2025年寒假集训随笔【树同构 & Prüfer 序列 & KMP & exKMP & 失配树 & AC自动机 & 回文自动机 & 扫描线】
哈希专题
- \(2025/01/18\)
[国家集训队] 等差子序列
简要题意
询问一个从 \(1\) 到 \(n\) 的排列是否存在一个等差子序列,且满足序列长度 \(\ge 3\)。
Solution
很显然的,我们只需要求出一个长度等于 \(3\) 的等差子序列即可,那尝试把突破口放在中间的数中,假设其为 \(x\),那我们只需要满足有 \(k\) 使得 \(x-k\) 和 \(x+k\) 分别位于 \(x\) 的两侧;
接着方法就非常巧妙了,将 \(x\) 位置前面的所有数在打上标记 \(1\),其余为 \(0\),感性理解,将整个标记序列以 \(x\) 为对称轴“翻折”,因为 \(x-k\) 和 \(x+h\) 与 \(x\) 距离都为 \(k\),所以对折后 \(x-h\) 和 \(x+h\) 的位置必然是重合的;
由于原序列是个排列,一个数在左边出现了就不会在右边出现;
那就可以引出若“翻折”后的同一个位置上的两个数都被标记上 \(1\),说明这两个数在 \(x\) 前面出现,固然这三个数不可能构成一个等差子序列;否则,只要有一组成立就可以了。
现在把问题转化到如何快速判断,因为有反转操作,又要判断位置上的数是否相等,可以进而想到用正反跑两次哈希,又要区间查询,所以采用线段树进行维护哈希即可。
注意:查询区间哈希值的的时候,要选择在叶子节点返回时就乘上其所在的位数:
inline int query1(int rt,int l,int r,int s,int t) {
if(l>t||r<s)
return 0;
if(s<=l&&r<=t)
return tree[rt].hs1*pw[t-r]%mod; //here
int mid=(l+r)>>1;
return (query1(lson,l,mid,s,t)+query1(rson,mid+1,r,s,t))%mod;
}
inline int query2(int rt,int l,int r,int s,int t) {
if(l>t||r<s)
return 0;
if(s<=l&&r<=t)
return tree[rt].hs2*pw[l-s]%mod; //here
int mid=(l+r)>>1;
return (query2(lson,l,mid,s,t)+query2(rson,mid+1,r,s,t))%mod;
}
树同构
前置知识
-
关于有根树和无根树同构的定义
注意:我们先要认识到树结构的本质是与树上节点编号无关的!!!
假设有两棵树 \(T1\) 和 \(T2\):
-
有根树:如果 \(T1\) 可以通过若干次左右兄弟子树互换,使得其结构(编号不参与讨论)和 \(T2\) 一样,则我们称两棵树
同构(也能说两棵树本质上是一样的)。更加具体的理解为:两棵树中的每两个对应结点的子树必须相同,左右位置可不一样。
注意到上面所说的左右孩子互换,有根树才会形成左右子树的关系,所以这个定义是基于有根树的。
-
无根树:与有根树有固定的根不同,顾名思义,无根树的根是不确定的,那么无根树的同构是指存在一组 \((a,b)\),使得当 \(T1\) 和 \(T2\) 分别以 \(a\) 和 \(b\) 为根形成的有根树时,能满足上面所述有根树同构的定义,则这两棵树同构;若不存在这样的情况,则不同构。
-
-
树哈希
树哈希
判断一些树是否同构的时,我们常常把这些树转成哈希值储存起来,以降低复杂度。
按照同构的定义是与编号无关的,这要求父节点哈希值与所有子节点相关,但与子节点顺序无关;
进而需要用具有交换律的运算来构造哈希函数 \(h\);
容易想到 \(h(u) = \sum_{v \in son(u)} h(v)\) 或者 \(h(u) = \prod_{v \in son(u)} h(v)\);
但是这样冲突概率较大,需要进行一些改进。
可以将二者结合:
-
\(h(u) = p_1 + p_2^{son\_cnt(u)} \prod_{v \in son(u)} h(v)\)
-
\(h(u)= \sum_{i = 1}^{son\_cnt(u)} h(v) \times p ^ i + size(u)\)
其中 \(h(v)\) 按照从小到大排序,去除子树顺序的问题。
上述中的 \(p\) 为 base 值,还需要用大素数对于哈希值进行取模。
还有一种新的方法。
有根树
针对有根树的情况,以 \(1\) 为根跑一遍 DFS 求出整棵树的哈希值,比较哈希值是否相等即可;
这里的哈希函数为:
\(f(S) = ( c + \sum_{x \in S} g(x)) \mod m\)
其中 \(c\) 为常数,一般使用 \(1\)。\(m\) 为模数,本人常用大素数进行自然溢出。
\(g\) 为整数到整数的映射,实现方式有很多种。
无根树
Solution I
根据定义,我们可以直接把以每个节点为根节点的哈希值求出来,进行排序,判断两棵树所取出来的所有点的哈希值是否一样,若全部相等,则这两棵树同构。
时间复杂度:\(O(mn^2\log{n})\)
Code I
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int base=1331;
const int mod=1e9+7;
const int N=52;
int m,n,a[N];
struct Node {
int to,nxt;
Node() {
to=nxt=0;
}
Node(int a,int b) {
to=a,nxt=b;
}
} adj[N<<1];
int head[N],idx,pw[N];
int sz[N],hsh[N][N];
inline void add(int x,int y) {
adj[++idx]=Node(y,head[x]);
head[x]=idx;
return ;
}
inline int dfs(int u,int fa) {
sz[u]=1;
int hsu=0,tot=0,hs[N];
for(int i=head[u];i;i=adj[i].nxt) {
int v=adj[i].to;
if(v==fa)
continue;
hs[++tot]=dfs(v,u);
sz[u]+=sz[v];
}
sort(hs+1,hs+tot+1);
for(int i=1;i<=tot;i++)
hsu=(hsu+hs[i]*pw[i])%mod;
return (hsu+sz[u])%mod;
}
inline void init_() {
idx=0;
for(int i=1;i<N;i++)
head[i]=sz[i]=0;
return ;
}
signed main() {
scanf("%lld",&m);
pw[0]=1;
for(int i=1;i<N;i++)
pw[i]=pw[i-1]*base%mod;
for(int i=1;i<=m;i++) {
init_();
scanf("%lld",&n);
a[i]=n;
for(int j=1;j<=n;j++) {
int x;
scanf("%lld",&x);
if(x!=0) {
add(x,j);
add(j,x);
}
}
for(int j=1;j<=n;j++)
hsh[i][j]=dfs(j,0);
sort(hsh[i]+1,hsh[i]+n+1);
for(int j=1;j<=i;j++) {
if(a[i]!=a[j])
continue;
bool flag=1;
for(int k=1;k<=n;k++) {
if(hsh[i][k]!=hsh[j][k]) {
flag=0;
break;
}
}
if(flag) {
printf("%lld\n",j);
break;
}
}
}
return 0;
}
Solution II
让我们尝试推广一下定义,对于两棵同构的树,既然结构都一样,那么两棵树的重心也一样,不妨以树的重心作为根,将无根树变为有根树,比较两棵树在重心上的哈希值即可。
注意:一棵树最多有两个重心,可以一一比较小(大)重心的哈希值是否都相等。
时间复杂度:\(O(mn\log{n})\)
Code II
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int inf=1e18;
const int base=1331;
const int mod=1e9+7;
const int N=52;
int n,m,a[N];
struct Node {
int to,nxt;
Node() {
to=nxt=0;
}
Node(int a,int b) {
to=a,nxt=b;
}
} adj[N<<1];
int head[N],idx,pw[N];
int sz[N],r1,r2,p,hsh[N][2];
inline void add(int x,int y) {
adj[++idx]=Node(y,head[x]);
head[x]=idx;
return ;
}
inline void init_() {
idx=0;
for(int i=1;i<N;i++)
head[i]=sz[i]=0;
return ;
}
inline void findrt(int u,int fa) {
sz[u]=1;
int maxx=0;
for(int i=head[u];i;i=adj[i].nxt) {
int v=adj[i].to;
if(v==fa)
continue;
findrt(v,u);
sz[u]+=sz[v];
maxx=max(sz[v],maxx);
}
maxx=max(maxx,n-sz[u]);
if(maxx<p) {
p=maxx;
r1=u,r2=0;
} else {
if(maxx==p)
r2=u;
}
return ;
}
inline int dfs(int u,int fa) {
