随笔分类 - 深度学习
1
摘要:一、项目概述 SLIME 是一个用于大语言模型(LLM)后训练的强化学习(RL)框架,主要提供两个核心功能: 高性能训练:通过连接Megatron与SGLang,支持多种模式下的高效训练 灵活数据生成:通过自定义数据生成接口和基于服务器的引擎实现任意训练数据生成工作流 从 REDAME 来看,SLI
阅读全文
摘要: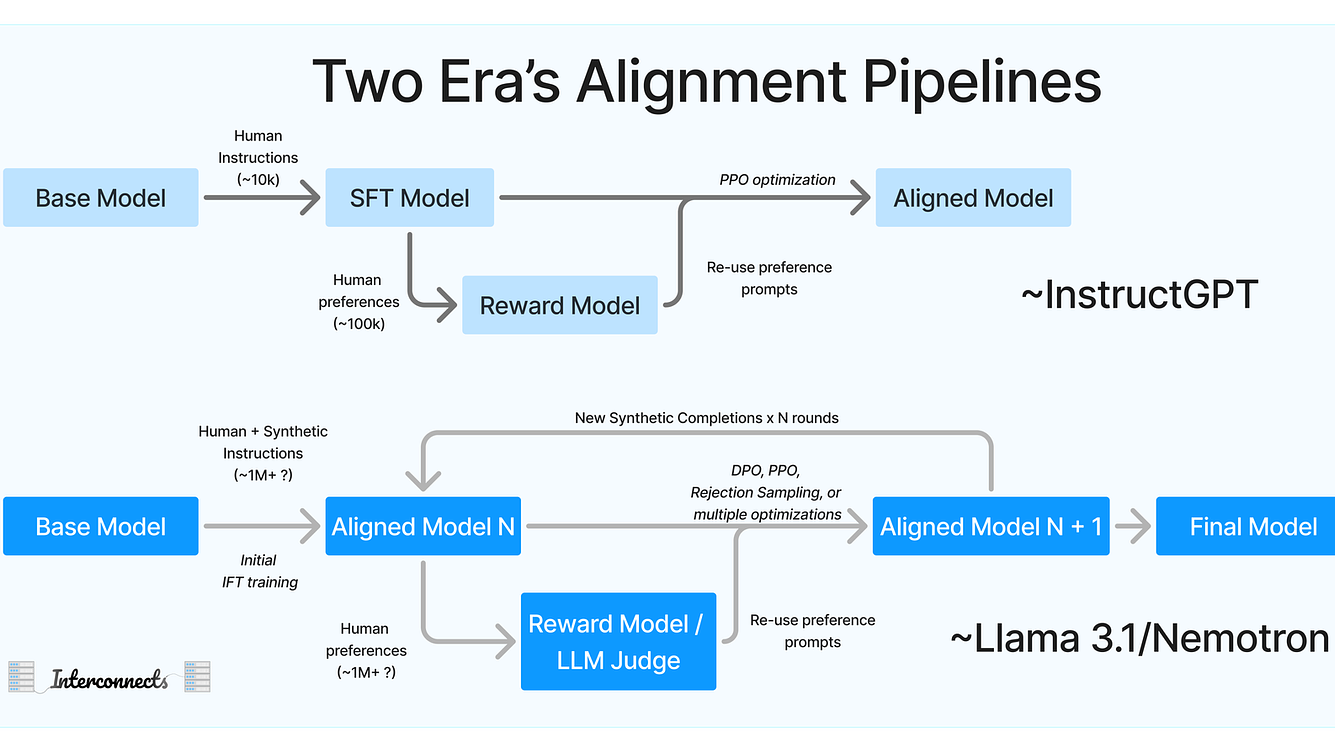 一、问题描述 在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。 1.1 主要特点
阅读全文
一、问题描述 在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。 1.1 主要特点
阅读全文
一、问题描述 在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。 1.1 主要特点
阅读全文
摘要: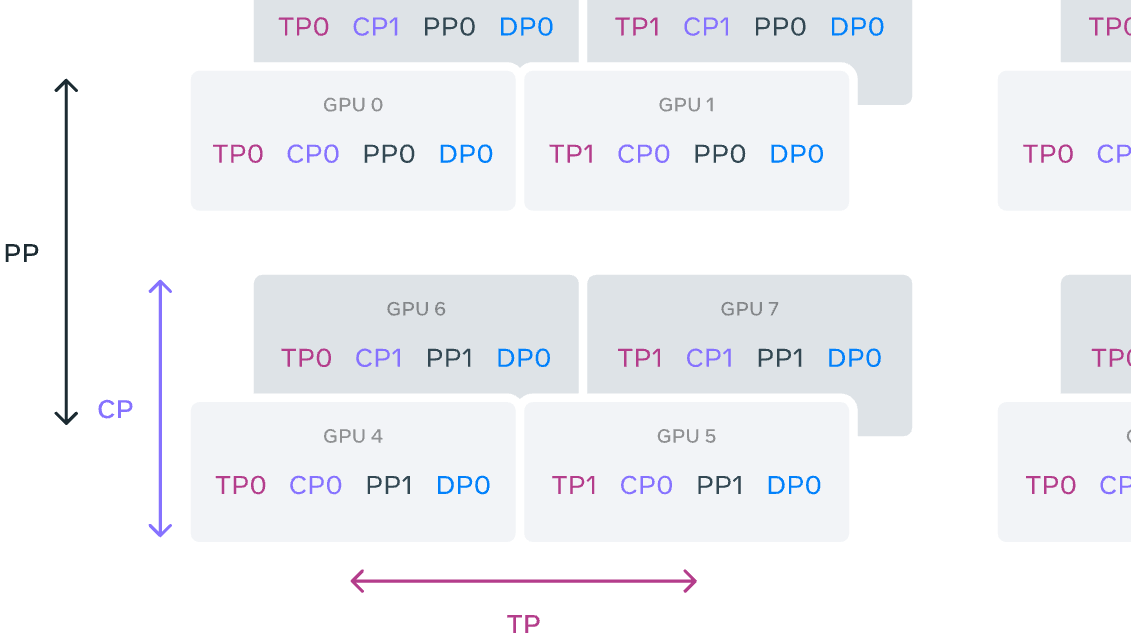 一、 引言概述(Intro & Overview) Llama3是一系列基于Transformer结构的大型多语言模型,通过优化数据质量、训练规模和模型架构,旨在提升模型在各种语言理解任务中的表现。 通过引入更优质的数据和更高效的训练方法,Llama3展示了在自然语言处理领域的巨大潜力。其创新点在于
阅读全文
一、 引言概述(Intro & Overview) Llama3是一系列基于Transformer结构的大型多语言模型,通过优化数据质量、训练规模和模型架构,旨在提升模型在各种语言理解任务中的表现。 通过引入更优质的数据和更高效的训练方法,Llama3展示了在自然语言处理领域的巨大潜力。其创新点在于
阅读全文
一、 引言概述(Intro & Overview) Llama3是一系列基于Transformer结构的大型多语言模型,通过优化数据质量、训练规模和模型架构,旨在提升模型在各种语言理解任务中的表现。 通过引入更优质的数据和更高效的训练方法,Llama3展示了在自然语言处理领域的巨大潜力。其创新点在于
阅读全文
