

我发现很多程序员都不会打日志。。。
 日志不是写给机器看的,是写给未来的你和你的队友看的!
日志不是写给机器看的,是写给未来的你和你的队友看的!
你是小阿巴,刚入职的低级程序员,正在开发一个批量导入数据的程序。
没想到,程序刚上线,产品经理就跑过来说:小阿巴,用户反馈你的程序有 Bug,刚导入没多久就报错中断了!
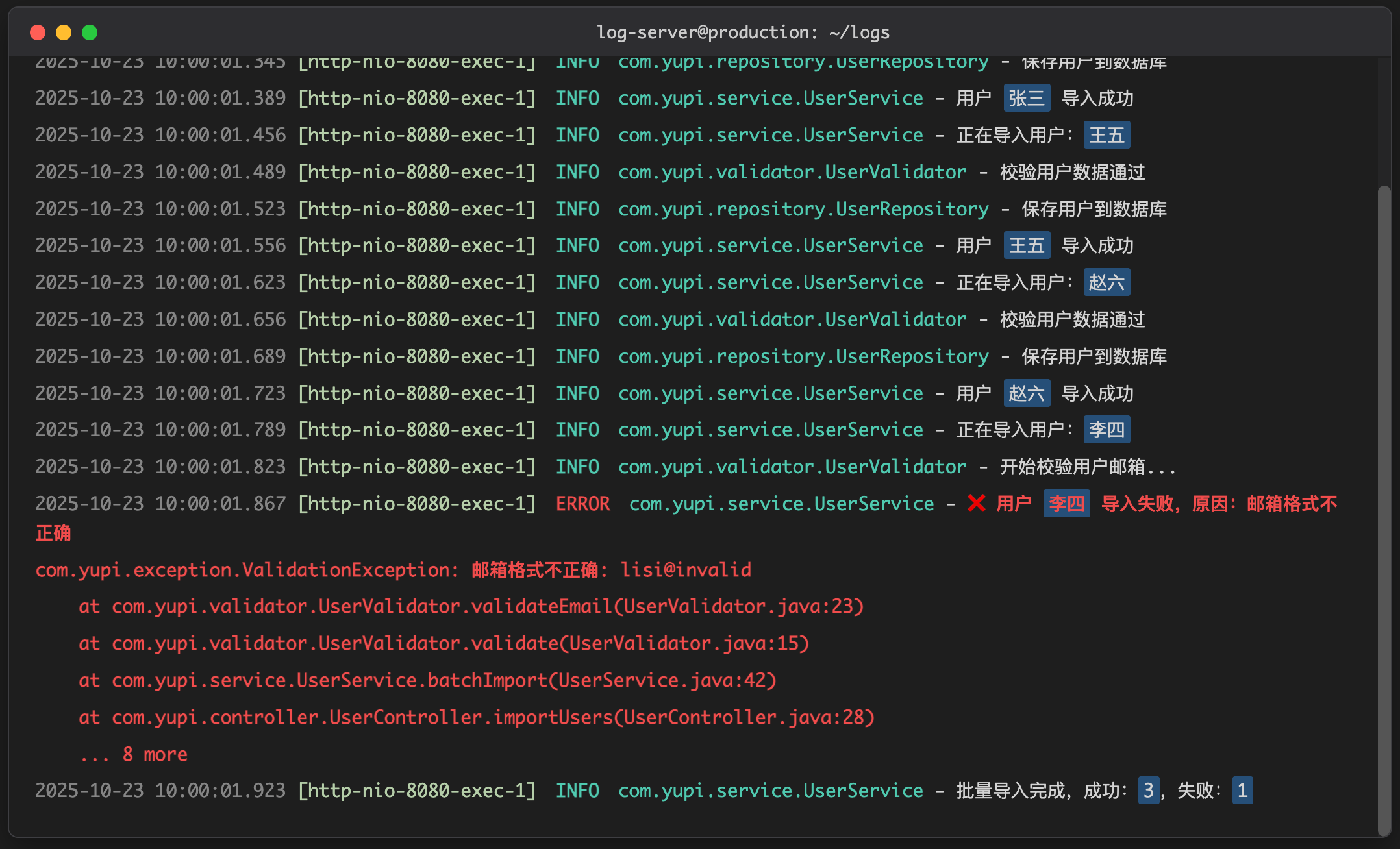
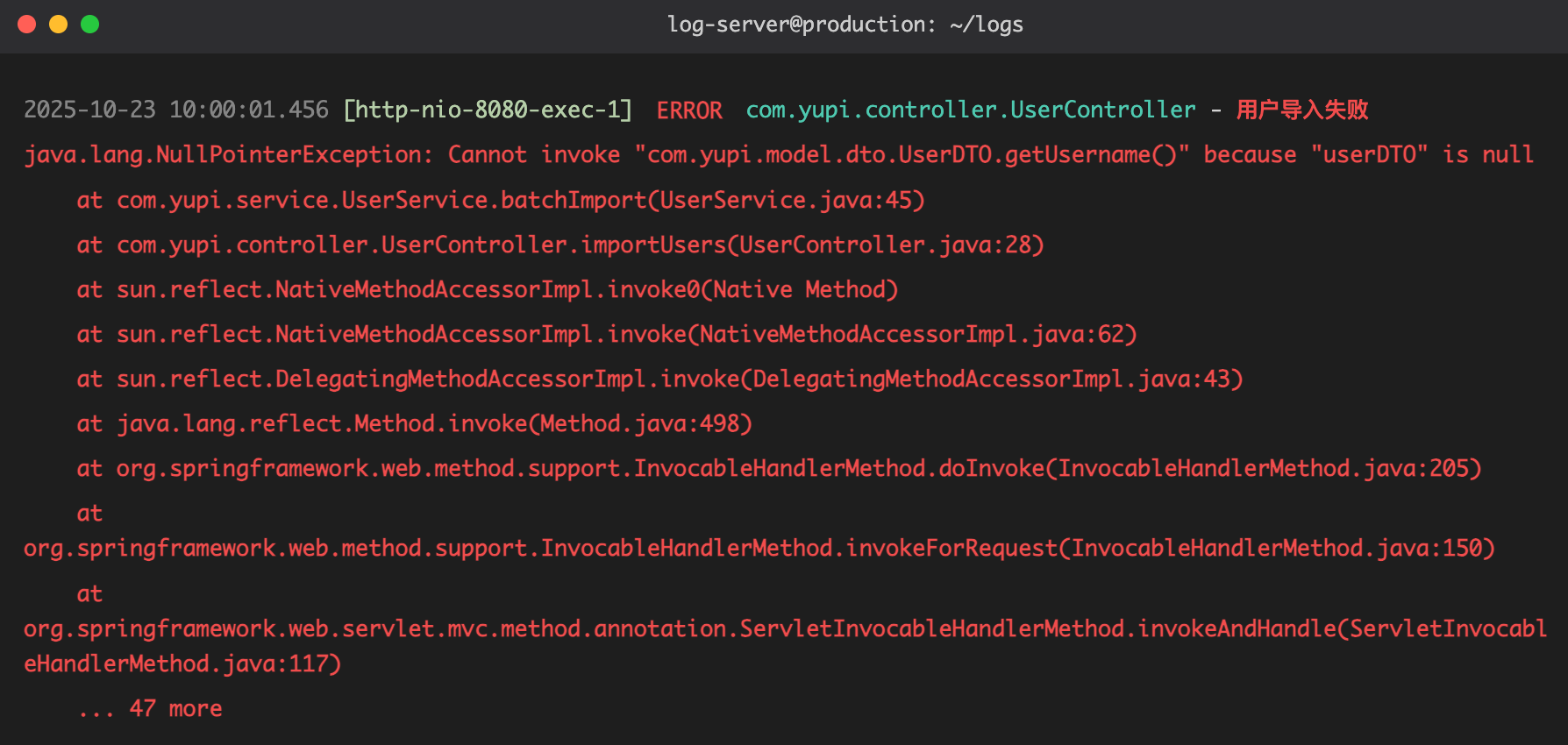
你赶紧打开服务器,看着比你发量都少的报错信息:

你一脸懵逼:只有这点儿信息,我咋知道哪里出了问题啊?!
你只能硬着头皮让产品经理找用户要数据,然后一条条测试,看看是哪条数据出了问题……
原本大好的摸鱼时光,就这样无了。
这时,你的导师鱼皮走了过来,问道:小阿巴,你是持矢了么?脸色这么难看?

你无奈地说:皮哥,刚才线上出了个 bug,我花了 8 个小时才定位到问题……
鱼皮皱了皱眉:这么久?你没打日志吗?
你很是疑惑:谁是日志?为什么要打它?

鱼皮叹了口气:唉,难怪你要花这么久…… 来,我教你打日志!
⭐️ 本文对应视频版:
什么是日志?
鱼皮打开电脑,给你看了一段代码:
你看着代码里的 log.info、log.error,疑惑地问:这些 log 是干什么的?
鱼皮:这就是打日志。日志用来记录程序运行时的状态和信息,这样当系统出现问题时,我们可以通过日志快速定位问题。
你若有所思:哦?还可以这样!如果当初我的代码里有这些日志,一眼就定位到问题了…… 那我应该怎么打日志?用什么技术呢?
怎么打日志?
鱼皮:每种编程语言都有很多日志框架和工具库,比如 Java 可以选用 Log4j 2、Logback 等等。咱们公司用的是 Spring Boot,它默认集成了 Logback 日志框架,你直接用就行,不用再引入额外的库了~

日志框架的使用非常简单,先获取到 Logger 日志对象。
1)方法 1:通过 LoggerFactory 手动获取 Logger 日志对象:
public class MyService {
private static final Logger logger = LoggerFactory.getLogger(MyService.class);
}
2)方法 2:使用 this.getClass 获取当前类的类型,来创建 Logger 对象:
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
}
然后调用 logger.xxx(比如 logger.info)就能输出日志了。
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void doSomething() {
logger.info("执行了一些操作");
}
}
效果如图:

小阿巴:啊,每个需要打日志的类都要加上这行代码么?
鱼皮:还有更简单的方式,使用 Lombok 工具库提供的 @Slf4j 注解,可以自动为当前类生成日志对象,不用手动定义啦。
上面的代码等同于 “自动为当前类生成日志对象”:
private static final org.slf4j.Logger log =
org.slf4j.LoggerFactory.getLogger(MyService.class);
你咧嘴一笑:这个好,爽爽爽!

等等,不对,我直接用 Java 自带的 System.out.println 不也能输出信息么?何必多此一举?
System.out.println("开始导入用户" + user.getUsername());
鱼皮摇了摇头:千万别这么干!
首先,System.out.println 是一个同步方法,每次调用都会导致耗时的 I/O 操作,频繁调用会影响程序的性能。

而且它只能输出信息到控制台,不能灵活控制输出位置、输出格式、输出时机等等。比如你现在想看三天前的日志,System.out.println 的输出早就被刷没了,你还得浪费时间找半天。