sz[u]=1;
int hsu=0,tot=0,hs[N];
for(int i=head[u];i;i=adj[i].nxt) {
int v=adj[i].to;
if(v==fa)
continue;
hs[++tot]=dfs(v,u);
sz[u]+=sz[v];
}
sort(hs+1,hs+tot+1);
for(int i=1;i<=tot;i++)
hsu=(hsu+hs[i]*pw[i])%mod;
return (hsu+sz[u])%mod;
}
signed main() {
scanf("%lld",&m);
pw[0]=1;
for(int i=1;i<N;i++)
pw[i]=pw[i-1]*base%mod;
for(int i=1;i<=m;i++) {
init_();
scanf("%lld",&n);
a[i]=n;
for(int j=1;j<=n;j++) {
int x;
scanf("%lld",&x);
if(x!=0) {
add(x,j);
add(j,x);
}
}
r1=r2=0,p=inf;
findrt(1,0);
hsh[i][0]=dfs(r1,0);
if(r2)
hsh[i][1]=dfs(r2,0);
if(hsh[i][0]<hsh[i][1])
swap(hsh[i][0],hsh[i][1]);
for(int j=1;j<=i;j++) {
if(a[i]!=a[j])
continue;
if(hsh[i][0]==hsh[j][0]&&hsh[i][1]==hsh[j][1]) {
printf("%lld\n",j);
break;
}
}
}
return 0;
}
树上问题
- \(2025/01/19\)
Prüfer 序列
定义
Prüfer 序列可以将一个带标号 \(n\) 个结点的无根树用 \([1,n]\) 中的 \(n − 2\) 个整数表示。也可以把它理解为完全图的生成树与数列之间的双射,常用树的组合计数问题中。
建立
每次选择一个编号最小的叶结点并删掉它,然后在序列中记录下它连接到的那个结点(父亲节点),删到只剩两个结点为止,一共删掉 \(n − 2\) 个点,产生一个长度为 \(n − 2\) 的序列。
构造 Prüfer 序列:
1.可以使用小根堆维护度数为 \(1\) 的点中的最小值实现,时间复杂度为 \(O(n\log{n})\)。
2.考虑如何使用线性构造,其本质就是用一个指针指向要删除的点。
叶子结点的数量是非严格单调递减的,删去一个叶子结点后,其总数要么不变,要么减 \(1\);
维护一个指针 \(p\) 初始时指向度数为 \(1\) 的最小编号的节点,再维护每个节点的度数,方便我们知道在删除结点的时侯是否会产生新的叶子结点,若删除掉一个叶子节点后,发现出现了一个新的叶子节点,这个新的点也必然是刚刚删掉的节点的父亲。
现在假设 \(p\) 指向 \(q\),若处理完 \(p\) 后发现产生新的叶子节点 \(q\),若 \(q<p\),则其余所有叶子节点都大于 \(q\),那就只能强制先对 \(q\) 进行处理,直至 \(q>p\) 时停止,就像是一连串的链式反应;否则,令 \(p++\),直到找到某个点的度数为 \(1\)。
通过势能分析,时间复杂度为 \(O(n)\)。
由这个构造的过程中,我们可以得到以下的结论:
-
编号最大的点一定不会被删除,因为一棵点数 \(\ge 2\) 的树至少有 \(2\) 个叶子节点,因此一定不会考虑到编号最大的点。
-
每个点的度数为 Prüfer 序列里的出现次数加 \(1\)。
假设一个节点 \(x\) 的度数为 \(d\),则其 \(d-1\) 个子树被删除后,指向的 \(x\) 就会加入序列 \(d-1\) 次,然后其就会变成叶子节点,无法再被其他节点贡献次数。
重构
由 Prüfer 序列中节点出现的次数逆推出树上每个点的度数;
考虑维护点的度数,便可以直接得到目前的叶子节点有哪些,接下来只需要找到当前编号最小的叶子节点,并将其与 Prüfer 序列从头往后一一对应即可,这与由树构造 Prüfer 序列是一样的,也可以用指针维护,就是反过来思考,时间复杂度为 \(O(n)\)。
关于 Caylay 公式
完全图一共有 \(n ^ {n−2}\) 个生成树。
由于树和 Prüfer 序列是一一对应的,则 Prüfer 序列的数量便是生成树的数量,等价于将 \(n\) 个数填入一个长度为 \(n-2\) 的序列中(可重复填同一个数字),则方案数为 \(n ^ {n−2}\)。
用矩阵树定理也可以方便证明(蒟蒻没学过,呜呜呜)。
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=5e6+10;
int n,m,f[N],p[N];
int d[N],ans;
signed main() {
scanf("%lld%lld",&n,&m);
if(m==1) {
for(int i=1;i<n;i++) {
scanf("%lld",&f[i]);
d[f[i]]++;
}
for(int i=1,j=1;i<=n-2;i++,j++) {
while(d[j])
++j;
p[i]=f[j];
d[p[i]]--;
while(i<=n-2&&!d[p[i]]&&p[i]<j) {
p[i+1]=f[p[i]];
++i,d[p[i]]--;
}
}
for(int i=1;i<=n-2;i++)
ans^=i*p[i];
} else {
for(int i=1;i<=n-2;i++) {
scanf("%lld",&p[i]);
d[p[i]]++;
}
p[n-1]=n;
for(int i=1,j=1;i<n;i++,j++) {
while(d[j])
++j;
f[j]=p[i];
d[p[i]]--;
while(i<n&&!d[p[i]]&&p[i]<j) {
f[p[i]]=p[i+1];
++i,d[p[i]]--;
}
}
for(int i=1;i<n;i++)
ans^=i*f[i];
}
printf("%lld\n",ans);
return 0;
}
[HNOI2004] 树的计数
前置知识
- 多重排列计数
多重排列计数
定义
如果 \(S\) 是一个多重集合,那么 \(S\) 中 \(n\) 个对象的一个有序放置是 \(S\) 的一个 \(n\) 排列。(多重排列)
例如,\(\{ 2a,1b,3c \}\) 有如下 \(4\) 排列:
\(acbc,cbcc,cccb,baac,\dots\)
多重排列的计算
尝试先考虑一个问题:
在一堆球中,球共有 \(k\) 个种类,每个种类均有无限多个球,那么这堆球的 \(r\) 排列有多少个?
很简单,\(r\) 个位置中每个位置都可以放 \(k\) 种球,根据乘法原理可以知道,排列数为 \(k^r\) 个。
再深入考虑有限的情况:
在 \(n\) 个球中,球共有 \(k\) 个种类,那么这堆球的 \(r\) 排列有多少个?
问题就是要求 \(\{ n_1 a_1,n_2 a_2,\dots,n_k a_k \}\) 的 \(n\) 排列,其中 \(n1+n2+\dots+n_k=n\)。
若这 \(n\) 个球全都不相同(即 \(k=n\) 的情况),那么这 \(n\) 个球的全排列个数是 \(n!\);
但是,这种情况是未必的:
事实上,当我们把 \(n\) 个球全排列时,第 \(i\) 种内的 \(n_i\) 个球也全被排列了,即计算了 \(n_i!\) 次,但由于同种球本质是相同的,应只被记录 \(1\) 次,否则会导致第 \(i\) 中球被重复计数 \(n_i!\) 次,故真正的排列个数应该是 \(\frac{n!}{\prod_{i=1}^{k} n_i!}\)。
简要题意
钦定每个点的度数,求生成树数量。
Solution
由于一个 Prüfer 序列对应一棵树,那就把问题转化为求不同序列的个数;
现在已经知道了每个节点的度数 \(d\),由上面的结论可以知道,这个相当于 Prüfer 序列中限制了每个数字的出现次数。
用多重排列计数求方案数,\(Ans=\Large \frac{(n-2)!}{\prod (d_i-1)!}\)。
依据 Prüfer 序列,需要先定下两个点,再确定剩下 \(n-2\) 个点所指向的点;然而我们只用关注那 \(n-2\) 个如何连边,最后剩下的两个点之间自然会连成一条边;
- 注意区分:这里不能像
UVA10843 Anne's game那样去思考,因为那题是完全图,每个点的度数都最大可以为 \(n\),随便生成的序列是必然一棵符合条件的生成树;而本题不一样,每个点有固定的度数。
其实就是求 \(n\) 个数填满一个长度为 \(n-2\) 的序列,且要求每个数出现的次数为 \(d_i-1\);
设 \(sum_i\) 表示前 \(i\) 个数出现的次数,则有 \(sum_i=\sum_{i=1}^{n}(d_i-1)\);
再运用组合数学知识可以知道:\(Ans=\prod_{i=1}^{n} C_{n-2-sum_{i-1}}^{d_i-1}\)。
注意以下几种的情况:
-
若 \(n=1\),则答案唯一,输出 \(1\);
-
一棵树有 \(n\) 个节点,\(n-1\) 条边,每个边连接两个点,总度数应为 \(2(n-1)\),即为 \(2n-2\);
-
\(n \not = 1\) 且有点没有度时,答案为 \(0\),无解。
大佬 Garbage_fish 暴力推了一下两式子之间的关系,感觉挺好的:
第一个点 \(m\) 个位置随便选 \(a_1\) 个组合地放,第二个点 \(m-a_1\) 个位置随便选 \(a_2\) 个组合地放,以此类推:
即
红色的全都消掉了,蓝色的因为 \((\sum_{i=1}^m a_i)=m\),所以值等于 \(1\)。
那么就是
割点割边
- \(2025/01/20\)
[NOI2016] 网格
前言
Tarjan,缩点,割点,桥,点双,边双的模板还是得多背....记得啊!!!
