Neural Network&Convolutional Neural Network
深度学习越是浅层的网络越是局部的特征,越是深度的网络越是全局的特征
因为,深层的卷积的上一层是浅层的卷积
神经网络原理
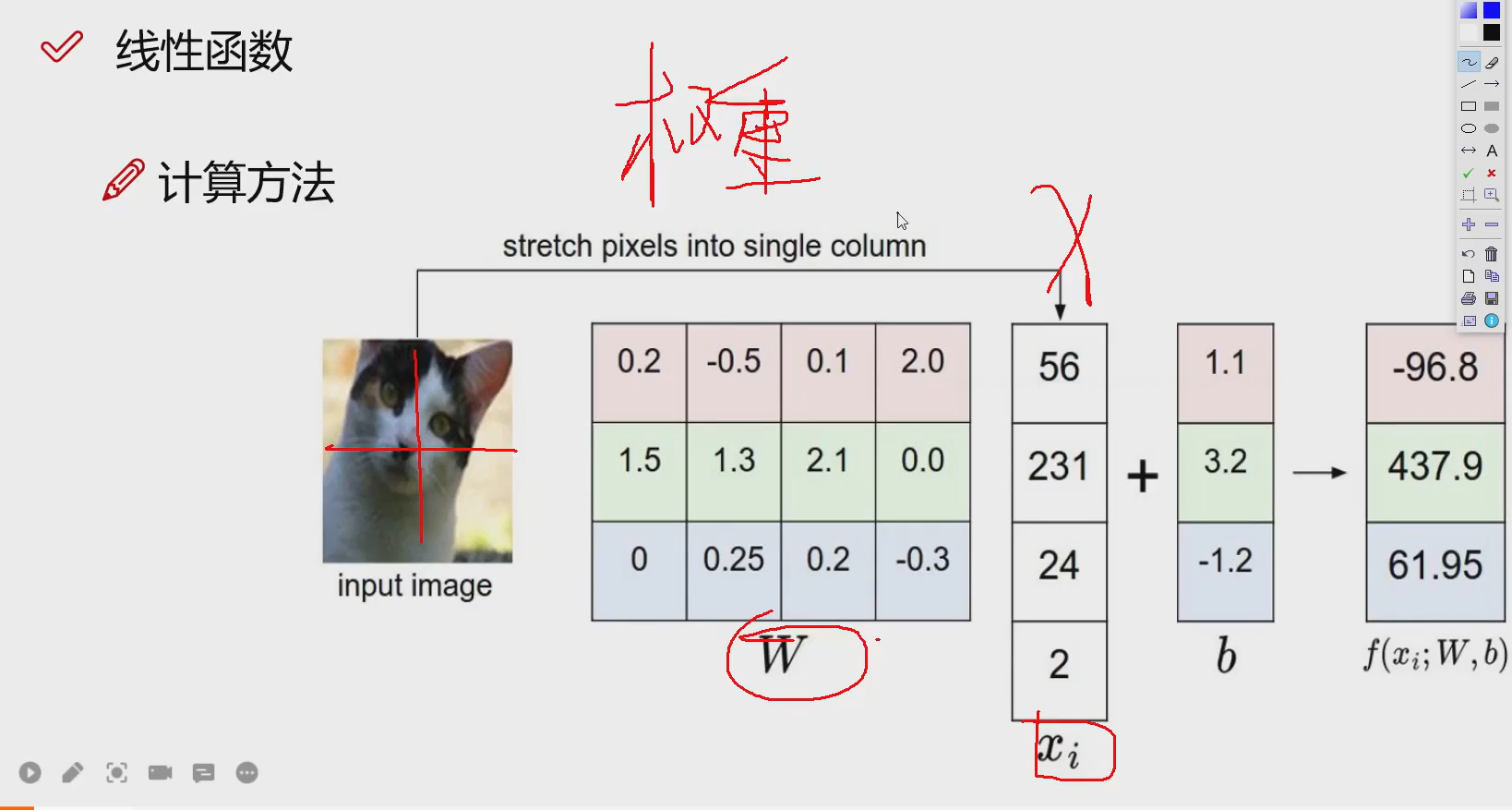
W是一个权重函数,x是分割的个数,b是偏置函数,因为输出结果有3个,是一个"权重参数矩阵"
如果结果不对要怎么调整呢?
就是提出来特征
计算机视觉

面临的挑战:跨域
对于炒股不能用ai
学习的是历史的规律
因为人的社会是一直在变的,所以过去的不能用于现在
技术不值钱,做成产品值钱
权重参数W:

这个值可以随机初始化,也可以去找别人训练好的模型的参数进行训练,预训练模型再用
网络结构和损失函数的设计是目标检测的关键
损失函数
限制限制错误就是损失函数

