吴恩达深度学习课程五:自然语言处理 第三周:序列模型与注意力机制 课后习题与代码实践
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课第三周的课后习题和代码实践部分。
1.理论习题
【中英】【吴恩达课后测验】Course 5 - 序列模型 - 第三周测验
在这一周的习题内容中有一道题的相关内容需要展开,先看一下题面:
网络通过学习注意力分数来决定「把注意力放在哪里」,这些值是由一个小神经网络计算得到的。
这里,我们不能把 \(s^{<t-1>}\) 替换成 \(s^{<t>}\) 作为这个神经网络的输入,
原因如下:因为 \(s^{<t>}\) 依赖于当前的注意力权重,而当前的注意力权重又依赖于注意力分数,因此在需要计算注意力分数的时刻,\(s^{<t>}\) 尚未被计算出来, 此时只能使用前一时刻的隐藏状态 \(s^{<t-1>}\),而无法使用当前的 \(s^{<t>}\)。
答案:正确
这道题一眼看下来是很迷惑的,这是因为这道题讲的是最早的注意力机制的逻辑,和我们在理论部分介绍的主流逻辑有所不同。
在理论部分,我们介绍的注意力机制,学习注意力分数的网络的输入就是 \(s^{<t>}\) ,但在最早的注意力机制中,它的输入是 \(s^{<t-1>}\)。
其传播逻辑可以用一句话总结:在当前时间步中,原始注意力机制将由上一时刻解码状态计算得到的上下文向量 \(c^{<t>}\) 作为解码器输入的一部分,用于计算当前解码状态 \(s^{<t>}\)。
我们展开如下:
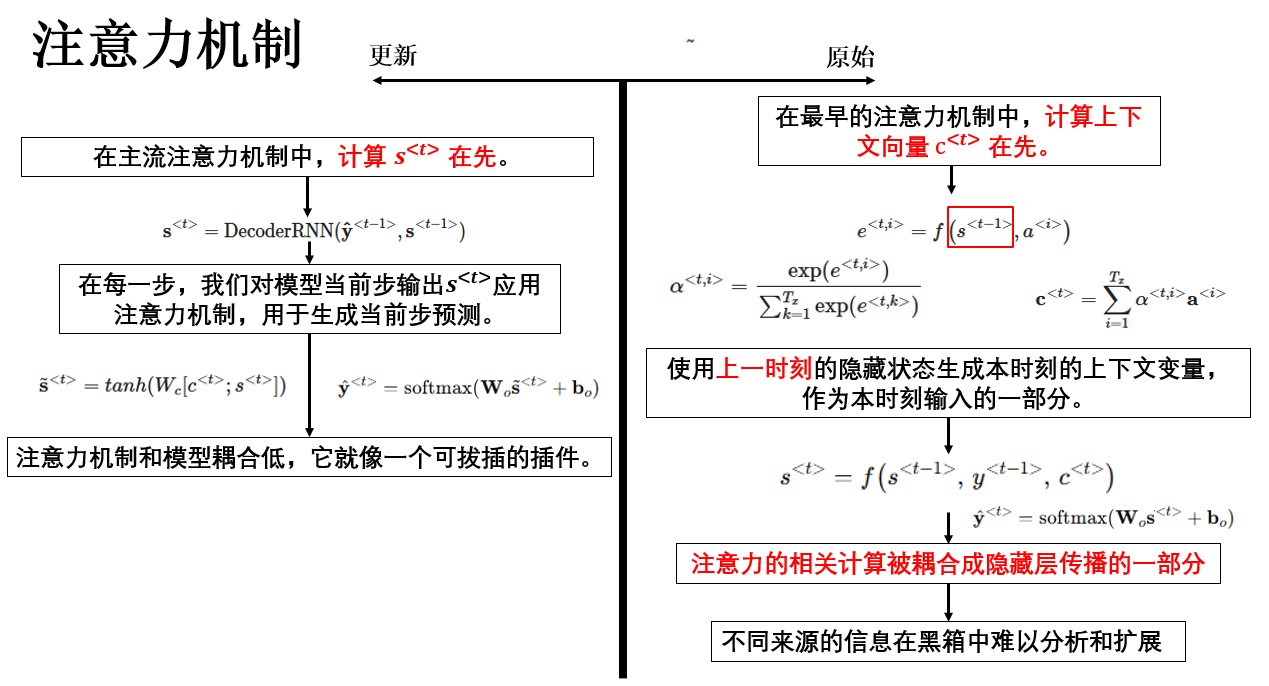
14 年的原论文使用的就是这种传播方式,具有开创性价值。但在现代,这种将上下文向量直接纳入状态递推的做法更多只具有历史意义,了解即可。
2.代码实践
【中文】【吴恩达课后编程作业】Course 5 - 序列模型 - 第三周作业
还是先摆链接,这篇里博主就机器翻译和触发词检测两部分内容,非常详细地演示了本周的内容,但还是要注意 Keras 的导包更新问题。
我们同样使用框架来演示这部分内容,主要内容如下:
- 使用编码解码框架进行日期格式翻译
- 在编码解码框架下对比贪心解码和束搜索性能
- 使用带注意力机制的编码解码框架进行日期格式翻译
2.1 数据准备
需要说明的是,由于 seq2seq 模型自身的编码–解码结构 以及 序列数据的时序特性,这类任务相比许多常规监督学习任务,通常对计算资源有更高的要求。
以机器翻译任务为例,网络上存在大量公开数据集,如英法翻译、中英翻译等。由于这类数据获取相对容易,同时自然语言本身具有词汇规模大、表达形式多样的特点,模型在训练过程中往往需要同时维护源语言词典和目标语言词典,其规模通常至少达到 数万级别。这直接导致模型在参数规模、计算量以及显存占用等方面的成本显著提升。
因此,这次我们选用一种相对简化的机器翻译任务——日期格式翻译,该类任务的主要特点在于词典规模小、输入输出结构清晰、语义歧义极少,可以较高效率地演示本周内容。
这次我们不使用网上公开的数据集,而是拓展吴恩达老师在编程作业里的逻辑,进行人工合成数据。
我们通过设计好的脚本,生成 10000 条 以下格式的相关数据和对应标签并保存为文件:
HUMAN_TEMPLATES = [
"{day} {month} {year}",
"{month} {day}, {year}",
"{day} of {month}, {year}",
"{month} {day} {year}",
"{day}/{month_num}/{year_short}",
"{month_num}/{day}/{year_short}",
"{weekday}, {day} {month_abbr} {year}",
"{month_abbr} {day}th {year_short}",
"{year}-{month_num}-{day}",
"The {day}{day_suffix} of {month}, {year}",
"{day}th {month_abbr}, {year}",
"{month} the {day}{day_suffix}, {year}",
"Date: {year}/{month_num}/{day}",
"{day} in Roman: {roman_day} {month} {year}",
"{month_abbr}. {day}, '{year_short}",
]
完整代码放在附录,打印几条生成数据如下:
[1] The 28th of April, 1975 ==> 1975-04-28
[2] Date: 2017/05/5 ==> 2017-05-05
[3] Jan 10th 44 ==> 1944-01-10
[4] Tuesday, 6 Nov 2096 ==> 2096-11-06
[5] The 26th of August, 2089 ==> 2089-08-26
[6] Date: 2061/08/18 ==> 2061-08-18
[7] 08/4/35 ==> 1935-08-04
[8] 27 of May, 1948 ==> 1948-05-27
[9] 8 of April, 1907 ==> 1907-04-08
[10] November 11, 1937 ==> 1937-11-11
准备好数据后,我们便可以进行下一步内容。
2.2 模型设计
在本周第一篇内容里我们就提到过:编码解码框架下的网络结构实际上是分别设计的两个子网络,在代码逻辑中,就是先分别定义设计编码器和解码器,再在整体网络中调用。我们分点展开如下:
(1)编码器
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim):
super().__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, emb_dim)
# 使用双向 LSTM
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True, bidirectional=True)
def forward(self, x):
embedded = self.embedding(x)
outputs, (hidden, cell) = self.lstm(embedded)
# outputs: LSTM 对每个时间步的输出,用于注意力的相关计算。
# (hidden,cell): 最后时间步的隐藏状态和细胞状态,是解码器的初始输入。
return outputs, (hidden, cell)
(2)解码器
class Decoder(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim, use_attention=False):
super().__init__()
# 设置参数,默认不使用注意力机制
self.use_attention = use_attention
# 嵌入层
self.embedding = nn.Embedding(vocab_size, emb_dim)
# LSTM
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True)
if use_attention:
# 注意力评分层,将解码器 hidden 与编码器 outputs 拼接计算注意力分数
self.attn = nn.Linear(hidden_dim + hidden_dim * 2, 1)
# 注意力结合层:将解码器 hidden 与上下文向量融合为最终 LSTM 输出
self.attn_combine = nn.Linear(hidden_dim + hidden_dim * 2, hidden_dim)
# 输出层:将 LSTM 输出映射到词表维度,预测下一个 token
self.out = nn.Linear(hidden_dim, vocab_size)
def forward(self, input_step, hidden_cell, encoder_outputs):
embedded = self.embedding(input_step)
# LSTM 前向计算,得到当前时间步输出和新的 hidden/cell
lstm_out, hidden_cell = self.lstm(embedded, hidden_cell)
# 去掉时间维度,方便注意力计算
query = lstm_out.squeeze(1)
if self.use_attention:
# 扩展 query,实际上就是把当前解码隐藏状态复制到和编码隐藏状态数相同。
query_exp = query.unsqueeze(1).repeat(1, encoder_outputs.size(1), 1)
# 计算注意力分数
attn_scores = self.attn(torch.cat((query_exp, encoder_outputs), dim=-1)).squeeze(-1)
# 转为注意力权重
attn_weights = F.softmax(attn_scores, dim=-1).unsqueeze(1)
# 计算上下文向量 bmm:批量矩阵乘法
context = torch.bmm(attn_weights, encoder_outputs).squeeze(1)
