加。在节省开支的情况下,每月做一次集群扩容,形成了与数据增长速度赛跑的情况。每月固定工作差不多变成了接受磁盘告警狂炸、扩容、均衡数据、再均衡数据的情况。遇到一些极端情况,比如阿里云在某个可用区没有数据类型设备资源而要新在另一个可用区创建,还会涉及到数据网段变更,就更复杂了。
- 存储所需资源跟计算资源不同步
在对离线集群数据做分析过程中发现,热点数据仅占大约 20%。在集群不断扩容的情况下,计算资源会有较大冗余,产生了不必要的成本,另外每次均衡会占用节点网络带宽,影响任务读写数据的速度。
- 跨集群数据同步
为了减少了实时任务和离线任务的相互影响,方便资源控制和云资源选型价值最大化,实时计算和离线计算集群在物理上做了资源隔离,难点也随之出现,实时和离线集群的数据无法实时同步,造成一些需求无法实现。
- NameNode内存持续增长,重启时间过久
在文件存储中,文件数量过多导致 NameNode 管理内存持续增加,重启一次时间过长,势必影响数据同步;并且在数仓层面不严加控制数据生命周期,资源占用也会越来越大,在对集群中整个资源做分析时也会受到影响。
选择 JuiceFS
针对以上这些问题,选取一款产品做底层存储势在必行。存储选择上作为大数据的基石,需要遵从如下特点:
- 兼容Hadoop框架协议
- 多版本集群兼容
- 高吞吐、低延时
- 支持深度压缩减少资源使用
在一开始,我们尝试使用阿里云的 OSS 作为冷备存储。在测试过程中,由于没有元信息管理,在数据维护上很受限制。后来接触到了 JuiceFS 这款产品,在选择上很是满足上述要求。对此我们做了一些性能测试(均基于实际场景提取业务逻辑)。
实际场景性能测试
以下测试均选取实际业务数据,数据大小是 where 查询条件不同选取的,仅做两个文件系统性能对比:
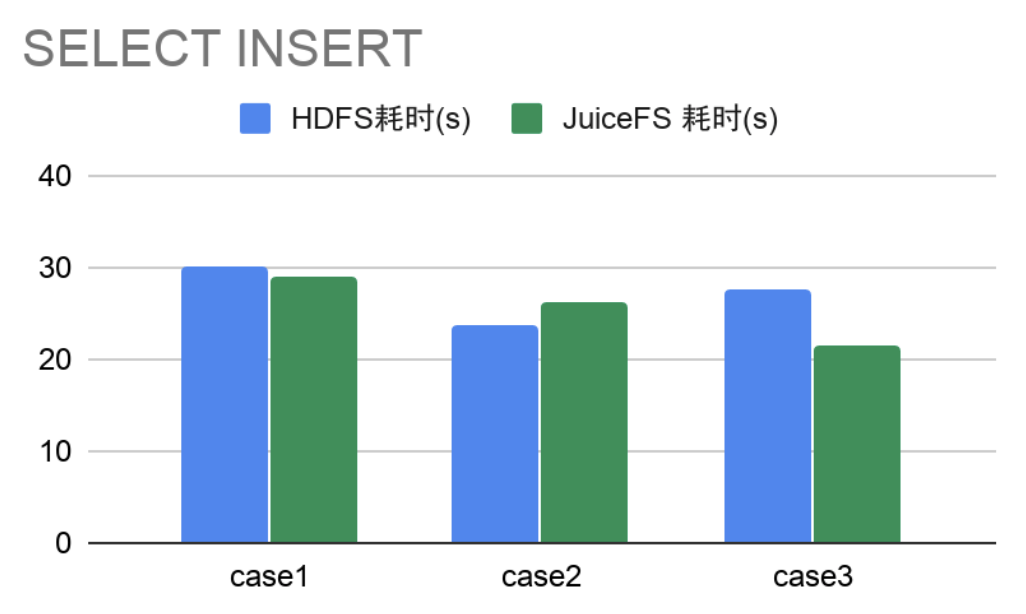
- SELECT + INSERT 操作
从 3000 万左右表中分别选取不同量级数据插入另一张表结构一样的表中,横向对比 HDFS 和 JuiceFS 耗时。