摘要: 本文章涉及的Megatron-llm的XMind思维导图源文件和PDF文件,可在网盘下载: https://pan.baidu.com/s/1xRZD-IP95y7-4Fn0C_VJMg 提取码: qxff 一、引言 Megatron-Core 是一个基于 PyTorch 的开源库,专为在 NVID
阅读全文
本文章涉及的Megatron-llm的XMind思维导图源文件和PDF文件,可在网盘下载: https://pan.baidu.com/s/1xRZD-IP95y7-4Fn0C_VJMg 提取码: qxff 一、引言 Megatron-Core 是一个基于 PyTorch 的开源库,专为在 NVID
阅读全文
本文章涉及的Megatron-llm的XMind思维导图源文件和PDF文件,可在网盘下载: https://pan.baidu.com/s/1xRZD-IP95y7-4Fn0C_VJMg 提取码: qxff 一、引言 Megatron-Core 是一个基于 PyTorch 的开源库,专为在 NVID
阅读全文
摘要: 一、目标 1.1 背景 AI工具库生态的碎片化:随着AI技术的快速发展,市场上涌现出了多种深度学习框架,如TensorFlow、PyTorch、PaddlePaddle等。每种框架都有其独特的优势和生态系统,但这也导致了AI工具库生态的碎片化。不同框架之间的模型和数据格式互不兼容,使得模型迁移和部署
阅读全文
一、目标 1.1 背景 AI工具库生态的碎片化:随着AI技术的快速发展,市场上涌现出了多种深度学习框架,如TensorFlow、PyTorch、PaddlePaddle等。每种框架都有其独特的优势和生态系统,但这也导致了AI工具库生态的碎片化。不同框架之间的模型和数据格式互不兼容,使得模型迁移和部署
阅读全文
一、目标 1.1 背景 AI工具库生态的碎片化:随着AI技术的快速发展,市场上涌现出了多种深度学习框架,如TensorFlow、PyTorch、PaddlePaddle等。每种框架都有其独特的优势和生态系统,但这也导致了AI工具库生态的碎片化。不同框架之间的模型和数据格式互不兼容,使得模型迁移和部署
阅读全文
