Slime RL 框架源码剖析
一、项目概述
SLIME 是一个用于大语言模型(LLM)后训练的强化学习(RL)框架,主要提供两个核心功能:
- 高性能训练:通过连接Megatron与SGLang,支持多种模式下的高效训练
- 灵活数据生成:通过自定义数据生成接口和基于服务器的引擎实现任意训练数据生成工作流
从 REDAME 来看,SLIME 采用了三层架构: Training (Megatron) ←→ Data Buffer ←→ Rollout (SGLang + router)
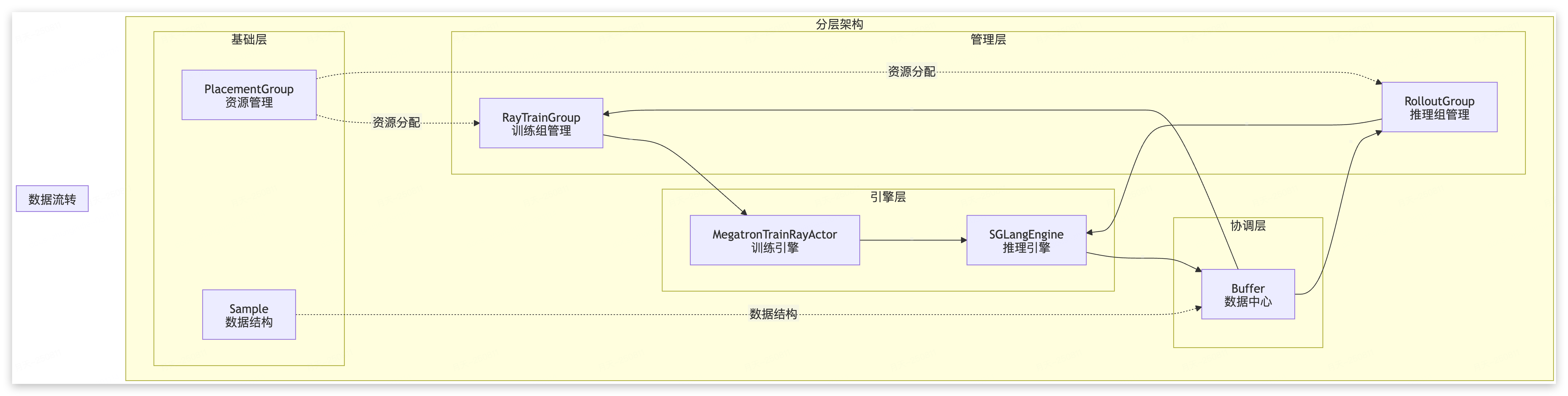
- Training模块:负责主要训练过程,从Data Buffer读取数据,训练后同步参数到rollout模块
- Rollout模块:生成新数据(包括奖励/验证器输出)并存储到Data Buffer
- Data Buffer:桥接模块,管理prompt初始化、自定义数据和rollout生成方法
二、ADT 设计描述(汇总)
研读源码之后,以ADT(Abstract Data Type)视角描述关键模块Type,以及Interface。
1. 资源类型
// Basic structure for a Slime framework module
type Int = number;
type Dict = Record<string, any>;
// RolloutRayActor and RolloutGroup
type Args = {
megatron_args: Dict; // Arguments for the Megatron model
sglang_args: Dict; // Arguments for the SGLang model
slime_args: Dict; // Arguments for the Slime framework
};
/*
Resource Concepts.
1. `--actor-num-nodes`:RL 的 actor 训练需要多少节点;
2. `--actor-num-gpus-per-node`:RL 的 actor 训练的每个节点有卡;
3. `--rollout-num-gpus`:rollout (inference)一共需要多少卡;
4. `--rollout-num-gpus-per-engine`:每个 inference engine 有多少卡,
5. `--colocate`:开启训推一体。开启后会忽略 `--rollout-num-gpus` 让训练和推理的卡数相等。
*/
type PlacementGroupID = Int; // Unique identifier for a placement group