wx+b有一个预测值,这个值x与y的差值就是损失值
就是我预测错的多少的一个表示,差的太大了,损失肯定大呀
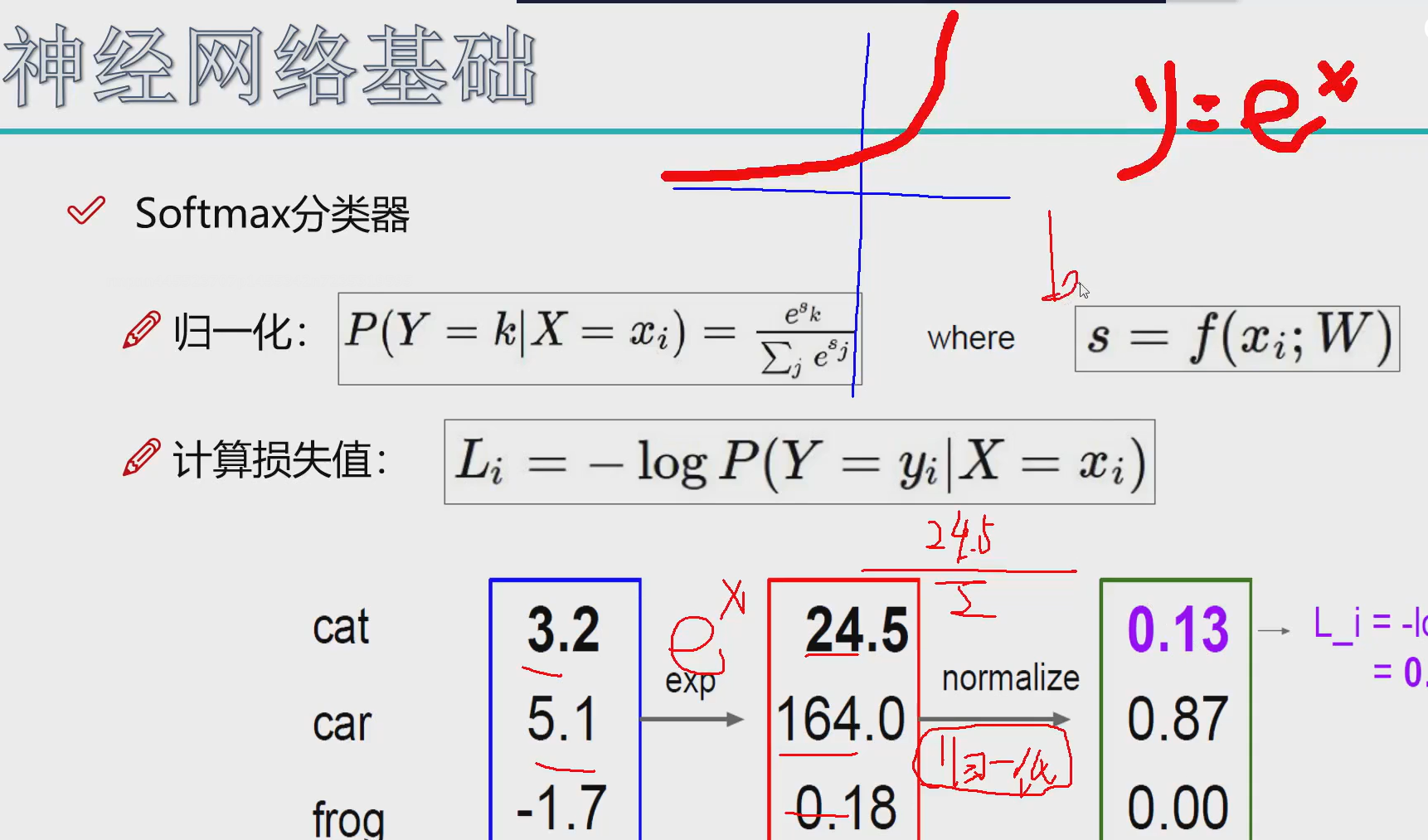
-
首先我们要把差异化映射出来,就用一个指数函数,大的正数越大,差距也大,负数的值都是0
-
然后进行归一化计算概率
-
对于每个值计算损失值
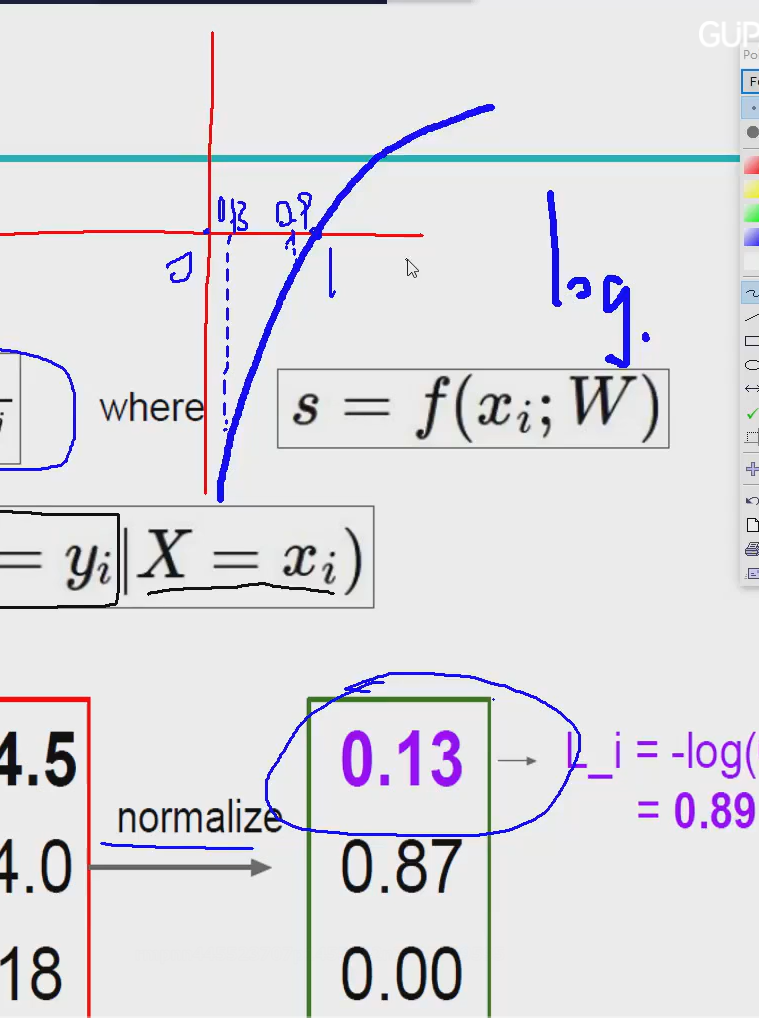
用对数函数,越接近1绝对值值越小,越接近0越大,这样就可以很明显看出损失值大小
然后-log就更加合理 恒为正
正则化
惩罚忽大忽小的
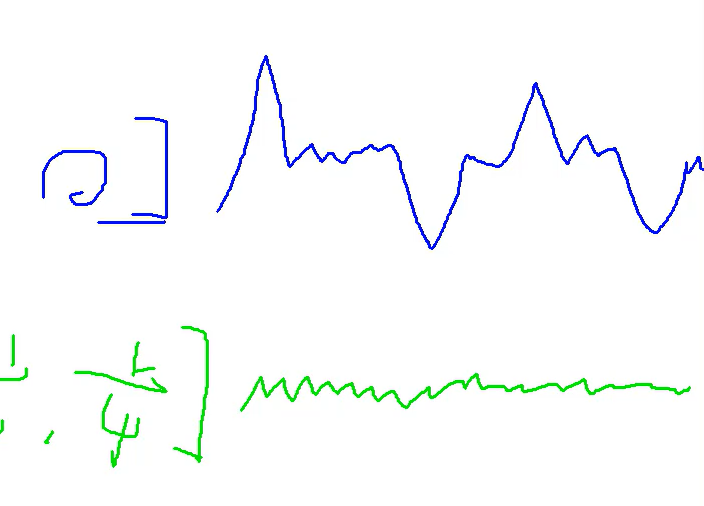
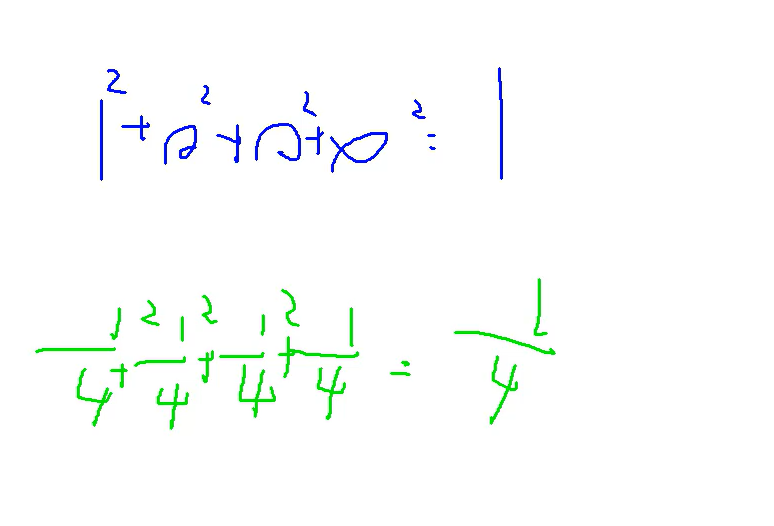
第一个的值大,惩罚大,避免过拟合
过拟合:就是所有的特征都倾向于一个方向