摘要: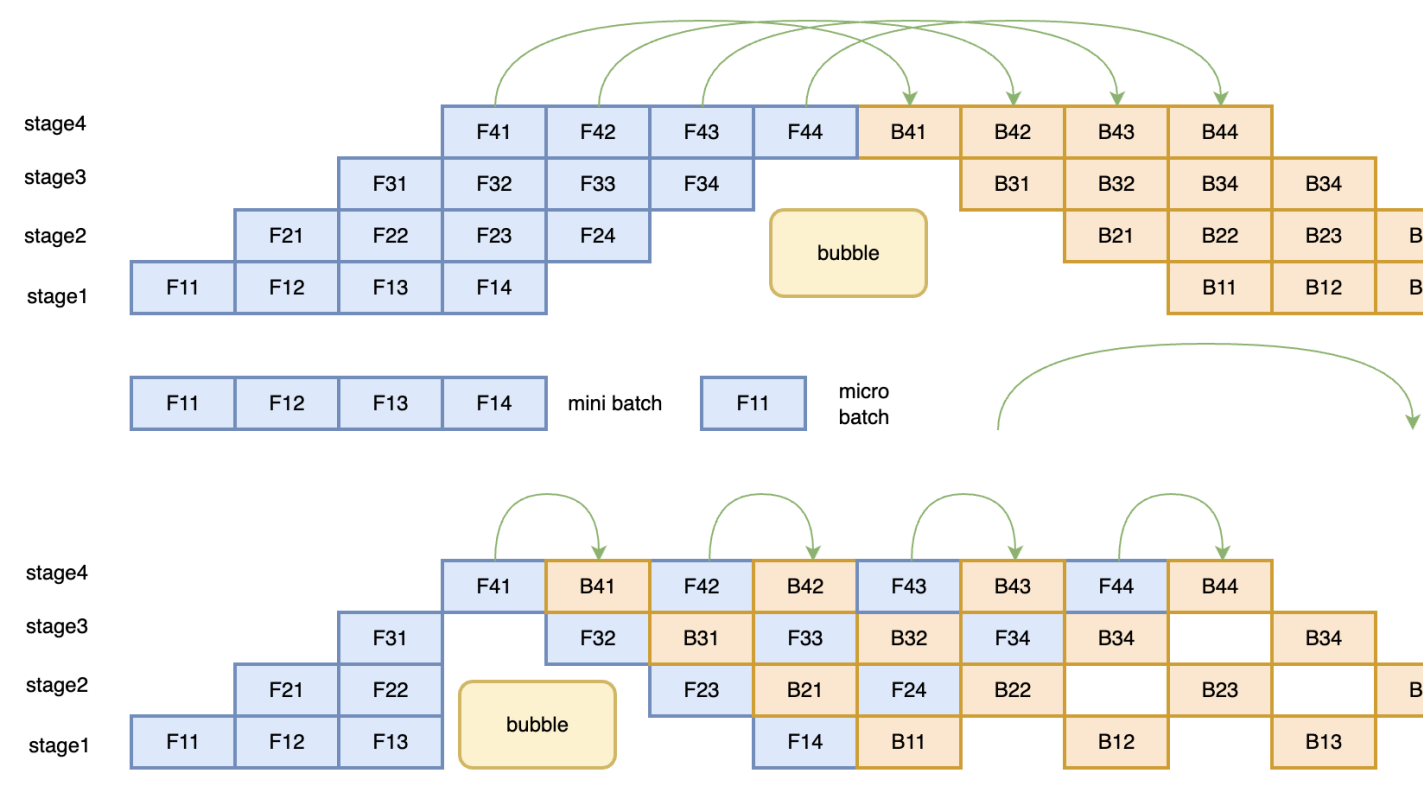 为个人参与深度学习框架飞桨PaddlePaddle 开发时,梳理的个人笔记。 一、并行方式 1.数据并行(Batch维度) 数据并行分为了两种模式:Data Parallel(DP) 和 Distributed Data Parallel(DDP) 。 1.1 Data Parallel DP是一种
阅读全文
为个人参与深度学习框架飞桨PaddlePaddle 开发时,梳理的个人笔记。 一、并行方式 1.数据并行(Batch维度) 数据并行分为了两种模式:Data Parallel(DP) 和 Distributed Data Parallel(DDP) 。 1.1 Data Parallel DP是一种
阅读全文
为个人参与深度学习框架飞桨PaddlePaddle 开发时,梳理的个人笔记。 一、并行方式 1.数据并行(Batch维度) 数据并行分为了两种模式:Data Parallel(DP) 和 Distributed Data Parallel(DDP) 。 1.1 Data Parallel DP是一种
阅读全文
摘要: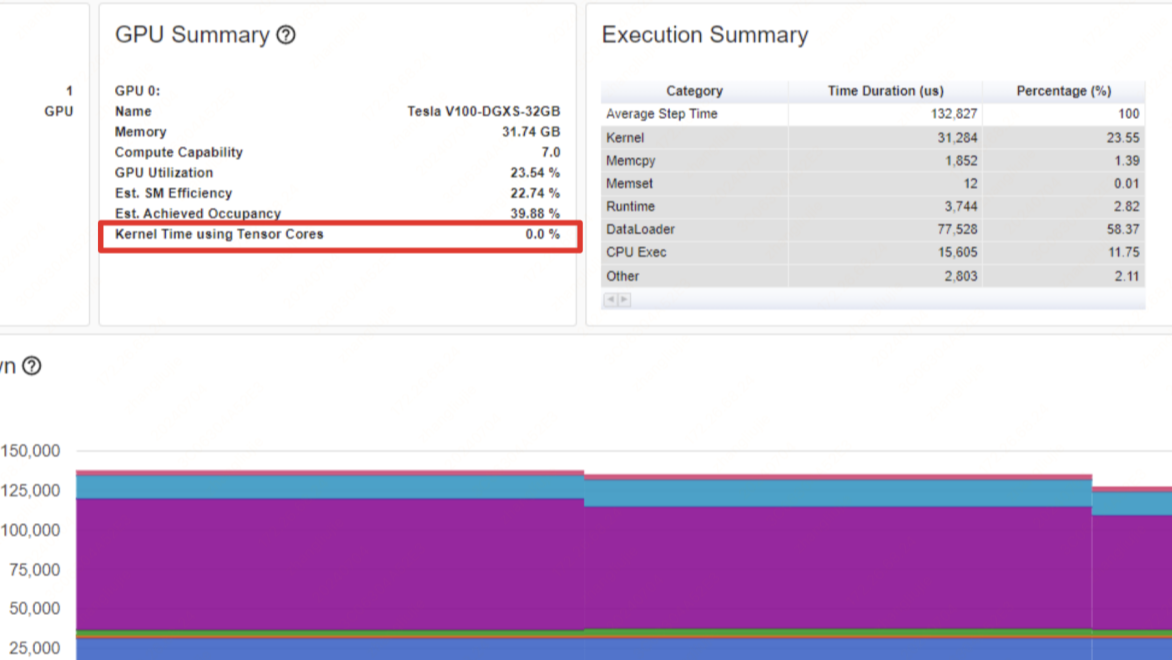 一、问题背景 随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。 1.1 直接目标 最直接地
阅读全文
一、问题背景 随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。 1.1 直接目标 最直接地
阅读全文
一、问题背景 随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。 1.1 直接目标 最直接地
阅读全文
摘要: 注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。 一、环境 & 工具配置 0. 开发机配置 # 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上
阅读全文
注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。 一、环境 & 工具配置 0. 开发机配置 # 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上
阅读全文
