

数据的预处理
准备数据
在数据能够被作为输入提供给机器学习算法之前,它经常需要被清洗,格式化,和重新组织 - 这通常被叫做预处理。这个预处理都可以极大地帮助我们提升几乎所有的学习算法的结果和预测能力。
转换倾斜的连续特征
一个数据集有时可能包含至少一个靠近某个数字的特征,但有时也会有一些相对来说存在极大值或者极小值的不平凡分布的的特征。算法对这种分布的数据会十分敏感,并且如果这种数据没有能够很好地规一化处理会使得算法表现不佳。在人口普查数据集的两个特征符合这个描述:'capital-gain'和'capital-loss'。
对数转换前:
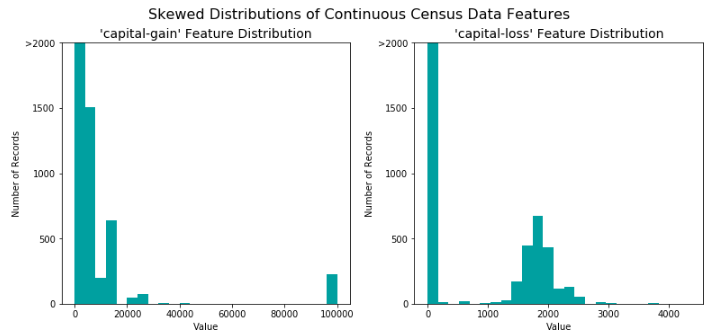
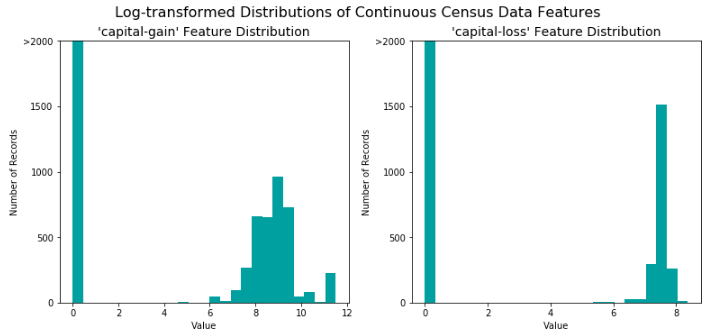
对于高度倾斜分布的特征如'capital-gain'和'capital-loss',常见的做法是对数据施加一个对数转换,将数据转换成对数,这样非常大和非常小的值不会对学习算法产生负面的影响。并且使用对数变换显著降低了由于异常值所造成的数据范围异常。但是在应用这个变换时必须小心:因为0的对数是没有定义的,所以我们必须先将数据处理成一个比0稍微大一点的数以成功完成对数转换。
# 对于倾斜的数据使用Log转换 skewed = ['capital-gain', 'capital-loss'] features_raw[skewed] = data[skewed].apply(lambda x: np.log(x + 1))
对数转换后:
规一化数字特征
除了对于高度倾斜的特征施加转换,对数值特征施加一些形式的缩放通常会是一个好的习惯。在数据上面施加一个缩放并不会改变数据分布的形式(比如上面说的'capital-gain' or 'capital-loss');但是,规一化保证了每一个特征在使用监督学习器的时候能够被平等的对待。注意一旦使用了缩放,观察数据的原始形式不再具有它本来的意义了,就像下面的例子展示的。
运行下面的代码单元来规一化每一个数字特征。我们将使用sklearn.preprocessing.MinMaxScaler来完成这个任务。
1 from sklearn.preprocessing import MinMaxScaler 2 3 # 初始化一个 scaler,并将它施加到特征上 4 scaler = MinMaxScaler() 5 numerical = ['age', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week'] 6 features_raw[numerical] = scaler.fit_transform(data[numerical]) 7 8 # 显示一个经过缩放的样例记录 9 display(features_raw.head(n = 1))
缩放前:

缩放后:

独热编码
从上面的数据探索中的表中,我们可以看到有几个属性的每一条记录都是非数字的。通常情况下,学习算法期望输入是数字的,这要求非数字的特征(称为类别变量)被转换。转换类别变量的一种流行的方法是使用独热编码方案。
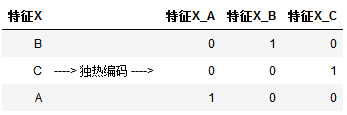
对于每一个特征,如果它有m个可能值,那么经过独热编码(激活)后,就变成了m个二元特征。只有一个被激活
下图在对 特征X 进行独热编码,会形成3个列,每个列都是0和1的组合,但是由于3个列互斥,只有一个被激活。
1 # TODO:使用pandas.get_dummies()对'features_raw'数据进行独热编码 2 features = pd.get_dummies(features_raw) 3 4 # TODO:将'income_raw'编码成数字值 5 income = pd.get_dummies(income_raw) 6 7 income=income.drop("<=50K", axis = 1) 8 # 打印经过独热编码之后的特征数量 9 encoded = list(features.columns)
103 total features after one-hot encoding.
混洗和切分数据
现在所有的 类别变量 已被转换成数值特征,而且所有的数值特征已被规一化。和我们一般情况下做的一样,我们现在将数据(包括特征和它们的标签)切分成训练和测试集。其中80%的数据将用于训练和20%的数据用于测试。然后再进一步把训练数据分为训练集和验证集,用来选择和优化模型。
运行下面的代码单元来完成切分。
1 # 导入 train_test_split 2 from sklearn.model_selection import train_test_split 3 4 # 将'features'和'income'数据切分成训练集和测试集 5 X_train, X_test, y_train, y_test = train_test_split(features, income, test_size = 0.2, random_state = 0, 6 stratify = income) 7 # 将'X_train'和'y_train'进一步切分为训练集和验证集 8 X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=0, 9 stratify = y_train) 11 # 显示切分的结果 12 print "Training set has {} samples.".format(X_train.shape[0]) 13 print "Validation set has {} samples.".format(X_val.shape[0]) 14 print "Testing set has {} samples.".format(X_test.shape[0])
Training set has 28941 samples. Validation set has 7236 samples. Testing set has 9045 samples.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号