关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0
hive版本:1.2.1
需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spark-sql程序实现将该文件读取并以parquet的格式通过外部表的形式保存到hive中,最终要实现通过传参的形式,将该日期区间内的csv文件批量加载进去,方式有两种:
1、之传入一个参数,说明只加载一天的数据进去
2、传入两个参数,批量加载这两个日期区间的每一天的数据
最终打成jar包,进行运行
步骤如下:
1、初始化配置,先创建sparkSession(spark2.0版本开始将sqlContext、hiveContext同意整合为sparkSession)
//初始化配置
val spark = new sql.SparkSession
.Builder()
.enableHiveSupport() //操作hive这一步千万不能少
.appName("project_1")
.master("local[2]")
.getOrCreate()
2、先将文件读进来,并转换为DF
val data = spark.read.option("inferSchema", "true").option("header", "false") //这里设置是否处理头信息,false代表不处理,也就是说文件的第一行也会被加载进来,如果设置为true,那么加载进来的数据中不包含第一行,第一行被当作了头信息,也就是表中的字段名处理了 .csv(s"file:///home/spark/file/project/${i}visit.txt") //这里设置读取的文件,${i}是我引用的一个变量,如果要在双引号之间引用变量的话,括号前面的那个s不能少 .toDF("mac", "phone_brand", "enter_time", "first_time", "last_time", "region", "screen", "stay_time") //将读进来的数据转换为DF,并为每个字段设置字段名
3、将转换后的DF注册为一张临时表
data.createTempView(s"table_${i}")
4、通过spark-sql创建hive外部表,这里有坑
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) stored as parquet
|location 'hdfs://master:9000/project_dest/${i}'
""".stripMargin)
这里的见表语句需要特别注意,如果写成如下的方式是错误的:
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) row format delimited fields terminated by '\t' stored as parquet
|location /project_dest/${i}'
""".stripMargin)
(1)对于row format delimited fields terminated by '\t'这语句只支持存储文件格式为textFile,对于parquet文件格式不支持
(2)对于location这里,一定要写hdfs的全路径,如果向上面这样写,系统不认识,切记
5、通过spark-sql执行insert语句,将数据插入到hive表中
spark.sql(s"insert overwrite table ${i}visit select * from table_${i}".stripMargin)
至此,即完成了将本地数据以parquet的形式加载至hive表中了,接下来既可以到hive表中进行查看数据是否成功载入
贴一下完整代码:
package _sql.project_1
import org.apache.spark.sql
/**
* Author Mr. Guo
* Create 2018/9/4 - 9:04
* ┌───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┐
* │Esc│ │ F1│ F2│ F3│ F4│ │ F5│ F6│ F7│ F8│ │ F9│F10│F11│F12│ │P/S│S L│P/B│ ┌┐ ┌┐ ┌┐
* └───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┘ └┘ └┘ └┘
* ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───────┐ ┌───┬───┬───┐ ┌───┬───┬───┬───┐
* │~ `│! 1│@ 2│# 3│$ 4│% 5│^ 6│& 7│* 8│( 9│) 0│_ -│+ =│ BacSp │ │Ins│Hom│PUp│ │N L│ / │ * │ - │
* ├───┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─────┤ ├───┼───┼───┤ ├───┼───┼───┼───┤
* │ Tab │ Q │ W │ E │ R │ T │ Y │ U │ I │ O │ P │{ [│} ]│ | \ │ │Del│End│PDn│ │ 7 │ 8 │ 9 │ │
* ├─────┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴─────┤ └───┴───┴───┘ ├───┼───┼───┤ + │