type BundleCache = Array<Dict>; // [{"GPU": 1, "CPU": 1} for _ in range(num_gpus)]
type pg = [PlacementGroup, Int[]];
// Ray 原生的组件
interface PlacementGroup {
id: PlacementGroupID;
bundle_cache: BundleCache;
ready: () => boolean; // Check if the placement group is ready
wait: (timeout: Int) => boolean; // Wait for the placement group to be ready
}
function create_placement_group(args: Args):Record<string, pg> {return {};};
2. Rollout 推理
// Rollout Group
class RolloutGroup {
args: Args;
data_buffer: Buffer;
all_rollout_engines: RolloutRayActor[]; // List of all rollout actors
rollout_engines: RolloutRayActor[]; // all_rollout_engines[::nodes_per_engine]
// Function
async_generate: (rollout_id: Int, evaluation: boolean) => void; //data_buffer.generate()
};
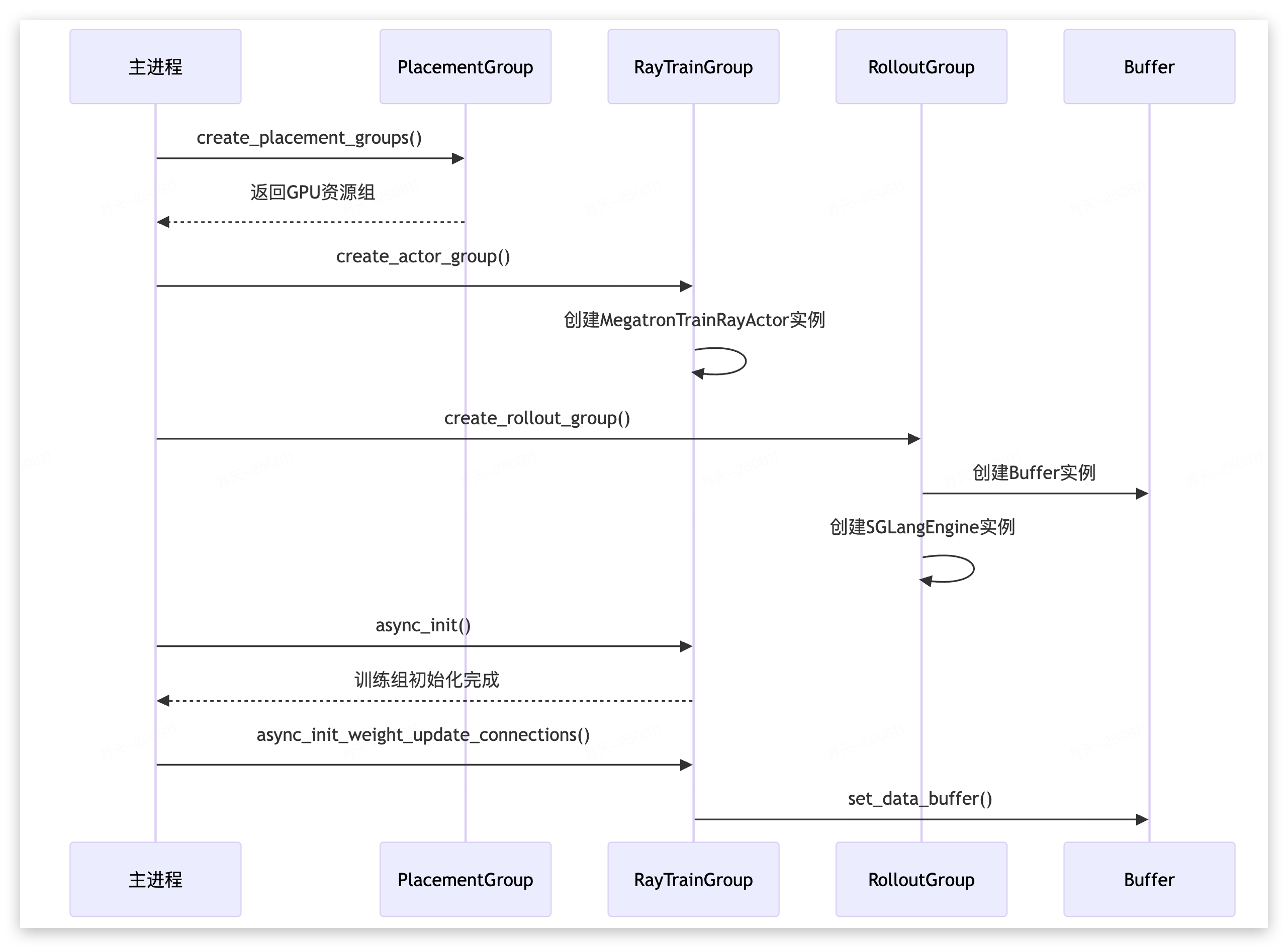
function create_rollout_group(args: Args): RolloutGroup { return new RolloutGroup();}
// Rollout engine
type SGLangInferenceEngine = {};
type vLLMInferenceEngine = {};
type InferEngine = SGLangInferenceEngine | vLLMInferenceEngine;
type IPCHandle = {};
interface RolloutRayActor {
args: Args;
rank: Int;
infer_engine: InferEngine;
init_process_group: (master_addr: string, master_port: Int, rank_offset: Int, world_size: Int, backend: string) => void;