你恍然大悟:原来如此!那使用日志框架就能解决这些问题吗?
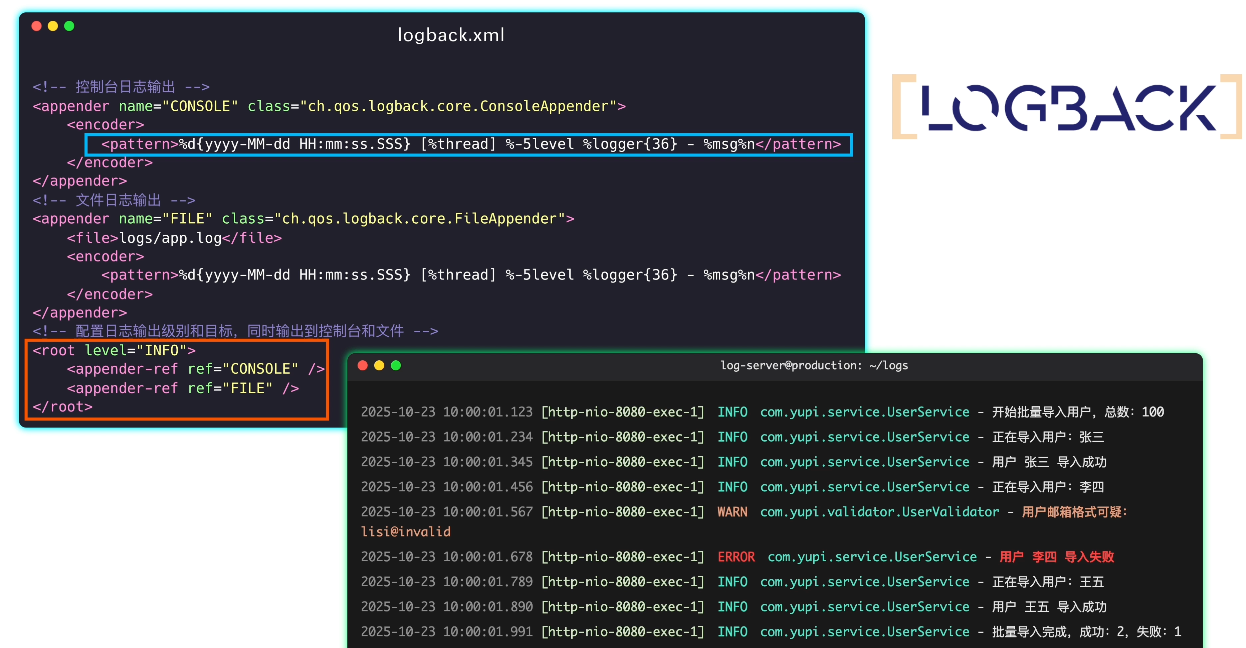
鱼皮点点头:没错,日志框架提供了丰富的打日志方法,还可以通过修改日志配置文件来随心所欲地调教日志,比如把日志同时输出到控制台和文件中、设置日志格式、控制日志级别等等。
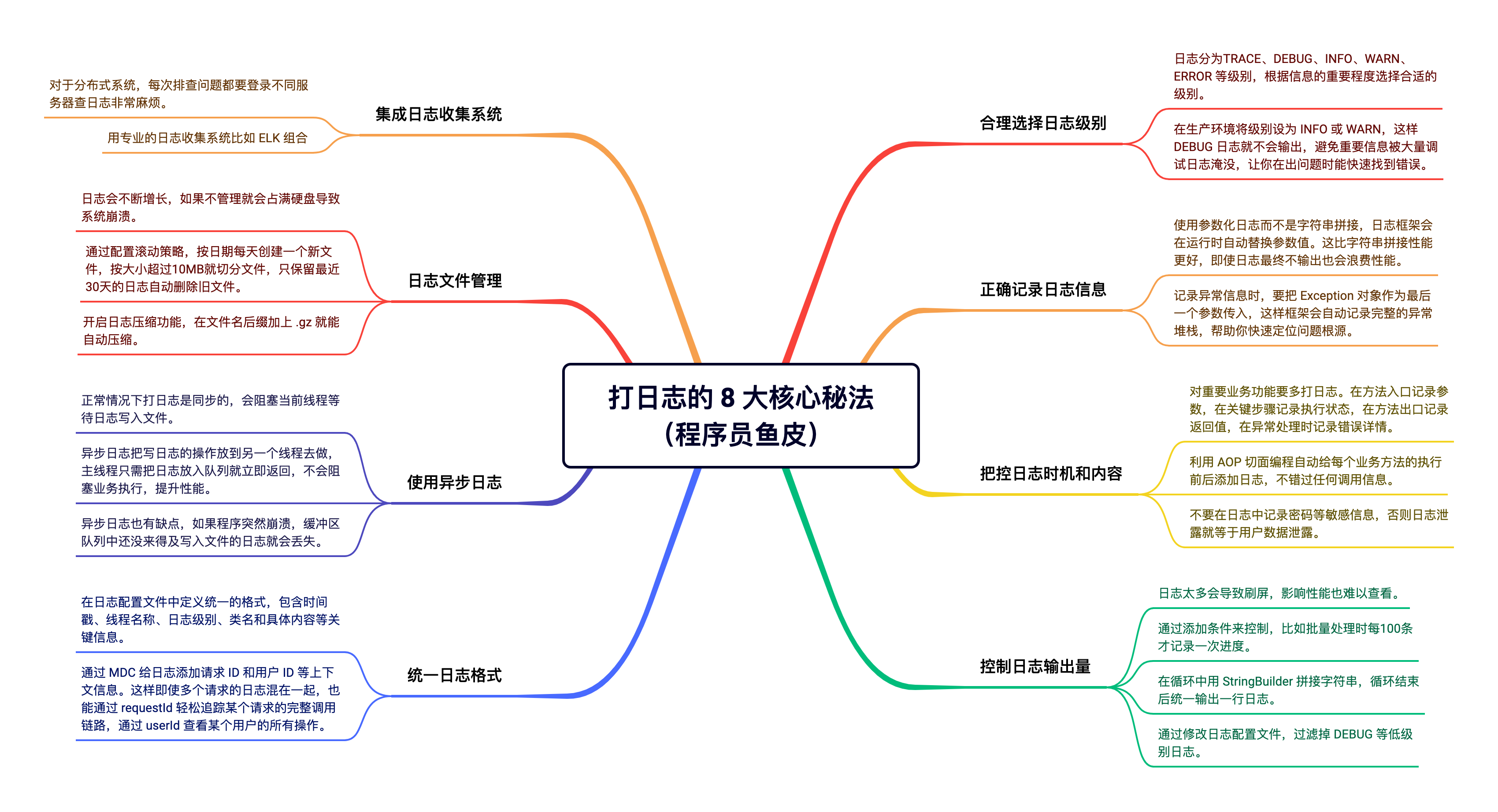
在下苦心研究日志多年,沉淀了打日志的 8 大邪修秘法,先传授你 2 招最基础的吧。
打日志的 8 大最佳实践
1、合理选择日志级别
第一招,日志分级。
你好奇道:日志还有级别?苹果日志、安卓日志?
鱼皮给了你一巴掌:可不要乱说,日志的级别是按照重要程度进行划分的。

其中 DEBUG、INFO、WARN 和 ERROR 用的最多。
-
调试用的详细信息用 DEBUG
-
正常的业务流程用 INFO
-
可能有问题但不影响主流程的用 WARN
-
出现异常或错误的用 ERROR
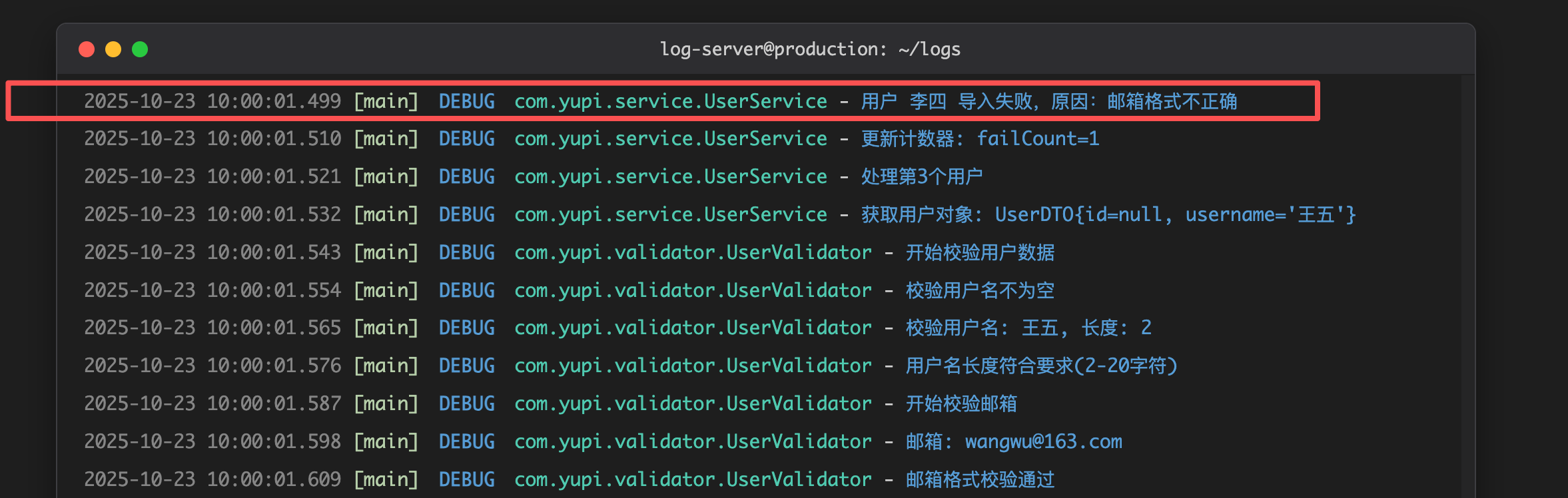
log.debug("用户对象的详细信息:{}", userDTO); // 调试信息
log.info("用户 {} 开始导入", username); // 正常流程信息
log.warn("用户 {} 的邮箱格式可疑,但仍然导入", username); // 警告信息
log.error("用户 {} 导入失败", username, e); // 错误信息
你挠了挠头:俺直接全用 DEBUG 不行么?
鱼皮摇了摇头:如果所有信息都用同一级别,那出了问题时,你怎么快速找到错误信息?
在生产环境,我们通常会把日志级别调高(比如 INFO 或 WARN),这样 DEBUG 级别的日志就不会输出了,防止重要信息被无用日志淹没。
你点点头:俺明白了,不同的场景用不同的级别!
2、正确记录日志信息
鱼皮:没错,下面教你第二招。你注意到我刚才写的日志里有一对大括号 {} 吗?
log.info("用户 {} 开始导入", username);
你回忆了一下:对哦,那是啥啊?
鱼皮:这叫参数化日志。{} 是一个占位符,日志框架会在运行时自动把后面的参数值替换进去。
你挠了挠头:我直接用字符串拼接不行吗?
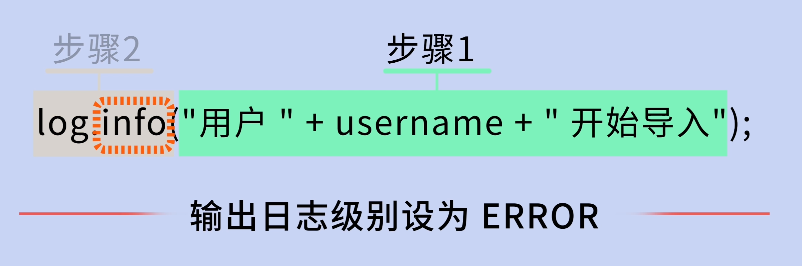
log.info("用户 " + username + " 开始导入");
鱼皮摇摇头:不推荐。因为字符串拼接是在调用 log 方法之前就执行的,即使这条日志最终不被输出,字符串拼接操作还是会执行,白白浪费性能。
你点点头:确实,而且参数化日志比字符串拼接看起来舒服~