简要题意
给出一张 \(n \times m\) 的黑白网格,在其中有 \(c\) 个格子是黑色,问至少将多少个白点染黑,能使得图上存在两个白点不连通,或输出无解。
Solution
很显然,由于是四连通图,一眼会发现答案必然 \(\le 4\),但进一步思考,最左上角的白点必然有两边与边界或黑点相连接,所以可以知道答案最后的范围 \(\le 2\)。
接下来尝试分类讨论:
-
否则若图只有不超过两个点,则无解,输出 \(-1\);
-
若所有四联通的白色格子组成的图不连通,则答案是 \(0\),如左图;
-
否则若图有割点,则答案是 \(1\);反之,答案则为 \(2\),如右图就为无割点的情况。

暴力建图跑 Tarjan,时间复杂度为 \(0(nm)\),超级大爆炸!!!
套路肯定是想要优化建图,消去无用的点和连边,思考怎样的图能完全覆盖所有判断:
首先所有的黑点一定要保留下来;
接下来需要保留如下的白点(感性理解原因):
-
与网格四个角的至少一个角的 \(x,y\) 坐标之差 \(\le 2\);
-
在某个黑点的八连通之内;
但是如果我们取出与黑点八连通的点集,如下图:
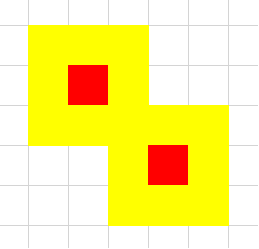
虽然这个联通块是有割点的,其实白点和黄点也是联通的,固然不能用 \(1\) 次操作解决,所以可以尝试在外再套一层:

这样的图求出的割点才是真正的割点,为了简化操作,我们也可以将其等价换成:
-
在网格的上边或下边上,且所在列有至少一个黑点;
-
在网格的左边或右边上,且所在行有至少一个黑点。
将同一行或同一列上两两染色的点相连,前提是相连的两点间没有黑色的点。
例如这样,蓝色的格子是保留下来的点:
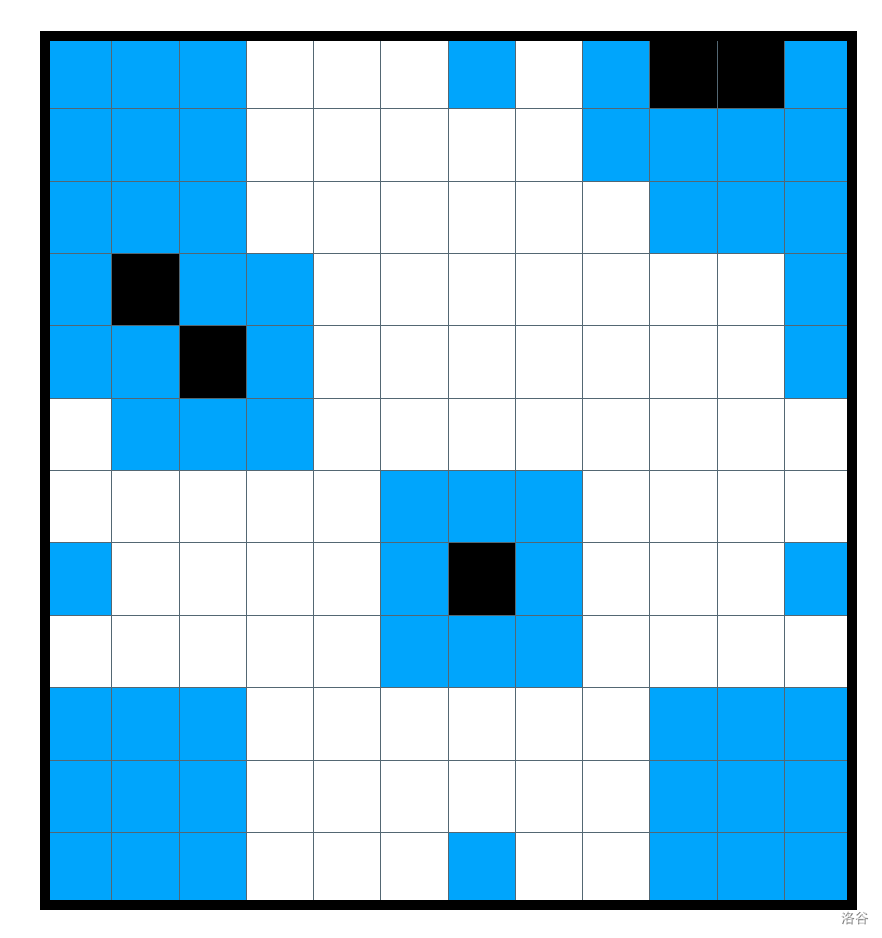
还需要注意,若图有两个点,且其相连,则答案无解,否则为 \(1\)。
(注:大部分内容有参考题解)
dp 凸优化
- \(2025/01/21\)
斜率优化DP
网络流
字符串选讲
-
\(2025/01/22\)
-
不得不说,yyc讲得确实好...
Border
定义
Border
对于字符串 \(S\),若其严格前缀(不包括自身) \(S_{:i}\) 满足 \(S_{:i} = S_{n-i+1:}\),则称为 Border。
记 \(mxBd(S)\) 为 \(S\) 的最大 Bd,\(Bd(S)\) 为 \(S\) 的 Bd 集合。
周期
对于字符串 \(S\),若恒有 \(S_i = S_{i + p}\),则称 \(p\) 为 \(S\) 的周期。特殊地,若 \(p|n\) 则称为整周期。
定理
-
\(S\) 有长度为 \(d\) 的 Bd,等价于 \(S\) 有周期 \(n − d\)。
-
证明:结合画图,我是考虑分类讨论(假设字符串 \(S\) 的长度为 \(n\),整个字符串区间为 \([p,q]\)):
-
当 \(d \le \Large \frac{n}{2}\) 时,相当于字符串 \(S\) 中有两个周期,一个段完整的,后一段是不一定完整的;
-
当 \(d > \Large \frac{n}{2}\) 时,\(mxBd\) 所在的前后缀(假设分别为 \([p,r],[l,q]\))是相交的,相交的部分为 \([l,r]\),那么 \(n - d\) 就是区间 \([p,l]\),可以很容易想到 \([q,l]=[l,l+(l-q+1)-1]\);
因为 \([l,r]=[q-(r-l+1)+1,q]\),从而得出 \([p,p+(r-l+1)-1]=[q-(r-l+1)+1,q]\),所以 \([q-(r-l+1)+1,q]\) 也可以成为周期的一部分;
最后,字符串 \(S\) 可以被分成三个周期,分别是 \([p,l],[l,l+(l-p+1)-1],[q-(r-l+1)+1,q]\)(其实这里的 \(l+(l-p+1)-1+1=q-(r-l+1)+1\))。
反正感觉这里很神奇,按这样证完也可以促进对其的理解。
-
-
-
\(Bd(S) = mxBd(S) + Bd(mxBd(S))\)
即:原串所有的 Bd 恰是 mxBd 加上 mxBd 的 Bd。
这很显然,由于 Bd 的 Bd 是 Bd;Bd 是 mxBd 的 Bd,这里不多讲。
参考自 yyc 的《字符串选讲》。
KMP 算法
用 Border 去理解更快。
引入
对于字符串 \(S\),记 \(fail_i\) 为 \(S_{: i}\) mxBd 长度。求 \(fail[1 ∼ n]\)。
实现方法
根据前文定理,\(\{fail_{n}, fail_{fail_n},\dots \}\) 恰构成 \(S\) 的所有 Bd。
按顺序求解 \(fail\),现已知 \(fail_1, \dots ,fail_{i-1}\),考虑如何使用现已知的条件来优化寻找过程,这里 \(j\) 为 \(S_{:i}\) 所匹配到的 mxBd(最大公共前后缀):
-
若 \(S_i = S_j\),这时 mxBd 长度就加 \(1\),即 \(fail_i=fail_{i-1}+1\),这里给 \(j+1 \to j\);
-
若 \(S_i \not = S_j\),则说明失配,尝试寻找一个更小的答案,由上面的定理可以知道,字符串中所有的 Bd 都是 mxBd 的 Bd,现在的 \(fail_{i-1}\) 不就是 mxBd 吗?
