学习日记(2.15---2.16)
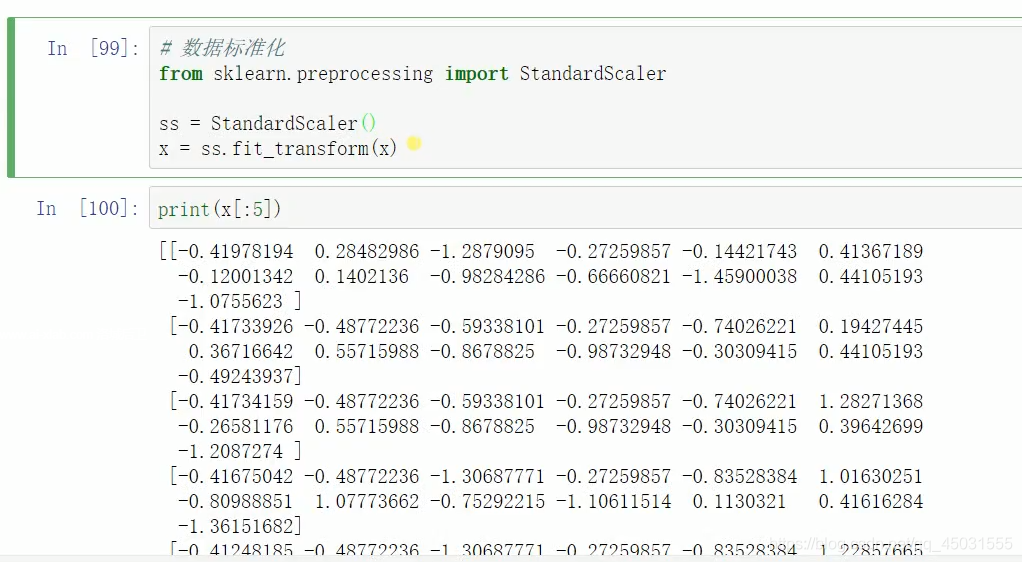
1.数据标准化
数据标准化就是把数据的特征减去关于的这个特征的平均值再除以这个特征的方差,效果是把数据都变成0附近的一些数值,方便计算,同时保存特征。
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
x=ss.fit_transform(x)
3级标题![在这里插入图片描述]()
2.KNN算法中的交叉验证法

3.使用jupter做葡萄酒质量与时间关系预测收获
1.在编程过程中 matplotlib.pyplot库中画图的时候 横坐标纵坐标 全部设计成英文不然汉字是不会显示出来的
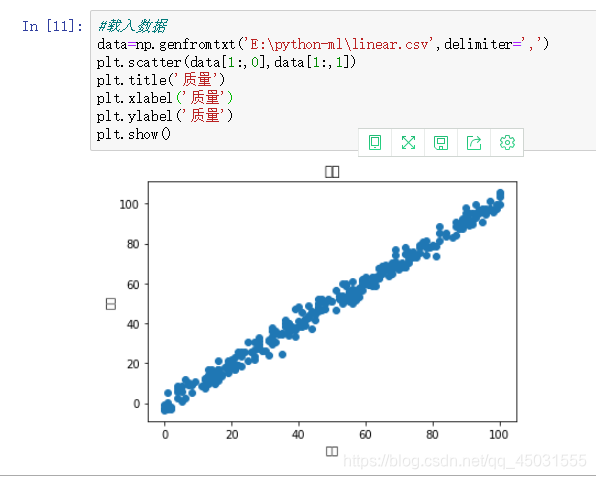
2.plt.scatter(data[1:,0],data[1:,1])python语法中就是制作图的依据
(data[从第行开始取到最后一行,取第0列],data[从1行开始取到最后一行,取第1列])
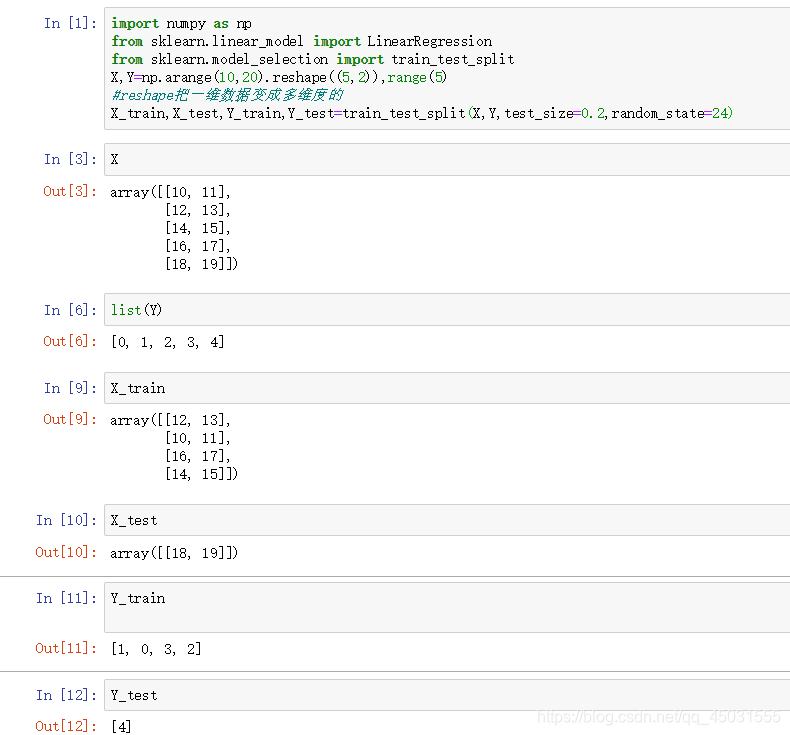
3.x_train,x_test,y_train,y_test=train_test_split(data[1:,0],data[1:,1],test_size=0.3)
语法分析:
a.首先这是一个来自于sklearn.model_selection.train_test_split随驾划分训练集和测试集
b.train_test_split是交叉验证中常用的函数,功能是从样本中随机的按照比例 test_size 来选取 test_data和train_data
train_test_split(train_data,train_target,test_size,random_state)
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。不填的话默认值为False,即每次切分的比例虽然相同,但是切分的结果不同。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数
接下来做一个小实验加深印象
4.X_train=X_train[:,newaxis]
给数据增加一个维度

np.newaxis 在使用和功能上等价于 None,其实就是 None 的一个别名。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号