鱼皮:没错。而且当你要输出异常信息时,也可以使用参数化日志:
try {
// 业务逻辑
} catch (Exception e) {
log.error("用户 {} 导入失败", username, e); // 注意这个 e
}
这样日志框架会同时记录上下文信息和完整的异常堆栈信息,便于排查问题。
你抱拳:学会了,我这就去打日志!
3、把控时机和内容
很快,你给批量导入程序的代码加上了日志:
光做这点还不够,你还翻出了之前的屎山代码,想给每个文件都打打日志。
但打着打着,你就不耐烦了:每段代码都要打日志,好累啊!但是不打日志又怕出问题,怎么办才好?
鱼皮笑道:好问题,这就是我要教你的第三招 —— 把握打日志的时机。
对于重要的业务功能,我建议采用防御性编程,先多多打日志。比如在方法代码的入口和出口记录参数和返回值、在每个关键步骤记录执行状态,而不是等出了问题无法排查的时候才追悔莫及。之后可以再慢慢移除掉不需要的日志。

你叹了口气:这我知道,但每个方法都打日志,工作量太大,都影响我摸鱼了!
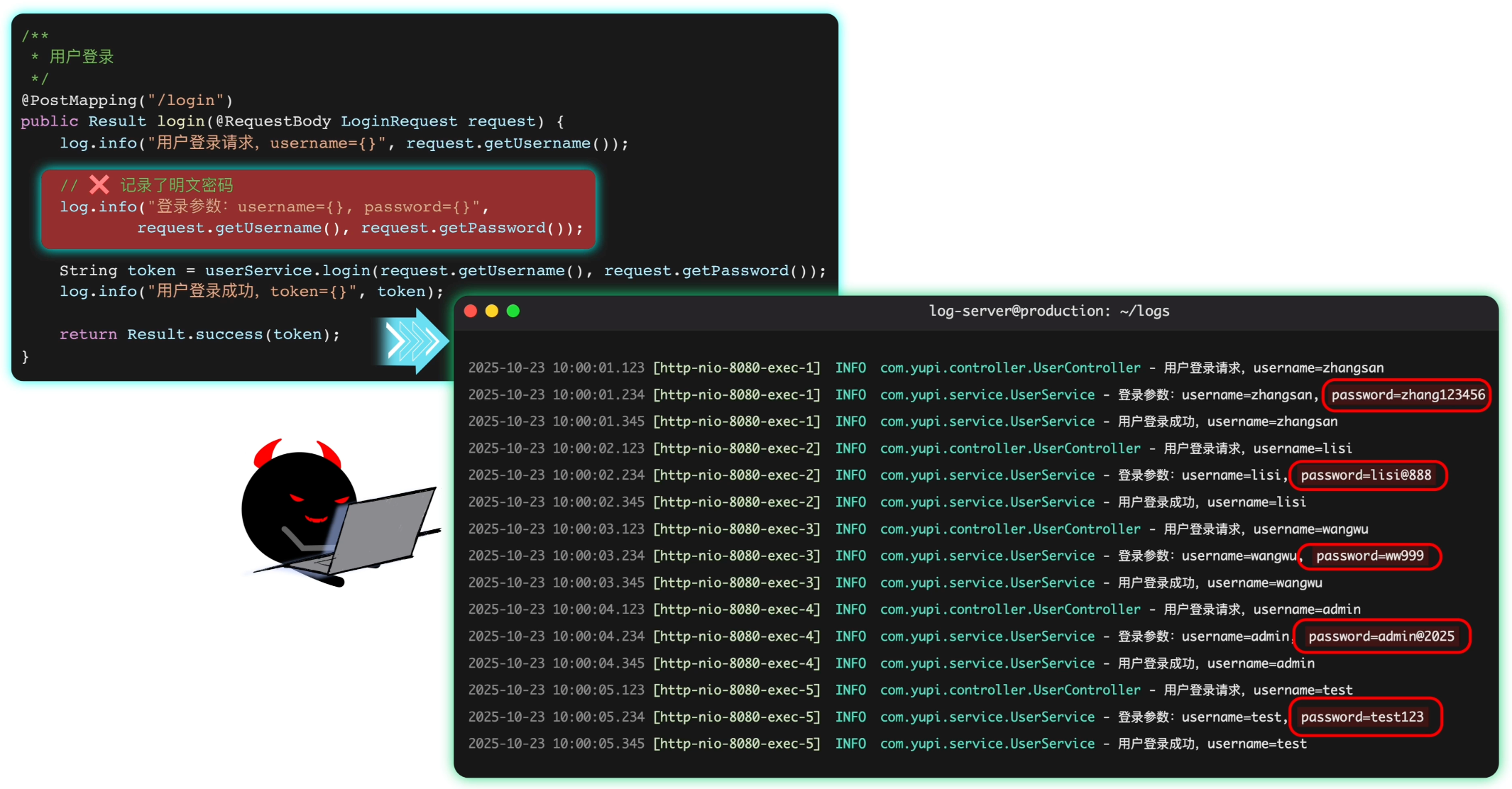
鱼皮:别担心,你可以利用 AOP 切面编程,自动给每个业务方法的执行前后添加日志,这样就不会错过任何一次调用信息了。

你双眼放光:这个好,爽爽爽!

