

【AI语音】本地部署 - SenseVoice多语言语音理解模型Small
前言
最近了解到很多语音类产品都在使用 SenseVoice,包括小智 AI,我个人之前也简单了解过一些其基本内容,但是对于到底怎么用还是不明白,所以我寻思着自己在本地部署试一试。加深下对于这种模型之类的使用的理解。这里和大家分享下
开发环境:
- 工具:
VSCode - 操作系统:
Windows 10
1. 简介
SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或声学事件检测(AED)。
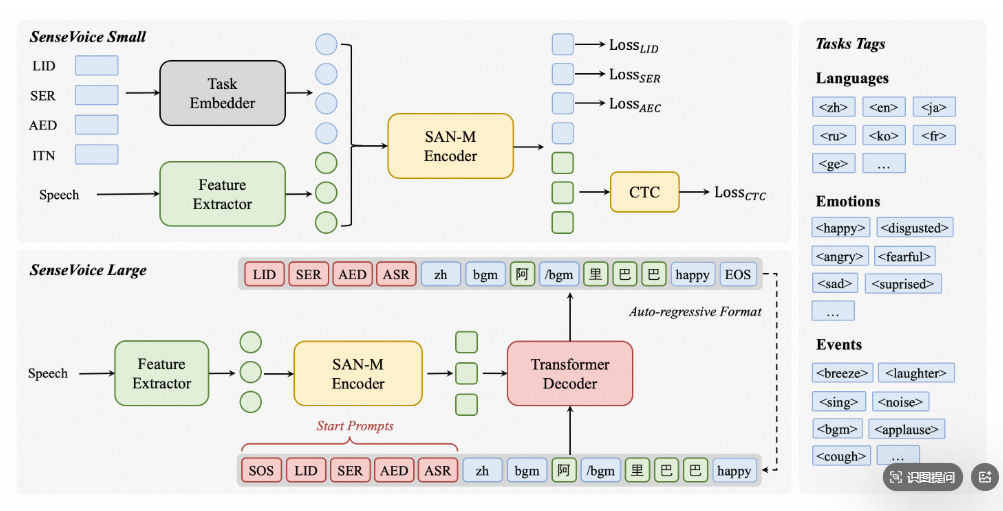
上图中左边提到的,SenseVoice-Small 和 SenseVoice-Large 本质上是同一技术框架下的两个不同尺寸的模型,就像手机有“标准版”和“Pro版”的区别。
然后最右边的输出,是指经过模型的推理之后,所输出的信息包含哪些,例如 Language(语种)/ Emotion(情感)/ Event(事件)
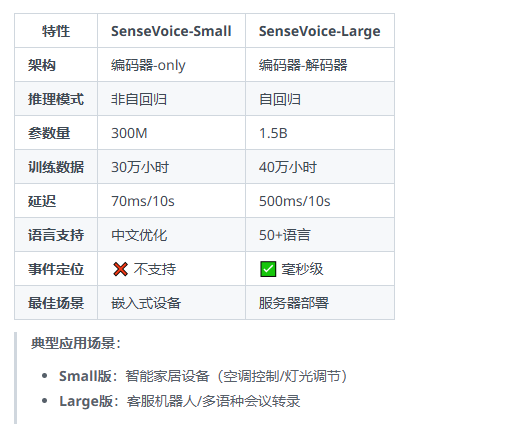
两种模型的区别
这里我们主要是使用 SenseVoice-Small
2. 环境搭建
2.1 模型下载
模型下载有两种方式,分别是 SDK 下载(代码运行时下载)还有就是通过 Git 进行下载。
SDK 下载:
# 安装 ModelScope
pip install modelscope # SDK 模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('iic/SenseVoiceSmall') Git 下载:
git clone https://www.modelscope.cn/iic/SenseVoiceSmall.git 注意点:
我在尝试时本来是先使用的 Git 下载,下载到了本地。结果运行 demo 时,其自动又触发了下载模型到我的 C 盘。
然后发现:
- 自动下载行为是由
AutoModel初始化时的model_dir = "iic/SenseVoiceSmall"参数导致的AutoModel来自FunASR库,当指定model_dir为相对路径"iic/SenseVoiceSmall"时,它会自动从远程下载模型到该路径- 要阻止自动下载,可以修改代码使用本地已有模型路径,当前工作目录下已有
SenseVoiceSmall目录- 需要将
