百度飞桨GPU平台深度学习项目搭建指南
写在前面
笔者在搭建项目时发现自己的算力不够用了,在尝试了多个云服务器平台后发现,只有百度飞桨平台的GPU服务器是免费时长最多,且相对计算资源是最好的平台,调查结果如下:
笔者首先尝试了算力最强的google colab 平台,但是碍于其依赖于google云盘作为硬盘,但是作者自身的财力无法购买专业版google云盘,因此大型项目无法白嫖其算力进行实现。
然后便尝试了华为云,阿里云等大型云服务器厂商,但是发现其学生优惠均没有明显降价,最后尝试了百度飞桨,网上只有两个文章介绍了怎么进行服务进行租用的教程但都没有介绍学生认证的相关细节,
最关键的是还没有文章介绍怎么使用百度飞桨进行脚本运行项目的搭建
因此作者决定写出此文填补这一空白
百度飞桨平台
学生认证
-
首先点击右上角的个人中心
-
点击右上角的编辑个人信息
-
在完善信息界面点击学生认证
-
填写
-
再次返回查看详细的设置
可以看到现在的认证结果已经是,设置成功的结果如下图所示

上传数据集

https://aistudio.baidu.com/my/dataset
点击这个链接上传咱们的数据集, 然后写出来咱们数据集名称,记得选择私密
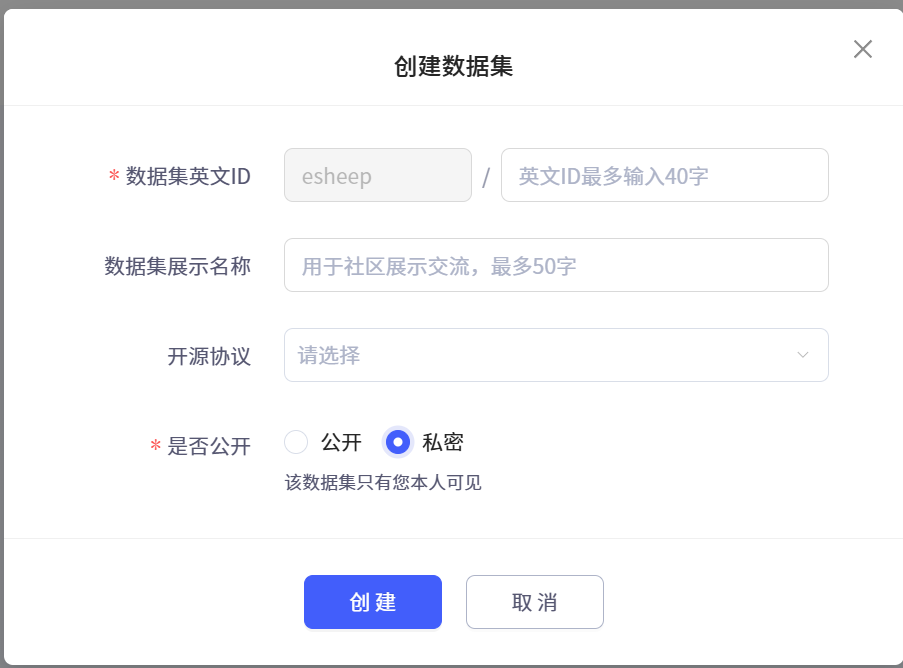
建立完毕后的样子界面如下所示:

点击数据集文件,可以上传文件

可以适用网页上传,也可以使用代码进行本地上传
# 首次使用需要安装aistudio-sdk库
# pip install --upgrade aistudio-sdk
import os
# 需要填写aistudio-access-token, 在我的控制台--令牌获取
os.environ["AISTUDIO_ACCESS_TOKEN"] = "e267a3df376b76367ba6742d7fd9e7d91df24c0a"
#上传单个文件
from aistudio_sdk.hub import upload_file
res = upload_file(
# 填写数据集详情页面中的repo_id
repo_id='esheep/stcray_sd1.5',
# 填写要上传的文件在本地的路径,如'./path/to/local/README.md'
path_or_fileobj='./path/to/local/README.md',
# 填写上传至repo后的文件路径及文件名,如填写'README.md',则会在master分支的根目录内,上传README.md
path_in_repo='README.md',
# 填写commit信息,非必填
commit_message='upload dataset file to repo',
# 填写仓库类型为dataset,上传数据集文件时为必填项
repo_type = 'dataset'
)
print(res)
#上传文件夹
from aistudio_sdk.hub import upload_folder
res = upload_folder(
# 填写数据集详情页面中的repo_id
repo_id='esheep/stcray_sd1.5',
# 填写要上传的文件在本地的路径,如'./path/to/local/dir'
folder_path='./path/to/local/dir',
# 填写上传至repo后的文件路径,如填写'data/',则会将文件上传至data目录内;或不填,则默认上传至master分支的根目录内
path_in_repo='data/',
# 填写commit信息,非必填
commit_message='upload dataset folder to repo',
# 填写仓库类型为dataset,上传数据集文件时为必填项
repo_type = 'dataset'
)
print(res)
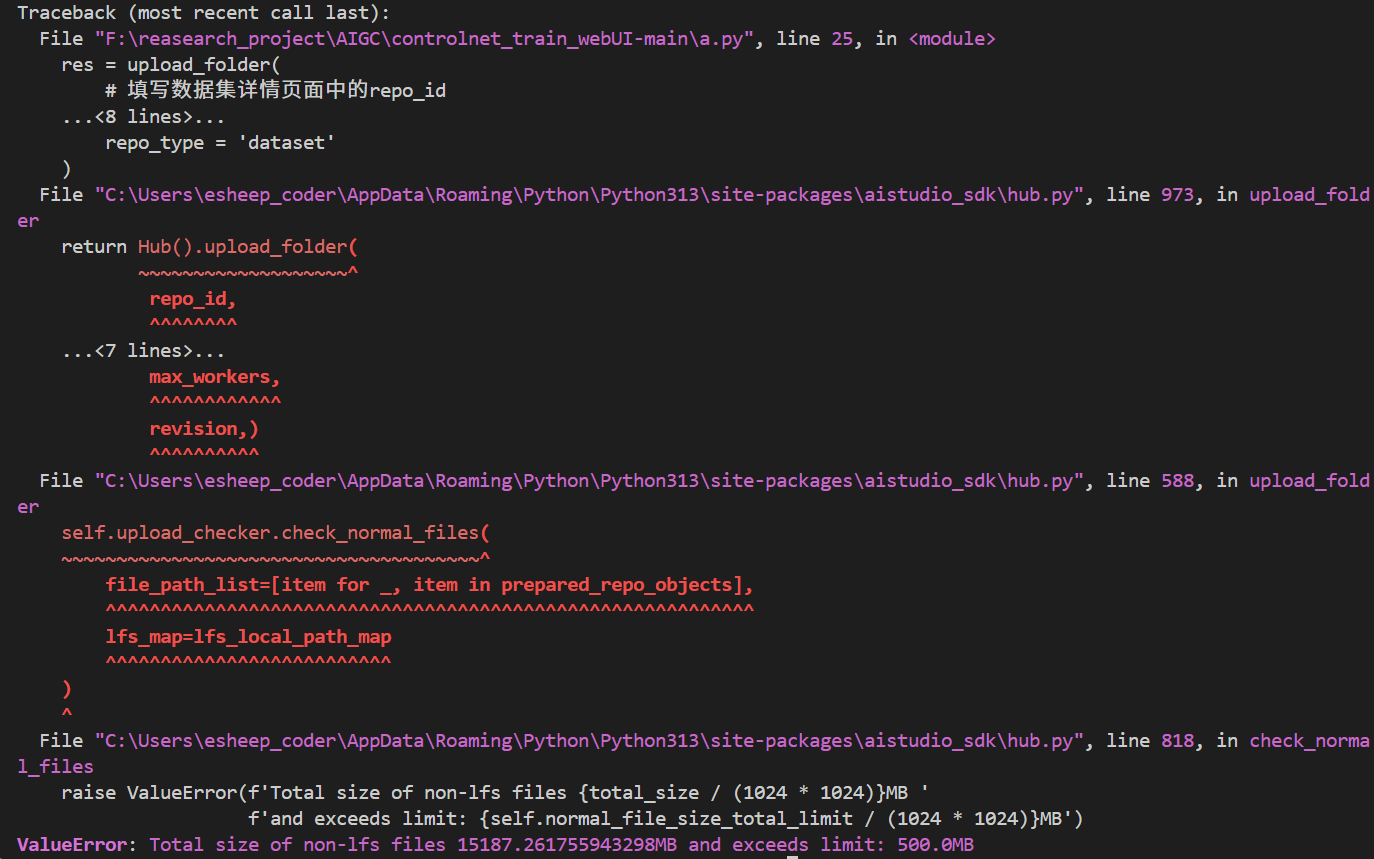
其中上传文件夹中的文件单个最大大小为500MB
项目搭建
https://aistudio.baidu.com/my/project
可以点击这个链接直接来到这个页面
点击脚本任务:
可以看到提供了编辑项目名称的选项,也可以选择我们自己创建的数据集