那就依照性质\({\color{red}从大到小}\)枚举 Bd(长度为 \(j\)),这里再想一想如何找?
由于 Bd 表示公共的前后缀,\({\color{red} 找 Bd 中的 mxBd}\),我们只能从前缀出手,因为只有前缀 \([1,j]\) 才有已知所记录的 \(fail_j\)(相反的,后缀在之前没有记录),直到有符合条件的 Bd 时停止,此时的 \(fail_i \leftarrow j+1\);
若一直搜到底都没有,则说明前面没有前缀和 \(S_i\) 匹配,\(fail_i \leftarrow 0\)。
这一步俗称“跳 fail”。
应用 KMP 查询子字符串是否相等的操作也是同理的。
关于时间复杂度
重点在于跳 fail 那里,我们假设 \(S_{:i}\) 所匹配到的 Bd 中的最长后缀(更好理解,前缀难分析)为 \([l,r]\),我们发现 \(l\) 的位置只会不断向后跳,为什么呢?
感性理解一下,按照刚刚的实现步骤,若 \(S_i = S_j\),则 \(l\) 的位置不变,\(r\) 的位置加 \(1\);
否则,\(j\) 减小(即 Bd 的长度减小),也就是刚刚操作中在 \(S_{:i-1}\) 上按长度从大到小找一个符合条件的 Bd 嘛(不同的是,现在按后缀分析),在寻找的时候右端 \(r\) 不变,但是由于长度减小,所以左端点 \(l\) 一直向右跳,直至寻找到符合条件的 Bd 时停止,现在的 \([l,r+1]\) 又成了 \(S_{:i}\) 的最长后缀;
综上,想象一下,有点像单调队列的滑动窗口,最长后缀的区间 \([l,r]\) 的左右端点 \(l\) 和 \(r\) 都一直往后蹦,均摊一下可以知道时间复杂度是 \(O(n)\)。
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=1e6+10;
char a[N],b[N];
int fail[N];
signed main() {
scanf("%s%s",a+1,b+1);
int lena=strlen(a+1);
int lenb=strlen(b+1);
for(int i=2,j=0;i<=lenb;i++) {
while(j&&b[i]!=b[j+1])
j=fail[j];
if(b[i]==b[j+1]) ++j;
fail[i]=j;
}
for(int i=1,j=0;i<=lena;i++) {
while(j&&a[i]!=b[j+1])
j=fail[j];
if(a[i]==b[j+1]) ++j;
if(j==lenb) {
printf("%lld\n",i-lenb+1);
j=fail[j];
}
}
for(int i=1;i<=lenb;i++)
printf("%lld ",fail[i]);
printf("\n");
return 0;
}
扩展 KMP/exKMP(Z 函数)
引入
给出长为 \(n\) 的字符串 \(S\),定义 \(z_i = lcp(S,S_{i:})\)。求 \(z[1 ∼ n]\),
即 \(S\) 的所有后缀与 \(S\) 的 LCP。
实现方法
约定 \(z_0=0\),很显然 \(z_1=n\),同样地从 \(2\) 到 \(n\) 顺序求解。
现在需要定义一些东西:
记后缀 \(S_{l:}\) 与 \(S\) 的 LCP 为 \([l,l + z_l − 1]\),称其为“\(l\) 处的匹配段”,目前右端点最大的匹配段为 \([l,r]\)。
计算 \(z_i\) 时,显然 \(l < i\),接下来对 \(r\) 进行分类讨论(其实画图很好理解):
-
若 \(r < i\),很显然,我们用不了一点以前所记录的信息,\(z_i\) 初始化为 \(0\),然后暴力扩展匹配;
-
若 \(r \ge i\),考虑如何使用前面已知的 \(z\),那么 \(S[1,r-l+1] = S[l,r]\),那么可以利用 \(z_{i-l+1}\) 的值,但我们需要注意判断这个值是否会超过现在已经知道的最大右端点区间 \([l,r]\),因为在字符串中 \(> r\) 的位置还未遍历,是否能构成 LCP 还无法确定,所以 \(z_i\) 初始化为 \(min_{r-i+1,z_{i-l+1}}\),然后如刚刚一样暴力扩展。
不难发现,由于每次都取出右端点最大的 \(r\),所以暴力匹配中 \(r\) 是不断增大的,复杂度均摊一下为 \(O(n)\)。
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=2e7+10;
char a[N],b[N];
int n,m,z[N],p[N];
inline void getZ(char *s) {
int n=strlen(s+1);
for(int i=1;i<=n;i++)
z[i]=0;
z[1]=n;
int l=0,r=0;
for(int i=2;i<=n;i++) {
if(i<=r)
z[i]=min(z[i-(l-1)],r-i+1);
while(i+z[i]<=n&&s[i+z[i]]==s[1+z[i]])
++z[i];
if(i+z[i]-1>r)
l=i,r=i+z[i]-1;
}
return ;
}
inline void exkmp(char *s,char *t) {
int n=strlen(s+1);
int m=strlen(t+1);
for(int i=1;i<=n;i++)
p[i]=0;
int l=0,r=0;
for(int i=1;i<=n;i++) {
if(i<=r)
p[i]=min(z[i-(l-1)],r-i+1);
while(i+p[i]<=n&&1+p[i]<=m&&s[i+p[i]]==t[1+p[i]])
++p[i];
if(i+p[i]-1>r)
l=i,r=i+p[i]-1;
}
return ;
}
signed main() {
scanf("%s%s",a+1,b+1);
getZ(b);
exkmp(a,b);
int ans=0;
for(int i=1;i<=strlen(b+1);i++)
ans^=i*(z[i]+1);
printf("%lld\n",ans);
ans=0;
for(int i=1;i<=strlen(a+1);i++)
ans^=i*(p[i]+1);
printf("%lld\n",ans);
return 0;
}
失配树
失配???听起来怎么那么奇妙...我不要失配!!!
引入
给出长为 \(n\) 的字符串 \(S\),每次询问 \(S_{:p},S_{:q}\) 的最长公共 Bd 长度。
方法
学完失配树,感觉对 KMP 的理解更深了一层...
先跑一遍 KMP,再建立 fail 树,怎么建立呢?
