Google分布式构建软件之一:获取源代码
本文原文在google开发者工具组的博客上[需要FQ],以下是我的翻译,欢迎转载,但尊重作者版权,注名原文地址。
在Google,所有的产品都是在主干上开发的。这样的好处:每个人都可以查看和修改代码,避免了在分支上长时间开发后合并主干时候的痛苦,从源码构建也避免了库之间的二进制兼容问题。Google是跨国公司,这意味着分布在世界各地的办公室会放大下载代码的时间。通过计算依赖关系来限制下载的文件数量,我们成功地减少了代码下载的时间。然而,计算依赖关系也要花时间,而且即使这样改进了,获取源码的时间仍然很长。
最明显的代价是工程师花费在下载代码上的时间,而实际上的代价更高。自动化构建和测试需要访问源码。在这些系统中下载代码上花费的时间会增加整个过程的时间,同时也会增加这些系统的复杂度,因为他们需要在文件系统上维护状态并为了获得代码的只读权限而和版本控制系统紧密耦合。
实际上,我们发现工程师下载代码后修改的代码相对于执行构建需要的代码而言是非常小的一部分。因为我们所有的东西都是从代码构建的,而修改的只是源码树中的一小部分。所以,工程师和自动构建系统都需要对执行构建所需要的未修改的大量代码拥有一个更快,只读的访问方式。未修改的代码本身是没有发生变化的,因为自动提交到版本管理系统后,就没有改动过。这意味着我们可以使用Google的基础设施来在云上对所有的版本控制信息做镜像来对源码提供更快且可扩展的只读访问。
在我们系统中,每个文件的每个版本都有对应的元信息记录。元信息包含的信息包括:文件在代码库里面的路径信息,文件名称,大小,版本号等,也包含了针对这个版本的文件内容的摘要。这个摘要是使用适合基于内容寻址存储CAS的哈希函数来对文件内容的哈希。在系统中很多地方我们实现了CAS。在后续的文章会中读到更多的CAS内容。
/som/path/foo.c文件的第5个版本的元信息和CAS的文件内容看起来是这样的:
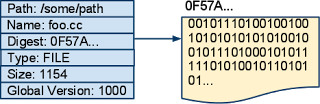
我们的系统监控版本控制系统中到来的修改。当发生修改后,我们哈希文件内容来计算摘要并把内容插入到BigTable存储系统中。然后我们计算每个受影响的文件的元数据信息并插入到BigTable中。这样我们就在云上拥有了所有文件的各个版本的完整历史。
现在我们有了这些数据,我们怎么使用它?我们在开发人员的本地机器上使用命令行工具来下载云端的代码。这样能够减少版本控制系统的负载,并由于使用的是在办公地点附近的云端数据拷贝,也会由于减少了网络时延而提升性能。我们实现的时候不是下载全部代码,而是自动按需下载代码,这非常有用。
上面提到的按需自动下载代码,可以通过实现一个定制的文件系统来完成,这个定制的文件系统提供对版本历史的只读访问。通过用户空间文件系统(File System in Userspace)可以很方便的用一个用户态空间里的守护进程来实现这样的文件系统。用户使用跟其他文件系统一样的方法来和这个源码文件系统交互,唯一差别是路径中有配置了版本信息的特殊元素。
例如,访问前面例子里提到的foo.cc文件的1000版本:
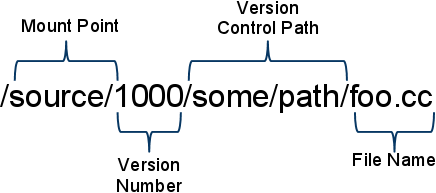
文件系统通过类似stat()和readdir()这样的调用来获得元信息,首先是从路径中解析出版本号,然后从云上获得版本控制数据。
例如,使用gcc(或者其他工具)来编译foo.cc,gcc首先调用stat()来检查文件是否存在:
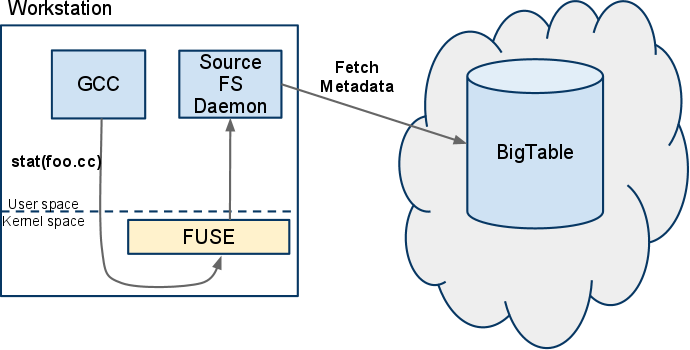
这就允许用户和工具仅仅使用版本元数据来访问版本控制。文件内容只有在文件被打开的时候才会下载下来。由于文件版本是不可变的,所以文件内容可以缓存下来并无限次的重复使用[文件内容和元数据在本地有缓存]。CAS的使用同时也消除了文件内容的重复数据,相同的内容不会重复下载。
通过把版本历史存储在云端,我们就可以让开发人员访问到所有的代码的同时,还能够保证下载时间非常短。通过把云扩展到多个地理区域,就可以保证世界各地的办公区的性能都差不多。最终,自动化的构建和测试系统可以通过简单的文件系统接口来而很容易的获得代码而不用跟版本控制工具直接打交道。所有这些组成了一个快速高效的系统来保证工程师和自动化的系统可以专注于构建和测试软件而不是下载源码上。
如果您看了本篇博客,觉得对您有所收获,请点击右下角的“推荐”,让更多人看到!




 浙公网安备 33010602011771号
浙公网安备 33010602011771号