吴恩达深度学习课程四:计算机视觉 第四周:卷积网络应用 (二) 图像风格转换
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课的第四周内容,4.6到4.11的内容,同时也是本篇理论部分的最后一篇。
本周为第四课的第四周内容,这一课所有内容的中心只有一个:计算机视觉。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的“特化”,也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第四周的内容是对前三周内容的综合应用,介绍了一些通过卷积网络实现的实际应用,它们在使用卷积网络的基础上又各有自己的特点来匹配不同的任务要求,是对如何真实应用卷积网络的良好演示。
本篇的内容关于图像风格转换。
1. 什么是图像风格转换?
并不难理解,我们之前也提到过它,用课程里的例子来进行演示:

如图所示,使用图像风格转换,我们就可以把自己拍的照片在保证内容不变的同时,转换成名画,或者整蛊版的画风。这种应用更贴近我们的生活,在现在的手机应用里也十分普遍。
现在就来看看如何实现图像风格转换。
2. 如何实现图像风格转换?
我们已经不止一次提到,神经网络中的许多学习任务,本质上都可以抽象为一个优化问题:通过定义合适的目标函数,并借助梯度下降等方法,使优化目标不断减小,从而得到期望的结果。
在监督学习中,这一过程通常表现为不断更新模型参数,以减小模型输出与标签之间的差异。
而在图像风格转换任务中,也沿用了同样的优化思想。
此时,我们需要回答的关键问题是:如何度量内容图像与风格图像之间的差异,使生成结果在保持内容结构的同时,逐步逼近目标风格?
答案就在于构造合适的代价函数。
代价函数这个名字已经很久没有出现过了,我们先回顾一下损失函数和代价函数的概念:前者是单个样本输出和标签之间的差距,后者是训练集中所有样本输出和标签之间差距的平均值。
但在实际工程实现和大量论文中,二者往往被混用,深度学习框架中也普遍使用 loss 来指代最终用于反向传播的优化目标。
因此,虽然二者数学上可区分,但在实际工程上经常不区分,我们明白含义就好。
