Java项目常用到的一些生疏的语法和自定义函数
文件路径
假设项目文件的源路径如下所示
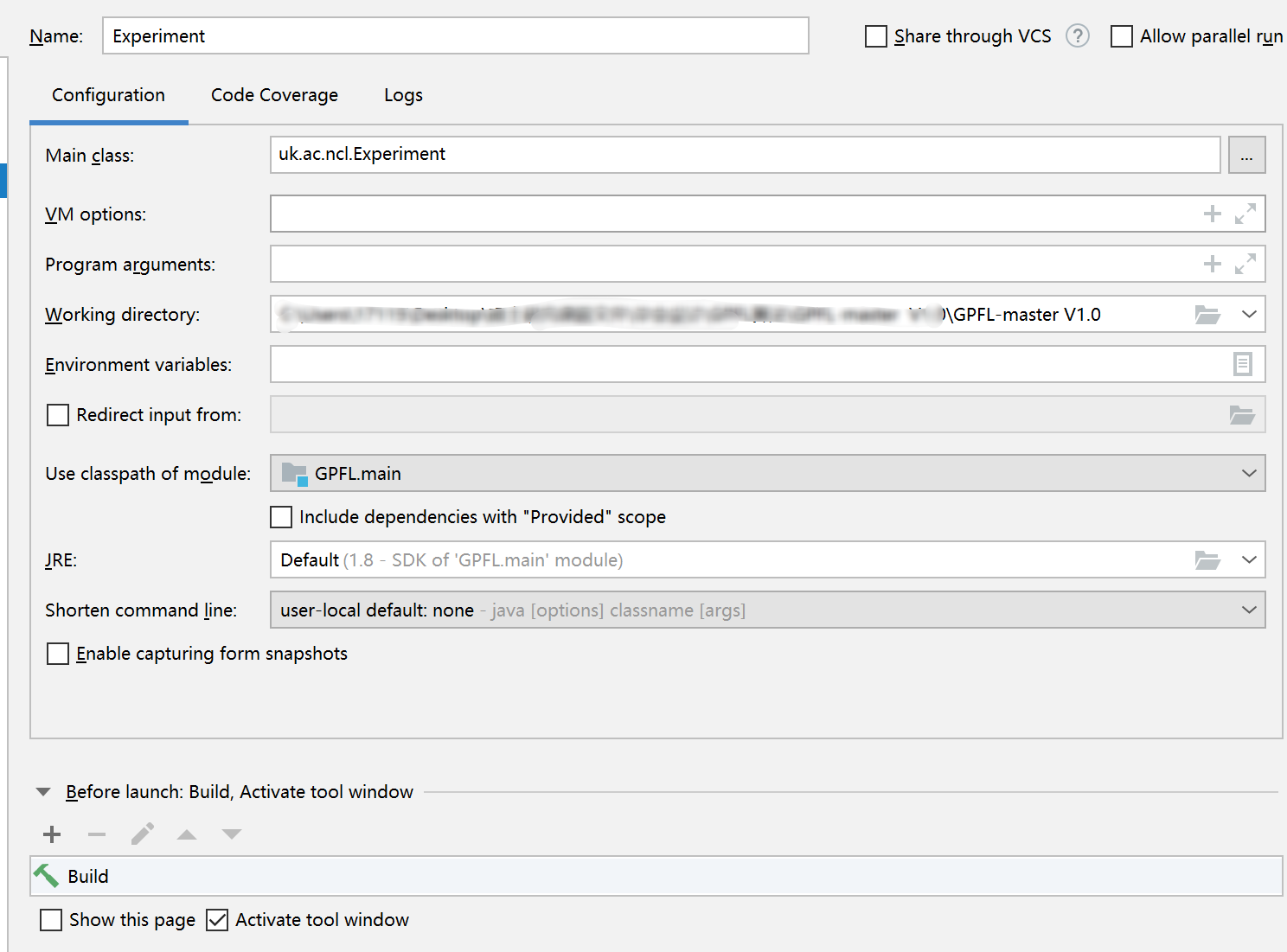
若想获取train.txt
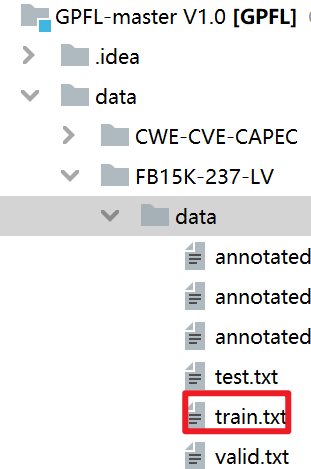
则路径应该写为
File file=new File("data/FB15K-237-LV/databases/graph.db`);
long值的定义
long size=0L;
对map的value值进行排序
public class Sort {
/**
* sort for map's value
* @param map
* @param <K>
* @param <V>
*/
public static <K, V extends Comparable<? super V>> Map<K, V> sortDescend(Map<K, V> map) {
List<Map.Entry<K, V>> list = new ArrayList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
int compare = (o1.getValue()).compareTo(o2.getValue());
return -compare;
}
});
Map<K, V> returnMap = new LinkedHashMap<K, V>();
for (Map.Entry<K, V> entry:list) {
returnMap.put(entry.getKey(), entry.getValue());
}
return returnMap;
}
}
public static <K, V extends Comparable<? super V>> Map<K, V> sortAscend(Map<K, V> map) {
List<Map.Entry<K, V>> list = new ArrayList<Map.Entry<K, V>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
int compare = (o1.getValue()).compareTo(o2.getValue());
return compare;
}
});
Map<K, V> returnMap = new LinkedHashMap<K, V>();
for (Map.Entry<K, V> entry : list) {
returnMap.put(entry.getKey(), entry.getValue());
}
return returnMap;
}
比较String的内容是否相同
public class StringCompare {
public static boolean stringArrayCompare(String[] b, String[] c) {
boolean flag = true;
for(int i=0;i<b.length;i++){
if(b[i]!=c[i]){
flag=false;
break;
}
}
return flag;
}
}
可重复排列
public class Arrangement {
private static ArrayList<String> tmpArr = new ArrayList<>();
public static ArrayList<ArrayList<String>> totalArr= new ArrayList<>();
/**
* 可重复排列
* 类似自己和自己笛卡尔积,类似k层循环拼接的结果,元素个数[arr.len^3]
* @param k 选取的元素个数(k层循环)
* @param arr 数组
*/
public static void repeatableArrangement(int k,String []arr){
if(k==1){
for(int i=0;i<arr.length;i++){
tmpArr.add(arr[i]);
// System.out.print(tmpArr.toString() + ",");
totalArr.add((ArrayList<String>) tmpArr.clone());
tmpArr.remove(tmpArr.size()-1); //移除尾部元素
}
}else if(k >1){
for(int i=0;i<arr.length;i++){
tmpArr.add(arr[i]);
repeatableArrangement(k - 1, arr); //不去重
tmpArr.remove(tmpArr.size()-1); //移除尾部元素,不能用remove(Object),因为它会移除头部出现的元素,我们这里需要移除的是尾部元素
}
}else{
return;
}
}
}
public List<Relation> GenerateRelationList(File home, String[] Targets_to_String) {
/**
* Generate the set of relation
* Add the target combination into the element
* can be repeatable
*/
ArrayList<ArrayList<String>> Relations_String = new ArrayList<>();
Arrangement arrgement = new Arrangement();
for (int k = 1; k <= 3; k++) {
arrgement.repeatableArrangement(k, Targets_to_String);