注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。 一、环境 & 工具配置 0. 开发机配置 # 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上
阅读全文
摘要: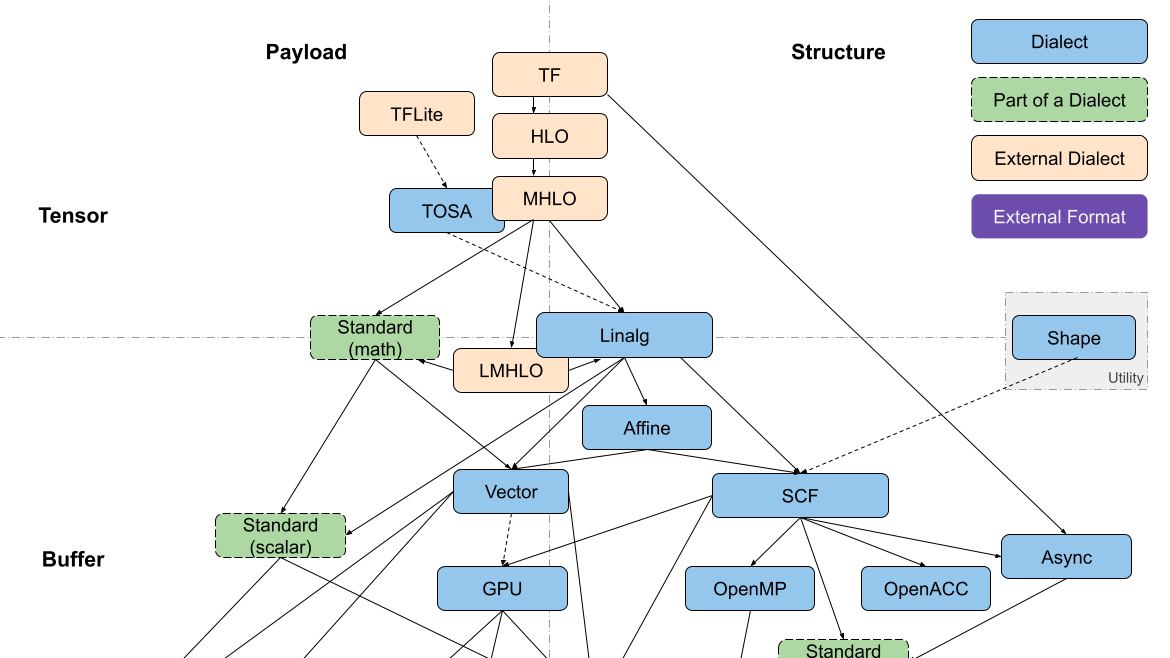 > 以「疑问 - 求解」的形式来组织调研,此处记录整个过程。 ## 1. MLIR 中的 Dialect 是「分层」设计的么? 先问是不是,再谈为什么。从 [LLVM 社区](https://discourse.llvm.org/t/codegen-dialect-overview/2723) 可以
阅读全文
> 以「疑问 - 求解」的形式来组织调研,此处记录整个过程。 ## 1. MLIR 中的 Dialect 是「分层」设计的么? 先问是不是,再谈为什么。从 [LLVM 社区](https://discourse.llvm.org/t/codegen-dialect-overview/2723) 可以
阅读全文
> 以「疑问 - 求解」的形式来组织调研,此处记录整个过程。 ## 1. MLIR 中的 Dialect 是「分层」设计的么? 先问是不是,再谈为什么。从 [LLVM 社区](https://discourse.llvm.org/t/codegen-dialect-overview/2723) 可以
阅读全文
摘要: > 如下的技术点梳理仅以「日常优化工作」为牵引点,涉及哪个模块,就具体去看哪个模块的代码。 # 一、CINN 框架 CINN 中`CodeGen`之后的代码编译主要交给了`Compiler`类来负责。核心的函数主要是: * `Build(ir::Module&, string& code)` * `
阅读全文
> 如下的技术点梳理仅以「日常优化工作」为牵引点,涉及哪个模块,就具体去看哪个模块的代码。 # 一、CINN 框架 CINN 中`CodeGen`之后的代码编译主要交给了`Compiler`类来负责。核心的函数主要是: * `Build(ir::Module&, string& code)` * `
阅读全文