回到正题,在 2015 年,一篇名为A Neural Algorithm of Artistic Style的论文首次提出神经风格转换的概念。
这篇论文的核心思想是:在固定预训练卷积神经网络参数的前提下,利用网络中间层特征,将图像的内容结构与风格统计进行显式分离,并通过在特征空间中最小化相应的代价函数,直接对输入图像进行优化,从而重构出一幅同时匹配内容与风格约束的图像。
简单来说,图像风格转换的代价函数被分成了两部分:内容代价函数和风格代价函数:
其中,\(\mathcal{J}_{\text{content}}\) 用于约束生成图像在高层特征空间中与内容图像保持一致,\(\mathcal{J}_{\text{style}}\) 则通过统计特征相关性来刻画并匹配目标风格,\(\alpha\) 与 \(\beta\) 用于平衡内容与风格在生成结果中的相对重要性。
陈述偏学术,有些迷惑很正常,我们下面就来详细展开:
2.1 图像风格转换的训练逻辑
在刚刚说明神经风格转换的核心思想时,你可能注意到了一个细节:固定预训练卷积神经网络参数。
这意味着,我们在优化的过程中不去改变网络本身的权重。
那问题来了:如果网络不动,代价函数还能下降吗?答案是肯定的——关键在于优化的对象变了。
这便是神经风格转换的一个核心点:被优化的不是网络参数,而是生成图像本身。
这是什么意思?我们展开说明:
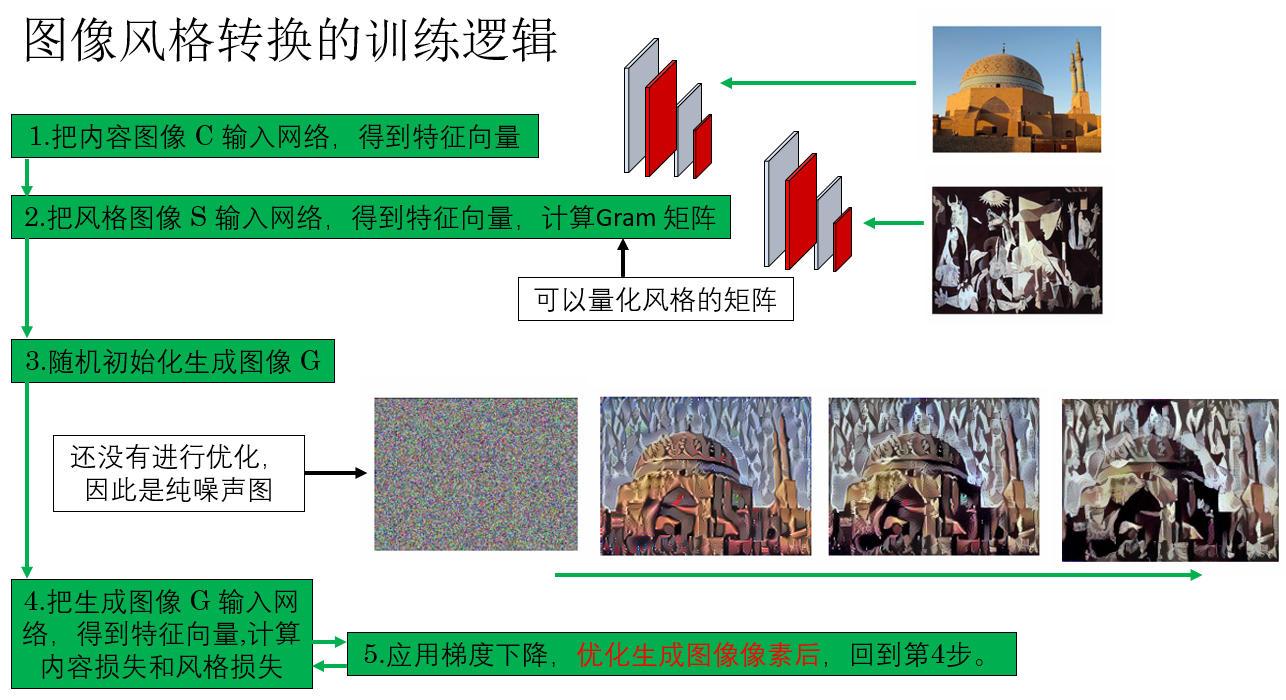
如图所示,你会发现,在这套训练逻辑中,网络只是一个工具,就像一把已经刻好的尺子,只负责提取图像的内容和风格特征。
我们将生成图像输入网络,通过前向传播得到其内容特征和风格特征,再与内容图像和风格图像的预计算目标特征比较,得到代价函数。随后,通过梯度反向传播,更新生成图像像素,而网络参数保持固定。
这样一来,虽然网络不训练,我们仍然可以通过迭代优化生成图像,使其内容与风格逐步逼近目标。
了解了基本的训练逻辑后,我们再来看看到底如何实现代价函数。
2.2 内容代价函数
我们先来看看较为直观的内容代价函数:\(\mathcal{J}_{\text{content}}(C,G)\)
顾名思义,这部分代价函数的作用是用来衡量生成图像和内容图像之间的差异,显然,我们希望这部分能最小化来保持图像内容不变。
如何实现这部分?