第一次群架打头,下一次我带头盔你还打头,效果就很差了,所以要泛化遍布全身才能达到最佳效果
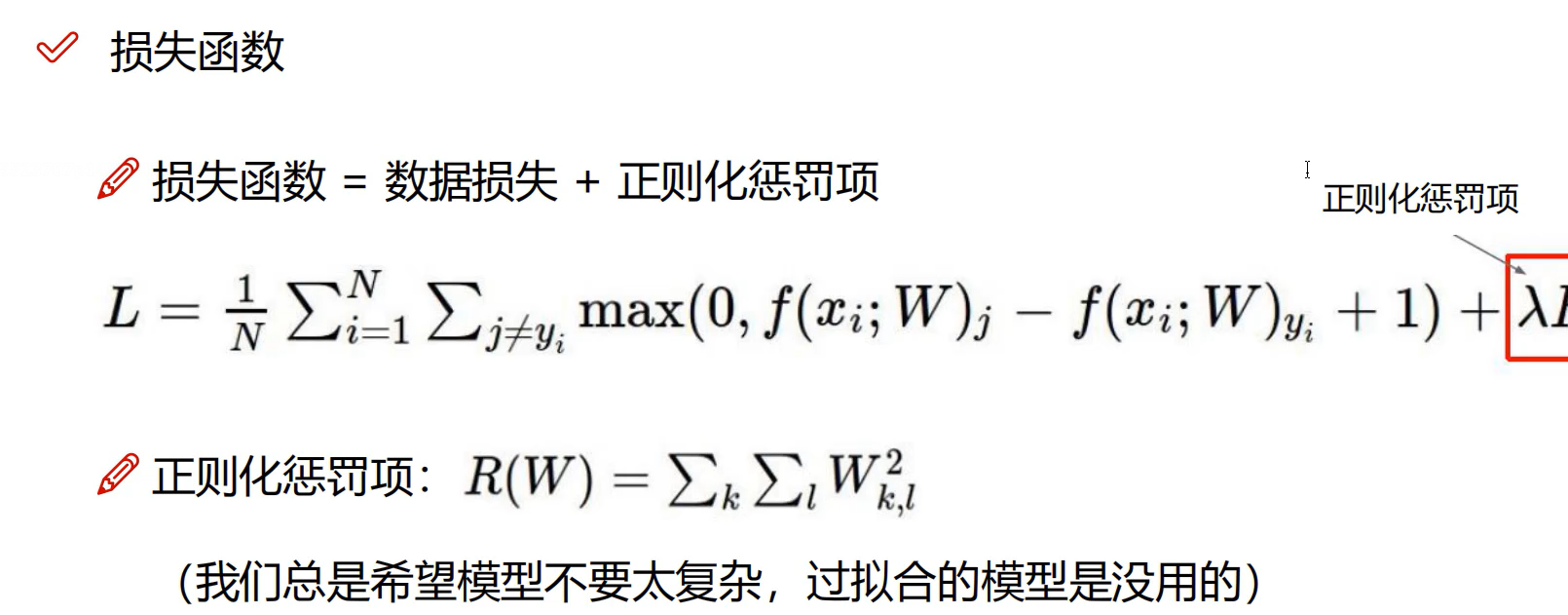
开始前要人为去除坏点

反向传播
怎么利用损
失值把特征值修改达到损失值最小
梯度
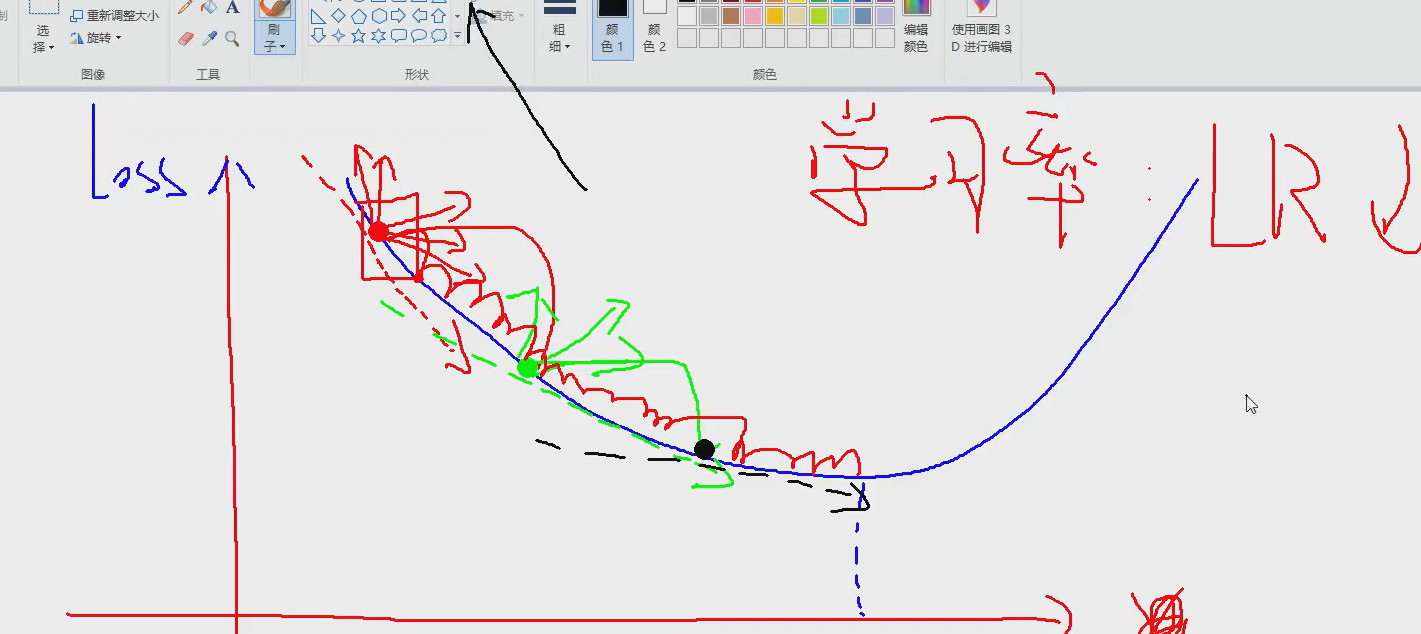
沿着梯度的反方向去更新就叫做梯度下降,按切线方向 下降最快
调小学习率越小越好,因为每个点的切线方向改变的都很大
0.01 0.001
LR(学习率):warmup
就是前期的500次这样的学习率调低点,因为如果前期不正确后面越来越错
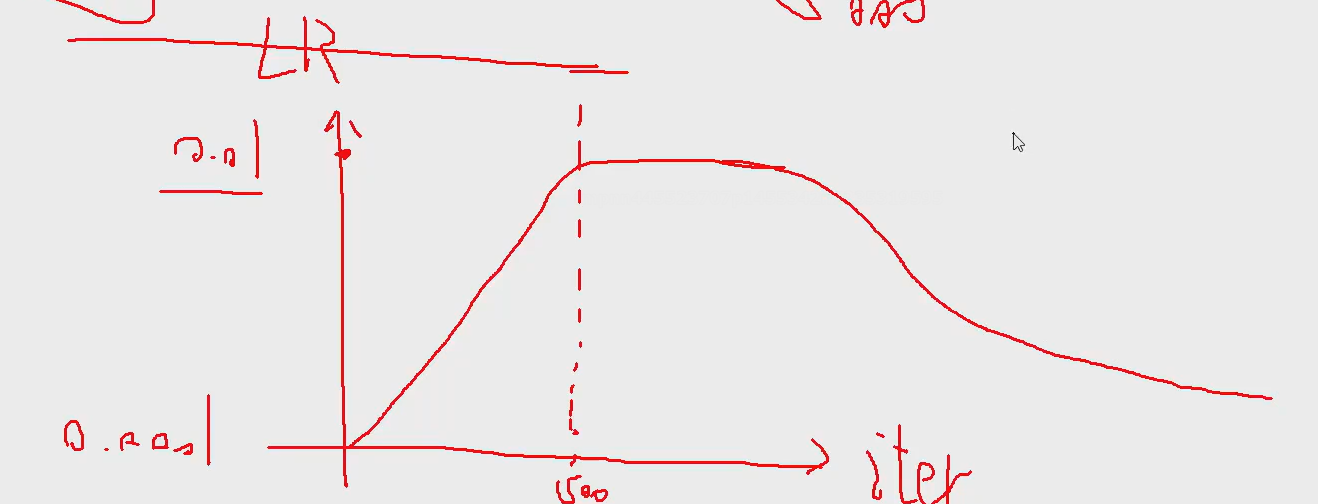
前期慢慢升,升到正常值一段时间,最后那点在慢慢下降
batch
一次迭代的个数,就是一个平均
越大越好 300 足够
