windows下大数据开发环境搭建(2)——Hadoop环境搭建
一、所需环境
搭建过程详见:windows下大数据开发环境搭建(1)——Java环境搭建
二、Hadoop下载
hadoop下载地址:http://hadoop.apache.org/releases.html
建议下载Binary版本,这是直接解压即可运行的版本。笔者下载的是hadoop-2.7.7版本。
若下载速度较慢,可以到国内镜像源进行下载,如:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
另外还需要下载winutils插件作为hadoop windows版本的补充,下载地址:https://github.com/steveloughran/winutils
整个clone下来后选择适合的winutils版本,若没有完全匹配的版本,建议选择比自己所下载的hadoop高一个版本的插件。
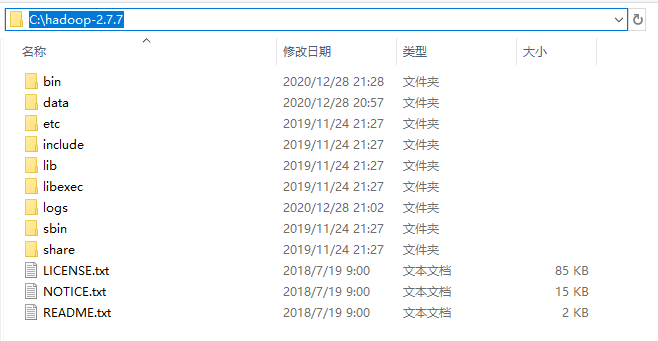
(一)解压hadoop压缩包到指定目录
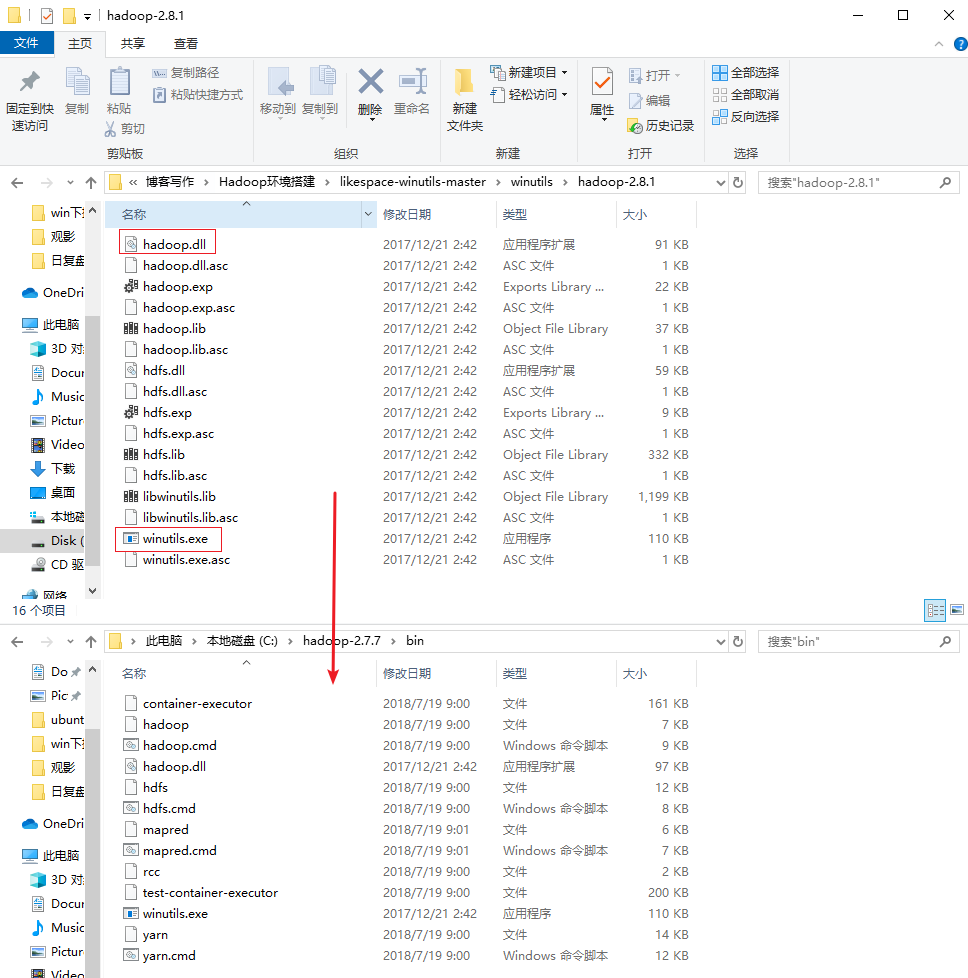