我们尝试让 \(i \to fail_i\) 连一条边,那么显然的,对于树上一个节点 \(u\),其所有的祖先都是该节点的 Bd。
我们还可以知道一些性质:
- 越靠近 \(u\) 的祖先,对应的字符串长度越长;反之,越远离 \(u\) 的祖先,对应的字符串长度越短。
如这个序列:
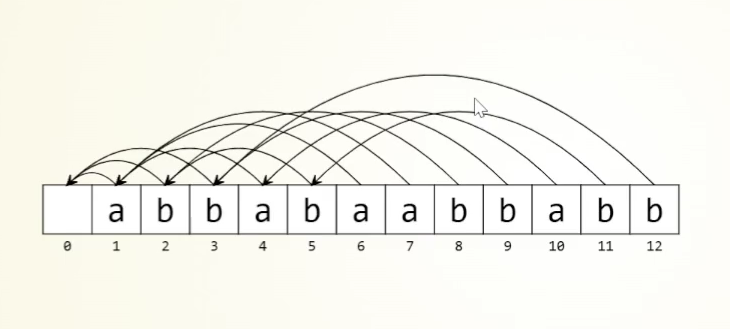
将其建立成失配树:
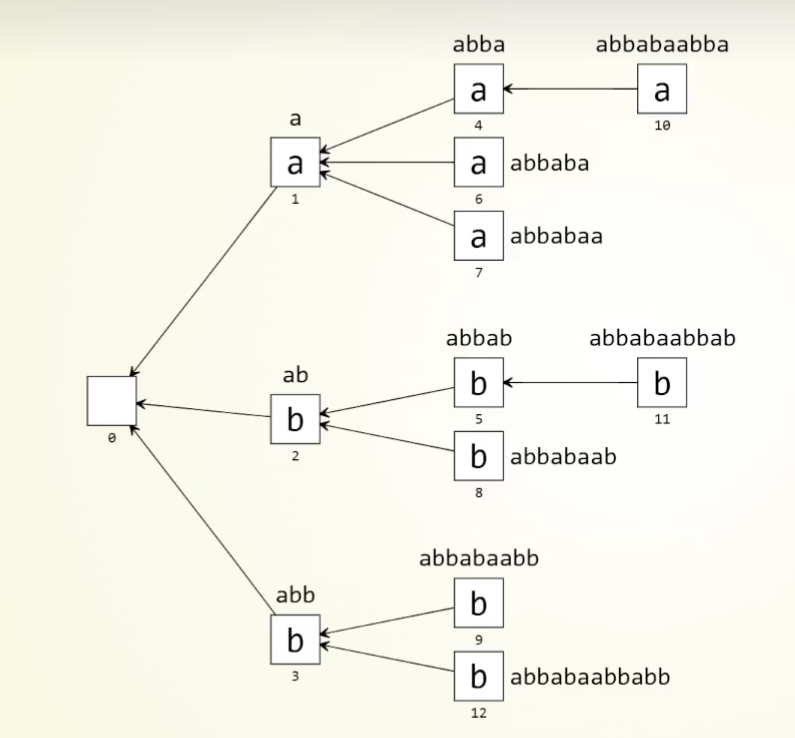
注意到 Bd 集合等价于祖先集合,引入中的询问等价于求最近公共祖先(特殊地,答案不能等于 \(p,q\))。
我们如果在树上从编号小到大模拟 KMP 的过程,便能感受到若字符串中某个位置失配后从大到小再次寻找正确的匹配,其实就在树上的一个找正确祖先的过程。
注意细节,在最后查询 LCA 的时候,由于不能取本身,需要特判。
还有:虚点的深度不能设为 \(-1\),否则会数组越界!!!
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=1e6+10;
char s[N];
int n,m,fail[N];
struct Node {
int to,nxt;
Node() {
to=nxt=0;
}
Node(int a,int b) {
to=a,nxt=b;
}
} adj[N<<1];
int head[N],idx;
int dep[N],f[N][22];
inline void add(int x,int y) {
adj[++idx]=Node(y,head[x]);
head[x]=idx;
return ;
}
inline void dfs(int u,int fa) {
dep[u]=dep[fa]+1,f[u][0]=fa;
for(int i=1;i<=20;i++)
f[u][i]=f[f[u][i-1]][i-1];
for(int i=head[u];i;i=adj[i].nxt) {
int v=adj[i].to;
if(v==fa)
continue;
dfs(v,u);
}
return ;
}
inline int lca(int x,int y) {
if(dep[x]<dep[y])
swap(x,y);
for(int i=20;i>=0;i--) {
if(dep[f[x][i]]>=dep[y])
x=f[x][i];
}
if(x==y)
return x;
for(int i=20;i>=0;i--) {
if(f[x][i]!=f[y][i]) {
x=f[x][i];
y=f[y][i];
}
}
return f[x][0];
}
signed main() {
scanf("%s",s+1);
n=strlen(s+1);
for(int i=2,j=0;i<=n;i++) {
while(j&&s[i]!=s[j+1])
j=fail[j];
if(s[i]==s[j+1])
++j;
fail[i]=j;
}
for(int i=1;i<=n;i++)
add(fail[i],i),add(i,fail[i]);
dfs(0,0);
scanf("%lld",&m);
while(m--) {
int x,y;
scanf("%lld%lld",&x,&y);
int z=lca(x,y);
if(x==z||y==z)
printf("%lld\n",f[z][0]);
else printf("%lld\n",z);
}
return 0;
}
AC 自动机
闲话
yyc 在给我一对一辅导的时候还普及了一下自动机是啥???没懂~~~
前置知识
-
Trie 树
-
KMP 算法
ok,这些肯定都已经掌握的炉火纯青了,直接进入正题。
引入
给定 \(n\) 个模式串和 \(1\) 个文本串,处理文本串中出现的模式串的相关问题。
建立 Trie 树和 fail 树
先把所有的模式串全部扔进 Trie 树中,在每个字符串的结尾打上标记;
类似 KMP 地,我们还需要 \(fail_i\) 数组来记录字符串 \(i\) 的后缀,用于快速寻找字符串失配后所指向的点。
假设现有的模式串集合为 \(\{ abab , babb \}\):
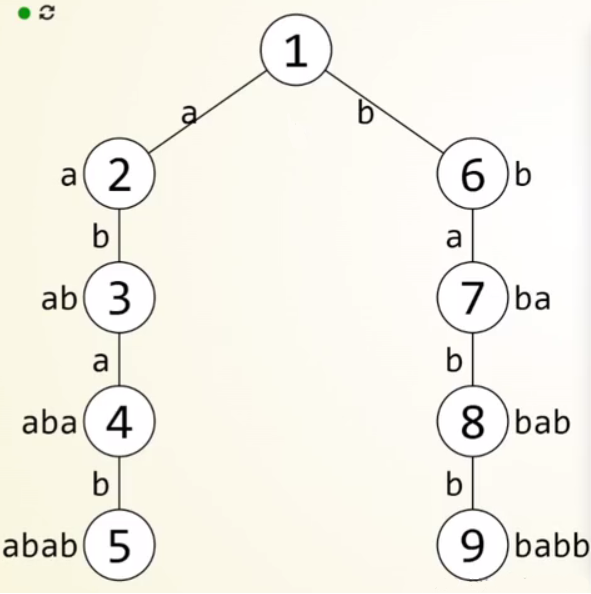
初始的时候 \(fail_2\) 和 \(fail_6\) 肯定都是指向虚点 \(1\) 的,现在进一步深入求 \(2\) 所连接的儿子 \(3\);
脑子里联系一下 KMP 匹配时的过程,这里同样的在另一边让指针停留在 \(fail_2\) 上,也就是 \(1\) 号点,尝试进行匹配字符 \(b\),发现 \(6\) 号点符合条件,直接让其 \(fail_3\) 指向 \(6\);
若没有匹配成功(失配),那就可以从实行上面在讲 KMP 时已经说过的跳 fail 操作即可 \(^{[1]}\),不过在这里直接跳的复杂度有可能会过大,还不如像压缩路径一样直接指过去,不跳先,最后查询时再跳也可以\(^{[2]}\)(也就是说可以有两种方法处理)。
AC 自动机实际上由两棵树构成,一棵 Trie 树,一棵 fail 树,把模式串集合改为 \(\{ abab , babb \}\),为了更加清楚地展现 AC 自动机,这里采用了第一种方法的图,处理出来的图应该是这样的(实线时 Trie 树,虚线是 fail 指针)
:
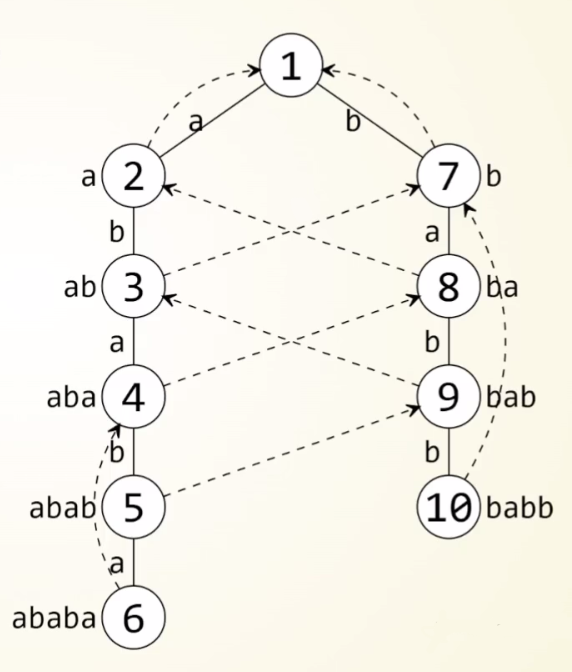
沿着 Trie 树往下走,本质是字符串的延展的过程:
- \(1 \to 2 \to 3 \to 4\)
- \(空串 \to a \to ab \to aba\)
沿着 fail 树往上走,本质上是在切割字符串,留下字符是某个后缀部分:
- \(6 \to 4 \to 8 \to 2 \to 1\)
- \(ababa \to aba \to ba \to a \to 空串\)
在打代码时我选择了时间更优的第二种实现方法:
重点:这里的方法二有一个很奇妙的地方,若 Trie 树中 \(u\) 没有指向字符 \(i\) 的点 \(trie_{u,i}\),也就是说这个点所代表的字符串在模式串中是失配的,但是我们为了优化时间,不能像方法一那样跳 fail 去匹配,那不如直接让 \(trie_{u,i}\) 等效赋到 \(trie_{fail_u,i}\) 上!!!
