吴恩达深度学习课程四:计算机视觉 第一周:卷积基础知识 课后习题和代码代码实践
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第四课第一周的课后习题和代码实践部分。
1. 理论习题
【中英】【吴恩达课后测验】Course 4 -卷积神经网络 - 第一周测验
本周的题多是一些尺寸和参数量的计算,只要对公式和层级结构足够熟练,就没什么大问题。
来看看这道可能容易混淆的题:
把下面这个过滤器应用到灰度图像会怎么样?
答案:检测竖直边缘。
这道题乍一看可能会有些迷惑,但是观察就会发现,左右数字对称,符号相反。
也就是说,如果应用这个过滤器,当对应区域左右像素接近时,结果就几乎为0。但当左右像素出现较大差别时,结果的绝对值就会较大。
这就是竖直边缘的逻辑,如果把整个矩阵旋转 90 度,检测的就是水平边缘,只是二者的效果可能都没有我们常用的边缘检测过滤器好。
2. 代码实践
吴恩达卷积神经网络实战
同样,这位博主还是手工构建了卷积网络中的各个组件,有兴趣可以链接前往。
我们还是用 PyTorch 来进行演示,终于正式引入了卷积网络,还是用猫狗二分类来看看卷积网络在图学习中的效果。
首先来看看 PyTorch 中如何定义卷积层:
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=0, stride=1)
# Conv2d 是指二维卷积,虽然图片可以有多个通道,但它实际上还是二维的”纸片人“。
# Conv3d 便适用于视频和 3D 图片这样的三维数据。
# 3,16 是指输入和输入的通道数,必须显式指定。
# kernel_size=3 是卷积核尺寸,必须显式指定。
# padding=0 ,0 就是padding 的默认值。
# stride 就是步长,1 就是步长的默认值。
再看看池化层:
self.max_pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# MaxPool2d 即为最大池化。
# 在池化层中,stride 默认和 kernel_size 相同。
# 池化层会自适应输入通道数,因此不用显示指定。
self.avg_pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
# 同理,AvgPool2d 就是平均池化。
现在,我们就来看看卷积网络的使用效果。
2.1 卷积网络 1.0
我们现在设计卷积网络如下:
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
# 全连接层
self.fc1 = nn.Linear(64 * 16 * 16, 128)
