我发现很多程序员都不会打日志。。。
我发现很多程序员都不会打日志。。。
你是小阿巴,刚入职的低级程序员,正在开发一个批量导入数据的程序。
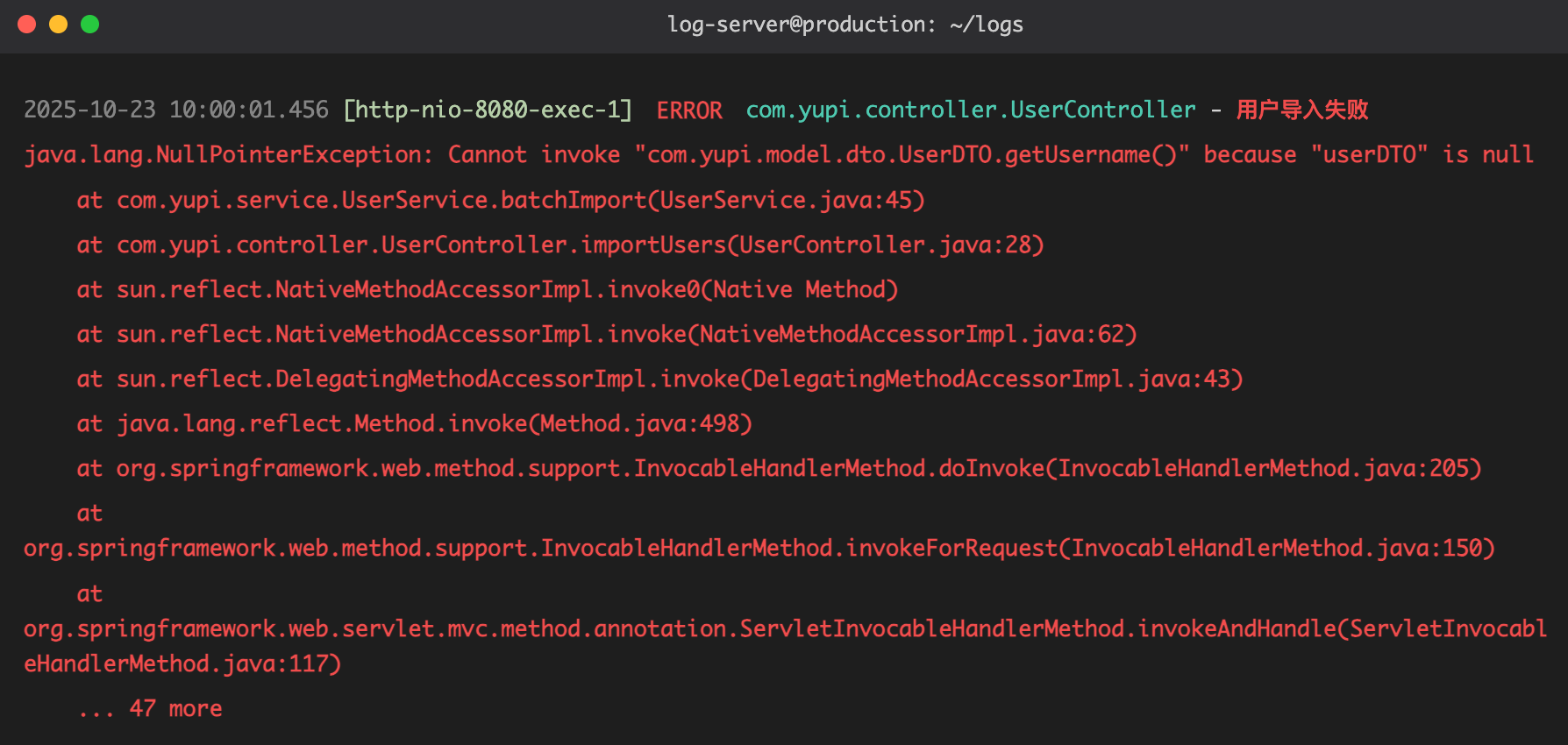
没想到,程序刚上线,产品经理就跑过来说:小阿巴,用户反馈你的程序有 Bug,刚导入没多久就报错中断了!
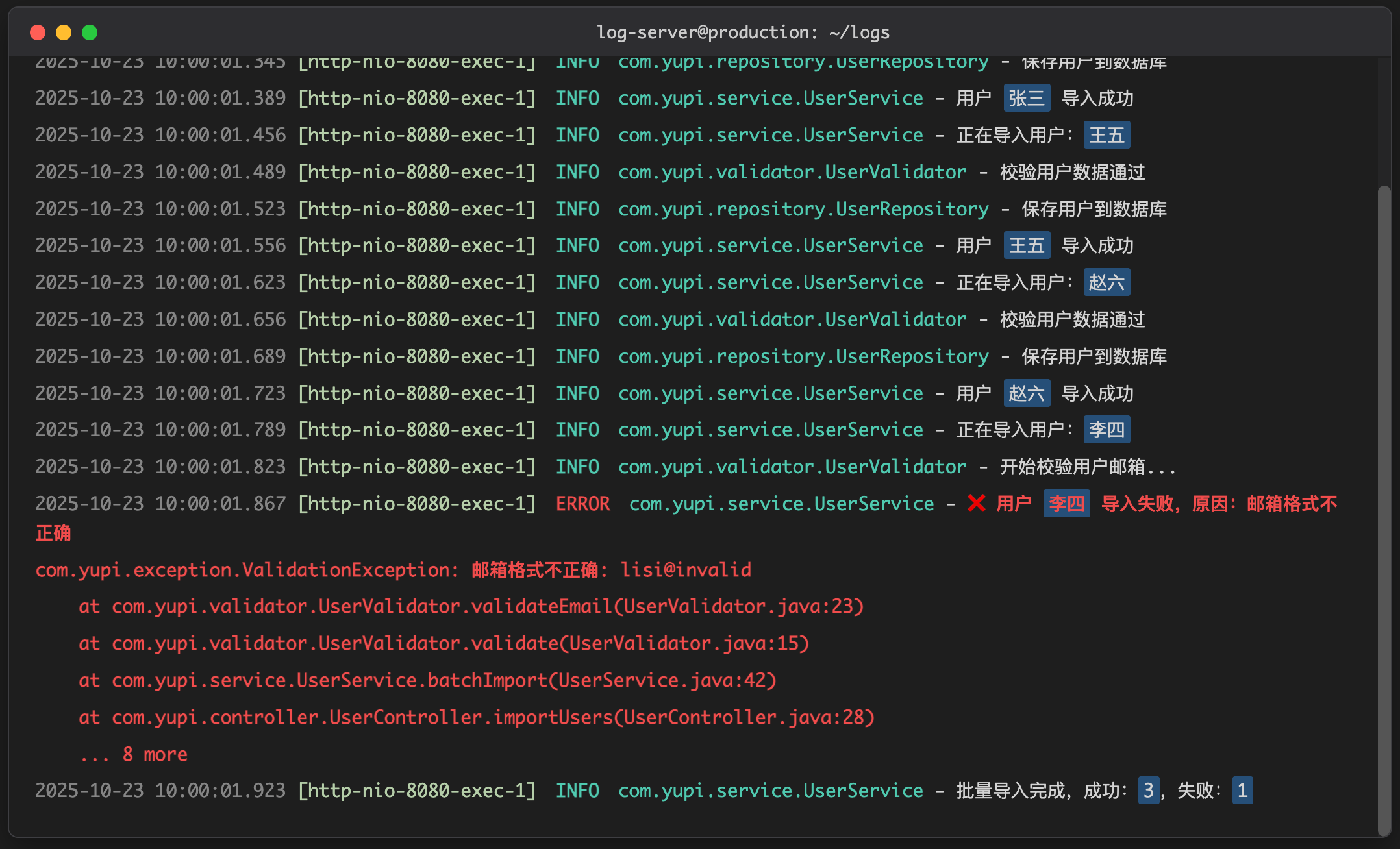
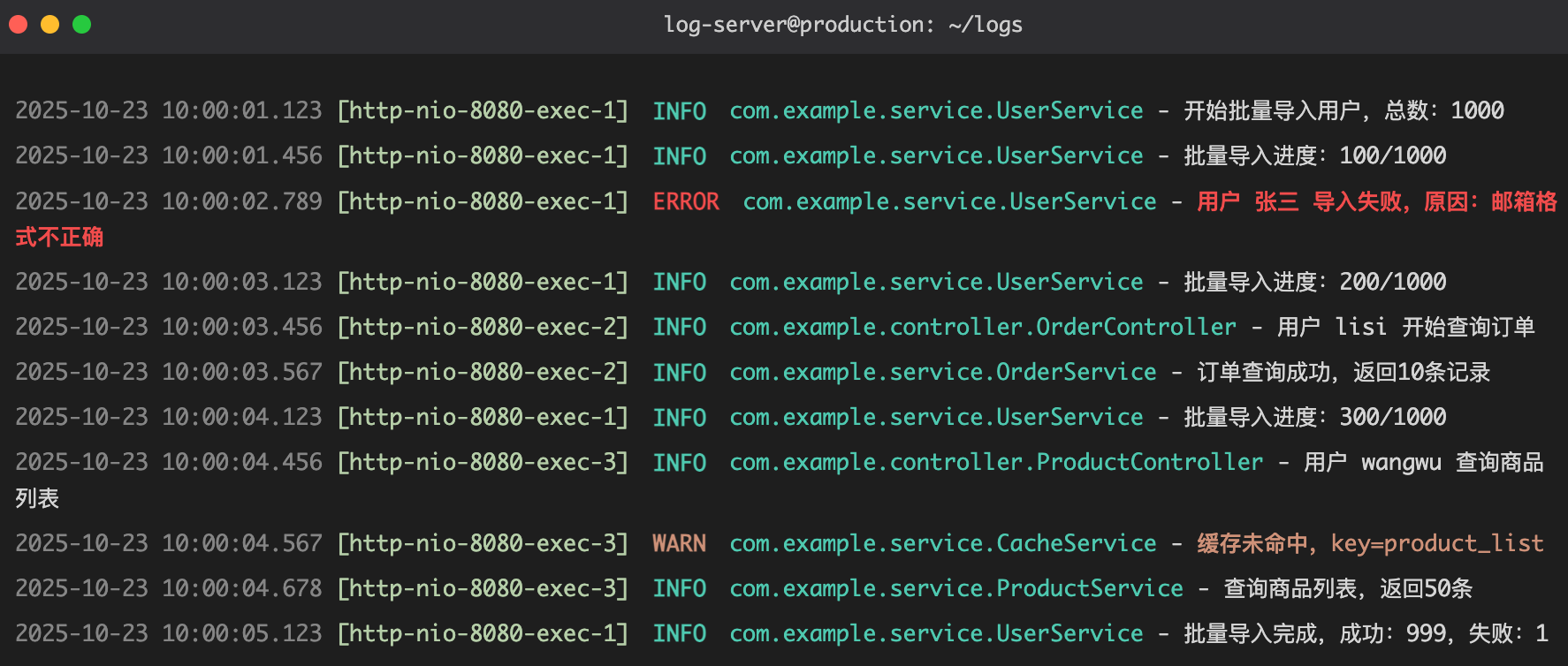
你赶紧打开服务器,看着比你发量都少的报错信息:

你一脸懵逼:只有这点儿信息,我咋知道哪里出了问题啊?!
你只能硬着头皮让产品经理找用户要数据,然后一条条测试,看看是哪条数据出了问题……
原本大好的摸鱼时光,就这样无了。
这时,你的导师鱼皮走了过来,问道:小阿巴,你是持矢了么?脸色这么难看?

你无奈地说:皮哥,刚才线上出了个 bug,我花了 8 个小时才定位到问题……
鱼皮皱了皱眉:这么久?你没打日志吗?
你很是疑惑:谁是日志?为什么要打它?

鱼皮叹了口气:唉,难怪你要花这么久…… 来,我教你打日志!
⭐️ 本文对应视频版:
什么是日志?
鱼皮打开电脑,给你看了一段代码:
@Slf4j
public class UserService {
public void batchImport(List<UserDTO> userList) {
log.info("开始批量导入用户,总数:{}", userList.size());
int successCount = 0;
int failCount = 0;
for (UserDTO userDTO : userList) {
try {
log.info("正在导入用户:{}", userDTO.getUsername());
validateUser(userDTO);
saveUser(userDTO);
successCount++;
log.info("用户 {} 导入成功", userDTO.getUsername());
} catch (Exception e) {
failCount++;
log.error("用户 {} 导入失败,原因:{}", userDTO.getUsername(), e.getMessage(), e);
}
}
log.info("批量导入完成,成功:{},失败:{}", successCount, failCount);
}
}你看着代码里的 log.info、log.error,疑惑地问:这些 log 是干什么的?
鱼皮:这就是打日志。日志用来记录程序运行时的状态和信息,这样当系统出现问题时,我们可以通过日志快速定位问题。
你若有所思:哦?还可以这样!如果当初我的代码里有这些日志,一眼就定位到问题了…… 那我应该怎么打日志?用什么技术呢?
怎么打日志?
鱼皮:每种编程语言都有很多日志框架和工具库,比如 Java 可以选用 Log4j 2、Logback 等等。咱们公司用的是 Spring Boot,它默认集成了 Logback 日志框架,你直接用就行,不用再引入额外的库了~

日志框架的使用非常简单,先获取到 Logger 日志对象。
1)方法 1:通过 LoggerFactory 手动获取 Logger 日志对象:
public class MyService {
private static final Logger logger = LoggerFactory.getLogger(MyService.class);
}2)方法 2:使用 this.getClass 获取当前类的类型,来创建 Logger 对象:
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
}然后调用 logger.xxx(比如 logger.info)就能输出日志了。
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void doSomething() {
logger.info("执行了一些操作");
}
}效果如图:

小阿巴:啊,每个需要打日志的类都要加上这行代码么?
鱼皮:还有更简单的方式,使用 Lombok 工具库提供的 @Slf4j 注解,可以自动为当前类生成日志对象,不用手动定义啦。
@Slf4j
public class MyService {
public void doSomething() {
log.info("执行了一些操作");
}
}上面的代码等同于 “自动为当前类生成日志对象”:
private static final org.slf4j.Logger log =
org.slf4j.LoggerFactory.getLogger(MyService.class);
你咧嘴一笑:这个好,爽爽爽!

等等,不对,我直接用 Java 自带的 System.out.println 不也能输出信息么?何必多此一举?
System.out.println("开始导入用户" + user.getUsername());
鱼皮摇了摇头:千万别这么干!
首先,System.out.println 是一个同步方法,每次调用都会导致耗时的 I/O 操作,频繁调用会影响程序的性能。

而且它只能输出信息到控制台,不能灵活控制输出位置、输出格式、输出时机等等。比如你现在想看三天前的日志,System.out.println 的输出早就被刷没了,你还得浪费时间找半天。