Code
inline void get_fail() {
queue<int> q;
for(int i=0;i<26;i++) {
if(trie[0][i]) {
fail[trie[0][i]]=0;
q.push(trie[0][i]);
}
}
while(!q.empty()) {
int u=q.front();
q.pop();
for(int i=0;i<26;i++) {
if(trie[u][i]) {
fail[trie[u][i]]=trie[fail[u]][i];
q.push(trie[u][i]);
} else trie[u][i]=trie[fail[u]][i];
}
}
return ;
}
查询问题
① 在文本串中出现的模式串的个数
直接遍历整个字符串,从字典树的头往下找,对于 Trie 树上某个点上的串,利用 fail 指针遍历其所有的后缀串,并统计入答案,为了防止过度无用的遍历,需要加上标记;
定义所有模式串的总长为 \(n\),则时间复杂度为 \(O(n)\)。
inline int query(string s) {
int p=0,res=0;
for(int i=0;i<s.size();i++) {
int tem=s[i]-'a';
p=trie[p][tem];
for(int now=p;now&&!vis[now];now=fail[now]) {
res+=cnt[now];
vis[now]=1;
}
}
return res;
}
② 在文本串中每个模式串出现的次数
我们先要将 Trie 树中每个字符串尾的标记改为其编号,即 \(cnt_p \leftarrow id\);
在查询的时候不能再打标记了,因为我们需要多次经过同一个串。
这里每到一个串跳 fail 的时候,所在点处于的树深度是在不断减小的,最坏的情况下就会跳完一个模式串的长度,若最长模式串的长度为 \(n\),文本串的长度为 \(m\),则复杂度为 \(O(nm)\)。
inline void query(string s) {
int p=0;
for(int i=0;i<s.size();i++) {
int tem=s[i]-'a'+1;
p=trie[p][tem];
for(int now=p;now;now=fail[now])
sum[cnt[now]]++;
}
return ;
}
优化
像刚刚上面所述去求每个模式串出现的次数的时候的 \(O(nm)\) 做法明显很劣,我们可以发现这个算法的最大问题在于在查询的时候,跳 fail 太过于频繁了,考虑如何化简这个过程;
尝试寻找多次跳 fail 操作的相同路径,这不就有点相似与拓扑排序的计数吗???而且 fail 树也是属于 DAG 图;
在查询的时候不跳 fail,只用在当前串的点上添加贡献值,最后跑一遍拓扑排序即可,时间复杂度是线性的。
这里还要注意模式串是否保证两两不相同的问题。
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=2e5+10;
string s,t[N];
int n,trie[N][32],idx;
int rd[N],cnt[N],fail[N];
int ind[N],res[N],ans[N];
inline void insert(string s,int id) {
int p=0;
for(int i=0;i<s.size();i++) {
int tem=s[i]-'a'+1;
if(!trie[p][tem])
trie[p][tem]=++idx;
p=trie[p][tem];
}
if(!cnt[p])
cnt[p]=id;
rd[id]=cnt[p];
return ;
}
inline void get_fail() {
queue<int> q;
for(int i=1;i<=26;i++) {
if(trie[0][i]) {
fail[trie[0][i]]=0;
q.push(trie[0][i]);
}
}
while(!q.empty()) {
int u=q.front();
q.pop();
for(int i=1;i<=26;i++) {
if(trie[u][i]) {
fail[trie[u][i]]=trie[fail[u]][i];
ind[fail[trie[u][i]]]++;
q.push(trie[u][i]);
} else trie[u][i]=trie[fail[u]][i];
}
}
return ;
}
inline void query(string s) {
int p=0;
for(int i=0;i<s.size();i++) {
int tem=s[i]-'a'+1;
p=trie[p][tem],res[p]++;
}
return ;
}
inline void topsort() {
queue<int> q;
for(int i=1;i<=idx;i++) {
if(!ind[i])
q.push(i);
}
while(!q.empty()) {
int u=q.front();
q.pop();
ans[cnt[u]]=res[u];
res[fail[u]]+=res[u];
--ind[fail[u]];
if(!ind[fail[u]])
q.push(fail[u]);
}
return ;
}
signed main() {
scanf("%lld",&n);
for(int i=1;i<=n;i++) {
cin>>t[i];
insert(t[i],i);
}
get_fail();
cin>>s;
query(s);
topsort();
for(int i=1;i<=n;i++)
printf("%lld\n",ans[rd[i]]);
return 0;
}
回文自动机(PAM)/回文树
引入
给定一个字符串 \(s\),求以第 \(i\) 个位置为结尾的回文子串的个数。
实现
在 AC 自动机的基础上学习回文自动机更加容易理解。
首先的,回文串有奇数偶数之分,如果像 Manacher 等算法,在字符串中加入分隔符 # 将所有回文串的长度都变为奇数,这样明显很麻烦;
尝试建立两棵回文树,分别用于储存长度为偶数和奇数的回文子串,两棵树的根分别记为偶根和奇根;
从根往下走,每经过一条边,权值为字符 \(x\),下一个节点所代表字符串就是在当前字符串的前后分别添加上字符 \(x\);特殊地,对于奇根所连接的点,只需要添加一次。
回文树中的每个节点也应该有自己的 fail 指针,指向除自己外最长的的回文后缀;
对于初始状态,可以将偶根的 fail 指针指向奇根,因为奇根永远不会失配,所有长度为 \(1\) 的串都是回文串。
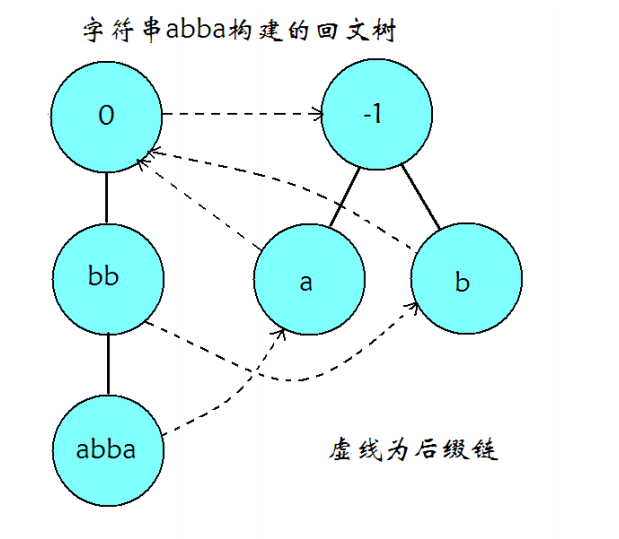
图片源自OI-WIKI,后缀链其实就是 fail 指针。
定义 \(len_i\) 表示该节点所代表的字符串的长度,显然的对于节点 \(u\),\(len_u = len_{fa_u}\),为了处理方便,可以将奇根的 \(len\) 赋值为 \(-1\)。
PAM 的构造方法是在线的,处理到第 \(i\) 个字符,前 \(i-1\) 个字符已经全部都构造完了,对于以第 \(i\) 个字符为结尾的回文串,将其头尾各去掉一个字符,那不就变成了寻找以第 \(i-1\) 个字符为结尾的回文串中最长的回文后缀 \([p,i-1]\),且满足 \(s_{p-1} = s_i\),又是跳 fail!!!
fail[++idx]=trie[u][tem];
这真的是个很神奇的操作,上面的 AC 自动机中已经重点提过了一次,再说一下:
和上面 AC 自动机的同一个操作有一点不同,AC 自动机的 \(fail_i\) 有可能指向的是虚点,也就是说,可能在以前的所有字符串中没出现过以 \(i\) 结尾的相同后缀(而 \(fail_i\) 又不一定指向的是本串上的点,有随机性),而且很显然,这样操作对最终答案的正确性并没有影响(数组开都开了,不用太浪费了,哦,对了,还要注意是否会爆空间!!!);
但是回文自动机中的就不一样了,\(fail_i\) 指向的是实点,若以第 \(i\) 个字符为结尾的回文串有最长回文后缀,那么记录这个后缀的点必然在回文树上出现过,其本质就是在自己原本的串上指 fail。
最后计数时非常好理解,\(num_u = num_{fail_u}+1\),就是在上一个回文后缀的基础上多了一个更大的嘛...