# 将 query 与上下文向量融合
combined = torch.cat((query, context), dim=1)
output = torch.tanh(self.attn_combine(combined))
else:
# 不使用注意力时,直接用 LSTM 输出预测
output = query
# 输出层
output = self.out(output)
return output, hidden_cell
(3)整体网络
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
# 编码器和解码器直接作为初始化参数,在主函数中创建传入
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt):
# src:样本 tgt:标签
# 编码器
enc_outputs, (hidden, cell) = self.encoder(src)
# 这里是合并双向 LSTM 的 hidden/cell
# 将两个方向的 hidden/cell 在层维度上分开,再求和或拼接作为解码器初始状态
hidden = hidden.view(2, -1, hidden.size(-1)).sum(dim=0, keepdim=True)
cell = cell.view(2, -1, cell.size(-1)).sum(dim=0, keepdim=True)
dec_hidden = (hidden, cell) # 解码器初始状态
outputs = [] # 存储每个时间步的输出
# 解码器
for t in range(tgt.size(1)):
# 训练逻辑:每步使用真实标签作为输入
out, dec_hidden = self.decoder(
tgt[:, t].unsqueeze(1), dec_hidden, enc_outputs
)
# tgt[:, t] 因为批次训练,每次要去取第 t 列
# out: 当前时间步预测的 token 概率分布 [batch_size, vocab_size]
# dec_hidden: 更新后的解码器隐藏状态
outputs.append(out) # 保存当前输出
# 将所有时间步输出堆叠为最终结果。
return torch.stack(outputs, dim=1)
这样我们就完成了模型的设计,继续下一部分内容。
2.3 解码函数
还是理论部分提到的,在推理阶段,解码器的输出其实是一系列的概率分布,我们使用解码函数,就是设计相应的搜索策略来寻找最大的联合概率,得到最终输出。
这里,我们定义完整的解码函数,主逻辑为贪心解码,补充束搜索的相关逻辑并通过参数选择是否使用:
def decode(model, input_tensor, use_beam_search=False, beam_width=3, max_len=20):
"""
参数:
- model: 已训练的 Seq2Seq 模型(包含 encoder 和 decoder)
- input_tensor: 输入序列的 tensor(一个样本)
- use_beam_search: 是否使用束搜索
- beam_width: 束搜索时的候选数量
- max_len: 解码最大长度
"""
model.eval() # 评估模式
with torch.no_grad():
input_tensor = input_tensor.unsqueeze(0)
# 编码器传播
enc_outputs, (hidden, cell) = model.encoder(input_tensor)
hidden = hidden.view(2, -1, hidden.size(-1)).sum(dim=0, keepdim=True)
cell = cell.view(2, -1, cell.size(-1)).sum(dim=0, keepdim=True)
dec_hidden = (hidden, cell) # 解码器初始状态
# 贪心解码
if not use_beam_search:
# 初始解码输入:SOS:初始符,这里是简化为了 \t
dec_input = torch.tensor([[target_token_index['\t']]], device=device)
result = []
for _ in range(max_len):
# 解码器传播
out, dec_hidden = model.decoder(dec_input, dec_hidden, enc_outputs)
# 取当前时间步最大概率的 token
pred = out.argmax(dim=-1)
token = pred.item()
if token == target_token_index['\n']: # 遇到 EOS 停止,同样简化为\n
break
result.append(reverse_target_char_index[token]) # 保存字符
dec_input = pred.unsqueeze(0) # 下一步输入为当前预测,即自回归。
return ''.join(result) # 返回解码后的字符串
# 束搜索
candidates = [([target_token_index['\t']], 0.0, dec_hidden)] # 初始化候选序列
for _ in range(max_len):
new_cands = []
for seq, score, h in candidates:
# 如果序列已遇到 EOS,保留候选
if seq[-1] == target_token_index['\n']:
new_cands.append((seq, score, h))
continue
# 当前时间步输入
inp = torch.tensor([[seq[-1]]], device=device)
out, new_h = model.decoder(inp, h, enc_outputs)
# 计算 log 概率
log_probs = F.log_softmax(out, dim=-1).squeeze(0)
# 取 top-k 候选
top_vals, top_idx = log_probs.topk(beam_width)
for v, idx in zip(top_vals, top_idx):
new_seq = seq + [idx.item()] # 扩展序列
new_score = score + v.item() # 更新累积 log 概率
new_cands.append((new_seq, new_score, new_h))
# 按累积概率排序,保留前 beam_width 个序列
candidates = sorted(new_cands, key=lambda x: x[1], reverse=True)[:beam_width]
# 最终选择概率最高的序列
best = candidates[0][0]
# 去掉控制符,转换为最终字符
return ''.join(reverse_target_char_index.get(i, '')
for i in best[1:] if i != target_token_index['\n'])
解码的逻辑也被使用在之后的评估环节中。
2.4 评估指标:BELU 和完全匹配率
自然,在完成训练后,我们要有相应的指标来进行评估,首先就是我们在理论部分介绍的 BELU ,它通过计算输出和标签在不同尺度上的匹配度来评估模型效果。
但是,我们说:BELU 这类语言指标使用的原因是因为存在”同义不同形“的情况。
而在日期翻译里,翻译结果是唯一的:错一个数字就是完全不同的一天。
因此,我们再手工定义一个完全匹配率:输出和标签只有相同和不相同两种情况。
这样,我们使用 BELU 来评估序列模型拟合的大致效果,再用完全匹配率来观察在日期翻译任务中模型的真正性能。
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
# BLEU
def evaluate_bleu(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
total_bleu = 0
# BLEU 平滑方法,避免短句导致分数过低
smoother = SmoothingFunction().method4
for i in range(len(test_enc_input)):
# 使用 decode 函数生成预测序列
pred = decode(model, test_enc_input[i], use_beam_search, beam_width)
# 去掉目标序列的起始符和结束符
true = test_targets[i][1:-1]
# BLEU 接受列表形式:ref 是参考序列列表,hyp 是预测序列
ref = [list(true)]
hyp = list(pred)
# 计算当前样本 BLEU 分数
bleu = sentence_bleu(ref, hyp, smoothing_function=smoother)
total_bleu += bleu
# 平均 BLEU 分数,并转换为百分比
avg_bleu = total_bleu / len(test_enc_input) * 100
print(f"BLEU: {avg_bleu:.2f}")
return avg_bleu