你恍然大悟:原来如此!那使用日志框架就能解决这些问题吗?
鱼皮点点头:没错,日志框架提供了丰富的打日志方法,还可以通过修改日志配置文件来随心所欲地调教日志,比如把日志同时输出到控制台和文件中、设置日志格式、控制日志级别等等。
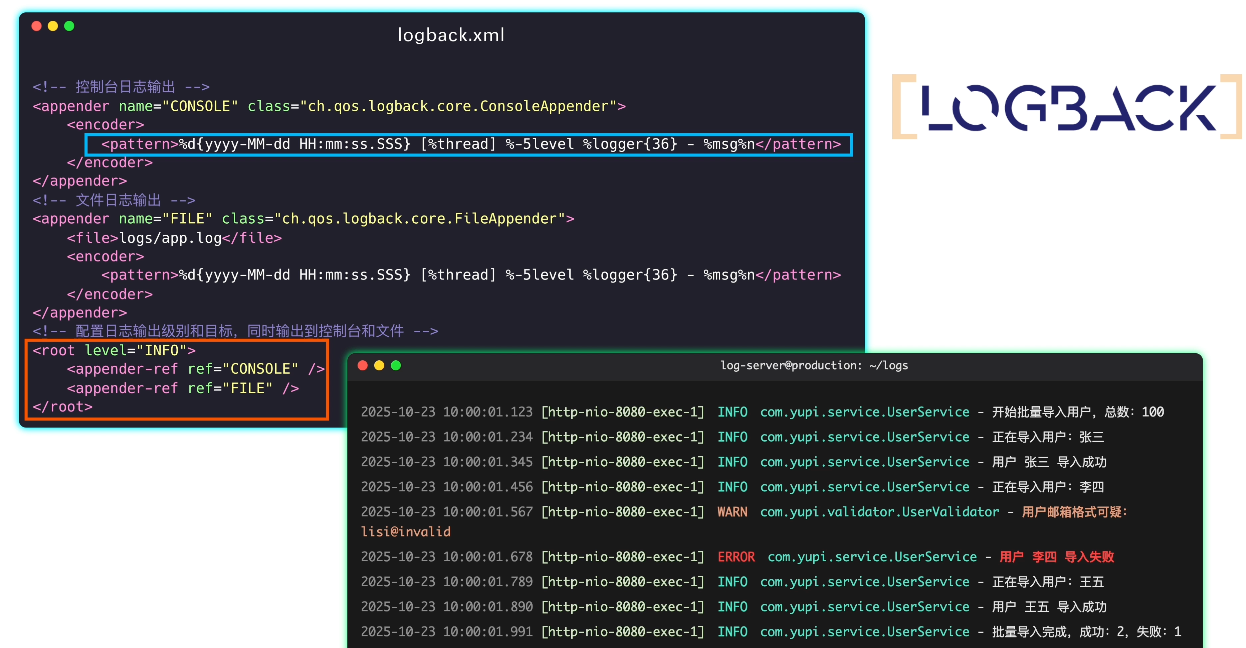
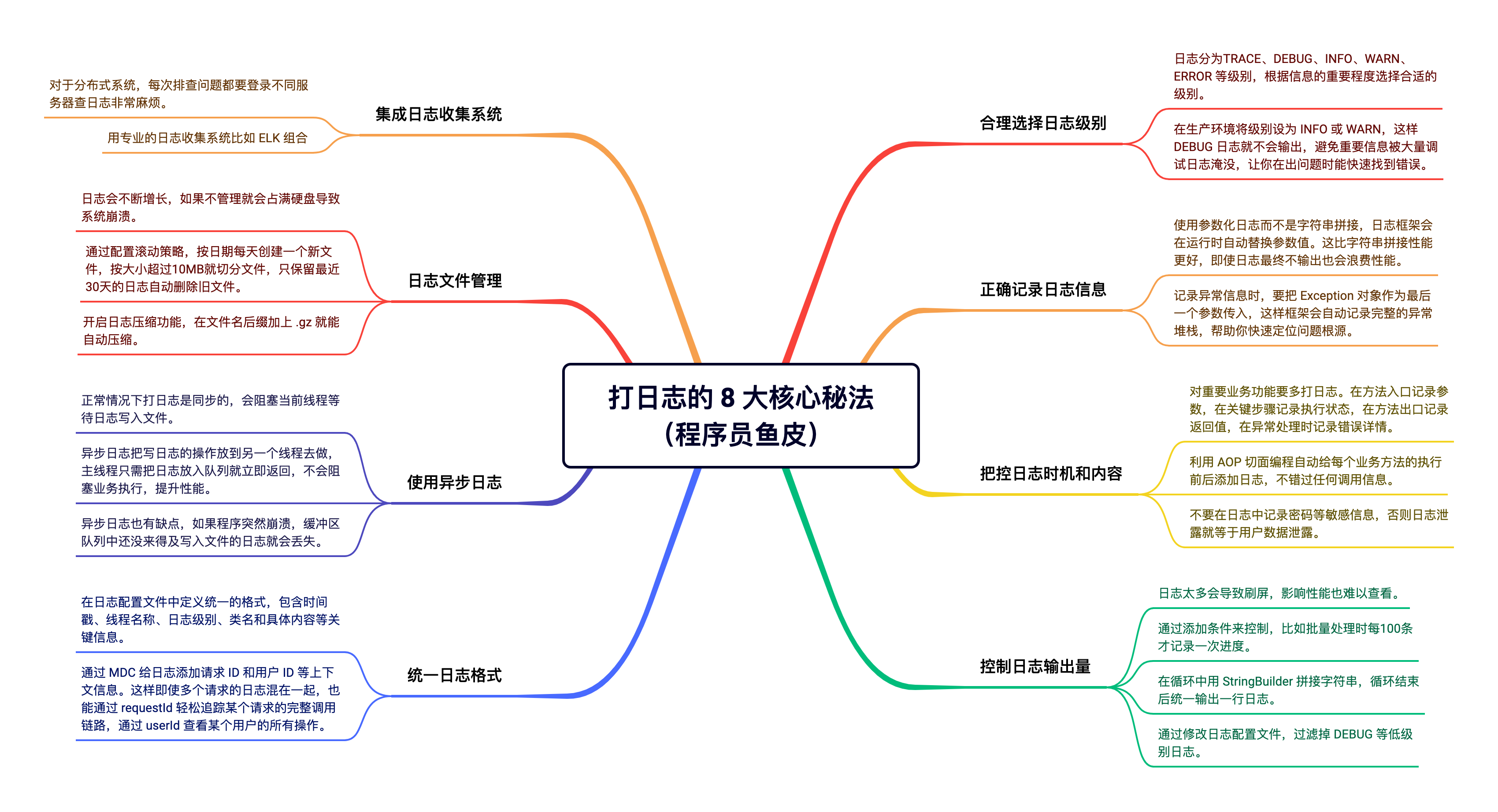
在下苦心研究日志多年,沉淀了打日志的 8 大邪修秘法,先传授你 2 招最基础的吧。
打日志的 8 大最佳实践
1、合理选择日志级别
第一招,日志分级。
你好奇道:日志还有级别?苹果日志、安卓日志?
鱼皮给了你一巴掌:可不要乱说,日志的级别是按照重要程度进行划分的。

其中 DEBUG、INFO、WARN 和 ERROR 用的最多。
-
调试用的详细信息用 DEBUG
-
正常的业务流程用 INFO
-
可能有问题但不影响主流程的用 WARN
-
出现异常或错误的用 ERROR
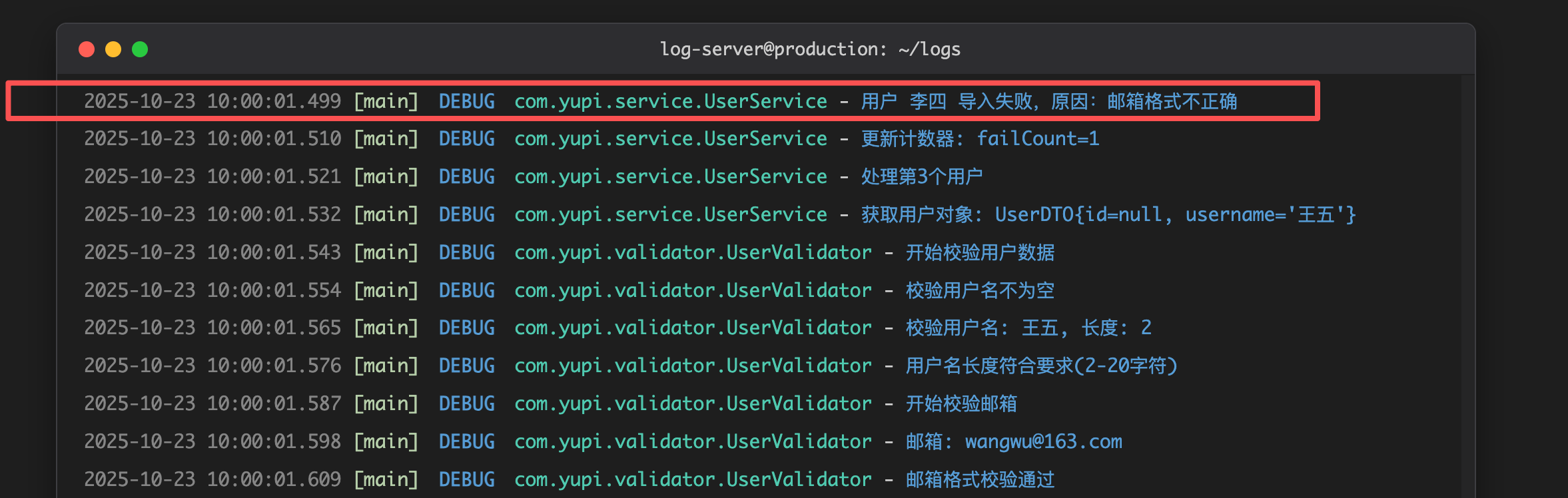
log.debug("用户对象的详细信息:{}", userDTO); // 调试信息
log.info("用户 {} 开始导入", username); // 正常流程信息
log.warn("用户 {} 的邮箱格式可疑,但仍然导入", username); // 警告信息
log.error("用户 {} 导入失败", username, e); // 错误信息
你挠了挠头:俺直接全用 DEBUG 不行么?
鱼皮摇了摇头:如果所有信息都用同一级别,那出了问题时,你怎么快速找到错误信息?
在生产环境,我们通常会把日志级别调高(比如 INFO 或 WARN),这样 DEBUG 级别的日志就不会输出了,防止重要信息被无用日志淹没。
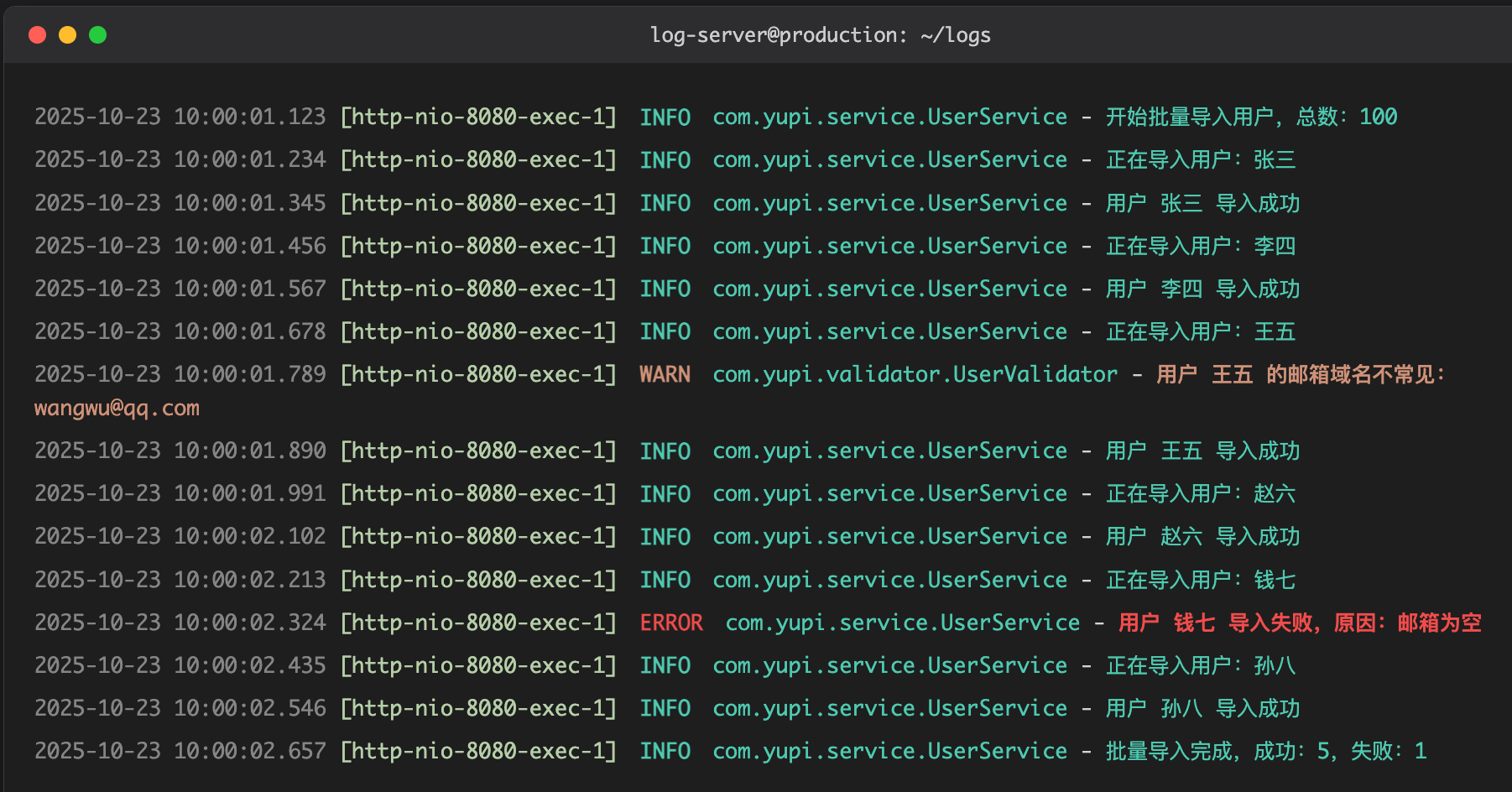
你点点头:俺明白了,不同的场景用不同的级别!
2、正确记录日志信息
鱼皮:没错,下面教你第二招。你注意到我刚才写的日志里有一对大括号 {} 吗?
log.info("用户 {} 开始导入", username);你回忆了一下:对哦,那是啥啊?
鱼皮:这叫参数化日志。{} 是一个占位符,日志框架会在运行时自动把后面的参数值替换进去。
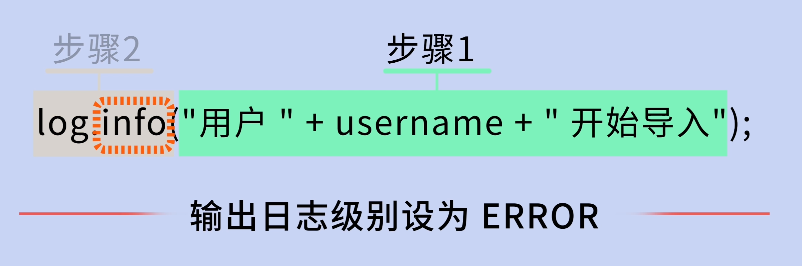
你挠了挠头:我直接用字符串拼接不行吗?
log.info("用户 " + username + " 开始导入");鱼皮摇摇头:不推荐。因为字符串拼接是在调用 log 方法之前就执行的,即使这条日志最终不被输出,字符串拼接操作还是会执行,白白浪费性能。
你点点头:确实,而且参数化日志比字符串拼接看起来舒服~