sleep: (level: Int) => void;
wakeup: () => void;
pause_generation: () => void;
continue_generation: () => void;
update_weights_from_tensor: (ipc_handles: IPCHandle[]) => void; // sync weight
};
function create_rollout_engines(args, pg: pg): RolloutRayActor[] {
const rollout_engines: RolloutRayActor[] = [];
/*
const num_engines = args.rollout_num_gpus / 8;
for (const rank of Array.from({ length: num_engines }, (_, i) => i) ) {
const actor = new RolloutRayActor(args, pg, rank);
rollout_engines.push(actor);
}
*/
return rollout_engines;
}
3. Data Buffer 管道
// DataBuffer
type Sample = {
index: Int; // rollout.n 的第几个
// inputs
prompt: string | Array<Dict>;
tokens: Int[];
// outputs
response: string;
response_length: Int;
// others
label: string;
reward: number | Dict;
loss_mask: Int[];
};
type Dataset = {};
// 数据容器涉及到三个不同的概念:buffer、dataset、train/eval_data_pool
interface Buffer {
// Members
args: Args;
buffer: Sample[][]; // [[0_0, 0_1], [1_0, 1_1]] 第一层为 rollout_id,第二层为Rollout Group样本
train_data_pool: Dict;
eval_data_pool: Dict;
rollout_id: Int; // 记录当前轮次 rollout_id
buffer_filter: (buffer: Buffer, num_samples: Int) => Sample[][];
dataset: Dataset;
// Functions
