吴恩达深度学习课程四:计算机视觉 第三周:检测算法 (四)YOLO 的完整传播过程
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课的第三周内容,3.9到3.10的内容,同时也是本周理论部分的最后一篇。
本周为第四课的第三周内容,这一课所有内容的中心只有一个:计算机视觉。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的“特化”,也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第三周的内容将从图像分类进一步拓展到目标检测(Object Detection) 这一更具挑战性的计算机视觉任务。
与分类任务只需回答“图中有什么”不同,目标检测需要同时解决“ 有什么”以及“在什么位置”两个问题,因此在模型结构设计、训练方式和评价标准上都更为复杂。
本篇的内容关于YOLO 传播,是在了解完之前的基础后的完整演示和一些简单拓展。
1. YOLO 传播过程
在上一篇中,我们了解了交并比、非极大值抑制和锚框这些目标检测算法的组件,这里就应用这些内容,来看看课程里演示的 YOLO 算法的完整传播过程。
1.1 数据设置
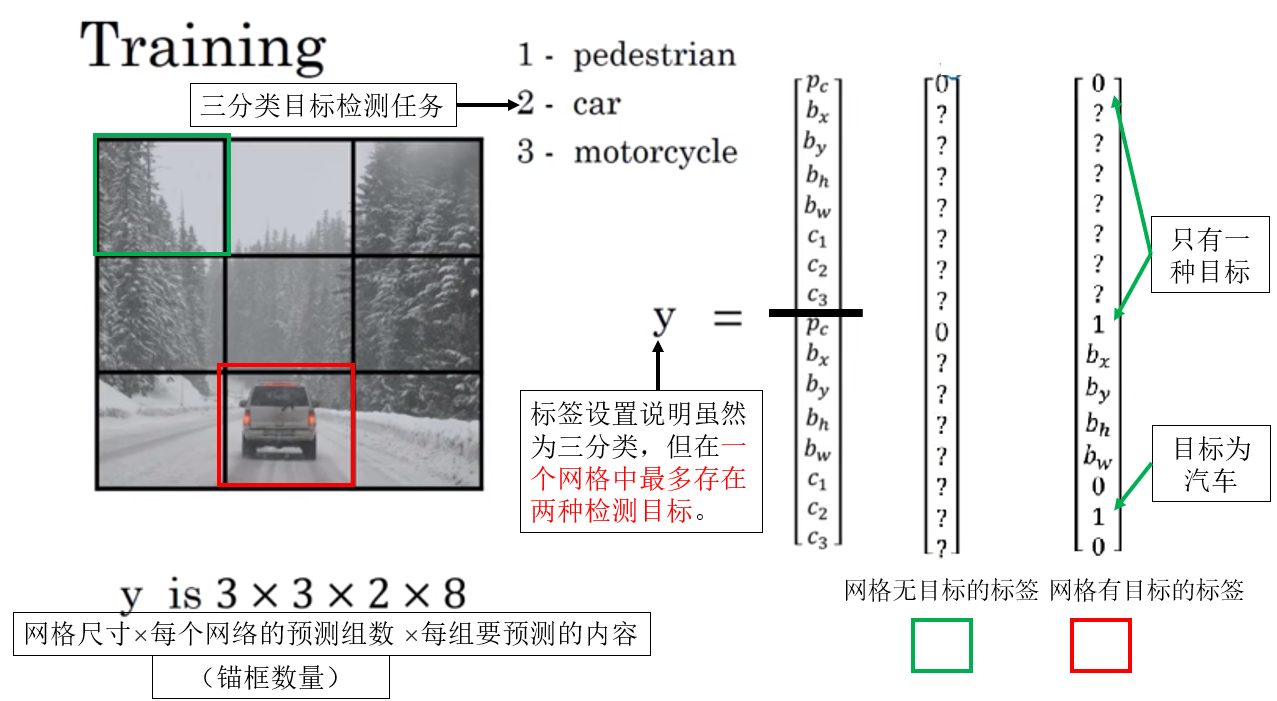
1.2 正向传播
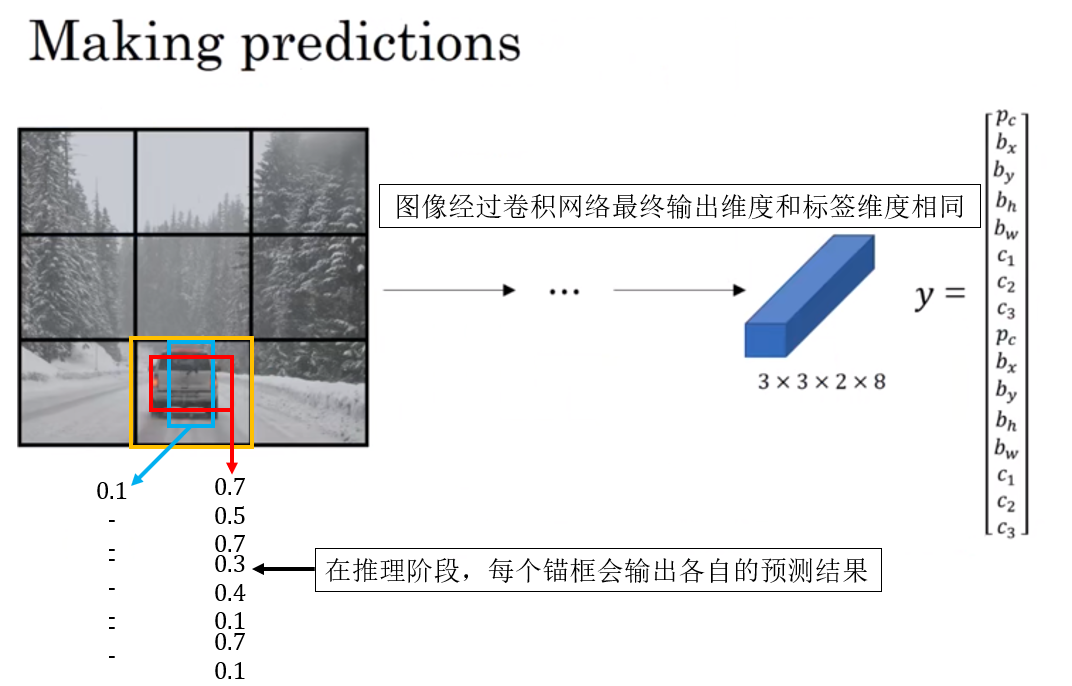
1.3 正向传播输出的后处理
这是一个新出现的概念,我们来展开一下这部分。
其实这部分内容在上一篇中已经有所提及,就是我们说的:“两次筛选”。