鱼皮:没错。而且当你要输出异常信息时,也可以使用参数化日志:
try {
// 业务逻辑
} catch (Exception e) {
log.error("用户 {} 导入失败", username, e); // 注意这个 e
}这样日志框架会同时记录上下文信息和完整的异常堆栈信息,便于排查问题。
你抱拳:学会了,我这就去打日志!
3、把控时机和内容
很快,你给批量导入程序的代码加上了日志:
@Slf4j
public class UserService {
public BatchImportResult batchImport(List<UserDTO> userList) {
log.info("开始批量导入用户,总数:{}", userList.size());
int successCount = 0;
int failCount = 0;
for (UserDTO userDTO : userList) {
try {
log.info("正在导入用户:{}", userDTO.getUsername());
// 校验用户名
if (StringUtils.isBlank(userDTO.getUsername())) {
throw new BusinessException("用户名不能为空");
}
// 保存用户
saveUser(userDTO);
successCount++;
log.info("用户 {} 导入成功", userDTO.getUsername());
} catch (Exception e) {
failCount++;
log.error("用户 {} 导入失败,原因:{}", userDTO.getUsername(), e.getMessage(), e);
}
}
log.info("批量导入完成,成功:{},失败:{}", successCount, failCount);
return new BatchImportResult(successCount, failCount);
}
}
光做这点还不够,你还翻出了之前的屎山代码,想给每个文件都打打日志。
但打着打着,你就不耐烦了:每段代码都要打日志,好累啊!但是不打日志又怕出问题,怎么办才好?
鱼皮笑道:好问题,这就是我要教你的第三招 —— 把握打日志的时机。
对于重要的业务功能,我建议采用防御性编程,先多多打日志。比如在方法代码的入口和出口记录参数和返回值、在每个关键步骤记录执行状态,而不是等出了问题无法排查的时候才追悔莫及。之后可以再慢慢移除掉不需要的日志。

你叹了口气:这我知道,但每个方法都打日志,工作量太大,都影响我摸鱼了!
鱼皮:别担心,你可以利用 AOP 切面编程,自动给每个业务方法的执行前后添加日志,这样就不会错过任何一次调用信息了。

你双眼放光:这个好,爽爽爽!

鱼皮:不过这样做也有一个缺点,注意不要在日志中记录了敏感信息,比如用户密码。万一你的日志不小心泄露出去,就相当于泄露了大量用户的信息。
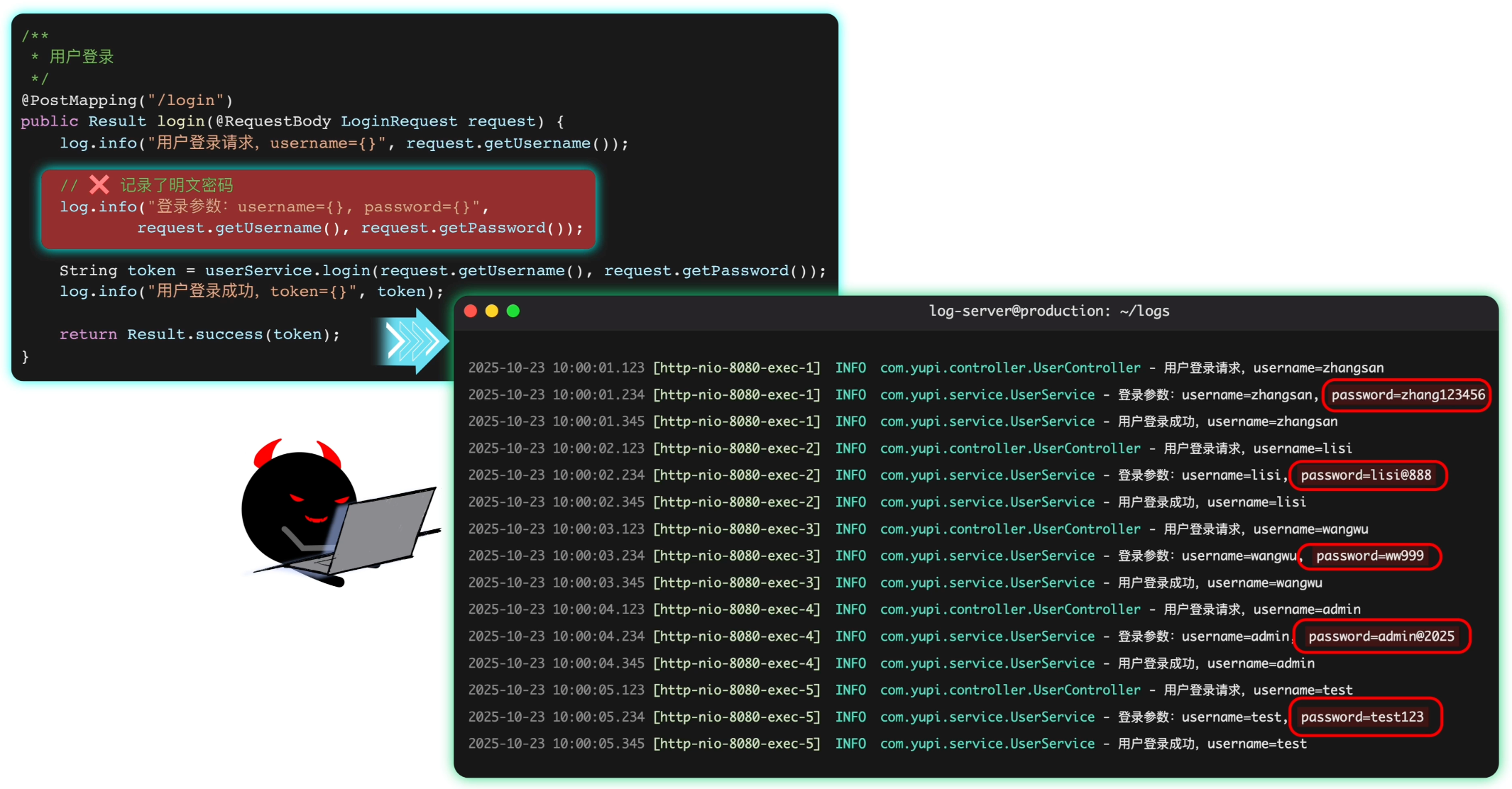
你拍拍胸脯:必须的!
4、控制日志输出量
一个星期后,产品经理又来找你了:小阿巴,你的批量导入功能又报错啦!而且怎么感觉程序变慢了?
你完全不慌,淡定地打开服务器的日志文件。结果瞬间呆住了……
好家伙,满屏都是密密麻麻的日志,这可怎么看啊?!