鱼皮:不过这样做也有一个缺点,注意不要在日志中记录了敏感信息,比如用户密码。万一你的日志不小心泄露出去,就相当于泄露了大量用户的信息。
你拍拍胸脯:必须的!
4、控制日志输出量
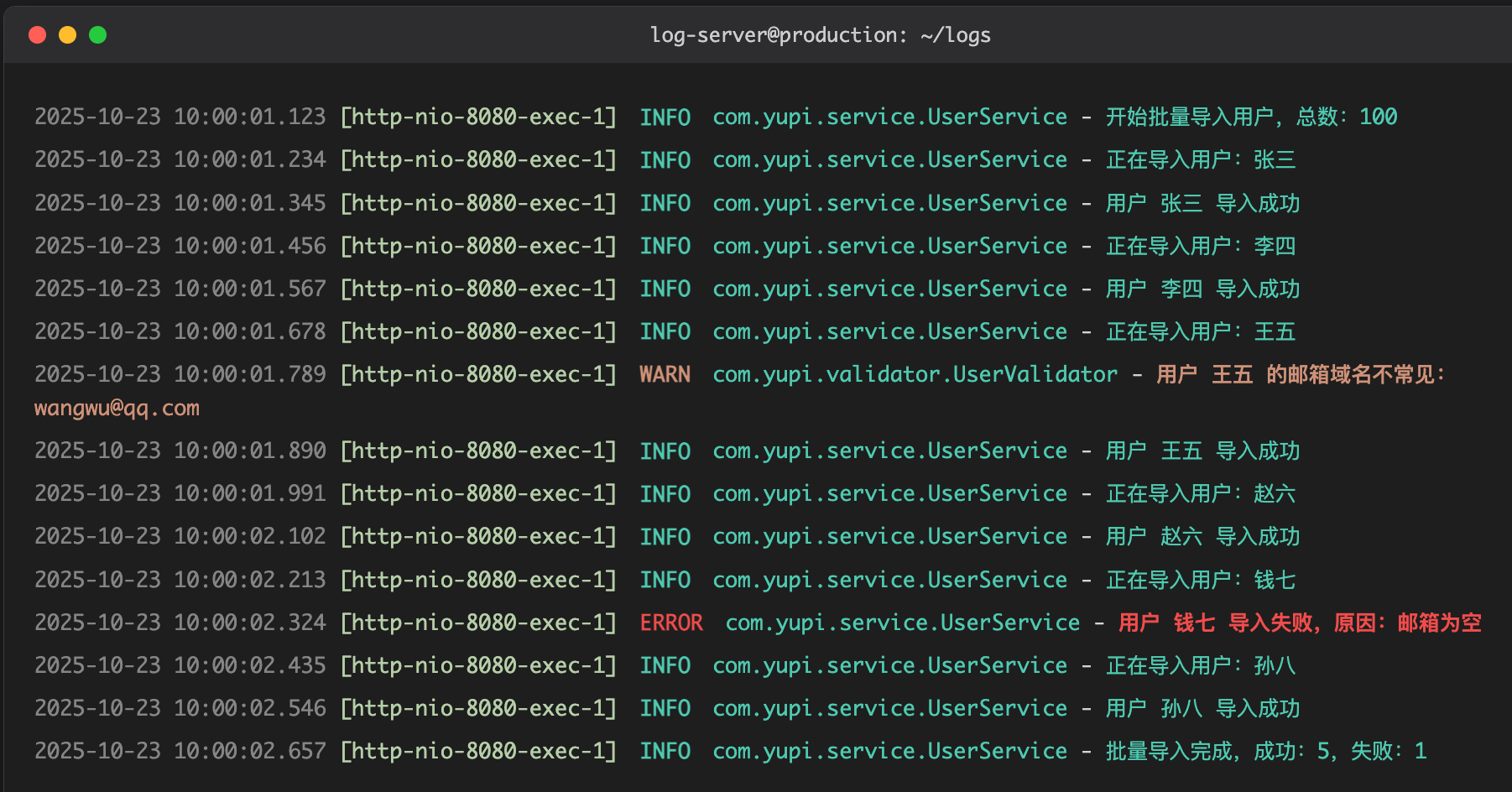
一个星期后,产品经理又来找你了:小阿巴,你的批量导入功能又报错啦!而且怎么感觉程序变慢了?
你完全不慌,淡定地打开服务器的日志文件。结果瞬间呆住了……
好家伙,满屏都是密密麻麻的日志,这可怎么看啊?!