# 完全匹配率
def evaluate_exact_match(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
correct = 0
total = len(test_enc_input)
for i in range(total):
pred = decode(model, test_enc_input[i], use_beam_search, beam_width)
true = test_targets[i][1:-1]
# 判断预测与真实是否完全一致
if pred == true:
correct += 1
acc = correct / total * 100
print(f"完全匹配率: {acc:.2f}%")
return acc
这里分开写两个指标方便演示和单独调用,实际上,把二者的前半部分逻辑合在一起是更高效的做法。
到此,需要强调的部分就全部定义完毕,我们开始正式运行。
2.5 运行效果
我们设置参数如下:
EMB_DIM = 64
HIDDEN_DIM = 256
EPOCHS = 10
BATCH_SIZE = 128
LR = 0.001
下面,就来分情况看看效果:
(1)不使用注意力机制,使用贪心解码
在这个条件下,我们定义主函数如下:
if __name__ == "__main__":
EMB_DIM = 64
HIDDEN_DIM = 256
EPOCHS = 10
BATCH_SIZE = 128
LR = 0.001
# 关键设置
USE_ATTENTION = False
USE_BEAM_SEARCH = False
BEAM_WIDTH = 3
print(f"\n=== 配置 ===")
print(f"使用注意力: {USE_ATTENTION}")
print(f"使用束搜索: {USE_BEAM_SEARCH} (beam width = {BEAM_WIDTH if USE_BEAM_SEARCH else 'No'})")
encoder = Encoder(num_encoder_tokens, EMB_DIM, HIDDEN_DIM).to(device)
decoder = Decoder(num_decoder_tokens, EMB_DIM, HIDDEN_DIM, use_attention=USE_ATTENTION).to(device)
model = Seq2Seq(encoder, decoder).to(device)
print("\n开始训练...")
train_time = train(model, epochs=EPOCHS, batch_size=BATCH_SIZE, lr=LR)
print("\n评估中...")
bleu = evaluate_bleu(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
exact_acc = evaluate_exact_match(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print("\n=== 抽取测试样本输出 ===")
sample_indices = random.sample(range(len(test_encoder_input)), 10)
for i in sample_indices:
src = test_inputs[i]
true = test_targets[i][1:-1]
pred,_ = decode(model, test_encoder_input[i],
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print(f"Human : {src} | True : {true} | Predicted : {pred}")
结果如下:
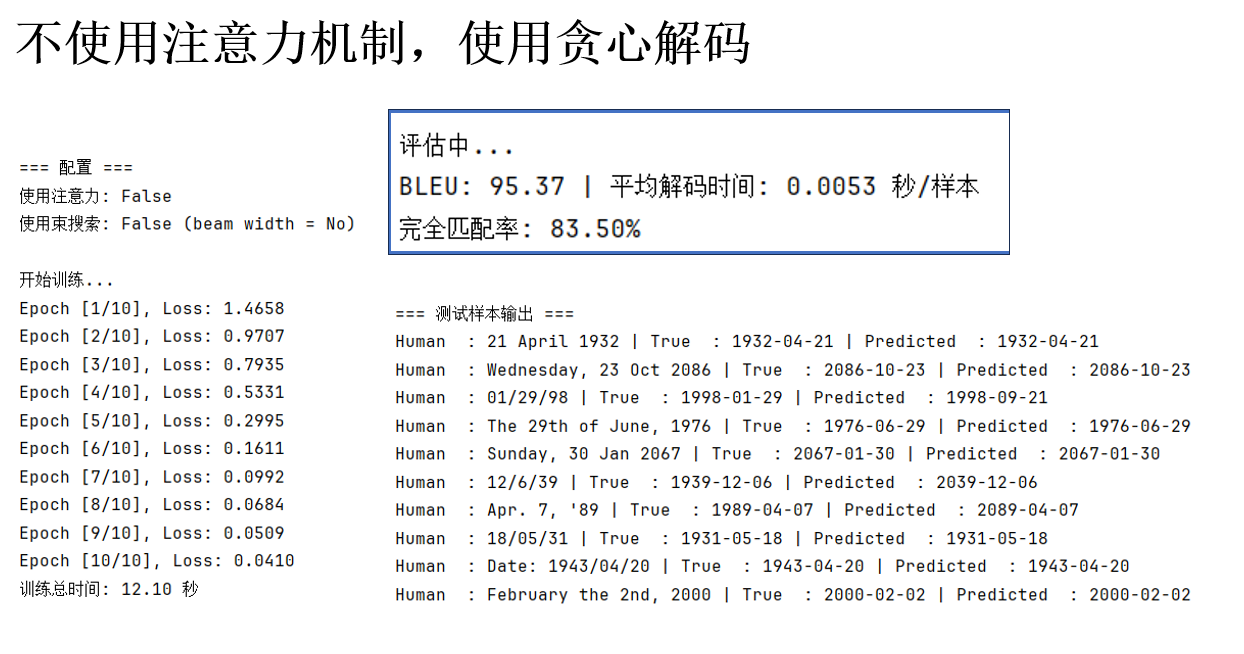
得益于任务本身和合成数据较为简单,可以发现指标还不错,我们不着急分析 ,继续下一步设置进行对比。
(2)不使用注意力机制,使用束搜索
这次,设置主函数参数如下:
USE_ATTENTION = False
USE_BEAM_SEARCH = True # 使用束搜索
BEAM_WIDTH = 3 # 束宽
看看结果:
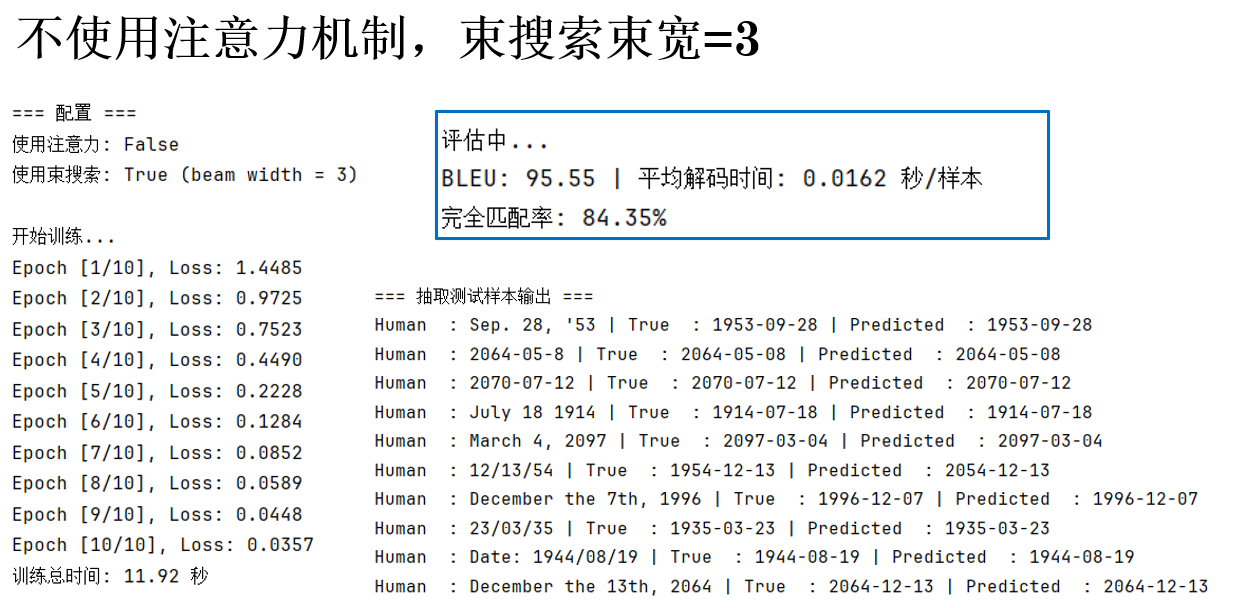
指标好像有所提升,但也可能是训练中的偶然性,我们再增加束宽看看:
BEAM_WIDTH = 10
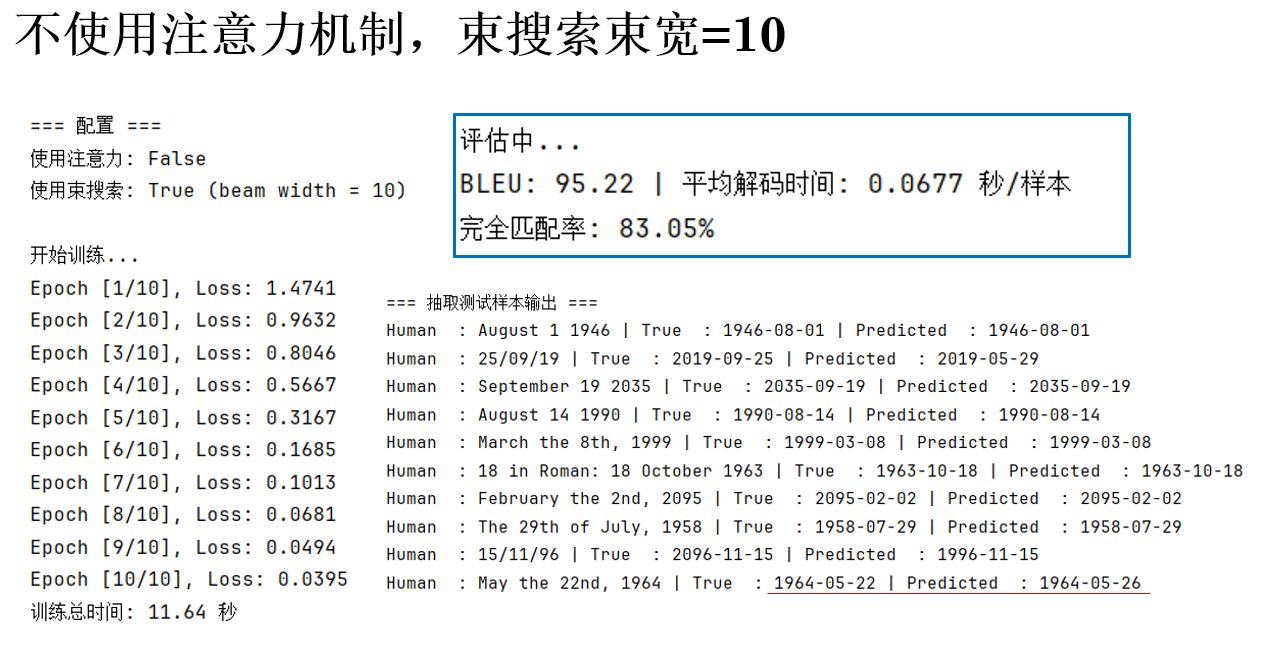
可以发现,随着束宽的增加,解码时间明显增加,而指标浮动不大,这说明限制指标的关键因素可能不是搜索策略。
由此,我们进入下一步:
(3)使用注意力机制
现在,设置参数如下:
USE_ATTENTION = True # 使用注意力机制
USE_BEAM_SEARCH = True
BEAM_WIDTH = 3
看看结果:
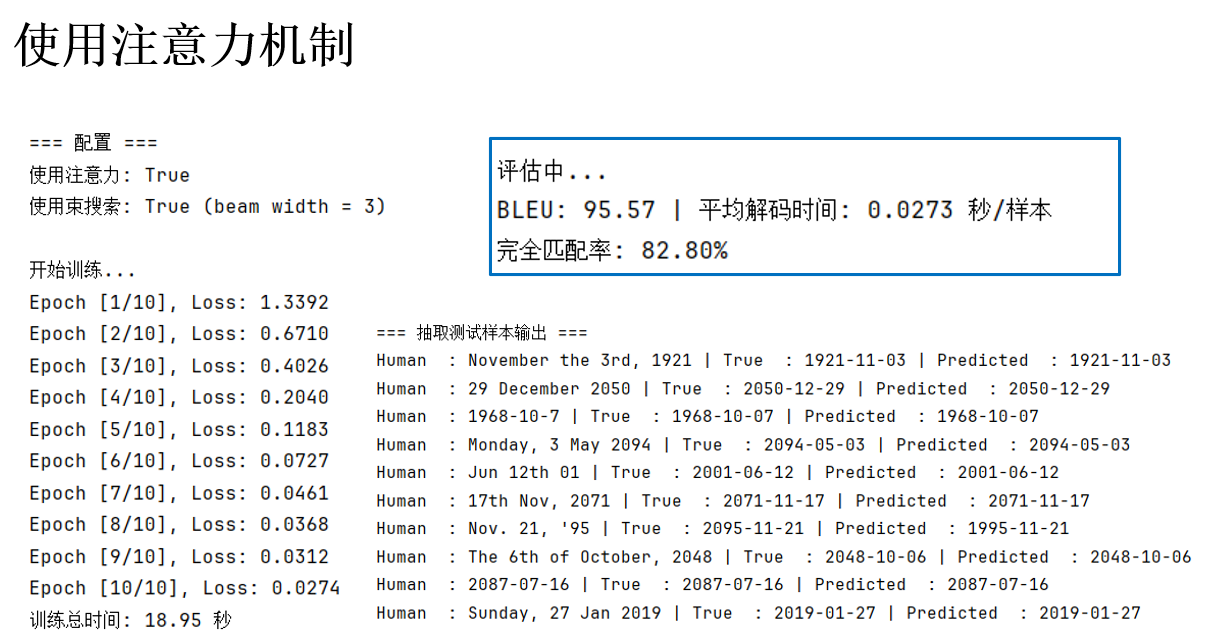
好像也没什么用啊? 你会发现:使用注意力机制后,训练时间因相关计算明显增加,但是指标并没有明显提升。
实际上,这和我们的日期翻译任务本身的特点有关:
- 输入输出序列较短:每个样本通常只有 5~15 个字符左右,LSTM 很容易在没有注意力的情况下就捕捉到序列整体信息。
- 信息对齐较简单:日期翻译本质上是字符级的对齐映射,例如 “Jan 5, 2003” → “2003-01-05”,几乎不存在复杂的长距离依赖。
注意力机制最明显的作用是在序列较长或输入输出关系复杂时,帮助解码器聚焦到相关的编码状态。而对于现在这种短序列、规则性强的任务,其计算成本增加,而带来的性能提升很有限。
在这个任务中,想要指标继续增加,有一个很简单的方法就是在脚本中增加我们人工合成的数据量,就不再展示了。
至此,吴恩达深度学习课程五课十五周的内容就全部结束了,之后会出一个完整的目录。
3. 附录
3.1 数据合成
import torch
import random
import numpy as np
from datetime import datetime, timedelta
from sklearn.model_selection import train_test_split
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
PAD_TOKEN = "<PAD>"
MONTHS_FULL = [
"January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November", "December"
]
MONTHS_ABBR = ["Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
HUMAN_TEMPLATES = [
"{day} {month} {year}",
"{month} {day}, {year}",
"{day} of {month}, {year}",
"{month} {day} {year}",
"{day}/{month_num}/{year_short}",
"{month_num}/{day}/{year_short}",
"{weekday}, {day} {month_abbr} {year}",
"{month_abbr} {day}th {year_short}",
"{year}-{month_num}-{day}",
"The {day}{day_suffix} of {month}, {year}",
"{day}th {month_abbr}, {year}",
"{month} the {day}{day_suffix}, {year}",
"Date: {year}/{month_num}/{day}",
"{day} in Roman: {roman_day} {month} {year}",
"{month_abbr}. {day}, '{year_short}",
]
def roman_numeral(n):
vals = (10, 9, 5, 4, 1)
nums = ('X', 'IX', 'V', 'IV', 'I')
result = ""
for v, r in zip(vals, nums):
while n >= v:
result += r
n -= v
return result
def random_date(start_year=1900, end_year=2100):
start = datetime(start_year, 1, 1)
end = datetime(end_year, 12, 31)
delta = end - start
return start + timedelta(days=random.randint(0, delta.days))
def human_readable_date(date):
template = random.choice(HUMAN_TEMPLATES)
day = date.day
month_idx = date.month - 1
month_full = MONTHS_FULL[month_idx]
month_abbr = MONTHS_ABBR[month_idx]
year = date.year