GPT-3 300w
集群去训练,算法有上限
论文不要用公用数据集
动量 momentum
一般0.9 0.95
每次梯度方向都在改变,而且变得特别大
没有动量的样子:
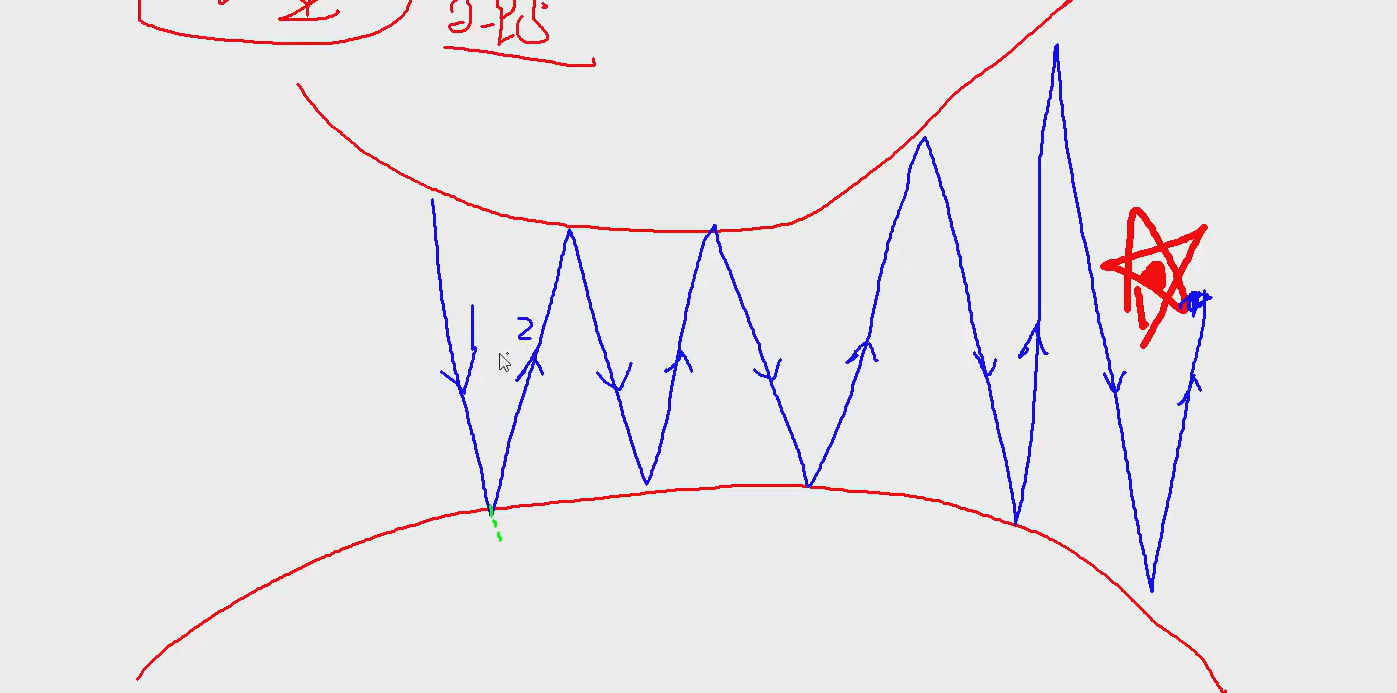
动量就是一个惯性,下一次更新时保存一些上次的方向。
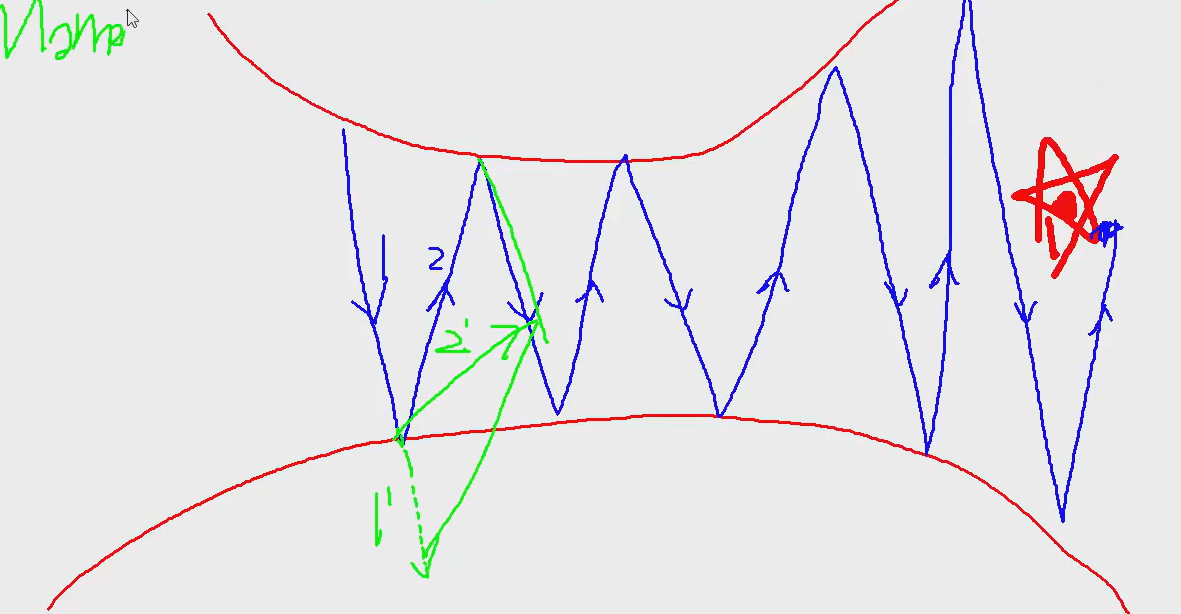
就是一个力的合成,2'更容易接近红星,得到最优解
0.9就是原来长度90%就是虚线的长度,用来和下次拟合
梯度消失,梯度爆炸
梯度消失
前者是梯度越削越小,成0了
每个权重参数都是独立的
梯度爆炸
这个大的值,特别大,导致对结果其了决定性的影响
出现的原因:
数据本身有异常点,还有错误点
整体结构
神经网络不可解释
FC:全连接
对特征做变换,改变网络的权重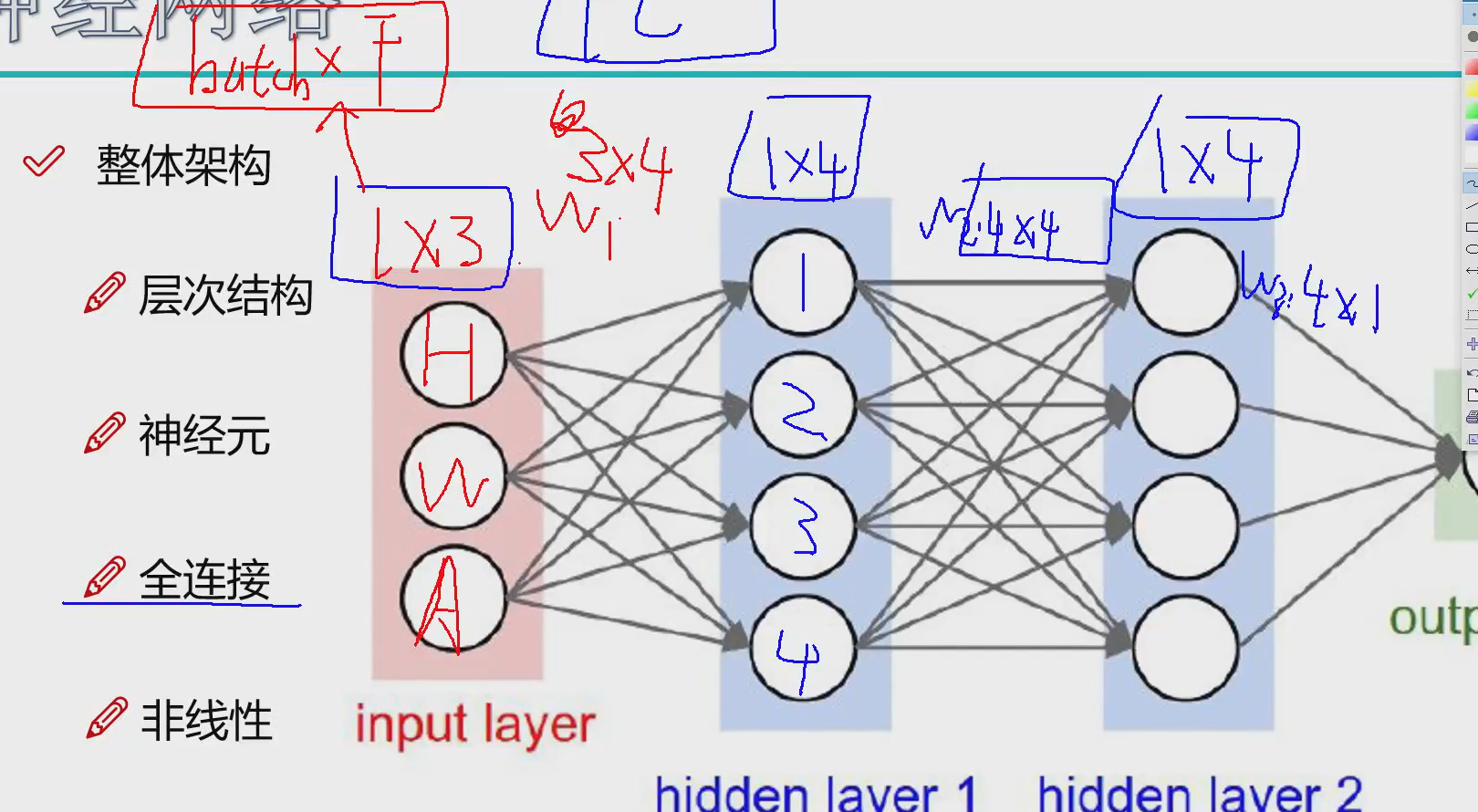