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x) # 另一种调用激活函数的方式
x = self.pool(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = torch.flatten(x, 1) # 进入全连接层前要先展平
x = self.fc1(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
来看看运行结果如何:
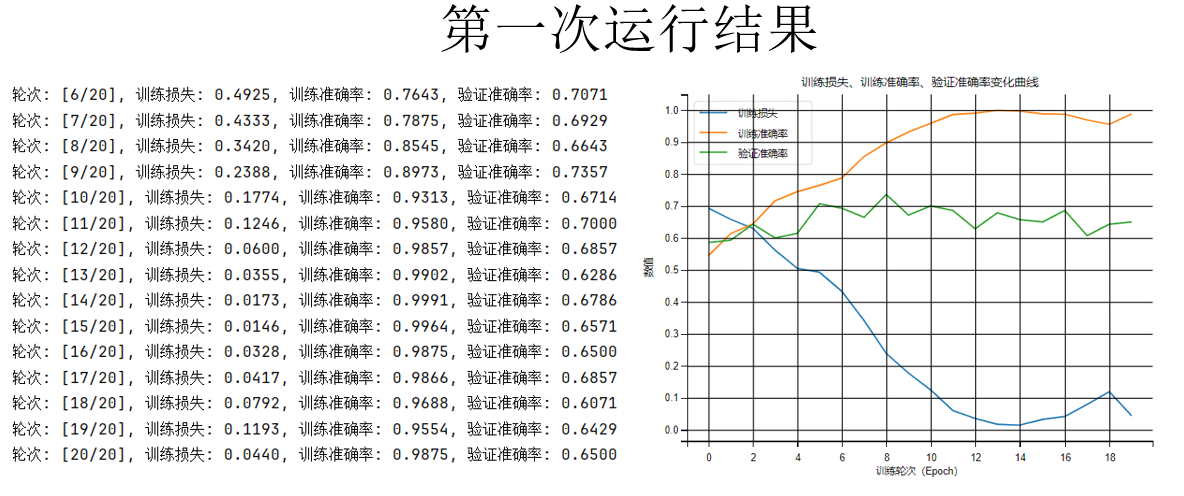
可以看到,仅仅经过 20 轮训练,训练准确率就几乎达到 100% ,但是验证准确率却仍在70%左右徘徊。
这是典型的过拟合现象:模型的学习能力很强,但是泛化能力不好。
经过前面的内容,我们已经了解了很多可以缓解过拟合现象的方法。现在,我们就开始一步步调试,缓解过拟合现象,增强模型的泛化能力。
2.2 卷积网络 2.0:加入 Dropout
我们在正则化部分了解了可以通过应用 dropout 来缓解过拟合,现在就来看看效果。
如果你有些忘了什么是dropout,它的第一次出现在这里:dropout正则化
应用 dropout 后,我们更新网络结构如下:
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
# 全连接层
self.fc1 = nn.Linear(64 * 16 * 16, 128)
self.fc2 = nn.Linear(128, 1)
# dropout
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x) # dropout
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x) # dropout
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x) # dropout
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.dropout(x) # dropout
x = self.fc2(x)
x = torch.sigmoid(x)
return x
现在再来看看结果:
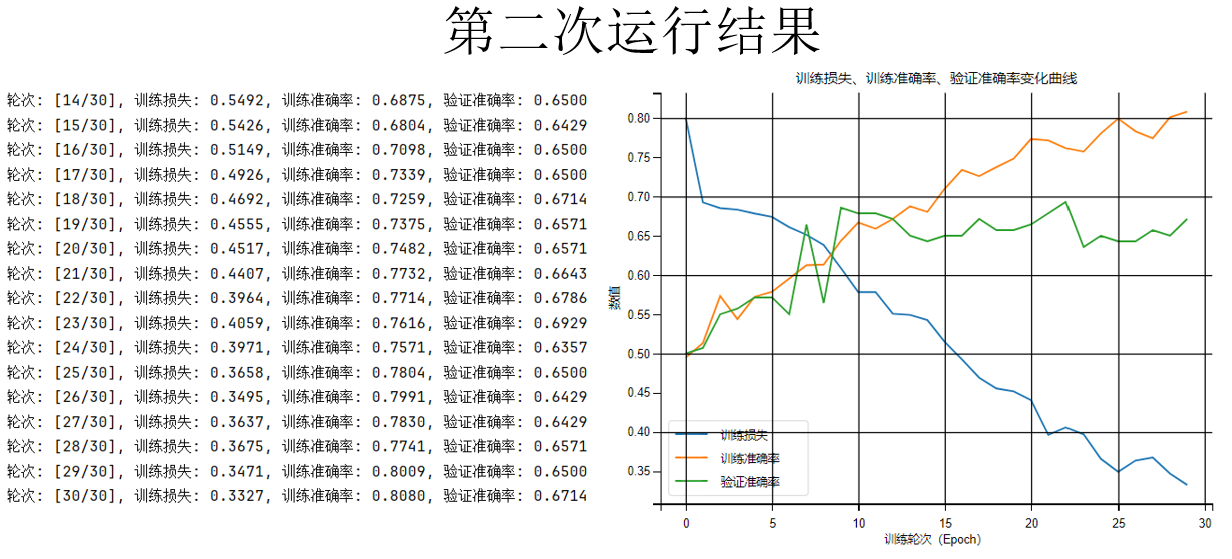
你会发现,dropout 确实有作用,增加训练轮次为 30 轮,训练集上的准确率上升的没有那么快了,确实和验证准确率的差距更小了。
但问题是验证准确率也没上去啊! 原本的过拟合问题,现在变成了欠拟合问题:模型对数据的拟合能力不足,而且通过趋势,会发现如果继续训练,仍存在过拟合风险。
那该怎么办呢?
