老旧环境torch版本(0.4.1)环境配置总结
遇到了CUDA 的计算架构不支持的情况
首先这个项目所要求的是安装一个非常老的版本的torch 是0.4.1这个非常老旧的torch 是一个甚至小于1.0 版本的上古架构
在安装的时候废了不小时间
最终终于在官网查到了安装这个版本的torch的方法
先前版本的torch下载路径:https://pytorch.org/get-started/previous-versions/
可以看到所支持的版本支持三种CUDA版本

然后我就尝试了,第一个版本进行安装
conda install pytorch=0.4.1 cuda90 -c pytorch
过程中出现了明明已经显示安装成功了,但是还是显示没有安装的结果
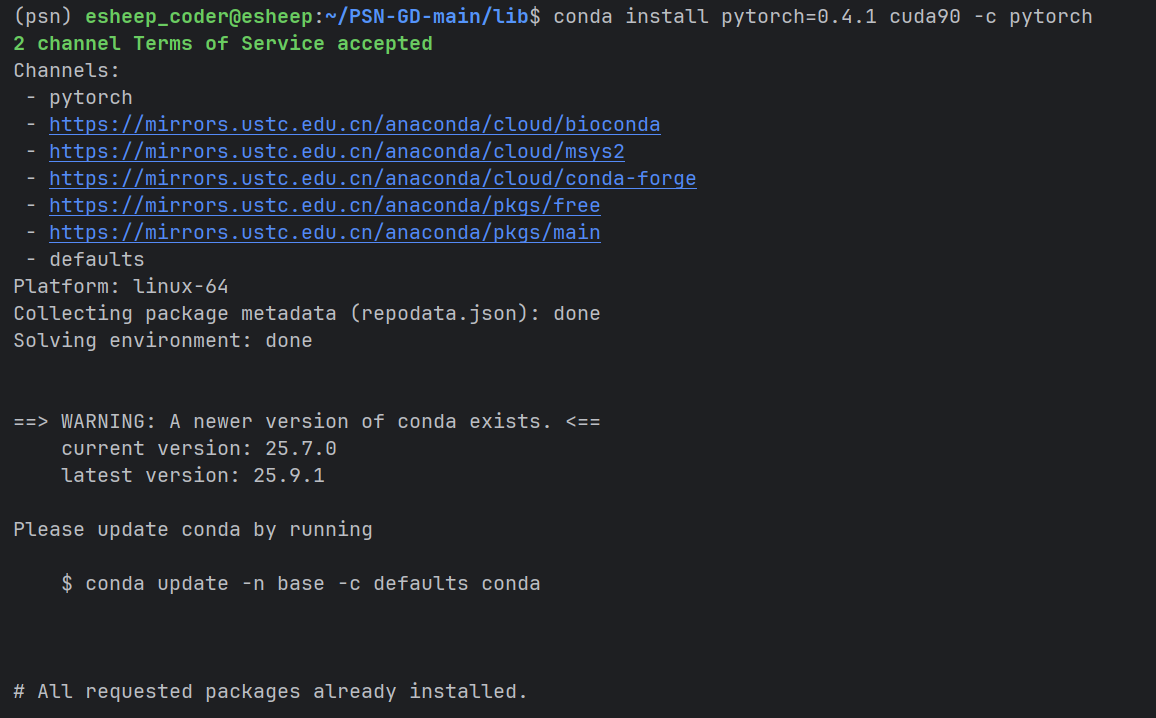
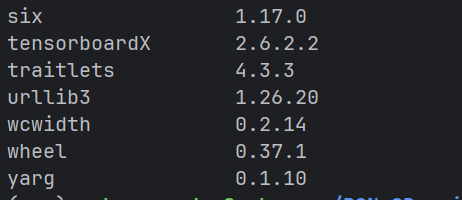
很明显是因为conda 包管理的原因让其无法在 pip中显示并且无法调用
所以尝试使用pip 进行安装 这里利用上了我之前写过的博客使用加速的情况下手动下载torch的whl文件然后手动安装文件,最终安装成功
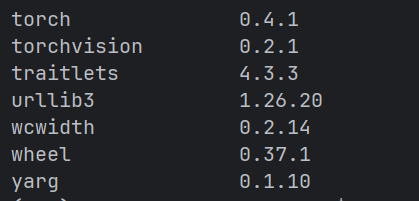
验证结果:

运行编译文件
发现出现了第一个比较抽象的报错:
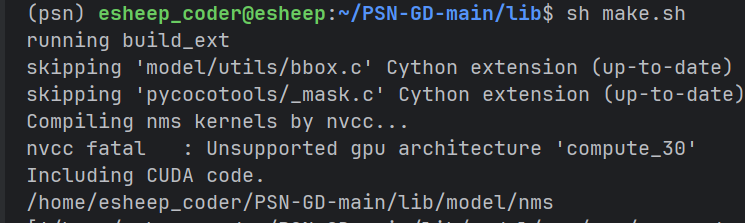
可以发现是说 nvcc fatal :不支持的计算结构 compute_30 去查找是哪里定义了这个参数,

定位到了具体位置后发现,这个地方是写CUDA_ARCH那么就去查找 CUDA_ARCH是什么意思 猜测应该是架构的意思
然后,发现了这个网页:
https://developer.nvidia.com/cuda-gpus

在问了AI之后发现,这个compute_30,sm_30 都只带的是当前显卡的计算性能 ,仔细一对比还真是。30系的8.6的性能,而我有12.0
然后就大胆的写下了

然后就输出了大量log:
running build_ext
skipping 'model/utils/bbox.c' Cython extension (up-to-date)
skipping 'pycocotools/_mask.c' Cython extension (up-to-date)
Compiling nms kernels by nvcc...
Including CUDA code.
/home/esheep_coder/PSN-GD-main/lib/model/nms
['/home/esheep_coder/PSN-GD-main/lib/model/nms/src/nms_cuda_kernel.cu.o']
generating /tmp/tmp8f4aey6q/_nms.c
setting the current directory to '/tmp/tmp8f4aey6q'
running build_ext
building '_nms' extension
creating home