Relations_String.addAll(arrgement.totalArr);
arrgement.totalArr.clear();
}
List<Relation> relations = new ArrayList<>();
for (ArrayList<String> relation : Relations_String) {
String[] relation1 = relation.toArray(new String[relation.size()]);
relations.add(new Relation(relation1));
}
for (Relation relation : relations) {
/**
* Create File
*/
relation.FilePath = new File(home, "SatisfyPath/" + relation.toString() + ".txt").getPath();
try {
new File(home, "SatisfyPath/" + relation.toString() + ".txt").createNewFile();
// System.out.println("文件创建成功");
} catch (IOException e) {
e.printStackTrace();
}
}
return relations;
}
小数限制为两位
DecimalFormat df = new DecimalFormat("######0.00");
writer.print(df.format(top1)+" ");
对Arraylist的运算
更改某个index的值
top5InLists.set(top5InLists.size()-1,count);
求最小值
Collections.min(top5InLists)
降序排序
Collections.sort(top5InLists,Collections.reverseOrder());
求和与求均值
ArrayList<Long> headhits1=new ArrayList<>();
long finalheadhits1=headhits1.stream().reduce(Long::sum).orElse((long) 0)/targets.size();
字符串的拼接
StringBuffer relation = new StringBuffer();
for (String ele:element) {
relation.append(ele);
}
文件的创建读写和删除
创建
new File(路径).createNewFile();
try {
new File(home, "SatisfyPath/" + relation.toString() + ".txt").createNewFile();
// System.out.println("文件创建成功");
} catch (IOException e) {
e.printStackTrace();
}
拼接路径,前面是File,后面是String。在这个代码里面home是File, "databases/graph.db"是String
File home = new File("data/" + dataset);
File graphFile = new File(home, "databases/graph.db");
写入
用字符串获取路径地址
new File(文件路径).getPath()
String FileString = new File(home, "SatisfyPath/" + relation.toString() + ".txt").getPath();
new PrintWriter(new FileWriter(文件路径,true));
true表示每次写入都在前一次内容的基础上继续写
public static void WriteToFile(String FileString, Path path) throws IOException {
PrintWriter writer = new PrintWriter(new FileWriter(FileString,true));
writer.print(path.startNode().getId()+",");
writer.print(path.endNode().getId());
writer.println();
writer.flush();
writer.close();
}
读取数据
分行读取数据。分行的工具LineIterator来源于org.apache.commons
1.首先获取路径地址
2.借助FileUtils的lineIterator划分文件
3.用逗号划分一行中的内容
File relationFile = new File(relation.FilePath);
LineIterator relationclass = FileUtils.lineIterator(relationFile);//it save head and tail
while (relationclass.hasNext()) {
String[] words = relationclass.next().split(",");
Integer head = Integer.valueOf(words[0]);
Integer tail = Integer.valueOf(words[1]);
}
删除文件
File resultFile = new File(home, "Result/result.txt");
resultFile.delete();
清空文件夹
import java.io.File;