鱼皮看了看你的代码,摇了摇头:你现在每导入一条数据都要打一些日志,如果用户导入 10 万条数据,那就是几十万条日志!不仅刷屏,还会影响性能。
你有点委屈:不是你让我多打日志的么?那我应该怎么办?
鱼皮:你需要控制日志的输出量。
1)可以添加条件来控制,比如每处理 100 条数据时才记录一次:
if ((i + 1) % 100 == 0) {
log.info("批量导入进度:{}/{}", i + 1, userList.size());
}
2)或者在循环中利用 StringBuilder 进行字符串拼接,循环结束后统一输出:
StringBuilder logBuilder = new StringBuilder("处理结果:");
for (UserDTO userDTO : userList) {
processUser(userDTO);
logBuilder.append(String.format("成功[ID=%s], ", userDTO.getId()));
}
log.info(logBuilder.toString());
3)还可以通过修改日志配置文件,过滤掉特定级别的日志,防止日志刷屏:
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>logs/app.log</file>
<!-- 只允许 INFO 级别及以上的日志通过 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
</appender>
5、统一日志格式
你开心了:好耶,这样就不会刷屏了!但是感觉有时候日志很杂很乱,尤其是我想看某一个请求相关的日志时,总是被其他的日志干扰,怎么办?
鱼皮:好问题,可以在日志配置文件中定义统一的日志格式,包含时间戳、线程名称、日志级别、类名、方法名、具体内容等关键信息。
<!-- 控制台日志输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 日志格式 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
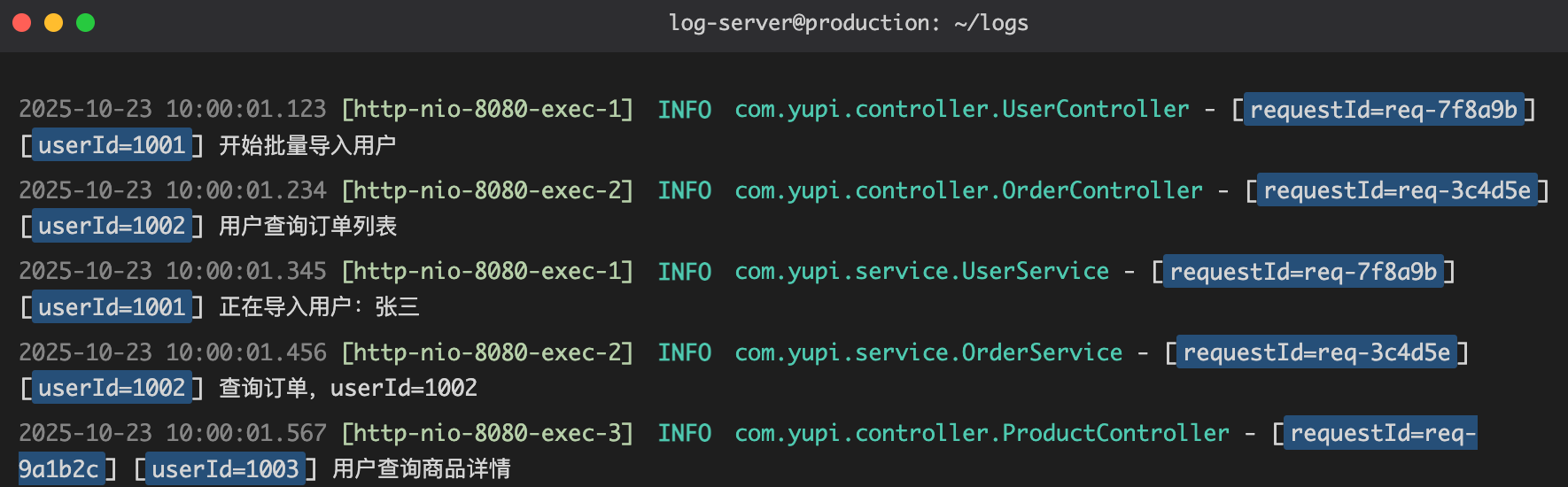
这样输出的日志更整齐易读:
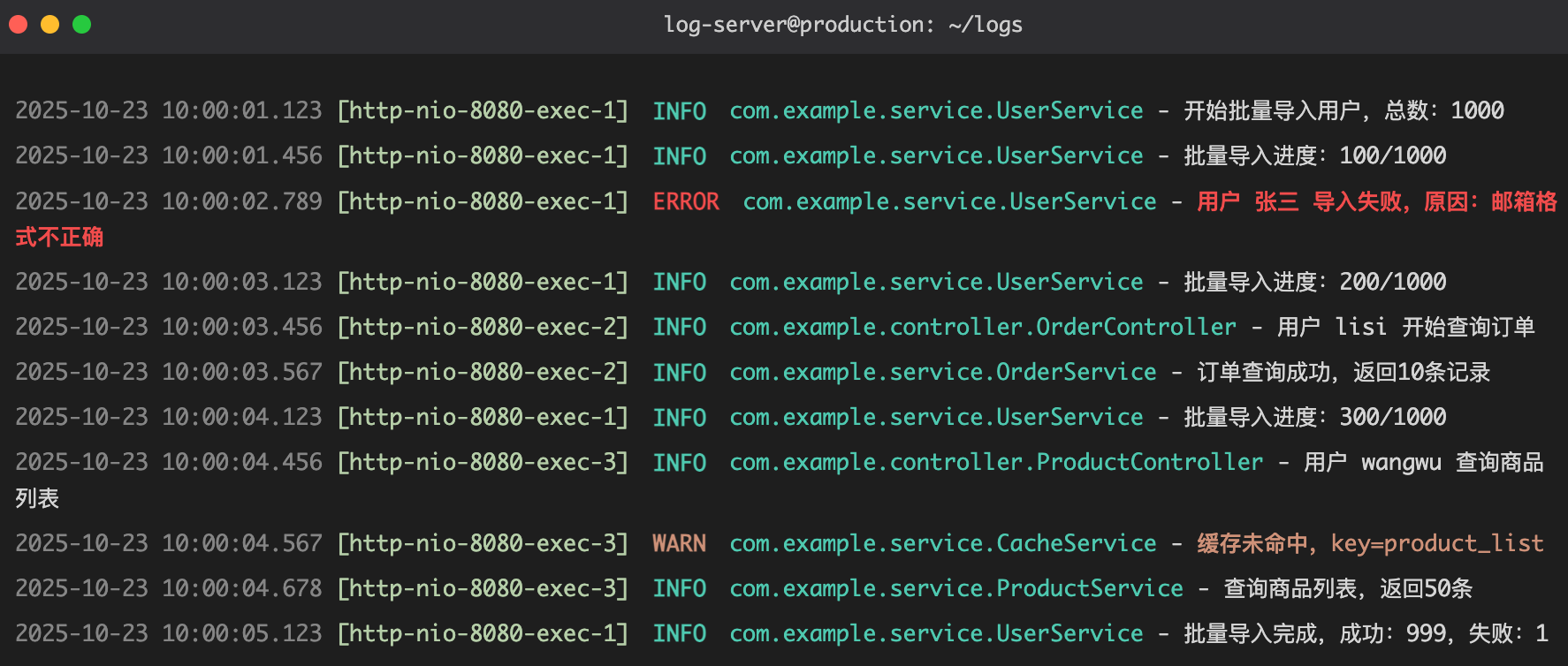
此外,你还可以通过 MDC(Mapped Diagnostic Context)给日志添加额外的上下文信息,比如请求 ID、用户 ID 等,方便追踪。
在 Java 代码中,可以为 MDC 设置属性值:
然后在日志配置文件中就可以使用这些值了:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<!-- 包含 MDC 信息 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [%X{requestId}] [%X{userId}] %msg%n</pattern>
</encoder>
</appender>
这样,每个请求、每个用户的操作一目了然。
6、使用异步日志
你又开心了:这样打出来的日志,确实舒服,爽爽爽!但是我打日志越多,是不是程序就会更慢呢?有没有办法能优化一下?
鱼皮:当然有,可以使用 异步日志。
正常情况下,你调用 log.info() 打日志时,程序会立刻把日志写入文件,这个过程是同步的,会阻塞当前线程。而异步日志会把写日志的操作放到另一个线程里去做,不会阻塞主线程,性能更好。
你眼睛一亮:这么厉害?怎么开启?
鱼皮:很简单,只需要修改一下配置文件:
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>512</queueSize> <!-- 队列大小 -->
<discardingThreshold>0</discardingThreshold> <!-- 丢弃阈值,0 表示不丢弃 -->
<neverBlock>false</neverBlock> <!-- 队列满时是否阻塞,false 表示会阻塞 -->
<appender-ref ref="FILE" /> <!-- 引用实际的日志输出目标 -->
</appender>
<root level="INFO">
<appender-ref ref="ASYNC" />
</root>
不过异步日志也有缺点,如果程序突然崩溃,缓冲区中还没来得及写入文件的日志可能会丢失。

所以要权衡一下,看你的系统更注重性能还是日志的完整性。
你想了想:我们的程序对性能要求比较高,偶尔丢几条日志问题不大,那我就用异步日志吧。
7、日志管理
接下来的很长一段时间,你混的很舒服,有 Bug 都能很快发现。
你甚至觉得 Bug 太少、工作没什么激情,所以没事儿就跟新来的实习生阿坤吹吹牛皮:你知道日志么?我可会打它了!

