windows下大数据开发环境搭建(5)——Hive环境搭建
本文介绍如何在windows下搭建Hive开发环境,主要依赖的环境是Java和Hadoop,其他大部分工作主要是动手配置的工作,按照下面的介绍一步步操作即可完成搭建。
一、所需环境
1、Java:windows下大数据开发环境搭建(1)——Java环境搭建
2、Hadoop:windows下大数据开发环境搭建(2)——Hadoop环境搭建
二、Hive及相关组件下载
(一)Hive二进制包下载
Apache Hive官方下载页面:http://hive.apache.org/downloads.html
笔者下载的是2.3.7版本,适配于Hadoop 2.7.7
如果觉得官网的下载速度慢,也可以通过国内的镜像下载。如:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
(二)Hive 1.x 源码下载
除了下载Hive 2.3.7的apache-hive-2.3.7-bin.tar.gz包,还需要下载Apache Hive 1.2.2 src,主要是只有1.x版本的Hive源码提供了.cmd启动脚本,建议直接取该1.x版本的src包来使用即可。
Apache Hive 1.2.2 src下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/
(三)mysql-connector jar包下载
connector-java官方下载地址:https://dev.mysql.com/downloads/connector/j/
(四)解压并做相关准备
1、下载了以上.tar.gz包后,将其解压到合适的位置,笔者新建了个hive文件夹统一管理上述压缩包。
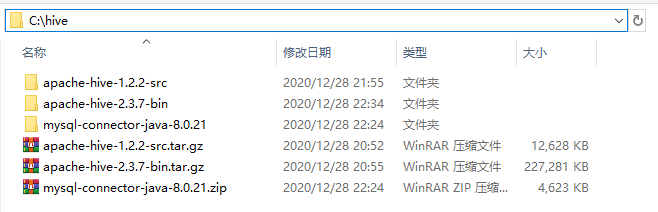
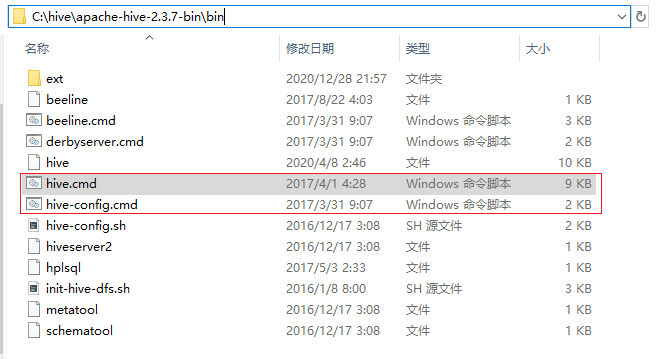
2、把源码包apache-hive-1.2.2-src.tar.gz解压后的bin目录下的文件拷贝到apache-hive-2.3.7-bin的bin目录中,如果遇到文件冲突(已存在的文件),则选择忽略并跳过,不要选择覆盖!不要选择覆盖!不要选择覆盖!
apache-hive-2.3.7-bin的bin目录主要还是新增了.cmd启动脚本:
三、配置Hive
(一)在HDFS上创建相关文件夹
Hive是构筑于HDFS上的,所以务必确保Hadoop已经启动。Hive在HDFS中默认的文件路径前缀是/user/hive/warehouse,因此可以先通过命令行在HDFS中创建此文件夹:
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod -R 777 /user/hive/warehouse
同时需要通过下面的命令创建并为tmp目录赋予权限:
hadoop fs -mkdir /tmp
hadoop fs -chmod -R 777 /tmp
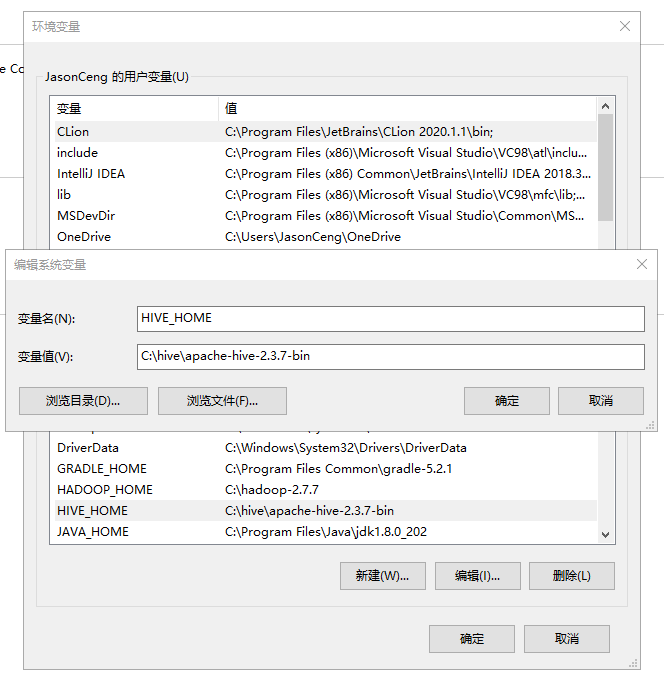
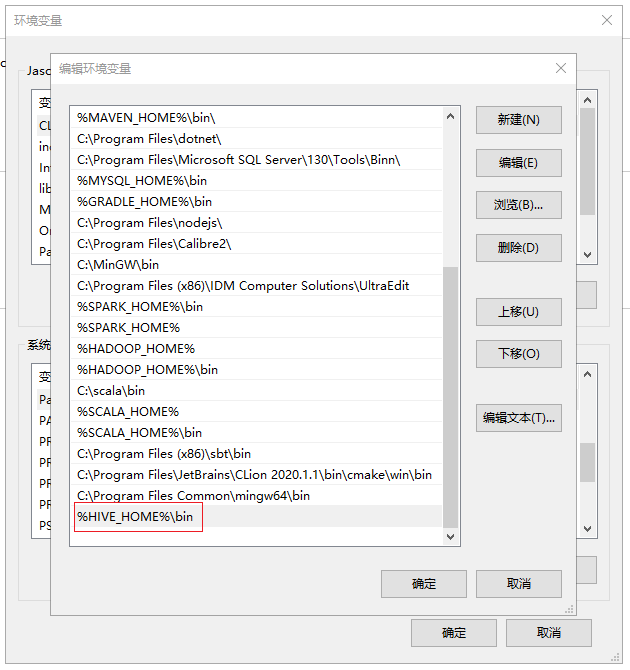
(二)配置环境变量
在系统变量中添加HIVE_HOME,具体的值配置为C:\hive\apache-hive-2.3.7-bin,同时在Path变量添加%HIVE_HOME%\bin
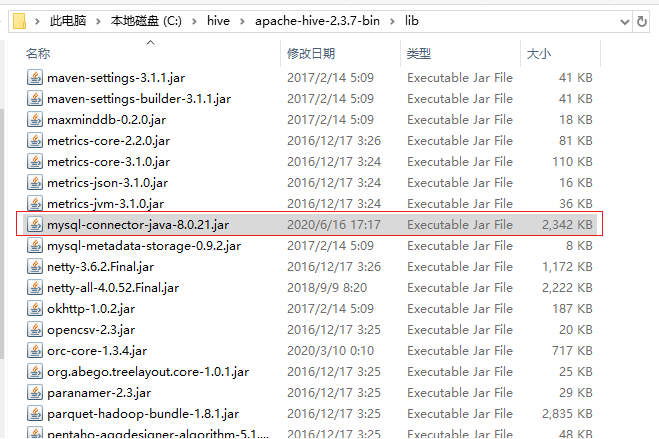
(三)添加mysql-connector到/lib目录
将之前下载的mysql-connector解压出来后,拷贝mysql-connector-java-8.0.21.jar到$HIVE_HOME/lib目录下:
(四)修改Hive配置文件
创建Hive的配置文件,在$HIVE_HOME/conf目录下已经有对应的配置文件模板,需要拷贝和重命名,具体如下:
$HIVE_HOME/conf/hive-default.xml.template => $HIVE_HOME/conf/hive-site.xml$HIVE_HOME/conf/hive-env.sh.template => $HIVE_HOME/conf/hive-env.sh$HIVE_HOME/conf/hive-exec-log4j2.properties.template => $HIVE_HOME/conf/hive-exec-log4j2.properties$HIVE_HOME/conf/hive-log4j2.properties.template => $HIVE_HOME/conf/hive-log4j2.properties
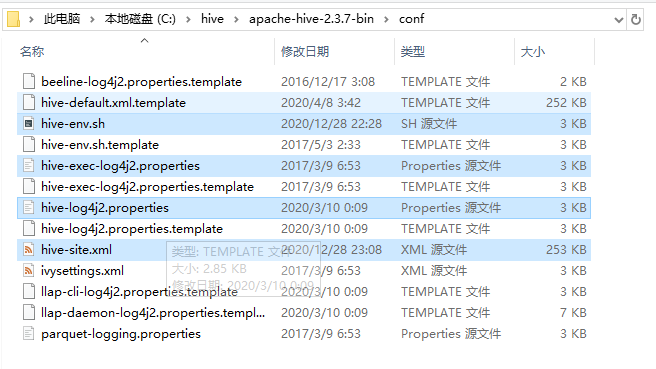
1、修改hive-env.sh脚本,在尾部添加下面内容:
export HADOOP_HOME=C:\hadoop-2.7.7
export HIVE_CONF_DIR=C:\hive\apache-hive-2.3.7-bin\conf
export HIVE_AUX_JARS_PATH=C:\hive\apache-hive-2.3.7-bin\lib
2、修改hive-site.xml文件,主要修改下面的属性项:
| 属性名 | 属性值 | 备注 |
|---|---|---|
| hive.metastore.warehouse.dir | /user/hive/warehouse | Hive的数据存储目录,这个是默认值 |
| hive.exec.scratchdir | /tmp/hive | Hive的临时数据目录,这个是默认值 |