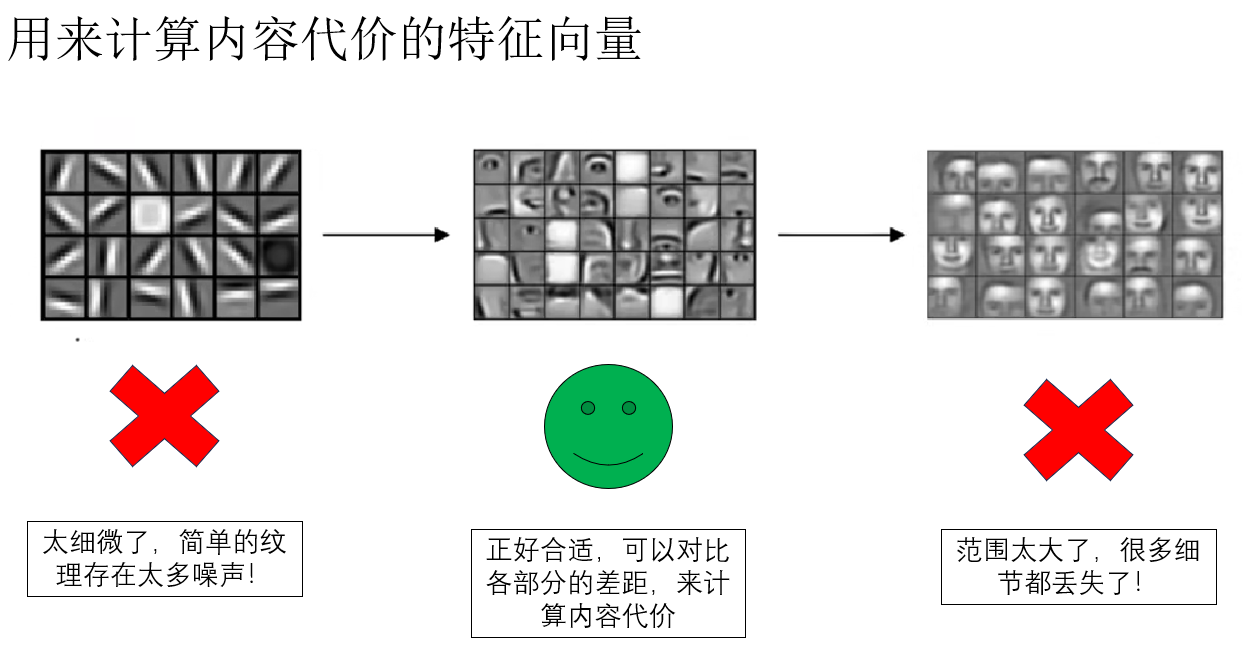
我们知道,在卷积神经网络中,随着网络层数的增加,输出特征图的抽象程度逐渐提高:
- 浅层特征主要捕捉局部纹理和边缘信息
- 深层特征则编码全局语义和高级抽象
我们一般使用深层特征来进行分类或检测等任务,但如果直接使用深层特征来计算内容损失,虽然语义信息丰富,但局部结构可能丢失;如果只用浅层特征,又容易被细节干扰。
因此,我们通常选择中间层特征来计算内容代价,它既能反映图像的整体结构,又保留足够的局部信息,正好适合衡量生成图像与内容图像之间的差异。
可以形象地理解为:我们不希望只对纹理“计较”,也不希望只看整体概念,而是找到一个中间尺度,既能保留结构,又不过于抽象。
也就是说,我们让用来计算内容代价的两组特征向量的抽象程度维持在一个合适的程度,既不是简单的纹理,也不是全局语义,就像这样:
明白了这一点后,我们现在就来看看到底如何计算内容代价:
并不复杂,一句话就可以说明:计算这两组向量中对应量差的平方和。
公式表示为:
其中,\(l\) 为我们选定的输出特征抽象程度合适的层级。
你也可以加入归一化:
了解完计算方式后,我们来看一个实例加深一下印象:
假设我们在某一中间层得到的特征图如下:
- 内容图像 \(C\) 的特征向量:
- 生成图像 \(G\) 的对应特征向量:
代入内容代价公式计算:
可以看到,这个值就表示生成图像在该层特征上与内容图像的差异。优化的目标就是让这个值尽量减小,从而让生成图像尽量保留原有内容结构。
这就是对内容代价的计算,下面我们继续看代价的另一部分:风格代价。
2.3 风格代价函数
相比内容代价,风格代价显得就抽象了些。我们把这节分为几部分,来进行较详细的介绍。
(1)量化风格
显然,要计算风格代价的首要问题就在于:我们要如何量化一幅图像的“风格”?