鱼皮看了看你的代码,摇了摇头:你现在每导入一条数据都要打一些日志,如果用户导入 10 万条数据,那就是几十万条日志!不仅刷屏,还会影响性能。
你有点委屈:不是你让我多打日志的么?那我应该怎么办?
鱼皮:你需要控制日志的输出量。
1)可以添加条件来控制,比如每处理 100 条数据时才记录一次:
if ((i + 1) % 100 == 0) {
log.info("批量导入进度:{}/{}", i + 1, userList.size());
}2)或者在循环中利用 StringBuilder 进行字符串拼接,循环结束后统一输出:
StringBuilder logBuilder = new StringBuilder("处理结果:");
for (UserDTO userDTO : userList) {
processUser(userDTO);
logBuilder.append(String.format("成功[ID=%s], ", userDTO.getId()));
}
log.info(logBuilder.toString());3)还可以通过修改日志配置文件,过滤掉特定级别的日志,防止日志刷屏:
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>logs/app.log</file>
<!-- 只允许 INFO 级别及以上的日志通过 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
</appender>
5、统一日志格式
你开心了:好耶,这样就不会刷屏了!但是感觉有时候日志很杂很乱,尤其是我想看某一个请求相关的日志时,总是被其他的日志干扰,怎么办?
鱼皮:好问题,可以在日志配置文件中定义统一的日志格式,包含时间戳、线程名称、日志级别、类名、方法名、具体内容等关键信息。
<!-- 控制台日志输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 日志格式 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>这样输出的日志更整齐易读:
此外,你还可以通过 MDC(Mapped Diagnostic Context)给日志添加额外的上下文信息,比如请求 ID、用户 ID 等,方便追踪。
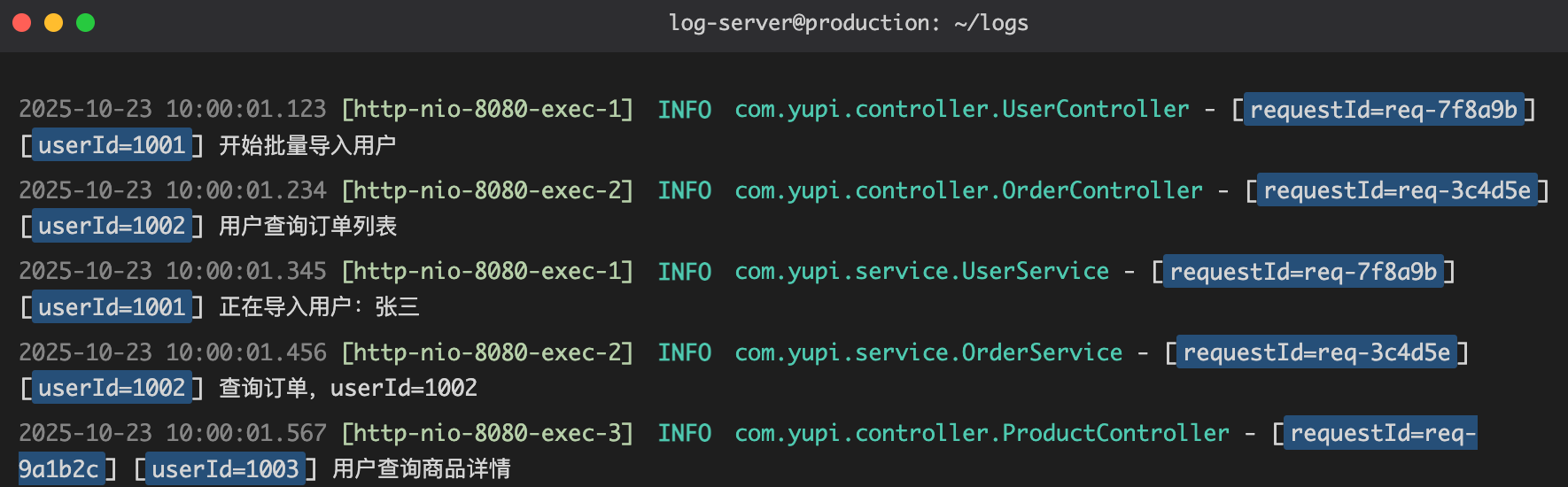
在 Java 代码中,可以为 MDC 设置属性值:
@PostMapping("/user/import")
public Result importUsers(@RequestBody UserImportRequest request) {
// 1. 设置 MDC 上下文信息
MDC.put("requestId", generateRequestId());
MDC.put("userId", String.valueOf(request.getUserId()));
try {
log.info("用户请求处理完成");
// 执行具体业务逻辑
userService.batchImport(request.getUserList());
return Result.success();
} finally {
// 2. 及时清理MDC(重要!)
MDC.clear();
}
}然后在日志配置文件中就可以使用这些值了:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<!-- 包含 MDC 信息 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [%X{requestId}] [%X{userId}] %msg%n</pattern>
</encoder>
</appender>这样,每个请求、每个用户的操作一目了然。
6、使用异步日志
你又开心了:这样打出来的日志,确实舒服,爽爽爽!但是我打日志越多,是不是程序就会更慢呢?有没有办法能优化一下?
鱼皮:当然有,可以使用 异步日志。
正常情况下,你调用 log.info() 打日志时,程序会立刻把日志写入文件,这个过程是同步的,会阻塞当前线程。而异步日志会把写日志的操作放到另一个线程里去做,不会阻塞主线程,性能更好。
你眼睛一亮:这么厉害?怎么开启?
鱼皮:很简单,只需要修改一下配置文件:
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>512</queueSize> <!-- 队列大小 -->
<discardingThreshold>0</discardingThreshold> <!-- 丢弃阈值,0 表示不丢弃 -->
<neverBlock>false</neverBlock> <!-- 队列满时是否阻塞,false 表示会阻塞 -->
<appender-ref ref="FILE" /> <!-- 引用实际的日志输出目标 -->
</appender>
<root level="INFO">
<appender-ref ref="ASYNC" />
</root>不过异步日志也有缺点,如果程序突然崩溃,缓冲区中还没来得及写入文件的日志可能会丢失。

所以要权衡一下,看你的系统更注重性能还是日志的完整性。
你想了想:我们的程序对性能要求比较高,偶尔丢几条日志问题不大,那我就用异步日志吧。
7、日志管理
接下来的很长一段时间,你混的很舒服,有 Bug 都能很快发现。
你甚至觉得 Bug 太少、工作没什么激情,所以没事儿就跟新来的实习生阿坤吹吹牛皮:你知道日志么?我可会打它了!