| javax.jdo.option.ConnectionURL | jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&serverTimezone=UTC | Hive元数据存放的数据库连接 |
| javax.jdo.option.ConnectionDriverName | com.mysql.cj.jdbc.Driver | Hive元数据存放的数据库驱动 |
| javax.jdo.option.ConnectionUserName | root | Hive元数据存放的数据库用户 |
| javax.jdo.option.ConnectionPassword | root | Hive元数据存放的数据库密码 |
| hive.exec.local.scratchdir | C:/hive/apache-hive-2.3.7-bin/data/scratchDir | 创建本地目录$HIVE_HOME/data/scratchDir |
| hive.downloaded.resources.dir | C:/hive/apache-hive-2.3.7-bin/data/resourcesDir | 创建本地目录$HIVE_HOME/data/resourcesDir |
| hive.querylog.location | C:/hive/apache-hive-2.3.7-bin/data/querylogDir | 创建本地目录$HIVE_HOME/data/querylogDir |
| hive.server2.logging.operation.log.location | C:/hive/apache-hive-2.3.7-bin/data/operationDir | 创建本地目录$HIVE_HOME/data/operationDir |
| datanucleus.autoCreateSchema | true | 可选 |
| datanucleus.autoCreateTables | true | 可选 |
| datanucleus.autoCreateColumns | true | 可选 |
| hive.metastore.schema.verification | false | 可选 |
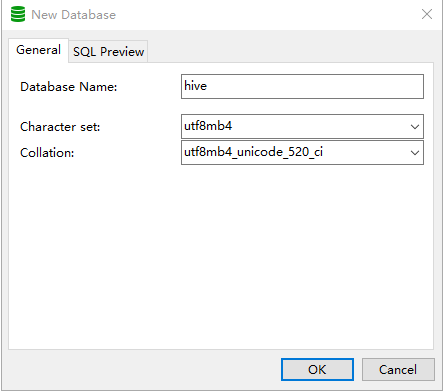
(五)使用MySQL配置Hive元数据库
修改完毕之后,在本地的MySQL服务新建一个数据库hive,编码和字符集可以选用范围比较大的utf8mb4(虽然官方建议是latin1,但是字符集往大范围选没有影响):
(六)Hive元数据库初始化
上面的准备工作做完之后,可以进行Hive的元数据库初始化,在$HIVE_HOME/bin目录下执行下面的脚本:
hive.cmd --service schematool -dbType mysql -initSchema
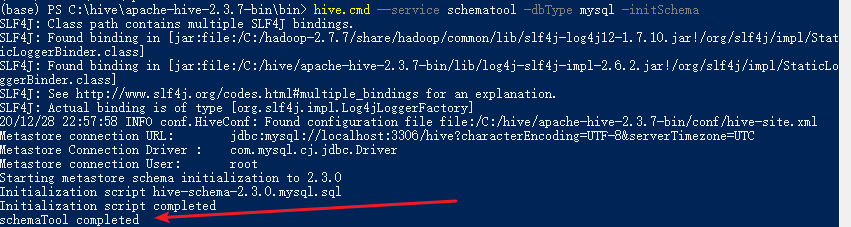