> 如下的技术点梳理仅以「日常优化工作」为牵引点,涉及哪个模块,就具体去看哪个模块的代码。 # 一、CINN 框架 CINN 中`CodeGen`之后的代码编译主要交给了`Compiler`类来负责。核心的函数主要是: * `Build(ir::Module&, string& code)` * `
阅读全文
摘要: 一、概览 注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性 |框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle | |: :|: :|: :|: :| | cond/while| √ | √ | √ |
阅读全文
一、概览 注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性 |框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle | |: :|: :|: :|: :| | cond/while| √ | √ | √ |
阅读全文
一、概览 注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性 |框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle | |: :|: :|: :|: :| | cond/while| √ | √ | √ |
阅读全文
摘要: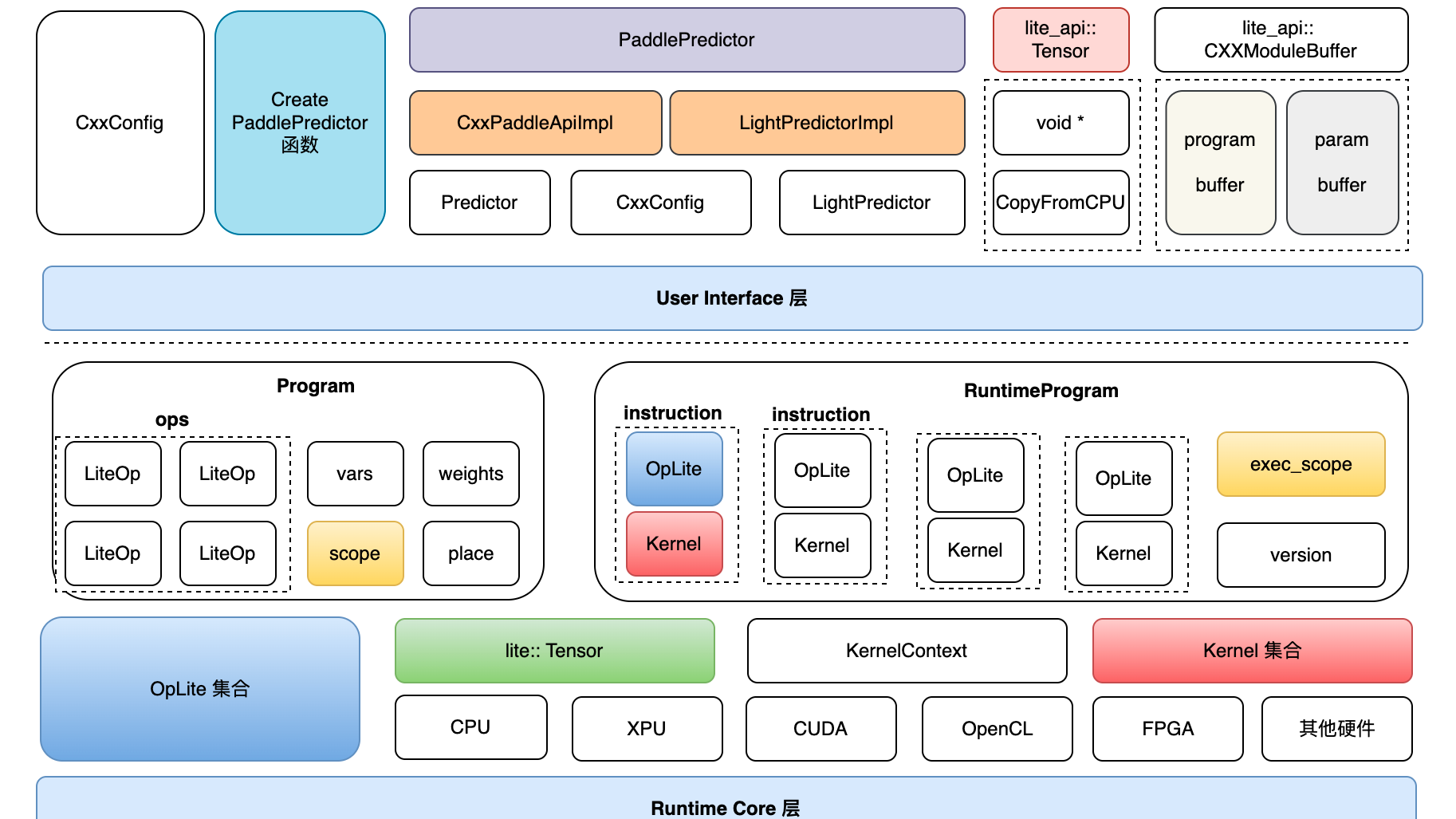 一、架构全景图 二、源码详细解读 1. Lite体系下似乎有多种 op_desc/program_desc 的定义,之间的关系是什么?这样设计的背景和好处是什么? model_parser目录下,包含 flatbuffers——结构描述定义在 framework.fbs 文件中,命名空间为paddl
阅读全文
一、架构全景图 二、源码详细解读 1. Lite体系下似乎有多种 op_desc/program_desc 的定义,之间的关系是什么?这样设计的背景和好处是什么? model_parser目录下,包含 flatbuffers——结构描述定义在 framework.fbs 文件中,命名空间为paddl
阅读全文
