ubuntu 单机配置hadoop
前言
因为是课程要求,所以在自己电脑上安装了hadoop,由于没有使用虚拟机,所以使用单机模拟hadoop的使用,可以上传文件,下载文件。
1.安装配置JDK
Ubuntu18.04是自带Java1.8的,你可以在命令行输入
java -version查看,如果你想重新配置的话清查看以下的教程。
-
下载JDK
单击下载地址进行下载
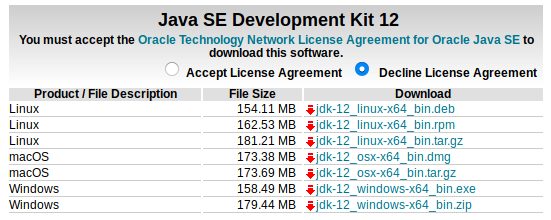
下载之前点击 Accept License Agreement, 然后下载 jdk-12_linux-64_bin.tar.gz
-
解压JDK
进行下载目录,打开terminal,输入
tar zxvf jdk-12_linux-64_bin.tar.gz将解压后的文件夹移动到 /usr/local 文件夹中,在命令行中输入如下命令
sudo mv jdk-12_linux-64_bin /usr/localjdk-12_linux-64_bin 为你解压后得到的文件夹,如果和你的不一样,清按实际情况进行修改。
-
配置Java环境
在terminal中输入如下命令
sudo gedit ~/.bashrc在文件末尾写入如下内容
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH然后在terminal中输入如下命令
source ~/.bashrc -
测试Java安装是否成功
在terminal中输入如下命令
java -version如果配置成功的话会显示出java 的版本,再继续输入如下命令
javac配置成功的话会显示出可以使用的命令
2.下载hadoop
请单击下载地址进行下载
下载 hadoop-2.7.6.tar.gz 这个版本,有需要可以下载其他版本
3.解压到 /opt 目录(如果有需要可以改为其他目录,后面的操作也要陆续修改)
打开terminal进入下载目录,执行命令
tar -zxvf hadoop-2.7.6.tar.gz -C /opt/
4.配置hadoop环境变量
打开命令行,输入如下命令
sudo gedit /etc/profile
在文件中添加如下代码
export HADOOP_HOME=/opt/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
在命令行中执行如下命令
source /etc/profile
5.配置hadoop
5.1配置hadoop-env.sh
在命令行中执行如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.将其下面的一行改为:
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin
如果你没有按照我上面的步骤安装java,清填写你自己的java路径
5.2 配置core-site.xml (5.2和5.3中配置文件里的文件路径和端口随自己习惯配置)
其中的IP:192.168.44.128为虚拟机ip,不能设置为localhost,如果用localhost,后面windows上用saprk连接服务器(虚拟机)上的hive会报异常
在命令行输入 ifconfig查看自己的ip地址,在下面的代码中将 192.168.44.128 改为你自己的ip就可以了