month_num = str(date.month).zfill(2)
year_short = str(year % 100).zfill(2)
weekday = date.strftime("%A")
day_suffix = "th"
if day % 10 == 1 and day != 11: day_suffix = "st"
elif day % 10 == 2 and day != 12: day_suffix = "nd"
elif day % 10 == 3 and day != 13: day_suffix = "rd"
day_str = str(day)
roman_day = roman_numeral(day) if random.random() < 0.2 else day_str
return template.format(
day=day_str,
day_suffix=day_suffix,
month=month_full,
month_abbr=month_abbr,
year=year,
month_num=month_num,
year_short=year_short,
weekday=weekday,
roman_day=roman_day
)
def machine_readable_date(date):
return date.strftime("%Y-%m-%d")
def generate_date_pair():
d = random_date()
return human_readable_date(d), machine_readable_date(d)
NUM_SAMPLES = 10000
input_texts, target_texts = [], []
for _ in range(NUM_SAMPLES):
human, machine = generate_date_pair()
input_texts.append(human)
target_texts.append('\t' + machine + '\n')
train_inputs, test_inputs, train_targets, test_targets = train_test_split(
input_texts, target_texts, test_size=0.2, random_state=42
)
all_input_chars = [PAD_TOKEN] + sorted(set(''.join(input_texts)))
all_target_chars = [PAD_TOKEN] + sorted(set(''.join(target_texts)))
input_token_index = {c: i for i, c in enumerate(all_input_chars)}
target_token_index = {c: i for i, c in enumerate(all_target_chars)}
reverse_input_char_index = {i: c for c, i in input_token_index.items()}
reverse_target_char_index = {i: c for c, i in target_token_index.items()}
max_encoder_len = max(len(txt) for txt in input_texts)
max_decoder_len = max(len(txt) for txt in target_texts)
num_encoder_tokens = len(all_input_chars)
num_decoder_tokens = len(all_target_chars)
print(f"max enc len: {max_encoder_len}, max dec len: {max_decoder_len}")
print(f"input vocab size: {num_encoder_tokens}, target vocab size: {num_decoder_tokens}")
def texts_to_tensor(texts, token_index, max_len):
pad_idx = token_index[PAD_TOKEN]
data = np.full((len(texts), max_len), pad_idx, dtype=np.int64)
for i, txt in enumerate(texts):
for t, char in enumerate(txt):
if t < max_len:
data[i, t] = token_index[char]
return torch.tensor(data, dtype=torch.long, device=device)
train_encoder_input = texts_to_tensor(train_inputs, input_token_index, max_encoder_len)
train_decoder_input = texts_to_tensor(train_targets, target_token_index, max_decoder_len)
test_encoder_input = texts_to_tensor(test_inputs, input_token_index, max_encoder_len)
test_decoder_input = texts_to_tensor(test_targets, target_token_index, max_decoder_len)
dataset_pt = {
'train_encoder_input': train_encoder_input,
'train_decoder_input': train_decoder_input,
'test_encoder_input': test_encoder_input,
'test_decoder_input': test_decoder_input,
'input_token_index': input_token_index,
'target_token_index': target_token_index,
'reverse_input_char_index': reverse_input_char_index,
'reverse_target_char_index': reverse_target_char_index,
'max_encoder_len': max_encoder_len,
'max_decoder_len': max_decoder_len,
'num_encoder_tokens': num_encoder_tokens,
'num_decoder_tokens': num_decoder_tokens
}
torch.save(dataset_pt, "date_dataset.pt")
print("已保存:date_dataset.pt")
def tensor_to_numpy(t):
return t.detach().cpu().numpy()
dataset_npz = {
"train_encoder_input": tensor_to_numpy(train_encoder_input),
"train_decoder_input": tensor_to_numpy(train_decoder_input),
"test_encoder_input": tensor_to_numpy(test_encoder_input),
"test_decoder_input": tensor_to_numpy(test_decoder_input),
"input_token_index": np.array(input_token_index, dtype=object),
"target_token_index": np.array(target_token_index, dtype=object),
"reverse_input_char_index": np.array(reverse_input_char_index, dtype=object),
"reverse_target_char_index": np.array(reverse_target_char_index, dtype=object),
"max_encoder_len": max_encoder_len,
"max_decoder_len": max_decoder_len,
"num_encoder_tokens": num_encoder_tokens,
"num_decoder_tokens": num_decoder_tokens
}
np.savez("date_dataset.npz", **dataset_npz)
print("已保存:date_dataset.npz\n")
def decode(tensor_row, reverse_dict):
return ''.join(
reverse_dict[idx.item()]
for idx in tensor_row
if reverse_dict[idx.item()] != PAD_TOKEN
)
print("示例数据:")
for i in range(20):