我们知道,无论是过拟合还是欠拟合,我们希望提高模型性能,最直接的方法就是增加数据量。
我们先不急着上网找图片,不如就先试试我们之前经常提到的数据增强,看看效果如何。
2.3 卷积网络 3.0:进行数据增强
现在,我们要进行数据增强,那么要修改的代码内容就换到了预处理部分。
同样,数据增强第一次出现在这里:其他缓解过拟合的方法
现在,我们仍然保留上一步的 dropout 内容,修改预处理代码如下:
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.RandomHorizontalFlip(),# 图片有 50% 可能水平翻转
transforms.RandomRotation(10), # 在 角度 -10° 到 10° 之间随机旋转图像。
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
再再来看看效果如何:
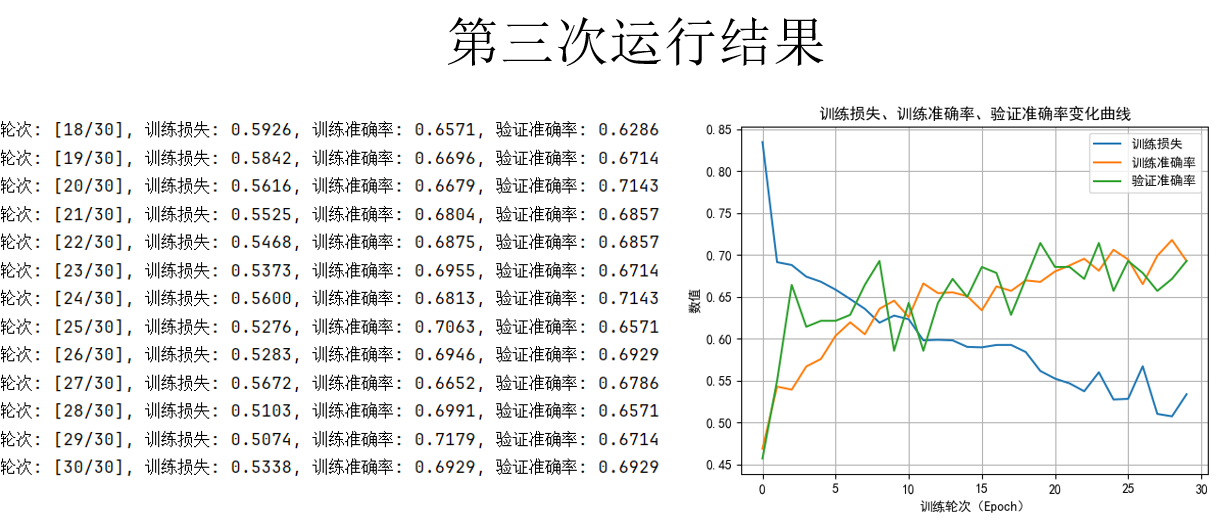
不是,好像变化不大啊!
别着急,之前我们一直在关注准确率,但是你会发现,在相同的训练轮次下,损失仍在平稳下降,但是下降的更慢了,并没有达到最开始过拟合的损失水平,比刚加入 dropout 时的损失还要高。
这说明:我们还没有达到模型的上限。
现在,继续维持其他内容不变,只增加训练轮次,我们再来运行看看。
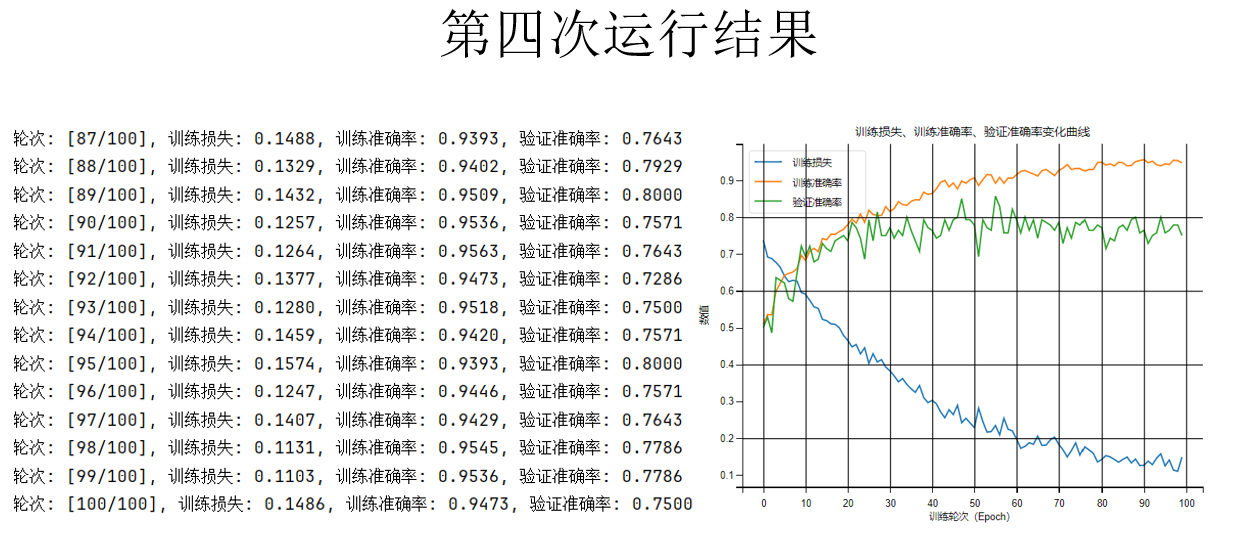
现在,把训练轮次增加到100轮,就可以发现:验证准确率有了一定的提升,但好像还是有过拟合风险,如果要继续修改,可以选择提高 dropout 的比率,也可以尝试其他正则化。
简单了解卷积层的性能后,我们就不在继续调试了。
实际上,通过继续修改网络结构或者继续增强数据,还可以让模型有更多的提升,但就不在这里演示了。
下一周的内容就是对现有的一些经典网络结构的介绍,到时候,我们再来看看出色的网络结构是什么效果。
3.附录
3.1 卷积网络 3.0 pytorch代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
# 全连接层
self.fc1 = nn.Linear(64 * 16 * 16, 128)
self.fc2 = nn.Linear(128, 1)
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleCNN().to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
epochs = 100
train_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(epochs):
model.train()
epoch_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_loss = epoch_loss / len(train_loader)
train_acc = correct_train / total_train
train_losses.append(avg_loss)
train_accuracies.append(train_acc)
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
val_accuracies.append(val_acc)
print(f"轮次: [{epoch+1}/{epochs}], 训练损失: {avg_loss:.4f}, 训练准确率: {train_acc:.4f}, 验证准确率: {val_acc:.4f}")
# 可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(train_losses, label='训练损失')
plt.plot(train_accuracies, label='训练准确率')
plt.plot(val_accuracies, label='验证准确率')
plt.title("训练损失、训练准确率、验证准确率变化曲线")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show()
# 最终测试,可忽略
model.eval()
correct_test = 0