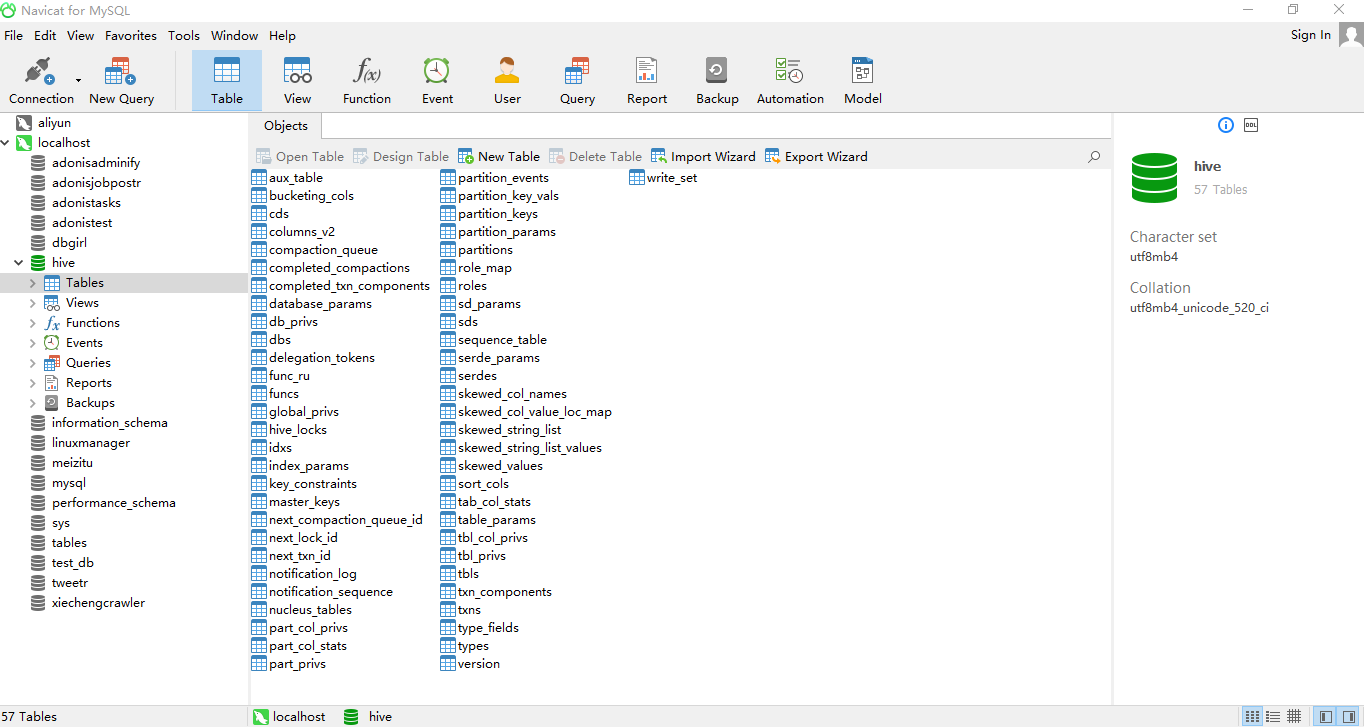
当控制台输出Initialization script completed schemaTool completed的时候,说明元数据库已经初始化完毕:
四、启动Hive并测试
在$HIVE_HOME/bin目录下,通过hive.cmd可以连接Hive(关闭控制台即可退出):
> hive.cmd
尝试创建一个表t_test:
hive> create table t_test(id INT,name string);
hive> show tables;
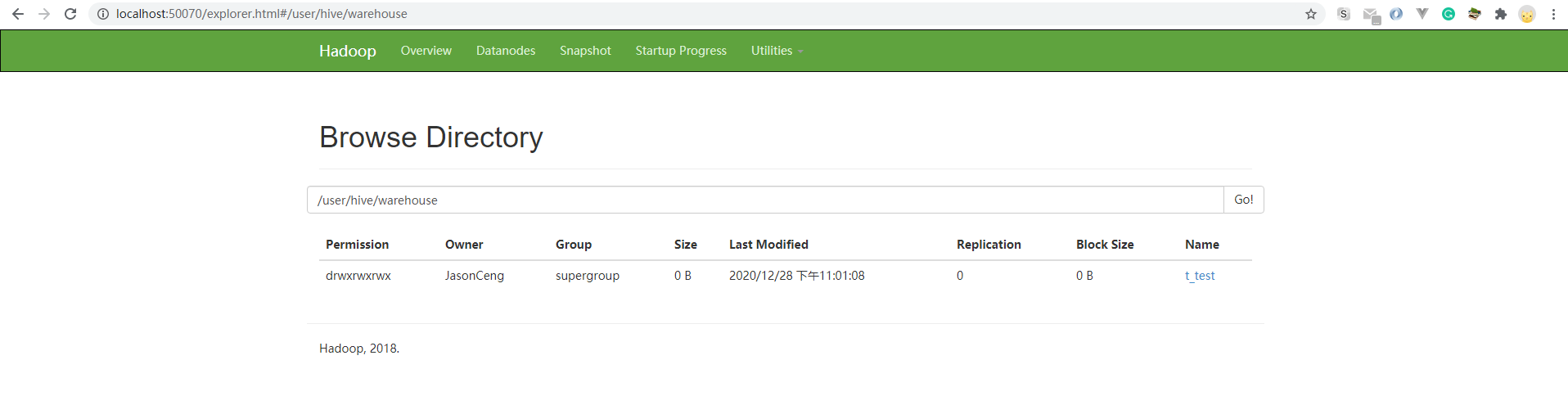
查看http://localhost:50070/确认t_test表已经创建成功。
尝试执行一个写入语句和查询语句:
hive> insert into t_test(id,name) values(1,'throwx');
insert语句完整的执行log如下:
hive> insert into t_test(id,name) values(1,'throwx');
20/12/28 23:03:05 INFO conf.HiveConf: Using the default value passed in for log id: a92d44b2-e635-4635-845a-4c553d9e14af
20/12/28 23:03:05 INFO session.SessionState: Updating thread name to a92d44b2-e635-4635-845a-4c553d9e14af main
20/12/28 23:03:05 INFO ql.Driver: Compiling command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192): insert into t_test(id,name) values(1,'throwx')
20/12/28 23:03:05 INFO parse.CalcitePlanner: Starting Semantic Analysis
20/12/28 23:03:05 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:05 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:06 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
20/12/28 23:03:08 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:08 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:08 INFO parse.CalcitePlanner: Completed phase 1 of Semantic Analysis
20/12/28 23:03:08 INFO parse.CalcitePlanner: Get metadata for source tables
20/12/28 23:03:08 INFO parse.CalcitePlanner: Get metadata for subqueries
20/12/28 23:03:08 INFO parse.CalcitePlanner: Get metadata for destination tables
20/12/28 23:03:08 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:08 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:08 INFO parse.CalcitePlanner: Completed getting MetaData in Semantic Analysis
20/12/28 23:03:13 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:13 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:13 INFO parse.CalcitePlanner: Get metadata for source tables
20/12/28 23:03:13 INFO parse.CalcitePlanner: Get metadata for subqueries
20/12/28 23:03:13 INFO parse.CalcitePlanner: Get metadata for destination tables
20/12/28 23:03:13 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:13 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:13 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://localhost:9000/user/hive/warehouse/t_test/.hive-staging_hive_2020-12-28_23-03-05_555_7157770556105354149-1
20/12/28 23:03:14 INFO parse.CalcitePlanner: CBO Succeeded; optimized logical plan.