src = decode(train_encoder_input[i], reverse_input_char_index)
tgt = decode(train_decoder_input[i], reverse_target_char_index)
print(f"[{i+1}] {src} ==> {tgt.strip()}")
3.2 日期格式翻译-PyTorch版
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
import time
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data = torch.load("date_dataset.pt", map_location=device)
train_encoder_input = data['train_encoder_input']
train_decoder_input = data['train_decoder_input']
test_encoder_input = data['test_encoder_input']
test_decoder_input = data['test_decoder_input']
input_token_index = data['input_token_index']
target_token_index = data['target_token_index']
reverse_target_char_index = data['reverse_target_char_index']
num_encoder_tokens = data['num_encoder_tokens']
num_decoder_tokens = data['num_decoder_tokens']
max_encoder_len = data['max_encoder_len']
max_decoder_len = data['max_decoder_len']
PAD_TOKEN = "<PAD>"
reverse_input_char_index = {i: c for c, i in input_token_index.items()}
def tensor_to_text(tensor_row, reverse_dict):
return ''.join(
reverse_dict[idx.item()]
for idx in tensor_row
if reverse_dict[idx.item()] != PAD_TOKEN
)
test_inputs = [tensor_to_text(test_encoder_input[i], reverse_input_char_index)
for i in range(len(test_encoder_input))]
test_targets = [tensor_to_text(test_decoder_input[i], reverse_target_char_index)
for i in range(len(test_decoder_input))]
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True, bidirectional=True)
def forward(self, x):
embedded = self.embedding(x)
outputs, (hidden, cell) = self.lstm(embedded)
return outputs, (hidden, cell)
class Decoder(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim, use_attention=False):
super().__init__()
self.use_attention = use_attention
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True)
if use_attention:
self.attn = nn.Linear(hidden_dim + hidden_dim * 2, 1)
self.attn_combine = nn.Linear(hidden_dim + hidden_dim * 2, hidden_dim)
self.out = nn.Linear(hidden_dim, vocab_size)
def forward(self, input_step, hidden_cell, encoder_outputs):
embedded = self.embedding(input_step)
lstm_out, hidden_cell = self.lstm(embedded, hidden_cell)
query = lstm_out.squeeze(1)
if self.use_attention:
query_exp = query.unsqueeze(1).repeat(1, encoder_outputs.size(1), 1)
attn_scores = self.attn(torch.cat((query_exp, encoder_outputs), dim=-1)).squeeze(-1)
attn_weights = F.softmax(attn_scores, dim=-1).unsqueeze(1)
context = torch.bmm(attn_weights, encoder_outputs).squeeze(1)
combined = torch.cat((query, context), dim=1)
output = torch.tanh(self.attn_combine(combined))
else:
output = query
output = self.out(output)
return output, hidden_cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt):
enc_outputs, (hidden, cell) = self.encoder(src)
hidden = hidden.view(2, -1, hidden.size(-1)).sum(dim=0, keepdim=True)
cell = cell.view(2, -1, cell.size(-1)).sum(dim=0, keepdim=True)
dec_hidden = (hidden, cell)
outputs = []
for t in range(tgt.size(1)):
out, dec_hidden = self.decoder(tgt[:, t].unsqueeze(1), dec_hidden, enc_outputs)
outputs.append(out)
return torch.stack(outputs, dim=1)
def train(model, epochs=10, batch_size=128, lr=0.001):
enc_optimizer = optim.Adam(model.encoder.parameters(), lr=lr)
dec_optimizer = optim.Adam(model.decoder.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss(ignore_index=0)
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
num_batches = 0
perm = torch.randperm(len(train_encoder_input))
for i in range(0, len(train_encoder_input), batch_size):
idx = perm[i:i+batch_size]
enc_in = train_encoder_input[idx]
dec_in_full = train_decoder_input[idx]
dec_in = dec_in_full[:, :-1]
dec_target = dec_in_full[:, 1:]
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
outputs = model(enc_in, dec_in)
loss = criterion(outputs.reshape(-1, num_decoder_tokens), dec_target.reshape(-1))
loss.backward()
enc_optimizer.step()
dec_optimizer.step()
total_loss += loss.item()
num_batches += 1
avg_loss = total_loss / num_batches
print(f"Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}")
train_time = time.time() - start_time
print(f"训练总时间: {train_time:.2f} 秒")
return train_time
import time