直到有一天,运维小哥突然跑过来:阿巴阿巴,服务器挂了!你快去看看!
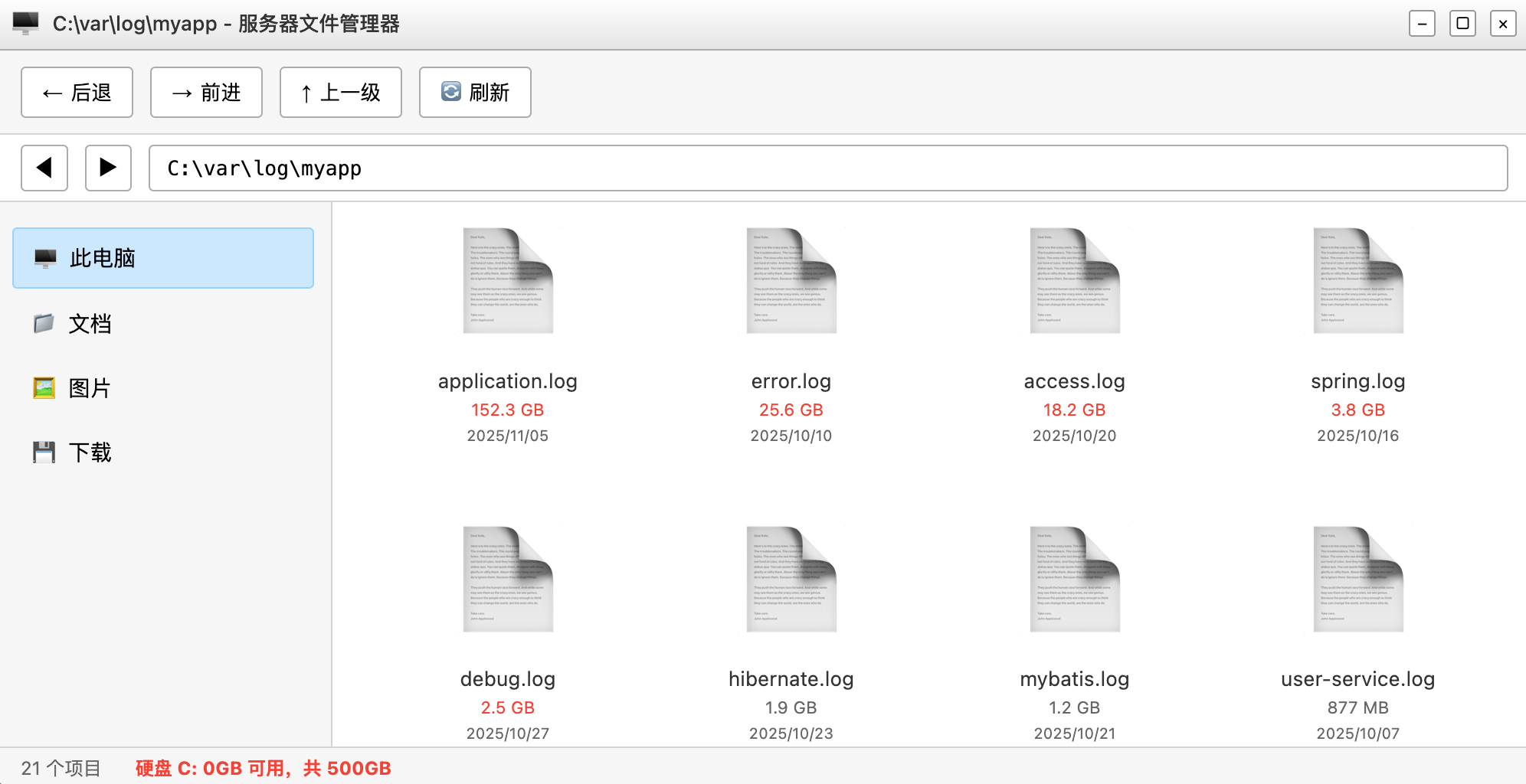
你连忙登录服务器,发现服务器的硬盘爆满了,没法写入新数据。
你查了一下,发现日志文件竟然占了 200GB 的空间!
你汗流浃背了,正在考虑怎么甩锅,结果阿坤突然鸡叫起来:阿巴 giegie,你的日志文件是不是从来没清理过?
你尴尬地倒了个立,这样眼泪就不会留下来。