一、架构全景图 二、源码详细解读 1. Lite体系下似乎有多种 op_desc/program_desc 的定义,之间的关系是什么?这样设计的背景和好处是什么? model_parser目录下,包含 flatbuffers——结构描述定义在 framework.fbs 文件中,命名空间为paddl
阅读全文
摘要: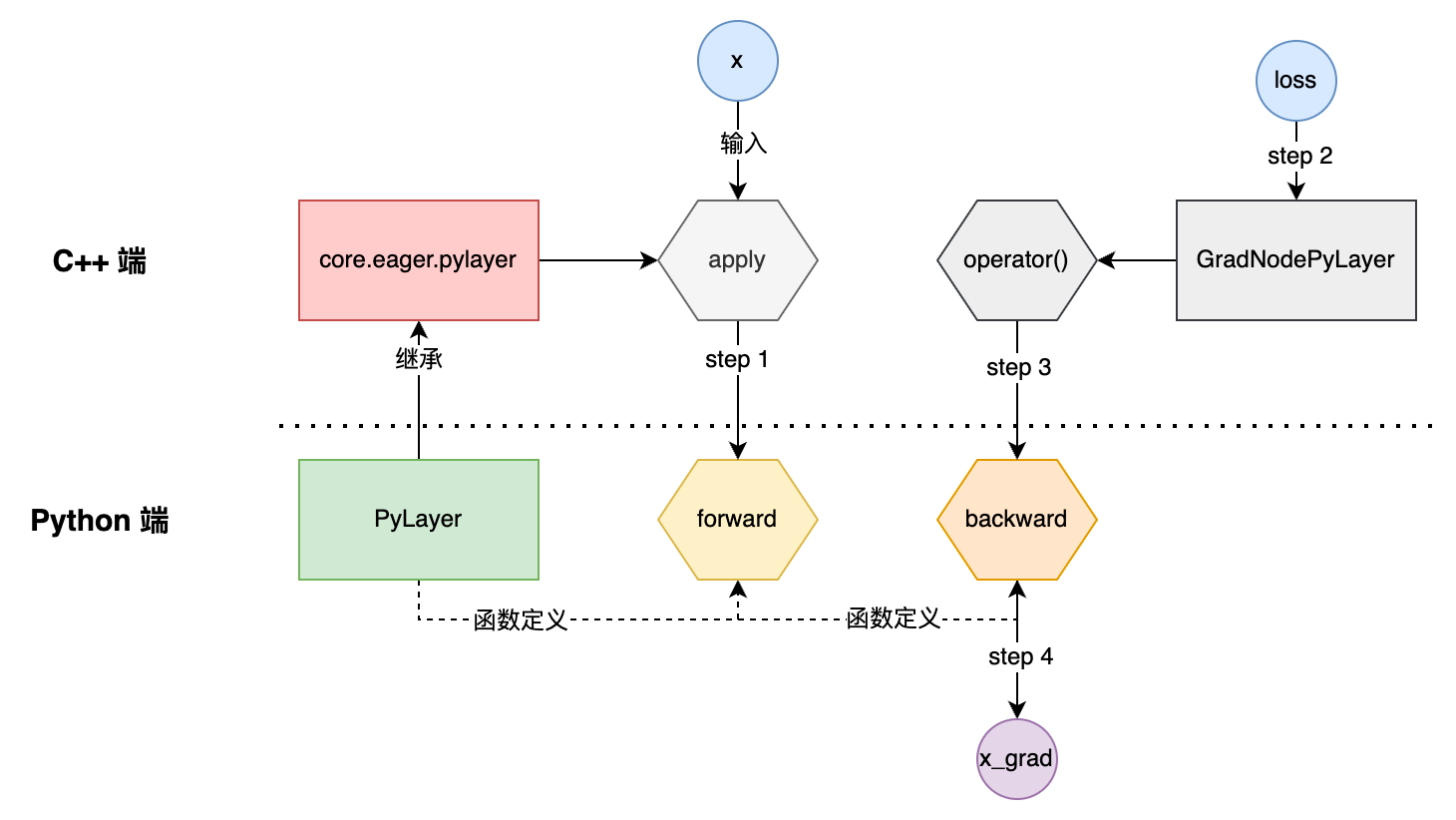 一、主要用法 如下是官方文档上的使用样例: import paddle from paddle.autograd import PyLayer # Inherit from PyLayer class cus_tanh(PyLayer): @staticmethod def forward(ctx,
阅读全文
一、主要用法 如下是官方文档上的使用样例: import paddle from paddle.autograd import PyLayer # Inherit from PyLayer class cus_tanh(PyLayer): @staticmethod def forward(ctx,
阅读全文
一、主要用法 如下是官方文档上的使用样例: import paddle from paddle.autograd import PyLayer # Inherit from PyLayer class cus_tanh(PyLayer): @staticmethod def forward(ctx,
阅读全文
摘要: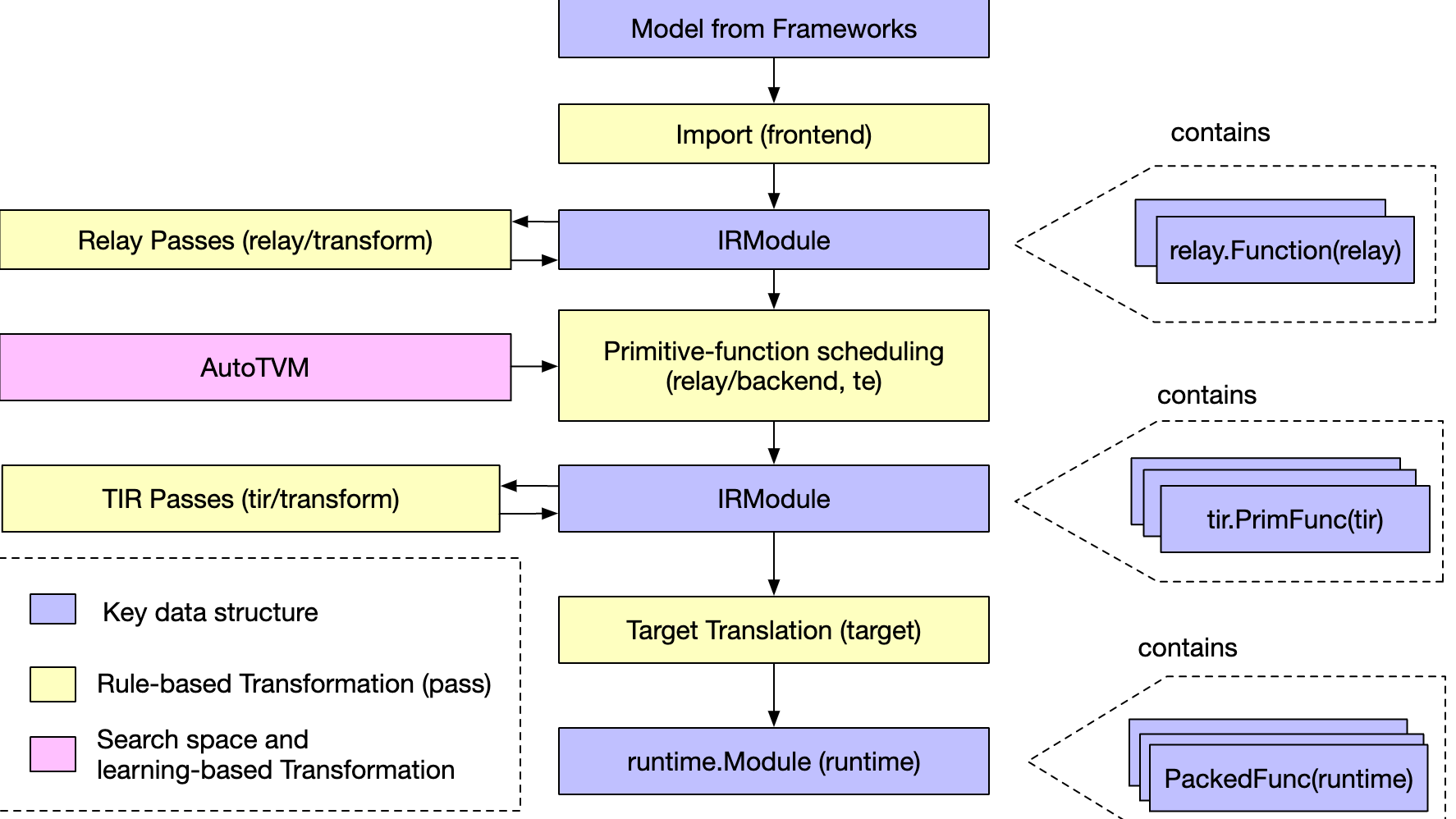 一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。
阅读全文
一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。
阅读全文
一、关键问题 TVM中的 IR 是什么,架构设计上分几层? 解答:TVM的整体结构图如下: 概念上,分为两层:上层为面向前端组网的Relay IR, 下层为面向LLVM的底层 IR。 但从设计实现上,底层通过 Object 元类实现统一的AST Node表示,借助一个 IRModule 贯穿上下层。
阅读全文