creating home/esheep_coder
creating home/esheep_coder/PSN-GD-main
creating home/esheep_coder/PSN-GD-main/lib
creating home/esheep_coder/PSN-GD-main/lib/model
creating home/esheep_coder/PSN-GD-main/lib/model/nms
creating home/esheep_coder/PSN-GD-main/lib/model/nms/src
gcc -pthread -B /home/esheep_coder/miniconda3/envs/psn/compiler_compat -Wl,--sysroot=/ -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -std=c99 -fPIC -DWITH_CUDA -I/home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/../../lib/include -I/home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/../../lib/include/TH -I/home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/../../lib/include/THC -I/usr/local/cuda/include -I/home/esheep_coder/miniconda3/envs/psn/include/python3.6m -c _nms.c -o ./_nms.o -std=c99
In file included from /home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/../../lib/include/THC/THCGeneral.h:15,
from /home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/../../lib/include/THC/THC.h:4,
from _nms.c:570:
/usr/local/cuda/include/cusparse.h:434:1: warning: ‘csric02Info_t’ is deprecated: The type
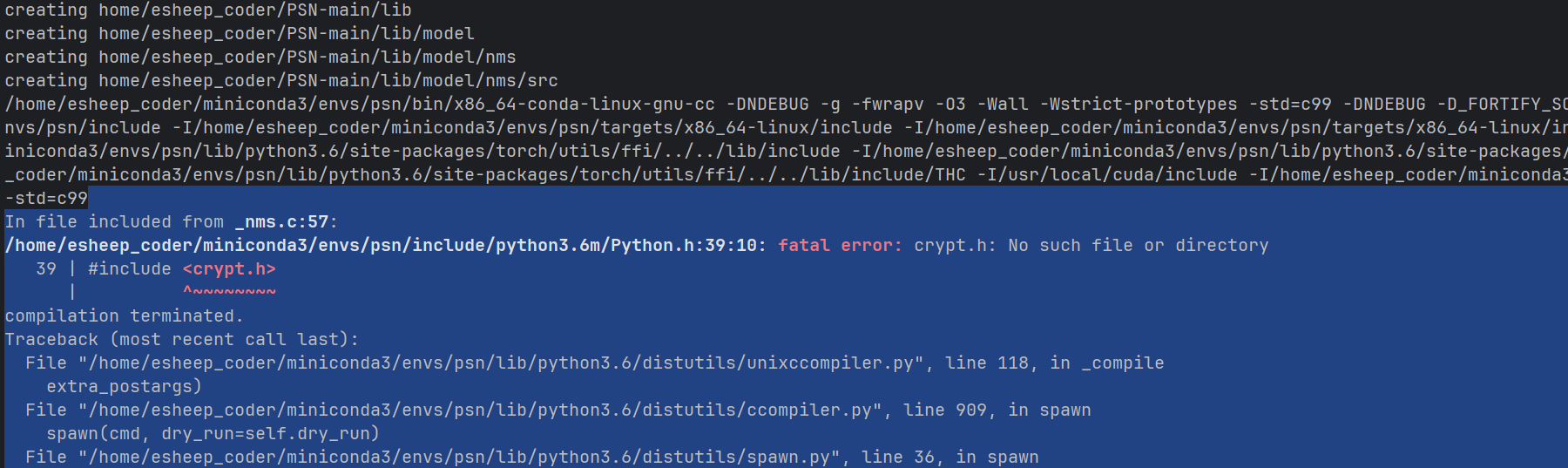
可算没有错误了,既然cuda编译完毕了那么现在开始实现训练过程编译
编译过程错误详解
- 问题1详解

错误分析:这个错误是因为 Pillow (PIL) 库缺少 libtiff 依赖。问题在于 Pillow 需要 libtiff 的动态链接库,但在当前环境中找不到。
解决办法:
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install libtiff5-dev libtiff5