model_dir = "iic/SenseVoiceSmall"改为使用本地路径model_dir = "./SenseVoiceSmall"
代码介绍
下载完成后如下图所示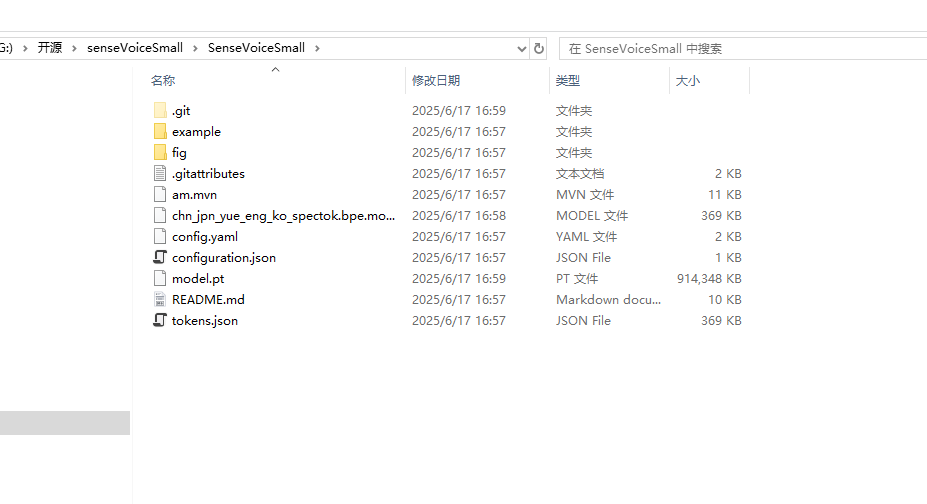
其核心文件主要包括:
tokens.json- 可能包含语音识别使用的token词汇表chn_jpn_yue_eng_ko_spectok.bpe.model- 多语言(中/日/粤/英/韩)BPE(Byte Pair Encoding)模型文件model.pt-PyTorch训练好的模型权重文件config.yaml/configuration.json- 项目配置文件
example 文件:
- 多语言音频样本(
en/ja/ko/yue/zh.mp3)
2.2 依赖环境搭建
推理之前,请务必更新 FunASR 与 ModelScope 版本。
python -m pip install --upgrade pip
pip install -U funasr modelscope 上述命令行的目的是安装和更新两个核心工具 FunASR 和 ModelScope。
FunASR:
一个语音识别相关的工具包,由阿里巴巴开发,用于语音识别任务。FunASR 提供了运行语音识别模型的基础设施,包括音频处理、解码等功能。没有它,无法加载和运行 SenseVoice 模型。
ModelScope:
一个模型共享平台,类似于 Hugging Face 的 Model Hub,提供模型下载和管理功能。
3. 编写测试 demo
3.1 复制下 model.py
model.py 是一个基于 PyTorch 实现的语音处理模型,它提供了核心模型框架。一般情况下,预训练模型文件(model.pt)只包含了训练好的参数(模型的权重),而 model.py 定义了模型的结构和计算逻辑,就像是菜谱和食材的关系,光有食材(模型的权重)不知道怎么做菜(如何计算)是不行的。
在这个路径下将 model.py 拷贝到自己的工作目录下:
https://github.com/FunAudioLLM/SenseVoice/blob/main/model.py
3.2 创建 demo.py
demo.py 是一个使用 SenseVoice 语音识别模型的示例脚本,它用于加载模型,并将语音文件交给模型去进行识别,然后打印出识别的结果。
将如下代码拷贝进去:
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
# Copyright FunASR (https://github.com/FunAudioLLM/SenseVoice). All Rights Reserved.
# MIT License (https://opensource.org/licenses/MIT)
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
# zh
res = model.generate(
input=f"{model.model_path}/example/zh.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
# yue
res = model.generate(
input=f"{model.model_path}/example/yue.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
# ja
res = model.generate(
input=f"{model.model_path}/example/ja.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
# ko
res = model.generate(
input=f"{model.model_path}/example/ko.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text) 3.3 运行 demo
在 VSCode 中执行:
python demo.py 在运行过程中,如果碰到了问题可以直接通过询问 DeepSeek 进行解决,一般情况下就是有一些组件没有进行安装,例如:
ModuleNotFoundError: No module named 'torch'
这个错误表明您的Python环境中缺少PyTorch库,然后我们执行下:pip install torch torchvision torchaudio进行安装即可。
初次运行:
初次运行时会看到又重新下载了 SenseVoiceSmall 模型文件,这是因为我们这里的 model_dir = "iic/SenseVoiceSmall" 会触发自动从网上下载模型。我们告诉模型的 model_dir 下找不到该模型,它就会自动下载。修改办法之一是把我们已经下载好的路径告诉它:model_dir = "./SenseVoiceSmall"
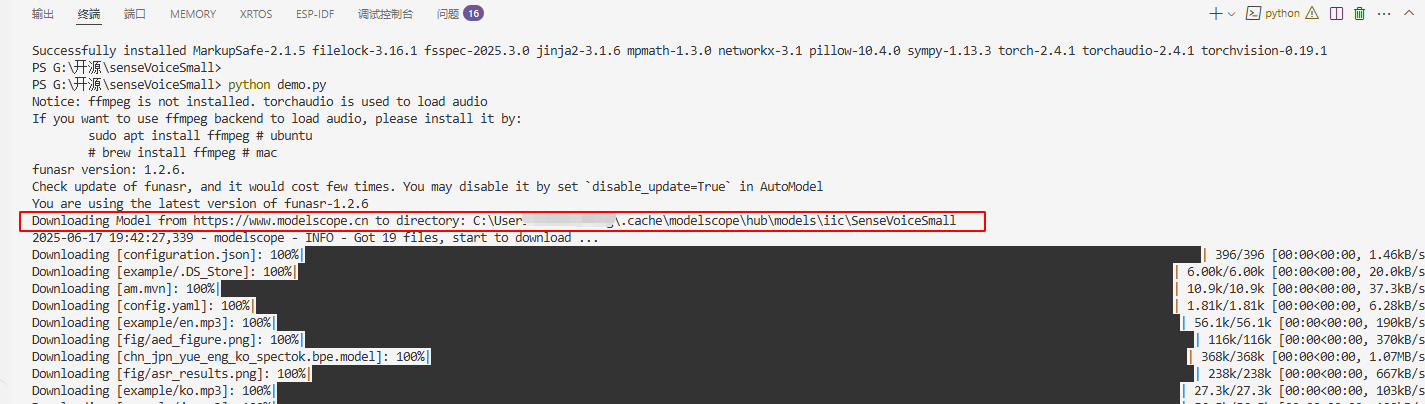
到 C 盘的路径下查看了下,和我之前用 Git 下载的一模一样: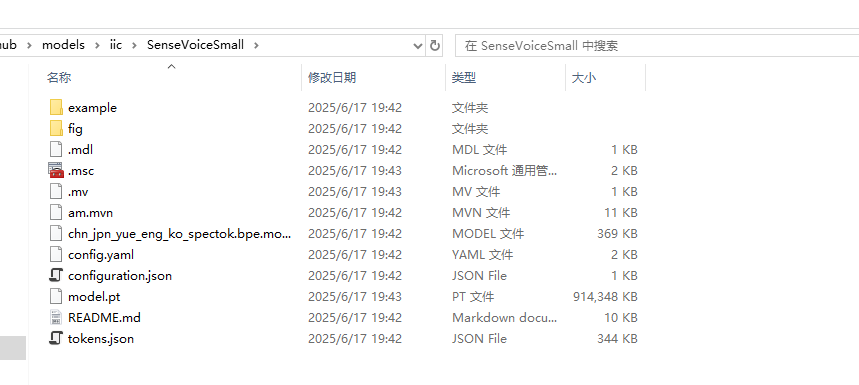
查看 demo 的输出
如下所示,成功将 example 下的语音文件转换成了对应不同国家语言的文本: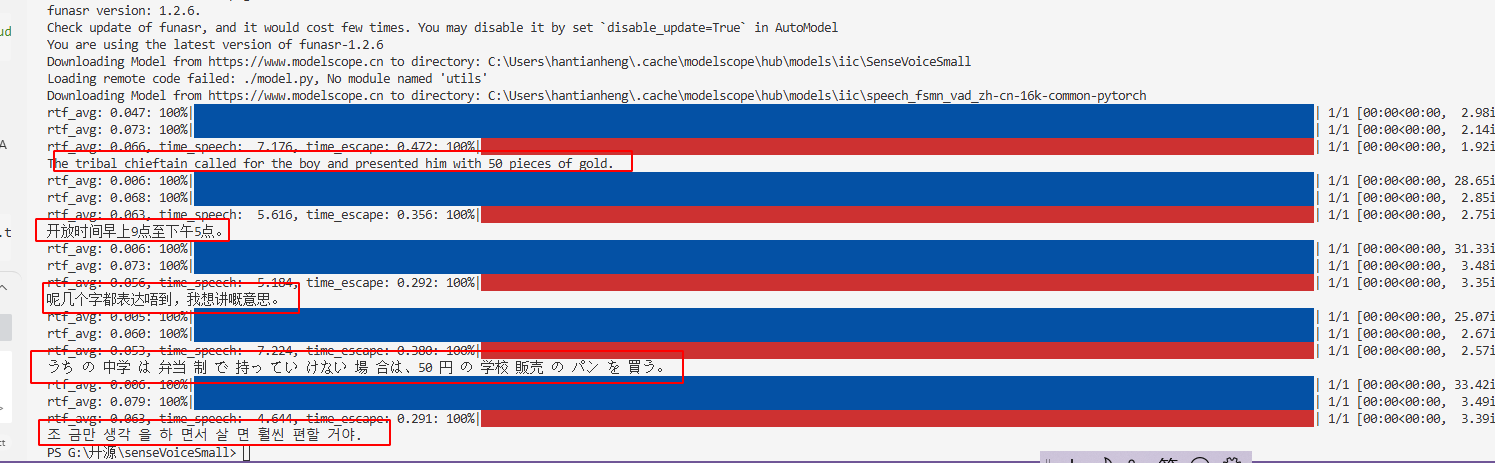
4. 我的疑问
4.1 PyTorch 训练好的模型权重文件 model.pt 这个是啥啊?
