

Google分布式构建软件之二:构建系统如何工作
分布式软件构建第二部分:构建系统如何工作
注:本文英文原文在google开发者工具组的博客上[需要FQ],以下是我的翻译,欢迎转载,但请尊重作者版权,注名原文地址。
上篇文章中提到了在Google,所有的产品都是从头开始构建的。这篇文章会更深入的介绍Google的构建系统[即Blaze]是如何工作的,并介绍让软件构建过程更快的方法。在后续的文章里,我们会解释如何利用这种确定的信息来在大规模集群之上进行分布式的软件构建并在开发者之间共享构建结果。
问题:Google是如何描述驱动构建和测试的依赖关系的呢?
在Google我们把代码划分成叫做包[package]的小单元。可以把包理解为一个目录,这个目录里面包含了源文件和一个描述文件,描述文件中指定了如何将源文件转换成构建的输出。这个描述文件叫做 BUILD,一个目录中存在这个BUILD文件,就可以把这个目录当作一个包。
所有的包都在同一个文件树下面,使用从文件树的根到包含BUILD文件的目录的相对路径来做为这个包的全局唯一的标示。这说明包名和目录名之间是一一对应的关系。
在BUILD文件中我们用规则[rules]来描述构建后包的输出。使用包名和规则名称可以唯一的标示这条规则。我们把这两者的结合叫做标签[label],我们使用标签来描述规则之间的依赖关系。
来看一个具体例子:
/search/BUILD:
cc_binary(name = ‘google_search_page’,
deps = [ ‘:search’,
‘:show_results’])
cc_library(name = ‘search’,
srcs = [ ‘search.h’,‘search.cc’],
deps = [‘//index:query’])
/index/BUILD:
cc_library(name = ‘query’,
srcs = [ ‘query.h’, ‘query.cc’, ‘query_util.cc’],
deps = [‘:ranking’,
‘:index’])
cc_library(name = ‘ranking’,
srcs = [‘ranking.h’, ‘ranking.cc’],
deps = [‘:index’,
‘//storage/database:query’])
cc_library(name = ‘index’,
srcs = [‘index.h’, ‘index.cc’],
deps = [‘//storage/database:query’])
这个例子展示了两个BUILD文件。第一个BUILD文件描述了//search 这个包,包含一个可执行文件和一个库。第二个BUILD文件描述了包含几个库的//index包。name属性来命名规则,deps属性来描述规则之间的依赖关系。使用冒号来分隔包名和规则名。如果某条规则所依赖的规则在其他目录下,就用"//"开头,如果在同一目录下,可以忽略包名而用冒号开头。这样可以清晰的看到各个规则之间的依赖关系。如果你仔细看了上面的例子,可以看到几个规则都依赖于//storage/database:query 这个规则,说明依赖之间构成了一个有向图。这个有向图必须是无环的,这样我们就可以梳理出构建各个目标的顺序了。
下图是上面描述的依赖关系的一个图形化展示:
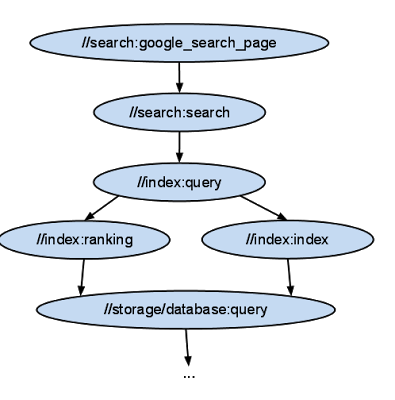
可以看到,跟基于make的构建系统不同,我们引用的是抽象的实体而非具体构建的输出结果。实际上,cc_library 这样的规则并不需要产出任何输出,它就是一个简单的从逻辑上组织源文件的方式。为了让我们的构建系统以更快的速度构建,这一点尤其重要。尽管各个cc_library规则之间有依赖关系,但我们可以用任意顺序编译所有的源文件。编译 'query.cc'和'query_util.cc'时,我们只需要依赖头文件'ranking.h'和'index.h'。实际上我们可以同时编译这些源文件,除非我们依赖于其他规则的输出文件。