# 或者如果上面的不行,尝试:
sudo apt-get install libtiff-dev
- 问题2详解
Traceback (most recent call last):
File "main.py", line 24, in <module>
from model.utils.net_utils import weights_normal_init, clip_gradient, sampler
File "/home/esheep_coder/PSN-GD-main/lib/model/utils/net_utils.py", line 10, in <module>
from model.roi_crop.functions.roi_crop import RoICropFunction
File "/home/esheep_coder/PSN-GD-main/lib/model/roi_crop/functions/roi_crop.py", line 4, in <module>
from .._ext import roi_crop
File "/home/esheep_coder/PSN-GD-main/lib/model/roi_crop/_ext/roi_crop/__init__.py", line 3, in <module>
from ._roi_crop import lib as _lib, ffi as _ffi
ImportError: /home/esheep_coder/PSN-GD-main/lib/model/roi_crop/_ext/roi_crop/_roi_crop.so: undefined symbol: __cudaRegisterFatBinaryEnd
问题原因:这个错误又回到了 CUDA 版本不匹配 的问题。__cudaRegisterFatBinaryEnd 符号缺失表明编译环境和运行环境的 CUDA 版本不一致。
根本原因
之前编译的 .so 文件是用不同版本的 CUDA 编译的,与当前 PyTorch 使用的 CUDA 版本不兼容。
所以要删除之前编译的结果
使用如下办法可以进行删除原先的文件 这个指令可以直接查找.so 文件然后在本地进行编译
解决办法:
find . -name "*.so" -delete
使用这个后所有的后缀的文件都删除了,然后可以重新编译
编译后还是遇到了相同的报错:
(psn) esheep_coder@esheep:~/PSN-GD-main$ sh scripts/train-1-2-fc.sh
Traceback (most recent call last):
File "main.py", line 24, in <module>
from model.utils.net_utils import weights_normal_init, clip_gradient, sampler
File "/home/esheep_coder/PSN-GD-main/lib/model/utils/net_utils.py", line 10, in <module>