直到有一天,运维小哥突然跑过来:阿巴阿巴,服务器挂了!你快去看看!
你连忙登录服务器,发现服务器的硬盘爆满了,没法写入新数据。
你查了一下,发现日志文件竟然占了 200GB 的空间!
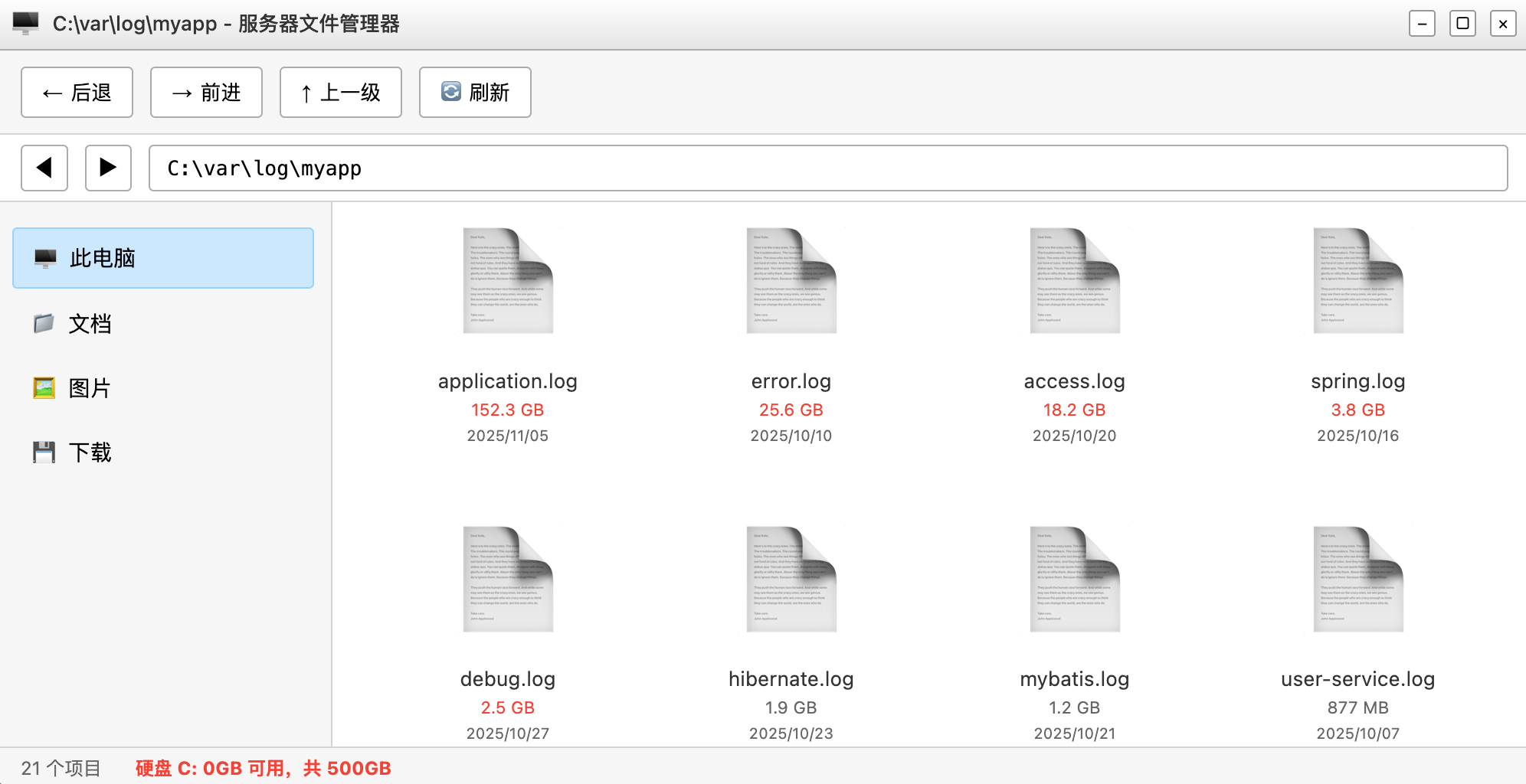
你汗流浃背了,正在考虑怎么甩锅,结果阿坤突然鸡叫起来:阿巴 giegie,你的日志文件是不是从来没清理过?
你尴尬地倒了个立,这样眼泪就不会留下来。

鱼皮叹了口气:这就是我要教你的下一招 —— 日志管理。
你好奇道:怎么管理?我每天登服务器删掉一些历史文件?
鱼皮:人工操作也太麻烦了,我们可以通过修改日志配置文件,让框架帮忙管理日志。
首先设置日志的滚动策略,可以根据文件大小和日期,自动对日志文件进行切分。
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>10MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>这样配置后,每天会创建一个新的日志文件(比如 app-2025-10-23.0.log),如果日志文件大小超过 10MB 就再创建一个(比如 app-2025-10-23.1.log),并且只保留最近 30 天的日志。
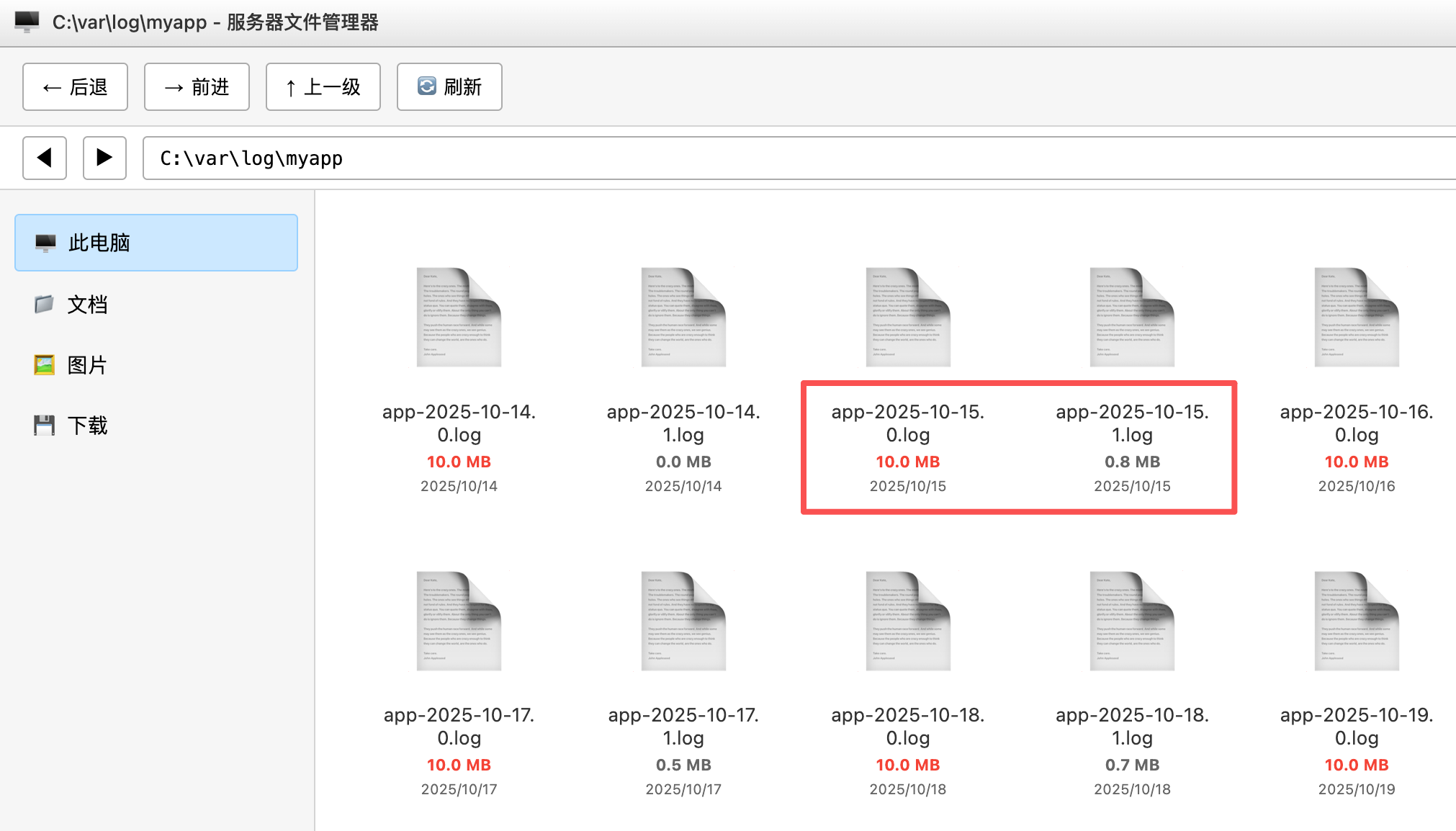
还可以开启日志压缩功能,进一步节省磁盘空间:
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- .gz 后缀会自动压缩 -->
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log.gz</fileNamePattern>
</rollingPolicy>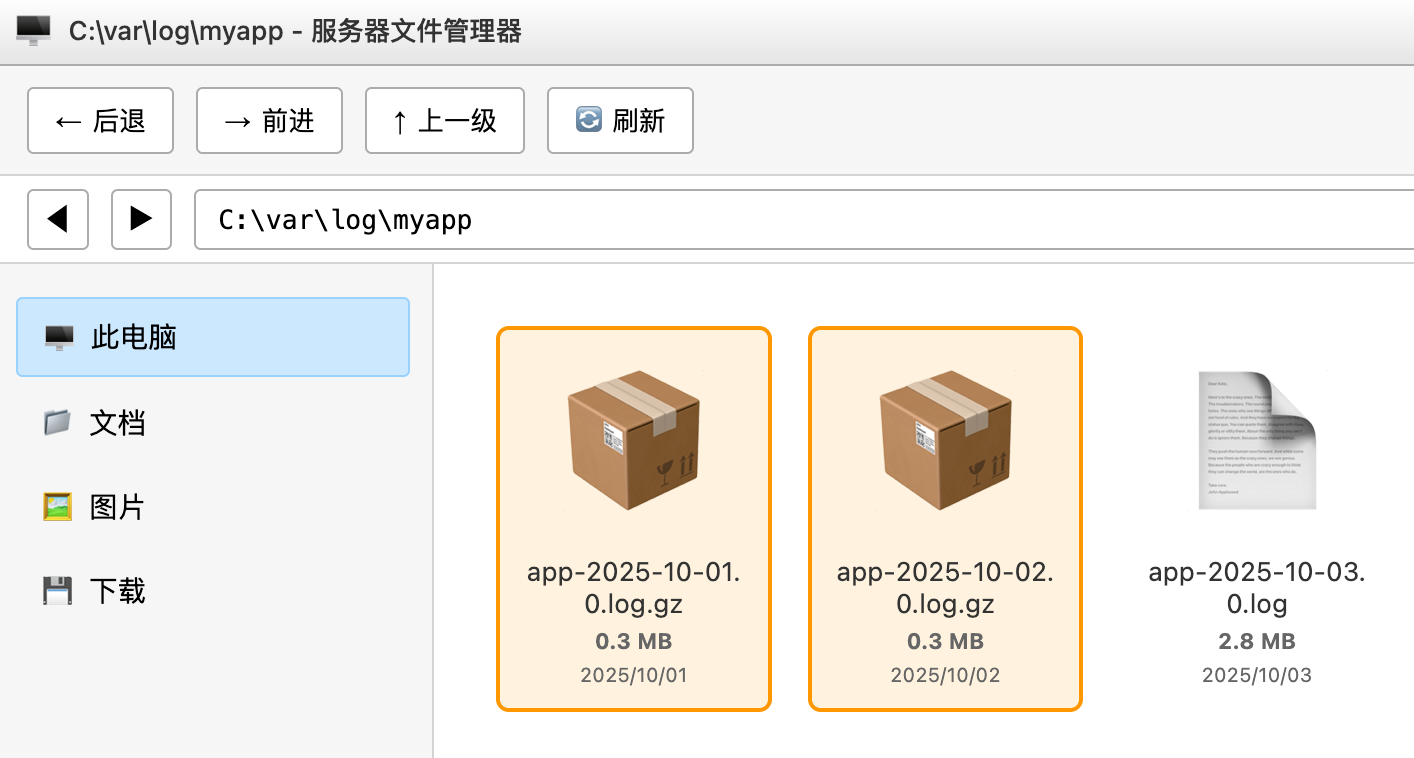
你有些激动:吼吼,这样我们就可以按照天数更快地查看日志,服务器硬盘也有救啦!
8、集成日志收集系统
两年后,你负责的项目已经发展成了一个大型的分布式系统,有好几十个微服务。
如今,每次排查问题你都要登录到不同的服务器上查看日志,非常麻烦。而且有些请求的调用链路很长,你得登录好几台服务器、看好几个服务的日志,才能追踪到一个请求的完整调用过程。

