
04 Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
起源:hadoop实现在大量计算机组成的集群中对海量数据进行分布式计算。适合大数据的分布式存储和计算平台。
发展阶段:
-
2002~2004
当时第一轮互联网泡沫刚刚破灭, 一个对搜索引擎特别了解但是同时又失去工作的屌丝
Doug Cutting(1), 当时主要靠写点技术专栏文章赚赚稿费。同时, 他联合了另外一个RD
Mike Cafarella, 当时两人觉得以后搜索被一个大公司给一统天下是一个很可怕的事情, 这家公司掌握信息入口, 能翻手为云覆手为雨。所以决定自己搞一个开源的搜索引擎出来, 于是说干就干, 干了个项目叫
Nutch。两人吭哧吭哧干了一年之后, 终于把这个系统干到能支持1亿网页的抓取, 索引和搜索了。但是当时的网站差不多就有10亿, 网页数量是万亿这个规模。这两哥们也没多想, 就是干, 继续把网页量给干到下一个数量级。
-
2004~2006
结果很不巧, 在那个时候, Google公布了GFS和MapReduce两篇Paper。这两哥们一看, 完了, 这两年白干了, 人家干得那才是漂亮, 自己现在干得实在是太苦逼了, 所有工作都处于人肉运维的状态。
那咋办呢, 重构呗, 咋重构啊, 抄一个呗。于是就开始抄GFS和MapReduce, Google用的C++做, 他们用的Java做。到2004年的时候, 已经差不多能在40台左右的机器上运行了。
-
2006以后
Dog Cutting跟好多我们同龄人一样, 做了几年公司, 发现干也干不过google了, 好像创业没啥前途了, 那咋办呢, 就找个大公司吧。这哥们本来一开始想去IBM, 但是人家IBM要做lucene, 不用Nutch。这哥们表示不开心, 就去问Yahoo愿不愿意要Nutch, 人家Yahoo有自己的搜索引擎, 也不愿意要Nutch。不过Yahoo考虑了一下, 说虽然不要你的搜索系统, 但是你底层那几个GFS/MapReduce那些东西还是挺有用的嘛, 要不你过来弄这个?Dog Cutting也就从了, 于是把底层系统剥离出来, 把自己儿子的一个大象的玩具的名字Hadoop赋予了这个项目。但是到目前为止, Hadoop其实还不能称之为一个独立的大数据项目, 顶多只能称之为一个搜索系统的子项目, 因为他只有一个应用方, 就是搜索。
-
2006~
当系统进入yahoo了以后, 项目逐渐发展并成熟了起来。首先是集群规模, 从最开始的几十台机器的规模发展到能支持上千个节点的机器, 中间做了很多工程性质的工作, 然后是除搜索以外的业务放, yahoo逐步将自己的广告系统的数据挖掘相关工作也迁移到了hadoop上面来, 进一步成熟化了hadoop系统。
当有多个用户方在使用hadoop系统的时候, 又必须要增加qos调度队列等机制, 也必须要增加数据安全认证授权机制等等, 各种功能都加到hadoop上面来的时候, hadoop就算是真正成熟起来了。必须要称道的一点是, 在成熟化整个系统的过程当中, yahoo一直都将hadoop做成一个开源软件, 而不是自己的私有软件。
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
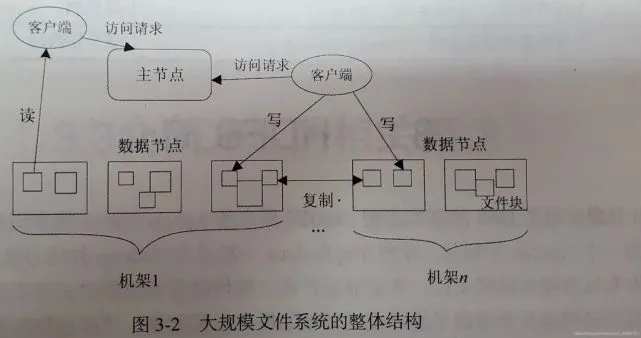
名称节点功能:在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog;
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是 单独运行在一台机器上;
数据节点:数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调 度来进行数据的存储和检 索,并且向名称节点定期发送自己所存储的块的列表。 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
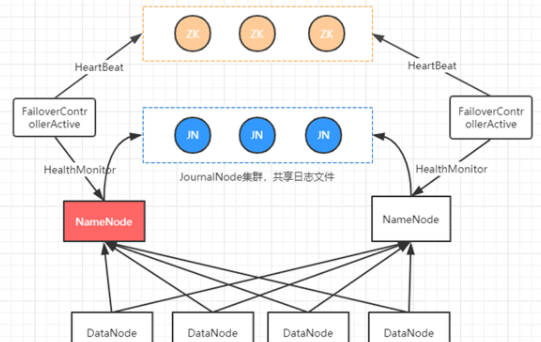