(二)把winutils中的的hadoop.dll和winutils.exe文件拷贝到Hadoop的解压目录的bin文件夹下
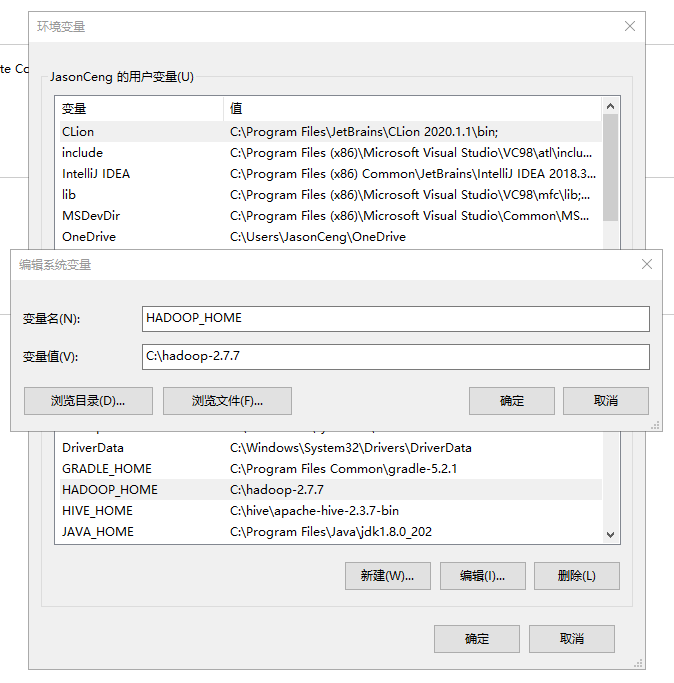
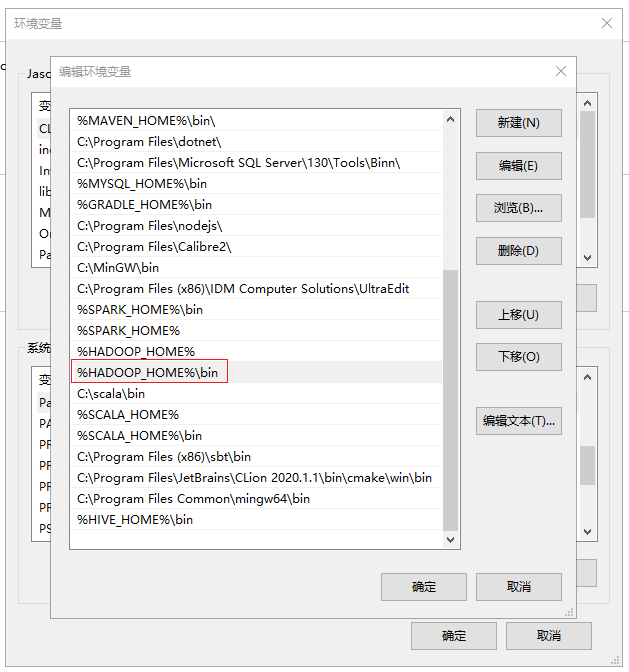
三、配置环境变量
HADOOP_HOME: C:\hadoop-2.7.7
Path: C:\hadoop-2.7.7\bin
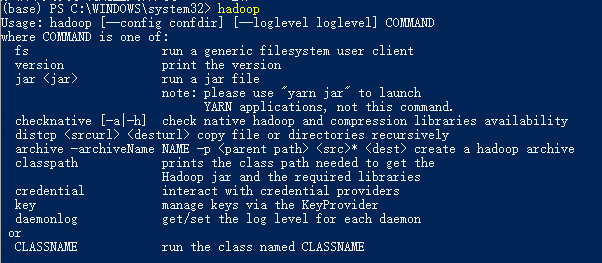
四、命令行检验
hadoop
四、配置和启动Hadoop
在HADOOP_HOME的etc\hadoop子目录下,找到并且修改下面的几个配置文件:
(一)core-site.xml
这里的tmp目录一定要配置一个非虚拟目录,别用默认的tmp目录,否则后面会遇到权限分配失败的问题
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/c:/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
(二)hdfs-site.xml
这里要预先创建nameNode和dataNode的数据存放目录,注意一下每个目录要以/开头,笔者这里预先在HADOOP_HOME/data创建了nameNode和dataNode子目录