from model.roi_crop.functions.roi_crop import RoICropFunction
File "/home/esheep_coder/PSN-GD-main/lib/model/roi_crop/functions/roi_crop.py", line 4, in <module>
from .._ext import roi_crop
File "/home/esheep_coder/PSN-GD-main/lib/model/roi_crop/_ext/roi_crop/__init__.py", line 3, in <module>
from ._roi_crop import lib as _lib, ffi as _ffi
ImportError: /home/esheep_coder/PSN-GD-main/lib/model/roi_crop/_ext/roi_crop/_roi_crop.so: undefined symbol: __cudaRegisterFatBinaryEnd
只有一种可能就是当前的cuda版本和torch做默认使用cuda版本不一致
那么我们使用下面的代码进行验证当前的torch的cuda版本 和当前计算机中所安装的cuda版本
(psn) esheep_coder@esheep:~$ python -c "import torch; print('PyTorch version:', torch.__version__); print('CUDA version:', torch.version.cuda)"
PyTorch version: 0.4.1
CUDA version: 9.0.176
(psn) esheep_coder@esheep:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:23:50_PST_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0
那么现在就只剩一条路了,就是重新安装cuda 9.0 版本卸载12.8版本
这么搞就时间复杂喽,要动的东西太多了
发现cuda 不一致原因
是因为我们的conda里面安装了一个cuda版本,是cuda9.0 但是系统在默认执行的时候使用是系统环境变量的主cuda版本 也就是cuda 12.8 。
使用一下代码实现查看当前所使用的cuda位置
(psn) esheep_coder@esheep:~$ which nvcc
/usr/local/cuda-12.8/bin/nvcc
现在确定了我们已经安装了一个cuda 版本后,接下来就是想办法让conda环境中的cuda全程生效 覆盖掉全局变量 这样就不会出现在编译的时候使用的是cuda9.0 但是运行训练脚本的时候使用的是12.8
解决办法:将当前环境的cuda直接作为全局变量进行生效,就不会出现这个问题了
1.查看当前的cuda 和当前环境的conda环境变量