total_test = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_test += (preds == labels.int()).sum().item()
total_test += labels.size(0)
test_acc = correct_test / total_test
print(f"测试准确率: {test_acc:.4f}")
3.2 卷积网络 3.0 TF版代码
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
img_size = (128, 128)
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
'./cat_dog',
validation_split=0.2,
subset="training",
seed=42,
image_size=img_size,
batch_size=batch_size
)
val_test_ds = tf.keras.preprocessing.image_dataset_from_directory(
'./cat_dog',
validation_split=0.2,
subset="validation",
seed=42,
image_size=img_size,
batch_size=batch_size
)
val_size = int(0.5 * len(val_test_ds))
val_ds = val_test_ds.take(val_size)
test_ds = val_test_ds.skip(val_size)
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1)
])
normalization = layers.Rescaling(1/0.5, offset=-1)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.map(lambda x, y: (normalization(data_augmentation(x)), y)).prefetch(AUTOTUNE)
val_ds = val_ds.map(lambda x, y: (normalization(x), y)).prefetch(AUTOTUNE)
test_ds = test_ds.map(lambda x, y: (normalization(x), y)).prefetch(AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().prefetch(tf.data.AUTOTUNE)
model = models.Sequential([
layers.Conv2D(16, (3, 3), padding='same', activation='relu', input_shape=img_size + (3,)),
layers.MaxPooling2D(2, 2),
layers.Dropout(0.3),
layers.Conv2D(32, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(2, 2),
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(2, 2),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.summary()
model.compile(
optimizer=tf.keras.optimizers.Adam(1e-3),
loss='binary_crossentropy',
metrics=['accuracy']
)
epochs = 100
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title("训练损失、训练准确率、验证准确率变化曲线")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show()
test_loss, test_acc = model.evaluate(test_ds)
print(f"测试准确率: {test_acc:.4f}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号