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/c:/hadoop-2.7.7/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/c:/hadoop-2.7.7/data/dataNode</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
(三)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(四)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
至此,最小化配置基本完成。
(五)格式化namenode
接着需要格式化namenode。切换至$HADOOP_HOME/bin目录下,使用CMD输入命令:hdfs namenode -format

(六)启动Hadoop服务
切换至$HADOOP_HOME/sbin目录下,执行start-all.cmd脚本:

start-all.cmd成功执行后,会拉起四个JVM实例(见上图中的Shell窗口自动新建了四个Tab),此时可以通过jps查看当前的JVM实例:
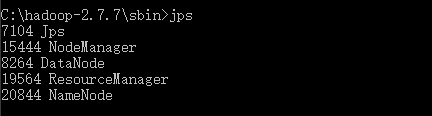
可见已经启动了ResourceManager、NodeManager、NameNode和DataNode四个应用,至此Hadoop的单机版已经启动成功。
tips:通过stop-all.cmd命令可以退出这四个进程。
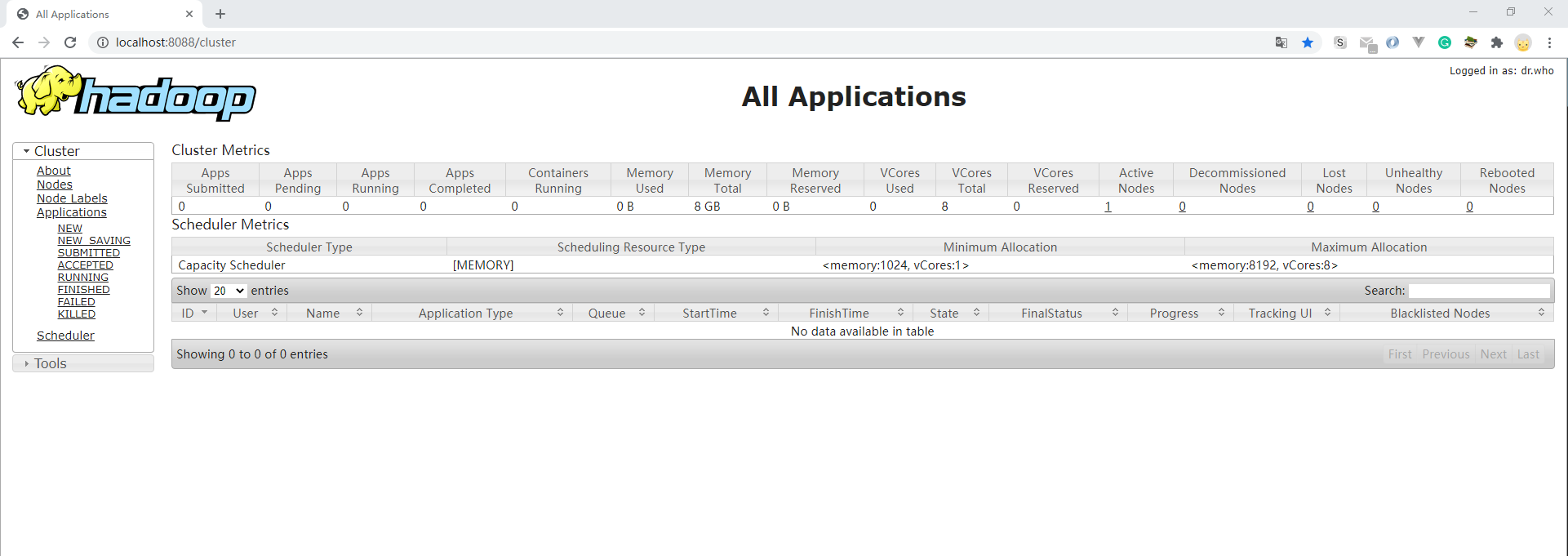
(七)查看调度任务
可以通过http://localhost:8088/查看调度任务的状态:
(八)查看HDFS状态和文件
通过http://localhost:50070/去查看HDFS的状态和文件:
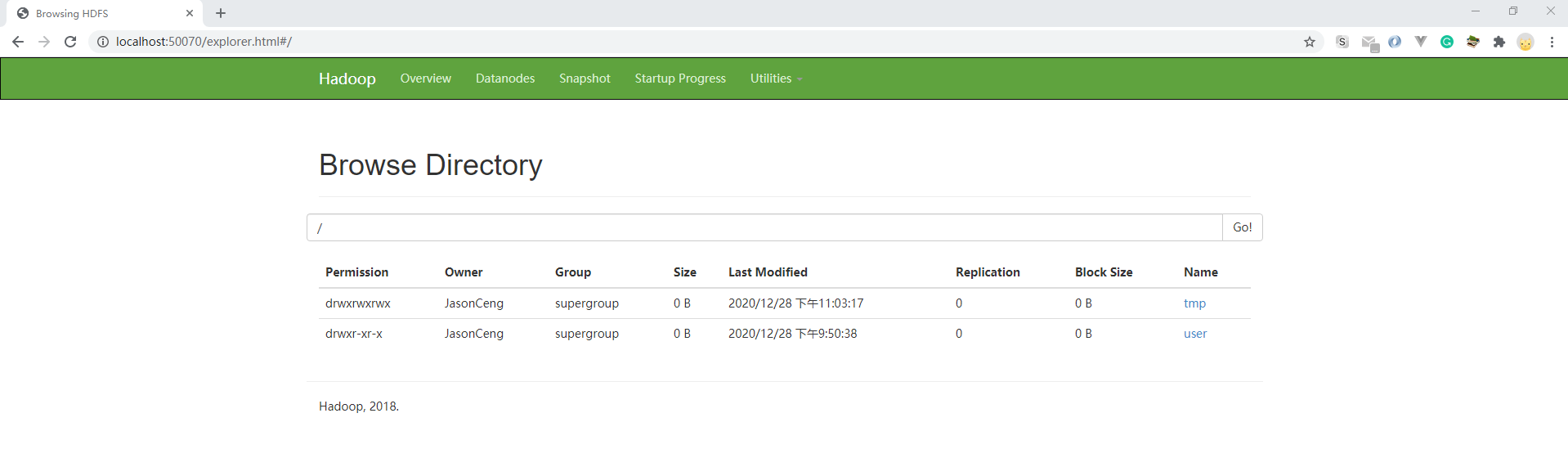
(九)停止和重启hadoop
停止Hadoop的方法:执行HADOOP_HOME\sbin路径下的 stop-all.cmd
重启Hadoop的方法:先执行 stop-all.cmd,再执行 start-all.cmd
至此,我们已经成功在windows环境下搭建起hadoop开发环境,可以在本地单机模式下愉快地开启自己的大数据之旅了!