为了真正执行构建所需的步骤,我们把每个规则分解成一个或多个实际的步骤,称之为"行为"[actions]. 可以把行为理解为一条命令和输入/输出文件。一个行为的输出可以是另外一个行为的输入。这样所有的行为就形成了由行为和文件组成的二分图。为了构建目标所需要做的就是从这个二分图的叶子节点--那些不需要任何行为来创建就已经存在的源文件--遍历到根节点并顺序执行这些行为。这保证在执行一个行为之前,相关的所有输入文件都已经就位了。
一个小规模目标组成的行为二分图的例子如下,行为是绿色,文件是黄色。
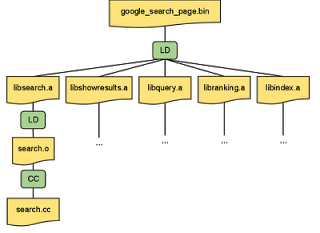
同时我们确保每个行为对应的命令行参数中的文件名称都使用的是相对路径--源文件使用从源文件目录层级中根目录开始的相对路径。同时由于我们知道一个行为所有的输入和输出文件,所以可以很容易的远程执行任何的行为:只需要把所有的输入文件拷贝到远程机器,然后在远程机器上执行命令,再把输出文件拷贝回用户机器。后续的文章中我们会介绍一些使远程构建更高效的方法。
所有的这些跟 make 所做的事情没有太大区别。最重要的区别是我们不是以文件为单元来确定依赖关系,这就让构建系统在决定行为的执行顺序时,有更大的自由度。在一次构建过程中并发度越高(即行为二分图宽度越宽),执行时间就越短。在Google,通过简单的增加机器就可以扩展构建系统。如果我们数据中心的机器足够多,那么一次构建的时间就主要由行为二分图的高度来决定。
上面描述的是在Google,一次干净的构建是如何进行的。在实际中大多数开发过程中的构建是增量的。这意味着一个开发人员在两次构建中间只修改了小部分源文件,这种情况下构建整个行为图是很浪费的,所以我们只执行跟上次构建相比,输入文件发生变化的的行为。为了达到这个目标,我们跟踪了每次执行行为时输入文件的内容摘要。上篇博客中提到,我们跟踪源文件的内容摘要并使用这个摘要来跟踪对文件的修改。前文描述的FUSE文件系统把每个文件的摘要当作一个扩展的属性。这种设计下构建系统很容易就能拿到一个文件的摘要并且能够让我们不用执行那些输入文件没有改变的行为。
本系列的第三部分会介绍如何使远程执行真正的高效甚至让它提高构建的速度!
PS:从英文原文中看到的一些回复:
根据BUILD文件产生Makefile是很容易的,而从Makefile推导出BUILD文件是几乎不可能的。因为BUILD文件提供的依赖是更高级别的抽象单元(目标和包),这是很难从基于文件的依赖关系中推倒出来的。
Gilbert说,文中提到的构建系统,会有两个问题:
- 把实际不需要的依赖库包含进来,除非用工具来自动化的检查
- 在低级别的模块中库的使用会有效的聚合依赖,但是它也会让依 赖图不准确,这就会导致过度构建--例如,你修改了一个库的目标文 件,那么依赖于这个库的所有的可执行文件都需要重新链接,但实际上 这些可执行文件可能并不需要这个目标文件。
nyork的答复是:
1确实是一个问题,在问题2的场景下,确实是一种潜在的过度构建。
构建系统和基础设施是跟语言无关的,这是一个非常重要的一点。构建系统应该能够支持C++,Java, shell脚本等。唯一的要求就是执行所需要的底层工具(编译器,连接器等)必须遵守确定的规则(后续的文章会有更多介绍)。完整的定义依赖关系,构建系统就不需要理解每个语言的语义了,这就意味者我们不需要花费CPU时间(和IO)来在工作站上读取并解析源代码。
后续的文章介绍了我们如何使用BUILD文件提供的信息来让构建过程尤其快速和高效,这也说明了为什么相比而言,过度构建根本就不是问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号