get_samples: (num_samples: Int) => Sample[][]; // 优先从buffer中取。为什么还要加 Dataset 逻辑?
add_sample: (samples: Sample[][]) => void; // 放到 buffer
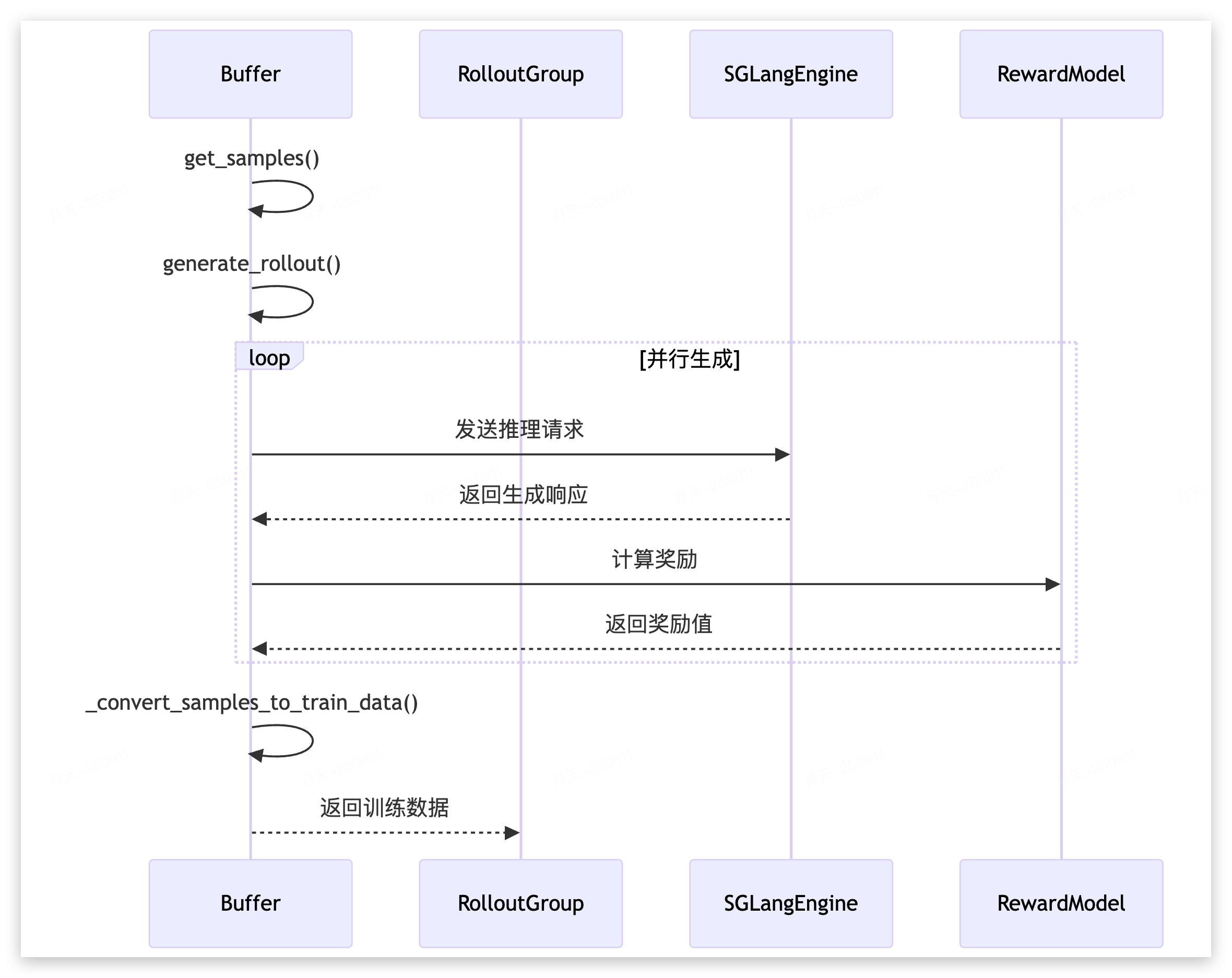
generate: (rollout_id: Int) => void; // data = generate_rollout(rollout_id), 放到 data_pool 里
get_data: (rollout_id: Int, eval: boolean) => Sample[]; // 根据 rollout_id 和 eval 从data_pool里取
// utils
_convert_samples_to_train_data: (samples: Sample[]) => Dict[];
};
// 用户可以自定义这个模块
function generate_rollout(args: Args, rollout_id: Int, data_buffer: Buffer, eval: boolean) : Sample[][]{ return [[]];};
4. Train Actor
4.1 Backend 抽象接口
type RayActor = {
// master_addr: string;
// master_port: Int;
};
interface TrainRayActor extends RayActor {
/*
init: (args: Args) => void;
set_data_buffer: (data_buffer: Buffer) => void; // 通过 Buffer 与Rollout 做数据链接
train: (rollout_id: Int) => void;
eval: (rollout_id: Int) => void;
// 与Rollout 做实例和通信链接
connect_rollout_engines: (rollout_engines: RolloutRayActor[], lock: any) => void;
update_weights: () => void;
*/
};
function init_model_and_optimizer (args: Args): [any, any]{ return [null, null]; }
function process_rollout_data(rollout_id: Int, rollout_data: Dict): void {
/*
1. 从 data_buffer 中获取 rollout_id 对应的样本
