AI+大数据
将AI深度融入ETL、数据仓库和BI的解决方案,能够彻底改变传统数据处理的被动模式,将其转变为主动、智能的数据驱动体系。
下面我将为你详细阐述具体的实现方式、技术方法,并提供行业内的成功案例。
![deepseek_mermaid_20250901_e63319]()
下面我将为你详细阐述具体的实现方式、技术方法,并提供行业内的成功案例。
🛠️ AI在ETL过程中的应用
ETL(提取、转换、加载)是数据 pipeline 的起点,AI的注入能显著提升其智能化水平。
1. 智能数据发现与编目
· 实现方式:利用自然语言处理(NLP)和模式识别技术自动扫描数据源。AI模型能推断数据的语义类型(如姓名、地址、信用卡号),并生成数据质量评估报告(如缺失率、唯一值数量、值域分布)。
· 技术实现:采用预训练的NLP模型(如BERT)或自定义的命名实体识别(NER)模型对字段名和样本数据进行分类。工具方面,可考虑 AWS Glue DataBrew, Google Cloud Data Catalog, Azure Purview。
2. 动态数据清洗与增强
· 实现方式:
· 异常检测:使用隔离森林(Isolation Forest)、自编码器(Autoencoder) 等无监督学习算法自动识别并标记数据中的异常记录。
· 缺失值处理:利用生成对抗网络(GAN) 或回归模型根据数据上下文预测并填充最合理的值。
· 非结构化数据处理:通过计算机视觉(CV) 处理图片/视频,使用NLP处理文本日志/文档,提取结构化信息(如从客服录音中提取“客户情绪”分数)。
· 技术实现:在Spark集群上运行机器学习算法(如使用 Apache Spark MLlib)进行分布式的、大规模的数据清洗和特征工程。
3. 智能元数据管理与血缘分析
· 实现方式:AI自动学习数据和Pipeline的使用模式,智能推荐数据血缘关系。当上游数据变更时,AI能预测哪些下游报表和模型会受影响,并自动警报。
· 技术实现:利用图数据库(如Neo4j)存储元数据关系,ML模型分析访问日志和查询日志来构建血缘。工具可选择 Lyft Amundsen, DataHub。
🗄️ AI在数据仓库与数据湖中的应用
现代数据仓库不仅是存储中心,更演变为智能计算核心。
1. 内嵌机器学习 (In-Database ML)
· 实现方式:用户无需将数据导出,可直接使用SQL语句在数据仓库内部创建、训练和部署机器学习模型。
· 技术实现:
· Google BigQuery ML:直接用SQL创建线性回归、逻辑回归、K-Means聚类、时间序列预测等模型。