def decode(model, input_tensor, use_beam_search=False, beam_width=3, max_len=20):
model.eval()
start_time = time.time()
with torch.no_grad():
input_tensor = input_tensor.unsqueeze(0)
enc_outputs, (hidden, cell) = model.encoder(input_tensor)
hidden = hidden.view(2, -1, hidden.size(-1)).sum(dim=0, keepdim=True)
cell = cell.view(2, -1, cell.size(-1)).sum(dim=0, keepdim=True)
dec_hidden = (hidden, cell)
if not use_beam_search:
dec_input = torch.tensor([[target_token_index['\t']]], device=device)
result = []
for _ in range(max_len):
out, dec_hidden = model.decoder(dec_input, dec_hidden, enc_outputs)
pred = out.argmax(dim=-1)
token = pred.item()
if token == target_token_index['\n']:
break
result.append(reverse_target_char_index[token])
dec_input = pred.unsqueeze(0)
decoded = ''.join(result)
else:
candidates = [([target_token_index['\t']], 0.0, dec_hidden)]
for _ in range(max_len):
new_cands = []
for seq, score, h in candidates:
if seq[-1] == target_token_index['\n']:
new_cands.append((seq, score, h))
continue
inp = torch.tensor([[seq[-1]]], device=device)
out, new_h = model.decoder(inp, h, enc_outputs)
log_probs = F.log_softmax(out, dim=-1).squeeze(0)
k = min(beam_width, log_probs.size(0))
top_vals, top_idx = log_probs.topk(k)
for v, idx in zip(top_vals, top_idx):
new_seq = seq + [idx.item()]
new_score = score + v.item()
new_cands.append((new_seq, new_score, new_h))
candidates = sorted(new_cands, key=lambda x: x[1], reverse=True)[:beam_width]
best = candidates[0][0]
decoded = ''.join(reverse_target_char_index.get(i, '') for i in best[1:] if i != target_token_index['\n'])
decode_time = time.time() - start_time
return decoded, decode_time
def evaluate_bleu(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
total_bleu = 0
total_time = 0
smoother = SmoothingFunction().method4
for i in range(len(test_enc_input)):
pred, dt = decode(model, test_enc_input[i], use_beam_search, beam_width)
total_time += dt
true = test_targets[i][1:-1]
ref = [list(true)]
hyp = list(pred)
bleu = sentence_bleu(ref, hyp, smoothing_function=smoother)
total_bleu += bleu
avg_bleu = total_bleu / len(test_enc_input) * 100
avg_time = total_time / len(test_enc_input)
print(f"BLEU: {avg_bleu:.2f} | 平均解码时间: {avg_time:.4f} 秒/样本")
return avg_bleu, avg_time
def evaluate_exact_match(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
correct = 0
total = len(test_enc_input)
for i in range(total):
pred, _ = decode(model, test_enc_input[i], use_beam_search, beam_width)
true = test_targets[i][1:-1]
if pred == true:
correct += 1
acc = correct / total * 100
print(f"完全匹配率: {acc:.2f}%")
return acc
if __name__ == "__main__":
EMB_DIM = 64
HIDDEN_DIM = 256
EPOCHS = 10
BATCH_SIZE = 128
LR = 0.001
USE_ATTENTION = True
USE_BEAM_SEARCH = True
BEAM_WIDTH = 3
print(f"\n=== 配置 ===")
print(f"使用注意力: {USE_ATTENTION}")
print(f"使用束搜索: {USE_BEAM_SEARCH} (beam width = {BEAM_WIDTH if USE_BEAM_SEARCH else 'No'})")
encoder = Encoder(num_encoder_tokens, EMB_DIM, HIDDEN_DIM).to(device)
decoder = Decoder(num_decoder_tokens, EMB_DIM, HIDDEN_DIM, use_attention=USE_ATTENTION).to(device)
model = Seq2Seq(encoder, decoder).to(device)
print("\n开始训练...")
train_time = train(model, epochs=EPOCHS, batch_size=BATCH_SIZE, lr=LR)
print("\n评估中...")
bleu = evaluate_bleu(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
exact_acc = evaluate_exact_match(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print("\n=== 抽取测试样本输出 ===")
sample_indices = random.sample(range(len(test_encoder_input)), 10)
for i in sample_indices:
src = test_inputs[i]
true = test_targets[i][1:-1]
pred,_ = decode(model, test_encoder_input[i],
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print(f"Human : {src} | True : {true} | Predicted : {pred}")
3.3 日期格式翻译-TF版
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
import random
import time
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
dataset = np.load("date_dataset.npz", allow_pickle=True)
train_encoder_input = dataset['train_encoder_input']
train_decoder_input = dataset['train_decoder_input']
test_encoder_input = dataset['test_encoder_input']
test_decoder_input = dataset['test_decoder_input']