我一开始把 \(fail_u\) 记错了,导致一直陷入理解死循环; 回文树中的 \(fail_u\) 是指 \(u\) 节点所代表的字符串的最长的的回文后缀!!!
分析一下 PAM 的势能,设当前最长回文后缀所在的点是 \(now\),每次跳 fail 必然都是沿着 \(now\) 到根所形成的链去跳,链的长度最多累计增加 \(n\) 次,那么就意味着最多能跳 \(n\) 次 fail,这才是程序的精髓部分!!!
假设字符串的长度为 \(n\),时间复杂度为 \(O(n)\)。
Code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=5e5+10;
string s;
int trie[N][52];
int idx=1,fail[N];
int len[N],num[N];
inline int get_fail(int x,int i) {
while(i-len[x]-1<0||s[i-len[x]-1]!=s[i])
x=fail[x];
return x;
}
signed main() {
cin>>s;
int n=s.size();
int now=0,last;
fail[0]=1,len[1]=-1;
for(int i=0;i<n;i++) {
if(i>=1)
s[i]=(s[i]+last-97)%26+97;
int p=get_fail(now,i);
int tem=s[i]-97;
if(!trie[p][tem]) {
int u=get_fail(fail[p],i);
fail[++idx]=trie[u][tem];
trie[p][tem]=idx;
len[idx]=len[p]+2;
num[idx]=num[fail[idx]]+1;
}
now=trie[p][tem];
last=num[now];
printf("%lld ",last);
}
printf("\n");
return 0;
}
数据结构选讲
- \(2025/01/24\)
序列扫描线
实现
\(\sum_{l=1}^{n}\sum_{r=l}^{n} (f(l,r))^{2} = \sum_{r=1}^{n} \sum_{l=1}^{r} (f(l,r))^{2}\)
定义 \(g_l=f(l,r)\),则变为求 \(\sum_{r=1}^{n} \sum_{l=1}^{r} g_l^2\);
这里记 \(lst_i\) 为 \(a_i\) 最后出现的位置。
按 \(r\) 从小到大顺序遍历,考虑 \(r\) 增大 \(1\) 会对 \(g\) 产生怎样的影响:
-
\(l \le lst_{r}\),这时的 \(f(l,r-1)\) 中已经包含 \(a_r\),故 \(f(l,r)=f(l,r-1)\),对 \(g_l\) 不产生贡献,\(g_l\) 不变;
-
\(l > lst_{r}\),说明 \(f(l,r-1)\) 中不包含 \(a_r\),多了一种数字,产生一点贡献,\(g_l \leftarrow g_l+1\)。
综上所述,我们可以用区间加维护 \(g\),除此还需要记录答案的平方和;
区间和的修改是简单的,在这里再推一下区间平方(利用平方和公式):
时间复杂度为 \(O(n\log{n})\)。
最后说一下在下沉信息时要注意更新顺序,先更新区间平方和,在更新区间和;
还有,本题线段树的常数较大,需要开 O2 才能过(听说不勤取模也可以过);可以尝试使用二位树状数组。
刚刚还看到一个很好的方法:
设 \(g_r=\sum_{l=1}^{r}\),则本题答案为 \(\sum_{r=1}^{n}g_r\)。
这里同样记 \(lst_i\) 为 \(a_i\) 最后出现的位置。
也是考虑 \(r-1 \to r\) 的变化:
在 \(l \in (lst_{r},r]\) 的范围内 \(f(l,r)=f(l,r-1)+1\);其余部分是不变得,对 \(g\) 也无影响。
那么:
显然的,我们只需要维护 \(f(l,r)\) 的一段区间和,其中还要使 \(l \in (lst_{r},r]\) 加 \(1\) 即可。
扫描线
定义
顾名思义,就是一条线在一个二维的图上扫描,用来解决图形面积,周长,以及二维数点等问题。
二维矩形面积并问题
在二维坐标系上,给出多个矩形的左下以及右上坐标,求出所有矩形构成的图形的面积。
实现方法
对于一个二维图,扫描线可以从左到右,也可以从上到下,我选择后者,感觉好理解些。
其实我们可以把几个图形的并集切分为多个矩形,然后一一算出面积再相加即可。
观察图形,发现影响面积的因素有上下的横线、左右端点的坐标;
尝试将一个矩形的上边赋值为 \(-1\),下边赋值为 \(1\),这样扫描线从下扫到上面,前缀和差分一样,就不会出现负数的情况,便于计算;
为了快速计算每一次扫描线所截线段(横切)的长度,我们需要用到线段树。
对于所有矩形左右端点 \(x_i\) 取出来并排序去重,对于每一条横边,我们存下其左右端点,高度,权值(下边 \(1\),上边 \(-1\)),所有按照高度从小到大排序;
处理完同一高度的总横截长度,再乘相邻两段高度不同横截的高度差,就是这一层的矩形面积。
下面是 OI-WIKI 提供的动图:

现在还有个问题,如何建线段树,和往常的建树不一样,会发现,按照普通的线段树相邻两个儿子端点之间是相差 \(1\) 的,我们需要求的是线段,若答案就在左儿子右端点和右儿子左端点构成的线段区间中,那不就炸了吗!那如何解决呢?
那就按病下药,将左儿子端点和右儿子端点标号一样不就行了嘛!但为了更加贴近平时的写法,我们也可以在查询区间 \([l,r]\) 时,实际上取的值域为 \([x_l,x_{r+1}]\)。
我们需要特别注意上传信息时:
我们始终要求的都是线段,所以不应该找到一个点(多余),否则需要多开一倍的空间;
由于上面讲的线段树上的区间 \([l,r]\) 所对应的真实区间为 \([l,r+1]\),所以在代码中我们直到区间 \(l=r\) 时,就不能再向下遍历了,可以返回并上传信息。
为什么要打一个 \(cnt\) 记作区间是否全部被覆盖呢?
和上面类似的的,到最小的区间的时候,也就是 \(l=r\) 时,下面的区间没有任何信息可以上传,也就是说不能将两个儿子的所截线段长度相加(因为都为 \(0\)),此时只能暴力标记判断区间是否被覆盖,直接赋值。
应该这样打:
inline void push_up(int rt,int l,int r) {
if(tree[rt].cnt)
tree[rt].len=x[r+1]-x[l];
else {
if(l==r)
tree[rt].len=0;
else tree[rt].len=tree[lson].len+tree[rson].len;
}
return ;
}
最后,假设去重之后 \(x\) 序列的大小为 \(m\),总的线段树的范围应该是 \([1,m-1]\),所对应的实际区间为 \([1,m]\)。
算法瓶颈在线段树和排序去重,时间复杂度为 \(O(n\log{n})\)。
Code
#include<bits/stdc++.h>
#define int long long
#define lson rt<<1
#define rson rt<<1|1
using namespace std;
const int N=2e5+10;
int n,x[N];
struct Node {
int l,r,h,k;
} line[N];
struct Tree {
int len,cnt;
} tree[N<<3];
inline bool cmp(Node x,Node y) {
return x.h<y.h;
}
inline void push_up(int rt,int l,int r) {
if(tree[rt].cnt)
tree[rt].len=x[r+1]-x[l];
else {
if(l==r)
tree[rt].len=0;
else tree[rt].len=tree[lson].len+tree[rson].len;
}
return ;
}
inline void update(int rt,int l,int r,int s,int t,int k) {
if(x[r+1]<=s||t<=x[l])
return ;
if(s<=x[l]&&x[r+1]<=t) {
tree[rt].cnt+=k;
push_up(rt,l,r);
return ;
}
int mid=(l+r)>>1;
update(lson,l,mid,s,t,k);
update(rson,mid+1,r,s,t,k);
push_up(rt,l,r);
return ;
}
signed main() {
scanf("%lld",&n);
for(int i=1;i<=n;i++) {
int x1,y1,x2,y2;
scanf("%lld%lld%lld%lld",&x1,&y1,&x2,&y2);
x[i]=x1,x[i+n]=x2;
line[i]=(Node){x1,x2,y1,1};
line[i+n]=(Node){x1,x2,y2,-1};
}
n*=2;
sort(x+1,x+n+1);
sort(line+1,line+n+1,cmp);
int tot=unique(x+1,x+n+1)-(x+1);
int ans=0;
for(int i=1;i<n;i++) {
update(1,1,tot-1,line[i].l,line[i].r,line[i].k);
ans+=tree[1].len*(line[i+1].h-line[i].h);
}
printf("%lld\n",ans);
return 0;
}
二维矩形合并后周长问题
[IOI1998] [USACO5.5] 矩形周长Picture
有点小难处理...
