
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业2 |
| GitHub的链接 | Flut12的GitHub主页 |
| 其他参考文献 | 《构建之法》…… |
PART 1. 阅读《构建之法》并提问
Q1:16.1.7 关于“成功的团队更能创新”的思考
-
成功的团队在已经成功的领域创新将面临更大的期待和阻力,如果是颠覆性的创新则还可能会影响到原本公司的既得利益和老用户群体,往往是吃力不讨好得不偿失的,所以大公司一般都会更看重已有的市场和客户群体做线性完善和革新,如不是选择创造性的突破。但是在互联网行业中,很多东西都有垄断性质,大公司之间互相抗争争夺市场,小公司往往就是夹缝生存,优化自己的产品去提高用户粘性是首要大事,往往无暇顾及技术创新,反过来说小公司的资金能力有限,去尝试开创性的举措对他们来说也是万分艰难的,不可避免地要陷入持久战。
-
就拿游戏行业来说,前不久很火的《黑神话:悟空》被称作是国产3A的跨时代的大作,虽然只是放出了一段实机演示的预告,不过也可以看得出其对3A动作游戏的理解和丰富的脚本系统。不过其制作者游戏科学工作室并不是业内的大公司,扛不住过分的期待压力,于是赶紧放通告,谢绝过多的勘问,而且公布了新一轮的招聘和融资消息,可见小作坊是很难做好创新举措的,还不提这个项目已经做了多少年了,未来还会迎来UE4到UE5的革新,项目进度可能还会大大推迟,能否最后落成也未可知。
-
因此我发现大公司收购小公司作为工作室,提供足够的支持但是不不参与研究开发才能更有利于创新,比如腾讯收购的SuperCell还有Epic等,都是收购股份但是不介入开发研究,最多就是做一些国内代理,发挥用户群体优势,保留了原本工作室的创新氛围,不至于落入“已成功者”的陷阱中。
Q2:16.3.4 效能过剩是否也暗示了另一种效能不足?
- 效能过剩大概指的就是一个技术达到了持续阶段以后,他的效能已经远远满足大部分用户的需求,就会出现效能过剩的问题,例如书中举得U盘的例子:
2013年打算购买2GB的U盘(需求仅有2GB),但是市面上的U盘都是4GB以上的(效能4GB以上)
- 这里就是U盘储存空间的效能过剩,但是如果我开发一种快速的读取方法,使用空间换时间的策略(计算机很多优化都可以遵循空间换时间和时间换空间的策略),把原本2GB的文件,额外加上1GB的驱动文件来加速读取,并把这部分内容附在U盘的空间中,那么就可以得到一个3GB空间大小的快速读取的U盘,缓解了存储空间上的效能过剩,也提高了读取速度上的效能。这种情况下,是不是就证明在其他方面(如此处的读取速度)存在着效能不足,可以同时改进二者。
Q3:16.3.2 动量和加速度
- 在一个技术产品的不同生命周期都有他不同的动量和加速度,当进入衰退阶段以后甚至是成熟阶段的时候,如果通过加入颠覆性的革新,来使得他的加速度猛增(有点像老树开新花的情况),此时这个技术产品生命周期是否算是回溯了,还是应该把新加入的技术部分当作一个独立的技术产品来看待
比如前几年很多的自走棋玩法,游戏Dota2再加入自走棋玩法以后,用户量和用户粘性激增,迅速拉拢了一大批的下棋玩家,甚至一度超远原来的成熟期的高峰。
虽然后来热度又被其他的自走棋游戏瓜分掉了
无独有偶,游戏英雄联盟也推出云顶之奕玩法,炉石传说推出酒馆战旗玩法,我很喜欢这个模式,至今有在玩,甚至是王者荣耀也推出过类似玩法。
再比如有很多游戏也都效仿PUBG的成功案例,加入了大逃杀的玩法
- 这些个情况是否算是同一个技术产品的生命周期,如果算,其中很多产品已经到达用户量下降,但仍然有收益的衰退阶段了,焕发第二春以后要怎么算他的生命周期。
Q4:6.2 关于敏捷流程的问题和解法中几种情况的思考1
当自己想认领某个任务时,发现自己不具备足够的知识去完成这个任务,而团队里面其他成员对这个任务不感兴趣时,该怎么办?有些人认领的多,有些人认领的少,忙闲不均怎么办?