* │ Caps │ A │ S │ D │ F │ G │ H │ J │ K │ L │: ;│" '│ Enter │ │ 4 │ 5 │ 6 │ │
* ├──────┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴────────┤ ┌───┐ ├───┼───┼───┼───┤
* │ Shift │ Z │ X │ C │ V │ B │ N │ M │< ,│> .│? /│ Shift │ │ ↑ │ │ 1 │ 2 │ 3 │ │
* ├─────┬──┴─┬─┴──┬┴───┴───┴───┴───┴───┴──┬┴───┼───┴┬────┬────┤ ┌───┼───┼───┐ ├───┴───┼───┤ E││
* │ Ctrl│ │Alt │ Space │ Alt│ │ │Ctrl│ │ ← │ ↓ │ → │ │ 0 │ . │←─┘│
* └─────┴────┴────┴───────────────────────┴────┴────┴────┴────┘ └───┴───┴───┘ └───────┴───┴───┘
**/
object Spark_Sql_Load_Data_To_Hive {
//初始化配置
val spark = new sql.SparkSession
.Builder()
.enableHiveSupport()
.appName("project_1")
.master("local[2]")
.getOrCreate()
//设置日志的级别
spark.sparkContext.setLogLevel("WARN")
def main(args: Array[String]): Unit = {
try {
if (args.length != 1) {
data_load(args(0).toInt)
} else if (args.length != 2) {
for (i <- args(0).toInt to args(1).toInt) {
data_load(i)
}
} else {
System.err.println("Usage:<start_time> or <start_time> <end_time>")
System.exit(1)
}
}catch {
case ex:Exception => println("Exception")
}finally{
spark.stop()
}
}
def data_load(i:Int): Unit = {
println(s"*******data_${i}********")
val data = spark.read.option("inferSchema", "true").option("header", "false")