2. 计算 adv、组内平均 reward
3. balance_data 数据切片,提前move_to GPU
通过传入 Dict 形式的 rollout_data, 来做in-place 更新
*/
}
function compute_advantages_and_returns(rollout_data: Dict): void {
/*
1. 计算 advantages 和 returns
2. 更新 rollout_data 中的 reward 字段
*/
}
function backend_train(rollout_id: Int, model: any, optimizer: any, rollout_data: Dict): void {
/*
1. for step in range(num_step_per_rollout)
2. train_one_step
*/
}
function save(iteration: Int, model: any, optimizer: any): void {
/*
megatron.training.checkpointing.save_checkpoint()
*/
}
4.2 Megatron Trainer
// Actor 但可以 with_ref
class MegatronTrainRayActor implements TrainRayActor {
// members
model: any; // Megatron model instance
optimizer: any; // Optimizer instance
weight_updator: any; // UpdateWeightFromTensor | UpdateWeightFromDistributed
data_buffer: Buffer; // Data buffer for training samples
rollout_engines: RolloutRayActor[]; // List of rollout engines connected to this actor
rollout_data_postprocess: (samples: Sample[]) => Sample[]; // Post-processing function for samples
init(args: Args, role: any, with_ref: false): void {
[this.model, this.optimizer] = init_model_and_optimizer(args);
if (with_ref) {
// Initialize with reference to the model and optimizer