- 认领和分配任务是一件很难权衡的事,对于同样的一个要求,大牛和狗熊程序员需要的时间和精力肯定是不一样的,可能对于有的人来说很简单很快完成的工作,换另一个人就要处理很久,那这种时候是该考虑重新安排任务,还是考虑更换就职人员?假如说没有可换人员的情况下,按能力分配任务,将会出现每个人虽然花的时间精力差不多,也没怎么摸鱼,做的内容却不一样多,会不会导致一些人心里不平衡?此时又要怎么安排薪酬?
我自己之前和同学一起做项目就遇到过这种情况,一开始对于要做的任务的难度和体量没有太大的认识,导致后面有的人很划水,有的人却忙不过来。最后好歹是把项目完成了,可是心里却挺不平衡的。
Q5:6.2 关于敏捷流程的问题和解法中几种情况的思考2
每日会议流于形式,没有遇到困难不等于没有困难,每天瞎忙活可能最后离重点线只会更远。
- 他提出一个改进是记载完成这个任务还需要多少时间,利用绘制燃尽图,设置每天跟踪的三个值,实际剩余时间,预计剩余时间和实际花费时间。这个和我们这次作业要求的PSP图表很想,也是把任务分化然后对于每个任务量进行估计和统计。只不过这个书中方法还多了一项每日跟踪,对于工作量进行统计来说更方便。
PART 2. WordCount编程
1.github的链接Flut12的GitHub主页
2.PSP表格
| PSP | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 10 | 15 |
| • 估计这个任务需要多少时间 | 10 | 15 |
| 开发 | 600 | 450 |
| • 需求分析 (包括学习新技术) | 50 | 70 |
| • 生成设计文档 | 50 | 35 |
| • 设计复审 | 15 | 15 |
| • 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| • 具体设计 | 30 | 10 |
| • 具体编码 | 280 | 255 |
| • 代码复审 | 35 | 40 |
| • 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| 报告 | 120 | 40 |
| • 测试报告 | 60 | 30 |
| • 计算工作量 | 20 | 10 |
| • 事后总结, 并提出过程改进计划 | 40 | 30 |
| 合计 | 700 | 640 |
3.解题思路
-
先把基本功能做出来,然后按要求进行封装。
基本功能包括1.统计字符数
2.统计单词数
3.统计最多的10个单词及其词频利用map来存储单词,单词作为key,词频作为value。因为key的存在是唯一的hash,因此可以很方便的进行词频统计。关键做好单词的划分。
分别设置handleCharacter方法newWord方法和isRepeatWord方法来做到以上三个功能,最后用wordCount类封装
先用构造函数来打开文件,然后调用hanldeInPut方法处理打开的文件,并且调用上述三个方法分别来处理文件,得出统计结果。
4.代码规范制定链接
5.设计与实现过程
功能上三个功能是独立分开编写的函数
int handleCharacter(char c);//处理输入的每一个字符,用于 1.统计字符数量
int newWord(string key, int value);//记录新的单词,用于 2.统计单词数量
bool isRepeatWord();//记录重复出现的单词词频,用于 3.统计最多的10个单词及其词频
实际上补充上对于单词的判断函数就可以把三个功能穿在一起,仅读一次文件就可以同时处理三个功能
void wordCount::wordBreak()//当出现字母数字字符时进行单词的分割和判断
{
if (characterCnt >= MIN_WORD_SIZE && !isRepeatWord())//判断符合单词长度规范的同时跳转到isRepeatWord()去验证是否事重复出现的单词
{ //如果是重复出现的单词,那么在单词要求上肯定也会满足规范,所以二者可以放在一起进行
newWord(singleWord, 1); //甚至后者包括前者。
}
singleWord = "";
characterCnt = 0;
}
当检验重复时,在isRepeatWord中统计词频,反之记录新词。
词频统计利用map来完成,map自带key的字典序排序。因此只需要在输出时加上value的大小排序即可。