加层数就是线性的但是我们期望是非线性的
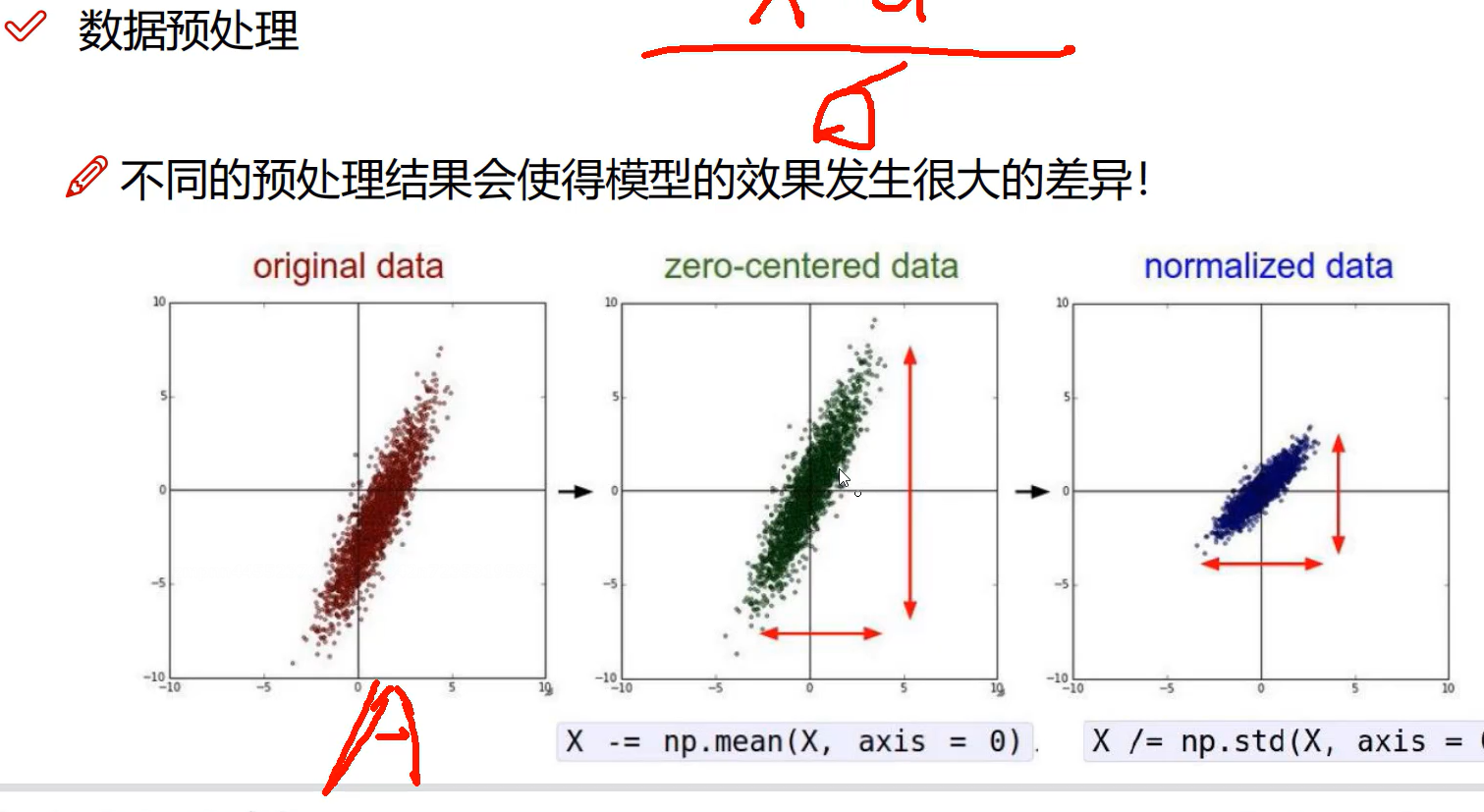
数据预处理
在输入之前数据已经经过预处理,但是在进行过程中数据又开始乱了
所有每次进行完后都要进行BN进行标准化,然后relu就是非线性映射
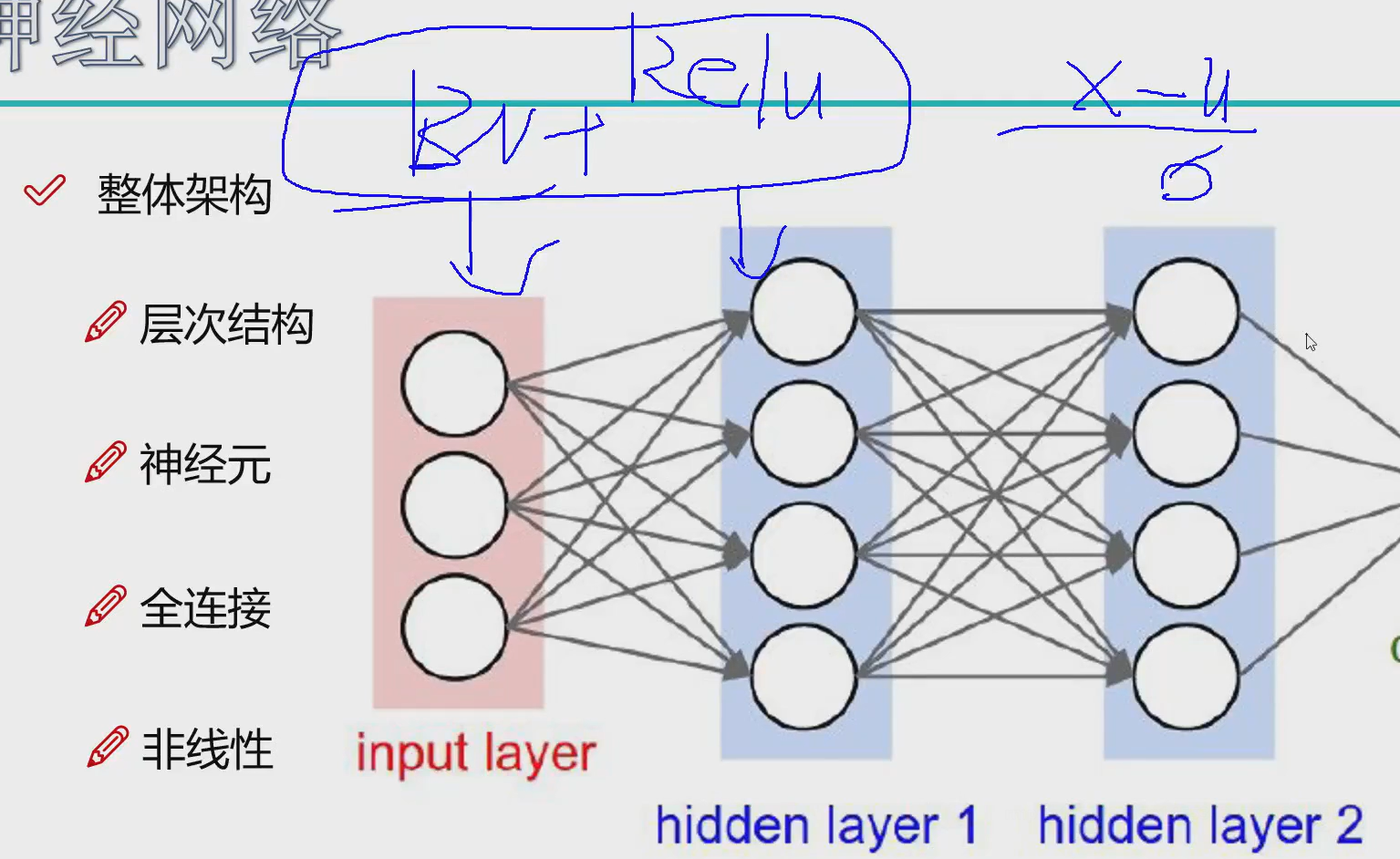
参数初始化
初始化参数小一些

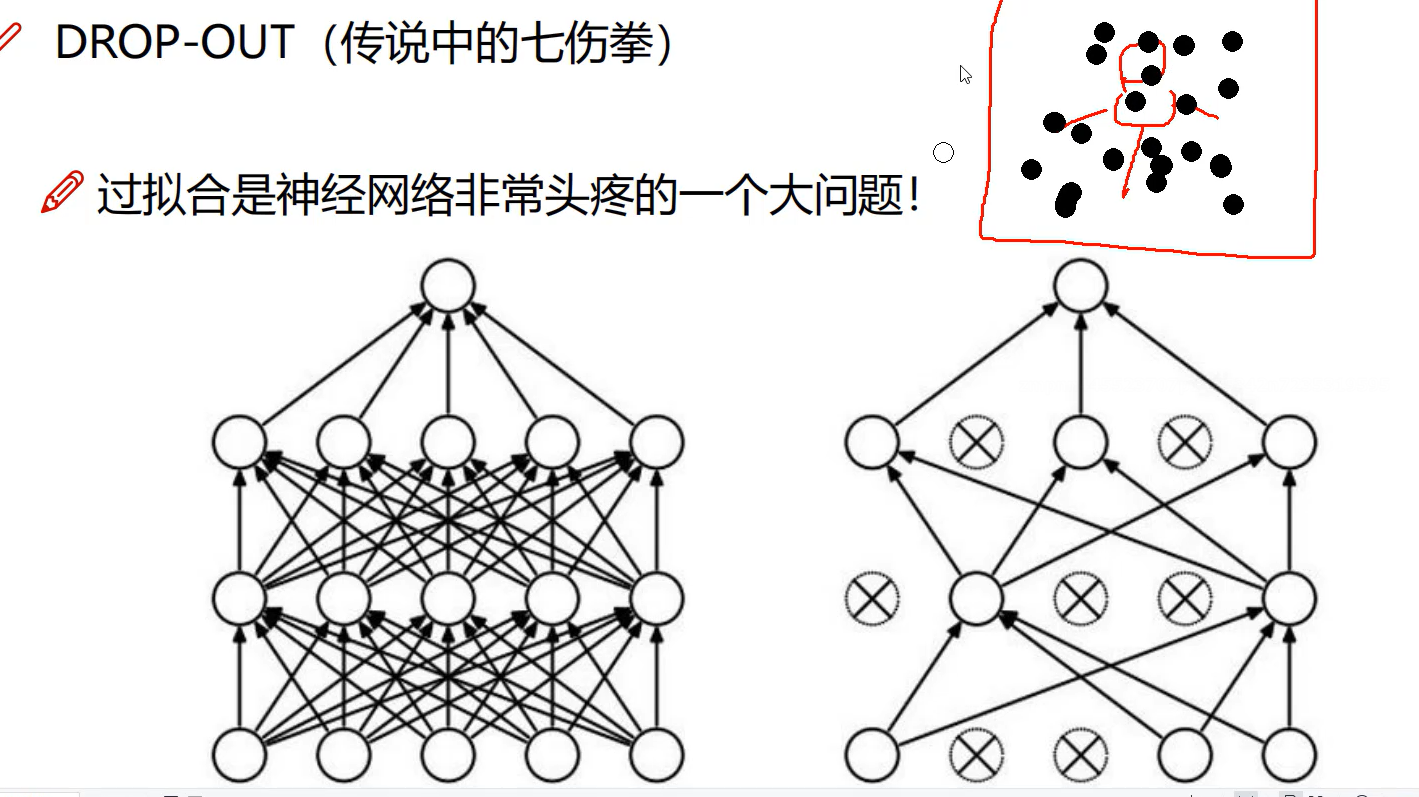
Drop-out
随机删掉一些特征,看能不能还能识别出正确结果
防止过拟合
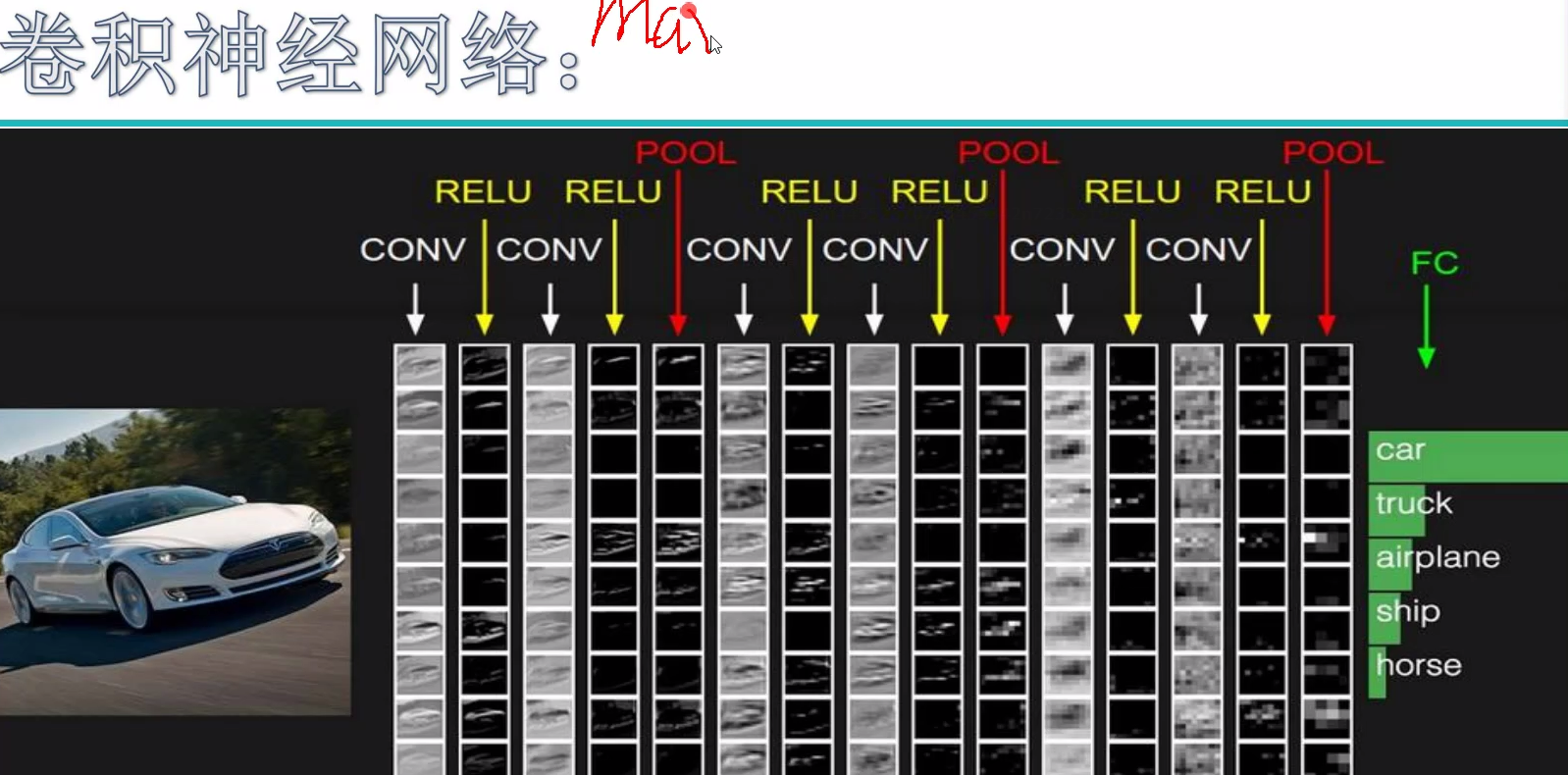
Convolutional Neural Network
最近很多火的模型都是cnn出来的
传统神经网络主要用于结构化的数据