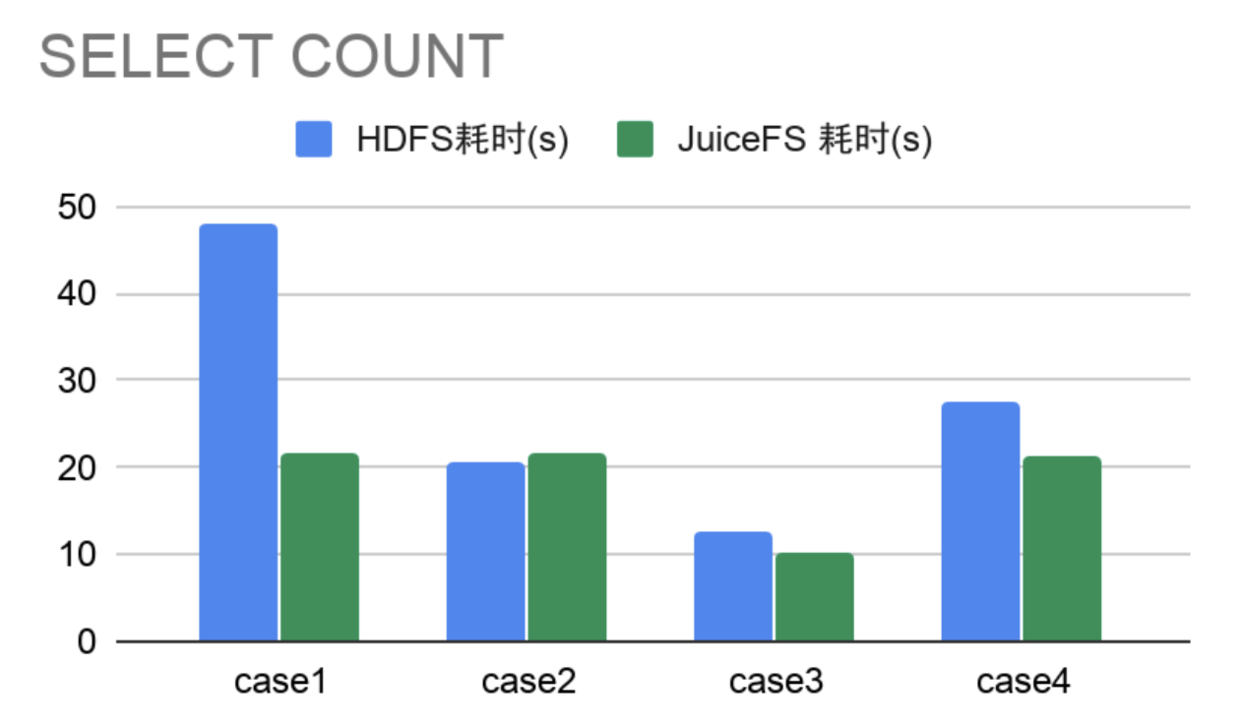
- SELECT + COUNT 操作
从3000万左右表中分别选取不同量级数据做 COUNT,横向对比 HDFS 和 JuiceFS 耗时。
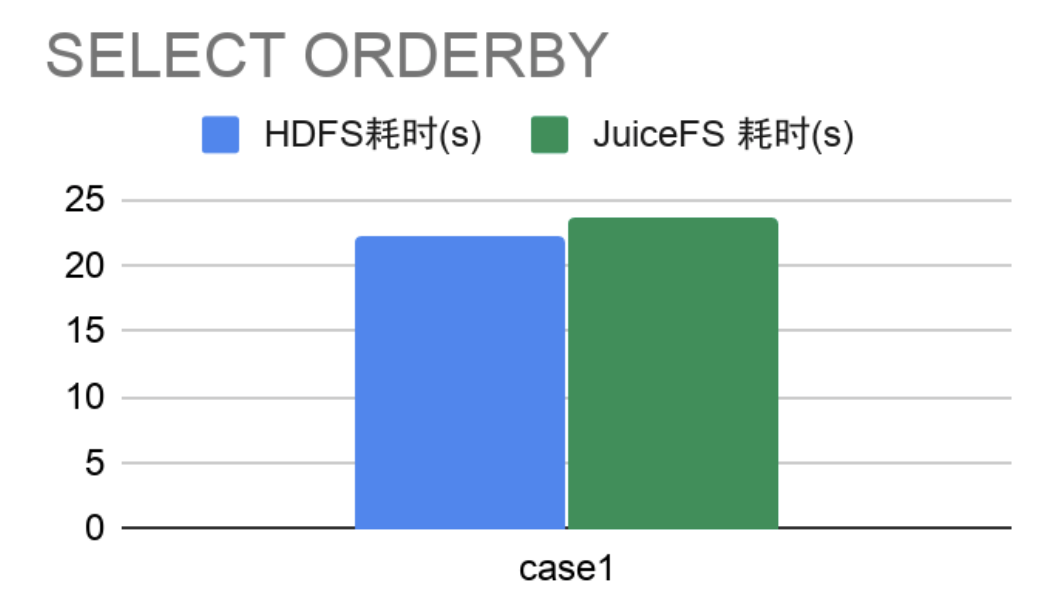
- SELECT + ORDERBY
对 3000 万左右表中数据做排序,横向比较 HDFS 和 JuiceFS 的耗时。
综上,JuiceFS 在查询、插入数据时多数耗时比较稳定且整体比HDFS耗时要少,在 SELECT 数据情况,多数性能相差不多极个别情况要优于 HDFS,单行做排序操作性能差不多。
成本控制
我们对比了采用 JuiceFS 和 HDFS 两种方案的费用(HDFS 集群保证存储冗余 20%)。在同等数据量(JuiceFS 会再次做深度压缩,压缩比大约为 3:1)和对等计算资源的情况下采用 JuiceFS 每月会比使用云主机部署 HDFS 节省至少 18%。