input_token_index = dataset['input_token_index'].item()
target_token_index = dataset['target_token_index'].item()
reverse_target_char_index = dataset['reverse_target_char_index'].item()
num_encoder_tokens = int(dataset['num_encoder_tokens'])
num_decoder_tokens = int(dataset['num_decoder_tokens'])
max_encoder_len = int(dataset['max_encoder_len'])
max_decoder_len = int(dataset['max_decoder_len'])
reverse_input_char_index = {i: c for c, i in input_token_index.items()}
PAD_TOKEN = "<PAD>"
def tensor_to_text(tensor_row, reverse_dict):
return ''.join(
reverse_dict.get(int(idx), '')
for idx in tensor_row
if reverse_dict.get(int(idx), '') != PAD_TOKEN
)
test_inputs = [tensor_to_text(test_encoder_input[i], reverse_input_char_index)
for i in range(len(test_encoder_input))]
test_targets = [tensor_to_text(test_decoder_input[i], reverse_target_char_index)
for i in range(len(test_decoder_input))]
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, emb_dim, hidden_dim):
super(Encoder, self).__init__()
self.embedding = Embedding(vocab_size, emb_dim, mask_zero=True)
self.lstm = Bidirectional(
LSTM(hidden_dim, return_sequences=True, return_state=True)
)
def call(self, x):
embedded = self.embedding(x)
outputs, fw_h, fw_c, bw_h, bw_c = self.lstm(embedded)
hidden = tf.concat([fw_h, bw_h], axis=-1)
cell = tf.concat([fw_c, bw_c], axis=-1)
return outputs, (hidden, cell)
class Decoder(tf.keras.layers.Layer):
def __init__(self, vocab_size, emb_dim, hidden_dim, use_attention=False):
super(Decoder, self).__init__()
self.use_attention = use_attention
self.embedding = Embedding(vocab_size, emb_dim, mask_zero=True)
self.lstm = LSTM(hidden_dim, return_sequences=False, return_state=True)
self.out = Dense(vocab_size)
if use_attention:
self.attn_W1 = Dense(hidden_dim)
self.attn_W2 = Dense(hidden_dim)
self.attn_V = Dense(1)
self.attn_combine = Dense(hidden_dim)
def call(self, input_step, hidden_cell, encoder_outputs):
embedded = self.embedding(input_step)
lstm_out, h, c = self.lstm(embedded, initial_state=hidden_cell)
query = lstm_out
if self.use_attention:
score = self.attn_V(
tf.tanh(
self.attn_W1(encoder_outputs) +
self.attn_W2(query[:, tf.newaxis, :])
)
)
attn_weights = tf.nn.softmax(score, axis=1)
context = tf.reduce_sum(encoder_outputs * attn_weights, axis=1)
combined = tf.concat([query, context], axis=-1)
output = tf.tanh(self.attn_combine(combined))
else:
output = query
logits = self.out(output)
return logits, (h, c)
class Seq2Seq(tf.keras.Model):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def call(self, src, tgt, training=True):
enc_outputs, (hidden, cell) = self.encoder(src)
hidden_fw, hidden_bw = tf.split(hidden, num_or_size_splits=2, axis=-1)
cell_fw, cell_bw = tf.split(cell, num_or_size_splits=2, axis=-1)
hidden = hidden_fw + hidden_bw
cell = cell_fw + cell_bw
dec_hidden = (hidden, cell)
outputs = []
for t in range(tgt.shape[1]):
step_input = tgt[:, t:t + 1]
logits, dec_hidden = self.decoder(
step_input, dec_hidden, enc_outputs
)
outputs.append(logits)
return tf.stack(outputs, axis=1)
def train(model, epochs=10, batch_size=128, lr=0.001):
optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
start_time = time.time()
n_samples = len(train_encoder_input)
for epoch in range(epochs):
total_loss = 0.0
num_batches = 0
indices = np.random.permutation(n_samples)
enc = train_encoder_input[indices]
dec = train_decoder_input[indices]
for i in range(0, n_samples, batch_size):
enc_batch = enc[i:i + batch_size]
dec_batch = dec[i:i + batch_size]
dec_in = dec_batch[:, :-1]
dec_tgt = dec_batch[:, 1:]
with tf.GradientTape() as tape:
logits = model(enc_batch, dec_in, training=True)
loss_value = loss_fn(dec_tgt, logits)
loss_value += tf.reduce_sum(model.losses)
grads = tape.gradient(loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
total_loss += float(loss_value)
num_batches += 1
avg_loss = total_loss / num_batches
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}")
train_time = time.time() - start_time
print(f"训练用时: {train_time:.2f} 秒")
return train_time
@tf.function
def greedy_decode_step(decoder, dec_input, dec_hidden, enc_outputs):