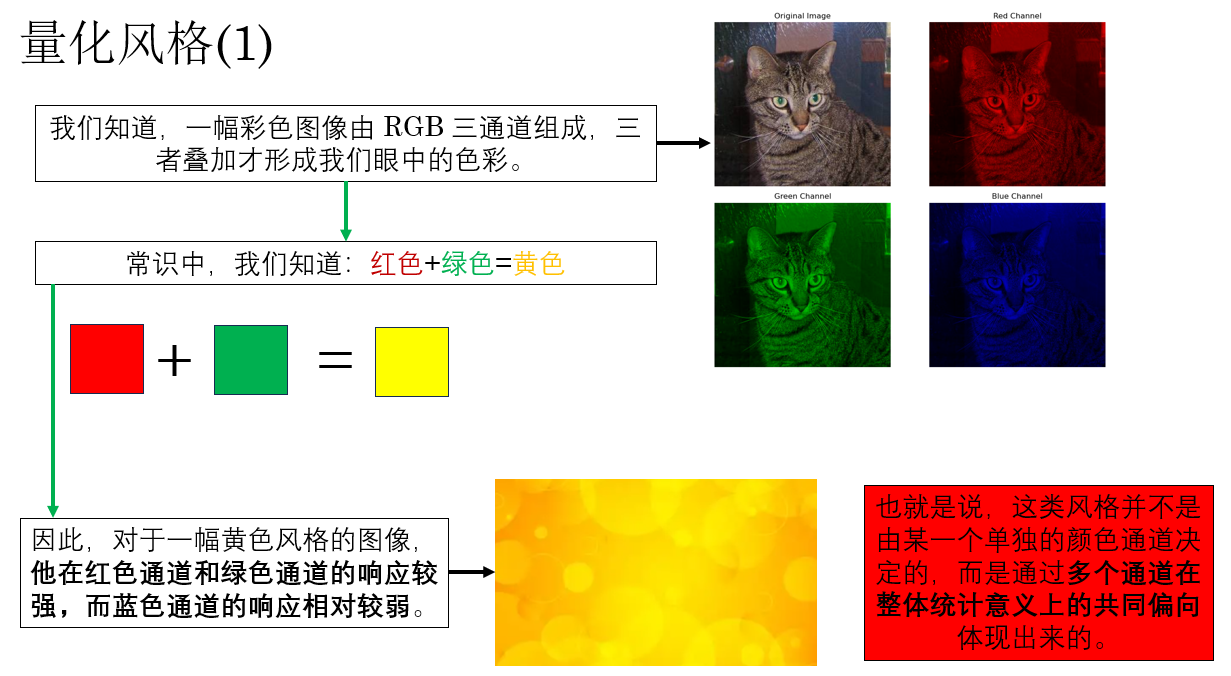
直觉上,风格并不取决于“画的是什么”,而更多体现在颜色搭配、纹理分布、笔触规律等整体视觉特征上,也就是说,**风格是一种“统计特性”,而不是依赖具体空间位置的结构信息。
因此,在计算风格代价时,我们需要一种统计方式:这种方式不关注具体的空间位置信息,而是聚焦于统计不同特征之间的相关性。
我们展开解释一下这句话,就像这样:
进一步地,我们把这样一幅彩色图像输入卷积网络,随着网络传播,输出特征图的通道数也不断增加,这时,每一个通道都可以粗略地理解为网络从图像中提取到的一类特征响应,它们可能对应颜色、纹理、局部形状或更复杂的视觉模式。
既然如此,不同特征通道之间自然也会存在某种统计上的关联关系,例如某些纹理特征往往与特定颜色分布同时出现,就像这样:
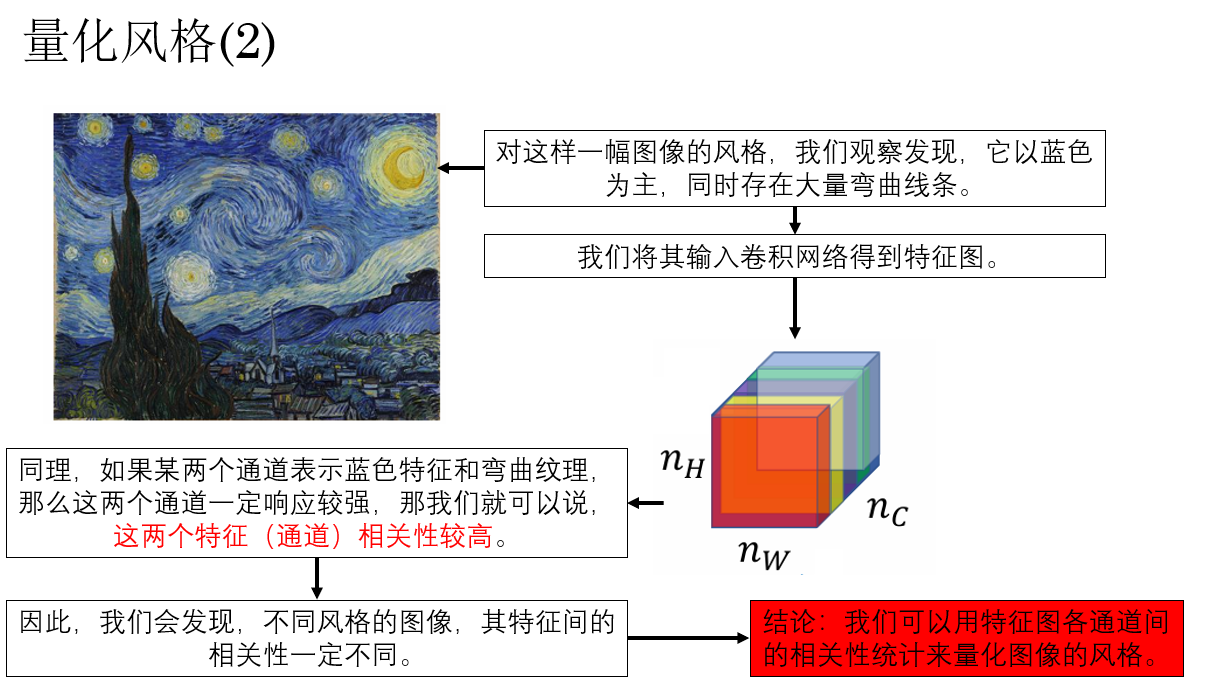
因此,我们可以将一幅图像的风格,量化为其特征图中各通道之间的相关性统计。
而同时,下一个就自然而然的产生:我们怎么统计各通道的相关性?