传统的就只要学一个树模型就行
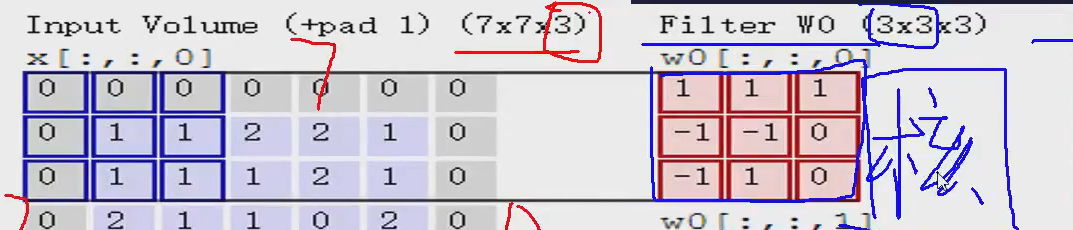
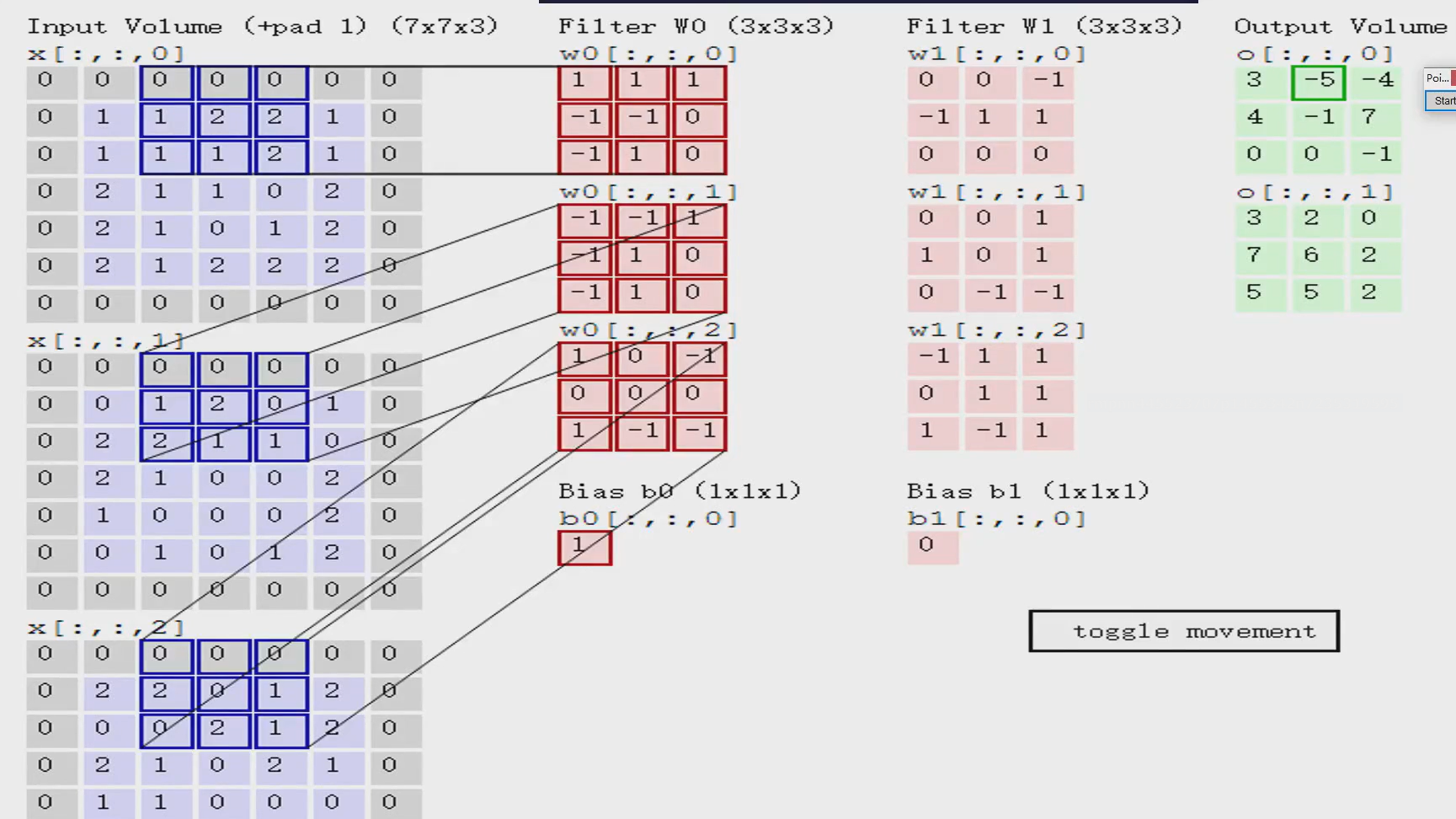
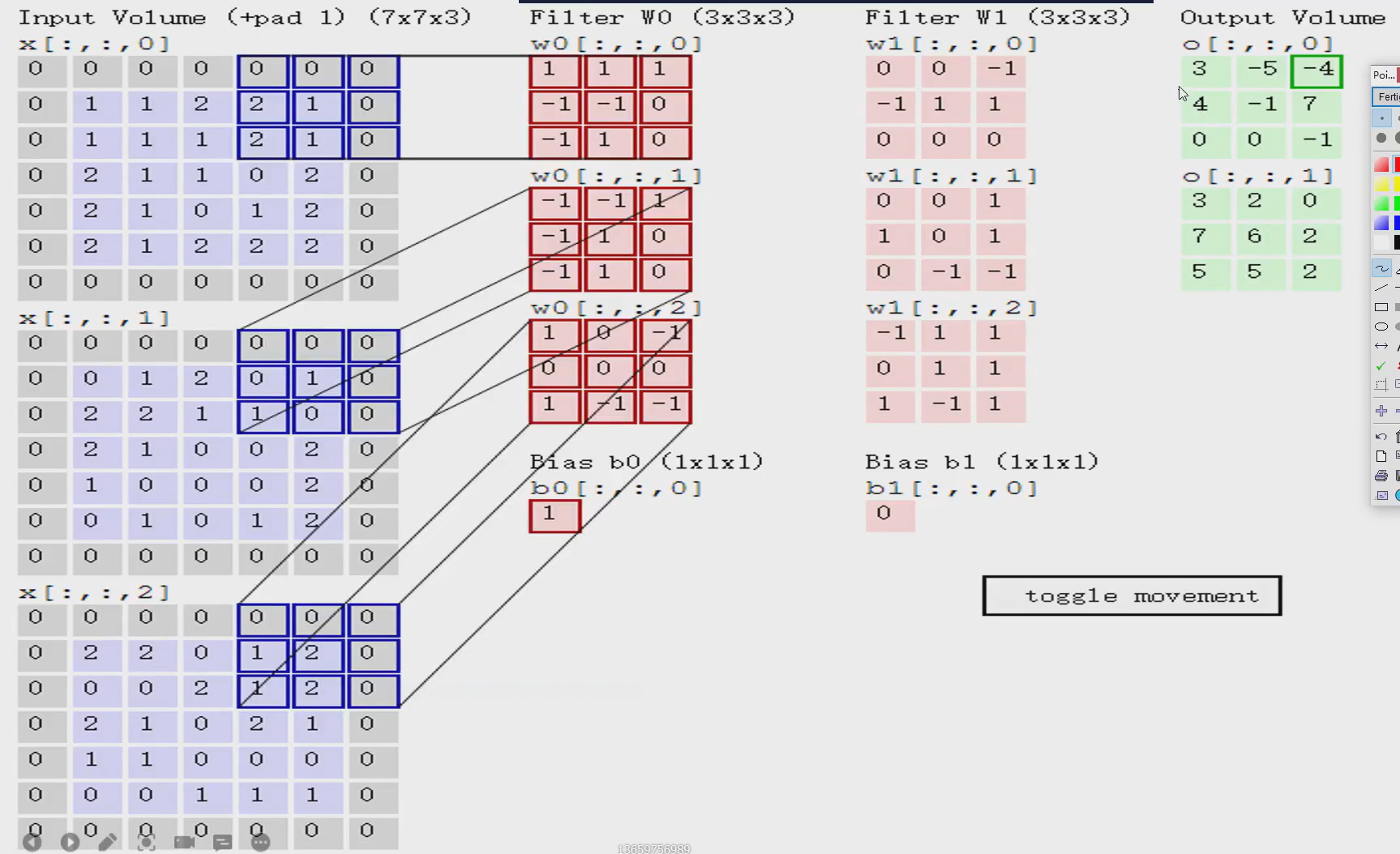
里面的每个红色的块就是一个卷积核,卷积核的里买的每一个值都是随机-生成的,然后就可以和左边算“内积”,不是矩阵乘法,是对应位置相乘再求和
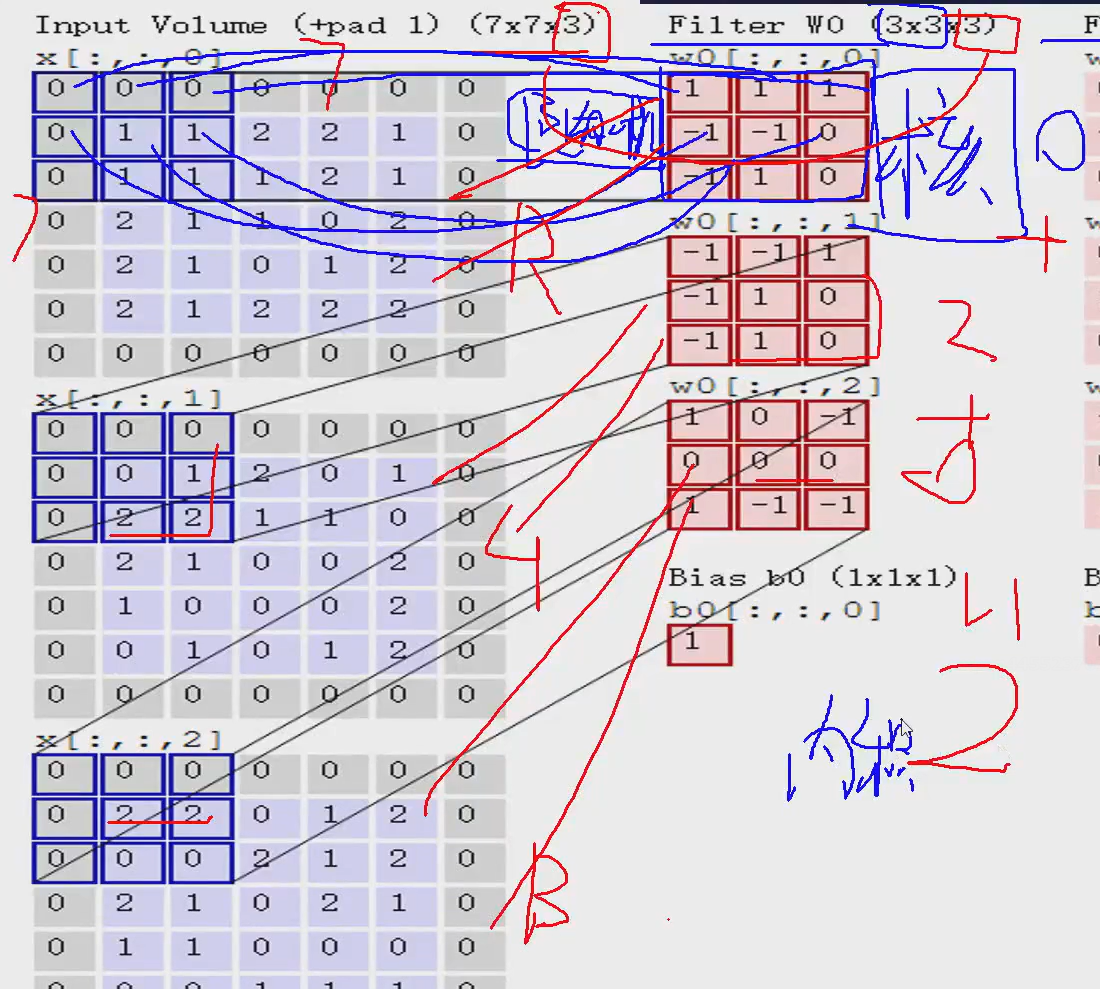
第一步:
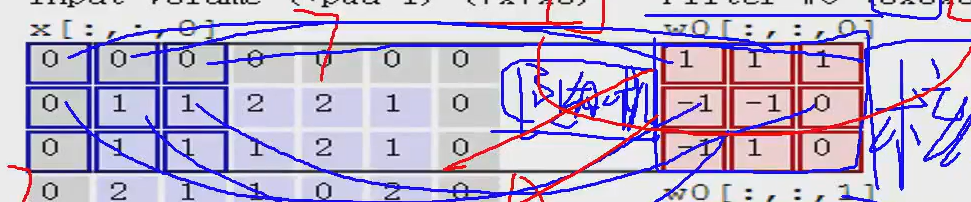
1+01+01+0-1+1-1+10+0-1+11+10=0
第一个的内积就是0
同理:
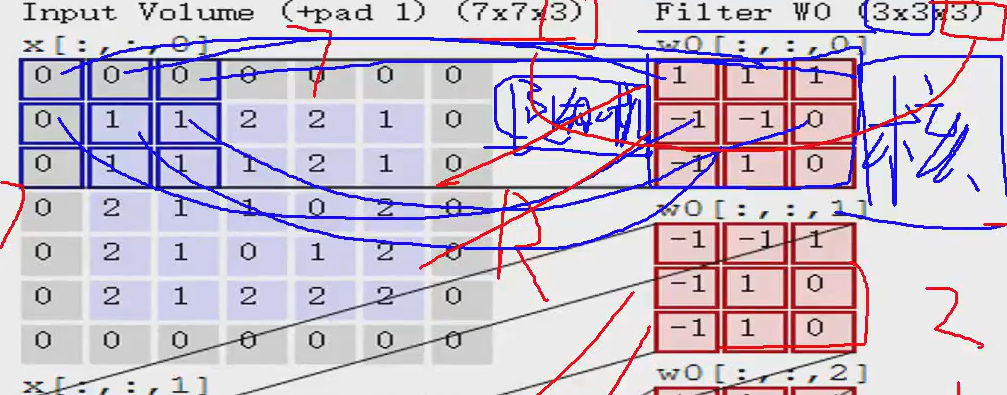