你简直要疯了!
于是你找到鱼皮求助:现在查日志太麻烦了,当年你还有一招没有教我,现在是不是……
鱼皮点点头:嗯,对于分布式系统,就必须要用专业的日志收集系统了,比如很流行的 ELK。
你好奇:ELK 是啥?伊拉克?
阿坤抢答道:我知道,就是 Elasticsearch + Logstash + Kibana 这套组合。
简单来说,Logstash 负责收集各个服务的日志,然后发送给 Elasticsearch 存储和索引,最后通过 Kibana 提供一个可视化的界面。
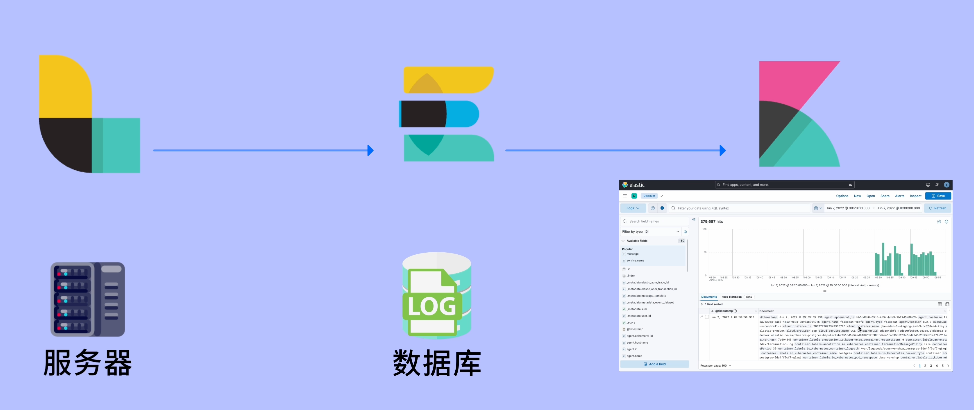
这样一来,我们可以方便地集中搜索、查看、分析日志。
你惊讶了:原来日志还能这么玩,以后我所有的项目都要用 ELK!
鱼皮摆摆手:不过 ELK 的搭建和运维成本比较高,对于小团队来说可能有点重,还是要按需采用啊。
结局
至此,你已经掌握了打日志的核心秘法。
只是你很疑惑,为何那阿坤竟对日志系统如此熟悉?
阿坤苦笑道:我本来就是日志管理大师,可惜我上家公司的同事从来不打日志,所以我把他们暴打了一顿后跑路了。
阿巴 giegie 你要记住,日志不是写给机器看的,是写给未来的你和你的队友看的!
你要是以后不打日志,我就打你!
更多编程学习资源
你打的日志,正在拖垮你的系统:从P4小白到P7专家都是怎么打日志的?
老A的代码茶座 vol.1
大家好,我是老A。
国庆假期的某天,我正懒洋洋地躺在海滩的沙滩椅上,哈着冰啤酒,海风拂面,惬意极了。
突然,手机震动个不停。点开一看,是公司告警群里接连蹦出几条「磁盘空间不足」的告警消息。虽然这不是我负责的应用,但我还是好奇地戳进去瞄了一眼。原来是日志文件膨胀得太猛,把磁盘给塞满了。没多久,负责的同事在群里发话:“这日志文件忘了挂载运维平台的自动清理脚本了。”他手动删掉一些旧日志,磁盘占用瞬间恢复正常。
这事儿让我不由得陷入了沉思。打日志,看似程序员日常中最不起眼的小事 —— 后端、前端、客户端,谁不是天天在打?但稍有不慎,轻则导致磁盘占用飙升,重则在线上故障时因为缺失关键日志而束手无策。明明是基础操作,却常常被忽略。从这个磁盘告警就能看出来,就连大厂里不少人,也没把打日志这件“小事”当回事儿。这本质上是一种认知偏差:小事不处理,往往酿成大事。
所以,今天咱们就来聊聊这个每个程序员每天都在做,但90%的人都没做对的事——打日志。把我从坑里爬出来的经验,分享给你,避免你重蹈覆辙。
第一幕:小白打日志的那些坑
说起打日志的坑,我和身边的同事们可谓是身经百战,基本上把能踩的都踩了个遍。尤其是那些刚入职的P4小白,日志打得那叫一个随性,结果往往是自食苦果。
先说第一个经典坑:日志打了个寂寞。
之前有个供应链团队的合作同事,刚校招入职,化名小张吧。我们因为项目合作频繁,关系不错,他经常来找我讨教技术问题。
有一次,他遇到一个线上偶发Bug,用户反馈操作失败。他急吼吼地跑来求助:“A哥,我在SLS里翻了半天,只有一句‘order process error!’,根本不知道是哪个用户、哪笔订单、在哪行代码出的错!这Bug没法复现,告警也没触发,日志没线索,咋办啊?”
我让他把出问题的代码发给我瞧瞧。瞄了几眼瞬间明白了:他的问题不是Bug难复现,而是就算复现了,这日志也没卵用。代码大致是这样(伪代码,展示日志打印的问题):
@Service
public class OrderService {
public void processOrder(OrderDTO order) {
try {
// ...此处省略50行业务逻辑...
// 问题实际在这里:在某种边界条件下,order.getCustomer()可能返回null,导致NPE
String customerName = order.getCustomer().getName();
log.info("OrderService start process order..."); // 这行日志没打任何关键信息
// ...此处省略另外50行业务逻辑...
} catch (Exception e) {
// 日志打了个寂寞。。。
log.error("OrderService#order process error!");
}
}
}大家仔细品品这段代码里的日志,相信不少新人都会心有戚戚焉。这里面藏着小白门常见的三大问题:
问题一:异常被莫名其妙地吃掉
看看catch块里,那个至关重要的Exception呢?直接被吃了!连完整的堆栈信息都不打印,也没有向上抛出,就这么被“吃干抹净”,不留痕迹。这就好比侦探赶到犯罪现场,发现一切证据都被擦得干干净净,还怎么破案?
问题二:没有任何关键信息
“OrderService#order process error!”——这是啥意思?哪个订单?哪个用户?哪个商品?日志里一个业务ID都没带。每秒钟成千上万笔订单涌入,这样的日志无异于大海捞针,纯纯浪费时间。
问题三:异常信息没有体现在日志中
error——到底是什么error?是NPE?数据库连接超时?还是RPC异常?一无所知。
最后,我叹了口气:“Bro,你的问题不是Bug无法复现,而是就算复现了,你这日志也定位不到问题。你这日志打了个寂寞啊”
第二幕:打日志的“三层境界”
是不是在小张身上看到了自己曾经的影子呢?你有思考过如何打日志这个问题吗?其实这里面还是有一些学问的。
在大厂这么多年,我总结出了打日志的“三层境界”,从P4小白到P7专家,每一级都有对应的行为特征和潜在“B面”灾难。咱们一层一层扒开,看看你处在哪一境界。
第一境:P4小白 —— 日志 = “到此一游”的涂鸦
行为特征:
- 万物皆可用System.out.println()或e.printStackTrace()。
- 日志内容随心所欲,比如log.info("111"), log.info("走到这里了")。
- 热衷于用字符串拼接("value=" + var)来构建日志消息。
潜在的“B面”灾难:
- 性能杀手:用字符串拼接,即使日志级别被禁用,也会强制执行字符串操作(浪费资源),在高并发下严重拖慢系统。
- 信息丢失:习惯性地丢掉异常,只打印e.getMessage()而不记录完整的堆栈跟踪,丢弃了最关键的异常信息。
- 毫无价值:无法关闭,无法分级,无法被集中式日志系统(如SLS)进行有效采集和分析。线上出事时,你只能干瞪眼。
第二境:P5中级 —— 日志 = “业务流水账”
P5级别的工程师,已经懂得封装Service,但处理异常的方式,也经常存在一些问题。来看小张的另一段代码示例:
@Service
public class OrderService {
public void createOrder(OrderDTO order) {
try {
// ...业务逻辑...
String userName = null;
userName.toLowerCase(); // 这里会一个NPE
} catch (Exception e) {
// 注意:这里没有打印日志,直接向上抛出一个模糊的异常
throw new BizException("创建订单失败");
}
}
}
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping("/orders")
public void createOrder(@RequestBody OrderDTO order) {
try {
orderService.createOrder(order);
} catch (BizException e) {
// 日志在这里打印,但没有实际异常的详细堆栈和信息
log.error("处理创建订单请求失败!", e);
}
}
}老A点评:
兄弟们,看懂了吗?当线上出问题时,你在Controller层看到的日志,只会告诉你创建订单失败,你无法知道问题的根因其实是OrderService第XX行那个NPE。这就是异常日志的二次转手,破案线索,在第一现场就被破坏了。
我至今都记得,有一次为了排查一个履约单的Bug,我和另一个同事,花了整整一个通宵,在几十万行日志里,去定位一个被这样二次转手过的NPE。那种感觉,才是真正的大海中捞针。
行为特征:
- 已经学会了使用日志门面(如SLF4J)和实现(如Logback),懂得INFO, WARN, ERROR的区别。