.csv(s"file:///home/spark/file/project/${i}visit.txt")
.toDF("mac", "phone_brand", "enter_time", "first_time", "last_time", "region", "screen", "stay_time")
data.createTempView(s"table_${i}")
spark.sql("use project_1".stripMargin)
spark.sql(
s"""
|create external table if not exists ${i}visit
|(mac string, phone_brand string, enter_time timestamp, first_time timestamp, last_time timestamp,
|region string, screen string, stay_time int) stored as parquet
|location 'hdfs://master:9000/project_dest/${i}'
""".stripMargin)
spark
.sql(s"insert overwrite table ${i}visit select * from table_${i}".stripMargin)
}
}
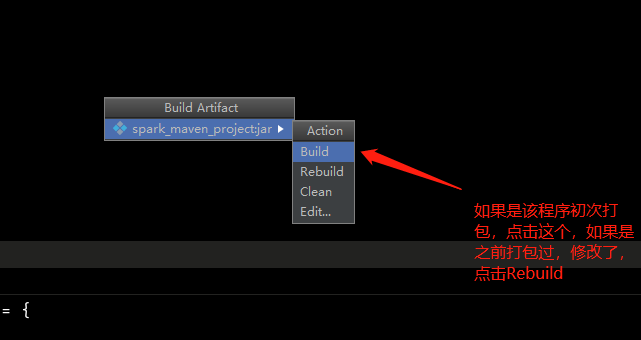
6、打成jar包(我的IDEA版本是2017.3版本)
如果没有上面这一栏,点击View,然后勾选Toolbar即可
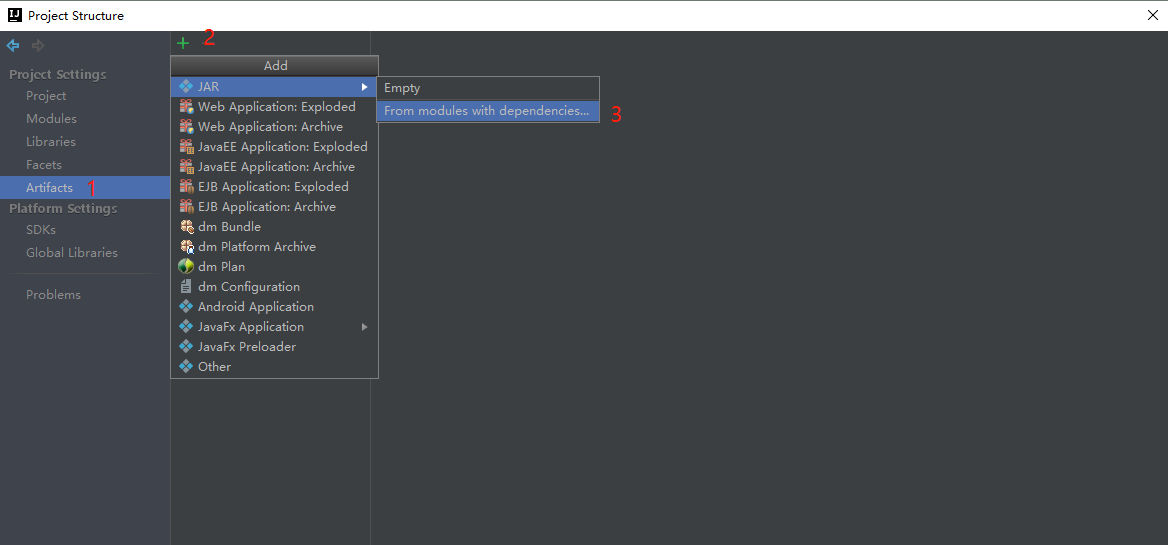
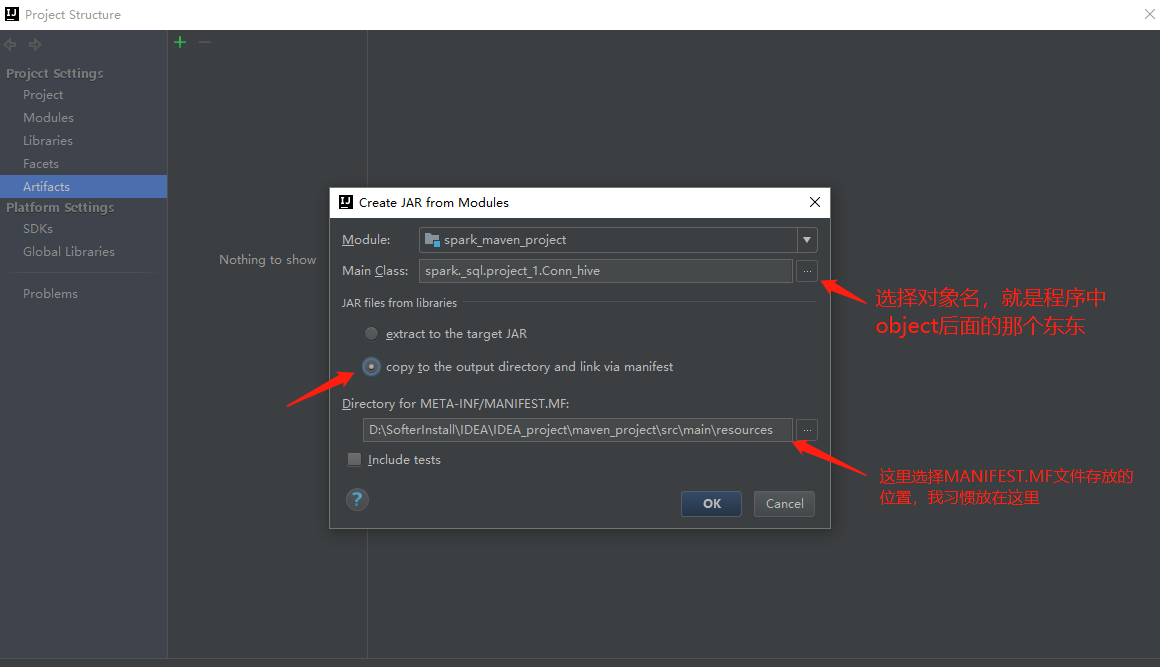
点击ok
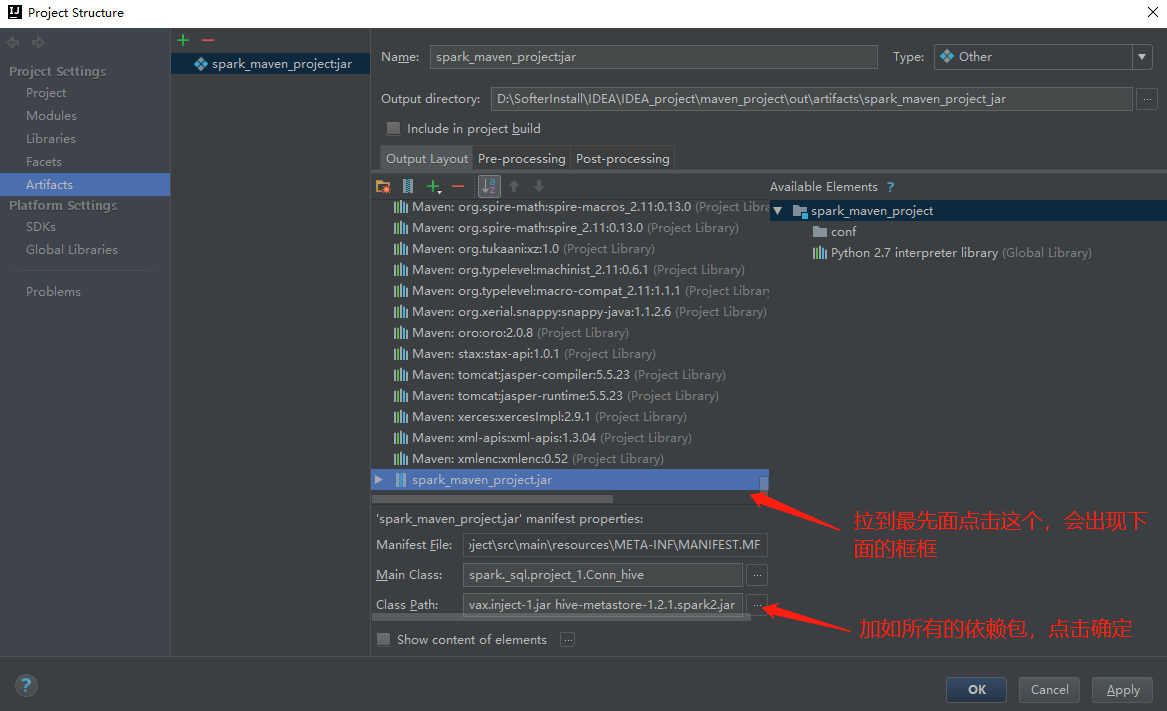
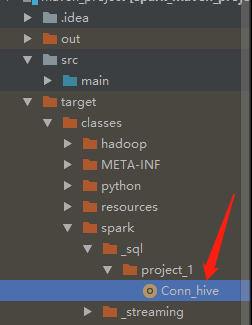
此时这里会成成这么一个文件,是编译之后的class文件

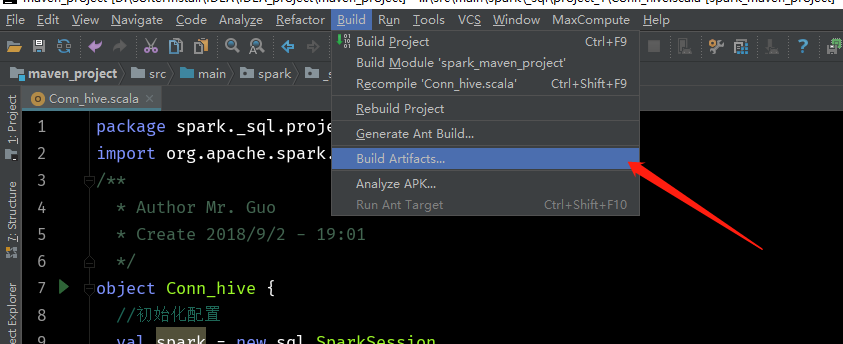
到这个目录下会找到这么一个jar包

找到该文件夹,上传到服务器,cd到该目录下运行命令:
spark-submit --class spark._sql.project_1.Conn_hive --master spark://master:7077 --executor-memory 2g --num-executors 3 /spark_maven_project.jar 20180901 20180910

 浙公网安备 33010602011771号
浙公网安备 33010602011771号