第二个内积就是2,第三个内积是0
第二步:把每个的内积再求和
0+2+0=2
第三步:加上bias (偏置)
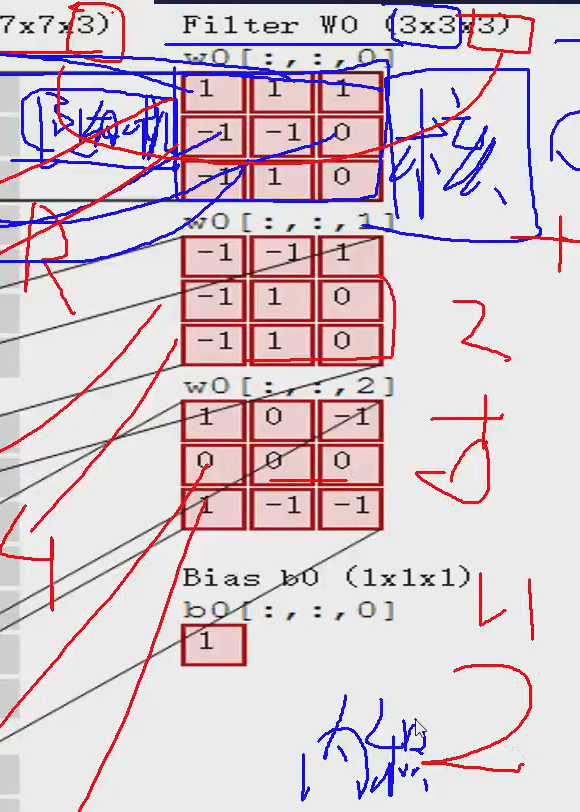
2+1=3
所以第一个窗口第一个位置的特征值就是3
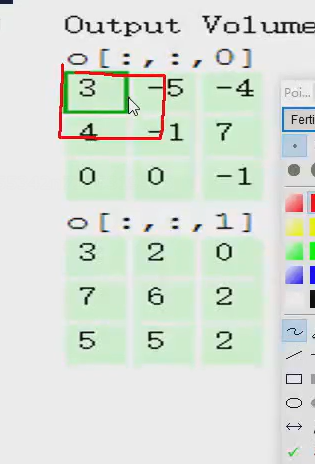
同理
算第二个位置的特征值:
第三个:
得到一个特征图
重点:
- 卷积核越小约好,走的慢,窗口多,特征多,更加详细,卷积目的就是:提特征数
- 卷积核越多越好,第二个卷积核得到了一个不同的特征


- pad
加上一圈0
因为:如果不加上边界,内部的点都被算了两次,这样就对边界的点有偏见,所以我们应当加上一圈进行补偿这就没了这样的偏见
卷积的公式

H2:输出的特征矩阵
H1: 输入的图像的矩阵
F:Filter size 就是卷积核大小?