· Snowflake with Snowpark:允许在Snowflake内部的安全沙箱中运行Python ML代码(如Scikit-learn)。
· Azure Synapse Analytics:与Azure ML深度集成,提供内置的模型训练和评分服务。
· Amazon Redshift ML:允许使用SQL创建模型,并通过Sagemaker在后台进行训练。
2. 智能性能与成本优化
· 实现方式:
· 自动聚类与分区:AI监控查询模式,自动调整数据的分布和排序键以优化查询性能。
· 智能缓存与预计算:ML模型预测高频访问的数据和查询,主动进行预聚合和缓存。
· 自动扩缩容:预测工作负载高峰,自动扩容缩容以优化成本。
· 技术实现:这通常是云数据仓库的内置功能(如Snowflake的自动聚类、BigQuery的自动缩放),背后由复杂的AI算法驱动。
3. 多模态数据与向量处理
· 实现方式:高效处理非结构化数据(如图片、文本)和向量数据,支持相似性检索。
· 技术实现:阿里云AnalyticDB引入 Lance 数据格式和 ADB Ray,将多模数据ETL与ML一体化,避免数据移动,提升处理效率。
📊 AI在BI与分析中的应用
这是AI价值最直观的体现,让BI从“静态报表”变为“动态数据顾问”。
1. 自然语言查询与对话式分析 (NLQ)
· 实现方式:用户直接用自然语言提问(如“显示上海地区去年第一季度销量最高的十款产品”),NLP引擎将其解析为SQL查询语句,执行并返回结果。
· 技术实现:基于Transformer的NLP模型(如类似GPT的架构),结合企业特定的元数据进行微调。工具如 ThoughtSpot, Microsoft Power BI Q&A, Qlik Sense Insight Advisor。
2. 自动洞察与归因分析
· 实现方式:系统自动分析数据,主动发现异常点、趋势和模式,并进行根本原因分析(RCA)。例如,自动提示“XX产品退货率异常升高30%”,并关联供应链数据。
· 技术实现:综合运用统计学显著性检验、时间序列分解、SHAP值解释等技术。工具如 Tableau Einstein Discovery, Salesforce Einstein Analytics。
3. 预测与情景模拟 (What-If Analysis)
· 实现方式:在BI界面中直接进行预测(如下季度营收)和假设分析(如“营销费用提高5%对销量的影响”)。
· 技术实现:后台调用数据仓库中已训练好的回归模型或时间序列预测模型(如Prophet、ARIMA)。BI工具通过API实时获取预测结果。
4. Agentic BI(智能体商业智能)
· 实现方式:AI Agent能理解用户业务需求,自主完成从数据建模、特征工程到模型选择、报表生成的全流程。