摘要: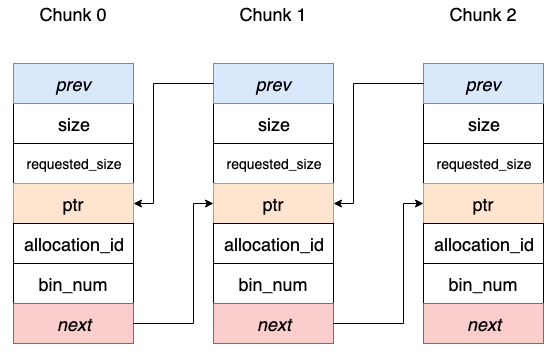 前言 在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。 在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的
阅读全文
前言 在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。 在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的
阅读全文
前言 在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。 在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的
阅读全文
摘要: 前言 本文翻译自《Attention?Attention!》 最近几年,注意力——在深度学习社区中,已然成为最广为流行的概念和实用工具。在这篇博客里,我们将一起回顾它是如何被“发明”出来的,以及引申出来的各种变种和模型,如 transformer和SNAIL。 目录 Seq2Seq问题所在 为”翻译
阅读全文
前言 本文翻译自《Attention?Attention!》 最近几年,注意力——在深度学习社区中,已然成为最广为流行的概念和实用工具。在这篇博客里,我们将一起回顾它是如何被“发明”出来的,以及引申出来的各种变种和模型,如 transformer和SNAIL。 目录 Seq2Seq问题所在 为”翻译
阅读全文
前言 本文翻译自《Attention?Attention!》 最近几年,注意力——在深度学习社区中,已然成为最广为流行的概念和实用工具。在这篇博客里,我们将一起回顾它是如何被“发明”出来的,以及引申出来的各种变种和模型,如 transformer和SNAIL。 目录 Seq2Seq问题所在 为”翻译
阅读全文
摘要: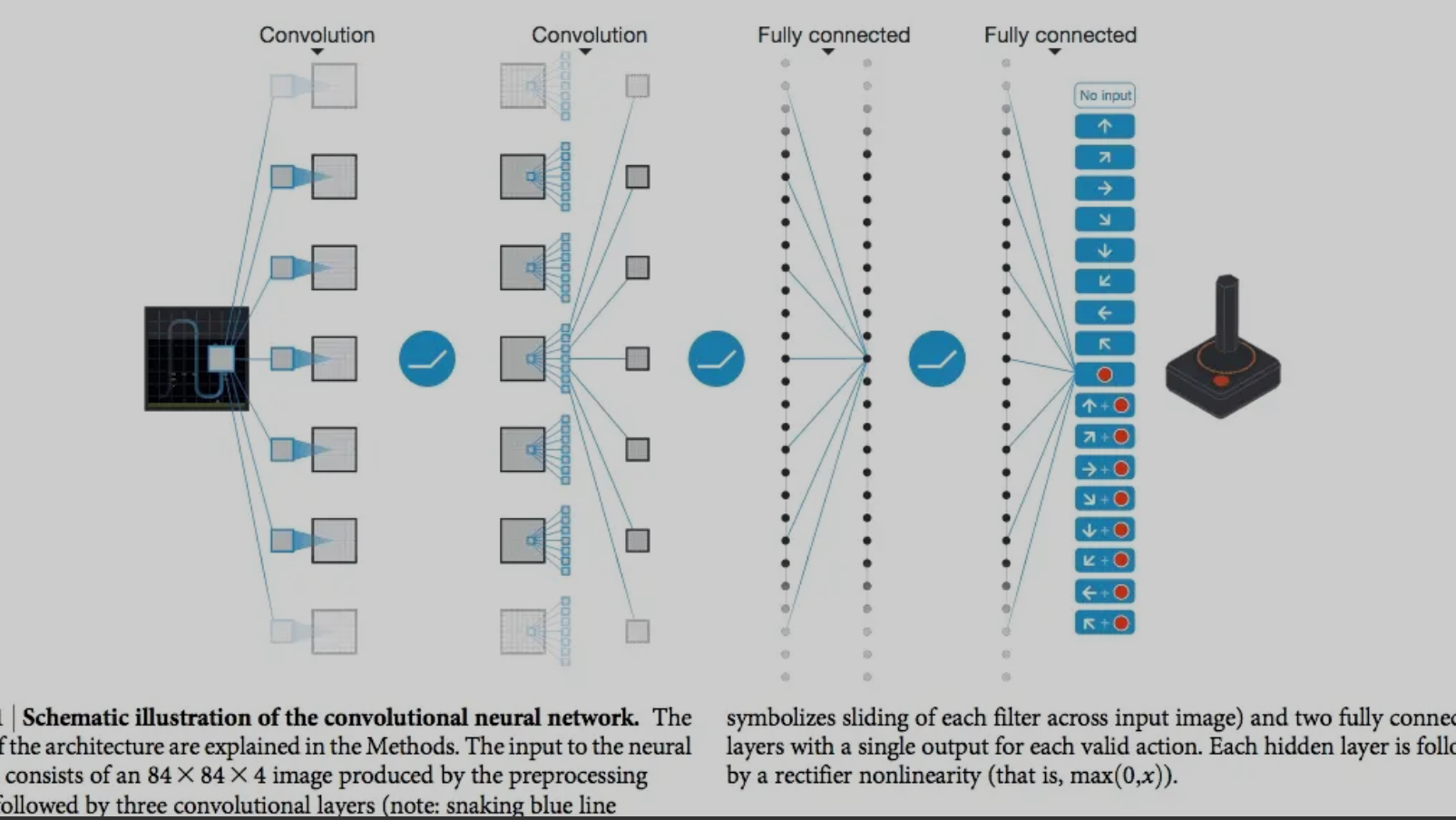 最近在学习斯坦福2017年秋季学期的《强化学习》课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生。 今天主要总结上午看的有关DQN的一篇论文《Human-level control through deep reinforcement lea