}
}
// data related functions
set_data_buffer: (data_buffer: Buffer) => void;
get_rollout_data(rollout_id: Int, rollout_data: Dict): void { // train() 会调用这个函数
process_rollout_data(rollout_id, rollout_data);
}
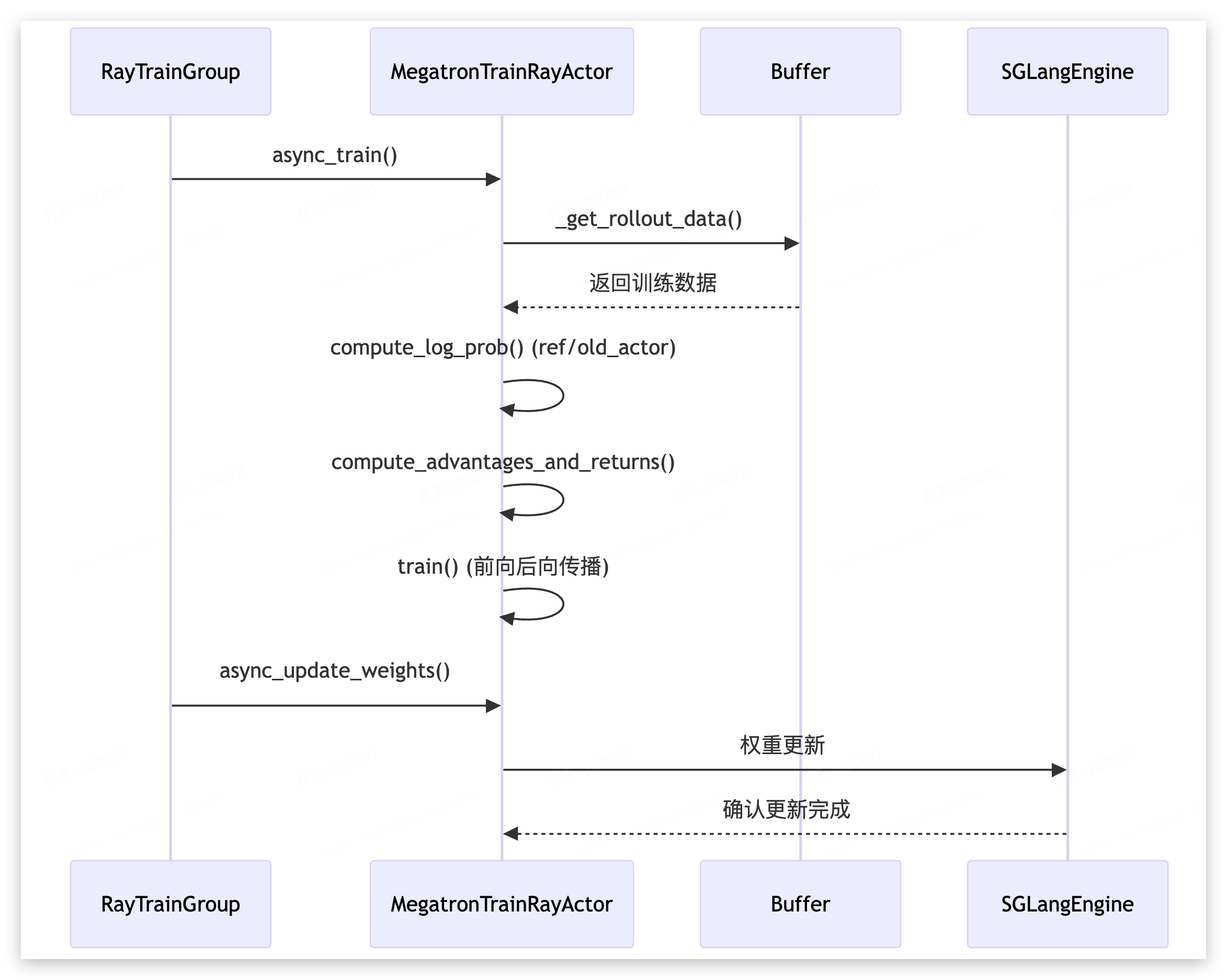
train(rollout_id: Int): void {
let rollout_data = {};
this.get_rollout_data(rollout_id, rollout_data);
this.compute_log_prob("ref", rollout_data);
this.compute_log_prob("actor", rollout_data);
compute_advantages_and_returns(rollout_data);
backend_train(rollout_id, this.model, this.optimizer, rollout_data);
}
compute_log_prob: (model_tag: string, rollout_data: Dict) => void;
// Weight related functions
connect_rollout_engines(rollout_engines: RolloutRayActor[], lock: any): void {
this.rollout_engines = rollout_engines;
this.weight_updator.connect_rollout_engines(rollout_engines, lock);
}
update_weights(): void {
this.weight_updator.update_weights(this.model, this.optimizer);
}
save_model(iteration: Int): void {
// Save the model and optimizer state
save(iteration, this.model, this.optimizer);
}
};
class RayTrainGroup {
// Member
num_nodes: Int;
num_gpus_per_node: Int;
actor_handlers: TrainRayActor[]; // List of actor handlers in the training group