20/12/28 23:03:14 INFO ppd.OpProcFactory: Processing for FS(3)
20/12/28 23:03:14 INFO ppd.OpProcFactory: Processing for SEL(2)
20/12/28 23:03:14 INFO ppd.OpProcFactory: Processing for SEL(1)
20/12/28 23:03:14 INFO ppd.OpProcFactory: Processing for TS(0)
20/12/28 23:03:15 INFO optimizer.GenMRFileSink1: using CombineHiveInputformat for the merge job
20/12/28 23:03:15 INFO metastore.HiveMetaStore: 0: get_table : db=default tbl=t_test
20/12/28 23:03:15 INFO HiveMetaStore.audit: ugi=JasonCeng ip=unknown-ip-addr cmd=get_table : db=default tbl=t_test
20/12/28 23:03:15 INFO parse.CalcitePlanner: Completed plan generation
20/12/28 23:03:15 INFO ql.Driver: Semantic Analysis Completed
20/12/28 23:03:15 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:string, comment:null)], properties:null)
20/12/28 23:03:15 INFO metadata.Hive: Dumping metastore api call timing information for : compilation phase
20/12/28 23:03:15 INFO metadata.Hive: Total time spent in this metastore function was greater than 1000ms : getTable_(String, String, )=1138
20/12/28 23:03:15 INFO ql.Driver: Completed compiling command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192); Time taken: 9.85 seconds
20/12/28 23:03:15 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager
20/12/28 23:03:15 INFO ql.Driver: Executing command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192): insert into t_test(id,name) values(1,'throwx')
20/12/28 23:03:15 WARN ql.Driver: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
20/12/28 23:03:15 INFO ql.Driver: WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192
20/12/28 23:03:15 INFO ql.Driver: Query ID = JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192
Total jobs = 3
20/12/28 23:03:15 INFO ql.Driver: Total jobs = 3
Launching Job 1 out of 3
20/12/28 23:03:15 INFO ql.Driver: Launching Job 1 out of 3
20/12/28 23:03:15 INFO ql.Driver: Starting task [Stage-1:MAPRED] in serial mode
Number of reduce tasks is set to 0 since there's no reduce operator
20/12/28 23:03:15 INFO exec.Task: Number of reduce tasks is set to 0 since there's no reduce operator
20/12/28 23:03:15 INFO ql.Context: New scratch dir is hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/hive_2020-12-28_23-03-05_555_7157770556105354149-1
20/12/28 23:03:15 INFO mr.ExecDriver: Using org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
20/12/28 23:03:15 INFO exec.Utilities: Processing alias values__tmp__table__1
20/12/28 23:03:15 INFO exec.Utilities: Adding 1 inputs; the first input is hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/_tmp_space.db/Values__Tmp__Table__1
20/12/28 23:03:15 INFO exec.Utilities: Content Summary not cached for hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/_tmp_space.db/Values__Tmp__Table__1
20/12/28 23:03:15 INFO ql.Context: New scratch dir is hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/hive_2020-12-28_23-03-05_555_7157770556105354149-1
20/12/28 23:03:16 INFO exec.SerializationUtilities: Serializing MapWork using kryo
20/12/28 23:03:16 INFO Configuration.deprecation: mapred.submit.replication is deprecated. Instead, use mapreduce.client.submit.file.replication
20/12/28 23:03:16 INFO exec.Utilities: Serialized plan (via FILE) - name: null size: 3.88KB
20/12/28 23:03:16 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/12/28 23:03:17 INFO fs.FSStatsPublisher: created : hdfs://localhost:9000/user/hive/warehouse/t_test/.hive-staging_hive_2020-12-28_23-03-05_555_7157770556105354149-1/-ext-10001
20/12/28 23:03:17 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/12/28 23:03:17 INFO exec.Utilities: PLAN PATH = hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/hive_2020-12-28_23-03-05_555_7157770556105354149-1/-mr-10004/04c35c58-8ec9-4660-b23f-74878370a308/map.xml
20/12/28 23:03:20 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
20/12/28 23:03:22 INFO exec.Utilities: PLAN PATH = hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/hive_2020-12-28_23-03-05_555_7157770556105354149-1/-mr-10004/04c35c58-8ec9-4660-b23f-74878370a308/map.xml
20/12/28 23:03:22 INFO io.CombineHiveInputFormat: Total number of paths: 1, launching 1 threads to check non-combinable ones.