· 技术实现:融合大语言模型(LLM)、知识图谱和自动化机器学习(AutoML)。例如,衡石的HENGSHI SENSE 6.0引入了环形数据模型和建模Agent。
🏭 行业成功落地案例
1. 零售行业:某大型连锁零售企业
· 痛点:500+门店数据延迟24小时,月度滞销品超300SKU,库存积压严重。
· 解决方案:部署智能滞销预警系统,设置动态阈值规则,利用AI预测需求。
· 成效:滞销品识别速度提升6倍,库存周转率提升40%,年度降本1200万元。
2. 制造业:某汽车零部件厂商
· 痛点:10+异构系统数据孤岛,工艺参数调整依赖老师傅经验,设备故障停机损失年均超千万。
· 解决方案:构建跨MES/ERP/IoT的统一数据底座,利用LSTM算法预测设备故障,自动识别200+工艺参数关联关系。
· 成效:设备无故障运行时间提升35%,良品率从89%提升至96%,年节约维护成本1200万元。
3. 金融行业:某头部银行
· 痛点:传统BI平台无法支撑海量用户的高并发、低延迟分析需求。
· 解决方案:采用 Delta Lake 和 Spark 构建数据湖仓一体架构,支撑BI平台。
· 成效:BI平台月活达到4万以上,90%的分析行为在3-5秒内完成,每日处理超过50万个Spark任务。
4. 有色金属行业:某大型有色金属集团
· 痛点:生产、设备、财务等系统数据不通,指标口径混乱,数据质量堪忧。
· 解决方案:建立企业级数据湖,梳理超3800个指标,引入智能问数和AI归因分析。
· 成效:管理层决策响应从“隔天”变“实时”,每日响应超1500次自然语言查询,替代80%传统报表,通过能耗优化降低无效成本数百万元。
🔧 技术架构与实现路径
一个典型的AI增强型数据平台架构如下:
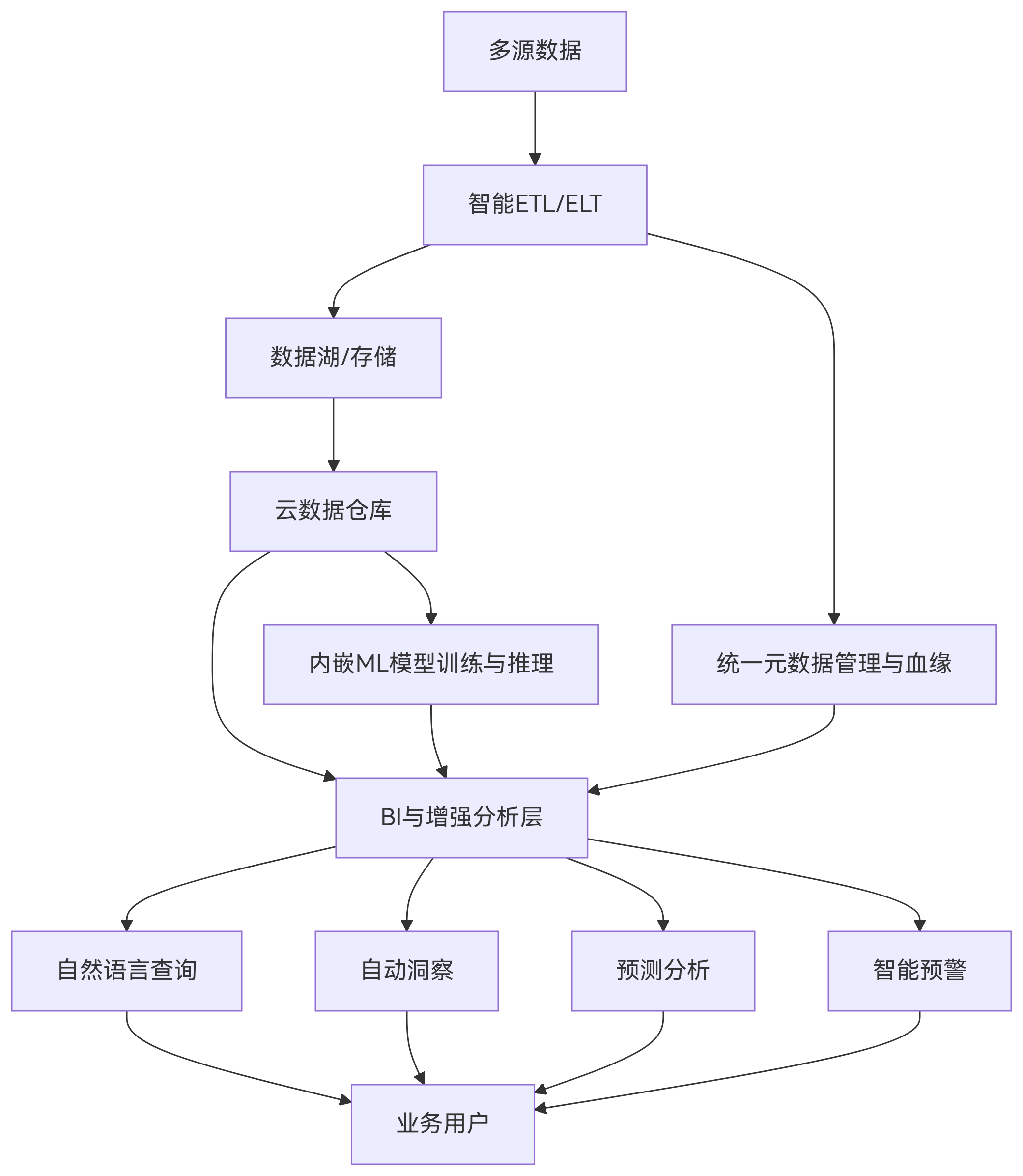
实现路径建议:
1. 起步:从智能数据目录和自动数据质量检查开始,打好数据基础。
2. 发展:在数据仓库中试点In-Database ML,尝试一两个预测性分析场景。
3. 深化:在BI层面引入自然语言查询和自动洞察,提升用户体验。
4. 成熟:向Agentic BI演进,实现从“人找数”到“数助人”的转变。
💎 总结
将AI深度融合到ETL、数据仓库和BI中,其核心价值在于通过自动化、智能化和平民化,降低数据使用门槛,提升决策效率与准确性,最终让数据真正成为企业的核心资产和竞争力。成功的实践表明,这是一个系统工程,需要扎实的数据基础、清晰的业务场景和循序渐进的技术引入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号