在命令行中输入如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/core-site.xml
在打开的文件中添加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/hadoop-2.7.6</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.44.128:8888</value>
</property>
</configuration>
保存并关闭文件,然后在命令行中输入以下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
在打开的文件中修改如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/data</value>
</property>
</configuration>
6.SSH免密登陆
在命令行中输入如下内容
sudo apt-get install openssh-server
cd ~/.ssh/
ssh localhost ssh-keygen -t rsa
/* 这个过程中持续按回车就可以了 */
cat id_rsa.pub >> authorized_keys
7.启动与停止
第一次启动hdfs需要格式化,在命令行中输入如下命令(出现询问输入Y or N,全部输Y即可)
cd /opt/hadoop-2.7.6
./bin/hdfs namenode -format
启动
./sbin/start-dfs.sh
停止
./sbin/stop-dfs.sh
验证,浏览器输入:http://192.168.44.128:50070
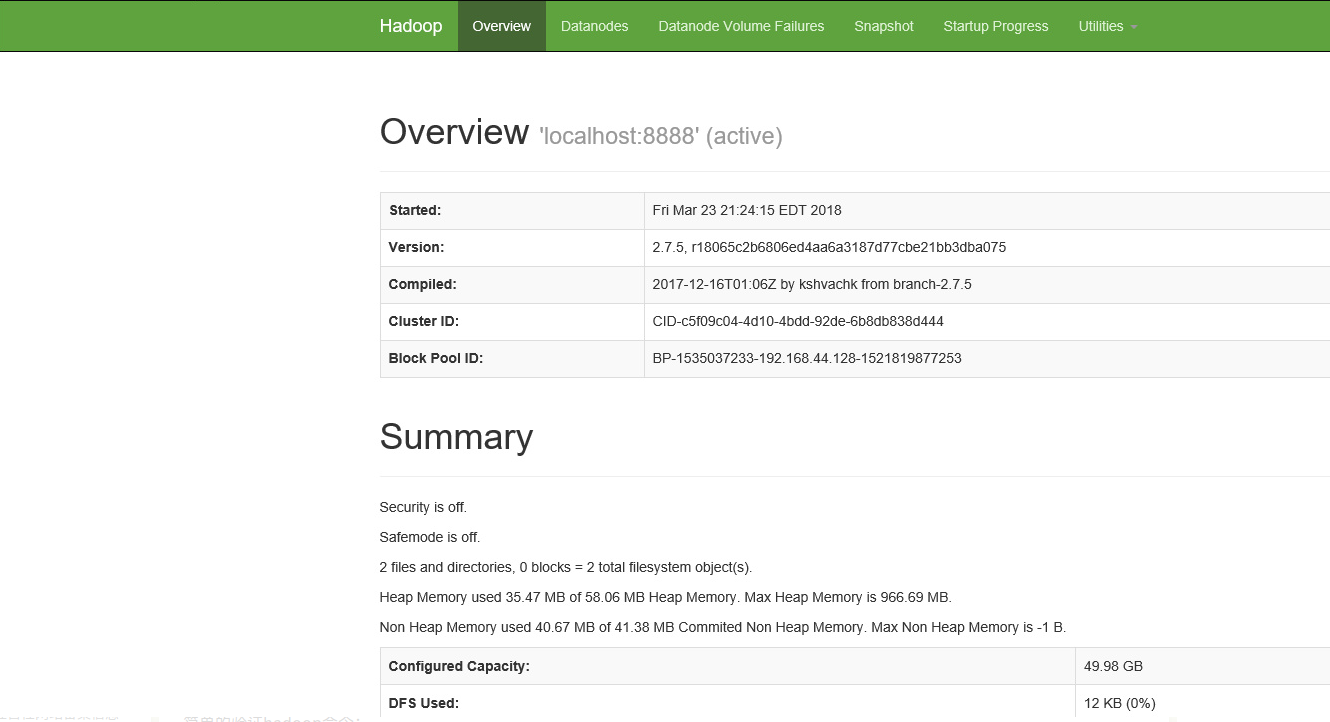
简单的验证hadoop命令:
hadoop fs -mkdir /test
在浏览器查看,出现如下图所示,即为成功
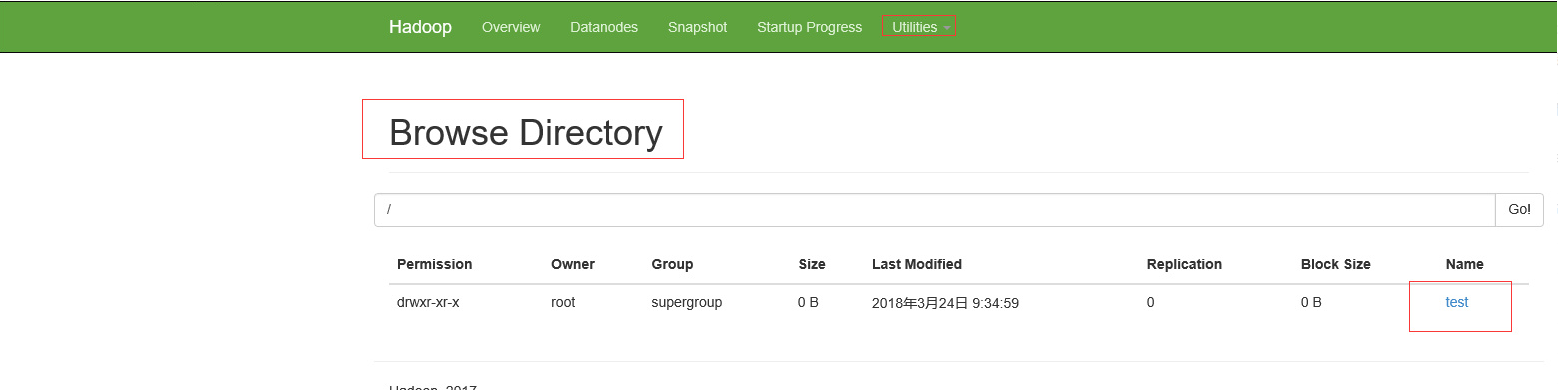
你也可以输入以下命令上传文件到hadoop
hadoop fs -put /test 1.txt /test
8.配置yarn
8.1 配置mapred-site.xml
命令行中输入如下命令:
cd /opt/hadoop-2.7.6/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xml
在文件中添加内容
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.2 配置yarn-site.xml
命令行中输入如下命令:
sudo gedit yarn-site.xml
在文件中添加内容
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.3 yarn启动与停止
启动
cd /opt/hadoop-2.7.5
./sbin/start-yarn.sh
停止
./sbin/stop-yarn.sh
浏览器查看:http://192.168.44.128:8088
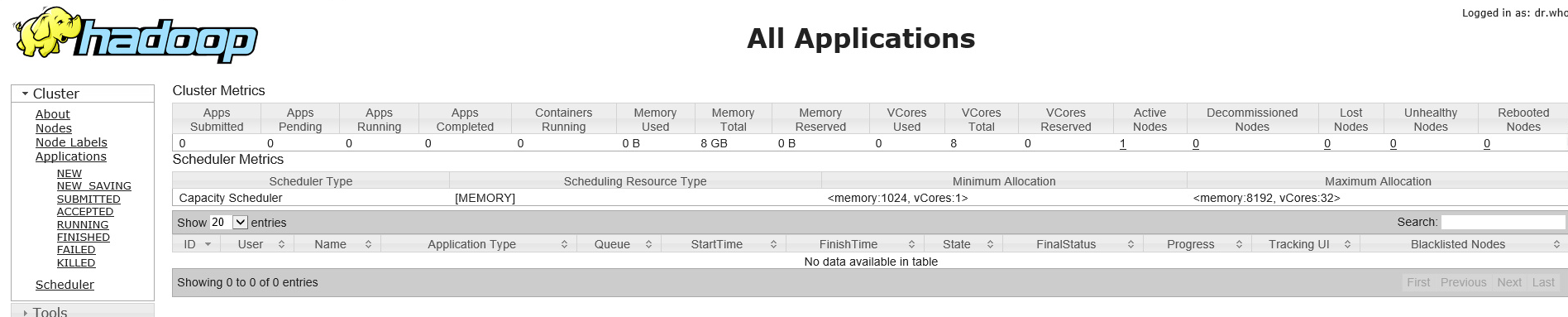
jps查看进程

输出如下所示,则表示hadoop单机模式配置成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号