logits, dec_hidden = decoder(dec_input, dec_hidden, enc_outputs)
return logits, dec_hidden
def decode(model, input_tensor, use_beam_search=False, beam_width=3, max_len=20):
dummy_src = tf.zeros((1, max_encoder_len), dtype=tf.int32)
dummy_tgt = tf.zeros((1, 1), dtype=tf.int32)
_ = model(dummy_src, dummy_tgt, training=False)
start_time = time.time()
input_tensor = tf.expand_dims(input_tensor, 0)
enc_outputs, (hidden, cell) = model.encoder(input_tensor)
hidden_fw, hidden_bw = tf.split(hidden, num_or_size_splits=2, axis=-1)
cell_fw, cell_bw = tf.split(cell, num_or_size_splits=2, axis=-1)
hidden = hidden_fw + hidden_bw
cell = cell_fw + cell_bw
dec_hidden = (hidden, cell)
if not use_beam_search:
dec_input = tf.constant([[target_token_index['\t']]], dtype=tf.int32)
result = []
for _ in range(max_len):
logits, dec_hidden = greedy_decode_step(
model.decoder, dec_input, dec_hidden, enc_outputs
)
pred = tf.argmax(logits, axis=-1)
token = int(pred[0])
if token == target_token_index.get('\n', -1):
break
result.append(reverse_target_char_index.get(token, ''))
dec_input = pred[:, tf.newaxis]
decoded = ''.join(result)
else:
candidates = [([target_token_index['\t']], 0.0, dec_hidden)]
for _ in range(max_len):
new_cands = []
for seq, score, h_c in candidates:
if seq[-1] == target_token_index.get('\n', -1):
new_cands.append((seq, score, h_c))
continue
inp = tf.constant([[seq[-1]]], dtype=tf.int32)
logits, new_h_c = model.decoder(inp, h_c, enc_outputs)
log_probs = tf.nn.log_softmax(logits, axis=-1)[0]
top_vals, top_idx = tf.math.top_k(log_probs, k=beam_width)
for v, idx in zip(top_vals, top_idx):
new_seq = seq + [int(idx)]
new_score = score + float(v)
new_cands.append((new_seq, new_score, new_h_c))
candidates = sorted(new_cands, key=lambda x: x[1], reverse=True)[:beam_width]
best_seq = candidates[0][0]
decoded = ''.join(
reverse_target_char_index.get(i, '') for i in best_seq[1:] if i != target_token_index.get('\n', -1))
decode_time = time.time() - start_time
return decoded, decode_time
def evaluate_bleu(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
total_bleu = 0
total_time = 0
smoother = SmoothingFunction().method4
for i in range(len(test_enc_input)):
pred, dt = decode(model, test_enc_input[i], use_beam_search, beam_width)
total_time += dt
true = test_targets[i][1:-1]
ref = [list(true)]
hyp = list(pred)
bleu = sentence_bleu(ref, hyp, smoothing_function=smoother)
total_bleu += bleu
avg_bleu = total_bleu / len(test_enc_input) * 100
avg_time = total_time / len(test_enc_input)
print(f"BLEU: {avg_bleu:.2f} | 平均解码时间: {avg_time:.4f} 秒/样本")
return avg_bleu, avg_time
def evaluate_exact_match(model, test_enc_input, test_targets, use_beam_search=False, beam_width=3):
correct = 0
total = len(test_enc_input)
for i in range(total):
pred, _ = decode(model, test_enc_input[i], use_beam_search, beam_width)
true = test_targets[i][1:-1]
if pred == true:
correct += 1
acc = correct / total * 100
print(f"完全匹配率: {acc:.2f}%")
return acc
if __name__ == "__main__":
EMB_DIM = 64
HIDDEN_DIM = 256
BATCH_SIZE = 128
LR = 0.001
USE_ATTENTION = True
USE_BEAM_SEARCH = True
BEAM_WIDTH = 3
print(f"\n=== 配置 ===")
print(f"使用注意力: {USE_ATTENTION}")
print(f"使用束搜索: {USE_BEAM_SEARCH} (beam width = {BEAM_WIDTH if USE_BEAM_SEARCH else 'No'})")
encoder = Encoder(num_encoder_tokens, EMB_DIM, HIDDEN_DIM)
decoder = Decoder(num_decoder_tokens, EMB_DIM, HIDDEN_DIM, use_attention=USE_ATTENTION)
model = Seq2Seq(encoder, decoder)
print("\n开始训练...")
train_time = train(model, epochs=EPOCHS, batch_size=BATCH_SIZE, lr=LR)
print("\n评估中...")
bleu = evaluate_bleu(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
exact_acc = evaluate_exact_match(model, test_encoder_input, test_targets,
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print("\n=== 抽取测试样本输出 ===")
sample_indices = random.sample(range(len(test_encoder_input)), 10)
for i in sample_indices:
src = test_inputs[i]
true = test_targets[i][1:-1]
pred, _ = decode(model, test_encoder_input[i],
use_beam_search=USE_BEAM_SEARCH, beam_width=BEAM_WIDTH)
print(f"Human : {src} | True : {true} | Predicted : {pred}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号