五、常见问题
(一)hadoop-env配置问题
Error: JAVA_HOME is incorrectly set. Please update C:\hadoop-2.7.7\conf\hadoop-env.cmd
1.打开C:\hadoop-2.7.7\etc\hadoop\hadoop-env.cmd
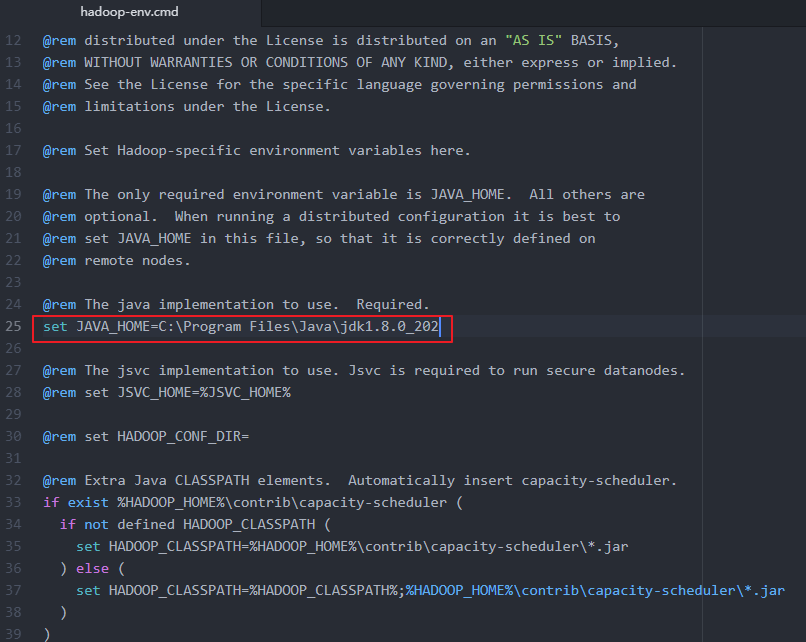
2.分析得出:是配置文件的问题,我的JAVA_HOME目录是C:\Program Files\Java\jdk1.8.0_121,因为Program Files中存在空格,所以出现错误,只需要用
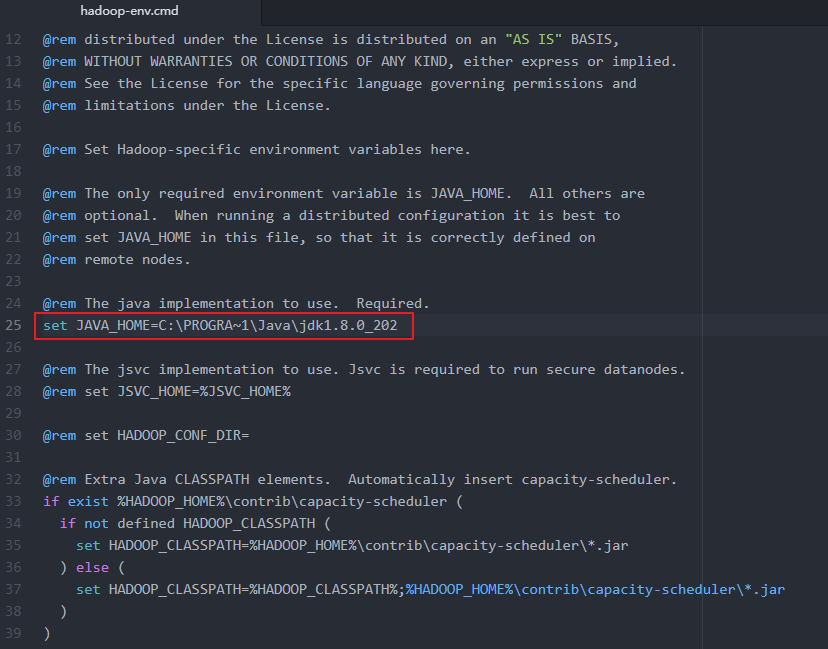
3. 用PROGRA~1代替Program Files即可,即改为C:\PROGRA~1\Java\jdk1.8.0_121,当然,你也可以讲jdk装到根目录或者不存在空格等目录下。
(二)找不到hadoop.dll问题
Error:Exception in thread “main”java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.acc
这个报错表示系统查找不到hadoop.dll这个文件,需要把winutils下的hadoop.dll复制到hadoop/bin路径下,详见上述安装过程的(二)把winutils中的的hadoop.dll和winutils.exe文件拷贝到Hadoop的解压目录的bin文件夹下
参考
1. Windows10系统下Hadoop和Hive开发环境搭建填坑指南[https://www.cnblogs.com/throwable/p/13917379.html]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号