综合看 JuiceFS 的性能和成本都非常满足公司对成本和产品性能的要求。
未来展望
存储计算分离
大数据集群引入 JuiceFS,存储和计算实际上已经分离。大数据集群灵活弹性扩展计算资源已经成为可能,在凌晨业务低谷期可以将业务机器的计算资源调度给大数据集群。
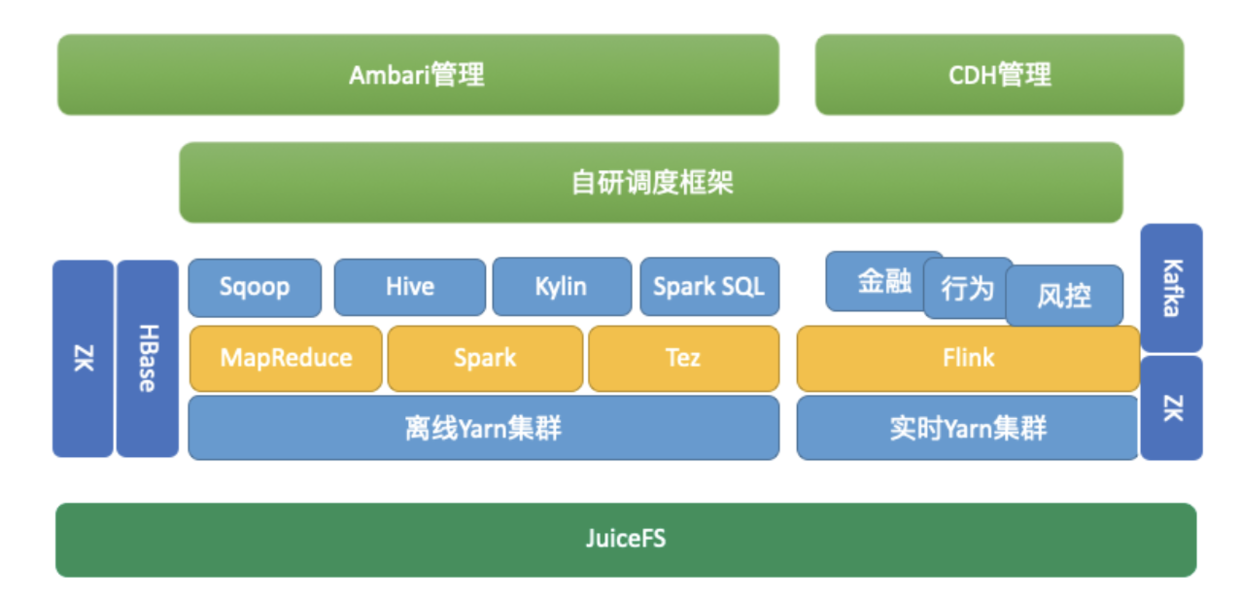
以下是目前整个大数据集群架构:
后续可以结合计算存储分离和动态伸缩设计为如下目标架构:
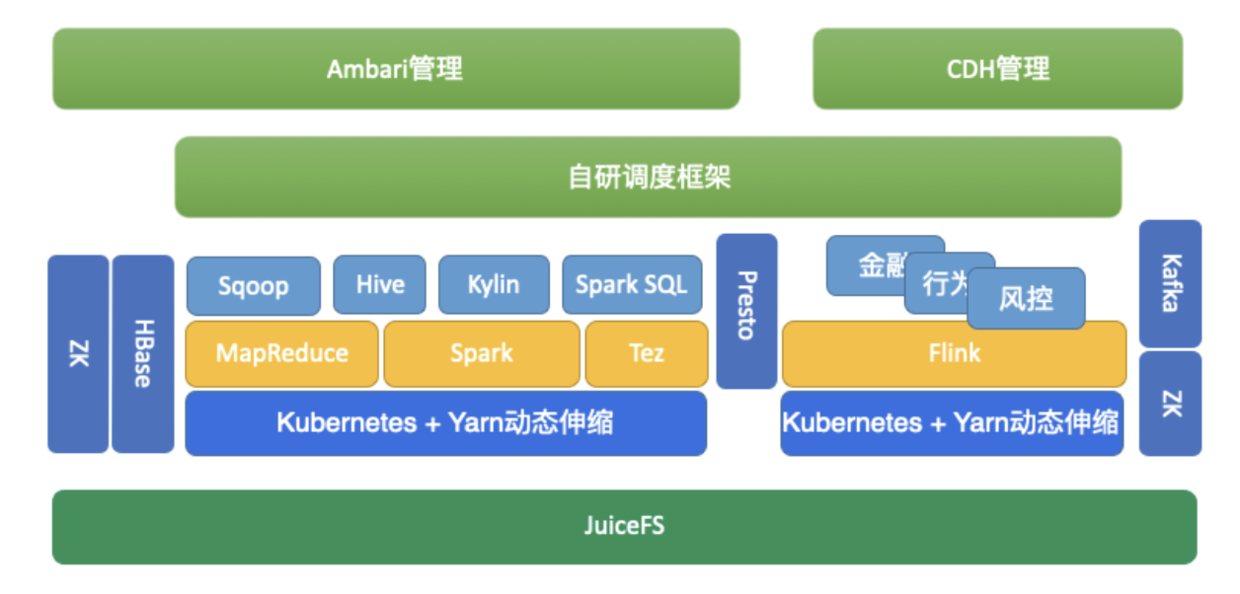
与 Kubernetes 做结合,按需申请资源,节省成本和减少维护成本。
推荐阅读:
JuiceFS CSI Driver 的最佳实践
项目地址: Github (https://github.com/juicedata/juicefs)如有帮助的话欢迎关注我们哟! (0ᴗ0✿)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号