为什么说是正向传播的后处理,是因为严格来说:当网络输出结果时,正向传播部分就结束了。
因此,不同于我们之前用作示例的“精准预测”,实际上,网络输出的结果是这样的:
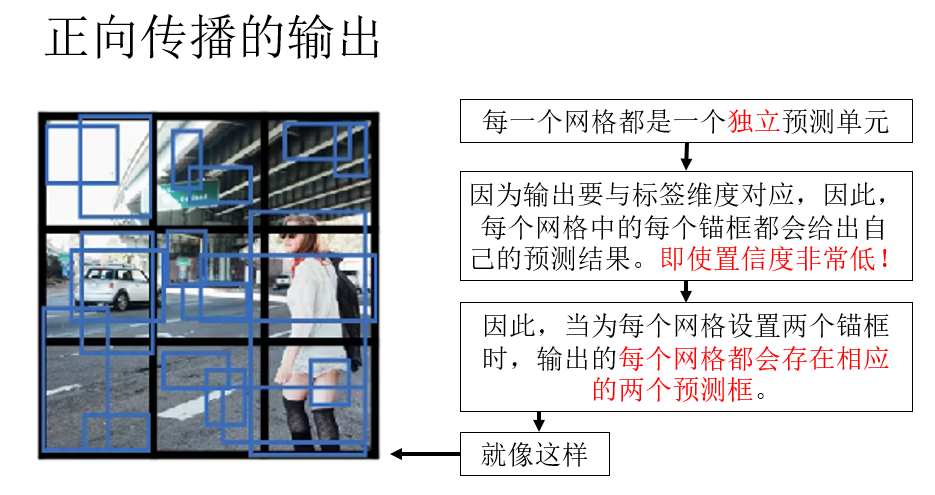
你会发现,即使在最边角的背景部分,该网格同样输出了两个预测框。
同时,因为背景部分没有目标的特征,因此,这两个预测框的置信度,也就是 \(p_c\) 一定是极低的。
所以,我们便由此进行了第一次筛选:
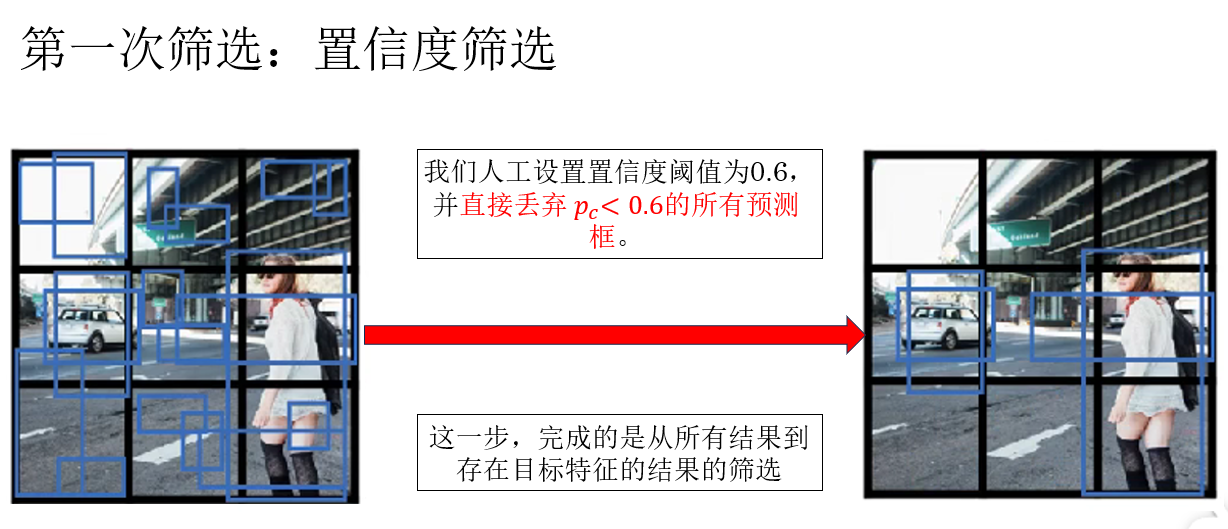
经过这一步后,我们才回到了之前提到过的多个预测框重叠导致的把一个目标的各个部分预测为多个目标的问题。
因此下一步就是非极大值抑制:
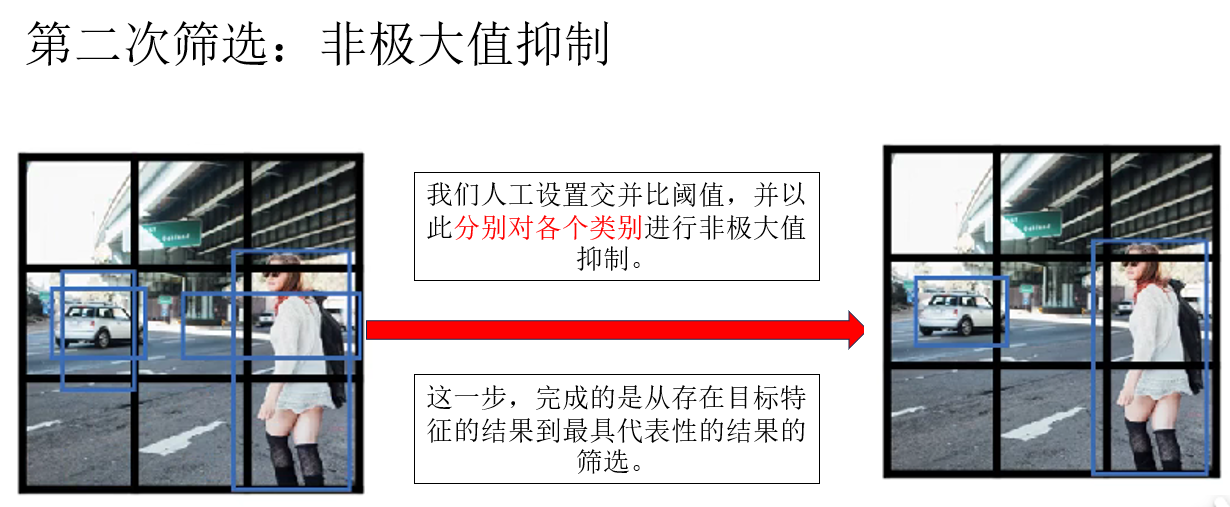