PyTorch(torch)是一个开源的深度学习框架,主要用于构建和训练神经网络。它有一个功能就是模型部署与导出:
TorchScript:将模型转换为脚本格式(.pt),脱离Python环境运行。ONNX支持:导出为ONNX格式(torch.onnx),与其他框架(如TensorFlow)互操作。
而 model.pt 是 PyTorch 模型的权重文件,相当于语音识别系统的“大脑”,它包含了神经网络的所有学习参数(权重和偏置),没有它的话就无法进行推理。
4.2 使用时是用 chn_jpn_yue_eng_ko_spectok.bpe.model 还是 model.pt 啊?
在实际使用中,这两个文件是配合使用的,各自承担不同功能:
model.pt:声学模型
- 处理原始音频信号
- 提取语音特征
- 输出原始
token概率分布
chn_jpn_yue_eng_ko_spectok.bpe.model:语言模型
- 将
token序列解码为文字 - 处理多语言混合场景
- 优化输出流畅度
典型调用代码示例:
# 加载声学模型
acoustic_model = load_model('model.pt')
# 加载 BPE tokenizer
tokenizer = Tokenizer.from_file('chn_jpn_yue_eng_ko_spectok.bpe.model')
# 完整推理流程
audio = load_audio('test.wav')
tokens = acoustic_model(audio) # 使用 model.pt
text = tokenizer.decode(tokens) # 使用 BPE 模型 4.3 tokens.json 的作用
tokens.json 是语音识别系统中的关键组件,它的作用相当于一个“字典”,将语音特征映射到文本单元。
在端到端语音识别系统中,模型不直接输出文字,而是输出一系列 token(标记),而 tokens.json 定义了这些 token 与实际文字/子词单元的对应关系。
语音信号 -> 声学特征 -> 神经网络 -> token 序列 -> tokens.json 解码 -> 最终文本
5. 总结
说实话目前为止我也只是知道了模型是怎么使用的,但是这个模型到底是怎么进行训练出来的,以及它背后的更多技术细节还不是很清楚。
之所以想要了解怎么本地部署,是因为我有个需求是通过将音频传递到服务端,然后服务端处理后再给我返回文本和语音回复。
不了解模型是怎么工作时,总感觉它是一个很难很难的东西。等真正去了解才发现它背后的原理很难,但是使用起来却很简单,这还是要感谢人家开源做得好啊。试想一下如果太难使用了,也不利于模型应用的推广。
现在了解了模型在本地是怎么进行运行的之后,也大概就理解了服务端的模型是怎么进行工作的了,无非是换了个环境以及通讯的方式发生了变化。在使用过程中我发现每次执行 demo 时电脑都会很卡,然后给出结果的时间也很慢,CPU 和内存消耗会飙得比较高,这么来看模型的推理确实很耗费资源啊。如果我们经常使用,最好还是在云服务器上使用 GPU 进行推理,不然每次调试起来太慢了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号