(2)Gram 矩阵
在神经风格转换中,Gatys 等人选择使用 Gram Matrix(格拉姆矩阵) 来刻画特征通道之间的相关性。
先不急着摆公式,我们来看看为什么 Gram 矩阵是一个合适的选择:
我们刚刚提到过,如果某两类特征在同一幅图像中经常同时被强烈激活,那么我们就可以认为它们在统计意义上是“相关的”。
而 Gram 矩阵做的事情正是这一点:它不关心这些特征在图像的哪个位置出现,而只关心——
不同特征通道在整幅图像中是否倾向于一起出现,以及出现得有多强。
也就是说,Gram 矩阵刻画的是一种 “特征与特征之间的共现关系”。
了解了Gram 矩阵的作用后,我们先用人话解释一下Gram 矩阵的计算过程:对所有通道两两组合,计算其相同位置上两个元素乘积的和,作为 Gram 矩阵中以两通道索引为坐标处的值。
然后,来看公式:
我们采用如下符号约定:
- \(a_{i,j,k}^{[l]}\):表示第 \(l\) 层中,空间位置 \((i,j)\) 处,第 \(k\) 个通道的激活值。
- 特征图空间尺寸为 \(n_H^{[l]} \times n_W^{[l]}\),通道数为 \(n_C^{[l]}\)。
在第 \(l\) 层中,输出特征图 的 Gram 矩阵 \(G^{[l]} \in \mathbb{R}^{n_C^{[l]} \times n_C^{[l]}}\) 定义为:
其中:
- \(k, k'\) 表示两个不同的特征通道。
- 对所有空间位置 \((i,j)\) 求和,显式消除了空间位置信息。
在实际计算中,通常会对 Gram 矩阵进行归一化:
这样可以避免特征图尺寸变化对风格代价产生不必要的影响。
最后,我们发现:Gram 矩阵中的每一个元素 \(G_{k k'}^{[l]}\),刻画的是第 \(k\) 个特征与第 \(k'\) 个特征在整幅图像中的共现强度,而不是它们出现的位置。
我们补充一个实例:
设第 \(l\) 层共有 \(n_C^{[l]} = 3\) 个通道,每个通道的特征图大小为 \(2\times 2\),三个通道的特征图分别为:
Gram 矩阵计算公式为:
- 计算对角项(通道自身的相关性)
- 计算非对角项(不同通道之间的相关性)
- 由于 Gram 矩阵是对称的:
最终 Gram 矩阵即为:
最终,这个 \(3 \times 3\) 的 Gram 矩阵完整地刻画了三种特征在整幅图像中的两两共现关系,而完全不包含任何空间位置信息。
到这一步,我们就实现了用一个矩阵来量化一幅图像的风格。
(3)计算风格代价
在成功实现对图像风格的量化后,我们便可以计算风格代价:\(\mathcal{J}_{\text{style}}(S,G)\)
它的计算逻辑并不复杂:对生成图像 G 和风格图像 S 的Gram 矩阵中对相应位置元素做差并平方,最后求和。
为保证与特征图尺寸和通道数无关,我们通常会加入归一化。
最终,它的公式是这样的:
再来演示一下:
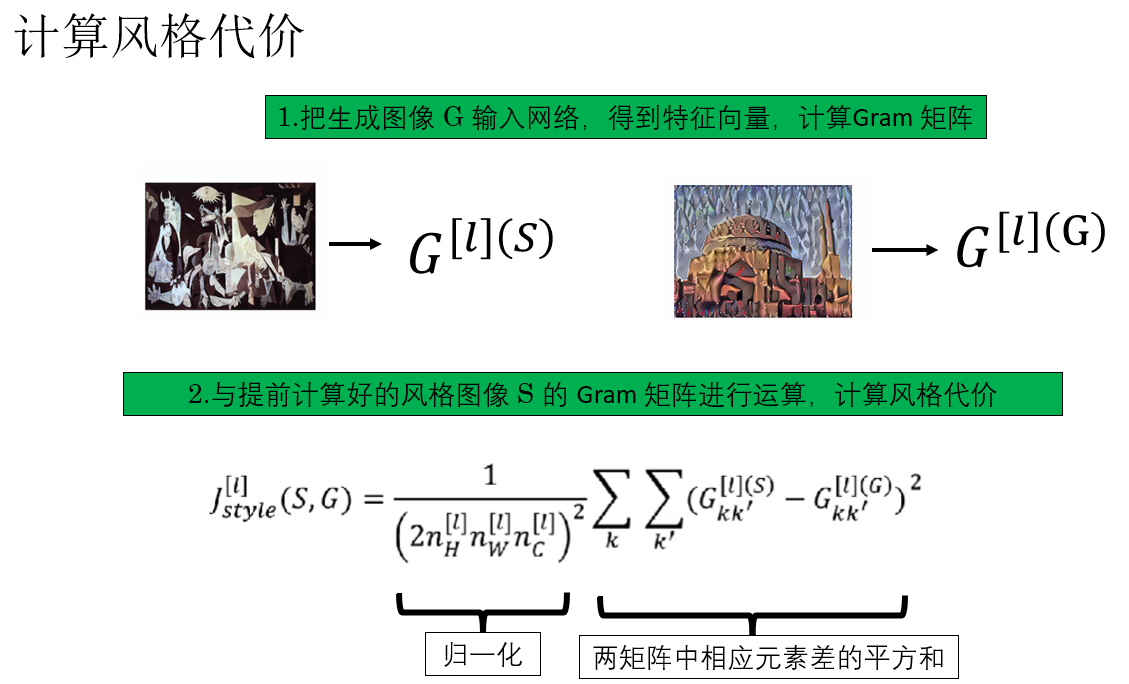
值得注意的是,上述公式严格来说只是单层风格代价,因为我们只使用了网络中某一层输出的特征图。