20/12/28 23:03:22 INFO io.CombineHiveInputFormat: CombineHiveInputSplit creating pool for hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/_tmp_space.db/Values__Tmp__Table__1; using filter path hdfs://localhost:9000/tmp/hive/JasonCeng/a92d44b2-e635-4635-845a-4c553d9e14af/_tmp_space.db/Values__Tmp__Table__1
20/12/28 23:03:22 INFO input.FileInputFormat: Total input paths to process : 1
20/12/28 23:03:22 INFO input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0
20/12/28 23:03:22 INFO io.CombineHiveInputFormat: number of splits 1
20/12/28 23:03:22 INFO io.CombineHiveInputFormat: Number of all splits 1
20/12/28 23:03:22 INFO mapreduce.JobSubmitter: number of splits:1
20/12/28 23:03:23 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1609162325951_0001
20/12/28 23:03:25 INFO impl.YarnClientImpl: Submitted application application_1609162325951_0001
20/12/28 23:03:25 INFO mapreduce.Job: The url to track the job: http://DESKTOP-E3N1FUJ:8088/proxy/application_1609162325951_0001/
Starting Job = job_1609162325951_0001, Tracking URL = http://DESKTOP-E3N1FUJ:8088/proxy/application_1609162325951_0001/
20/12/28 23:03:25 INFO exec.Task: Starting Job = job_1609162325951_0001, Tracking URL = http://DESKTOP-E3N1FUJ:8088/proxy/application_1609162325951_0001/
Kill Command = C:\hadoop-2.7.7\bin\hadoop job -kill job_1609162325951_0001
20/12/28 23:03:25 INFO exec.Task: Kill Command = C:\hadoop-2.7.7\bin\hadoop job -kill job_1609162325951_0001
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
20/12/28 23:03:44 INFO exec.Task: Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
20/12/28 23:03:44 WARN mapreduce.Counters: Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
2020-12-28 23:03:44,476 Stage-1 map = 0%, reduce = 0%
20/12/28 23:03:44 INFO exec.Task: 2020-12-28 23:03:44,476 Stage-1 map = 0%, reduce = 0%
20/12/28 23:03:44 WARN mapreduce.Counters: Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
Ended Job = job_1609162325951_0001 with errors
20/12/28 23:03:44 ERROR exec.Task: Ended Job = job_1609162325951_0001 with errors
Error during job, obtaining debugging information...
20/12/28 23:03:44 ERROR exec.Task: Error during job, obtaining debugging information...
20/12/28 23:03:44 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
20/12/28 23:03:44 INFO impl.YarnClientImpl: Killed application application_1609162325951_0001
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
20/12/28 23:03:44 ERROR ql.Driver: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
20/12/28 23:03:44 INFO ql.Driver: MapReduce Jobs Launched:
20/12/28 23:03:44 WARN mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
20/12/28 23:03:44 INFO ql.Driver: Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
20/12/28 23:03:44 INFO ql.Driver: Total MapReduce CPU Time Spent: 0 msec
20/12/28 23:03:44 INFO ql.Driver: Completed executing command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192); Time taken: 29.351 seconds
20/12/28 23:03:44 INFO conf.HiveConf: Using the default value passed in for log id: a92d44b2-e635-4635-845a-4c553d9e14af
20/12/28 23:03:44 INFO session.SessionState: Resetting thread name to main
编译命令Completed compiling command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192); Time taken: 9.85 seconds
执行命令Completed executing command(queryId=JasonCeng_20201228230305_024ffa3c-23a9-49a7-b80f-f3b434755192); Time taken: 29.351 seconds
五、使用JDBC连接Hive
HiveServer2是Hive服务端接口模块,必须启动此模块,远程客户端才能对Hive进行数据写入和查询。目前,此模块还是基于Thrift RPC实现,它是HiveServer的改进版,支持多客户端接入和身份验证等功能。配置文件hive-site.xml中可以修改下面几个关于HiveServer2的常用属性:
| 属性名 | 属性值 | 备注 |
|---|---|---|
| hive.server2.thrift.min.worker.threads | 5 | 最小工作线程数,默认值为5 |
| hive.server2.thrift.max.worker.threads | 500 | 最大工作线程数,默认值为500 |
| hive.server2.thrift.port | 10000 | 侦听的TCP端口号,默认值为10000 |
| hive.server2.thrift.bind.host | 127.0.0.1 | 绑定的主机,默认值为127.0.0.1 |
| hive.execution.engine | mr | 执行引擎,默认值为mr |
在$HIVE_HOME/bin目录下执行下面的命令可以启动HiveServer2:
> hive.cmd --service hiveserver2
参考
[1] Windows10系统下Hadoop和Hive开发环境搭建填坑指南[https://www.cnblogs.com/throwable/p/13917379.html#配置和启动hive]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号