upd:2025/09/22
前几天再看这题依旧感觉很难处理,但是已经想到了大体的思路,就是对 \(x\) 做扫描线,线段树维护区间被覆盖次数,覆盖的总长度,和不相交的覆盖区间的个数,左端点是否被覆盖,右端点是否被覆盖。
但是由于我执着于下传标记,并区间查询去求贡献,这样做的话,维护的东西太多了,而且删除线段时如果也有贡献的话并不好处理,代码难度直接飙升,故放弃;后面看题解发现了本来的思路就是对的。
然后就想着把行和列上的线段分开来计算贡献,那样线段树就只用记录区间被覆盖的次数,覆盖的总长度,维护方式跟上面的求面积时一样;
令上一次操作的整个值域的被覆盖总长度为 \(x\),发现对于加删操作的贡献,再令操作后的整个值域的被覆盖总长度为 \(y\),其实就是 \(|x - y|\),即变化量。
分析上面计算贡献的正确性(以对 \(x\) 做扫描线,计算列上的线段为例):
-
加入线段,像下图中加入黄色矩阵的左线段时,空的区间为紫色线段,说明这段区间没有被前面加入的其他矩阵覆盖到,所以紫色线段时要计入矩阵并周长的贡献里的,这个贡献就是加入黄左线段后整个值被域覆盖长度的增加量;
-
删除线段树,如下图中蓝色矩阵的右线段,当删除线段所在区间后,发现橙色线段所在的区间从覆盖到无覆盖,说明这一段区间在之前只被蓝色矩阵覆盖了,所以其也是矩阵并后的周长的一部分,并发现贡献为删除蓝右线段后整个值域被覆盖长度的减小量。
综上所述,每次操作对周长的贡献为操作前后值域被覆盖长度的变化量。
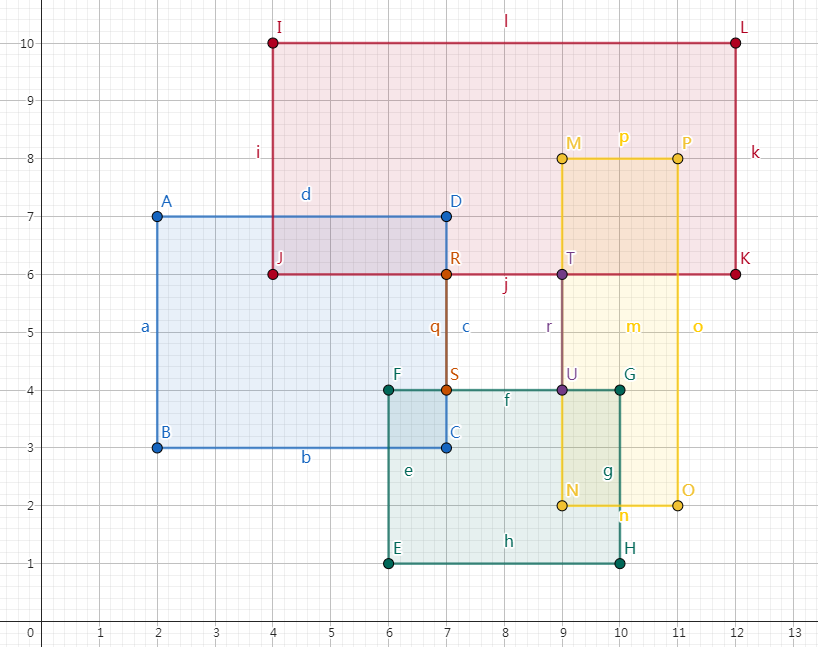
闲话/反思:这个是我一开始没有发现的,所以一直想着下传懒标记,然后对操作的区间去做查询,这样是麻烦的。
下面暂时只有第二种写法的 Code,后续有时间会补。
Code2
#include<bits/stdc++.h>
#define int long long
#define lson rt<<1
#define rson rt<<1|1
using namespace std;
const int N=5201;
int n,m;
struct Node {
int x1,y1,x2,y2;
} a[N];
struct Line {
int x,id,k;
} line[N*2];
struct Tree {
int cnt,len;
} tr[(N*2)<<2];
int tot,unq[N*2];
inline void push_up(int rt,int l,int r) {
if(tr[rt].cnt)
tr[rt].len=unq[r+1]-unq[l];
else {
if(l==r) tr[rt].len=0;
else tr[rt].len=tr[lson].len+tr[rson].len;
}
return ;
}
inline void build(int rt,int l,int r) {
if(l==r) {
tr[rt].cnt=tr[rt].len=0;
return ;
}
int mid=(l+r)>>1;
build(lson,l,mid);
build(rson,mid+1,r);
push_up(rt,l,r);
return ;
}
inline void update(int rt,int l,int r,int s,int t,int k) {
if(l>t||r<s)
return ;
if(s<=l&&r<=t) {
tr[rt].cnt+=k;
push_up(rt,l,r);
return ;
}
int mid=(l+r)>>1;
update(lson,l,mid,s,t,k);
update(rson,mid+1,r,s,t,k);
push_up(rt,l,r);
return ;
}
inline bool cmp(Line x,Line y) {
if(x.x!=y.x)
return x.x<y.x;
return x.k>y.k;
}
signed main() {
scanf("%lld",&n);
int ans=0,lst=0;
for(int i=1;i<=n;i++) {
scanf("%lld%lld%lld%lld",&a[i].x1,&a[i].y1,&a[i].x2,&a[i].y2);
unq[++tot]=a[i].y1,unq[++tot]=a[i].y2;
line[++m]=(Line){a[i].x1,i,1};
line[++m]=(Line){a[i].x2,i,-1};
}
sort(line+1,line+1+m,cmp);
sort(unq+1,unq+1+tot);
tot=unique(unq+1,unq+1+tot)-(unq+1);
build(1,1,tot-1);
for(int i=1;i<=m;i++) {
int id=line[i].id;
int p1=lower_bound(unq+1,unq+1+tot,a[id].y1)-unq;
int p2=lower_bound(unq+1,unq+1+tot,a[id].y2)-unq-1;
update(1,1,tot,p1,p2,line[i].k);
ans+=abs(tr[1].len-lst),lst=tr[1].len;
}
tot=m=lst=0;
for(int i=1;i<=n;i++) {
unq[++tot]=a[i].x1,unq[++tot]=a[i].x2;
line[++m]=(Line){a[i].y1,i,1};
line[++m]=(Line){a[i].y2,i,-1};
}
sort(line+1,line+1+m,cmp);
sort(unq+1,unq+1+tot);
tot=unique(unq+1,unq+1+tot)-(unq+1);
build(1,1,tot);
for(int i=1;i<=m;i++) {
int id=line[i].id;
int p1=lower_bound(unq+1,unq+1+tot,a[id].x1)-unq;
int p2=lower_bound(unq+1,unq+1+tot,a[id].x2)-unq-1;
update(1,1,tot,p1,p2,line[i].k);
ans+=abs(tr[1].len-lst),lst=tr[1].len;
}
printf("%lld\n",ans);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号