鱼皮叹了口气:这就是我要教你的下一招 —— 日志管理。
你好奇道:怎么管理?我每天登服务器删掉一些历史文件?
鱼皮:人工操作也太麻烦了,我们可以通过修改日志配置文件,让框架帮忙管理日志。
首先设置日志的滚动策略,可以根据文件大小和日期,自动对日志文件进行切分。
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>10MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
这样配置后,每天会创建一个新的日志文件(比如 app-2025-10-23.0.log),如果日志文件大小超过 10MB 就再创建一个(比如 app-2025-10-23.1.log),并且只保留最近 30 天的日志。
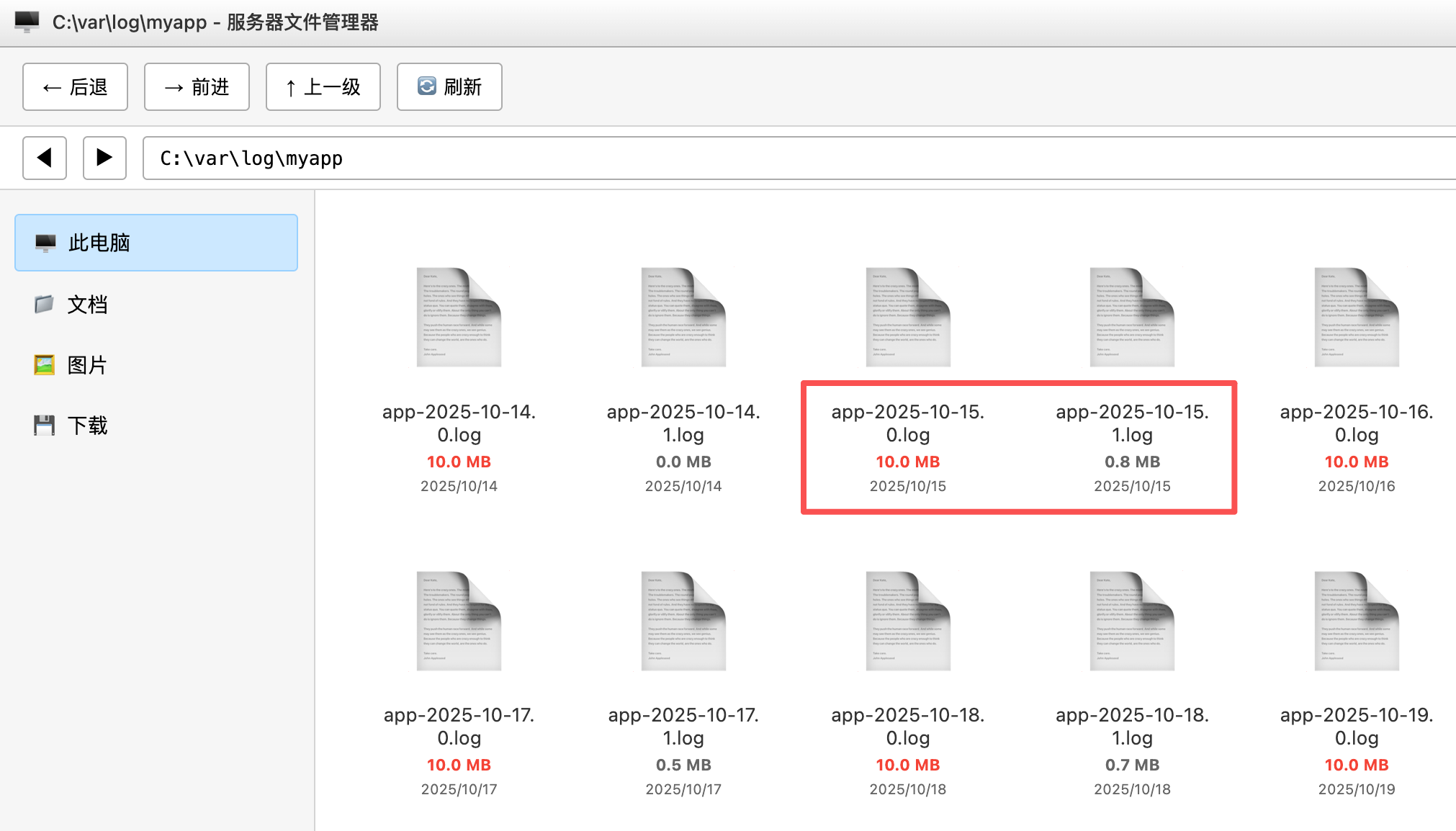
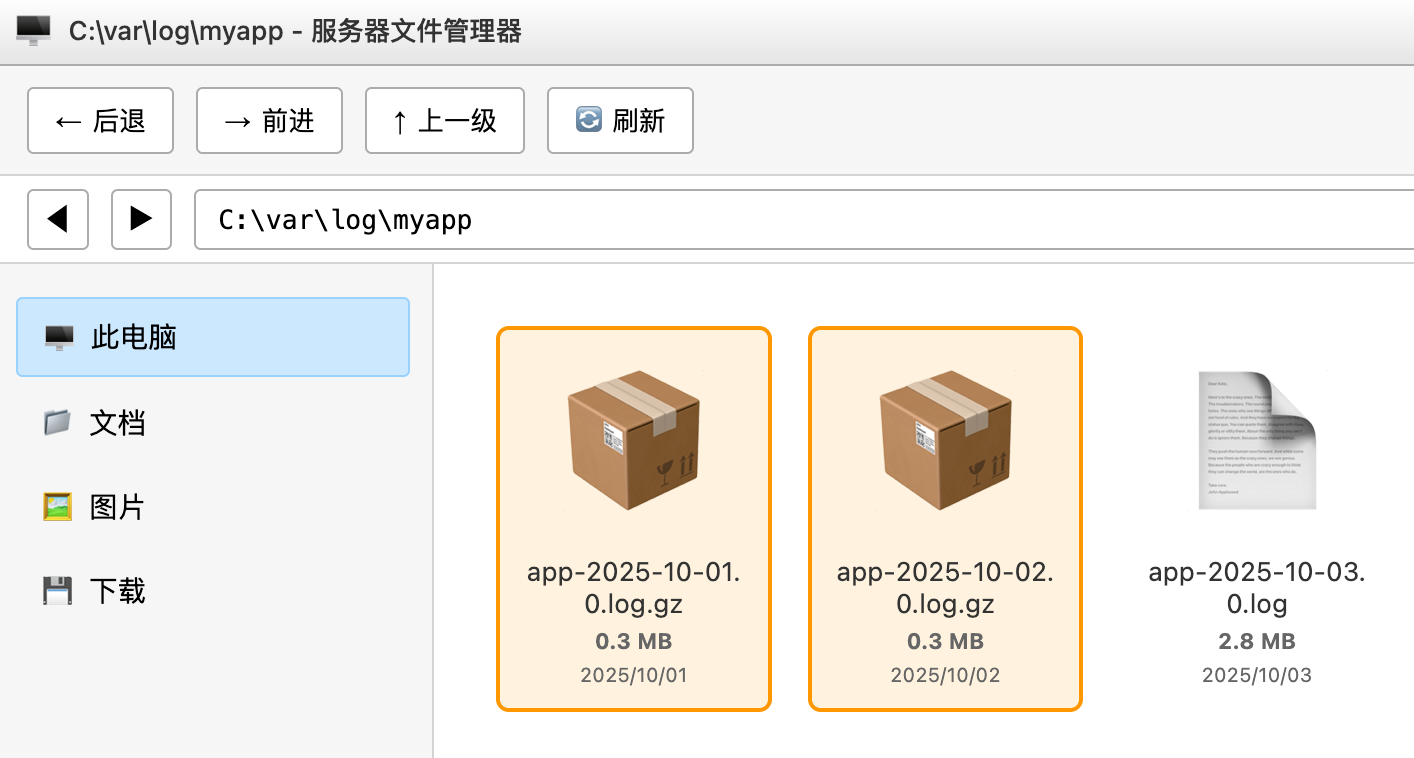
还可以开启日志压缩功能,进一步节省磁盘空间:
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- .gz 后缀会自动压缩 -->
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log.gz</fileNamePattern>
</rollingPolicy>
你有些激动:吼吼,这样我们就可以按照天数更快地查看日志,服务器硬盘也有救啦!
8、集成日志收集系统
两年后,你负责的项目已经发展成了一个大型的分布式系统,有好几十个微服务。
如今,每次排查问题你都要登录到不同的服务器上查看日志,非常麻烦。而且有些请求的调用链路很长,你得登录好几台服务器、看好几个服务的日志,才能追踪到一个请求的完整调用过程。

你简直要疯了!
于是你找到鱼皮求助:现在查日志太麻烦了,当年你还有一招没有教我,现在是不是……
鱼皮点点头:嗯,对于分布式系统,就必须要用专业的日志收集系统了,比如很流行的 ELK。
你好奇:ELK 是啥?伊拉克?
阿坤抢答道:我知道,就是 Elasticsearch + Logstash + Kibana 这套组合。
简单来说,Logstash 负责收集各个服务的日志,然后发送给 Elasticsearch 存储和索引,最后通过 Kibana 提供一个可视化的界面。
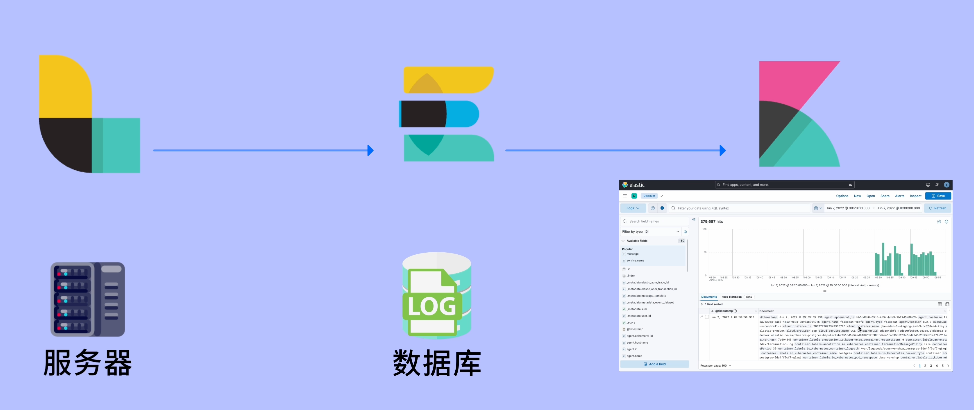
这样一来,我们可以方便地集中搜索、查看、分析日志。
你惊讶了:原来日志还能这么玩,以后我所有的项目都要用 ELK!
鱼皮摆摆手:不过 ELK 的搭建和运维成本比较高,对于小团队来说可能有点重,还是要按需采用啊。
结局
至此,你已经掌握了打日志的核心秘法。
只是你很疑惑,为何那阿坤竟对日志系统如此熟悉?
阿坤苦笑道:我本来就是日志管理大师,可惜我上家公司的同事从来不打日志,所以我把他们暴打了一顿后跑路了。
阿巴 giegie 你要记住,日志不是写给机器看的,是写给未来的你和你的队友看的!
你要是以后不打日志,我就打你!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号