1.HDFS结构体系和组成元素,HDFS2.x采用zookeeper实现NameNode主从节点选举,切换,监控;采用JournalNode集群共享NameNode节点的日志数据;DataNode则向主NameNode汇报。![]()
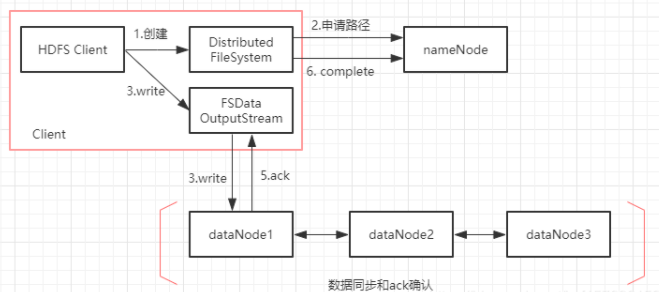
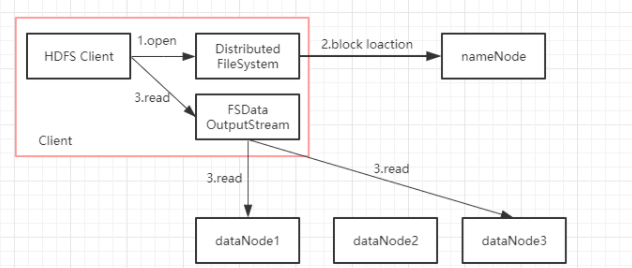
2.写流程,HDFS通过客户端写入文件,会先向NameNode申请存储Block块的路径,通过FSDataOutputStream将文件写入到对应的DataNode节点并通过ack确认数据写入成功。此时客户端已完成写入操作,但DataNode会遵循Block副本的放置策略,将Block数据另外同步给其他两个节点。![]()
3.读流程,HDFS通过客户端读取文件,会先访问NameNode,获取文件Block块的放置信息,再直接访问对应DataNode获取文件数据。
![]()
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
———负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡。 - Region服务器的功能
——负责存储和维护分配给自己的Region,处理来自客户端的读写请求,是真正干活的节点。 - Zookeeper协同的功能
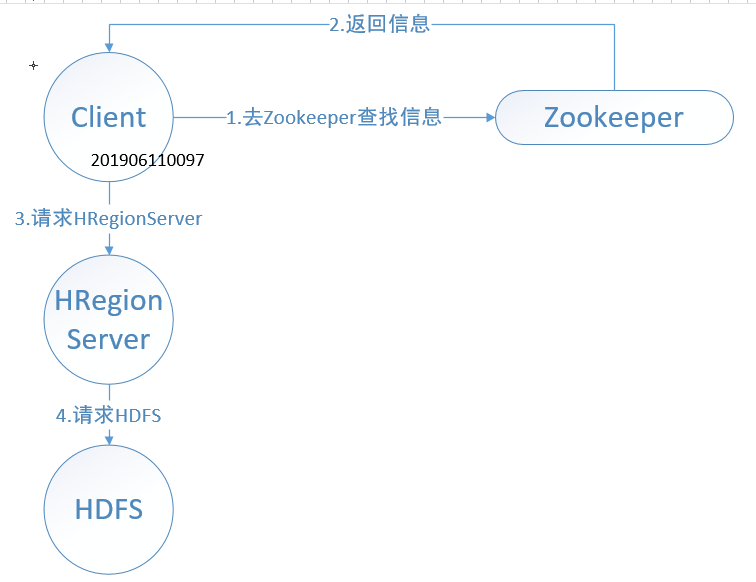
HQuorumPeer,HBase管理的Zookeeper ——外Client访问请求,向下层HDFS读写数据,内HRegionServer的健康状态。 - Client客户端的请求流程
![]()
5.把读写信信息返回给Client
![]()
- 与HDFS的关联
HBase是一个内存数据库,而HDFS是一个存储空间。
HDFS是Hadoop分布式文件系统。
HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
5.理解并描述Hbase表与Region的关系。
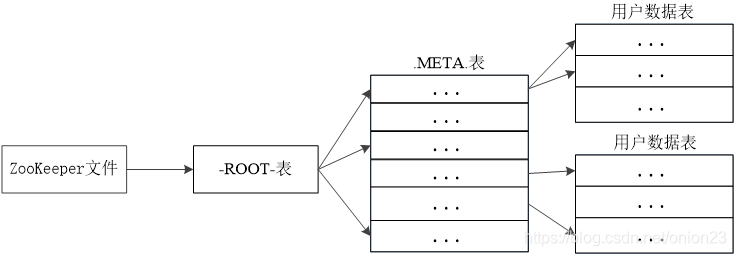
HBase内部维护着两个元数据表,分别是-ROOT- 和 .META. 表 他们分别维护者当前集群所有region 的列表、状态和位置。-ROOT-表包含.META.表的region 列表,因为.META.表 可能会因为超过region的大小而进行分裂,所以-ROOT-才会保存.META.表的region索引,-ROOT-表是不会分裂的 。而.META. 表中则 包含所有用户region(user-space region)的列表。表中的项使用region 名作为键。region名由所属的表名、region的起始行、创建的时间 以及对其整体进行MD5 hash值。6.理解并描述Hbase的三级寻址。
三级寻址顺序为:Zookeeper文件,-ROOT-表,.MEATA.表![]()
![]()
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
- Master主服务器的功能
- 4ZB
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。 -
主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
1、Client:程序通过Client提交到JT端,可以通过Cilent提供的接口查看作业运行状态。
2、JobTracker: 监控资源、调度作业,监控所有的TT和Job的健康,一旦发现失败,就会将任务转移到其他节点。
3、TaskTracker: 想JT汇报资源使用情况和作业运行情况,接受JT的命令并执行。
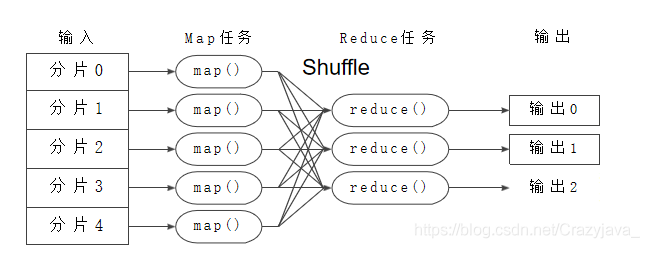
4、Task: Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。9.MapReduce的工作过程,用自己的例子,将整个过程梳理并用图形表达出来。
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号