bool wordCount::isRepeatWord()
{
map<string, int>::iterator iter = wordList.find(singleWord);
if (iter != wordList.end())
{
iter->second ++;
return true;
}
return false;
}
然而把这几个函数串在一起的函数是handleCharacter,通过处理每一个读入的字符来判断此时是否进行wordBreak,然后根据情况转入其他的函数。
int wordCount::handleCharacter(char c)
{
if (isalnum(singleCharacter))//判断是否为字母或数字
{
if (isalpha(singleCharacter))//判断是否为字母
{
if (isupper(singleCharacter))//如果是大写字母进行小写字母的转换
{
singleCharacter += 32;//ASCII码
}
characterCnt++; //这两句分别是计算当前单词的长度
singleWord += singleCharacter;//和把当前字符放入当前单词的string中,下面同理。
}
else//此情况主要用来判别开头字母长度不足时后跟数字的情况
{
if (characterCnt >= MIN_WORD_SIZE)//当单词长度满足时,后接的所有非分隔符字符都被纳入单词计算中
{
characterCnt++; //此处同上
singleWord += singleCharacter;
}
}
}
else//非字母或数字直接进行单词的判断
{
wordBreak();
}
cnt++;//计算字符数量
return cnt;
}
6.性能改进
- 因为单个字符的判断没办法减少的,所以主要优化的地方时单词的判断,更改了wordBreak函数里面的判断,把原本先判断是否重复再判断是否满足单词要求然后分别处理的操作简化成一行代码
if (characterCnt >= MIN_WORD_SIZE && !isRepeatWord())
重复单词会在isRepeatWord函数中接受处理,同时满足后者的时候就会满足前者,不必写两次判断对每一个字符串进行验证。
7.单元测试
- 测试代码:
namespace WordCountTest
{
TEST_CLASS(WordCountTest)
{
public:
TEST_METHOD(TestMethod1)
{
ofstream test("in.txt");
for (int i = 0; i < 10000; i++)//生成1W个随机字符用于测试
{
test << (char)(rand() % 96 + 32);
}
test.close();
wordCount wordcount("in.txt", "out.txt");
wordcount.handleInPut();//测试三个功能
wordcount.outPutAll();
}
};
}
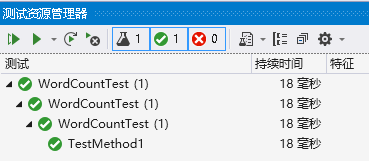
- 测试结果截图
8.异常处理说明
- 1.当文件无法打开时:
infile.open(inFileName);
outfile.open(outFileName);
if (!infile.is_open())
{
cout << "文件打开失败" << endl;
}
9.心路历程与收获
这一次的实践作业算是第一次使用github进行编程,一开始尝试用VScode的git功能进行作业,但是后来环境配置半天没成功就放弃转而选择VS了,VScode失败的主要原因是我没办法配置gcc的编译器,重新下过好几个版本,看了不少教程,外加网络属是拉跨最后折磨得放弃了。VS的项目git的clone还是比较好用的,多次commit的要求也让我意识到以后工作将面临的是团队一起编程的情况,团队之间的协同很重要,编程要注意可迁移性,还有代码的可读性,之前并没有写注释的习惯,以后如果要更好的进行配合,也得开始学会如何写注释了。最后就是代码风格的事,统一的代码风格真的很重要,不然长串的代码看下来真的是看吐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号