// Functions
__init__(num_nodes, num_gpus_per_node, pg: pg): void {
/*
1. Initialize member variables
2. Create actor handlers for each GPU by calling _allocate_gpus_for_actor
2.1 每个 rank 上实例化 1个 MegatronTrainRayActor
2.2 实例会放到 actor_handlers 数组中
*/
}
async_init: (args:Args, role, with_ref: boolean) => void;
async_train: (rollout_id: Int) => void;
async_eval: (rollout_id: Int) => void;
async_update_weights: () => void;
};
function create_actor_group(args: Args): RayTrainGroup { return new RayTrainGroup();}
三、深入源码
从目录能非常清晰地看出 Slime 优秀的组织形式。其中:
- ray 目录:Ray 分布式架构相关,包括训练actor 组管理、GPU 资源分配,数据生成管理等。
- backends 目录:训练是megatron、推理是SGLang,各子目录管理(预留了未来扩展性)
- rollout 目录:负责数据生成和采样,如Agent 轨迹生成,内含rm_hub(奖励模型中心) 和 filter_hub(数据过滤中心)
1. train 主流程
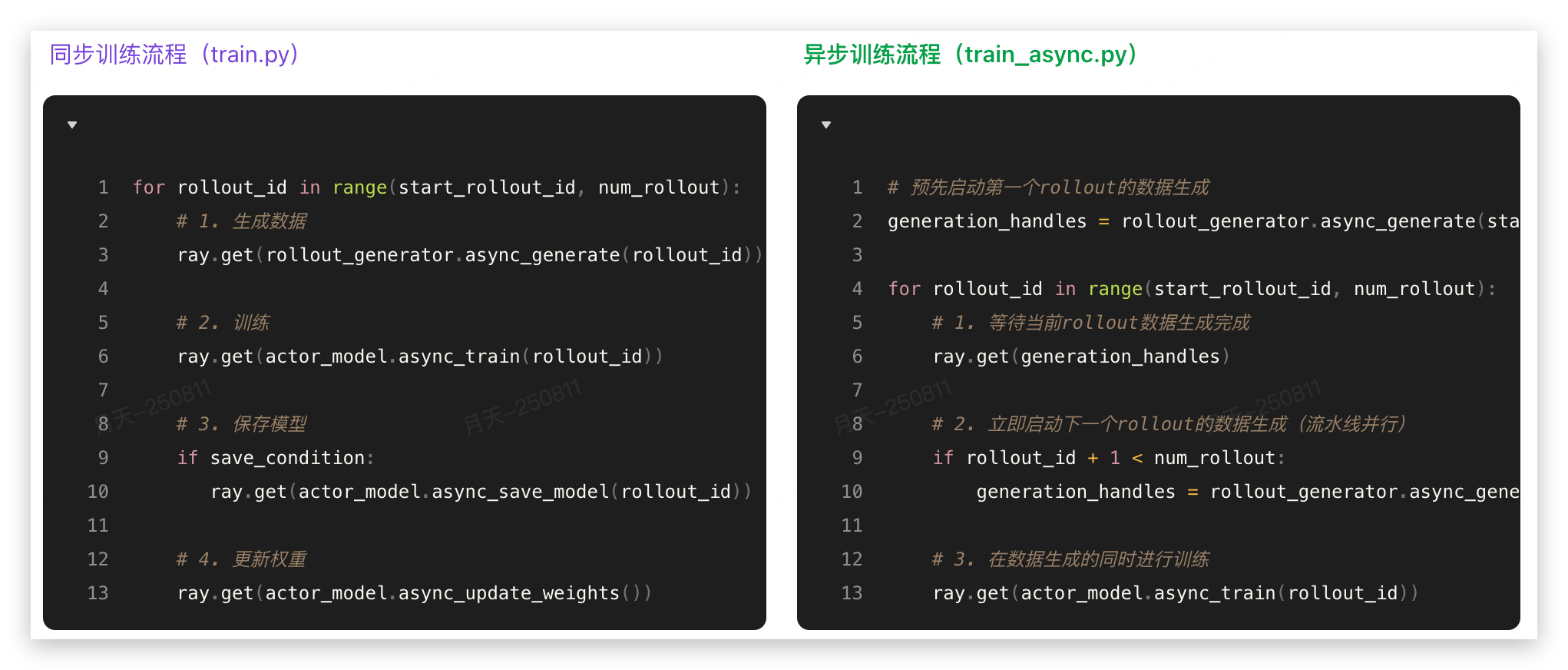
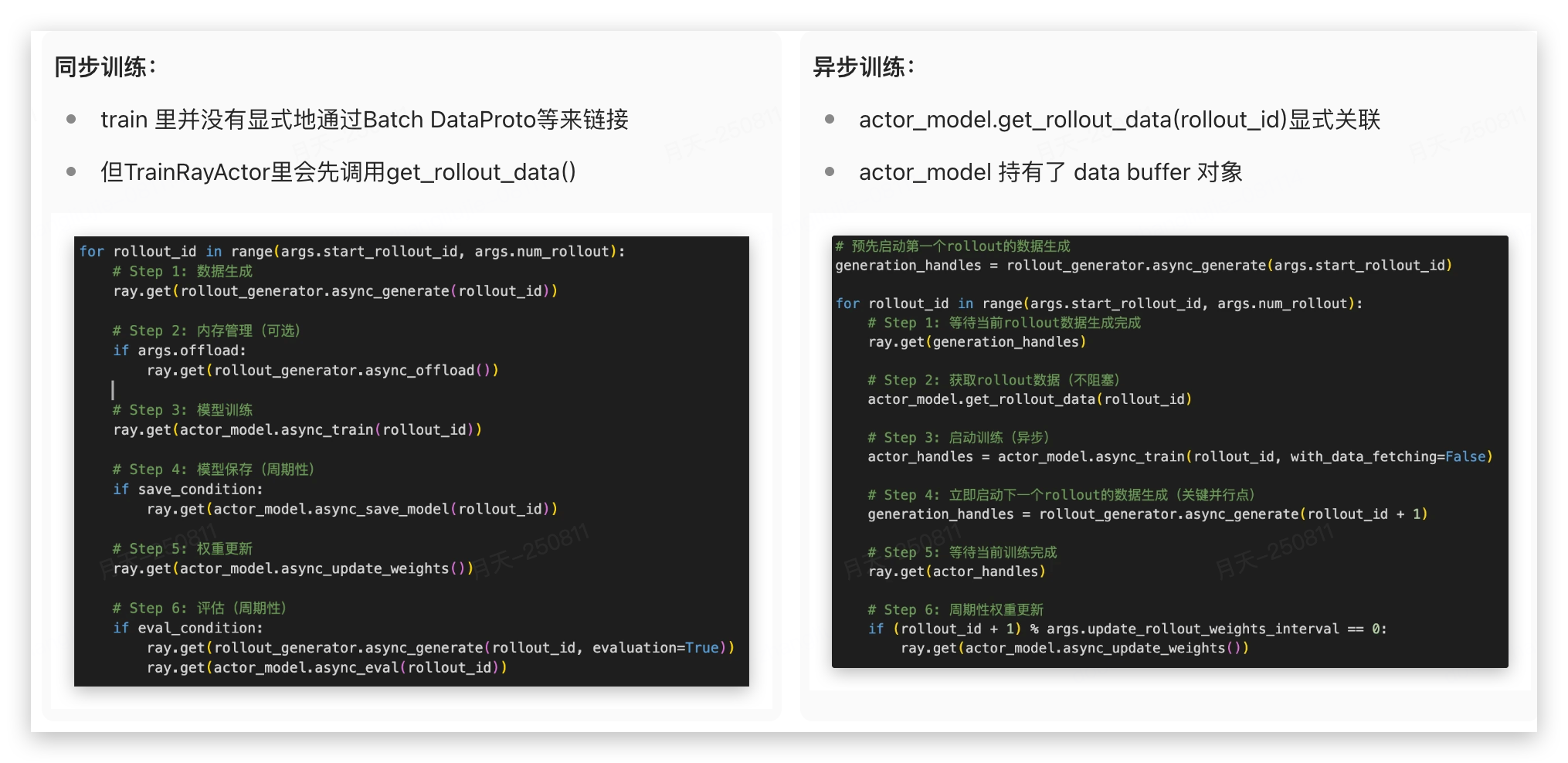
1.1 同步训练
train.py 是 SLIME框架的同步训练主入口,实现了基于Ray的分布式强化学习训练流程。整个文件采用了典型的PPO(Proximal Policy Optimization)训练模式。

从这里可以看出明显的架构优势点:

同步训练在代码各个地方都插入了 ray.get(),是一个完全串行的train loop,训练和推理无法真正并行,我们接着看异步训练。
1.2 异步训练
概括的看,train_agent_async.py 专门为agent训练场景设计,通过流水线并行实现训练和数据生成的重叠执行,提高资源利用率。
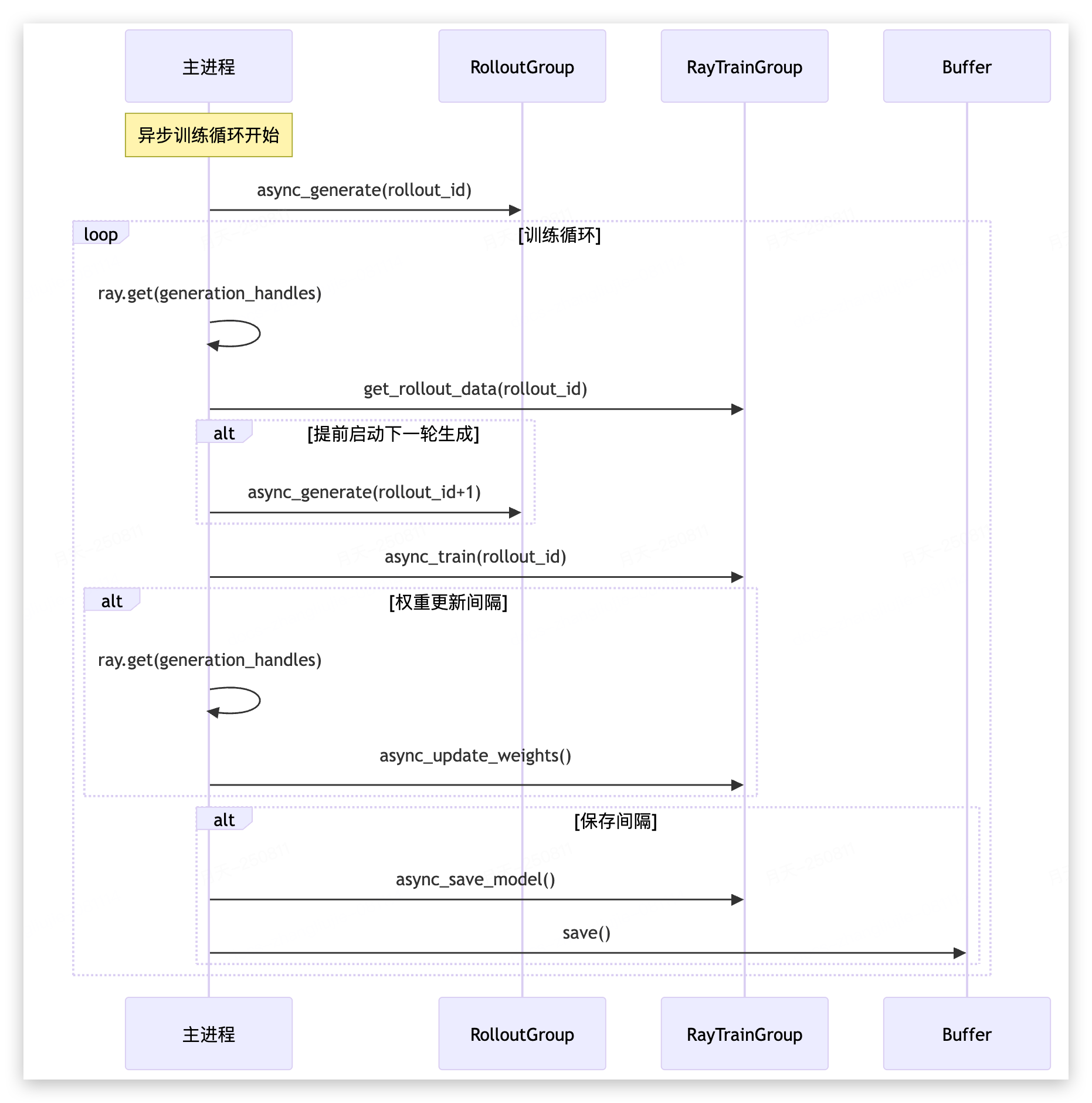

2. 核心组件
上述通过 train 文件从controller 层面一览了slime中的整体流程,能注意到几个关键的模块:

3. 分布式
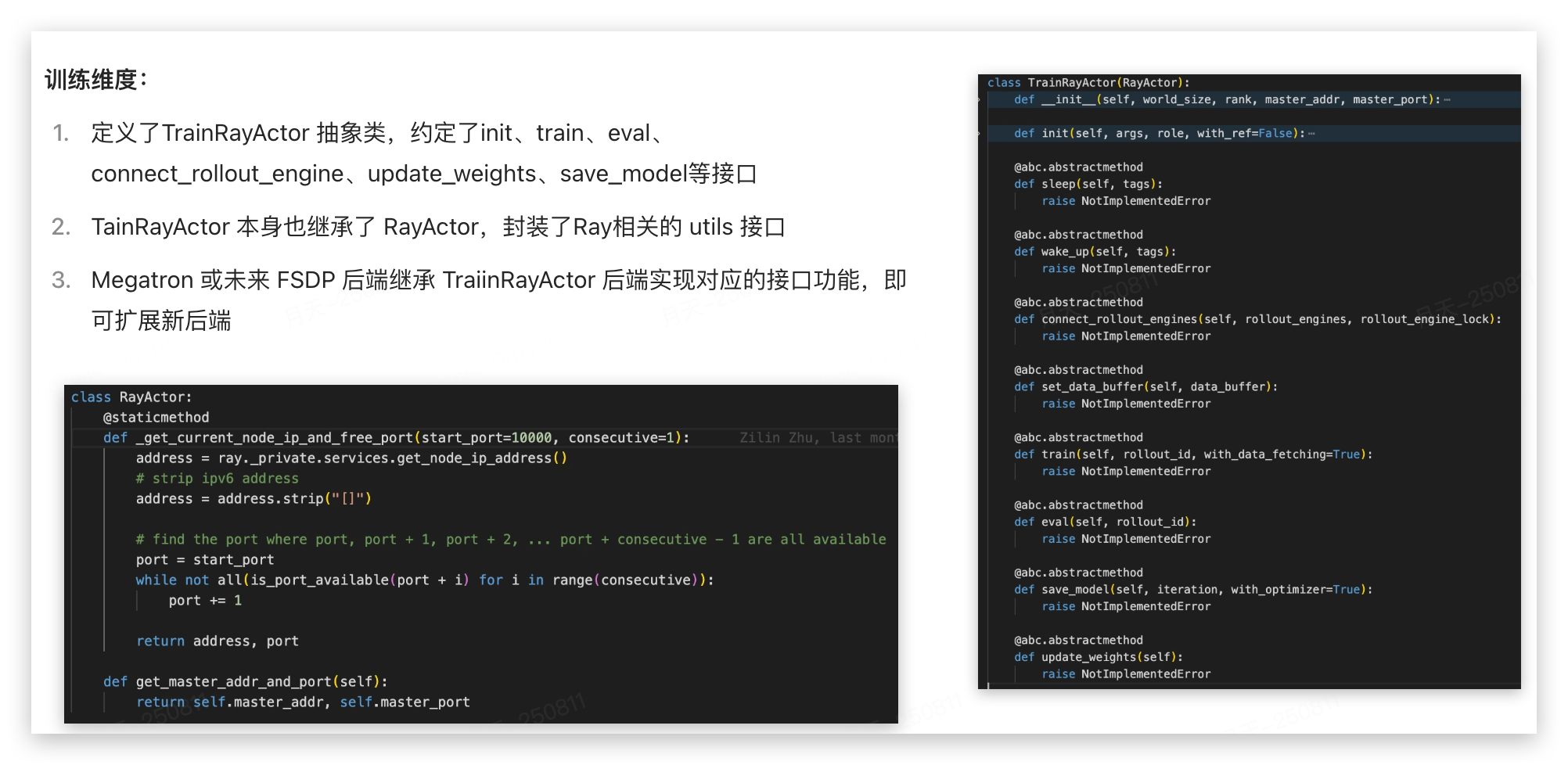
3.1 TrainRayActor
TrainRayActor是一个Ray远程Actor,代表单个GPU上的训练实例:
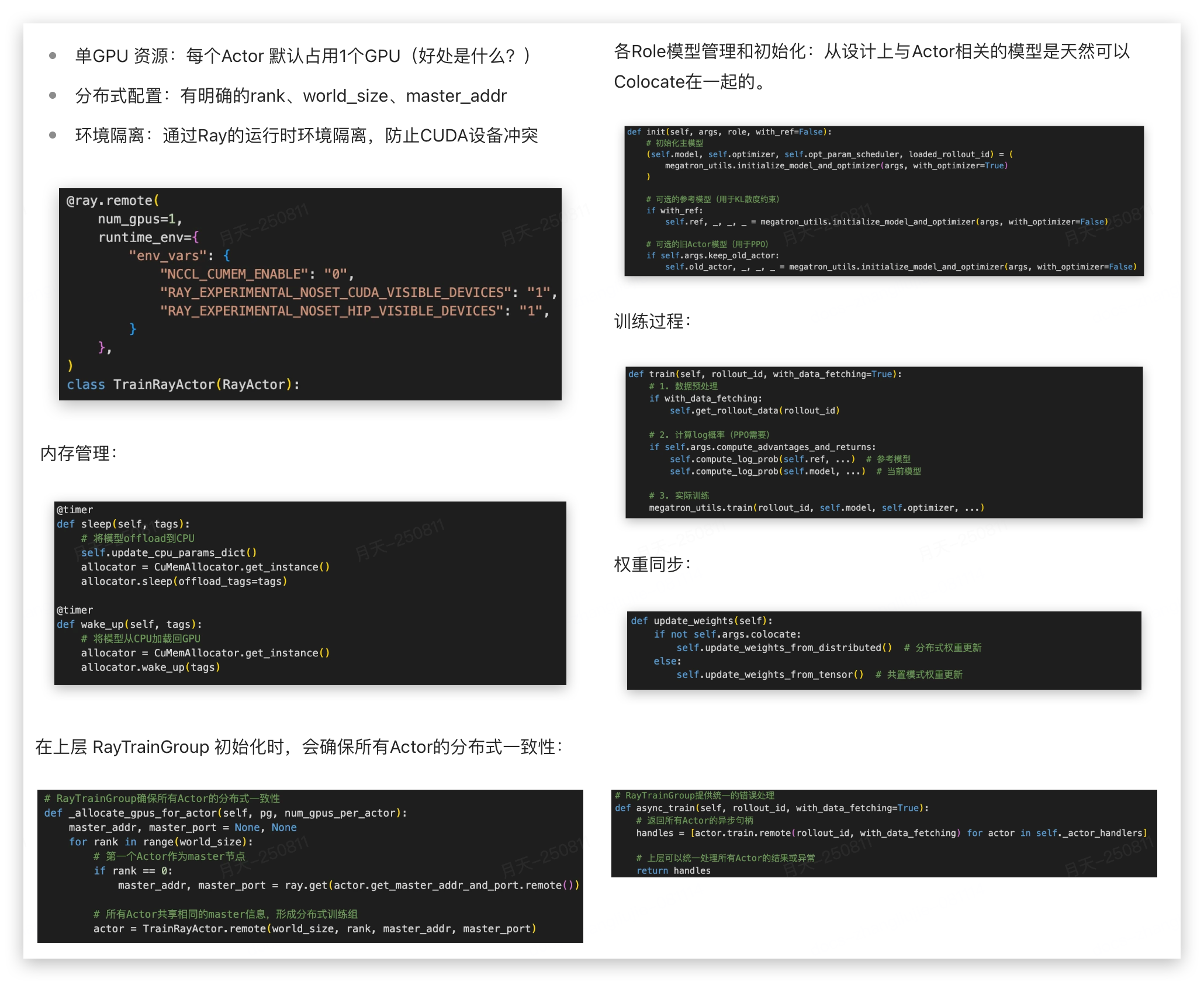
如此分层设计RayTrainGroup 和 TrainRayActor 的优点是什么?(一个负责在哪里训练,一个负责如何训练)
- 职责分离:RayActor 负责GPU上的高效计算,TrainGroup 专注于资源管理和协调
- 可扩展性:RayActor 之间相对独立,支持异构资源;TrainGroup 通过 num_nodes 的num_gpus_per_node 扩展多GPU
- 容错能力:单个Actor失败理论上不会影响整个训练组(但实际应该有影响吧?)

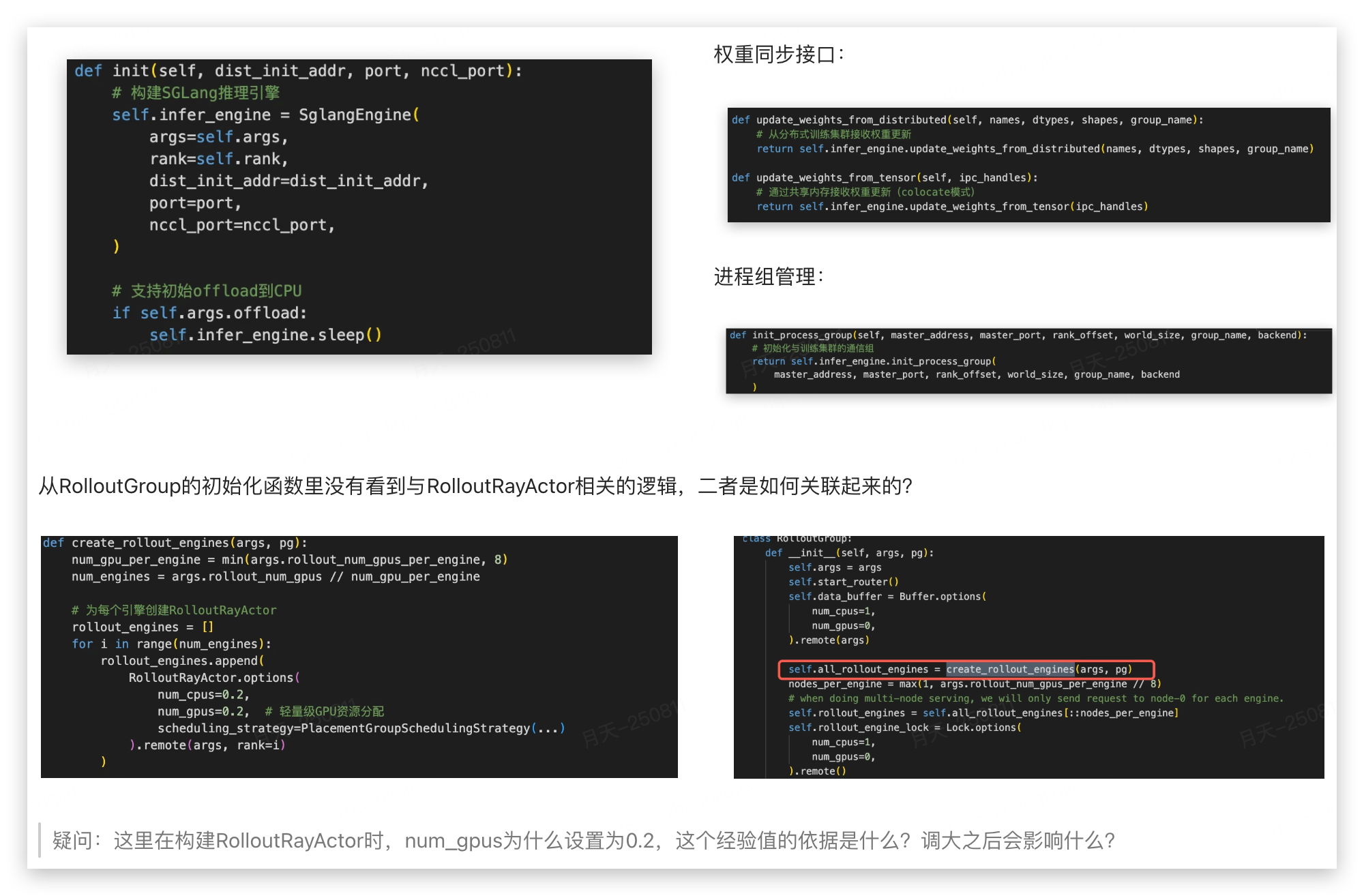
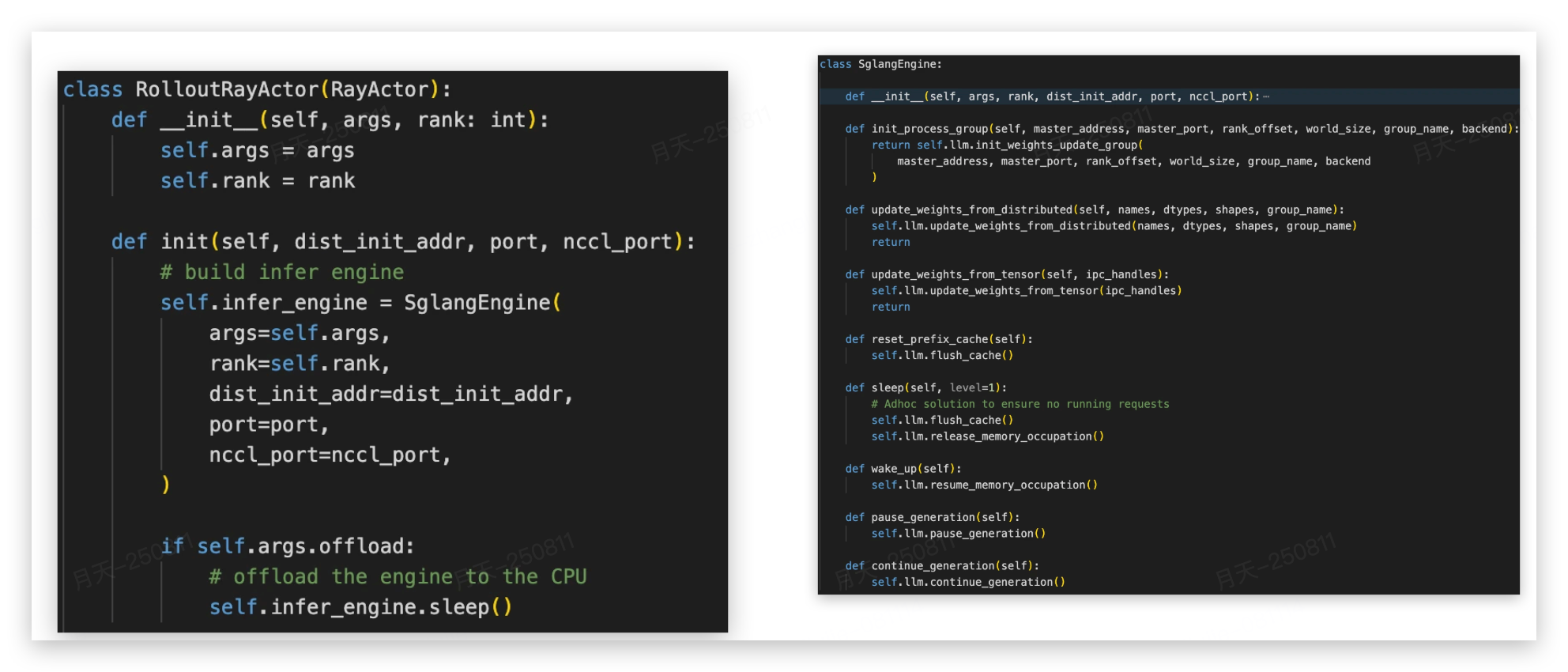
3.2 RolloutRayActor
RolloutRayActor是一个Ray远程Actor,代表单个SGLang推理引擎,提供了几个重要接口:
- sleep 和 wake_up(这里没有实现细粒度wake_up么?)
- pause_generation 和 continue_generation(没有返回值,怎么跟data buffer 交互的?)
4. 数据处理
大致了解了Train和Rollout 组件后面,我们从DataFlow的角度,来看下二者是怎么串联起来的。
TrainGroup.async_train() → RayActor.train() → RayActor().get_rollout_data() →data_buffer.get_data()← set_data()←generate()

5. 扩展功能
5.1 Backend
Slime 为了后续能够更灵活地扩展诸如FSDP/vLLM 训推后端,设计上约定了统一的抽象类和抽象接口
但在推理维度,slime 只实现了 RolloutRayActor,通过持有不同的infer_engine 对象来接入不同的推理后端,这一点与训练的多backend 有区别(感觉是没有来得及完全规范化模块设计。)
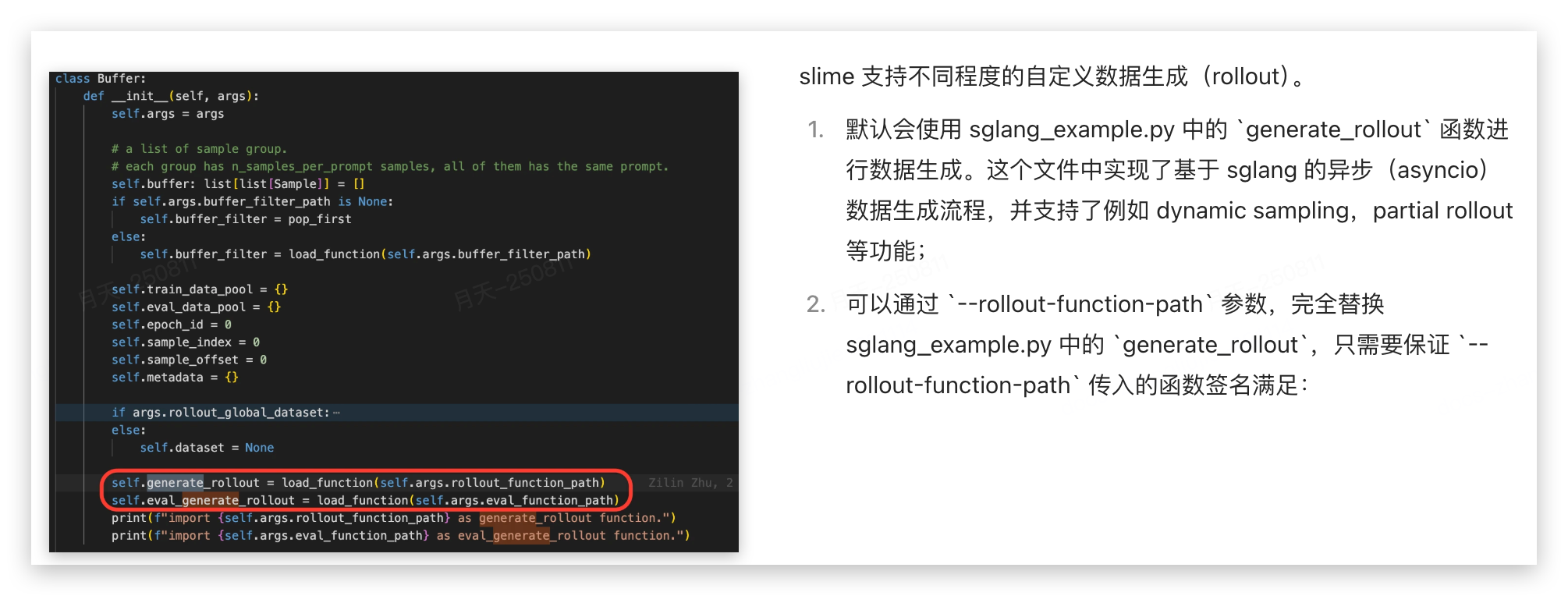
5.2 数据处理
RL 算法同学修改最多的模块,一个是reward,另一个则是数据的处理。前面在 Buffer 类我们知道 Rollout 是通过generate_out函数来路由的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号