- 日志内容开始关注业务流程,比如log.info("用户下单成功,订单号:{}", orderId)。
潜在的“B面”灾难:
- 信息孤岛,无法定位问题:日志只能证明“这个方法被执行了”,但无法串联起一个完整的用户请求链路。一旦出问题,你看到的只是散落在几十台机器上的、毫无关联的日志碎片。
- 缺少关键上下文:日志里只有orderId,但没有trace_id或其他关键的信息。大型系统中如果缺少trace_id这样的关联ID,当一个用户反馈问题时,我们根本无法从海量日志中,找到属于他的那几条。
第三境:P6/P7专家 —— 日志 = 天网
行为特征:
专家打日志,追求的不是简单“记录”,而是“可观测性”和“可诊断性”。他们会让日志成为系统的“黑匣子”。
“B面”心法:
心法一:结构化一切
- What:不再打印纯文本,而是输出JSON格式的日志。
- Why:结构化的日志,才能被SLS、ELK等系统完美解析、索引和聚合查询。这样才能解答“过去一小时,service_name为payment-processor且user_id为123的所有ERROR日志”这类问题。
- How:例如,使用SLF4J + Logback,配合JSON Encoder:
log.error("{"event":"order_creation_failed", "order_id":"{}", "user_id":"{}", "error":"{}"}", orderId, userId, e.getMessage());老A说:别小看这个JSON。有次618,我们需要紧急统计
某个特定优惠券,在上海地区,因为库存不足而失败的下单次数。用文本日志,SRE需要花半小时写脚本去捞。用结构化日志,我在SLS上只用10秒钟,就给出了答案。 这,就是专家的效率。
心法二:上下文为王 (MDC & trace_id)
- What:MDC(Mapped Diagnostic Context)是Java中记录与线程相关的上下文的一种机制。底层使用ThreadLocal。通过 MDC,我们可以为当前线程附加一些特定的上下文信息(例如用户 ID、事务 ID),这些信息会自动与日志关联,从而帮我们更有效地分析和跟踪日志。
- Why:每条日志必须包含trace_id,用于追踪请求在多个微服务间的流转。MDC像线程的“专属背包”,在入口处放入trace_id,后续日志自动携带。
- How:在Interceptor中设置:
public class TraceInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String traceId = UUID.randomUUID().toString();
MDC.put("trace_id", traceId);
return true;
}
}然后日志中会自动带上trace_id:log.error("Order failed, orderId: {}", orderId); // 会隐含trace_id
老A说:
MDC就是线上排错的GPS。有一次,一个用户反馈他的账户余额显示异常。在没有trace_id的年代,我们需要去用户、交易、支付三个系统的几十台机器上,靠着userId和时间戳去人肉关联日志。
有了MDC,我只需要拿到一个trace_id,就能在SLS或ELK里,一键拉出这个用户从App点击到数据库落地的完整生命周期。 5分钟搞定。其实我们厂基本都用EagleEye,感兴趣的同学可以去搜搜。
心法三:日志本身就是“炸弹”
- What:日志打印不当,可能会引发大型故障。
- Why:举个栗子:Redis超时 → 海量错误日志 → 撑爆Logstash → 丢弃日志 → 关键线索丢失。这就是日志炸弹。
- How:别直接打印复杂对象,只打印关键ID和字段。高频事件用采样,如只记录1%的INFO日志(参考EagleEye的采样策略)。
老A说:别以为日志打多了没事。我亲眼见过一个P2故障,就是因为一个同事在
log.info里,打印了一个超大对象。高并发流量一来,光是这个toString()方法的开销,就把整个集群的CPU干到了95%以上,比业务逻辑本身还耗资源。 这是自杀式打日志。”
现在,针对第二境的坑,来看看P7专家的正确解法,:
@Service
public class OrderService {
public void createOrder(OrderDTO order) {
try {
// ...业务逻辑...
String userName = null;
userName.toLowerCase();
} catch (Exception e) {
// 正解:记录下最完整的错误和堆栈
log.error("创建订单核心逻辑发生异常!orderId: {}", order.getId(), e);
// 然后再向上抛出业务异常,通知上层调用失败
throw new BizException("创建订单失败", e); // 把原始异常作为cause传递
}
}
}老A点评: 同样是抛出异常,但专家在抛出前,先用一行log.error,把
包含了完整堆栈信息和关键业务ID(orderId)的第一手证据,牢牢地钉在了日志里。这,就是专业。
第三幕:宗师的视野——成熟日志系统的终极形态
在聊完打日志的三层境界后,我们不妨再往前走一步,思考一下 一个真正成熟的日志系统该是什么样子。
一个成熟的日志系统,不应该仅仅是记录信息的工具,而应该是整个系统可观测性的一个核心支柱。应该像一台精密的仪器,静静地运行,却能在关键时刻提供最有力的支持。 要达到这个目标,它必须具备三大核心能力。
能力一:跨系统的“全局透视”能力
在一个分布式架构中,我们面临的第一个挑战,就是信息孤岛。成熟的日志系统,首先要解决的就是看得全的问题。通过trace_id这根线索,将一个用户请求在几十个微服务之间的完整调用,串联成一条可视化的调用链路。就像阿里巴巴的EagleEye系统那样,它能让你在上帝视角,清晰地看到一个请求从前端到数据库的每一个环节,哪里卡壳、哪里高效,一目了然。
能力二:恰到好处的数据呈现能力
看得全,不等于信息越多越好。成熟的日志系统,追求的是恰到好处。
一方面,它的每一条日志,都采用结构化的JSON格式,只包含timestamp, trace_id, span_id, error_code等最关键的字段,做到清晰、完整却不冗余。
另一方面,它有完善的过期机制。通过基于时间(保留7天)或大小(超过1GB自动轮转)的过期策略,确保日志不会成为拖垮磁盘的定时炸弹——记得我们开头的那个告警故事吧?那就是反面教材。
能力三:“先知先觉”的自动化响应能力
看得全、看得清,最终是为了效率高。一个成熟的日志系统,应该是一个半自动化的哨兵。
当它通过trace_id发现某条链路的错误率超过阈值时,它能自动触发告警,通过钉钉通知到责任人。在更高级的系统中,它甚至应该能触发自动化的修复脚本——比如隔离故障节点、回滚配置。
这,才是日志的终点:从被动的记录员,进化为主动的系统守护神。
老A感悟:
一个工程师在日志层面的成长,就是从用日志记录,到用日志说话,再到用日志透视整个系统的过程。你打日志的水平,就是你对系统掌控能力的真实写照。
老A时间
感谢各位兄弟的阅读。
我是老A,一个只想跟你说点B面真话的师兄。如果这篇文章让你有了一点点启发,那就是对我最大的肯定。
为了感谢大家的支持,我把这两年在一线大厂面试和带团队中,沉淀下来的所有上不了台面的私房笔记,整理成了一份《程序员B面生存手册》。
里面没有市面上千篇一律的八股文,只有一些极其管用的“潜规则”和“避坑指南”,希望能帮你少走一些弯路。
关注我的同名公众号【大厂码农老A】,在后台回复“B面”,就能免费获取。
回复“简历”获取《简历优化手册》
回复“arthas”获取史上最全的《大厂arthas实战手册》
回复“指导”获取《外包镀金手册》
回复“日志”获取《技术专家日志打印秘籍》
最后,如果觉得内容还行,也希望能点个赞、点个在看,让更多需要它的兄弟看到。
我们一起,在技术的路上结伴“陪跑”。
链接:https://juejin.cn/post/7561077821995597876
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号