P :pad 因为上下左右都加了,所以p*2
S :步长 每次向前一次走几个格子
S越大特征图越小,S越小特征图越大

32-5+2*2/1+1=32
如果是小数 ,pytorch 就 下取整
参数共享
理论上将不同的地方提取特征的参数应当不一样,但是因为运算的原因,我们只能使用同一个参数对整个使用
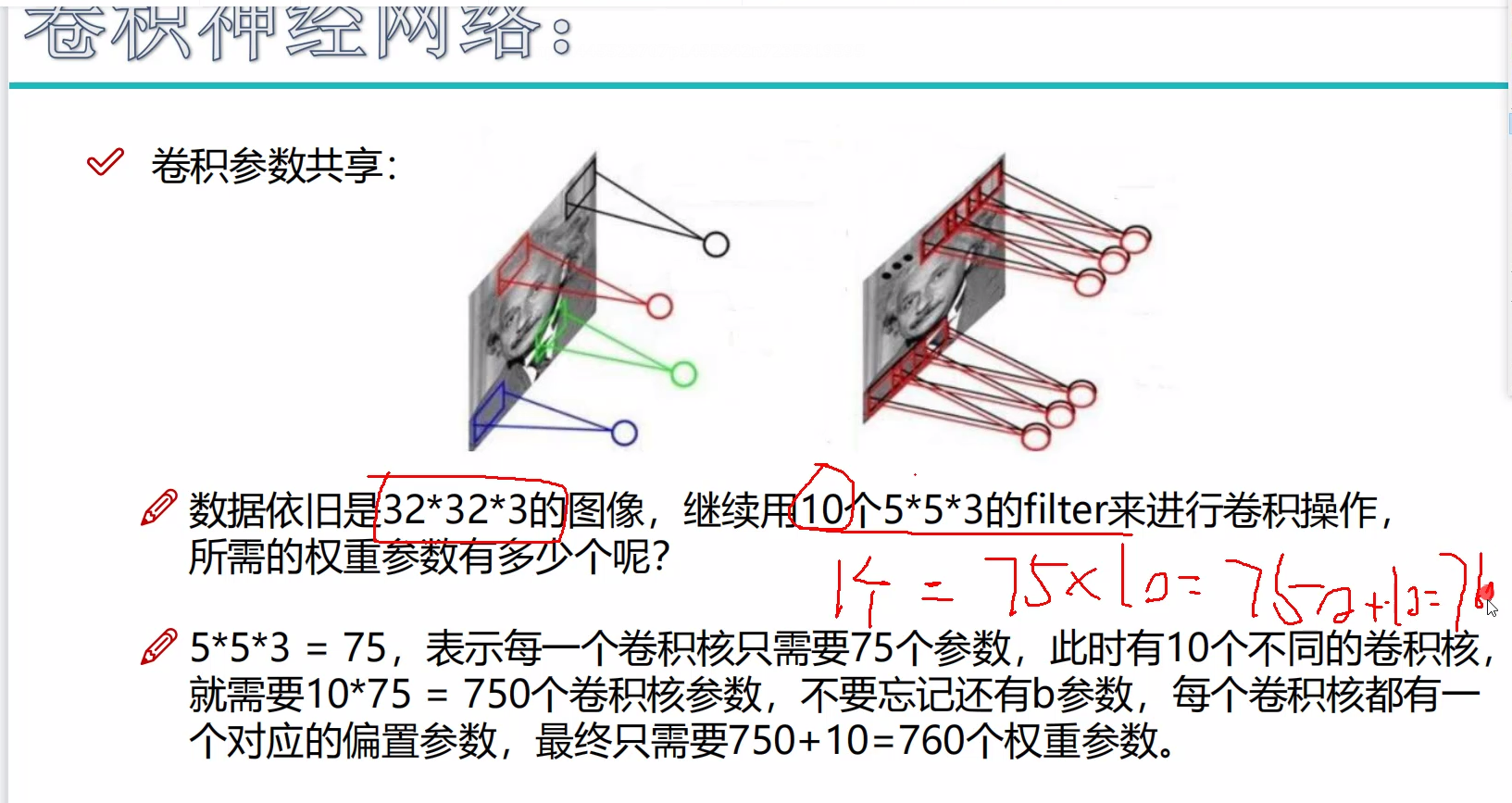
一次的训练每次都用同一批卷积核,实现共享,方便分析
每一个这个都是一个权重参数,也就是一个卷积核

所以:
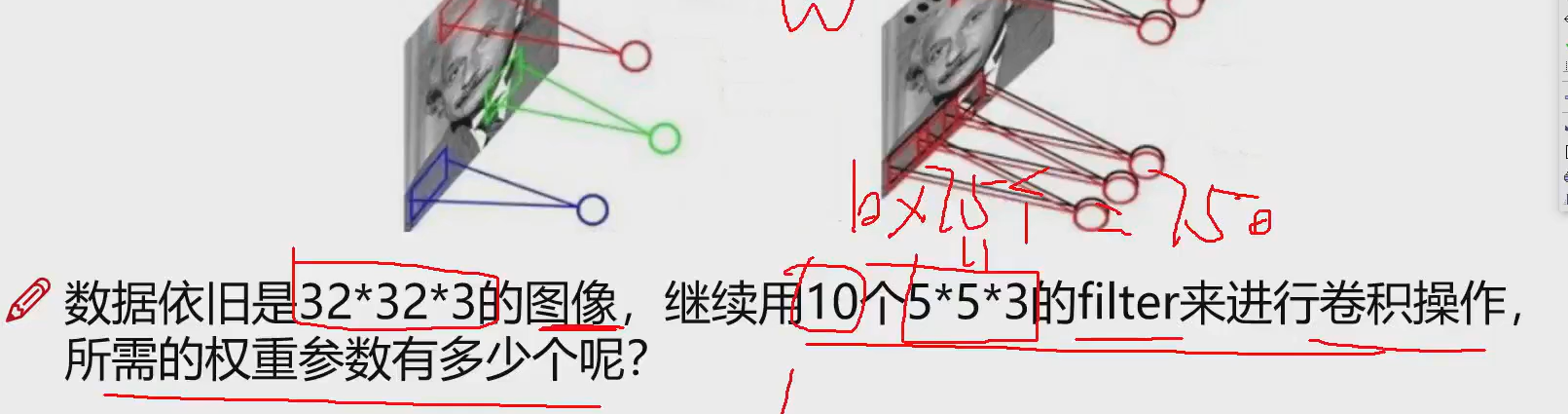
10个553就有750个参数,10个filter就有10个b,所以,就有760个权重参数
Max Polling
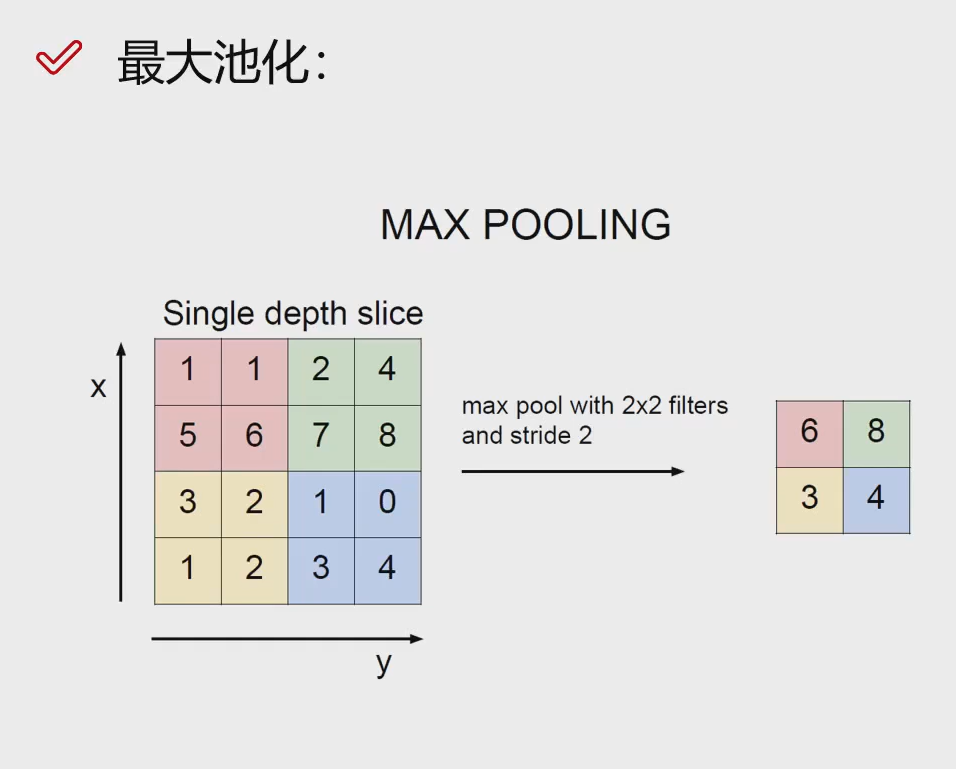
最大池化就是选择最大的作为这一块的特征
一般都是变为前一次的1/2
池化的好数就是让特征变少,提炼特征
(少了)
FC
不论是卷积,还是pool,还是transformer 的作用都是提特征,最后做FC就是提算出对应的概率
FC就是输出
公式:
wx+b得到概率
拉平卷积就是FC

感受野

所以不一定感受野越大越好
我觉得感受野就是一个卷积核的面积大小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号