(psn) esheep_coder@esheep:~$ echo "CONDA_PREFIX: $CONDA_PREFIX"
CONDA_PREFIX: /home/esheep_coder/miniconda3/envs/psn
(psn) esheep_coder@esheep:~$ echo "CUDA_HOME: $CUDA_HOME"
CUDA_HOME: :/usr/local/cuda-12.8
- 检查conda环境内的CUDA相关文件
(psn) esheep_coder@esheep:~$ find $CONDA_PREFIX -name "nvcc" -type f 2>/dev/null
(psn) esheep_coder@esheep:~$ find $CONDA_PREFIX -name "cudart*" -type f 2>/dev/null
(psn) esheep_coder@esheep:~$ ls -la $CONDA_PREFIX/bin/ | grep cuda
(psn) esheep_coder@esheep:~$ ls -la $CONDA_PREFIX/lib/ | grep cuda
-rw-r--r-- 2 esheep_coder esheep_coder 1092 Jan 9 2018 cudatoolkit_config.yaml
lrwxrwxrwx 1 esheep_coder esheep_coder 20 Oct 30 09:18 libcudart.so -> libcudart.so.9.0.176
lrwxrwxrwx 1 esheep_coder esheep_coder 20 Oct 30 09:18 libcudart.so.9.0 -> libcudart.so.9.0.176
-rwxr-xr-x 2 esheep_coder esheep_coder 454544 Jan 9 2018 libcudart.so.9.0.176
结果显示我们当前的cuda不是一个完整的cuda环境 还缺少一个NVCC编译环境 和 其他的CUDA 开发工具
现在有两条路,一条路是:直接补全环境
另一条路是利用现有的nvcc编译环境 进行编译 用以解决编译问题,但是我认为,这样的方法是无效的,因为现在的问题恰恰出在,编译的时候使用的是一个cuda版本)(12.8),运行的时候是另一个cuda版本(9.0) 也就是现在之所以代码能跑起来,但是有报错就是这个原因

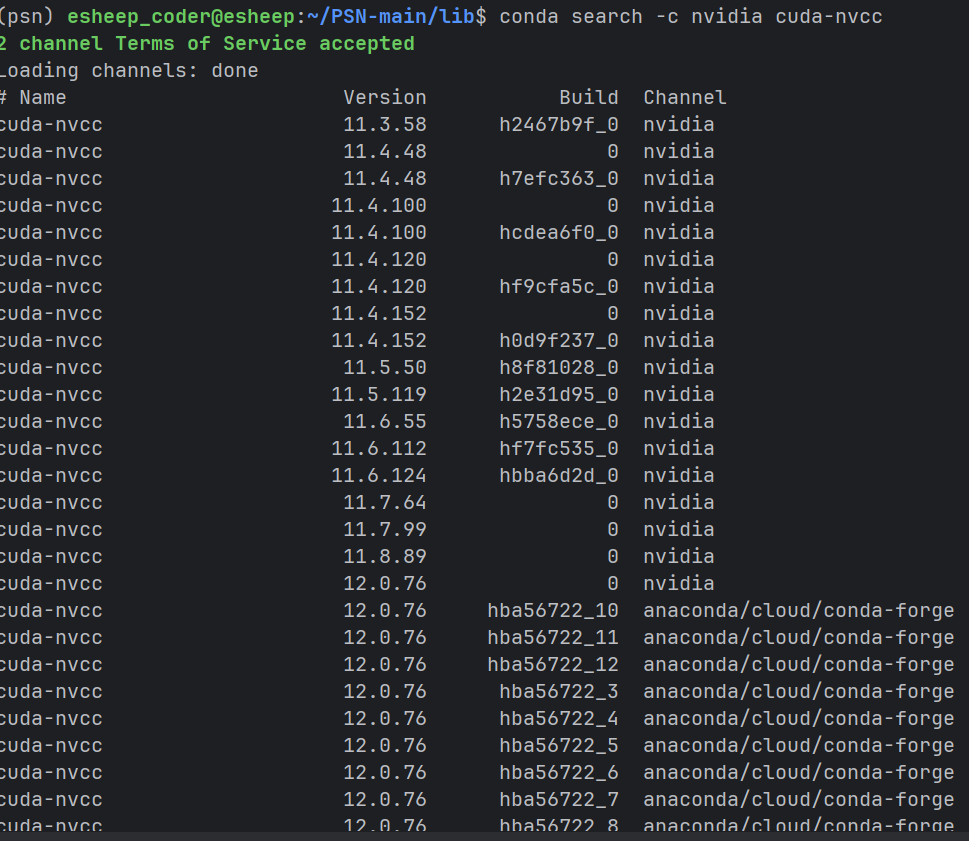
使用这个命令可以查看当前安装的cuda环境们
使用了很多方法都没有是成功将cuda-nvcc9.0 安装上去,最终多亏看到了这个博客 ,其中书写了如何安装nvcc的方法。AI所提供的信息全是叫你如何 使用正确的进行下载 但是会发现都找不到这个包 还是在这个命令厉害
conda install -c "nvidia/label/cuda-9.0" cuda-nvcc
验证一下 conda list | grep cuda
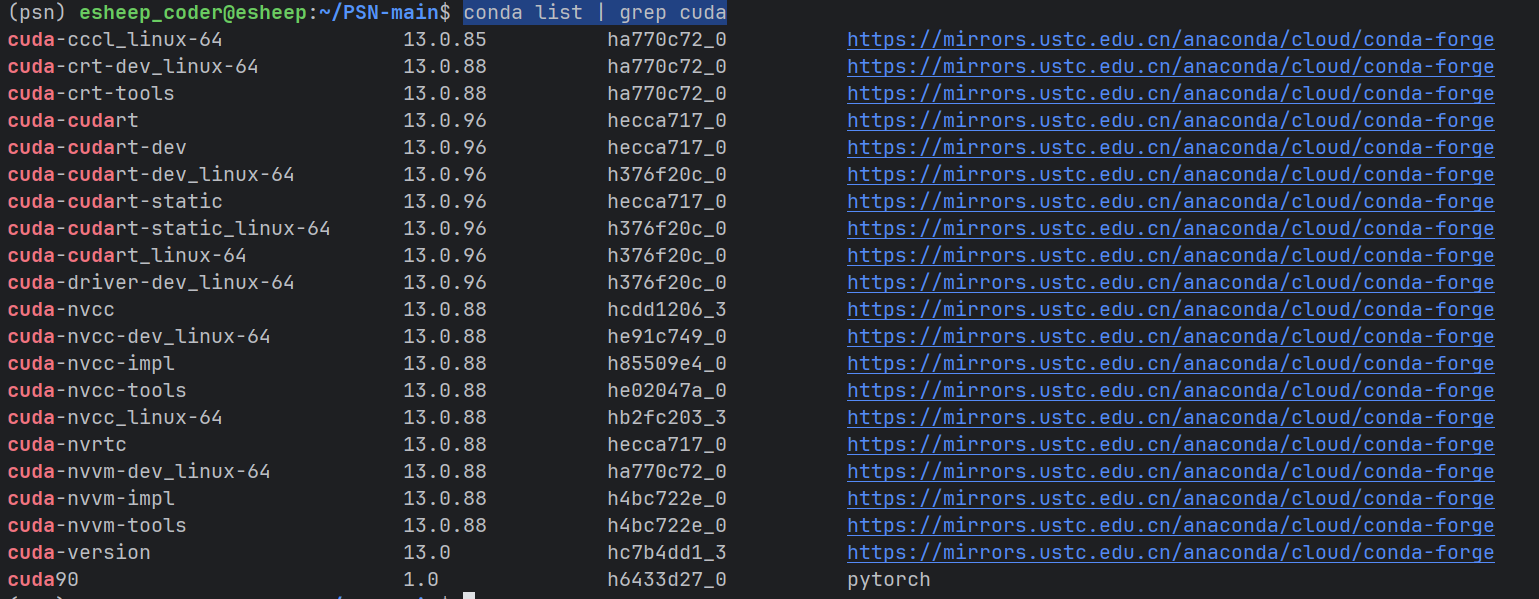
果然成功了吗?