阅读全文
最近在学习斯坦福2017年秋季学期的《强化学习》课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生。 今天主要总结上午看的有关DQN的一篇论文《Human-level control through deep reinforcement lea
阅读全文
最近在学习斯坦福2017年秋季学期的《强化学习》课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生。 今天主要总结上午看的有关DQN的一篇论文《Human-level control through deep reinforcement lea
阅读全文
摘要: 总结了2017年找实习时,在头条、腾讯、小米、搜狐、阿里等公司常见的机器学习面试题,包括决策树GBDT、XGboost、朴素贝叶斯、逻辑斯谛回归、KNN、正则化等。
阅读全文
总结了2017年找实习时,在头条、腾讯、小米、搜狐、阿里等公司常见的机器学习面试题,包括决策树GBDT、XGboost、朴素贝叶斯、逻辑斯谛回归、KNN、正则化等。
阅读全文
总结了2017年找实习时,在头条、腾讯、小米、搜狐、阿里等公司常见的机器学习面试题,包括决策树GBDT、XGboost、朴素贝叶斯、逻辑斯谛回归、KNN、正则化等。
阅读全文
摘要:对机器学习感兴趣的小伙伴,可以借助python,实现一个N-gram分词中的Unigram和Bigram分词器,来进行入门。
此项目并将前向最大切词FMM和后向最大切词的结果作为Baseline,对比分析N-gram分词器在词语切分正确率、词义消歧和新词识别等方面的优势。
阅读全文
摘要:前言 本文翻译自 An overview of gradient descent optimization algorithms 概要 梯度优化算法,作为各大开源库(如Tensorflow,Keras,PyTorch等)中重要的黑盒子,在网络训练中至关重要,拥有很强的魔力(实用性),但官网一般很少介
阅读全文
1
 浙公网安备 33010602011771号
浙公网安备 33010602011771号