注意!你会发现,在这个例子中,重叠现象并不明显,这是因为我们为了演示把网格尺寸设置的很大以至于目标特征集中在某些网格中,在置信度筛选中就丢弃了大部分预测框,在这种情况下,就要调低交并比阈值来实现更好的筛选,因为重叠部分本就不大。
因为置信度筛选和非极大值抑制并不在网络中进行,而是对网络的输出进行处理,因此,我们称之为正向传播输出的后处理内容。
1.4 反向传播
(1)正向传播、反向传播和后处理的关系
首先,先纠正一个可能出现的误解,那就是对输出的后处理并不是在正向传播和反向传播之间的一个流程,它只是对输出结果的整理。
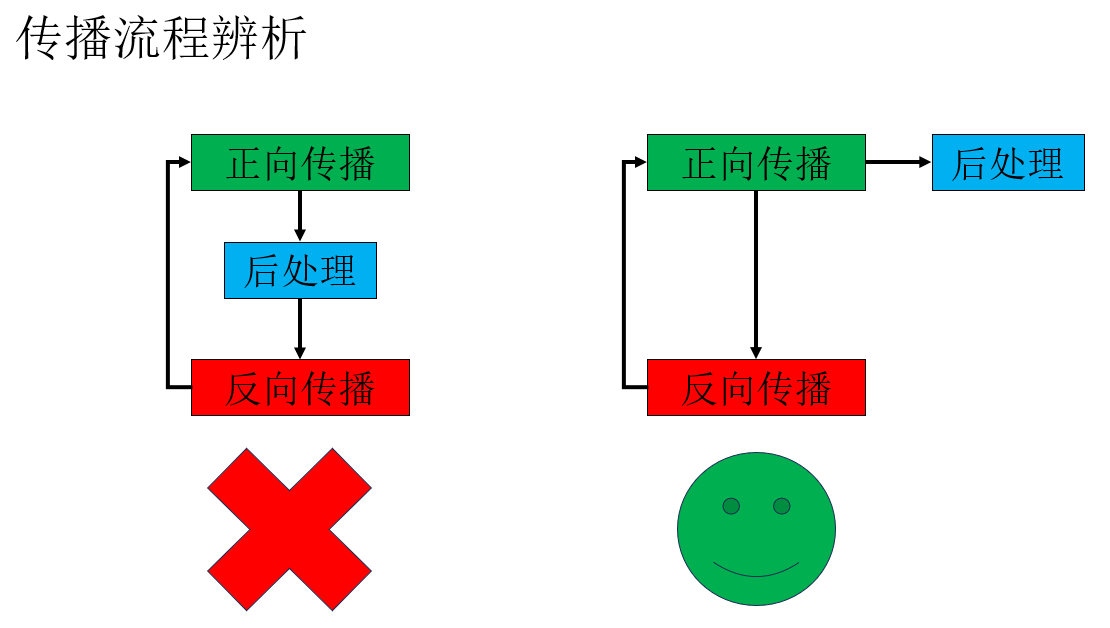
我们再详细展开一下:
既然置信度筛选和非极大值抑制并不在网络中进行,那它们会不会影响反向传播?
那些被筛掉的预测框,训练时是不是就“不算数”了?