public class DeleteDirTest {
public static void main(String[] args) {
String path = "G:\temp";
deleteDir(path);
}
public static boolean deleteDir(String path){
File file = new File(path);
if(!file.exists()){//判断是否待删除目录是否存在
System.err.println("The dir are not exists!");
return false;
}
String[] content = file.list();//取得当前目录下所有文件和文件夹
for(String name : content){
File temp = new File(path, name);
if(temp.isDirectory()){//判断是否是目录
deleteDir(temp.getAbsolutePath());//递归调用,删除目录里的内容
temp.delete();//删除空目录
}else{
if(!temp.delete()){//直接删除文件
System.err.println("Failed to delete " + name);
}
}
}
return true;
}
}
Multimap
针对一个key多个value值的情况,采用Multimap,来自于包 com.google.guava:guava:28.1-jre
1.首先初始化Multimap。MultimapBuilder.hashKeys().hashSetValues().build()
2.然后就可以用put(key,value)的方式存放数据
Multimap<ArrayList<Integer>, ArrayList<Long>> AnswerCandidates = MultimapBuilder.hashKeys().hashSetValues().build();
ArrayList<Integer> AnswerCandidate = new ArrayList<>();
AnswerCandidate.add(head);
AnswerCandidate.add(tail);
if (AnswerCandidates.containsKey(AnswerCandidate) == false) {
ArrayList<Long> Pxita_Ppath = new ArrayList<>();
Pxita_Ppath.add((long) (Math.random() * 10 + 1));
Pxita_Ppath.add((long) (Math.random() * 10 + 1));
AnswerCandidates.put(AnswerCandidate, Pxita_Ppath);
}
随机数
Math.random()产生0-1之间的小数
限制最大值和最小值,在此范围内生成整数的随机值
int num = min + (int) (Math.random() * (max - min + 1));
记录运行的时间和内存
long startTime = System.currentTimeMillis();
Runtime r = Runtime.getRuntime();
r.gc();
long startMemory = r.freeMemory();
long endTime = System.currentTimeMillis(); //获取结束时间
long Time=endTime - startTime;
System.out.println("Running time:" + (endTime - startTime)/1000 + "s"); //单位秒
long endMemory = r.freeMemory();
long Memory=startMemory - endMemory;
System.out.println("Runtime Memory:" + (startMemory - endMemory)/(1024*1024) + "m"); //单位兆
字符串
字符串与整型的互换
Integer转换成String
Integer a = 2;
String str = String.valueOf(a)
String转换成Integer
String str = "111";
Integer i = null;
if(str!=null){
i = Integer.valueOf(str);
}
字符串的比较
1.比较字符串的对象是否相同
if(str1==str2)
2.比较字符串的内容是否相同
if(str1.equals(str2))
ArrayList
判断ArrayList是否含有某个元素
if(r_template.contains(relations)==false){
continue;
}
判断某个元素在哪一位
r_template.indexOf(relations)
set与list的转换
set.addAll(list);
list.addAll(set);
数组
数组的深拷贝和浅拷贝
深拷贝
只拷贝值,不拷贝地址,修改值原来数组的值不会改变
Integer [] a = {1,2,3};
Integer [] b = Arrays.copyOf(a,a.length);
浅拷贝
拷贝地址,修改值原来数组的值会改变
数组的输出
int nums[] = {1,8,6,7,3,5,4};
System.out.print(Arrays.toString(nums) + "\n");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号