如果我们把图像传播到网络的多个卷积层,分别计算各层的 Gram 矩阵并得到对应的风格代价,再按权重加权求和,就得到多层风格代价:
- \(\lambda^{[l]}\):第 \(l\) 层风格代价的权重,可根据需要调节。
多层加权的好处是兼顾不同层次的风格特征:低层更偏向纹理和颜色,高层更偏向整体图案和结构,从而生成的图像风格更加自然丰富。
由此,我们便成功定义了可用于图像风格转换的代价函数,接下来就可以通过网络的反向传播实现风格转换。
在本周的实践内容中,我们也会实际演示一下这种应用。
另外,在本周课程最后,吴恩达老师补充了一节对一维卷积和三维卷积的介绍。
简单来说:一维卷积通常用于处理序列数据,例如时间序列或文本信号,它在序列方向上滑动卷积核,提取局部模式或特征。
三维卷积则常用于处理视频或体数据,它在高度、宽度和时间(或深度)三个维度上同时滑动卷积核,从而能够捕捉空间和时间上的联合特征,适合分析动态场景或三维结构信息。
我们就不再多展开这部分内容了,等遇到了它们的具体应用时,我们再详细介绍它们。
4.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 图像风格转换 | 利用预训练卷积神经网络提取图像内容和风格特征,通过优化生成图像使其内容保持不变、风格逼近目标图像 | 网络像一把刻好的尺子,生成图像像橡皮泥,通过不断调整橡皮泥使其符合尺子刻度 |
| 代价函数(总) | 将内容代价与风格代价加权求和:\(\mathcal{J}_{\text{total}} = \alpha \mathcal{J}_{\text{content}} + \beta \mathcal{J}_{\text{style}}\) | 衡量生成图像与目标图像“差距”的指标,越小越匹配 |
| 内容代价函数 | 衡量生成图像与内容图像在中间层特征空间的差异,通常使用平方和计算 | 找到“中间尺度”既保留结构,又不过于抽象,就像兼顾局部纹理与整体概念 |
| 内容特征选择 | 使用中间层特征,既保留全局结构,又不过分关注局部纹理 | 不希望只对纹理计较,也不希望只看整体概念 |
| 风格代价函数 | 利用Gram矩阵刻画各特征通道之间的相关性,通过平方差和加权求和计算 | Gram矩阵像统计特征共现的表格,不关心位置,只关注不同特征同时出现的强度 |
| Gram矩阵 | 对每对特征通道,在所有空间位置上求乘积并求和,归一化后得到 | 特征通道之间的“共现强度矩阵”,类似观察特征是否喜欢一起出现 |
| 单层 vs 多层风格代价 | 单层只考虑某一层特征,多层将多层风格代价加权求和,更全面捕捉风格 | 低层捕捉纹理与颜色,高层捕捉整体图案与结构 |
| 一维卷积 | 在序列方向上滑动卷积核,处理序列数据如时间序列或文本 | 像沿着时间轴观察和提取局部模式 |
| 三维卷积 | 在高、宽、深/时间三个维度上滑动卷积核,处理视频或体数据 | 像在空间和时间上同时观察动态或三维结构 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号