你发现了更离谱的情况,明明代码显示torch使用的是cuda 9.0 ,但是nvcc 显示的都是cuda 13.0 (2025新出) 因此cuda环境又错了
而且现在最新的cuda彻底编译这个项目都不支持了,彻底玩完
现在只有一种方法了:重装环境,然后将整个项目代码重构,实现支持cuda13.0 但这工程量太大,彻底不可能了
第二条路 试试 cuda 10.0能不能装上 nvcc (赌博的成分极大,因为官方只讲这个版本支持到9.0)
这个问题彻底成为一个我无法解决的难题了,因为这个问题一个无法调和的矛盾,只要使用torch0.4版本太过老旧,太多的组件现在已经无法下载,这个项目就是缺少了一个,9.0版本的NVCC编译器。
如果想要运行这个项目就必须使用这个版本进行论文复现,不能进行重写方法复现。
安装torch0.4 就自带了cuda9.0 (linux)无法避免的情况
当然就是去安装一个类似 1.1.x 1.2.x 这样的版本去尝试能不能完成安装nvcc了,也就是找一个更高版本torch,看看有没有一个能够正好兼容这个项目版本的代码,让代码跑起来

尝试
当前最低nvcc版本是11.3.58
conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 cudatoolkit=11.3 -c pytorch -c conda-forge

可以看到,此时已经成功安装,并且卸载掉原有框架了
那么再重新编译一下:
结果竟然是:
skipping 'model/utils/bbox.c' Cython extension (up-to-date)
skipping 'pycocotools/_mask.c' Cython extension (up-to-date)
Compiling nms kernels by nvcc...
nvcc fatal : Unknown option '--gencode'
Traceback (most recent call last):
File "build.py", line 4, in <module>
from torch.utils.ffi import create_extension
File "/home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/__init__.py", line 1, in <module>
raise ImportError("torch.utils.ffi is deprecated. Please use cpp extensions instead.")
ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.
Compiling roi pooling kernels by nvcc...
nvcc fatal : Unknown option '--gencode'
Traceback (most recent call last):
File "build.py", line 4, in <module>
from torch.utils.ffi import create_extension
File "/home/esheep_coder/miniconda3/envs/psn/lib/python3.6/site-packages/torch/utils/ffi/__init__.py", line 1, in <module>
raise ImportError("torch.utils.ffi is deprecated. Please use cpp extensions instead.")
ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.
立即修复步骤
先检查项目结构:
bash
cd /home/esheep_coder/PSN-main
find . -name "build.py" -exec grep -l "gencode|ffi" {} ;
告诉我找到的文件路径,我可以帮你具体修改编译选项
或者直接尝试安装 PyTorch 1.4.0:
bash
pip install torch1.4.0 torchvision0.5.0
这个项目明显是为老版本 PyTorch (0.4.1-1.4) 设计的,需要相应版本的环境才能正常编译。
结论
综上所述,本项目在原有基础上无法再做任何尝试,本项目本地部署失败,定为难题,等到以后解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号