答案是不会。
我们需要先明确一个边界:反向传播只依赖于网络的原始输出与真实标签计算得到的损失函数。
也就是说,当网络输出了每个网格、每个锚框对应的:
- 位置预测
- 置信度 \(p_c\)
- 类别概率
这时,正向传播已经结束,损失函数开始计算,反向传播随即发生。
而置信度阈值筛选与非极大值抑制:
- 不参与损失计算
- 不参与梯度传播
- 仅用于对“最终预测结果”的整理,用于下一步使用。
打个比方:网络是”你把这道题所有想到的答案写出来”,而后处理是“老师帮你去掉明显不对的答案”。
但当你学习分析这道题时,看的依然是原始答卷,而不是你后来用红笔划掉的部分,只有这样才能学习错误并改正。
这就是正向传播、反向传播和后处理间的关系。
要强调的是,后处理的结果是给我们查看并进行下一步应用的,网络不会因为输出看起来“乱”而学不到东西,反而,它正是在这种一一对应的信息反馈下才能不断学习。
(2)检测任务的反向传播逻辑
在监督学习中,不同任务虽然形式各异,但其反向传播的基本逻辑是共通的:模型输出与标注标签通过损失函数进行对比,得到可微的误差信号,并利用梯度下降与链式法则更新参数,使模型输出逐步符合任务目标。
接下来,我们从训练视角来看,再简述一下目标检测任务的反向传播流程:
当网络完成正向传播后,它会为每一个网格、每一个锚框都给出一组预测结果,这些预测结果并不会先经过筛选,而是整体送入损失函数中,与真实标签进行逐一对比。
在 YOLO 中,我们可以把损失函数拆分为三类误差来源:
- 位置误差:预测框的位置与真实目标框之间的偏差。
- 置信度误差:该预测框是否“应该负责一个目标”。
- 类别误差:在负责目标的前提下,类别预测是否正确。
而对于那些被分配去负责某个真实目标的预测框来说:
- 如果预测框位置不准,就会产生位置损失。
- 如果置信度不够高,就会产生置信度损失。
- 如果类别预测错误,就会产生类别损失。
这些损失会共同作用,通过梯度下降推动网络在反向传播中调整参数,使得下一次的输出框更贴近目标、\(p_c\) 更接近 1、类别分布更集中在正确类别上。
而对于那些不对应任何真实目标的预测框,它们的学习目标是:置信度应该尽可能低,即不应该“误以为自己发现了目标”。
因此,即使在后处理阶段我们会直接把它们筛掉,在训练阶段,它们依然会通过置信度损失向网络传递一个非常明确的信号: “这里是背景,不要乱报目标。”
正是这些大量、持续的背景约束,才让网络逐渐学会在复杂场景中抑制无意义的预测。

关于 YOLO 的内容就暂时介绍到这里,在下一篇中,我们就来实践一下它的效果。
吴恩达老师最后补充了一节关于候选区域的内容,简单来讲,候选区域的应用仍是基于滑动窗口的目标检测算法,它的思想是通过图像分割等算法提前找到更可能存在目标的区域作为候选区域,并只输入候选区域进入网络来减少计算量。
但是说实话,这种技术目前更适合于学术研究中,它的运行时间较长,实际部署价值不如 YOLO ,因此在实际应用中十分少见,就不再展开了。
2.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 正向传播(Forward Pass) | 网络接收图像输入,通过卷积、池化等运算生成每个网格、每个锚框的预测输出(位置、置信度、类别概率)。 | 网络“写下所有可能的答案”。 |
| 正向传播输出的后处理(Post-processing) | 包括置信度筛选和非极大值抑制(NMS),对网络输出进行整理,去掉低置信度和重叠多余的预测框。 | 老师“帮你划掉明显不对的答案”。 |
| 置信度筛选 | 根据预测框的置信度 \(p_c\) 判断是否保留。背景区域输出的框通常置信度低,会被筛掉。 | 去掉“明显错误的答案”。 |
| 非极大值抑制(NMS) | 对重叠的预测框进行筛选,只保留置信度最高的框,避免同一目标被重复检测。 | 老师只留下“最靠谱的答案”。 |
| 反向传播(Backward Pass) | 网络输出与真实标签计算损失,梯度通过链式法则回传,更新网络参数。所有预测框(目标和背景)都参与损失计算。 | 网络“看到原始答卷,知道哪里做错了并改正”。 |
| 候选区域(Region Proposal) | 基于滑动窗口或图像分割的方法,提前选出可能有目标的区域输入网络以减少计算量。 | 先挑出可能有答案的题目再做作业,但效率低于直接整张图像端到端检测(YOLO)。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号