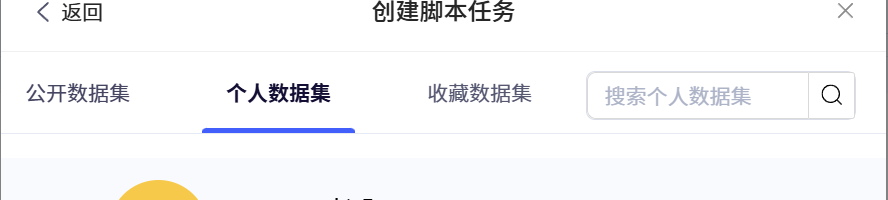
填写完项目名称后会看到代码主页,可以查看我们写好的脚本
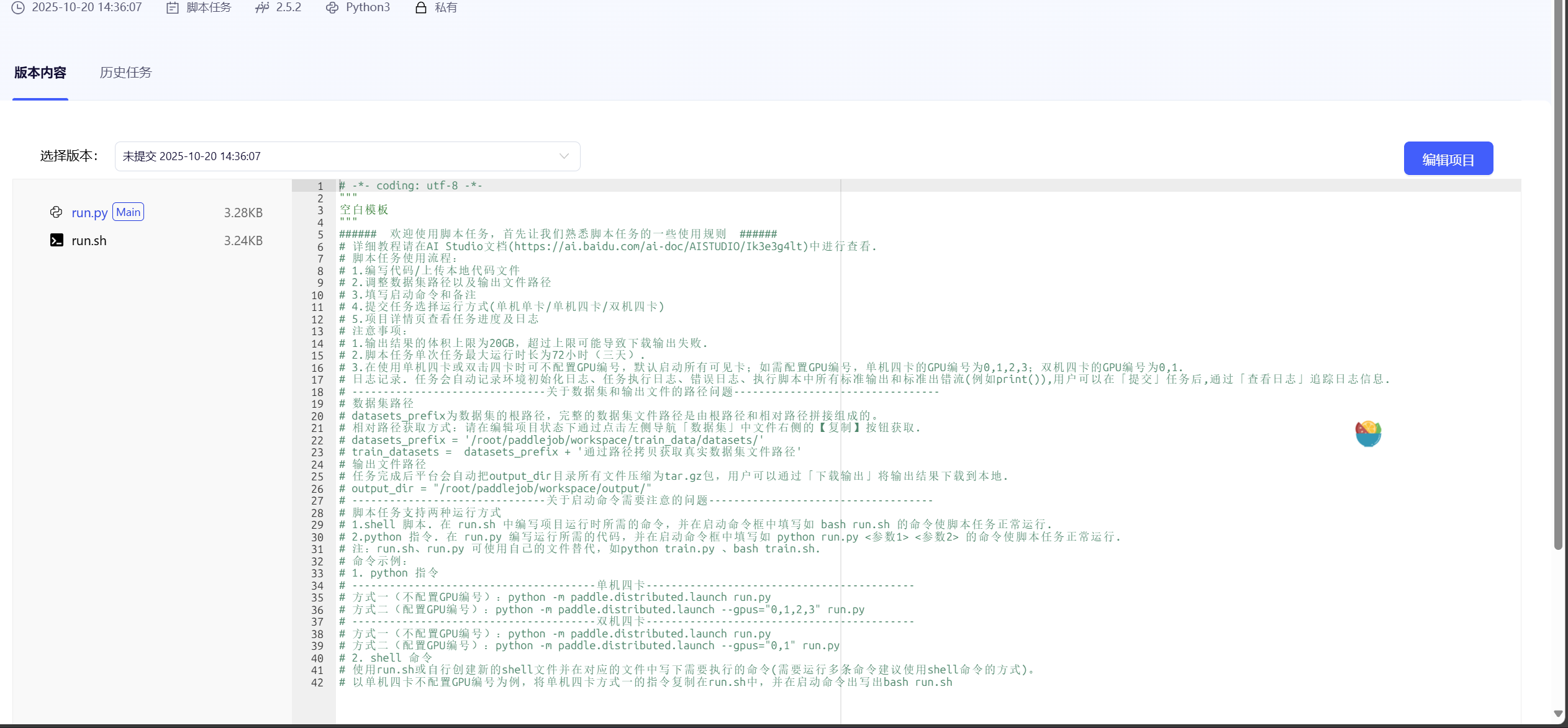
点击编辑项目,可以修改代码,编写自己的代码

值得注意的是,最大项目代码总大小为2.0g
这里我们可以上传好自己的代码文件然后进行运行项目了
项目执行
挂载好数据集之后,根据自己需求选择相应配置的环境启动,进入环境之后,把源代码里有关于数据集的部分,换成data目录下对应的路径,这里我建议使用绝对路径。
然后运行训练模型相关的代码即可。训练过程文件和模型文件可保存到指定目录下,后续可以右击该目录,将结果下载下来。
熟练之后呢,就可以尝试飞浆其他功能,如去使用飞浆的模型和数据集、去创建运行时间更长的脚本任务等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号